《从“连接”到“交互”—阿里巴巴智能对话交互实践及思考》(2017-07-26)阅读笔记
原文链接:https://yq.aliyun.com/articles/144035
作者:孙健/千诀
发布时间:2017-07-26 11:11:15
传统互联网最典型的特征就是连接。
智能设备的快速发展正在改变着人和设备之间的交互方式。
无论是用户的接受度,还是智能设备的快速发展和普及,都在促使人和设备之间交互方式的巨大改变,我称之为交互的时代。
对话交互的特点,我认为主要有以下四点:
第一,人和智能设备和机器对话的交互一定是自然语言,因为对于人来说,自然语言是最自然的方式,也是门槛最低的方式。
第二,人和设备的对话交互应该是双向的。即不仅是人和设备说话,而且设备也可以和人对话,甚至在某些特定条件下机器人可以主动发起对话。
第三,人和设备的对话交互是多轮的,为了完成一个任务,比如定机票,这里会涉及多轮交互。
第四,上下文的理解,这是对话交互和传统的搜索引擎最大的不同之处,传统搜索是关键词,前后的关键词是没有任何关系的。对话交互实际上是要考虑到上下文,在当前的上下文理解这句话什么意思。
我认为从连接到对话交互这背后的本质改变是从确定性变为不确定性。那么后面无论是算法还是交互设计,基本上都要想办法提高语言理解的确定性或者是降低交互的不确定性。

传统的对话交互,大概会分以下几个模块:语音识别子系统会把语音自动转成文字;语言理解就是把用户说的文字转化成一种结构化的语义表示;对话管理就是根据刚才的语义理解的结果来决定采取什么样的动作action,比如说定机票,或者设置闹钟。在语言生成这一块,就是根据action以及参数生成一段话,并通过一种比较自然的方式把它读出来。
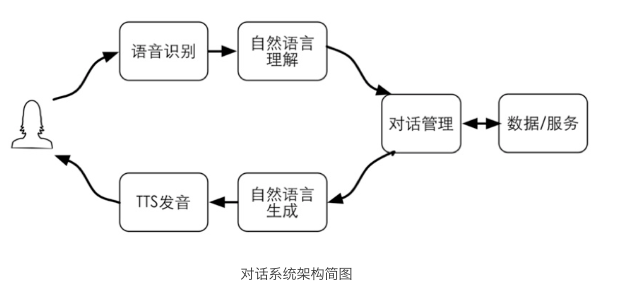
我认为现在人机交互和传统的人机交互一个不同点就是在数据和服务这一块,因为随着互联网的发展,数据和服务越来越丰富,那人机交互的目的是什么?归根到底还是想获取互联网的信息和各种各样的服务,所以,在现在的这种人机交互的场景中,数据和服务起的作用会越来越重要。
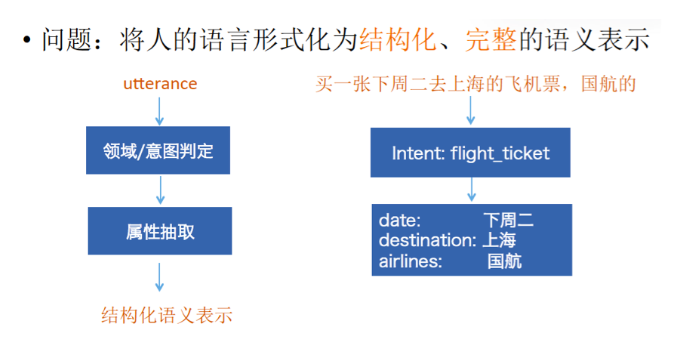

第一,表达的多样性。同样一个意图,比如用户说,我要听《大王叫我来巡山》,但是,不同的用户有太多太多不同的表达方式,我要听歌,给我放一首音乐等等。那对于机器来说,虽然表达方式不一样,但是意图是一样的,机器要能够理解这件事情。
第二,语言的歧义性。比如说,我要去拉萨,它是一首歌的名字,挺好听的歌。当用户说,我要去拉萨的时候,他也可能是听歌,也可能是买一张去拉萨的机票,也可能是买火车票,或者旅游。
第三,语言理解的鲁棒性,因为用户说话过程当中,比较自然随意,语言理解要能够捕获住或者理解用户的意图。
第四,上下文的理解。这是人机对话交互与传统的keyword搜索一个非常大的不同,它的理解要基于上下文。
在语言理解这一块,我们把用户语言的意图理解抽象为一个分类问题,把它抽象为分类问题之后,就有一套相对标准的方法解决,比如CNN神经网络、SVM分类器等等。阿里巴巴现在就是采用CNN神经网络方法,并在词的表示层面做了针对性的改进。
