
【2020春】李宏毅机器学习(Tips for DL)

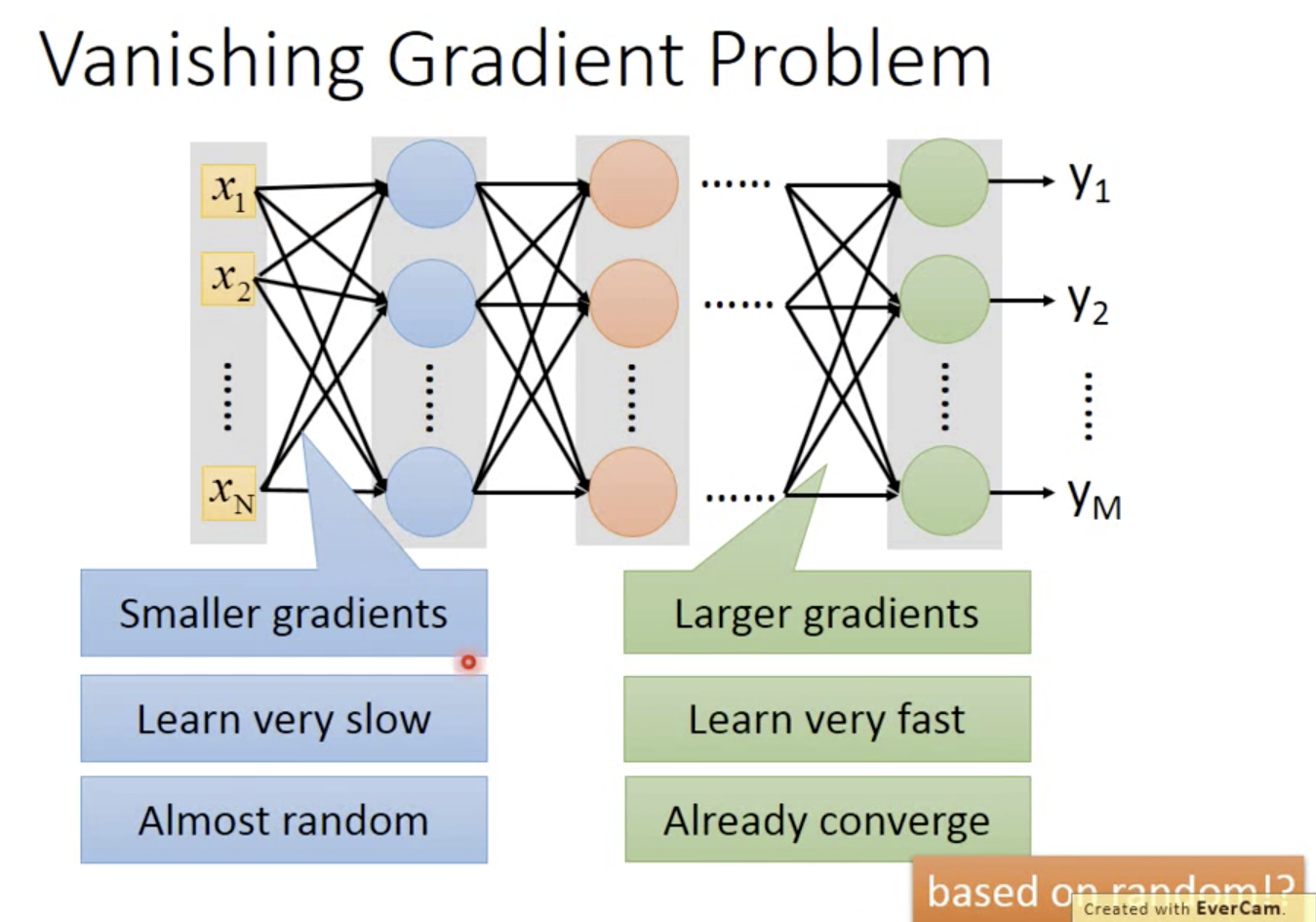
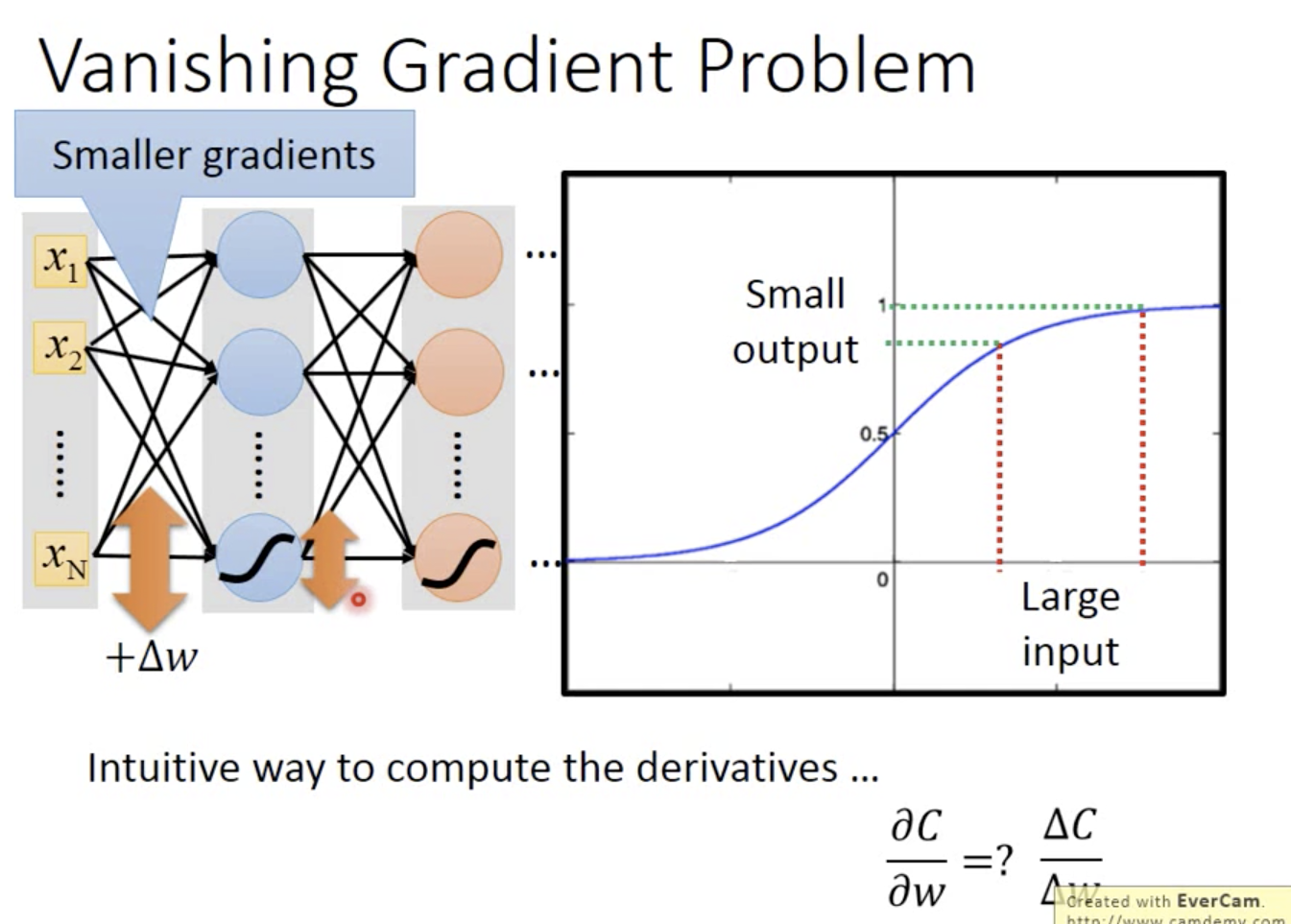
sigmoid会衰减输入的影响(大input,小output),层数过多的话,导致输入对cost的影响几乎为0


