《阿里小蜜这一年,经历了哪些技术变迁?》(2018-02-05)阅读笔记
原文链接:https://yq.aliyun.com/articles/431857
作者:海青
发布时间:2018-02-05 15:14:04
生态领域的思考
随着人工智能在全球领域的持续高涨,chatbot人机交互作为其中一个分支在智能助理、智能服务、IOT等领域进了白热化竞争态势,从全球大公司到创业公司纷纷加入战场并在一些独特的垂直领域开始精耕细作。在近两年的人机交互领域的发展中,一方面在To C端面向各个入口领域的竞争更加激烈(例如:在IOT领域的智能音箱)、垂直领域场景更加细分与丰富。另外一方面由To C市场的竞争开始转向To B市场的竞争,Google、Microsoft、Facebook、Amazon、百度、网易以及众多startups纷纷在To B领域通过IaaS、PaaS或者SaaS能力开始布局,并且基本围绕着如下两个体系进行输出:
- 围绕着IM生态体系的绑定输出。例如:Facebook在Messager平台上的wit.ai机器人平台输出、腾讯在微信体端也在逐步开发自己的机器人平台等
- 面向企业或者开发者领域的独立三方平台输出。例如:Amazon的Lex平台、微软的AI Solution、Google的AI SDK与Api.ai、网易七鱼等等
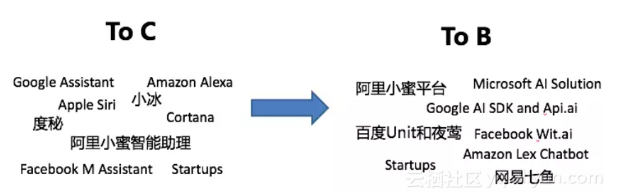
面向生态的阿里小蜜平台
在人机交互行业生态领域发展的大背景下,面向智能服务领域,阿里小蜜在这两年时间同样在不断的升级与变迁:
在To C端,持续在智能+人的混合模式上逐步升级,并且把传统的服务往更大的泛服务领域扩展,除了传统服务的智能化、还拓展了智能导购服务、智能助理服务,闲聊服务等,以服务为基础向平台与多领域升级
在To B端,阿里小蜜从淘宝到阿里行业生态、二环商家生态,以及三环企业平台逐步拓展。
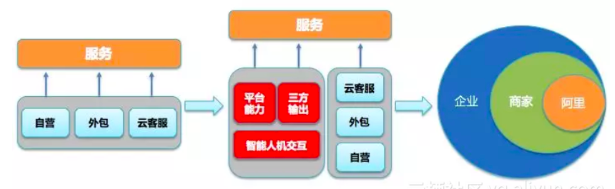
最终形成了整个阿里小蜜平台面向阿里生态圈、商家生态圈、企业生态圈的整个体系大图:
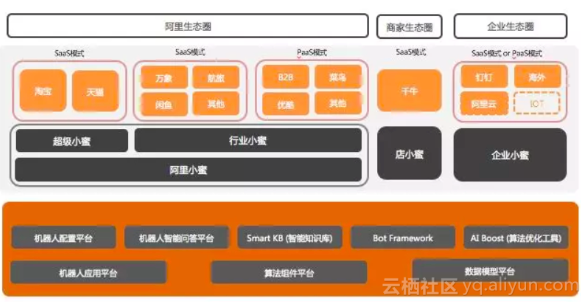
- 面对消费者:超级小蜜在淘宝生态体系面向服务、导购、助理以及闲聊4个领域逐步进行深入的探索
- 面对阿里行业生态圈:通过平台化能力赋能阿里集团生态超过30个BU,包含AE、ICBU、1688、菜鸟、飞猪、闲鱼、淘票票、阿里内外等
- 面对商家生态圈:与千牛平台团队协同,基于IM消息体系,构建店小蜜体系,提供给商家全自动+半自动人工辅助智能对话能力
- 面对企业生态圈:依托于钉钉企业沟通生态圈的IM消息体系以及阿里云上的整个企业开放生态,企业小蜜和云小蜜也踏上了企业赋能之路
在过去的2017年阿里小蜜从阿里走向行业,逐步赋能商家和企业;从中国开始走向世界,覆盖英语、葡语、西班牙、印尼语、泰语,赋能AE及Lazada海外业务;从PC、无线走向了PC、无线和热线,在多端进行赋能;阿里小蜜全面从智能人机交互走向智能人机协同。
