[No0000165]SQL 优化
SELECT 标识选择哪些列
FROM 标示从哪个表中选择
WHERE 过滤条件
GROUP BY 按字段数据分组
HAVING 字句过滤分组结果集
ORDER BY 序按字段排序 ASC( 默认) 序升序 DESC 降序
备注:尽量避免使用select * from TAB, 按需选取需要的字段
使用*, 在解析的过程中会将* 依次转换成所有的列名, 这个工作是通过
查询数据字典完成的, 这意味着将耗费更多的时
Oracle 表访问方式
• 全表扫描
1、Oracle读取表中所有的行,并检查每一行是否满足语句的WHERE限制条件。
2、非常消耗IO,CPU,内存资源,是我们尽量避免的一种方式
• 索引扫描
1、先通过index查找到数据对应的rowid值(对于非唯一索引可能返回多个rowid值),然后根据rowid直接从表中得到具体的数据,这种查找方式称为索引扫描或索引查找。
2、一般查取的数据量小于表里数据总量的 5%-10%时,建议采用索扫描。
Oracle多表连接方式
• Inner join(内连接)两边表同时符合条件的组合,只返回两表相匹配的数据。
• left join (左连接)显示符合条件的数据行,左表返回所有数据,右表中只返回与左表匹配的数据, 右边没有对应的条目显示NULL。
• right join(右连接)显示符合条件的数据行,右表返回所有数据,左表只返回与右表匹配的数据,左边没有对应的条目显示NULL。
• full join (全连接)显示符合条件的数据行,同时显示左右不符合条件的数据行,相应的左右两边显示NULL,即显示左连接、右连接和内连接的并集
inner join的方式: /*只返回两表相匹配的数据,显示左表的3、4和右表的 3,4 ,左表的1、2和右表的5、6都没有显示*/ SQL> SELECT L.str AS LEFT_str,R.str ASRIGHT_str FROM L INNER JOIN R ON L.v = R.v ORDER BY 1,2; LEFT_S ASRIGHT ------ ------- left_3 right_3 left_4 right_4 left join的方式:/*左表返回所有数据,右表中只返回与左表匹配的数据,右表5、6都没有显示并且与左表1、2对应的条目显示为null*/ SQL> SELECT L.str AS LEFT_str,R.str ASRIGHT_str FROM L LEFT JOIN R ON L.v = R.v ORDER BY 1,2; LEFT_S ASRIGHT ------ ------- left_1 left_2 left_3 right_3 left_4 right_4 right join的方式:/*左表只返回与右表匹配的数据3、4,右表返回所有数据,左表 1、2都没有显示且与右表5、6对应没有条目的显示null*/ SQL> SELECT L.str AS LEFT_str,R.str ASRIGHT_str FROM L RIGHT JOIN R ON L.v = R.v ORDER BY 1,2; LEFT_S ASRIGHT ------ ------- left_3 right_3 left_4 right_4 right_5 right_6 full join的方式:/*左右表均返回所有数据,但只有相匹配的数据显示在同一行,非匹配的行只显示一个表的数据*/ SQL> SELECT L.str AS LEFT_str,R.str ASRIGHT_str FROM L FULL JOIN R ON R.v = L.v ORDER BY 1,2; LEFT_S ASRIGHT ------ ------- left_1 left_2 left_3 right_3 left_4 right_4 right_5 right_6
标量子查询
select tab.owner, (select object_type from obj where tab.table_name=obj.object_name)
from tab where tab.status='VALID';
标量子查询的原理:
(1).主查询返回多少行,标量子查询就被扫描多少次,如果返回的记录数很少的时候sql性能影响的不是很大。
(2).如果主查询返回的结果集比较的大话,性能会有严重的影响,我们可以在业务容许的情况下,让返回的结果集尽量的少(加过滤条件)或者我们考虑减少子查询访问的体积,例如在合适的字段上面建立索引。
(3).如果还不能解决问题,最好就是要改写了,使用join的方式将子查询改写到语句的from后面。
SQL> select /*+ gather_plan_statistics */ tab.owner, (select object_type from obj where tab.table_name=obj.object_name) from tab where tab.status='VALID';
SQL> select * from table(dbms_xplan.display_cursor(null,null,'advanced allstats last'));

Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJ"."OBJECT_NAME"=:B1)
2 - filter("TAB"."STATUS"='VALID')
可以看到 tab执行一次全表扫描,获取 203行数据, 然后 203条数据,每一条去和 obj表进行一次查询,obj表被查询 203次, 发生了 203次全表扫描,性能非常低下。
标量子查询 改写
SQL> select /*+ gather_plan_statistics */ tab.owner, obj.object_type from tab left join obj on tab.table_name=obj.object_name and tab.status='VALID';
SQL> select * from table(dbms_xplan.display_cursor(null,null,'advanced allstats last'));

Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("TAB"."TABLE_NAME"="OBJ"."OBJECT_NAME" AND "TAB"."STATUS"=CASE WHEN ("OBJ"."OBJECT_NAME" IS NOT NULL) THEN 'VALID' ELSE 'VALID' END )
可以看到 tab,obj 表各执行一次全表扫描,获取数据后进行HASH JOIN , 性能比标量子查询效率高。
Oracle不能使用索引的情况
- Where列上使用函数导致索引失效
避免对条件列使用函数
SQL> select count(*) from newsadmin.ann_basinfo t where to_char(eutime,‘yyyy-mm-dd’)=‘2018-06-20’ ;

SQL> select count(*) from newsadmin.ann_basinfo t where eutime=to_date('2018-06-20‘,’yyyy-mm-dd’);
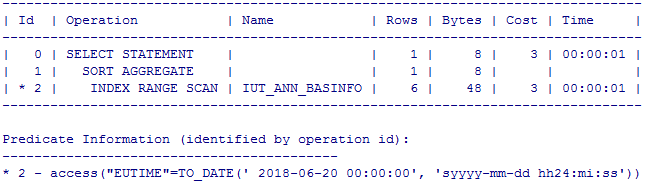
在对条件列上使用函数运算时,无法使用到列上的 索引,导致使用不好的执行计划,性能下降。
- Where 列上带有运算符
避免对条件列进行运算
SQL> select object_name from my_object where object_id -100 = 10086 ;

SQL> select object_name from my_object where object_id=10086+100;

在对条件列上进行运算时,无法使用到列上的 索引,导致使用不好的执行计划,性能下降。
- Where 列上存在隐式类型转换
避免条件列产生隐式类型转化

SQL> select * from my_object where OBJECT_ID_1=10086;

* 1 - filter(TO_NUMBER("OBJECT_ID_1")=10086)
SQL> select * from my_object where OBJECT_ID_1='10086';