机器要理解用户的话的意思,背后一定要依赖于大量的知识。比如说,“大王叫我来巡山”是一首歌的名字,“爱探险的朵拉”是一个视频,互联网上百万量级这样开放领域的实体知识并且每天都会有新的歌曲/视频出现,如果没有这样大量的知识,我觉得机器是很难真的理解用户的意图的。那么在词的语义表示这块,除了word embedding,还引入了基于知识的语义表示向量。
刚才提到了,用户的话实际上是比较随意和自然的。那我们怎么样让这个模型有比较好的鲁棒性来解决口语语言的随意性问题呢?我们针对用户标注的数据,通过算法自动加一些噪音,加了噪音之后(当然前提是不改变语义),然后基于这样的数据再training模型,模型会有比较好的鲁棒性。
第二个模块是属性抽取,在这一块,我们把它抽象为一个序列标注问题。这个问题,神经网络也有比较成型的方法,我们现在也是用这种双向LSTM,在上面有一层CRF解码器,取得了不错的效果。当然其实在方法论上还是在神经网络框架下还是比较常见的或者说是标准的,但是这背后更大的功夫来自于对数据的分析和数据的加工。
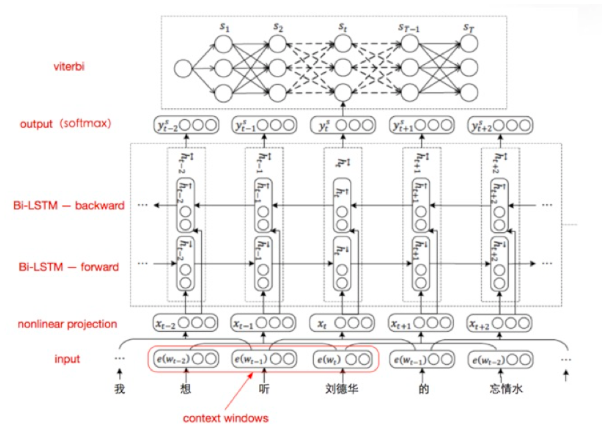
以上所述的人机对话语言理解最大的特色就是基于上下文的理解,什么是上下文?我们看一个例子,用户说“北京天气怎么样?”,机器回答说“北京的天气今天温度34度”。接着用户说“上海”呢?在这里的理解一定是理解他指的是上海的天气,所以是要能够理解用户说的话,是和上文有关系的,所以我们再对问题做了一个抽象,在上下文的情况下,这句话和上文有关还是无关,把它抽象为二分的分类问题。这么做了抽象和简化以后,这个事情就有相对成型的方法。
对话引擎就是根据语言理解的这种结构化的语义表示以及上下文,来决定采取什么样的动作。这个动作我们把它分成几类。
第一,用于语言生成的动作。
第二,服务动作。
第三,指导客户端做操作的动作。
我们来看一个简单的对话例子。用户说我要去杭州,帮我订一张火车票,这个时候机器首先要理解用户的意图是买火车票,之后就要查知识库,要买火车票依赖于时间和目的地,但是现在用户只说目的地没说时间,所以它就要发起一个询问时间的动作,机器问了时间之后,用户回答说“明天上午”。这个时候机器要理解用户说的明天上午正好是在回答刚才用户问的问题,这样匹配了之后,基本上这个机器就把这个最关键的信息都收集回来了:时间和目的地。之后,机器就可以发起另外一个请求服务指令,然后把火车票的list给出来。这个时候用户接着说,“我要第二个”。机器还要理解用户说的第二个,就是指的要打开第二个链接,之后用户说“我要购买”,这个时候机器要发起一个指令去支付。
综上,对话交互,我会把它分成两个阶段:
- 第一阶段,通过多轮对话交互,把用户的需求表达完整,因为用户信息很多,不可能一次表达完整,所以要通过对话搜集完整,第一阶段得到结构化的信息(出发地、目的地、时间等);
- 有了这些信息之后,第二阶段就是请求服务,接着还要去做选择、确定、支付、购买等等后面一系列的步骤。