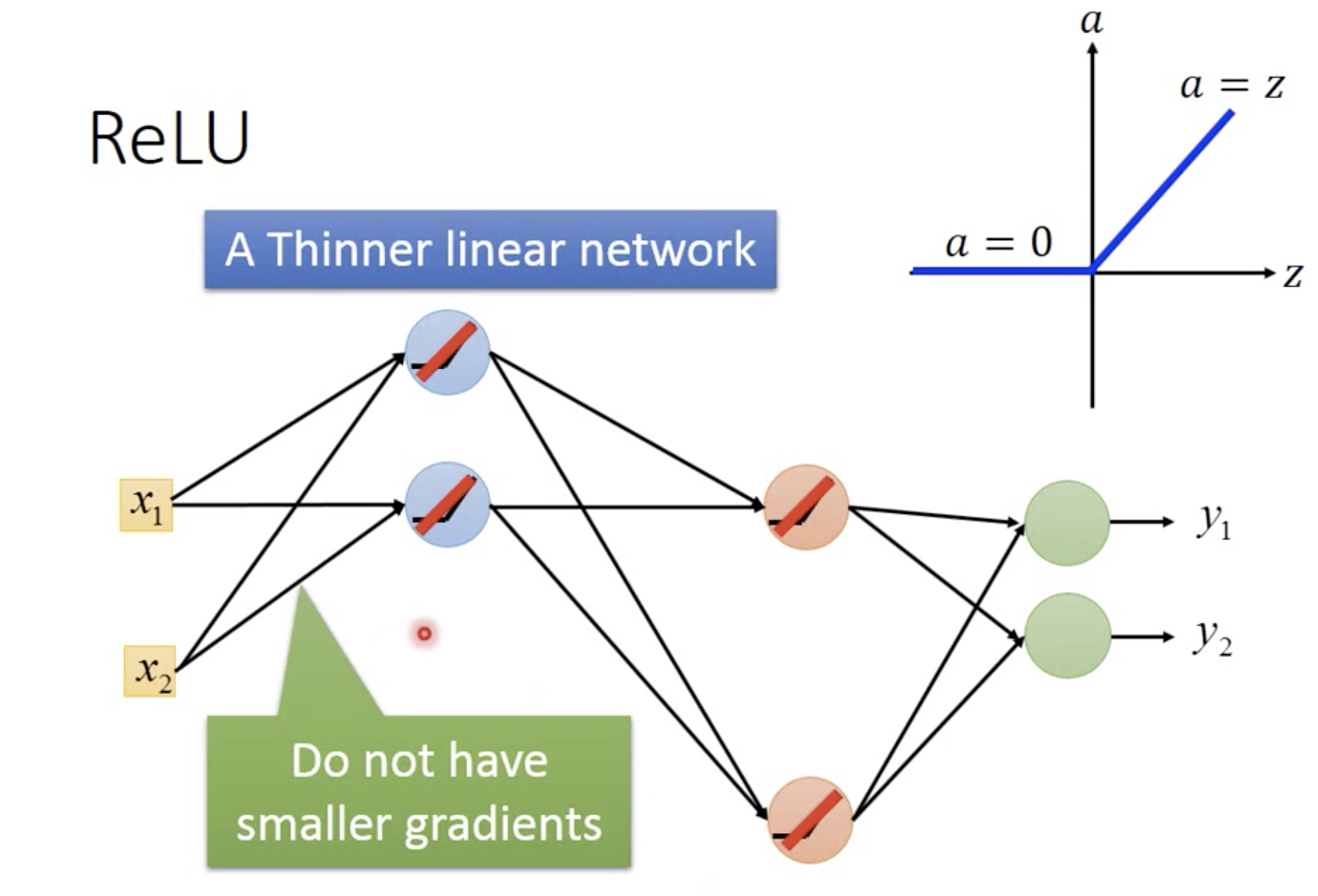

ReLU是Maxout的特例,Maxout比ReLU更灵活

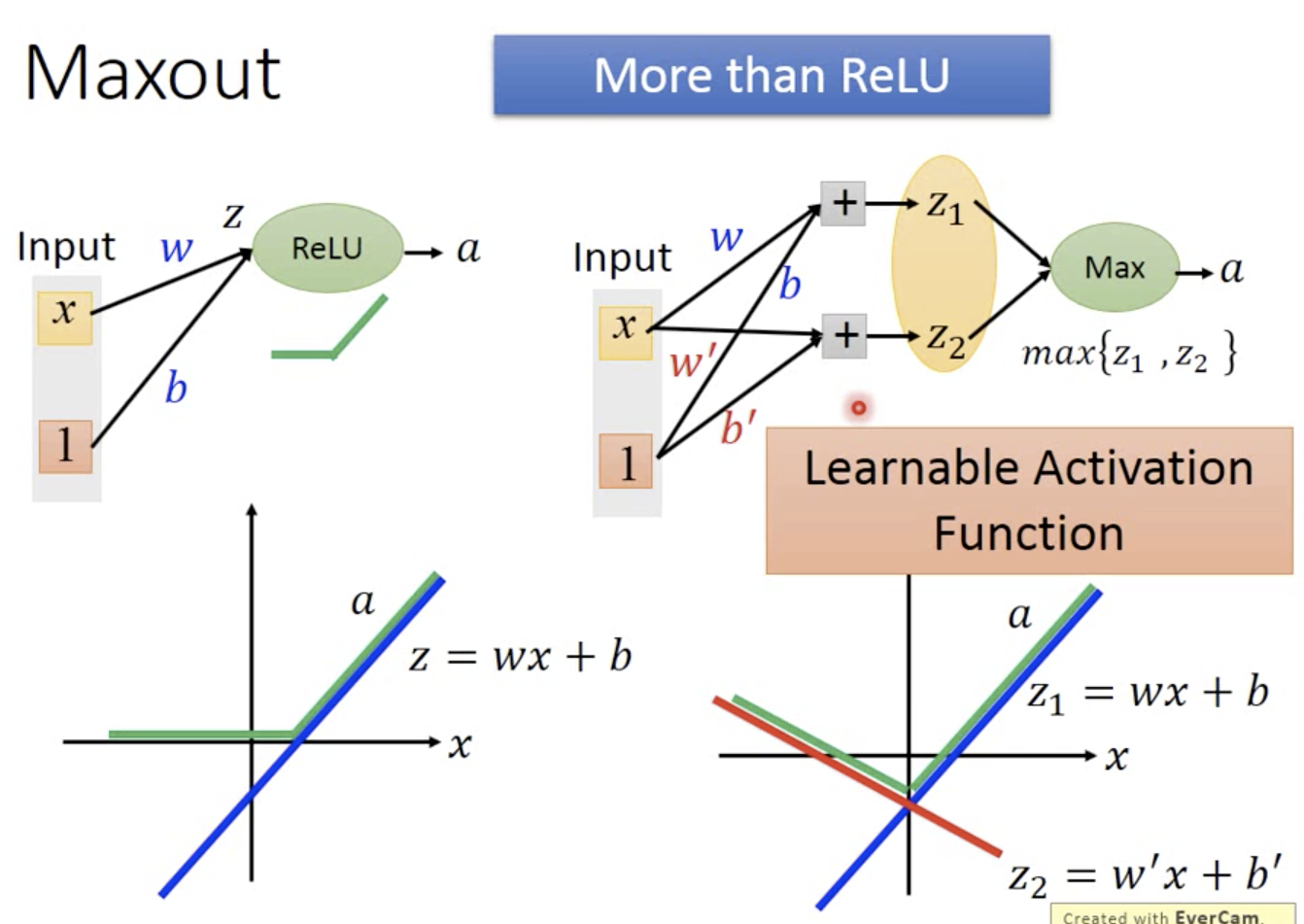

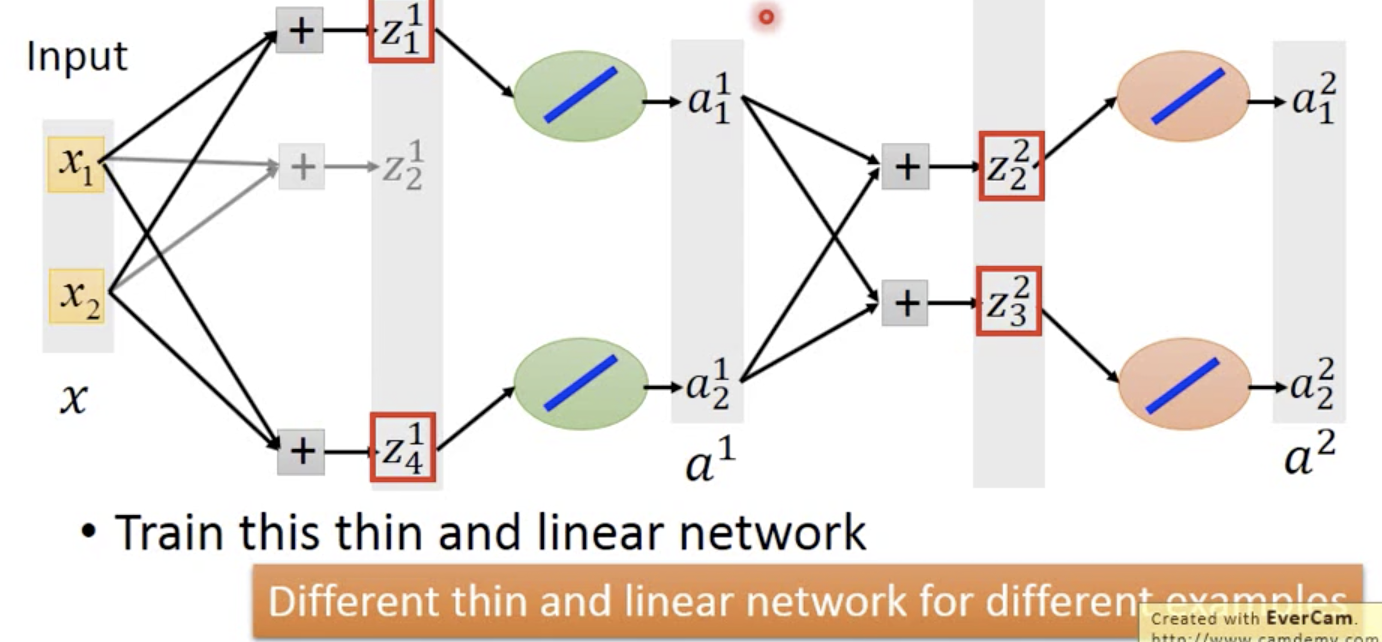
