Spring MVC源码分析
Servlet解析
Servlet是Server + Applet的缩写,表示一个服务器应用。(Servlet其实就是一套规范,我们按照这套规范写的代码就可以直接在Java的服务器上面运行。)
0. Servlet 3.1 中的Servlet结构图

1. Servlet接口

针对Servlet接口内的抽象方法,我们先看一段配置文件再做详细分析:

init方法:
在容器启动时被容器调用(当load-on-startup设置为负数或者不设置时会在Servlet第一次用到时才被调用),而且只会调用一次;
init方法被调用时会接收到一个ServletConfig类型的参数,是容器传进去的。而如上图中通过init-param标签配置的参数就是通过ServletConfig来保存的。
getServletConfig方法:
用于获取ServletConfig。
service方法:
用于具体处理一个请求。
getServletInfo方法:
用于获取一些servlet相关的信息,如作者、版权等,这个方法需要自己实现,默认返回空字符串。
destroy方法:
主要用于在Servlet销毁(一般指关闭服务器)时释放一些资源,也只会调用一次。
注:
- Tomcat中Servlet的init方法是在org.apache.catalina.core.StandardWrapper的initServlet方法中调用的,ServletConfig传入的是StandardWrapper(里面封装着Servlet)自身的门面类StandardWrapperFacade。
- Servlet是通过xml文件配置的,在解析xml时就会把配置参数给设置进去,这样StandardWrapper本身就包含配置项了,当然,并不是StandardWrapper的所有的内容都是Config相关的,所以就用了其门面Facade类。
2. ServletConfig接口

getServletName方法:
用于获取Servlet的名字,也就是在web.xml中定义的servlet-name。
getServletContext方法:
该方法非常重要,它的返回值ServletContext代表的是我们这个应用本身,回顾上面针对Tomcat中init方法调用的分析,你应该会想到,ServletContext其实就是Tomcat中Context的门面类ApplicationContextFacade。
既然ServletContext代表应用本身,那么ServletContext里面设置的参数就可以被当前应用的所有Servlet共享了。
我们做项目的时候都知道参数可以保存在Session中,也可以保存在Application中,而后者很多时候就是保存在ServletContext中。
getInitParameter方法:
用于获取init-param配置的参数。
getInitParameterNames方法:
用于获取配置的所有init-param的名字集合。
注:
- ServletConfig是Servlet级的,而ServletContext是Context(也就是Application)级的。
- ServletContext的功能要强大的多,并不只是保存一下配置参数,否则就叫ServletContextConfig了。
- 上图中,通过context-param配置的contextConfigLocation配置到了ServletContext中,而通过servlet下的init-param配置的contextConfigLocation配置到了ServletConfig中。在Servlet中可以分别通过它们的getInitParameter方法进行获取。
-
String contextLocation = getServletConfig().getServletContext().getInitParameter("contextConfigLocation")
-
String servletLocation = getServletConfig().getInitParameter("contextConfigLocation")
当然,为了操作方便,GenericServlet定义了getInitParameter方法,内部返回getServletConfig().getInitParameter的返回值,因此,我们如果需要获取ServletConfig中的参数,可以不再调用getServletConfig(),而直接调用getInitParameter。
getServletContext().setAttribute("contextConfigLocation", "new path")
补充:
Q: Servlet级和Context级都可以操作,那有没有更高一层的站点级,也就是Tomcat中的Host级的相应操作呢?
A: 在Servlet的标准里其实还真有,在ServletContext接口中有这么一个方法:public ServletContext getContext(String uripath), 它可以根据路径获取到同一个站点下的别的应用的ServletContext。当然,由于处于安全的原因,一般会返回null,如果想使用需要进行一些设置。
3. GenericServlet


如上图所示,GenericServlet是Servlet的默认实现,主要做了三件事:
1)实现了ServletConfig接口(我们可以直接调用ServletConfig里面的方法)


GenericServlet提供了两个log方法,一个记录日志,一个记录异常。具体实现是通过传给ServletContext的日志实现的。

注:
一般我们都有自己的日志处理方式,所以log这个方法用得不是很多。
GenericServlet是与具体协议无关的。
4. HttpServlet


HttpServlet是用HTTP协议实现的Servlet的基类,写Servlet时直接继承它就可以了,不需要再从头实现Servlet接口,而Spring MVC的DispatcherServlet就是继承的HttpServlet。
既然HttpServlet是和协议相关的,当然主要关心的就是如何处理请求了——> HttpServlet主要是重写了service方法。

protected void service(HttpServletRequest req, HttpServletResponse res) throws ServletException, IOException源码:
-
protected void service(HttpServletRequest req, HttpServletResponse resp)
-
throws ServletException, IOException
-
{
-
String method = req.getMethod();
-
-
if (method.equals(METHOD_GET)) {
-
long lastModified = getLastModified(req);
-
if (lastModified == -1) {
-
// servlet doesn't support if-modified-since, no reason
-
// to go through further expensive logic
-
doGet(req, resp);
-
} else {
-
long ifModifiedSince = req.getDateHeader(HEADER_IFMODSINCE);
-
if (ifModifiedSince < lastModified) {
-
// If the servlet mod time is later, call doGet()
-
// Round down to the nearest second for a proper compare
-
// A ifModifiedSince of -1 will always be less
-
maybeSetLastModified(resp, lastModified);
-
doGet(req, resp);
-
} else {
-
resp.setStatus(HttpServletResponse.SC_NOT_MODIFIED);
-
}
-
}
-
-
} else if (method.equals(METHOD_HEAD)) {
-
long lastModified = getLastModified(req);
-
maybeSetLastModified(resp, lastModified);
-
doHead(req, resp);
-
-
} else if (method.equals(METHOD_POST)) {
-
doPost(req, resp);
-
-
} else if (method.equals(METHOD_PUT)) {
-
doPut(req, resp);
-
-
} else if (method.equals(METHOD_DELETE)) {
-
doDelete(req, resp);
-
-
} else if (method.equals(METHOD_OPTIONS)) {
-
doOptions(req,resp);
-
-
} else if (method.equals(METHOD_TRACE)) {
-
doTrace(req,resp);
-
-
} else {
-
//
-
// Note that this means NO servlet supports whatever
-
// method was requested, anywhere on this server.
