ACL2020文章,用Dice Loss处理NLP任务的数据不均衡问题,Tensorflow实现
文章链接:https://zhuanlan.zhihu.com/p/128066632 (本文大部分内容都摘抄自这篇文章,主要用作个人笔记。)
论文标题:Dice Loss for Data-imbalanced NLP Tasks
论文作者:Xiaofei Sun, Xiaoya Li, Yuxian Meng, Junjun Liang, Fei Wu, Jiwei Li
论文链接:https://arxiv.org/pdf/1911.02855.pdf
数据不均衡导致的两个问题
- 训练与测试失配。占据绝大多数的负例会支配模型的训练过程,导致模型倾向于负例,而测试时使用的F1指标需要每个类都能准确预测;
- 简单负例过多。负例占绝大多数也意味着其中包含了很多简单样本,这些简单样本对于模型学习困难样本几乎没有帮助,反而会在交叉熵的作用下推动模型遗忘对困难样本的知识。
使用交叉熵损失存在的问题
- 大量简单负例会在交叉熵的作用下推动模型忽视困难正例的学习,而序列标注任务往往使用F1衡量,从而在正例上预测欠佳直接导致了F1值偏低;
- 交叉熵“平等”地看待每一个样本,无论正负,都尽力把它们推向1(正例)或0(负例)。但实际上,对分类而言,将一个样本分类为负只需要它的概率<0.5即可,完全没有必要将它推向0;
解决方案
- 基于已有的Dice Loss,提出一个自适应损失:DSC,在训练时推动模型更加关注困难的样本,降低简单负例的学习度,从而在整体上提高基于F1值的效果。
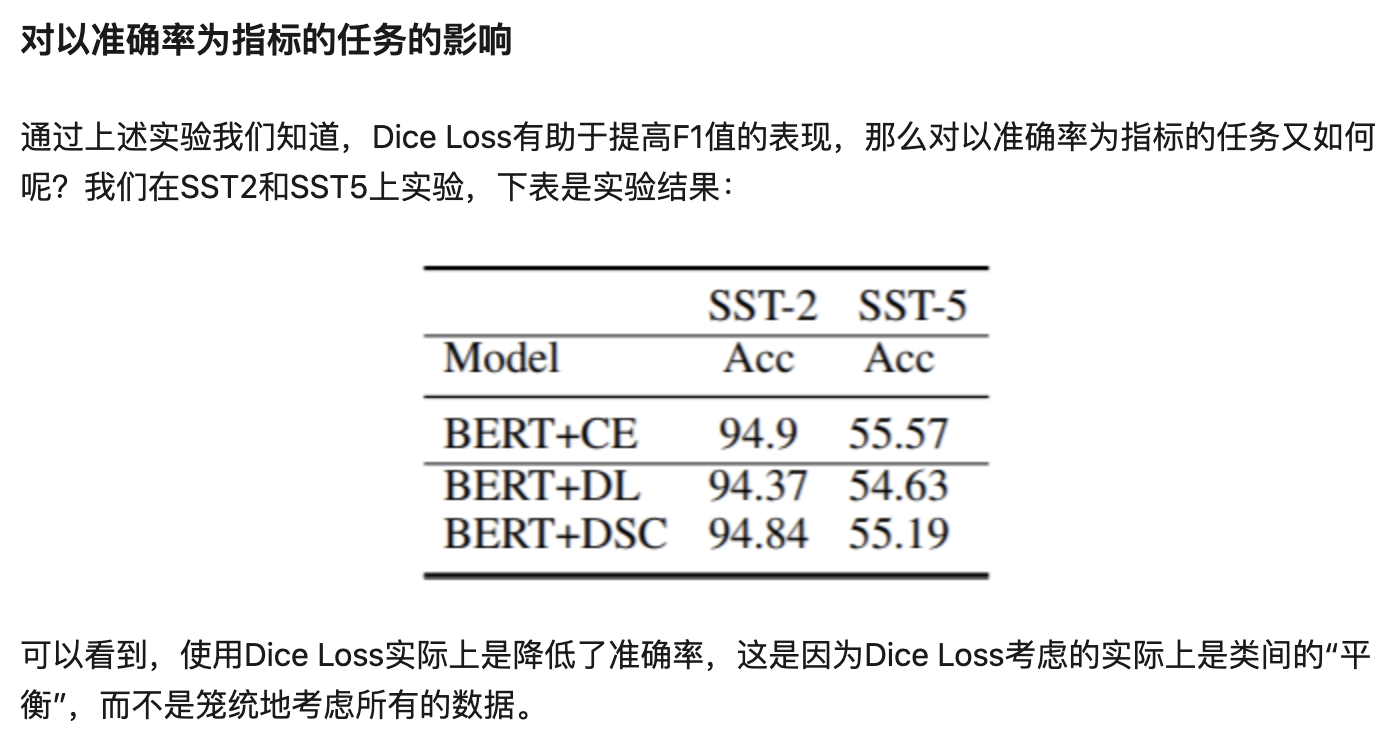
效果
- 在多个任务上实验,包括:词性标注、命名实体识别、问答和段落识别。F1值都取得了一定的提升;
传统二分类交叉熵
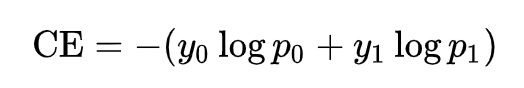
存在问题:对每个样本,CE对它们都一视同仁,不管当前样本是简单还是复杂。当简单样本有很多的时候,模型的训练就会被这些简单样本占据,使得模型难以从复杂样本中学习。
一种简单的改进方法是,降低模型在简单样本上的学习速率,从而得到下述加权交叉熵损失:
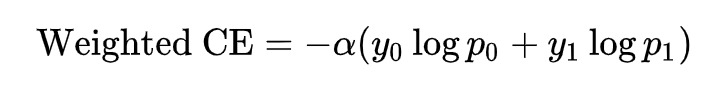
存在问题:对不同样本,我们可以设置不同的权重,从而控制模型在该样本上学习的程度。但是此时,权重的选择又变得比较困难。
DSC
- DSC是一种用于衡量两个集合之间相似度的指标:
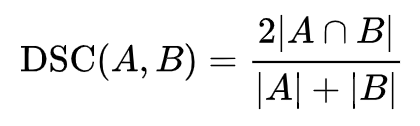
令A是所有模型预测为正的样本的集合,令B为所有实际上为正类的样本集合,那么DSC就可以重写为:
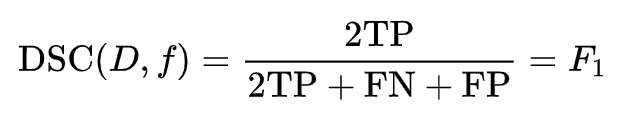
其中,TP是True Positive,FN是False Negative,FP是False Negative,D是数据集,f是一个分类模型。于是,在这个意义上,DSC是和F1等价的。推导公式如下:

然而上述表达式是离散的。为此,我们需要把上述DSC表达式转化为连续的版本,从而视为一种soft F1,对单个样本x,我们直接定义它的DSC:
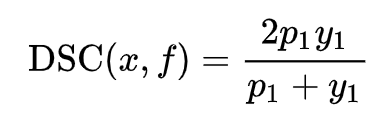
可以看到,若x是负类,那么它的DSC就为0,从而不会对训练有贡献。为了让负类也能有所贡献,我们增加一个平滑项:
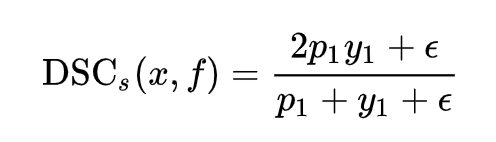
但这样一来,又需要我们根据不同的数据集手动地调整平滑项。而且,当easy-negative样本很多的时候,即便使用上述平滑项,整个模型训练过程仍然会被它们主导。基于此,我们使用一种“自调节”的DSC:
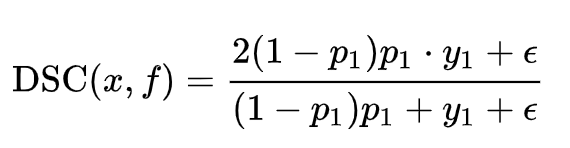