- 在过去的2017年阿里小蜜全年服务3.4亿名淘宝消费者,其中双11当天接待人次904万,智能服务占比达到95%,智能服务解决率达到93.1%
- 在过去的2017年赋能商家的店小蜜授权开启商家数达到30w,其中双11当天机器人对话量超过1亿
- 在过去的2017钉钉端赋能企业数超过1万家;2017年10月云栖大会正式开放云小蜜,截止到目前赋能Lazada东南亚服务业务,并逐步在多个行业领域与多家大中型企业推进云化服务体系
小蜜技术这一年
围绕着平台化和领域化不断完善和增强整个阿里小蜜平台
架构体系端:围绕着SaaS和PaaS体系,逐步将前端和后端体系进行模块化处理,逐步完善和构建整个平台体系
算法端:逐步在单个领域结合实际业务场景进行纵深探索,并且不断进行创新
前端架构体系
为了快速响应业务以及快速接入其他业务场景,阿里小蜜平台在前端架构上使用的是 WebApp 的技术选型。虽然WebApp在体验和功能上略逊于 Native App,但在快速响应业务需求和快速接入其他 APP 两方面相对Native优势明显。在经过3个大版本的不断升级与改造后,形成了按照模块划分的7层前端架构体系,如下图:
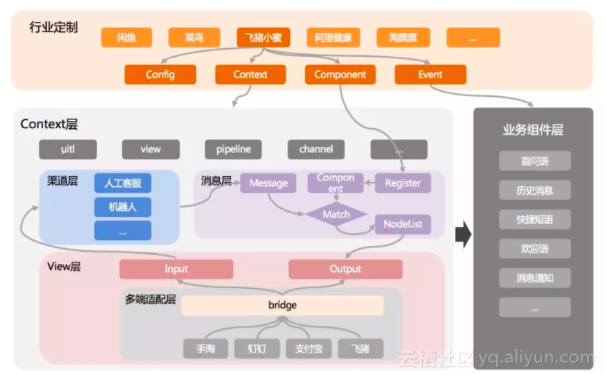
行业定制层:不同行业接入阿里小蜜平台,在既定的开放规范下对UI、业务、插件进行定制的模块
context层:类似 koa.js/express.js 的设计,将 view/util/request/pipeline/channel 等核心模块挂载 到 this 对象上,消息组件、业务模块等都执行在 this这个 context 中。我们可以轻松对 this 进行扩展,以满足不同业务对于小蜜平台的特殊定制需求
渠道层:用户的输入在不同场景会发送给不同的处理对象,我们把处理对象称之为”渠道“,虽然目前的渠道只有机器人和人工客服,我们在架构上支持任意多个渠道,并且可以轻松切换对话渠道
消息层:将“对话”过程中的特定功能都抽象为具有特定消息类型的组件,这些组件在不同的渠道中都可以复用,阿里小蜜平台90%的功能扩展都可以通过消息层轻松实现
业务组件层:将”非对话层“的业务都抽象到这层中,提供串行加载、扩展等功能
View层:具有典型 WebIM 功能,提供 Input、output、addPlugin等API
客户端定制层:适配不同行业业务在不同的APP端的定制层
后端架构体系
面向整个阿里小蜜平台平台化,面向阿里生态圈、商家生态圈和企业生态圈支持以PaaS和SaaS输出
模块化整个对话管理和流程模块化,构建算法和业务模块可插拔的并行架构体系

算法体系
在算法体系持续按照面向不同的场景优化和升级整个算法体系模型,在2017年阿里小蜜平台的算法体系同样也按照领域化和平台化体系持续升级发展,整个人机交互架构如下:
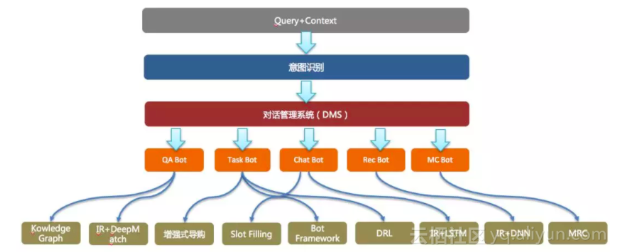
意图识别:识别语言的真实意图,将意图进行分类并进行意图属性抽取。意图决定了后续的领域识别流程,因此意图层是一个结合上下文数据模型与领域数据模型不断对意图进行明确和推理的过程,完成意图的补全、意图分类和意图转移工作。整个意图识别按照模型可组合以及进行单独的算法选型。

通过对话管理系统的控制,面向不同的领域场景采用不同的领域技术:
- QA Bot:通过知识图谱、传统IR以及DeepMatch的方法完成知识问答的匹配
- Task Bot:面向多领域技术完成任务型对话构建与问答
- Chat Bot:完成闲聊机器人的问答
- Rec Bot:完成推荐机器人的问答体系构建
- MC Bot:在文档无法结构化的场景下(例如淘宝或者商家的活动场景),通过Machine Reading的方法来完成问答
迁移学习下的DeepQA探索
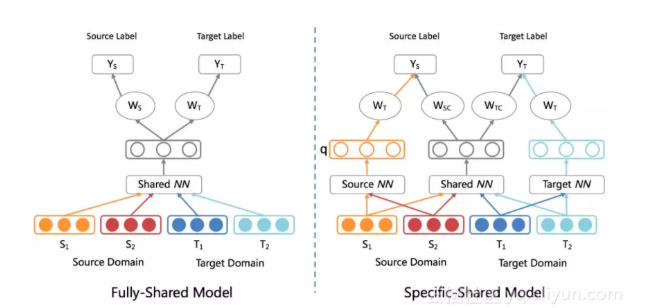
随着阿里小蜜平台不断的扩展,不仅需要在面向C端的手淘上帮助用户解决服务咨询类问题,而且也需要在新领域和国际化中承担起任务,而这些领域中存在标注数据量不足或者难以获得的问题(例如在AliExpress中的西班牙语场景)。基于此,我们希望利用已有的标注数据来优化小数据领域的QA匹配效果,而迁移学习在这方面就能发挥重要的作用。它最核心的思想就是将从一个环境中学到的知识用来帮助新环境中的学习任务。因此,在该场景下我们提出DRSS-Adv的迁移学习模型,用来建模QA匹配问题。
通常来说,TL的模型有两类,一种是unsupervised,另外一种是supervised。前者假设完全没有目标领域的标注数据,后者假设仅有少部分目标领域的标注数据。具体大家可以看下文献[2]的综述。在我们的业务中主要关注supervised的迁移学习技术,同时结合深度神经网络(DNN)。在这个设定下主要有两种框架,一个是Fully-shared(FS),另外一个是Specific-shared(SS),框架图如下:
基于增强学习的智能导购
智能导购主要通过支持和用户的多轮交互,不断的理解和明确用户的意图。并在此基础上利用深度强化学习不断的优化导购的交互过程。下图展示了智能导购的技术架构图:
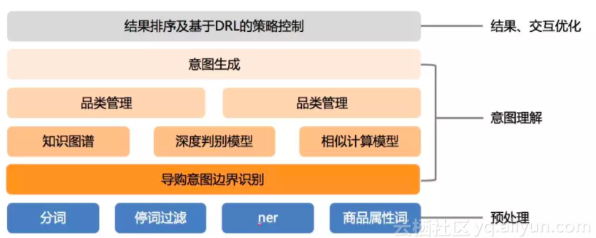
这里两个核心的问题:
a:在多轮交互中理解用户的意图。
b:根据用户的意图结果,优化排序的结果和交互的过程。 下面主要介绍 导购意图理解、以及深度增强学习的交互策略优化。
智能导购的意图理解和意图管理
智能导购的意图理解和意图管理
智能导购下的意图理解主要是识别用户想要购买的商品以及商品对应的属性,相对于传统的意图理解,也带来了几个新的挑战:
1.用户偏向于短句的表达。因此,识别用户的意图,要结合用户的多轮会话和意图的边界。
2.在多轮交互中用户会不断的添加或修改意图的子意图,需要维护一份当前识别的意图集合。
