MLflow系列2:MLflow追踪
英文链接:https://mlflow.org/docs/latest/tracking.html
本文链接:https://www.cnblogs.com/CheeseZH/p/11945089.html
MLflow Tracking
MLflow Tracking组件提供了API和UI,用于记录并可视化展示机器学习代码运行过程中的参数,代码版本,评价指标和输出文件。MLflow Tracking可以让你通过Python,REST API,R API或Java API来记录和查询试验。
一些概念
MLflow Tracking围绕着runs的概念进行组织,runs是一些数据科学代码片段的执行。一个run记录了以下信息:
Code Version/代码版本
如果run是来自一个MLflow项目,那么版本就是代码的Git提交对应的hash值。
Start&End Time/起止时间
run的开始时间和结束时间。
Source/源文件
启动run的文件名,或者MLflow项目的项目名和入口。
Parameters/参数
所选输入参数的Key-Value对,Key和Value都是字符串。
Metrics/评价指标
Key-value指标,value是数值。每个指标都可以在run的执行过程中被更新(比如记录模型损失函数的收敛曲线),MLflow记录并可视化指标的完整历史。
Artifacts/模型产品
任何格式的输出文件。你可以记录图片,模型或者数据文件。
你可以通过MLflow Python,R,Java或者REST APIs来记录runs。比如你可以记录一个单独的程序,可以记录远程及其或者交互式notebook。如果你记录MLflow项目的runs,MLflow会记住项目URI和源文件的版本。
你可以通过experiments来组织runs,experiments是用于特定任务的一组runs。你可以通过以下方式创建一个experiment:
mlflow experiments命令- mlflow.create_experiment()
- 使用对应的REST API
- MLflow API和UI让你可以创建和搜索experiments
当你的runs被记录之后,你可以通过Tracking UI或者MLflow API来查询。
Runs被记录在哪?
MLflow runs可以被存储在本地文件,SQLAlchemy兼容的数据库或者远程的服务器。默认情况下,MLflow Python API会把runs记录在你的运行程序所在的目录的mlruns子目录。你可以使用mlflow ui查看记录的runs。
如果把runs存储到远程服务器,需要配置环境变量MLFLOW_TRACKING_URI 或者调用mlflow.set_tracking_uri()。
URI可以有多种形式:
- 本地路径,格式为
/my/local/dir - 数据库,格式为
<dialect>+<driver>://<username>:<password>@<host>:<port>/<database>,Mlflow支持mysql,sqlite,postgresql等多种SQLAlchemy数据库 - HTTP服务器,格式为
https://my-server:5000,该服务是一个MLflow tracking server。 - Databricks工作空间,格式为
databricks或者databricks://<profileName>,一个Databricks CLI profile。更多信息参考文档或者Databricks社区版快速入门。
把数据保存成runs
你可以通过MLflow Python,R,Java或者REST API来把数据保存成runs,本章节主要介绍Python API。
Logging Functions/日志函数
mlflow.set_tracking_uri() 连接一个记录URI,也可以通过环境变量MLFLOW_TRACKING_URI 来配置,默认是本地的mlruns目录。
mlflow.tracking.get_tracking_uri()返回当前的记录URI。
mlflow.create_experiment()创建一个新experiment并返回ID。通过将ID传入mlflow.start_run可以启动experiment下面的runs。
mlflow.set_experiment()激活一个experiment。如果experiment不存在,则创建一个。
mlflow.start_run()返回当前激活的run,或者启动一个新的run并返回一个mlflow.ActiveRun对象。不需要显示调用start_run,如果没有激活状态的run,日志函数会自动创建一个。
mlflow.end_run()结束当前处于激活状态的run。
mlflow.active_run()返回一个mlflow.entities.Run对象。
mlflow.log_param()记录一个当前run的key-value参数。使用mlflow.log_params()可以记录多个参数。
mlflow.log_metric()记录一个当前run的key-value指标。MLflow会记录每个metric的所有历史值。使用mlflow.log_metrics()可以记录多个指标。
mlflow.set_tag()给当前run设置一个key-value标签。使用mlflow.set_tags()设置多个标签。
mlflow.log_artifact()把一个本地文件或目录存储为一个artifact,可以通过artifact_path指定run的artifact URI。Run artifacts可以通过目录的方式组织。
mlflow.log_artifacts()把指定目录下的所有文件存储为一个artifact。
mlflow.get_artifact_uri()返回当前run指定的artifact URI。
在一个程序中启动多个runs
有时候你希望能够在一个程序中启动多个runs,比如你在执行一个超参数搜索程序或者你的experiments运行非常快。mlflow.start_run()返回的ActiveRun对象是一个python context manager。你可以通过以下代码块来限定每个run的范围。
with mlflow.start_run():
mlflow.log_param("x", 1)
mlflow.log_metric("y", 2)
...
