图解Focal Loss以及Tensorflow实现(二分类、多分类)
论文链接:Focal loss for dense object detection
总体上讲,Focal Loss是一个缓解分类问题中类别不平衡、难易样本不均衡的损失函数。首先看一下论文中的这张图:

解释:
- 横轴是ground truth类别对应的概率(经过sigmoid/softmax处理过的logits),纵轴是对应的loss值;
- 蓝色的线(gamma=0),就是原始交叉熵损失函数,可以明显看出ground truth的概率越大,loss越小,符合常识;
- 除了蓝色的线,其他几个都是Focal Loss的线,其实原始交叉熵损失函数是Focal Loss的特殊版本(gamma=0)
- 其他几个Focal Loss线都在蓝色下边,可以看出Focal Loss的作用就是【衰减】;
- 从图中可以看出,ground truth的概率越大(即容易分类的简单样本),衰减越厉害,也就是大大降低了简单样本的loss;
- 从图中可以看出,ground truth的概率越小(即不易分类的困难样本),也是有衰减的,但是衰减的程度比较小;
下边是我自己模拟的一组数据,一组固定的logits=[0+epsilon, 0.1, 0.2, ..., 0.9, 1.0-epsilon],然后假设ground truth分别是0、1、2、...、9、10的时候,gamma=0、0.5、1、2、...、8、16对应的loss。
例如第3行第1列的2.75表示,ground truth是类别2,即对应的logits是0.2,gamma=0的时候,loss=2.75(gamma=0,就是原始的多分类交叉熵)。
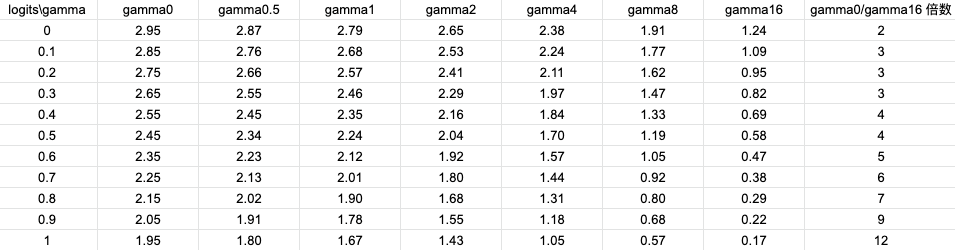
根据上表可以得到下边的图:
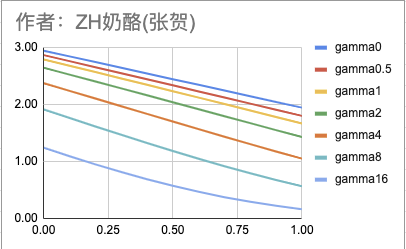
从上图可以看出,随着gamma增大,整体loss都下降了,但是logits相对越高(这个例子中最大logits=1),下降的倍数越大。从上表的最后一列也可以看出来,gamma=0和gamma=16的时候,logits=0只衰减了2倍,但是logits=1衰减了16倍。
因为论文中没有给出比较官方的focal loss实现,所以网上focal loss有很多实现版本。有以下几个判断标准:
- 当gamma为0的时候,等同于原始交叉熵损失;
- 二分类版本需要同时考虑正负样本的影响,多分类版本只需要考虑true label的影响,因为softmax的时候,已经考虑了其他labels;
- 多分类版本因为每个样本其实只需要1个值(即y_true one-hot向量中值为1的那个),所以有些实现会用tf.gather简化计算;
二分类Focal Loss
二分类交叉熵损失函数
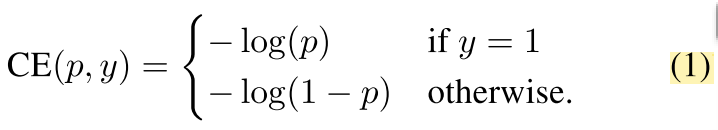
其中,y是ground truth 类别,p是模型预测样本类别为1的概率(则1-p是样本类别为0的概率)。
为了简化公式,用pt表示概率:
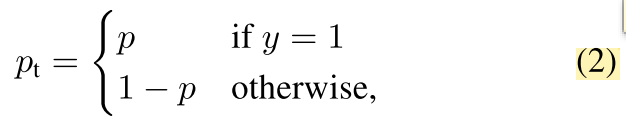
所以二分类交叉熵公式就是:
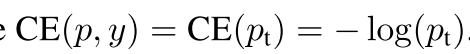
为了处理类别不均衡问题,我们可以给二分类交叉熵公式加上一个alpha参数,实际应用中,alpha通常会根据逆类别频率或者当作超参数根据交叉验证得到:
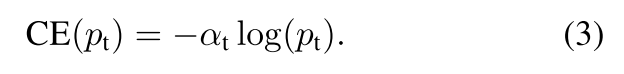
二分类Focal Loss
上边引入了alpha参数可以缓解类别不均衡问题,但是无法处理难易样本不均衡问题。为了处理难易样本不均衡的问题,可以引入一个调节因子(1-pt)gamma,例如gamma=2,则调节因子就是(1-pt)2。这个调节因子是个小于1的,所以可以起到衰减的作用,而且pt越接近1(模型置信度越高,说明样本越简单),衰减的越厉害。
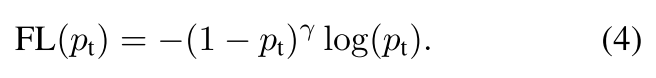
当然,我们也可以给这个损失函数再加上alpha,在原论文的实验中,这个会有一些提升。
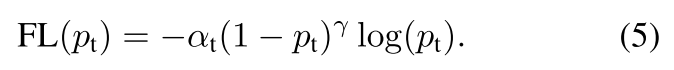
二分类Focal Loss的Tensorflow实现
需要注意的地方:
- 要知道公式中的pt是类别对应的probs,而不是logits(logits经过sigmoid/softmax变成probs);
- 很多代码中都用y_pred变量,自己要搞清楚y_pred是指logits还是probs;