* 2 - access("OBJECT_ID_1"='10086')
列类型隐式转换其他问题案例
截取一段 5.24日 EMBASERACPDG05 库系统负载图
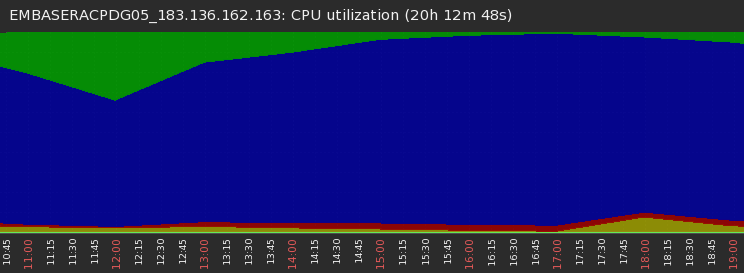
抓取到其中一条SQL 如下:
SELECT ROWNUM ID, A.CDSY_SECUCODE_EID, SPTM_MARKETRELATION_EID, B.EID LICO_FN_FCRGCASHS_EID, A1.CDSY_KP_PUBLISHSTOCK_EID, A1.CDSY_KP_PUBLISHRELATION_EID, A.MSECUCODE SECURITYCODE, A.SECURITYCODE STR_SECURITYCODE_HIDE, SECURITYSHORTNAME, TO_CHAR(B.REPORTDATE, 'YYYY') STR_BAOGAOQI, B.REPORTDATE DAT_REPORTDATE_HIDE, CASE WHEN TO_CHAR(B.REPORTDATE, 'MM') = '12' THEN '年报' WHEN TO_CHAR(B.REPORTDATE, 'MM') = '06' THEN '半年报' WHEN TO_CHAR(B.REPORTDATE, 'MM') = '03' THEN '一季报' WHEN TO_CHAR(B.REPORTDATE, 'MM') = '09' THEN '三季报' END STR_BAOGAORIQILEIXING, ROUND(B.NETOPERATECASHFLOW_S / 10000, 15) DEC_BENQIJINGYING, ROUND(C.NETOPERATECASHFLOW_S / 10000, 15) DEC_SHANGQIJINGYING, CASE WHEN NVL(NVL(B.NETOPERATECASHFLOW_S, 0) - NVL(C.NETOPERATECASHFLOW_S, 0), 0) = 0 OR NVL(C.NETOPERATECASHFLOW_S, 0) = 0 THEN 0 ELSE ROUND((NVL(B.NETOPERATECASHFLOW_S, 0) - NVL(C.NETOPERATECASHFLOW_S, 0)) / ABS(C.NETOPERATECASHFLOW_S) * 100, 15) END DEC_JINGYINGZENGZHANG, ROUND(B.NETINVCASHFLOW_S / 10000, 15) DEC_BENQITOUZI, ROUND(C.NETINVCASHFLOW_S / 10000, 15) DEC_SHANGQITOUZI, CASE WHEN NVL(NVL(B.NETINVCASHFLOW_S, 0) - NVL(C.NETINVCASHFLOW_S, 0), 0) = 0 OR NVL(C.NETINVCASHFLOW_S, 0) = 0 THEN 0 ELSE ROUND((NVL(B.NETINVCASHFLOW_S, 0) - NVL(C.NETINVCASHFLOW_S, 0)) / ABS(C.NETINVCASHFLOW_S) * 100, 15) END DEC_TOUZIZENGZHANG, ROUND(B.NETFINACASHFLOW_S / 10000, 15) DEC_BENQICHOUZI, ROUND(C.NETFINACASHFLOW_S / 10000, 15) DEC_SHANGQICHOUZI, CASE WHEN NVL(NVL(B.NETFINACASHFLOW_S, 0) - NVL(C.NETFINACASHFLOW_S, 0), 0) = 0 OR NVL(C.NETFINACASHFLOW_S, 0) = 0 THEN 0 ELSE ROUND((NVL(B.NETFINACASHFLOW_S, 0) - NVL(C.NETFINACASHFLOW_S, 0)) / ABS(C.NETFINACASHFLOW_S) * 100, 15) END DEC_CHOUZIZENGZHANG, ROUND(B.NICASHEQUI_S / 10000, 15) DEC_BENQIXIANJIN, ROUND(C.NICASHEQUI_S / 10000, 15) DEC_SHANGQIXIANJIN, CASE WHEN NVL(NVL(B.NICASHEQUI_S, 0) - NVL(C.NICASHEQUI_S, 0), 0) = 0 OR NVL(C.NICASHEQUI_S, 0) = 0 THEN 0 ELSE ROUND((B.NICASHEQUI_S - C.NICASHEQUI_S) / ABS(C.NICASHEQUI_S) * 100, 15) END DEC_XIANJINZENGZHANG, SUBSTR(STR_PUBLISHCODEZJH, 1, 6) STR_PUBLISHCODEZJH, (SELECT XX1.PUBLISHNAME FROM NEWSADMIN.CDSY_KP_PUBLISHRELATION XX1 WHERE XX1.PUBLISHCODE = SUBSTR(STR_PUBLISHCODEZJH, 1, 6) AND XX1.PUBLISHCODE LIKE '002%' AND XX1.EISDEL = 0) AS