在with语句中,这个run会保持打开状态,语句退出或者有异常时会自动关闭。
通过指标记录模型表现
你通过log方法来记录各个指标,log方法提供了两个可选方法用于区分指标的x-axis:timestamp和step。
timestamp是metric被记录的时间,默认是当前时间。
step是训练过程的量化值,可以是迭代次数,轮数或者其他值,默认是0并且有以下要求和特性:
- 一定是个合法的64位整型
- 可以是负数
- 可以是非连续的,比如(1,3,2)也是合法的
- 可以有跳跃性的,比如(1,5,74,-10)也是合法的
你可以同时指定timestamp和step,MLflow会分别存储。
Python示例:
with mlflow.start_run():
for epoch in range(0, 3):
mlflow.log_metric(key="quality", value=2*epoch, step=epoch)
可视化指标
下图取自quick start,包含一个step x-axis和两个timestamp x-axis。
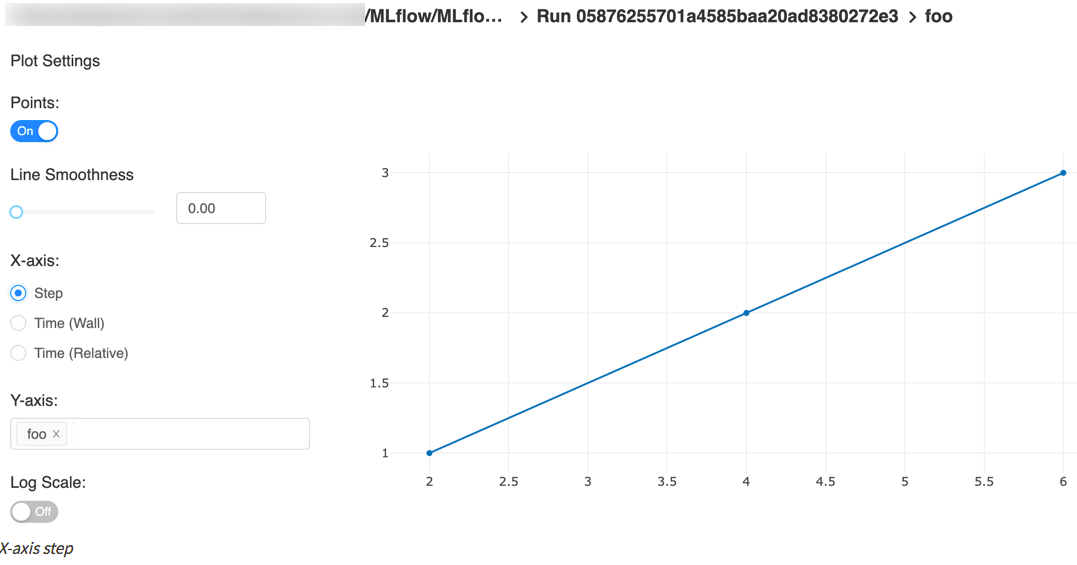
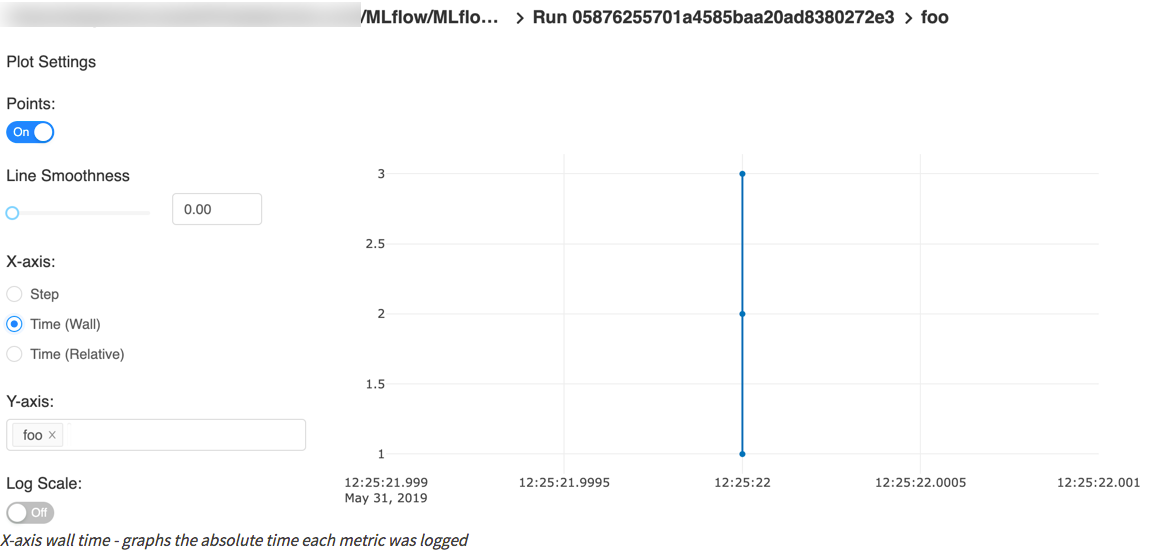
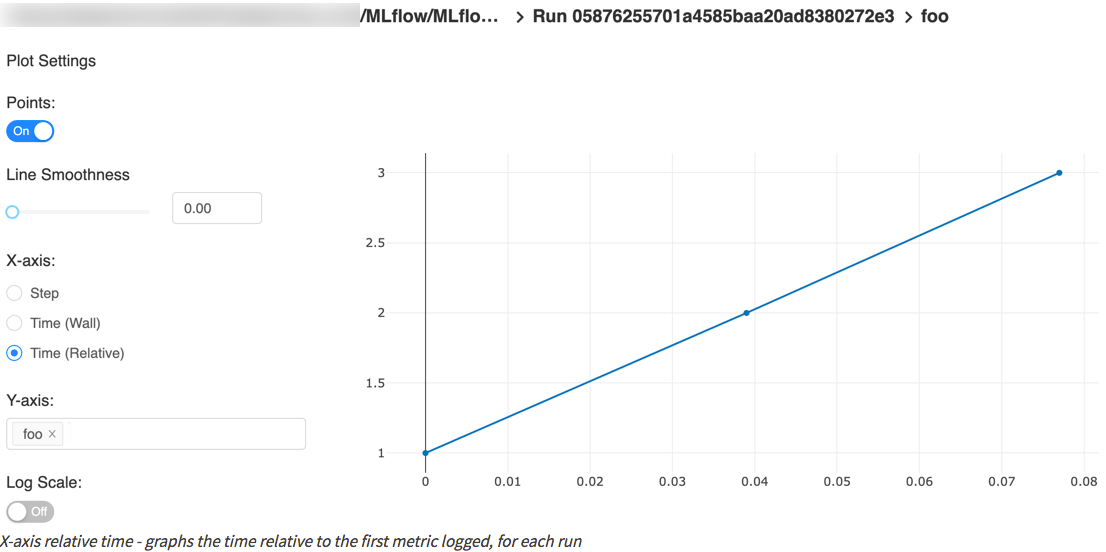
自动记录TensorFlow和Keras的日志(experimental)
在训练之前调用mlflow.tensorflow.autolog()或mlflow.keras.autolog()即可,参考Tensorflow和Keras的例子。
自动记录以下信息:
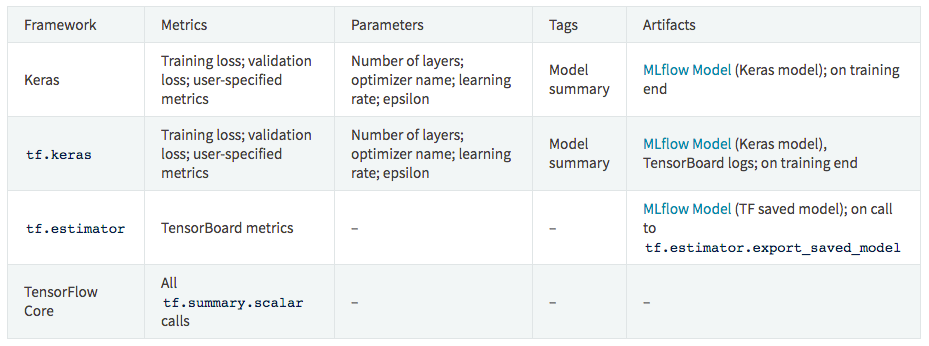
注意 tf.keras 使用 mlflow.tensorflow.autolog(), 而不是 mlflow.keras.autolog().
组织experiments中的runs
MLflow允许你在experiments中组织runs,这样可以方便的对比处理同个任务的不同runs。你可以通过命令行mlflow experiments或者python API mlflow.create_experiment()创建experiments。你可以在命令行中为单独的run指定experiment,例如mlflow run ... --experiment-name [name] 或者通过环境变量MLFLOW_EXPERIMENT_NAME 来指定。或者用experiment ID(--experiment-id命令行参数或者MLFLOW_EXPERIMENT_ID环境变量)也行。