如何训练Maxout

等价这个网络(不同的样本更新不同的参数)
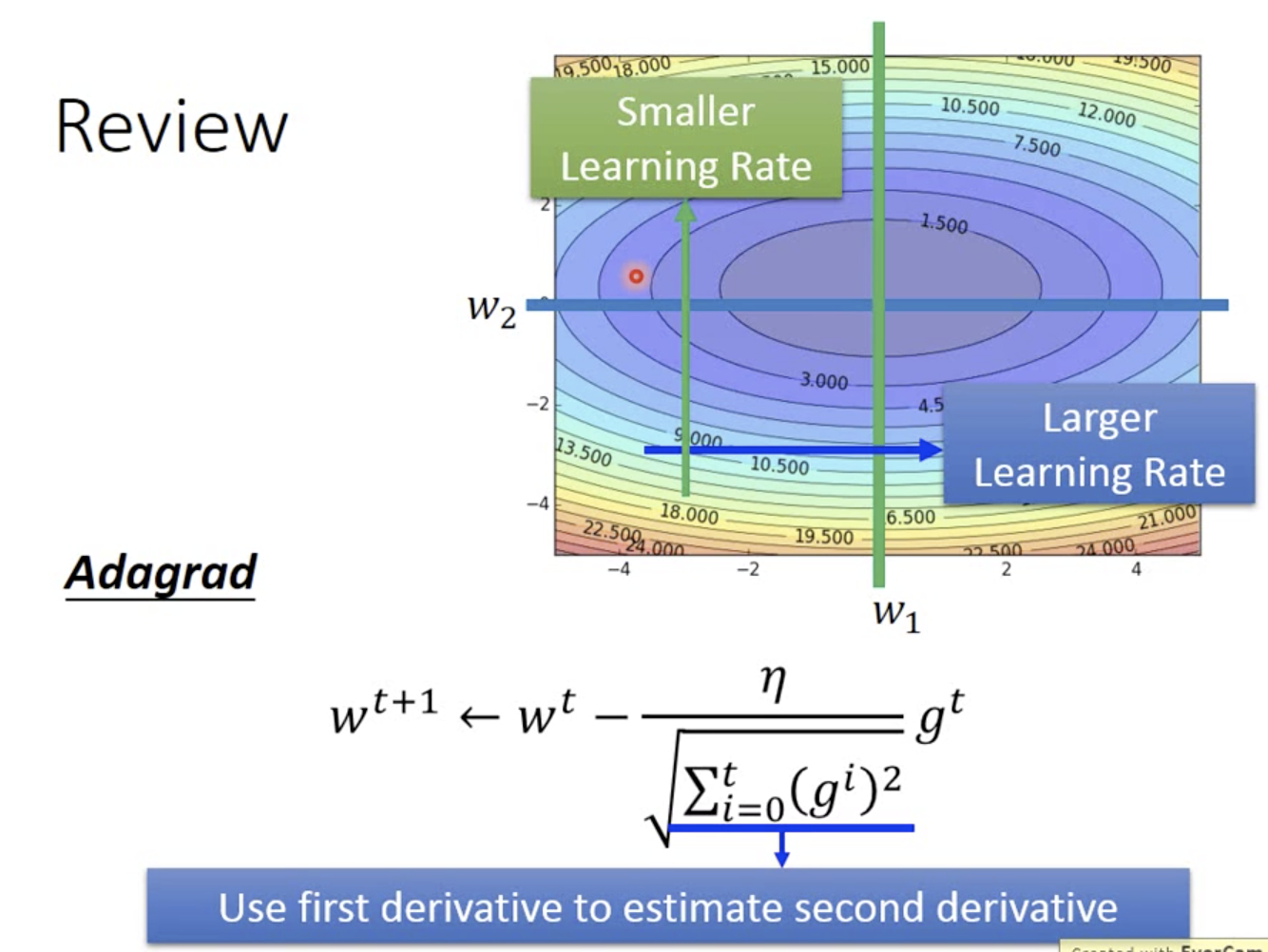
优化器AdaGrad
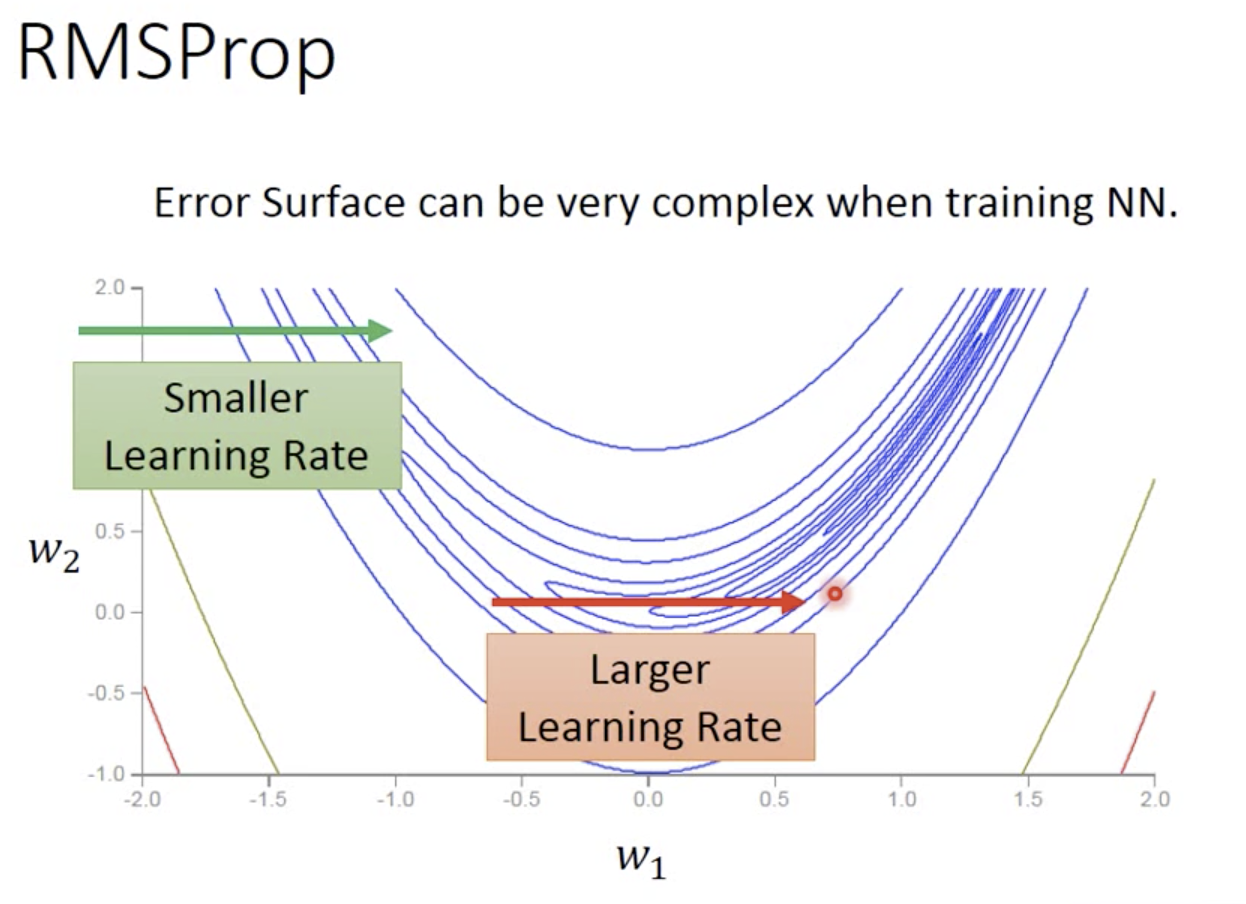