STR_PUBLISHNAMEZJH, SUBSTR(STR_PUBLISHCODEDC1, 1, 12) AS STR_PUBLISHCODEDC3, (SELECT XX1.PUBLISHNAME FROM NEWSADMIN.CDSY_KP_PUBLISHRELATION XX1 WHERE XX1.PUBLISHCODE = SUBSTR(STR_PUBLISHCODEDC1, 1, 12) AND XX1.PUBLISHCODE LIKE '004%' AND XX1.EISDEL = 0) AS STR_PUBLISHNAMEDC3 FROM (SELECT A.EID CDSY_SECUCODE_EID, B.EID SPTM_MARKETRELATION_EID, A.SECURITYCODE || B.MARKETRELEATION MSECUCODE, A.SECURITYCODE, A.SECURITYSHORTNAME, TO_CHAR(A.COMPANYCODE)COMPANYCODE FROM NEWSADMIN.CDSY_SECUCODE A JOIN NEWSADMIN.SPTM_MARKETRELATION B ON A.TRADEMARKETCODE = B.MARKETCODE WHERE A.EISDEL = 0 AND B.EISDEL = 0 AND (A.SECURITYTYPE = 'A股' OR A.SECURITYTYPE = 'B股' OR A.SECURITYTYPE = '三板股')) A JOIN (SELECT EID, COMPANYCODE, REPORTDATE, NETOPERATECASHFLOW_S, NETINVCASHFLOW_S, NETFINACASHFLOW_S, NICASHEQUI_S, DATAAJUSTTYPE FROM NEWSADMIN.LICO_FN_FCRGCASHS WHERE EISDEL = 0 AND COMBINETYPECODE = 001 AND DATAAJUSTTYPE = '3') B ON A.COMPANYCODE = B.COMPANYCODE LEFT JOIN (SELECT COMPANYCODE, REPORTDATE, NETOPERATECASHFLOW_S, NETINVCASHFLOW_S, NETFINACASHFLOW_S, NICASHEQUI_S, DATAAJUSTTYPE FROM NEWSADMIN.LICO_FN_FCRGCASHS a WHERE COMBINETYPECODE = 001 AND DATAAJUSTTYPE = '2') C ON B.COMPANYCODE = C.COMPANYCODE AND TO_CHAR(B.REPORTDATE, 'YYYY') - 1 = TO_CHAR(C.REPORTDATE, 'YYYY') AND TO_CHAR(B.REPORTDATE, 'MM-DD') = TO_CHAR(C.REPORTDATE, 'MM-DD') LEFT JOIN (SELECT B.EID CDSY_KP_PUBLISHSTOCK_EID, C.EID CDSY_KP_PUBLISHRELATION_EID, SECURITYCODE, COMPANYCODE, C.PUBLISHCODE AS STR_PUBLISHCODEZJH FROM NEWSADMIN.CDSY_KP_PUBLISHSTOCK B JOIN NEWSADMIN.CDSY_KP_PUBLISHRELATION C ON C.PUBLISHCODE = B.PUBLISHCODE WHERE C.PUBLISHCODE LIKE '002%' --证监会行业 AND B.EISDEL = 0 AND C.EISDEL = 0) A1 ON A1.SECURITYCODE = A.SECURITYCODE AND A1.COMPANYCODE = A.COMPANYCODE LEFT JOIN (SELECT SECURITYCODE, COMPANYCODE, C.PUBLISHCODE AS STR_PUBLISHCODEDC1 FROM NEWSADMIN.CDSY_KP_PUBLISHSTOCK B JOIN NEWSADMIN.CDSY_KP_PUBLISHRELATION C ON C.PUBLISHCODE = B.PUBLISHCODE WHERE C.PUBLISHCODE LIKE '004%' --东财行业 AND B.EISDEL = 0 AND C.EISDEL = 0) A2 ON A2.SECURITYCODE = A.SECURITYCODE AND A2.COMPANYCODE = A.COMPANYCODE --WHERE A.SECURITYCODE='000012' --AND TO_CHAR(B.REPORTDATE,'YYYY-MM-DD')='2010-12-31'
其中字段 COMBINETYPECODE 是varchar2 类型,SQL 中给了一个number ,导致SQL 走错执行计划,修改后 原来跑 50分钟的,后来只跑了 5分钟。
- Where 列上 Like ‘%XX’ 形式的查询
列上 Like ‘%XX’ 形式
SQL> select * from my_objects where object_name like '%FUND%';

