
摘要:
https://www.bilibili.com/video/av94519857?p=13 唯一需要知道的就是链式法则:引入隐变量。 只需要计算每1个样本对w的偏微分,然后求和,就得到所有样本对w的偏微分了;(b也是同样的。) 先考虑1个神经元的情况:有两部分,forward pass和backw 阅读全文
摘要:
https://www.bilibili.com/video/av94519857?p=12 如果没有参数,就是一个function set: 一连串矩阵运算 Loss function 阅读全文
摘要:
https://www.bilibili.com/video/av94519857?p=10 https://www.bilibili.com/video/av94519857?p=11 表格最左一列和最上一行 如果用regression的方法去做classification,就会发生右图的情况。 阅读全文
摘要:
https://www.bilibili.com/video/av94519857?p=8 https://www.bilibili.com/video/av94519857?p=9 总结 一次能够拿到所有训练数据,就是offline learning。 每次梯度反方向 Momentum(累加历史所 阅读全文
摘要:
https://www.bilibili.com/video/av94519857?p=5 https://www.bilibili.com/video/av94519857?p=6 https://www.bilibili.com/video/av94519857?p=7 为什么SGD比GD收敛更 阅读全文
摘要:
https://www.bilibili.com/video/av94519857?p=1 1. 课程介绍 分类、回归、生成 监督、无监督、强化学习 可解释AI、对抗攻击、网络压缩 异常检测(知道自己不知道) 迁移学习(训练和测试的数据分布不同) Meta Learning(学习如何学习, Lear 阅读全文
摘要:
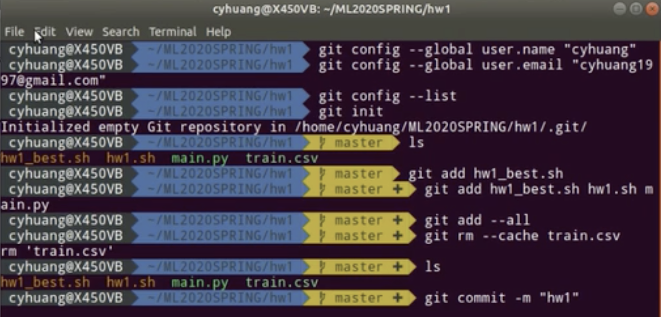 阅读全文
摘要:
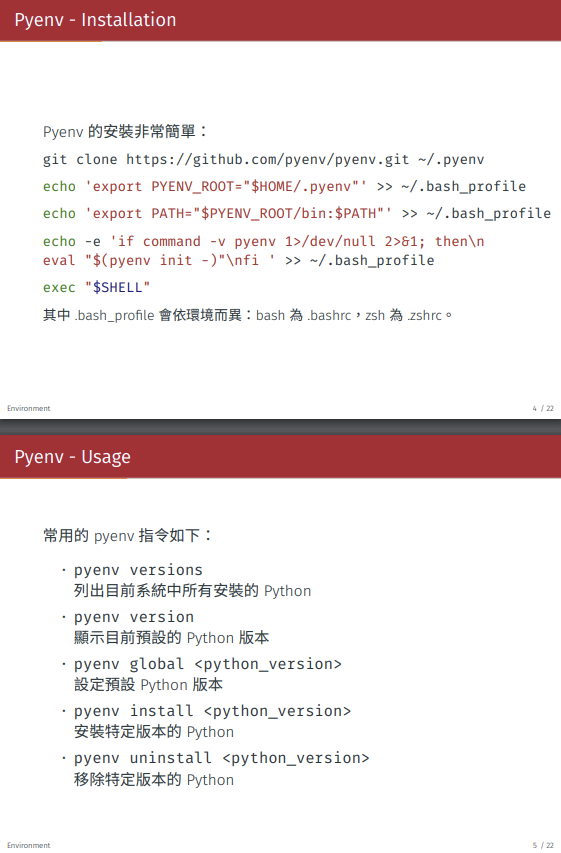 阅读全文