3商品意图之间存在着互斥,相似,上下位等关系。不同的关系对应的意图管理也不同。
4.属性意图存在着归类和互斥的问题。
针对短语表达,我们通过品类管理和属性管理维护了一个意图堆,从而较好的解决了短语表示,意图边界和具体的意图切换和修改逻辑。同时,针对较大的商品库问题,我们采用知识图谱结合语义索引的方式,使得商品的识别变得非常高效。下面我们分别介绍下品类管理和属性管理。
基于知识图谱和语义索引的品类管理
智能导购场景下的品类管理分为品类识别,以及品类的关系计算。下图是品类关系的架构图:
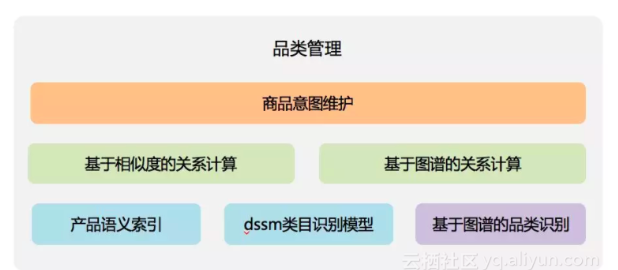
品类识别
采用了基于知识图谱的识别方案和基于语义索引及dssm的判别模型。
a:基于商品知识图谱的识别方案: 基于知识图谱复杂的结构化能力,做商品的类目识别。是我们商品识别的基础。
b:基于语义索引及dssm商品识别模型的方案: 知识图谱的识别方案的优势是在于准确率高,但是不能覆盖所有的case。因此,我们提出了一种基于语义索引和dssm结合的商品识别方案兜底。
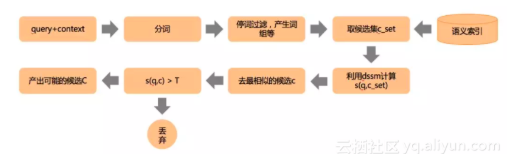
语义索引的构造
通常语义索引的构造有基于本体的方式,基于LSI的方式。我们用了一种结合搜索点击数据和词向量的方式构造的语义索引。主要包括下面几步:
1.利用搜索点击行为,提取分词到类目的候选。
2.基于词向量,计算分词和候选类目的相似性,对索引重排序。
基于dssm的商品识别
dssm是微软提出的一种用于query和doc匹配的有监督的深度语义匹配网络,能够较好的解决词汇鸿沟的问题,捕捉句子的内在语义。本文以dssm作为基础,构建了query和候选的类目的相似度计算模型。取得了较好的效果,模型的acc在测试集上有92%左右。

样本的构造:训练的正样本是通过搜索日志中的搜索query和点击类目构造的。负样本则是通过利用query和点击的类目作为种子,检索出来一些相似的类目,将不在正样本中的类目作为负样本。正负样本的比例1:1。
品类关系计算
品类关系的计算主要用于智能导购的意图管理中,这里主要考虑的几种关系是:上下位关系和相似关系。举个例子,用户的第一个意图是要买衣服,当后面的意图说要买水杯的时候,之前衣服所带有的属性就不应该被继承给水杯。相反,如果这个时候用户说的是要裤子,由于裤子是衣服的下位词,则之前在衣服上的属性就应该被继承下来。
上下位关系的计算2种方案:
1.采用基于知识图谱的关系运算。
2.通过用户的搜索query的提取。
相似性计算的两种方案:
1.基于相同的上位词。比方说小米,华为的上位词都是手机,则他们相似。
2.基于fast-text的品类词的embedding的语义相似度。
基于知识图谱和相似度计算的属性管理
下图是属性管理的架构图:
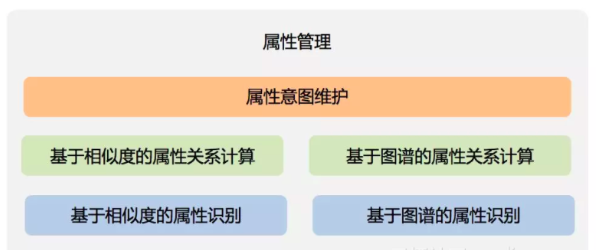
整体上属性管理包括属性识别和属性关系计算两个核心模块,思路和品类管理较为相似。这里就不在详细介绍了。