-
//
-
-
String errMsg = lStrings.getString("http.method_not_implemented");
-
Object[] errArgs = new Object[1];
-
errArgs[0] = method;
-
errMsg = MessageFormat.format(errMsg, errArgs);
-
-
resp.sendError(HttpServletResponse.SC_NOT_IMPLEMENTED, errMsg);
-
}
-
}
doGet方法:

注:
- doGet、doPost、doPut、doDelete方法都是模板方法,而且如果子类没有实现将抛出异常;
- 在调用doGet方法前还对是否过期做了检查,如果没有过期则直接返回304状态码使用缓存;
- doHead调用了doGet的请求,然后返回空body的Response;
- doOptionos和doTrace正常不需要使用,主要是用来做一些调试工作,doOptions返回所有支持的处理类型的集合,正常情况下可以禁用,doTrace是用来远程诊断服务器的,它会将接收到的header原封不动地返回,这种做法很可能会被黑客利用,存在安全漏洞,所以如果不是必须使用,最好禁用;
- HttpServlet对doOptions和doTrace做了默认实现。
Summary
1 了解Servlet的类层级关系(Servlet, ServletConfig, GenericServlet, HttpServlet)
2 HttpServlet主要是将不同的请求方法路由到不同的处理方法。
3 Spring MVC的处理思路则不一样,又将所有请求合并到了统一的一个方法进行处理。
好了,Servlet详解到此为止。如果想做更深入的学习,可以自己开发源码学习!
Spring MVC源码分析—Servlet解析_spring.mvc.servlet.path-CSDN博客
Tomcat分析
1. Tomcat的顶层结构
1)Tomcat中最顶层的容器是Server(一个Tomcat中只有一个Server),代表整个服务器。
2)Server中包含至少一个Service,用于具体提供服务。
3)Service主要包括两部分:Connector和Container。一个Service只有一个Container,但可以有多个Connector。
4)Connector用于处理连接相关的事情,并提供Socket与request、response的转换。
5)Container用于封装和管理Servlet,以及具体处理request请求。
6)Tomcat里的Server有org.apache.catalina.startup.Catalina来管理,Catalina是整个Tomcat的管理类,它里面的三个方法load、start、stop分别用来管理整个服务器的声明周期。
注:
1)Tomcat内部设计load、start、stop都会按容器的结构逐层调用相应的方法。(比如,Server的start方法会调用所有Service的start方法,Service中的start方法又会调用所有包含的Connector和Container的start方法,这样整个服务器就启动了,init和stop方法也一样。)
2)Tomcat启动,依次调用顺序为:Bootstrap ——> Catalina ——> Server ——> Service
2. Tomcat的声明周期
Key Point:
1) Tomcat通过org.apache.catalina.Lifecycle接口统一管理生命周期,所有生命周期的组件都要实现Lifecycle接口
2)Lifecycle的默认实现是org.apache.catalina.util.LifecycleBase,所有实现了生命周期的组件都直接或间接地继承自LifecycleBase
3. Container
3.1 Container结构图
3.2 Container简介
1)Container一共有4个子接口Engine、Host、Context、Wrapper和一个默认实现类ContainerBase。
2)每个子接口都是一个容器,这4个子容器都有一个对应的StandardXXX实现类,并且这些实现类都继承ContainerBase类。
3)Engine、Host、Context、Wrapper这4个子容器都符合Tomcat生命周期管理模式。
4)Engine是最顶层,每个Service最多只能有一个Engine,一个Engine可以有多个Host,每个Host下可以有多个Context,每个Context下可以有多个Wrapper,他们的装配关系如下所示:
4个容器的作用:
Engine:引擎,用来管理多个站点,一个Service最多只能有一个Engine
Host:代表一个站点,也可以叫虚拟主机,通过配置Host就可以添加站点
Context:代表一个应用程序,对应着平时开发的一套程序,或者一个WEB-INF目录以及下面的web.xml文件
Wrapper:每个Wrapper封装着一个Servlet
3.3 子容器配置方法
1)Engine和Host的配置都在conf/server.xml文件中,server.xml文件是Tomcat中最重要的配置文件,Tomcat的大部分功能都可以在这个文件中配置。