# Set the experiment via environment variables
export MLFLOW_EXPERIMENT_NAME=fraud-detection
mlflow experiments create --experiment-name fraud-detection
# Launch a run. The experiment is inferred from the MLFLOW_EXPERIMENT_NAME environment
# variable, or from the --experiment-name parameter passed to the MLflow CLI (the latter
# taking precedence)
with mlflow.start_run():
mlflow.log_param("a", 1)
mlflow.log_metric("b", 2)
通过追踪服务API来管理Experiments和Runs
MLflow提供了更详细的追踪服务API来管理experiments和runs,主要是用mlflow.tracking模块的client SDK。这样就可以查询过去runs的数据,记录更多日志,创建experiments,添加tag等。
from mlflow.tracking import MlflowClient
client = MlflowClient()
experiments = client.list_experiments() # returns a list of mlflow.entities.Experiment
run = client.create_run(experiments[0].experiment_id) # returns mlflow.entities.Run
client.log_param(run.info.run_id, "hello", "world")
client.set_terminated(run.info.run_id)
为Runs添加标签
mlflow.tracking.MlflowClient.set_tag()方法可以为runs添加个性化标签。一个标签一次只能有一个唯一值。例如:
client.set_tag(run.info.run_id, "tag_key", "tag_value")
注意:不要用mlflow作为tag的前缀,以下是系统tags。