其实,传统的人机对话,包括现在市面上常见的人机对话,一般都是只在做第一阶段的对话,包括像大家熟知的亚马逊Alexa,也只是在解决第一阶段的对话,第二阶段的对话做得不多。
我们在这个对话交互这块,在这方面还是做了一些有特色的东西。
第一,我们设计了一套面向Task Flow的对话描述语言。刚才说了,对话其实是分两个阶段的。传统的对话只是解决了第一阶段,我们设计的语言能够把整个对话任务流完整地表达出来,这个任务流就是类似于咱们程序设计的流程图。对话描述语言带来的好处是它能够让对话引擎和业务逻辑实现分离,分离之后业务方可以开发脚本语言,不需要修改背后的引擎。
第二,由于有了Task Flow的机制,我们在对话引擎方带来的收益是能够实现对话的中断和返回机制。在人机对话当中有两类中断,一类是用户主动选择到另外一个意图,更多是由于机器没有理解用户话的意思,导致这个意图跳走了。由于我们维护了对话完整的任务流,知道当前这个对话处在一个什么状态,是在中间状态还是成功结束了,如果在中间状态,我们有机会让它回来,刚才讲过的话不需要从头讲,可以接着对话。
第三,我们设计了对话面向开发者的方案,称之为Open Dialog,背后有一个语言理解引擎和一个对话引擎。面向开发者的语言理解引擎是基于规则办法,能够比较好的解决冷启动的问题,开发者只需要写语言理解的Grammar、基于对话描述语言开发一个对话过程,并且还有对数据的处理操作。这样,一个基本的人机对话就可以完成了。
问答引擎
其实人和机器对话过程中,不仅仅是有task的对话,还有问答和聊天,我们在问答引擎这块,目前还是着力于基于知识图谱的问答,因为基于知识图谱的问答能够比较精准地回答用户的问题,所以我们在这方面下的力气会多一点。
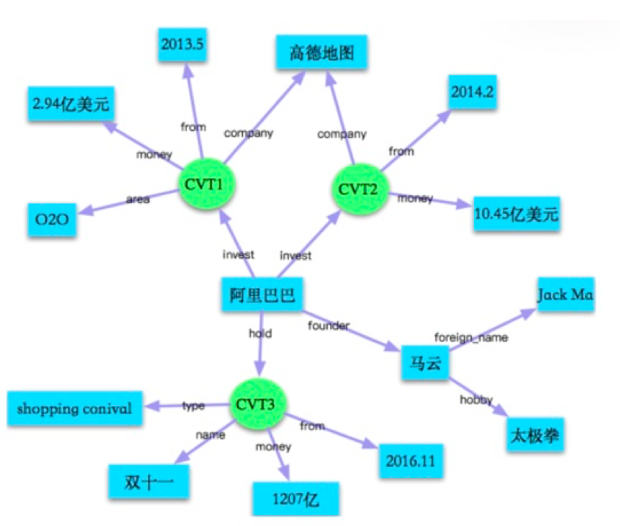
聊天引擎
在聊天这块,我们设计了两类聊天引擎。第一是基于<K,V>对的聊天引擎,它能够实现让业务方定制,为什么要定制呢?举个例子,在不同的场景下,机器的名字可能是不一样的,用户A和用户B给机器的名字是不一样的,我们有了这个机制之后,可以去定制机器的名字。但是这一方法的覆盖率是比较受限的。为了解决覆盖率的问题,我们又设计了基于seq2seq的生成式聊天引擎,这种生成式聊天,能够对开放的用户说的问题给出一个相对通顺并且符合逻辑的回答。当然这两类聊天引擎会有一个协同的策略在里面。

在功能上,比如说像地图、导航、路况,还有围绕着娱乐类的音乐、有声读物,还有实现对车的控制,在车的控制这块当然是受限的,现在能实现对车窗玻璃的控制。
在汽车场景下的对话交互,还和其他场景有非常多的不同。因为产品方希望当这个车在郊区网络不好的时候,最需要导航的时候,你要能够工作,所以我们的语音识别还有语言理解、对话引擎,就是在没有网络的情况下,要在端上能够完全工作,这里面的挑战也非常大。
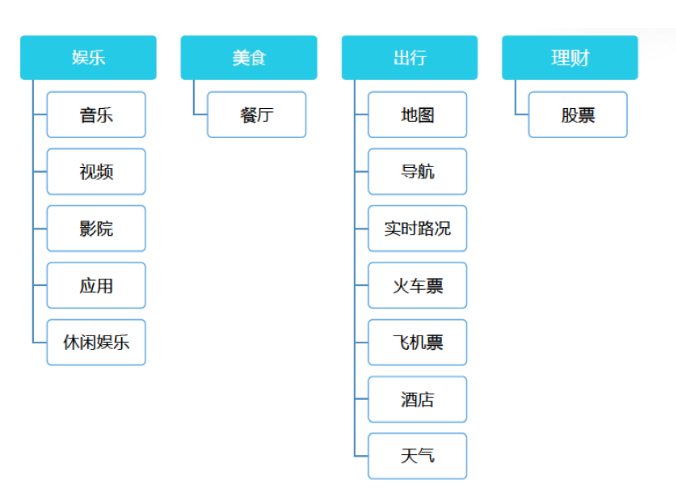
对话交互平台背后第二个能力,就是提供足够强的定制能力.