RMSProp

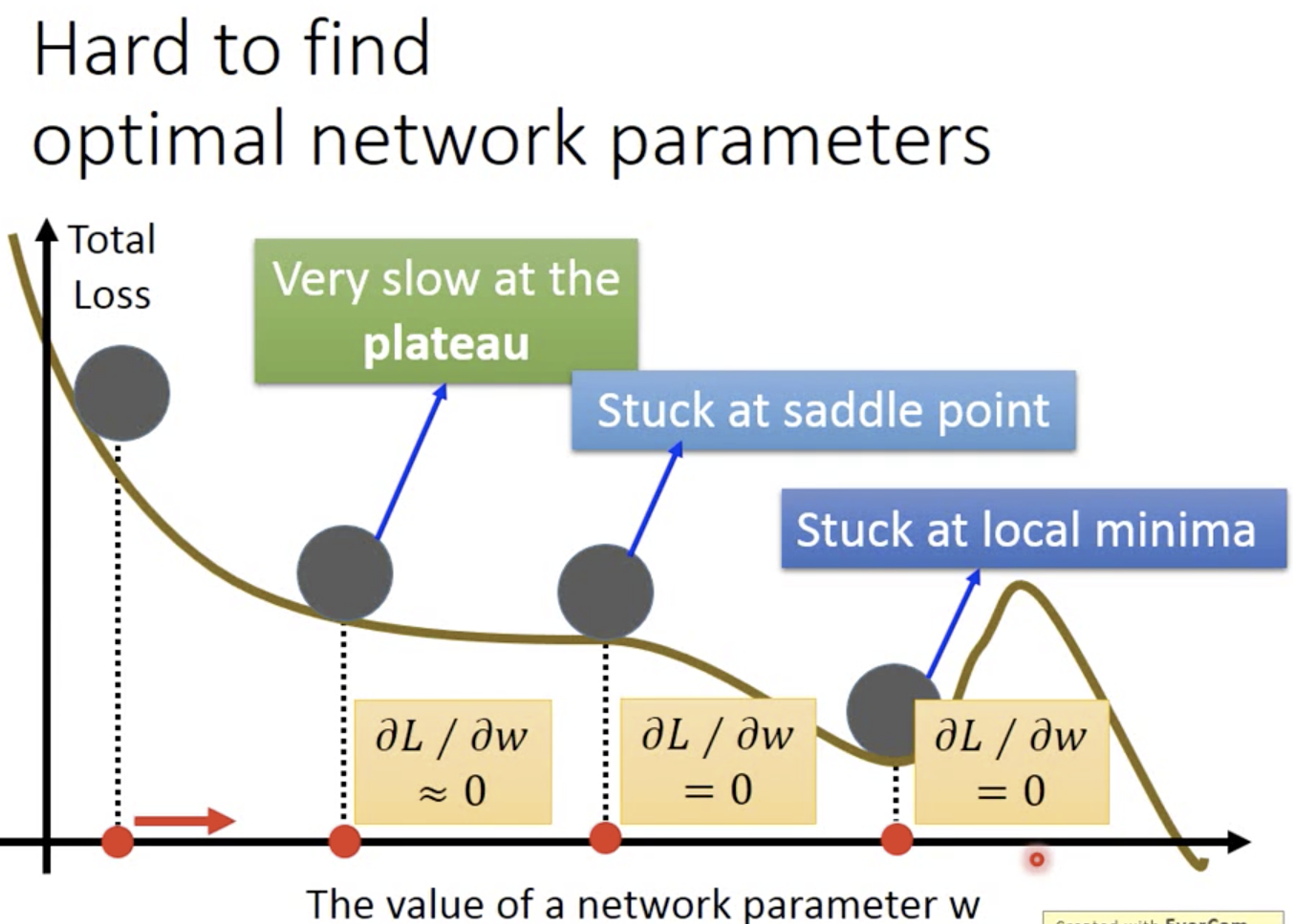
local minima(参数越多,可能性比较小,因为要求每个weight都是最低点) / saddle point / 鞍点
Momentum(动量)