2)Context有三种配置方法:
- a) 通过文件配置
- b) 将war应用直接放到Host目录下,Tomcat会自动查找并添加到Host中
- c) 将应用的文件夹放到Host目录下,Tomcat也会自动查找并添加到Host中
3)Wrapper的配置就是我们在web.xml中配置的Servlet,一个Servlet对应一个Wrapper
注:
同一个Service下的所有站点由于是共享Connector,所以监听的端口都一样。
如果想要添加监听不同端口的站点,可以通过不同的Service来配置。
4. Pipeline-Value管道
Pipeline-Value处理模式:
Pipeline-Value的管道模式有些类似于责任链模式,但和普通的责任链模式稍有不同:
- a) 每个Pipeline都有特定的Value,而且是在管道的最后一个执行,这个Value叫BaseValue,是不可删除的。
- b) 在上层容器的管道的BaseValue中会调用下层容器的管道。
4个容器的BaseValue分别是:
StandardEngineBalue、StandardHostValue、StandardContextValue、StandardWrapperValue
Pipeline处理流程:

5. Connector
Connector用于接收请求并将请求封装成Request和Response来具体处理,最底层是使用Socket来进行连接的,Request和Response是按照HTTP协议来封装的,所以Connector同时实现了TCP/IP协议和HTTP协议,Request和Response封装完之后交给Container进行处理,Container就是Servlet的容器,Container处理完之后返回给Connector,最后Connector使用Socket将处理结果返回给客户端,这样整个请求就处理完了。
5.1 Connector结构关系图
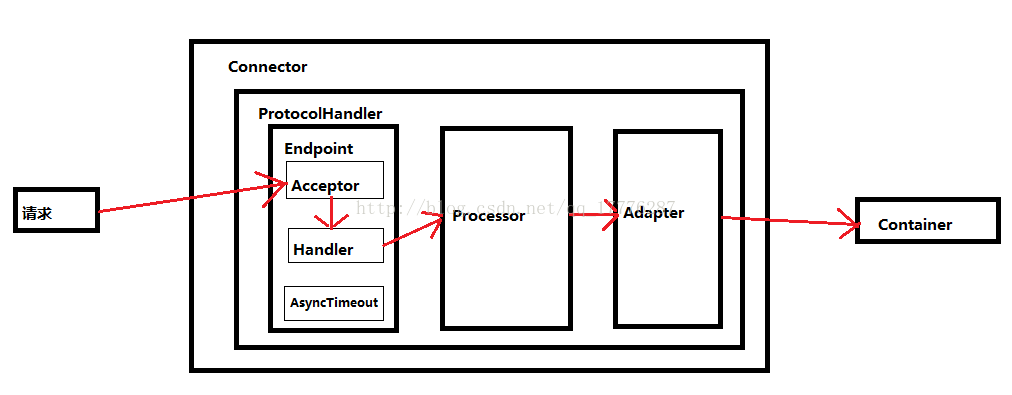
1)Connector中具体是用ProtocolHandler来处理请求的。
2)ProtocolHandler有3个非常重要的组件:Endpoint、Processor和Adapter。
- Endpoint::用于处理底层Socket的网络连接(用来实现TCP/IP协议)
- Processor:用于将Endpoint接收到的Socket封装成Request(用来实现HTTP协议)
- Adapter:用于将封装好的Request交给Container进行具体处理(将请求适配到Servlet容器进行具体处理)
- Acceptor用于监听请求
- AsyncTimeout用于检查异步request的超时
- Handler用于处理接收到的Socket,在内部调用了Processor进行处理
自己实现网络通讯
1.1 普通Socket用法
Java中的网络通讯是通过Socket实现的,Socket分为ServerSocket和Socket两大类,ServerSocket用于服务端,可以通过accept方法监听请求,监听到请求后返回Socket,Socket用于具体完整数据传输,客户端直接使用Socket发起请求并传输数据。
1.1.1 ServerSocket
ServerSocket的使用分为三步:
- 创建ServerSocket。
- 调用创建出来的ServerSocket的accept方法进行监听。
- 使用accept方法返回的Socket与客户端进行通信。
-
package com.jangz.deepinspringmvc.socket;
-
-
import java.io.BufferedReader;
-
import java.io.IOException;
-
import java.io.InputStreamReader;
-
import java.io.PrintWriter;
-
import java.net.ServerSocket;
-
import java.net.Socket;
-
-
public class Server {
-
-
public static void main(String[] args) {
-
ServerSocket server;
-
try {
-
server = new ServerSocket(8080);
-
Socket socket = server.accept();
-
-
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
-
String line = in.readLine();
-
System.out.println("received from client: " + line);
-
-
PrintWriter out = new PrintWriter(socket.getOutputStream());
-
out.write("received data: " + line);
-
-
out.flush();
-
out.close();
-
in.close();
-
socket.close();
-
server.close();
-
} catch (IOException e) {
-
e.printStackTrace();
-
}
-