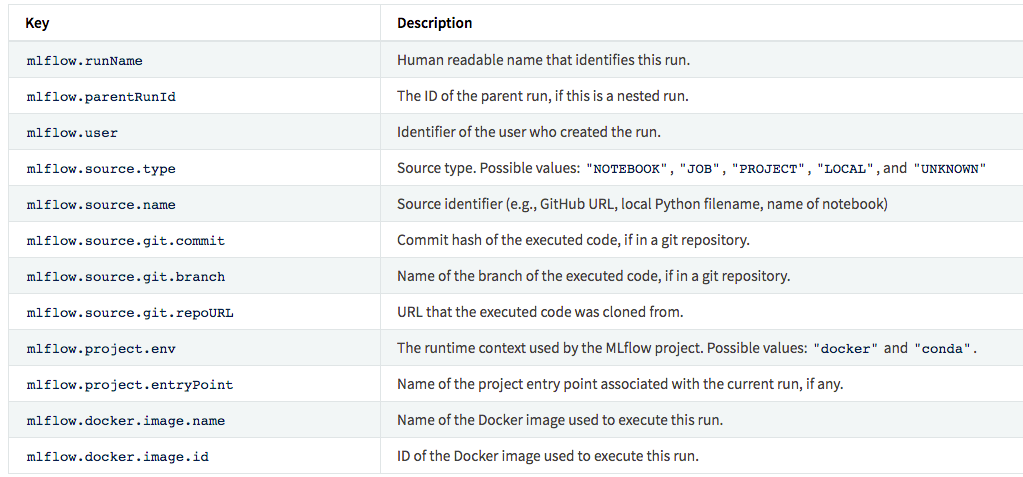
追踪UI
追踪UI能够可视化,搜索,对比runs,也能下载run的产品或者元数据。
如果将runs记录在本地mlruns目录,只需要在mlruns的上层目录中运行mlfow ui就可以。
或者你也可以通过MLflow tracking server来访问远程的runs。
UI主要包括以下功能:
- 基于experiment的run列表和对比
- 根据参数或者指标搜索runs
- 可视化run的指标
- 下载run的结果
通过编程查询runs
引用artifacts
- /Users/me/path/to/local/model
- relative/path/to/local/model
/ . 例如: - s3://my_bucket/path/to/model
- hdfs://
: / - runs:/<mlflow_run_id>/run-relative/path/to/model
例如
# Tracking API
mlflow.log_artifacts("<mlflow_run_id>", "/path/to/artifact")
# Models API
mlflow.pytorch.load_model("runs:/<mlflow_run_id>/run-relative/path/to/model")
MLflow Tracking Servers
你可以通过mlflow server命令启动一个tracking server,一个样例配置:
mlflow server \
--backend-store-uri /mnt/persistent-disk \
--default-artifact-root s3://my-mlflow-bucket/ \
--host 0.0.0.0
存储
一个MLflow tracking server包含两个存储组件:后端存储和产品存储。
后端存储用于保存experiment和run的元数据,比如参数,指标,标签等。后端存储支持两种类型:文件存储,数据库存储。通过--backend-store-uri来配置后端存储类型。
- ./path_to_store 或者 file:/path_to_store
- SQLAlchemy database URI:
+ 😕/ : @ : / ,比如--backend-store-uri sqlite:///mlflow.db会使用本地的SQLite数据库。
默认--backend-store-uri是./mlruns目录。