智能对话交互生态的范式思考
过去3-4年,在人机对话领域,应该是说还是取得了长足的进步,这样的进步来自于以深度学习为为代表的算法突破。这个算法的突破带来语音识别大的改进。同时,另一方面我们认为对话交互和真正的用户期望还是有明显的距离的,我认为有两点:第一,对话交互能覆盖的领域还是比较受限的,大家如果是用智能语音交互的产品,你就发现翻来覆去就是那几类,音乐、地图、导航、讲笑话等等。第二,有的能力体现得还不够好,所以我们想未来怎么办呢?
我们先看看现在的模式,有几种模式,我把它总结为两类模式。第一类,自主研发。很多的创业公司或者是团队基本上都是自主研发的,像苹果它基本上是自主研发的模式。第二类,平台模式,比如说典型代表就是亚马逊的Alexa,这个平台的一个好处,它能够发动开发者的力量快速地去扩展领域。但是你会发现现在在亚马逊Alexa上有8000多个这种能力,但是很多领域的体验都不够好,根本原因在于开放平台上开发的这些skill没有很好的评测手段和质量控制机制。
自主研发的好处是体验相对较好,平台模式的好处是能够快速扩展。所以如何把这两者结合在一起,有没有第三种模式。
第三种模式应该有以下几个特点
第一,由于自然语言理解的门槛还是比较高的,门槛高指的是对于开发者来说,它比开发一个APP难多了,从无到有开发出来不难,但要做到效果好是非常难的。所以,语言理解引擎最好能够自研;
第二,对话逻辑要平台化。对于对话交互因为它和业务比较紧,每个业务方有自己特殊的逻辑,通过平台化比较合适,让平台上的开发者针对各自场景的需求和交互过程来开发对话;
第三,需要建立一套评测体系,只有符合这个评测体系的,才能引入平台当中;
第四,需要商业化的机制,能够让开发者有动力去开发更多的以及体验更好的交互能力。

如果这几点能够做到,我们称之为第三种范式,基于这个范式的平台能够相对快速地并且开发的能力体验是有效果保证的。这样它开放给用户的时候,无论是对B用户还是C用户,可以有更多的用户价值。
总结
最后,总结下我们对于研发对话交互机器人的几点思考和体会:
第一,坚持用户体验为先。这个话说起来很容易,但是我们也知道,很多团队不是以用户为先的,是以投资者为先的,投资者喜欢什么样的东西,他们就开发什么样的东西。坚持用户体验为先,就是产品要为用户提供核心价值。
第二,降低产品和交互设计的不确定性。刚才也提到了,对话交互实际上最大的问题是不确定性,在产品的交互上我们要想办法把这种不确定性尽量降得低一点,惟有通过设备设计的时候降低,或者是交互界面的降低,或者是通过对话引导的方式,把这种不确定性尽量降低。
第三,打造语言理解的鲁棒性和领域扩展性。语言的理解能力尽量做到鲁棒性,能够比较好的可扩展。
第四,打造让机器持续学习能力。对话交互我认为非常非常重要的一点,就是怎么样能够让机器持续不断地学习。现在的这种对话交互基本上还都是有产品经理或者是人工定的,定好之后这个能力是固化的,所以怎么样能够把算法(策划学习)能力打造出来,就像小朋友学语言一样,随着年龄的增长,能力会持续不断地增强。
第五是打造数据闭环。要能够快速地达到数字闭环,当然这个闭环当中要把数据的效能充分调动起来,结合更多数据的服务。

找我内推: 字节跳动各种岗位
作者:
ZH奶酪(张贺)
邮箱:
cheesezh@qq.com
出处:
http://www.cnblogs.com/CheeseZH/
*
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号