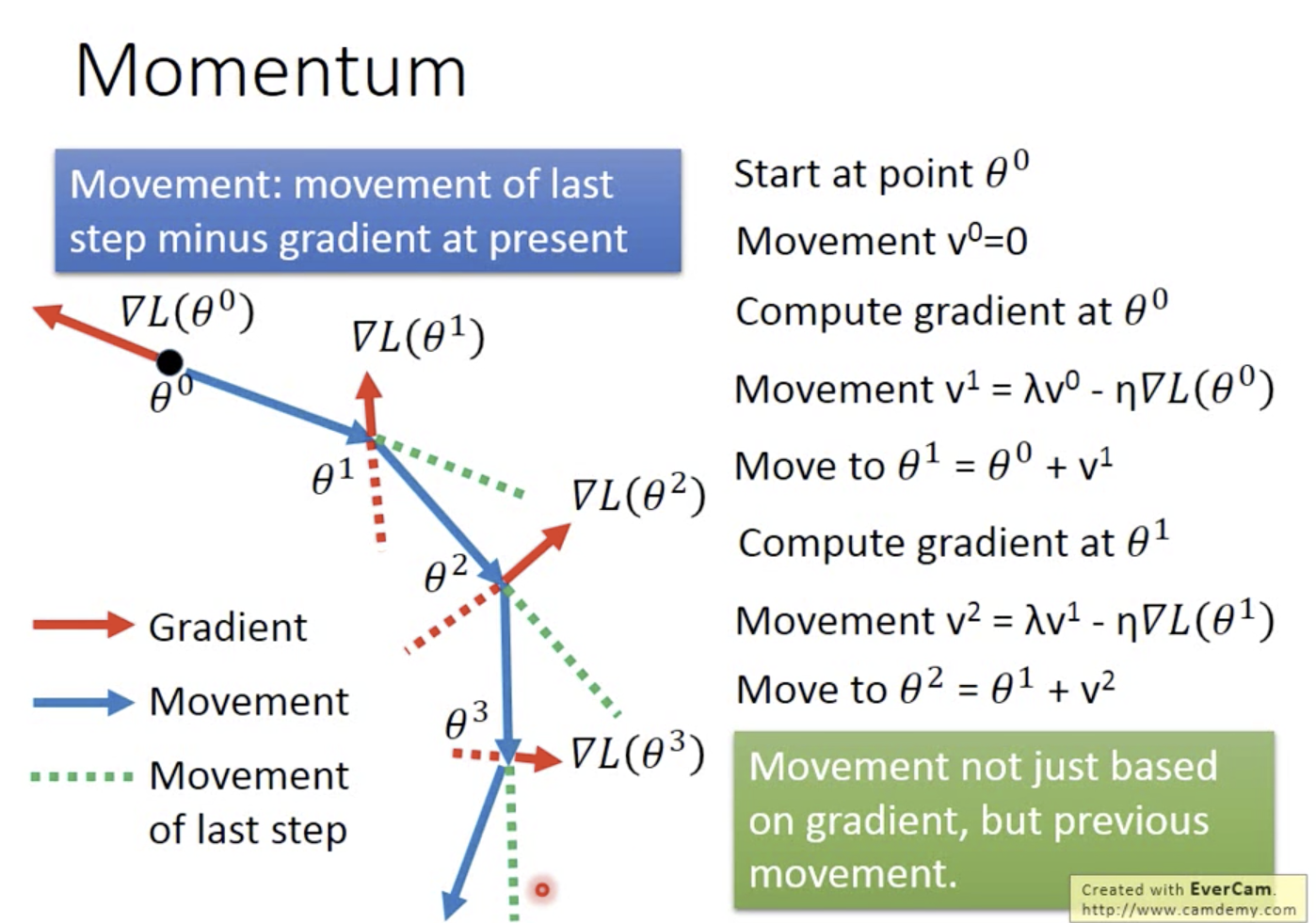
vi是所有历史梯度的加权和
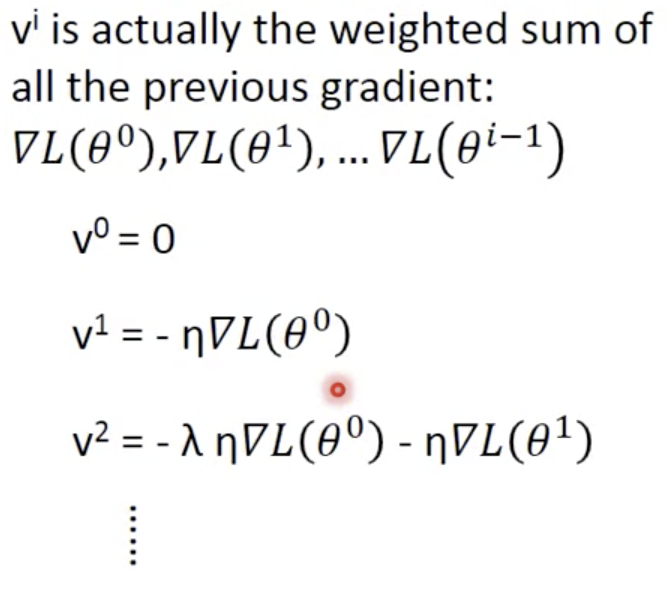