-
}
-
-
}
1.1.2 客户端Socket
-
package com.jangz.deepinspringmvc.socket;
-
-
import java.io.BufferedReader;
-
import java.io.IOException;
-
import java.io.InputStreamReader;
-
import java.io.PrintWriter;
-
import java.net.Socket;
-
import java.net.UnknownHostException;
-
-
public class Client {
-
-
public static void main(String[] args) {
-
String msg = "Hello, server!";
-
try {
-
Socket socket = new Socket("127.0.0.1", 8080);
-
-
PrintWriter writer = new PrintWriter(socket.getOutputStream());
-
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
-
-
writer.println(msg);
-
writer.flush();
-
-
String line = reader.readLine();
-
System.out.println("received from server: " + line);
-
-
writer.close();
-
reader.close();
-
socket.close();
-
} catch (UnknownHostException e) {
-
e.printStackTrace();
-
} catch (IOException e) {
-
e.printStackTrace();
-
}
-
}
-
-
}
先启动Server,然后启动Client就可以完成一次通信。
实现效果如下:
1.1.3 NioSocket的用法
从JDK1.4开始,Java增加了新的io模式——nio(new IO),nio在底层采用了新的处理方式,极大地提高了IO的效率。我们使用的Socket也属于IO的一种,nio提供了相应的工具:ServerSocketChannel和SocketChannel,它们分别对应原来的ServerSocket和Socket。
NioSocket三个概念:Buffer、Channel和Selector。
针对NioSocket的处理模式:Buffer就是所要送的货物,Channel就是送货员(或者开往某个区域的配货车),Selector就是中转站的分拣员。
NioSocket中服务端的处理过程可以分为5步:
- 创建ServerSocketChannel并设置相应参数
- 创建Selector并注册到ServerSocketChannel上
- 调用Selector的select方法等待请求
- Selector接收到请求后使用selectedKeys返回SelectionKey集合
- 使用SelectionKey获取到Channel、Selector和操作类型并进行具体操作
NioServer代码实现:
-
package com.jangz.deepinspringmvc.socket;
-
-
import java.io.IOException;
-
import java.net.InetSocketAddress;
-
import java.nio.ByteBuffer;
-
import java.nio.channels.SelectionKey;
-
import java.nio.channels.Selector;
-
import java.nio.channels.ServerSocketChannel;
-
import java.nio.channels.SocketChannel;
-
import java.nio.charset.Charset;
-
import java.util.Iterator;
-
-
public class NIOServer {
-
-
public static void main(String[] args) {
-
try {
-
ServerSocketChannel channel = ServerSocketChannel.open();
-
channel.socket().bind(new InetSocketAddress(8080));
-
channel.configureBlocking(false);
-
-
Selector selector = Selector.open();
-
channel.register(selector, SelectionKey.OP_ACCEPT);
-
// 创建处理器
-
Handler handler = new Handler(1024);
-
while (true) {
-
if (selector.select(3000) == 0) {
-
System.out.println("等待请求超时......");
-
continue;
-
}
-
-
System.out.println("处理请求......");