事实上,这比较类似Focal Loss (FL),即降低已分好类的样本的学习权重:
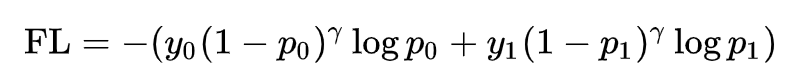
不过,FL即使能对简单样本降低学习权重,但是它本质上仍然是在鼓励简单样本趋向0或1,这就和DSC有了根本上的区别。因此,我们说DSC通过“平衡”简单样本和困难样本的学习过程,从而提高了最终的F1值(因为F1要求各类都有比较好的结果)。
Dice Loss(DL)与Tversky Loss(TL)


总结
本文使用现有的Dice Loss,并提出了一种新型的自适应损失DSC,用于各种数据分布不平衡的NLP任务中,以缓解训练时的交叉熵与测试时的F1的失配问题。实验表明,使用该损失可以显著提高标注任务、分类任务的F1值,并且也说明了F1效果的提升与数据不平衡的程度、数据量大小有密切的关系。
Tensorflow版本Dice Loss
import tensorflow as tf
tf.enable_eager_execution()
def dice_loss(n_classes, logits, label, smooth=1.e-5):
epsilon = 1.e-6
alpha = 2.0 # 这个是dice coe的系数,见下边的解释
y_true = tf.one_hot(label, n_classes)
softmax_prob = tf.nn.softmax(logits)
print("{}".format(softmax_prob.numpy()))
y_pred = tf.clip_by_value(softmax_prob, epsilon, 1. - epsilon)
y_pred_mask = tf.multiply(y_pred, y_true)
common = tf.multiply((tf.ones_like(y_true) - y_pred_mask), y_pred_mask)
nominator = tf.multiply(tf.multiply(common, y_true), alpha) + smooth
denominator = common + y_true + smooth
dice_coe = tf.divide(nominator, denominator)
return tf.reduce_mean(tf.reduce_max(1 - dice_coe, axis=-1))
n_classes = 6
logits = tf.constant([[0.1, 0.2, 0.8, 1.2, 1.24, 2.96],
[0.1, 0.2, 0.8, 1.2, 1.24, 2.96]])
for label in range(0, n_classes):
loss = dice_loss(n_classes, logits, [label, label+1])
print("{}".format(loss.numpy()))
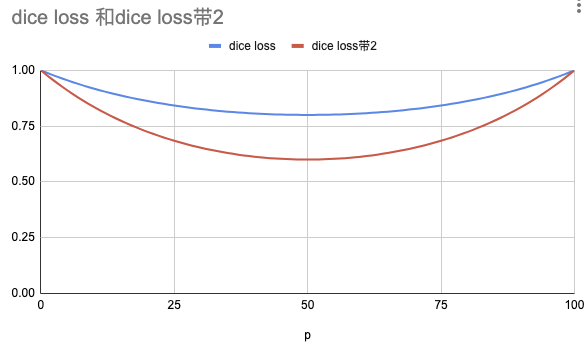
原论文中的公式11,这里有系数2(loss曲线,下凹的更厉害)
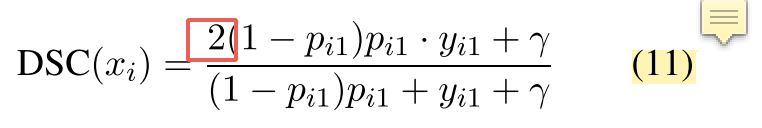
原论文中的表2,这里没有系数2(loss曲线,下凹的稍平缓)

如下图所示

找我内推: 字节跳动各种岗位
作者:
ZH奶酪(张贺)
邮箱:
cheesezh@qq.com
出处:
http://www.cnblogs.com/CheeseZH/
*
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号