SQL> select * from my_objects where object_name like 'FUND%';

在对条件列上进行%在前过滤时,无法使用到列上的 索引,导致使用不好的执行计划,性能下降。
- Where 列上使用 <>
避免对条件列使用<>
SQL> select * from my_objects where object_name <> 'FUND';

SQL> select * from my_objects where object_name = 'FUND';

在对条件列上进行运算时,无法使用到列上的 索引,导致使用不好的执行计划,性能下降。
优化 != , 可以通过建 decode(object_name,’FUND’,null,1) 函数索引优化
- Where 列上使用 is null
避免对条件列is null
SQL> select * from my_objects where object_name is null;

优化1:
create index inx_object_name1 on my_objects(object_name,1);
select * from my_objects where object_name is null;

优化2:
create index inx_object_name on my_objects(decode(object_name,null,1,2));
select * from my_objects where decode(object_name,null,1,2) =1;

在对条件列使用is null ,无法使用到列上的 索引,导致使用不好的执行计划,性能下降。
Oracle 其他优化技巧
UNION ALL 代替 OR
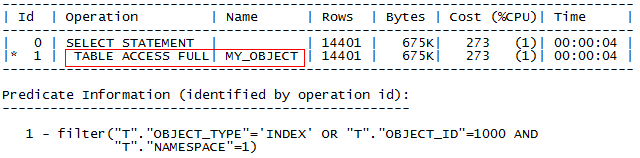
SQL> select owner, object_name, object_type from my_object t where t.object_id=1000 or t.object_type='INDEX';
SQL> select owner, object_name, object_type from my_object t where t.object_id=1000
union all
3 select owner, object_name, object_type from my_object t where t.object_type='INDEX';
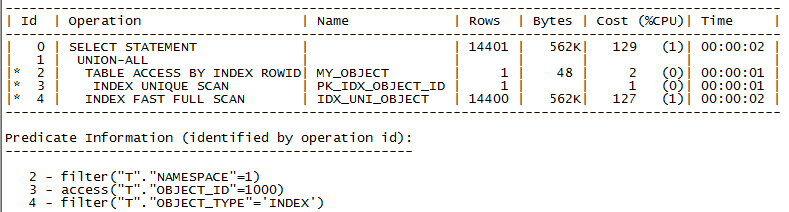
Object_id, object_type 列上都存在索引,使用OR 时全表扫描,性能较差,修改UNION ALL 后全部使用到索引,提升性能。
select (列名) 代替 select *
SQL> select /*+ gather_plan_statistics */ object_id from my_object where TEMPORARY='YES';
no rows selected
SQL> select * from table(dbms_xplan.display_cursor(null,null,'advanced allstats last'));

SQL> select /*+ gather_plan_statistics */ * from my_object where TEMPORARY='YES';
no rows selected
SQL> select * from table(dbms_xplan.display_cursor(null,null,'advanced allstats last'));

同样是没有查询到数据, select 列需要消耗 353k 内存资源, select * 则消耗了 4.9M 内存资源, 在内存资源,IO 资源,及网络流量上 select * 都要昂贵的多, 所以不要轻易写 select * 在 SQL 语句中。
减少不必要的排序
SQL> select count(*) from (select * from my_object order by object_name) t;

SQL> select count(*) from (select * from my_object ) t;