-
Iterator<SelectionKey> keyIter = selector.selectedKeys().iterator();
-
-
while (keyIter.hasNext()) {
-
SelectionKey key = keyIter.next();
-
-
try {
-
if (key.isAcceptable()) {
-
handler.handleAccept(key);
-
}
-
if (key.isReadable()) {
-
handler.handleRead(key);
-
}
-
} catch (IOException ex) {
-
keyIter.remove();
-
continue;
-
}
-
keyIter.remove();
-
}
-
}
-
} catch (IOException e) {
-
e.printStackTrace();
-
}
-
}
-
-
private static class Handler {
-
private int bufferSize = 1024;
-
private String localCharset = "UTF-8";
-
-
public Handler() {
-
}
-
-
public Handler(int bufferSize) {
-
this(bufferSize, null);
-
}
-
-
public Handler(String localCharset) {
-
this(-1, localCharset);
-
}
-
-
public Handler(int bufferSize, String localCharset) {
-
if (bufferSize > 0) {
-
this.bufferSize = bufferSize;
-
}
-
if (localCharset != null) {
-
this.localCharset = localCharset;
-
}
-
}
-
-
public void handleAccept(SelectionKey key) throws IOException {
-
SocketChannel channel = ((ServerSocketChannel) key.channel()).accept();
-
channel.configureBlocking(false);
-
channel.register(key.selector(), SelectionKey.OP_READ, ByteBuffer.allocate(bufferSize));
-
}
-
-
public void handleRead(SelectionKey key) throws IOException {
-
SocketChannel channel = (SocketChannel) key.channel();
-
ByteBuffer buffer = (ByteBuffer) key.attachment();
-
buffer.clear();
-
-
if (channel.read(buffer) == -1) {
-
channel.close();
-
} else {
-
buffer.flip();
-
String receivedStr = Charset.forName(localCharset).newDecoder().decode(buffer).toString();
-
System.out.println("received frm client: " + receivedStr);
-
-
String respStr = "received data: " + receivedStr;
-
buffer = ByteBuffer.wrap(respStr.getBytes(localCharset));
-
channel.write(buffer);
-
channel.close();
-
}
-
}
-
}
-
}
自己动手实现HTTP协议
我们知道HTTP协议是应用层解析内容的,只需要按照它的报文的格式封装和解析数据就可以了,具体的传输还是使用的Socket。
因为HTTP协议是在接收到数据之后才会用到的,所以我们只需要修改NioServer中的Handler就可以了,在修改后的HttpServer中首先获取到请求报文并打印出报文的头部(包含首行)、请求的方法类型、Url和Http版本,最后将接收到的请求报文信息封装到响应报文的主体中返回给客户端。这里的HttpHandler使用了单独的线程来执行,而且把SelectionKey中操作类型的选择也放在了HttpHandler中,不过具体处理过程和前面的NioServer没有太大区别。
代码实现:
-
package com.jangz.deepinspringmvc.http;
-
-
import java.io.IOException;
-
import java.net.InetSocketAddress;
-
import java.nio.ByteBuffer;
-
import java.nio.channels.SelectionKey;
-
import java.nio.channels.Selector;
-