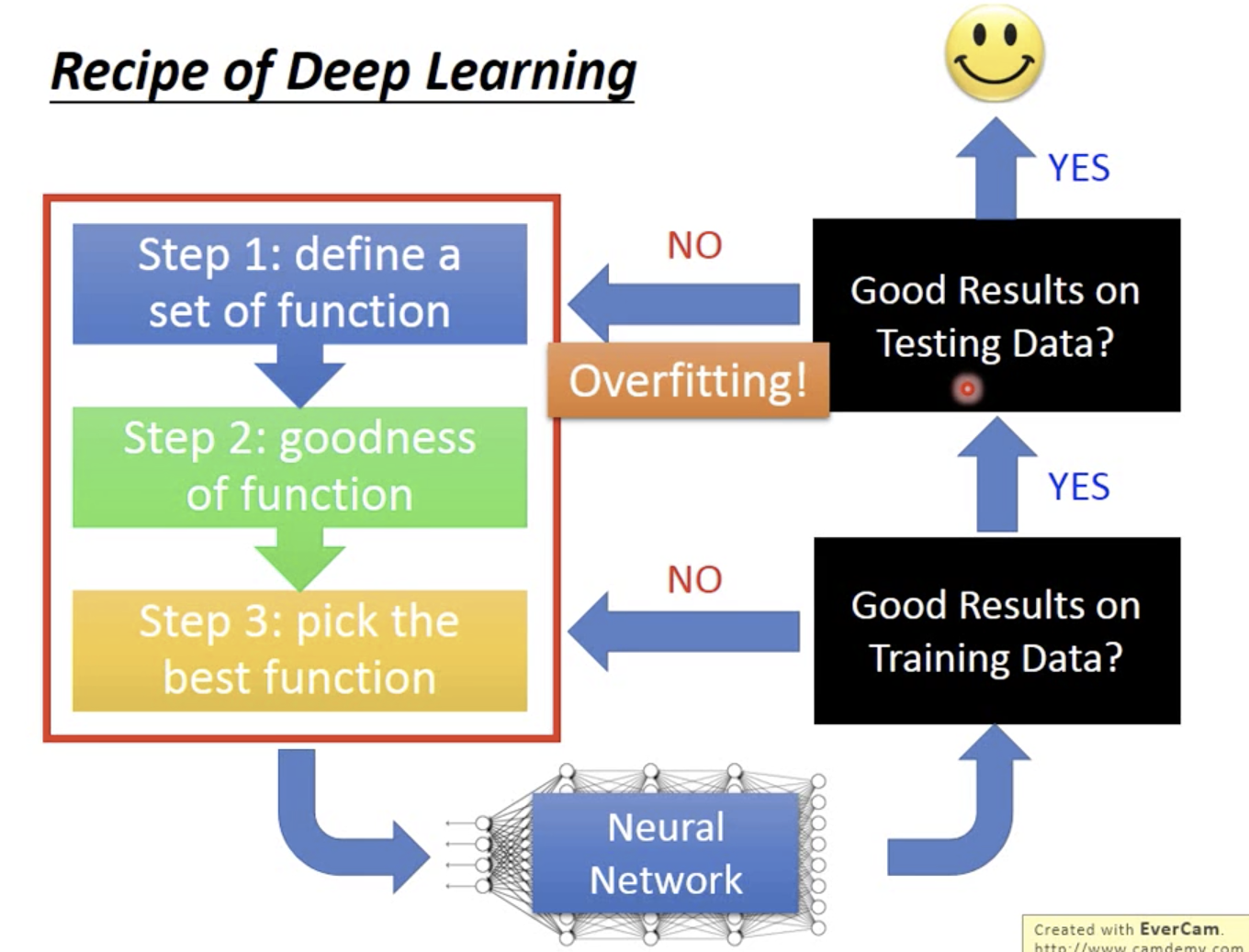
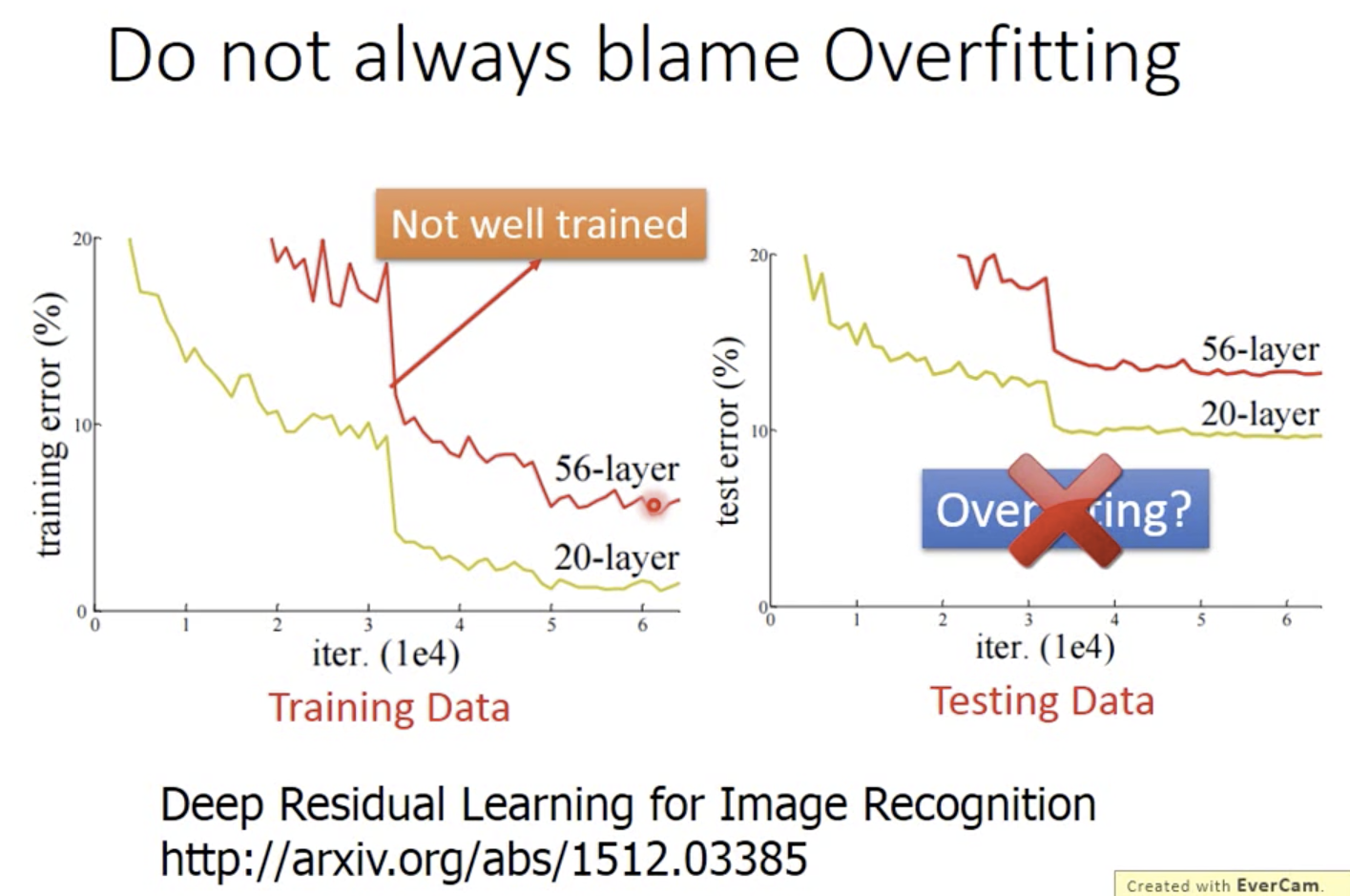