产品存储需要存储大量数据以及客户端记录的输出产品(例如模型)。artifact_location是mlflow.entities.Experiment的一个属性。artifact_uri是mlflow.entities.RunInfo的一个属性用于标明当前run的所有artifacts需要保存在哪里。
使用--default-artifact-root (默认./mlruns目录)来配置默认的存储位置。
Artifact存储
- Amazon S3
- Azure Blob Storage
- Google Cloud Storage
- FTP server
- SFTP Server
- NFS
- HDFS
Logging to a Tracking Server
通过环境变量MLFLOW_TRACKING_URI或者调用mlflow.set_tracking_uri()来指定Tracking服务器。
然后mlflow.start_run(), mlflow.log_param(), 和 mlflow.log_metric()会向指定的tracking服务器发送API请求。
import mlflow
remote_server_uri = "..." # set to your server URI
mlflow.set_tracking_uri(remote_server_uri)
# Note: on Databricks, the experiment name passed to mlflow_set_experiment must be a
# valid path in the workspace
mlflow.set_experiment("/my-experiment")
with mlflow.start_run():
mlflow.log_param("a", 1)
mlflow.log_metric("b", 2)
其他参考项目
- Multistep Workflow Example project:查询runs并构建一个多步骤工作流
- TensorFlow example:训练,导出,加载模型并使用模型进行预测。
- Hyperparameter Tuning Example project: 自动搜索模型的最佳超参数

找我内推: 字节跳动各种岗位
作者:
ZH奶酪(张贺)
邮箱:
cheesezh@qq.com
出处:
http://www.cnblogs.com/CheeseZH/
*
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号