import java.nio.channels.ServerSocketChannel;
-
import java.nio.channels.SocketChannel;
-
import java.nio.charset.Charset;
-
import java.util.Iterator;
-
-
public class HttpServer {
-
-
public static void main(String[] args) {
-
try {
-
ServerSocketChannel channel = ServerSocketChannel.open();
-
channel.socket().bind(new InetSocketAddress(80));
-
channel.configureBlocking(false);
-
-
Selector selector = Selector.open();
-
channel.register(selector, SelectionKey.OP_ACCEPT);
-
// 创建处理器
-
while (true) {
-
if (selector.select(3000) == 0) {
-
continue;
-
}
-
// 获取待处理的SelectionKey
-
Iterator<SelectionKey> keyIter = selector.selectedKeys().iterator();
-
while (keyIter.hasNext()) {
-
SelectionKey key = keyIter.next();
-
new Thread(new HttpHandler(key)).start();
-
// 处理完成后,从待处理的SelectionKey迭代器中移除当前所使用的key
-
keyIter.remove();
-
}
-
}
-
} catch (IOException e) {
-
e.printStackTrace();
-
}
-
}
-
-
private static class HttpHandler implements Runnable {
-
private int bufferSize = 1024;
-
private String localCharset = "UTF-8";
-
private SelectionKey key;
-
-
public HttpHandler(SelectionKey key) {
-
super();
-
this.key = key;
-
}
-
-
public void handleAccept() throws IOException {
-
SocketChannel clientChannel = ((ServerSocketChannel) key.channel()).accept();
-
clientChannel.configureBlocking(false);
-
clientChannel.register(key.selector(), SelectionKey.OP_READ, ByteBuffer.allocate(bufferSize));
-
}
-
-
public void handleRead() throws IOException {
-
// 获取channel
-
SocketChannel socketChannel = (SocketChannel) key.channel();
-
// 获取buffer并重置
-
ByteBuffer buffer = (ByteBuffer) key.attachment();
-
buffer.clear();
-
-
// 没有读到内容则关闭
-
if (socketChannel.read(buffer) == -1) {
-
socketChannel.close();
-
} else {
-
// 接受请求数据
-
buffer.flip();
-
String receivedString = Charset.forName(localCharset).newDecoder().decode(buffer).toString();
-
// 控制台打印请求报文头
-
String[] requestMessage = receivedString.split("\r\n");
-
for (String s : requestMessage) {
-
System.out.println(s);
-
// 遇到空行说明报文头已经打印完
-
if (s.isEmpty()) {
-
break;
-
}
-
}
-
-
// 控制台打印首行信息
-
String[] firstLine = requestMessage[0].split(" ");
-
System.out.println();
-
System.out.println("Method:\t" + firstLine[0]);
-
System.out.println("url:\t" + firstLine[1]);
-
System.out.println("HTTP Version:\t" + firstLine[2]);
-
System.out.println();
-
-
// 返回客户端
-