深度强化学习的探索及尝试
强化学习是agent从环境到行为的映射学习,目标是奖励信号(强化信号)函数值最大,由环境提供强化信号评价产生动作的好坏。agent通过不断的探索外部的环境,来得到一个最优的决策策略,适合于序列决策问题。下图是一个强化学习的model和环境交互的展示:

深度强化学习是结合了深度学习的强化学习,主要利用深度学习强大的非线性表达能力,来表示agent面对的state和state上决策逻辑。目前我们用DRL主要来优化我们的交互策略。因此,我们的设定是,用户是强化学习中的env,而机器是model。action是本轮是否出主动反问的交互,还是直接出搜索结果。 状态(state)的设计: 这里状态的设计主要考虑,用户的多轮意图、用户的人群划分、以及每一轮交互的产品的信息作为当前的机器感知到的状态。 state = ( intent1, query1, price1, isclick, queryitemsim, …, power, userinter, age) 其中intent1表明的是用户当前的意图,query1表示的用户的原始query。price1表示当前展现给用户的商品的均价,isclick表示本轮交互是否发生点击,queryitemsim表示query和item的相似度。power表示是用户的购买力,userinter表示用户的兴趣, age 表示用户的年龄。
reward的设计: 由于最终衡量的是用户的成交和点击率和对话的轮数。因此reward的设计主要包括下面3个方面:
a:用户的点击的reward设置成1
b:成交设置成[ 1 + math.log(price + 1.0) ]
c:其余的设置成0.1 DRL的方案的选型:这里具体的方案,主要采用了 DQN, policy-gradient 和 A3C的三种方案。
基于可配置Bot Framework体系构建
在阿里小蜜平台中还存在一种需要动态获取系统数据并且整个流程相对较为个性化的场景,这种场景的体系数据偏少甚至没有并且需要跟对应的ERP等系统打通,因此我们就构建以一套Bot Framework系统,来满足对应企业的运营或者开发同学完成个性化任务体系的定制。
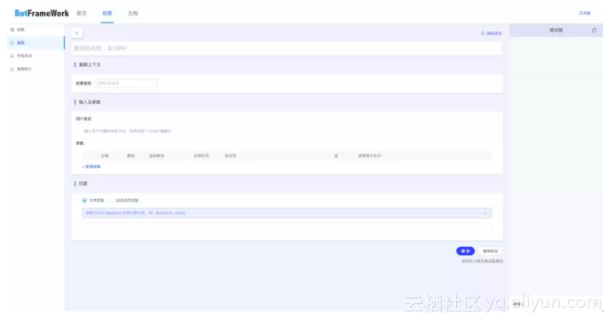
整个BFW1.0的体系支持:
1.自定义多轮对话流程
2.自定义意图、实体以及实体值
3.支持第三方接口在多轮交互平台的接入
尽管如此,整个BFW1.0面向复杂业务以及面向开发者的灵活度不足,因此在2018年,我们将BFW1.0按照chatflow的体系思路进行升级成为BFW2.0。
基于检索模型和深度学习模型相结合的聊天应用
智能聊天的特点:非面向目标,语义意图不明确,通常期待的是语义相关性和渐进性,对准确率要求相对较低。面向open domain的聊天机器人目前无论在学术界还是在工业界都是一大难题,通常在目前这个阶段我们有两种方式来做对话设计: 一种是学术界非常火爆的Deep Learning生成模型方式,通过Encoder-Decoder模型通过LSTM的方式进行Sequence to Sequence生成,如下图:
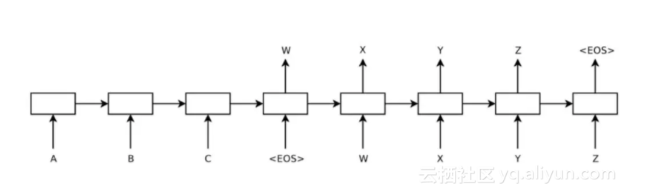
Generation Model(生成模型): 优点:通过深层语义方式进行答案生成,答案不受语料库规模限制 缺点:模型的可解释性不强,且难以保证一致性和合理性回答
另外一种方式就是通过传统的检索模型的方式来构建语聊的问答匹配。 Retrieval Model(检索模型): 优点:答案在预设的语料库中,可控,匹配模型相对简单,可解释性强 缺点:在一定程度上缺乏一些语义性,且有固定语料库的局限性
因此在阿里小蜜的聊天引擎中,我们结合了两者各自的优势,将两个模型进行了融合形成了阿里小蜜聊天引擎的核心。先通过传统的检索模型检索出候选集数据,然后通过Seq2Seq Model对候选集进行Rerank,重排序后超过制定的阈值就进行输出,不到阈值就通过Seq2Seq Model进行答案生成,整体流程图如下:
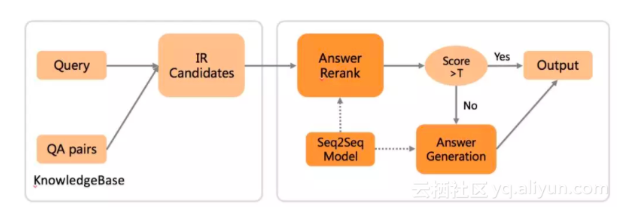
机器阅读理解技术探索与实践
在阿里小蜜平台的业务体系中,存在大量知识数据是无法通过先验知识结构化或者结构化效率极低的场景,例如淘宝双十一大促的活动、税务法律等等。因此我们通过机器阅读理解的运用,可以减少人工知识点拆解工作,让机器直接对规则进行阅读,为用户提供规则解读服务,是最自然的交互方式。因此在2017年阿里巴巴iDST团队与我们阿里小蜜团队合作共同在机器阅读领域进行了深入的探索和应用。
例如,如下图是2017年淘宝双十一“群战队”一个活动的规则:
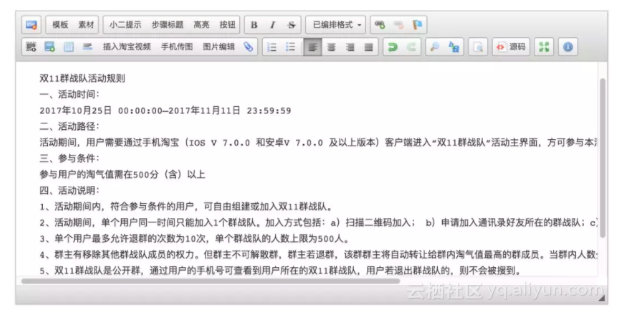
运营同学在知识库中录入群战队的活动规则文本,阿里小蜜即可直接基于文本内容的阅读来提供问答服务
机器阅读理解技术机器阅读理解模型已经在学术界取得了相当大的突破,但由于学术界和工业界具体场景的巨大差异,要将机器阅读理解技术运用到实际业务场景中,还存在相当大到挑战。
设计具有针对性的业务模型
- 从上面的例子可以看到,业务场景中的活动规则、法规文档具有一定的独特性,往往包含大量文档结构,如大小标题和文档的层级结构等。此外,不仅文章普遍比较长,答案也较长,往往跨多个句子。这与一些公开模型所阅读的wiki百科类数据特点有巨大的差异。需要针对场景的特点来设计模型结构。
模型的性能考虑
- 学术成果中的模型一般都较为复杂,而工业界场景中由于对性能的要求,无法将这些模型直接在线上使用,需要做一些针对性的简化,使得模型效果下降可控的情况下,尽可能提升线上预测性能。
模型领域的迁移
- 目前的机器阅读模型是领域相关的,这使得领域的快速拓展成为一大挑战,阿里小蜜的活动规则解读是我们支持的第一个场景,目前我们已经拓展了税务法规解读场景,未来还会在金融、电信等领域进行开拓,因此在新领域拓展时,需要利用到过去学习过的知识。