Order by 在此处就是不必要的,添加后 产生了一次排序操作,消耗了14M 的排序空间,消耗了大量的内存和CPU资源,性能非常差。
巧用CASE .. WHEN 用法
-----性能低下的写法
SQL> SELECT EID, LISTAGG(NAME, ',') WITHIN GROUP(ORDER BY EID) 发放日1 FROM (SELECT EID, '现金:' || TO_CHAR(CASHDATE, 'YYYY-MM-DD') NAME FROM NEWSADMIN.HK_HOLDER_DIVIDEND WHERE CASHDATE IS NOT NULL UNION ALL SELECT EID, '送股:' || TO_CHAR(SENDSHAREDATE, 'YYYY-MM-DD') NAME FROM NEWSADMIN.HK_HOLDER_DIVIDEND WHERE SENDSHAREDATE IS NOT NULL) GROUP BY EID;
执行计划:
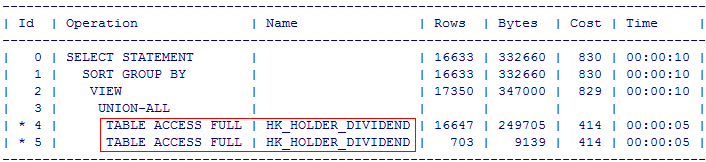
这条语句中对表NEWSADMIN.HK_HOLDER_DIVIDEND 全表扫描了 2次,看看这个如何用 case when 优化?
SQL>SELECT EID, CASE WHEN SENDSHAREDATE IS NOT NULL THEN '送股:' || TO_CHAR(SENDSHAREDATE, 'YYYY-MM-DD') || ',' END || CASE WHEN CASHDATE IS NOT NULL THEN '现金:' || TO_CHAR(CASHDATE, 'YYYY-MM-DD') END RELEASDATE1 FROM NEWSADMIN.HK_HOLDER_DIVIDEND WHERE CASHDATE IS NOT NULL OR SENDSHAREDATE IS NOT NULL;
执行计划:

通过改写 NEWSADMIN.HK_HOLDER_DIVIDEND 这张表2次全表扫描 是不是就变成 1次了, 执行效率大大提高。
CLOB,NCLOB等大字段要求
1、 大字段尽量不要出现在 select 列表里,如果一定要出现,可以使用dbms_lob.substr(XXX,2000,1)取特定长度查询。
2、 大字段尽量不要出现在 where 列条件里, 对大字段做条件判断性非常低下。
3、 大字段尽量不要出现在 JOIN 关联列里,性能低下不说,且毫无意义。
4、 大字段的设计优化,可以考虑从2个方面考虑:
1) 可以设计一张子表主要用于存放大字段数据,当主表中需要查询大字段时,通过主表与子表关联的方式查询,在多数情况下我们只需要查询主表信息,而并不需要查询大字段。
2)彻底将大字段列从数据库中分离出去 ,单独存放在共享文件服务器上,表中大字段列只存放指向文件服务器的一个路径,当需要读取大字段内容时,通过链接到文件服务器上打开文件。
这样设计从性能上,提高我们主表查询效率,从容量上同样减轻数据库的负担。
限制条件推入
SQL> select t.* from (select t.companycode, t.eid, t.eitime , rownum from newsadmin.balance_l t where t.eisdel ='4') t where t.eid=120000001555720986;
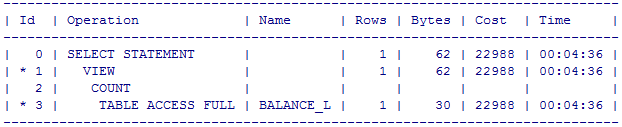
优化: rownum 放在外层。
SQL> select t.*,rownum from (select t.companycode, t.eid, t.eitime from newsadmin.balance_l t where t.eisdel ='4') t where t.eid=120000001555720986;

Predicate Information (identified by operation id):
------------------------------------------
* 1 - filter("T"."EISDEL"='4')
* 2 - access("T"."EID"=120000001555720986)
ROWNUM 放外层后, t.eid=120000001555720986 的条件成功带入里层进行过滤,并且使用到索引,性能高效。
有主键,count(主键)比count(1)快;
无主键,count(1)比count(列名)快;
表有多个列且无主键,count(1)优于count(*);
表只有一个字段,count(*)最优;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号