- 二分类的p_t是要同时计算正/负样本的,这里和多分类有区别;
下边的代码参考了这里【p.s. 这篇文章的多分类Focal Loss可能有问题?gamma=0时不等同原始交叉熵损失。】,但是也做了些调整。
def binary_focal_loss(gamma=2, alpha=0.25):
alpha = tf.constant(alpha, dtype=tf.float32)
gamma = tf.constant(gamma, dtype=tf.float32)
def binary_focal_loss_fixed(n_classes, logits, true_label):
epsilon = 1.e-8
# 得到y_true和y_pred
y_true = tf.one_hot(true_label, n_classes)
probs = tf.nn.sigmoid(logits)
y_pred = tf.clip_by_value(probs, epsilon, 1. - epsilon)
# 得到调节因子weight和alpha
## 先得到y_true和1-y_true的概率【这里是正负样本的概率都要计算哦!】
p_t = y_true * y_pred \
+ (tf.ones_like(y_true) - y_true) * (tf.ones_like(y_true) - y_pred)
## 然后通过p_t和gamma得到weight
weight = tf.pow((tf.ones_like(y_true) - p_t), gamma)
## 再得到alpha,y_true的是alpha,那么1-y_true的是1-alpha
alpha_t = y_true * alpha + (tf.ones_like(y_true) - y_true) * (1 - alpha)
# 最后就是论文中的公式,相当于:- alpha * (1-p_t)^gamma * log(p_t)
focal_loss = - alpha_t * weight * tf.log(p_t)
return tf.reduce_mean(focal_loss)
多分类Focal Loss
多分类交叉熵损失函数
首先看一下多分类的交叉熵损失函数:
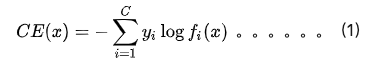
其中y_i为第i个类别对应的真实标签(一个one-hot向量,只有第i个位置为1),f_i(x)为对应的模型输出值,也就是p_t,也就是经过softmax处理过的logits。直观的解释就是:对于每个样本,从p_t数组中选择第i个数取对数,再乘-1,就是这个样本的loss了,所以y_i one-hot向量就是起一个选择的作用,为1,即选择,为0,即不选。
多分类Focal Loss
从公式上看,多分类Focal Loss和二分类Focal Loss没啥区别,也是加上一个调节因子weight=(1-pt)^gamma和alpha。
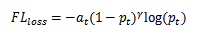
多分类Focal Loss的Tensorflow实现
首先看一下多分类交叉熵损失函数的实现
def test_softmax_cross_entropy_with_logits(n_classes, logits, true_label):
epsilon = 1.e-8
# 得到y_true和y_pred
y_true = tf.one_hot(true_label, n_classes)
softmax_prob = tf.nn.softmax(logits)
y_pred = tf.clip_by_value(softmax_prob, epsilon, 1. - epsilon)
# 得到交叉熵,其中的“-”符号可以放在好几个地方,都是等效的,最后取mean是为了兼容batch训练的情况。
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_true*tf.log(y_pred)))
return cross_entropy
所以需要做的就是往上边这段代码中加入gamma和alpha参数:
def test_softmax_focal_ce_3(n_classes, gamma, alpha, logits, label):
epsilon = 1.e-8
# y_true and y_pred
y_true = tf.one_hot(label, n_classes)
probs = tf.nn.softmax(logits)
y_pred = tf.clip_by_value(probs, epsilon, 1. - epsilon)