基于机器阅读理解模型的在线问答流程如下图所示,在解析用户问题到输出答案的过程中,共有4个模块参与处理:
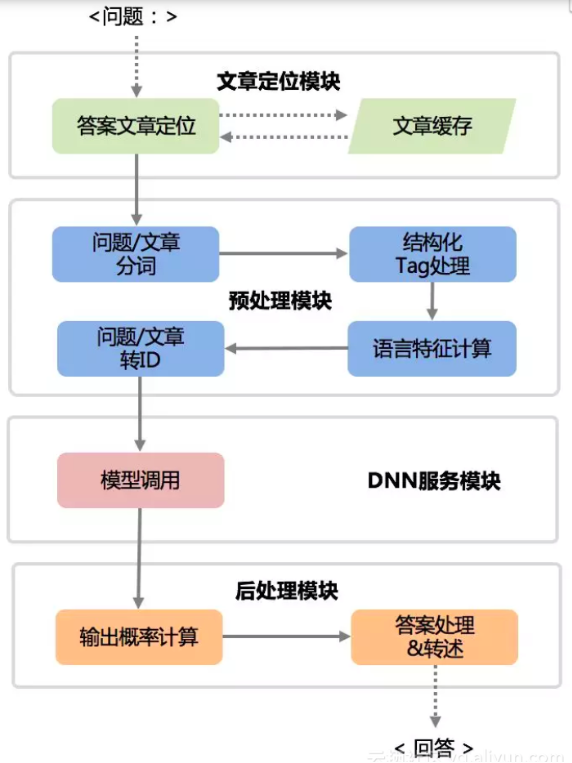
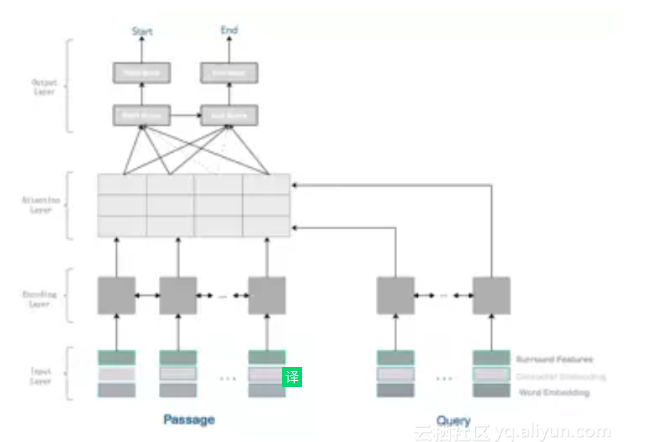
1.文章片段定位模块 文章片段定位模块针对用户问题,召回候选的文档段落集合供机器阅读产生答案。借助该模块,可帮助缩减机器阅读理解模型的计算量,同时在一定程度上提升准确率。例如用户提问「天猫造物节的活动什么时候开始?」,该模块需要返回所有与「天猫造物节」有关的文档段落。定位的方式可以通过文本分类、文本检索或者问题模板拦截来完成,文本分类需要提前标注数据训练模型,目前我们的流程中主要以无监督的文本检索或者人工维护的问题模板定位为主。
2.预处理模块 预处理模块包含4个步骤,首先需要对用户问题和待阅读文章做文本分词,由于带阅读文章常常伴有多级段落、特殊标签等结构信息,需要做格式化处理。
3.在线服务模块 DNN在线服务模块部署了本文前半部分描述的深度机器阅读理解模型,在接受第2步处理好的<question, doc>向量后,计算输出文章中的词语或者句子作为答案的概率。
4.后处理模块 后处理模块负责具体答案的构建,根据在线服务模块输出的答案概率,其按照特定策略计算出最可能的答案
就在最近我们机器阅读模型已排到SQuAD榜的top1,且ExactMatch指标首次超越了人类表现。
未来的展望与挑战
交互式智能的也逐渐成为了新的领域入口,在未来需要基于场景数据的基础上,需要持续结合技术、产品进行面领域性场景性探索与积累;
需要持续在领域数据和知识体系的持续积累;
在技术领域,我们将持续在生成模型、增强学习、迁移学习、机器阅读、情感化等持续深入。
在未来阿里小蜜平台会持续在平台化和垂直领域方向持续深入下去,围绕着行业、商家、企业以及整个chatbot生态构建智能服务的阿里小蜜智能服务平台。
References
- [1] Feng-Lin Li, Minghui Qiu, Haiqing Chen, Xiongwei Wang, Xing Gao, Jun Huang, Juwei Ren, Zhongzhou Zhao, Weipeng Zhao, Lei Wang, Guwei Jin, Wei Chu: AliMe Assist : An Intelligent Assistant for Creating an Innovative E-commerce Experience. CIKM 2017: 2495-2498