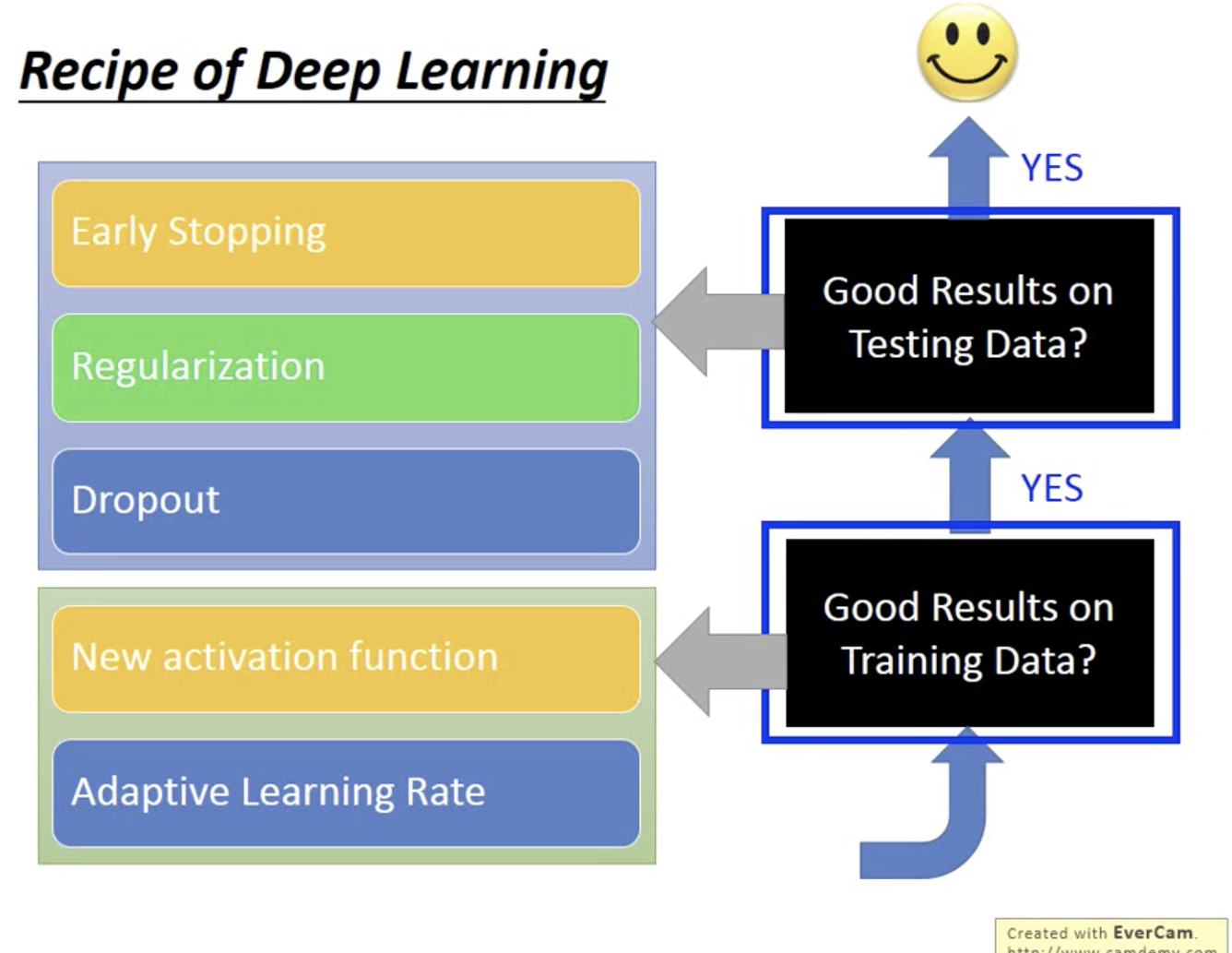
前边是如何在train data取得好结果。后边是如何在test data取得好data。
Early Stopping