# weight term and alpha term【因为y_true是只有1个元素为1其他元素为0的one-hot向量,所以对于每个样本,只有y_true位置为1的对应类别才有weight,其他都是0】这也是为什么网上有的版本会用到tf.gather函数,这个函数的作用就是只把有用的这个数取出来,可以省略一些0相关的运算。
weight = tf.multiply(y_true, tf.pow(tf.subtract(1., y_pred), gamma))
if alpha != 0.0: # 我这实现中的alpha只是起到了调节loss倍数的作用(调节倍数对训练没影响,因为loss的梯度才是影响训练的关键),要想起到调节类别不均衡的作用,要替换成数组,数组长度和类别总数相同,每个元素表示对应类别的权重。另外[这篇](https://blog.csdn.net/Umi_you/article/details/80982190)博客也提到了,alpha在多分类Focal loss中没作用,也就是只能调节整体loss倍数,不过如果换成数组形式的话,其实是可以达到缓解类别不均衡问题的目的。
alpha_t = y_true * alpha + (tf.ones_like(y_true) - y_true) * (1 - alpha)
else:
alpha_t = tf.ones_like(y_true)
# origin x ent,这里计算原始的交叉熵损失
xent = tf.multiply(y_true, -tf.log(y_pred))
# focal x ent,对交叉熵损失进行调节,“-”号放在上一行代码了,所以这里不需要再写“-”了。
focal_xent = tf.multiply(alpha_t, tf.multiply(weight, xent))
# in this situation, reduce_max is equal to reduce_sum,因为经过y_true选择后,每个样本只保留了true label对应的交叉熵损失,所以使用max和使用sum是同等作用的。
reduced_fl = tf.reduce_max(focal_xent, axis=1)
return tf.reduce_mean(reduced_fl)
参考:
- Pytorch中的Focal Loss实现
- Pytorch官方实现的softmax_focal_loss
- Pytorch官方实现的sigmoid_focal_loss
- 何恺明大神的「Focal Loss」,如何更好地理解?,苏剑林,2017-12
- https://github.com/artemmavrin/focal-loss/blob/master/src/focal_loss/_binary_focal_loss.py
- https://github.com/artemmavrin/focal-loss/blob/master/src/focal_loss/_categorical_focal_loss.py
- https://github.com/zhezh/focalloss/blob/master/focalloss.py
- focal loss的tensorflow实现,chris_xy,2019-03
- Multi-class classification with focal loss for imbalanced datasets,Chengwei Zhang,2018-12
- focal loss的几种实现版本(Keras/Tensorflow),随煜而安,2019-05【这篇文章的多分类Focal Loss有问题,gamma=0时不等同原始交叉熵损失。】
- keras中两种交叉熵损失函数的探讨,TAURUS,2019-08
- focal loss for multi-class classification,yehaihai,2018-07【这篇文章说alpha对于多分类Focal Loss不起作用,其实取决于alpha的含义,如果只是1个标量,的确无法起到缓解类别不均衡问题的作用,但如果alpah是一个数组(每个元素表示类别的权重),其实是alpha是可以在多分类Focal Loss中起到缓解类别不均衡作用的。】

找我内推: 字节跳动各种岗位
作者:
ZH奶酪(张贺)
邮箱:
cheesezh@qq.com
出处:
http://www.cnblogs.com/CheeseZH/
*
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号