- [2] Jianfei Yu, Minghui Qiu, Jing Jiang, Shuangyong Song, Jun Huang, Wei Chu and Haiqing Chen, et al. Modelling Domain Relationships for Transfer Learning on Retrieval-based Question Answering Systems in E-commerce[C]// WSDM 2018.
- [3] Yin W, Schütze H, Xiang B, et al. ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs[J]. Computer Science, 2015.
- [4] Hu B, Lu Z, Li H, et al. Convolutional neural network architectures for matching natural language sentences[J]. 2015, 3:2042-2050.
- [5] Pang L, Lan Y, Guo J, et al. Text Matching as Image Recognition[J]. 2016.
- [6] Sukhbaatar S, Szlam A, Weston J, et al. End-To-End Memory Networks[J]. Computer Science, 2015.
- [7] Wu Y, Wu W, Xing C, et al. Sequential Matching Network: A New Architecture for Multi-turn Response Selection in Retrieval-Based Chatbots[C]// Meeting of the Association for Computational Linguistics. 2017:496-505.
- [8] Huang P S, He X, Gao J, et al. Learning deep structured semantic models for web search using clickthrough data[C]// ACM International Conference on Conference on Information & Knowledge Management. ACM, 2013:2333-2338.
- [9] Pengfei Liu, Xipeng Qiu, and Xuanjing Huang. 2017. Adversarial Multi-task Learning for Text Classification. In ACL.

找我内推: 字节跳动各种岗位
作者:
ZH奶酪(张贺)
邮箱:
cheesezh@qq.com
出处:
http://www.cnblogs.com/CheeseZH/
*
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号