StringBuilder sendString = new StringBuilder();
-
sendString.append("HTTP/1.1 200 OK\r\n"); // 响应报文首行,200表示处理成功
-
sendString.append("Content-Type:text/html;charset=" + localCharset + "\r\n");
-
sendString.append("\r\n"); // 报文头结束后加一个空行
-
-
sendString.append("<html><head><title>显示报文</title></head><body>");
-
sendString.append("接收到请求报文是:<br/>");
-
for (String s : requestMessage) {
-
sendString.append(s + "<br/>");
-
}
-
sendString.append("</body></html>");
-
buffer = ByteBuffer.wrap(sendString.toString().getBytes(localCharset));
-
socketChannel.write(buffer);
-
socketChannel.close();
-
-
}
-
}
-
-
-
public void run() {
-
try {
-
// 接收到连接请求时
-
if (key.isAcceptable()) {
-
handleAccept();
-
}
-
if (key.isReadable()) {
-
handleRead();
-
}
-
} catch (IOException ex) {
-
ex.printStackTrace();
-
}
-
}
-
}
-
}
README.md
#### 启动代码后,在浏览器中输入http://localhost
GET /favicon.ico HTTP/1.1<br/>
Host: localhost<br/>
Connection: keep-alive<br/>
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36<br/>
Accept: image/webp,image/apng,image/*,*/*;q=0.8<br/>
Referer: http://localhost/<br/>
Accept-Encoding: gzip, deflate, br<br/>
Accept-Language: zh-CN,zh;q=0.8<br/>
<br/>
<br/>
Method: GET<br/>
url: /favicon.ico<br/>
HTTP Version: HTTP/1.1<br/>Spring MVC源码分析—网站架构及其演变过程_spring网站结构-CSDN博客
网站架构机器演变过程
1.1 软件的三大类型
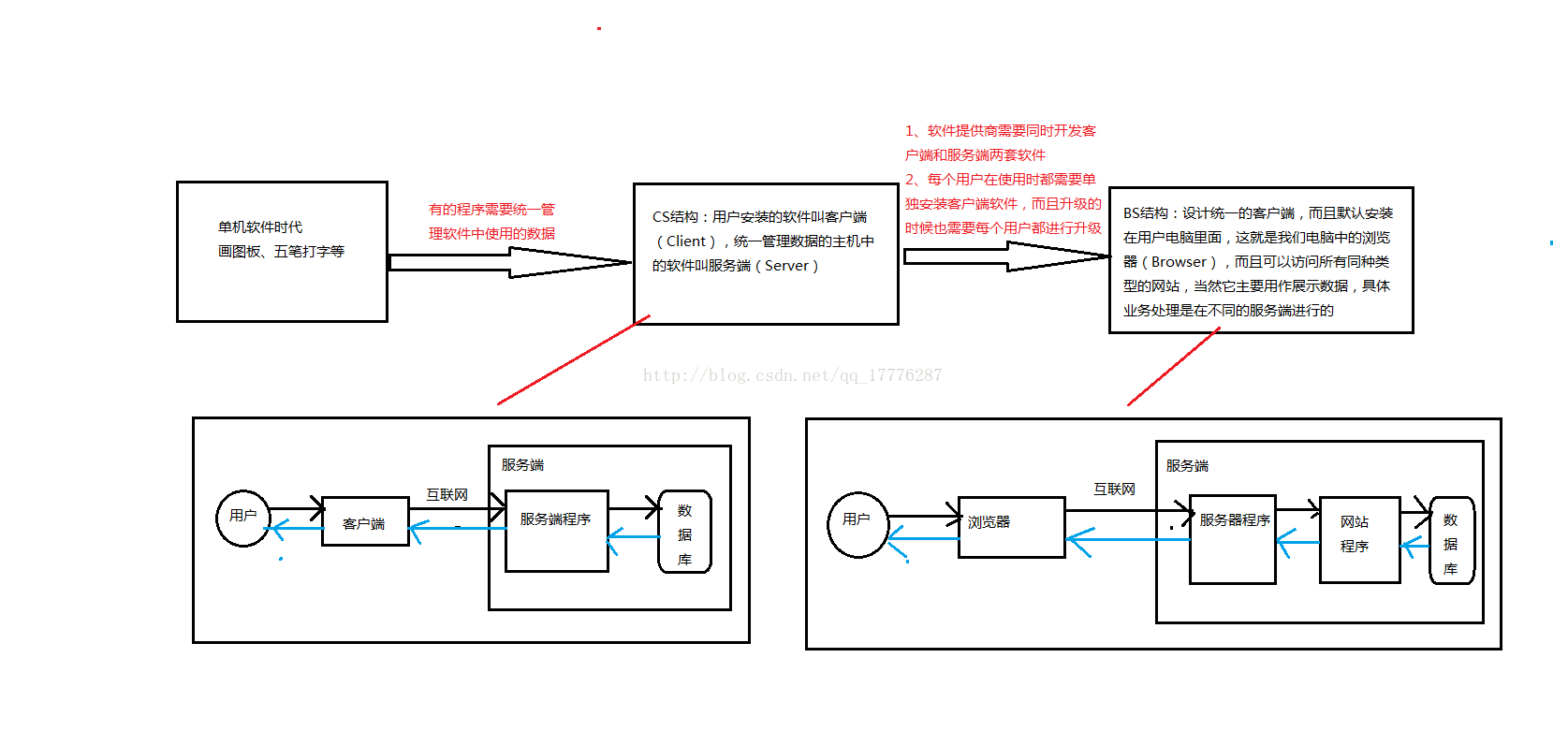
1.2 基础的结构并不简单
BS结构是最基础的结构,不过即使这种最基础的结构的底层实现也不简单,因为它需要通过互联网传输数据,而互联网是一个错综复杂的网络,其中包括的节点不计其数,而且每两个节点之间的距离以及连接的线路都是不确定的,数据在传输的过程中还可能会丢失,所以非常复杂。
所有问题都有它对治的方法,对于复杂问题的对治方法就是将其分解成多个简单的问题,然后通过解决每个简单的问题,最终解决复杂问题。BS结构网络传输的分解方式有两种:一种是标准的OSI参考模型,另一种是TCP/IP参考模型。它们的分层方式及对应关系如图所示:
OSI参考模型一共分7层,不过它主要用户教学,实际使用中更多的是TCP/IP的4层模型。对于TCP/IP的4层模型可以简单地理解为:
- 网络接入层:将需要相互连接的节点接入网络中,从而为数据传输提供条件。
- 网际互连层:找到要传输数据的目标节点。
- 传输层:实际传输数据。
- 应用层:使用接受到的数据。
由于网络传输应用非常广泛,所以需要大家都遵守规矩,不过网络传输中的这些规矩并不是强制性的,所以不叫制度也不叫标准而叫协议,其实TCP/IP参考模型也可以看作一种协议。
BS结构中TCP/IP模型中的网络接入层没有相应协议,网际互连层是IP协议,传输层是TCP协议,应用层是HTTP协议。
1.3 架构演变的起点
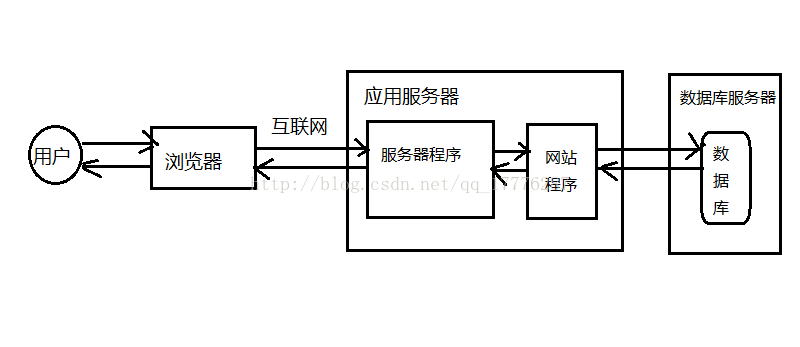
基础结构中服务端就一台主机,其中存储了应用程序和数据库,刚上线时时没有问题的,当数据和流量变得越来越大的时候就难以应付了,这时候就需要将应用程序和数据库分别放到不同的主机上,如图所示:
1.4 海量数据的解决方案
1.4.1 缓存和页面静态化
数据量大这个问题最直接的解决方案就是使用缓存,缓存就是将从数据库中获取的结果暂时保存起来,在下次使用的时候无需重新到数据库中获取,这样可以大大降低数据库的压力。
缓存的使用方式可以分为通过程序直接保存到内存中和使用缓存框架两种方式。
程序直接操作主要是使用Map,尤其是ConcurrentHashMap。
常用的缓存框架:Ehcache、Memcache和Redis等。
缓存在使用过程中最重要的问题是什么时候创建缓存和缓存的失效机制(还有粗粒度失效和细粒度失效)。