L2 regularization,乘上一个小于1的数,就会导致w越来越接近0,也就是不要离0太远,但是后边还有一项保证不是所有参数都成0. 这就是weight decay。因为每次都乘系数,所以最后都比较接近0,不会有很大的值(和L1的区别)。
在实际应用中,regularization有帮助,到那时可能没有那么重要,不像SVM中那么重要,因为初始化参数一般都是从0周围开始,early stopping也可以防止离0太远。

L1 也是接近0,但是每次减去的都是固定的。所以有接近0的,也有很大的值,显得比较稀疏。

Regularization = Weight Decay

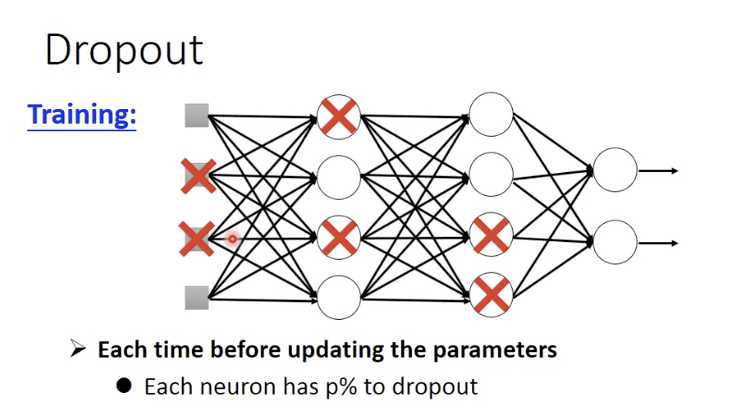
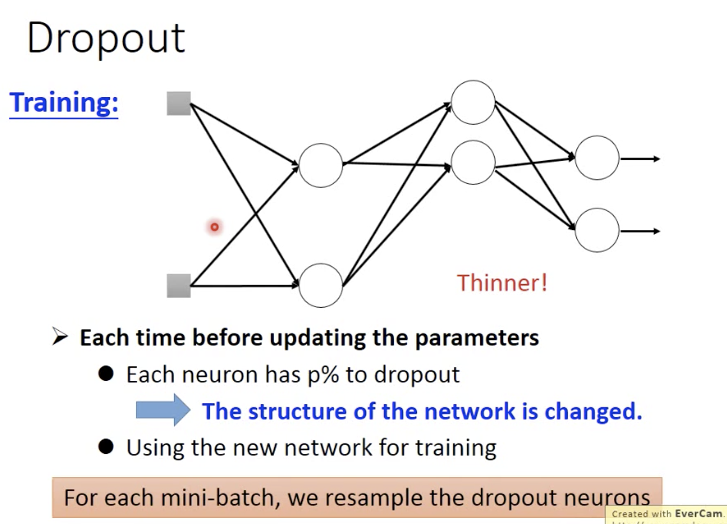
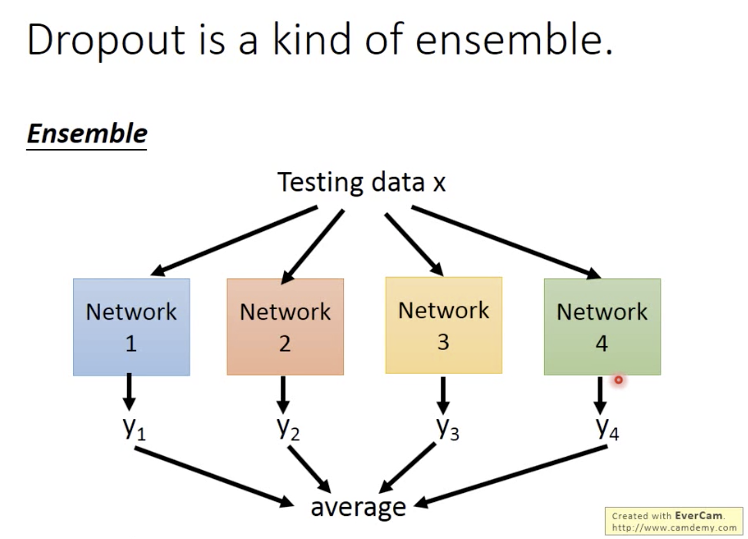
Dropout
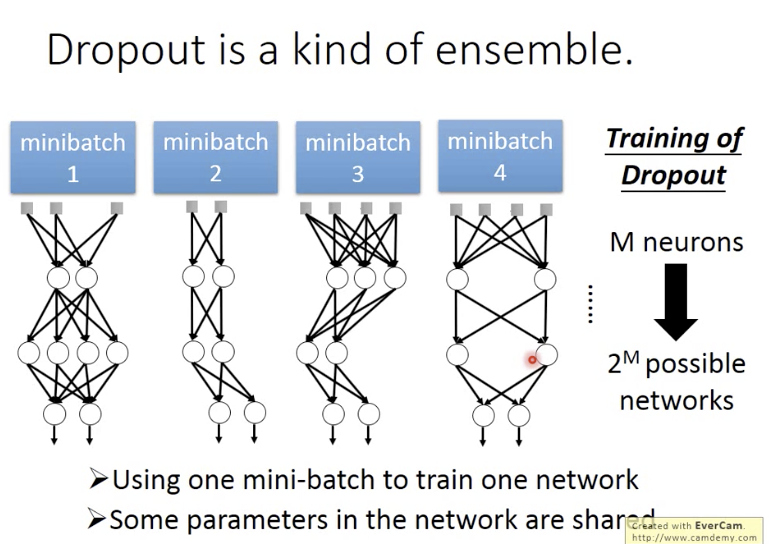
For each min-batch,we resample the dropout neurons。
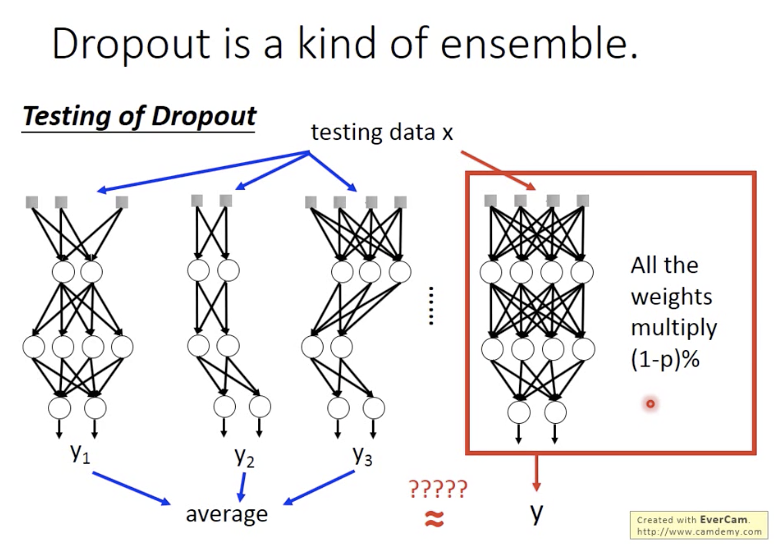
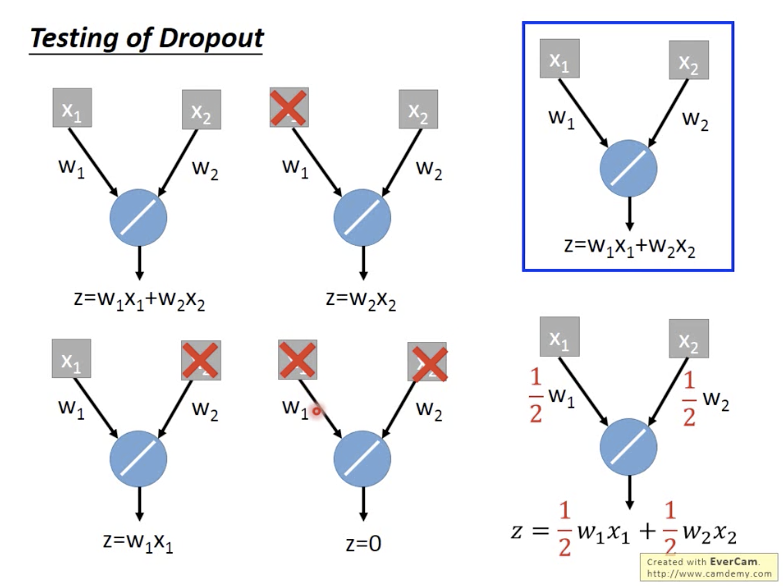
测试时候两件事,1: 不要dropout;2:乘以(1-p)即dropout_keep_prob。

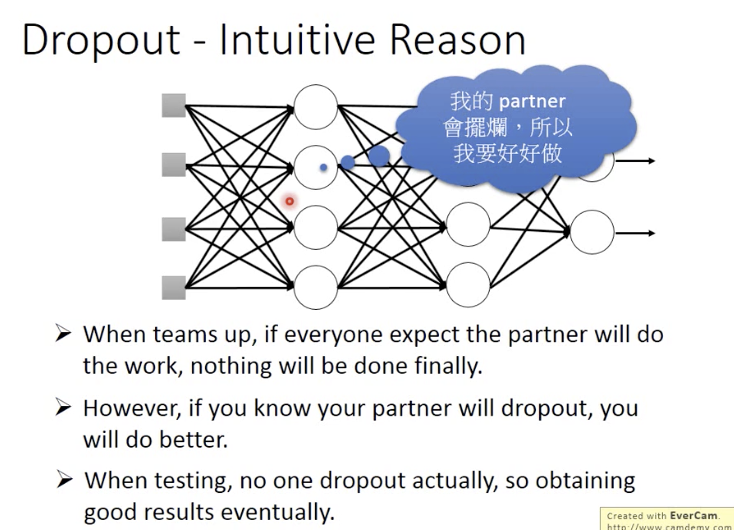


一个mini-batch训练一个网络;部分参数是共享的;

找我内推: 字节跳动各种岗位
作者:
ZH奶酪(张贺)
邮箱:
cheesezh@qq.com
出处:
http://www.cnblogs.com/CheeseZH/
*
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号