页面静态化可以在程序中使用模版技术生成,如常用的Freemarker和Velocity都可以根据模版生成静态页面,
另外也可以使用缓存服务器在应用服务器的上一层缓存生成的页面,如可以使用Squid,另外Nginx也提供了相应的功能。
1.4.2 数据库优化
表结构优化、SQL语句优化、分区、分表、索引优化、使用存储过程代替直接操作
1.4.3 分离活跃数据
虽然有些数据总量非常大,但是活跃数据并不多,这种情况就可以将活跃数据单独保存起来,从而提高处理效率。
1.4.4 批量读取和延迟修改
批量读取和延迟修改的原理都是通过减少操作的次数来提高效率,如果使用得恰当,效率将会呈数量级提升。
1.4.5 读写分离
读写分离的本质是对数据库进行集群,这样就可以在高并发的情况下将数据库的操作分配到多个数据库服务器去处理,从而降低单台服务器的压力,不过由于数据库的特殊性——每台服务器所保存的数据都需要一致,所以数据同步就成了数据库集群中最核心的问题。
如果多台服务器都可以写数据,那么数据同步将变得非常复杂,所以一般情况下是将写操作交给专门的一台服务器处理,这台专门负责写的服务器叫做主服务器。
当主服务器写入(增删改)数据后,从底层同步到别的服务器(从服务器),读数据的时候到从服务器读取,从服务器可以有多台,这样就可以实现读写分离,并且将读请求分配到多个服务器处理。
主服务器向从服务器同步数据时,如果从服务器数据很多,那么可以让主服务器先向其中一部分从服务器同步数据,第一部分从服务器接收到数据后再向另外一部分同步。
注:主/从服务器以及数据同步过程,有些类似于HDFS内的NameNode和DataNode
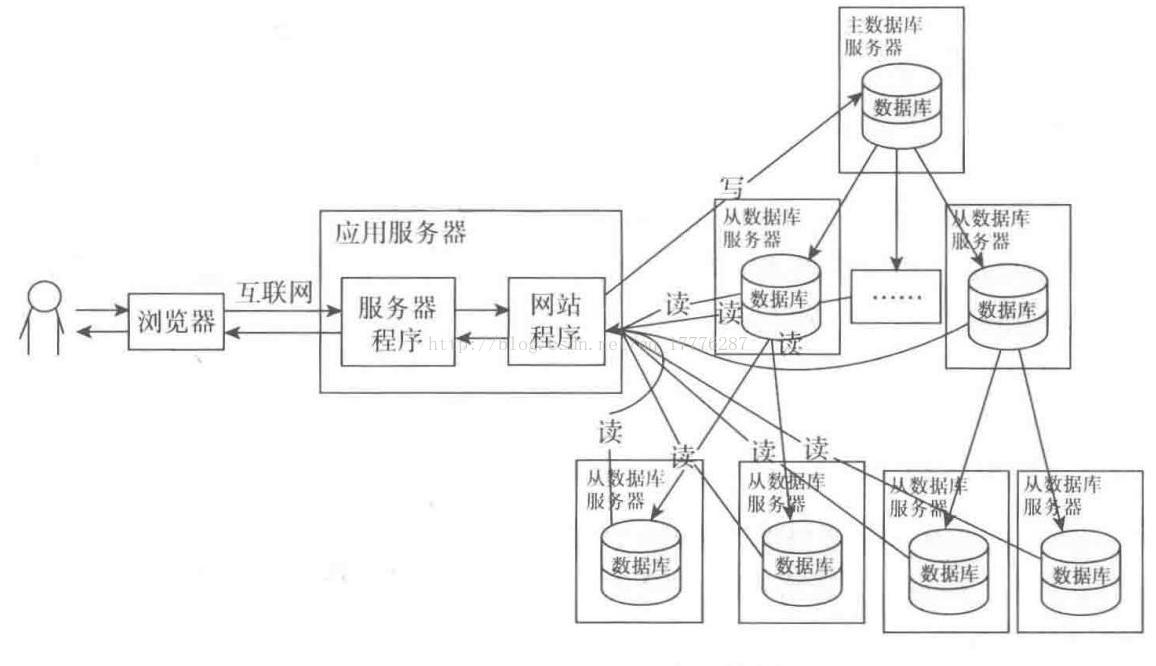
既然是集群,就会涉及到负载均衡问题,负载均衡和读写分离的操作一般采用专门程序处理,而且对应用系统来说是透明的。
1.4.6 分布式数据库
分布式数据库是将不同的表存放到不同的数据库中,然后再放到不同的服务器。这样在处理请求时,如果需要调用多个表,则可以让多台服务器同时处理,从而提高处理速度。
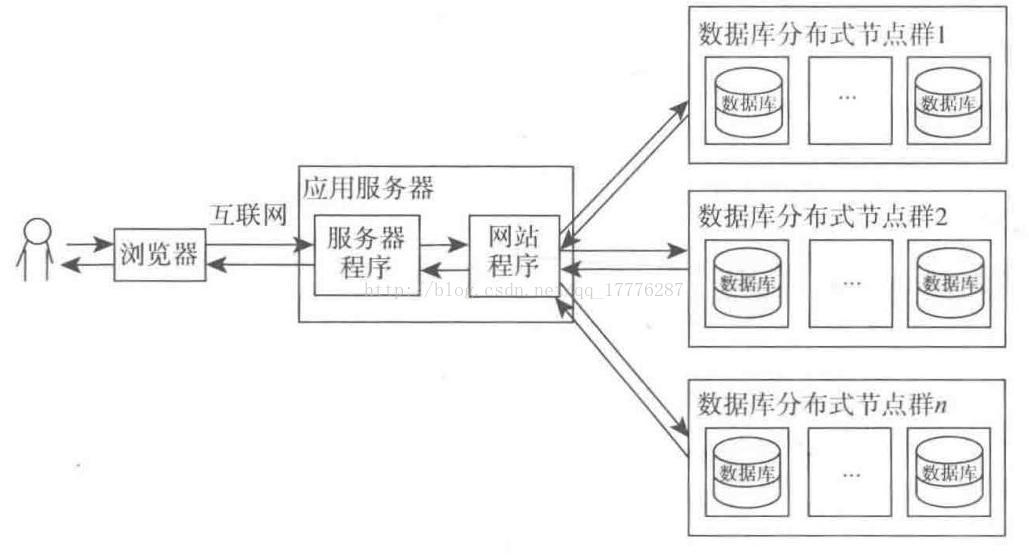
数据库集群的作用是将多个请求分配到不同的服务器处理,从而减轻单台服务器的压力。
分布式数据库是解决单个请求本身就非常复杂的问题,它可以将单个请求分配到多个服务器处理,使用分布式后的每个节点还可以同时使用读写分离,从而组成多个节点群。
1.4.7 NoSQL和Hadoop
因为NoSQL通过多个块存储数据的特点,其操作大数据的速度也非常快。
Hadoop对数据的处理是先对每一块的数据找到相应的节点并进行处理,然后再对每一个处理的结果进行处理,最后生成最终的结果。(Map-Reduce、分而治之的思想)
1.5 高并发的解决方案
除了数据量大,另一个常见的问题就是并发量高,很多架构就是针对这个问题设计出来的。
- 应用和静态资源分离:静态文件(图片、视频、JS、CSS等)放在专门的服务器上
- 页面缓存(Nginx服务器、Squid服务器)
- 集群和分布式
- 反向代理
反向代理指的是客户端直接访问的服务器并不真正提供服务,它从别的服务器获取资源,然后将结果返回给用户的。
反向代理服务器和代理服务器的区别:
- 代理服务器的作用是代我们获取想要的资源,然后将结果返回给我们,其中所要获取的资源是我们主动告诉代理服务器的。
- 反向代理服务器是我们正常访问一台服务器时,服务器自己调用了别的服务器的资源,并将结果返回给我们,我们自己并不知道。
- CDN
- 底层的优化:网络传输协议
Summary
1、网站架构的整个演变过程主要是围绕大数据和高并发这两个问题展开的,解决方案主要分为使用缓存和使用多资源两种方式。
2、要想设计出合理的架构,首先需要理解每种架构所针对的问题和它背后的本质,只有这样才能真正把架构用作解决问题的工具,而不是为了架构而架构,最后问题不一定能解决,还浪费了资源。
3、在使用复杂框架之前,一定要先将自己的业务优化好,这是基础中的基础,非常重要!
Spring MVC源码分析—常见协议和标准以及DNS设置-CSDN博客
常见协议与标准
1、DNS协议
DNS协议的作用是将域名解析为IP。域名和IP的对应关系不像电视频道那样稳定,而是经常在变化,所以就需要有专门将域名解析为IP的服务器,也就是“DNS服务器”,我们把域名发过去,它就可以给我们返回相应的IP,在windows下可以通过nslookup命令查看DNS解析的结果。
世界各地有很多DNS服务器,ISP会给我们提供默认的DNS服务器,也有一些大型公用的DNS服务器可以使用,比如Google的8.8.8.8和国内的114.114.114.114。我们直接访问的DNS服务器叫本地DNS服务器,它本身也没有域名和IP的对应关系,在我们发出请求的时候,它会从主DNS服务器获取,然后保存到缓存中,下次再有相同的域名请求时,直接从缓存中获取就可以了。
2、TCP/IP协议与Socket
TCP/IP协议通常放在一起来说,不过它们是两个不同的协议,所起的作用也不一样。
IP协议:用来查找地址的,对应着网际互联层;
TCP协议:用来规范传输规则的,对应着传输层。
IP只负责找到地址,具体传输的工作交给TCP来完成,这就像快递送货一样,货单上填写地址的规则以及怎么根据填写的内容找到客户,这就相当于IP协议,而送货时要先打电话,然后将货物送过去,最后客户签收时要签字等就相当于TCP协议。
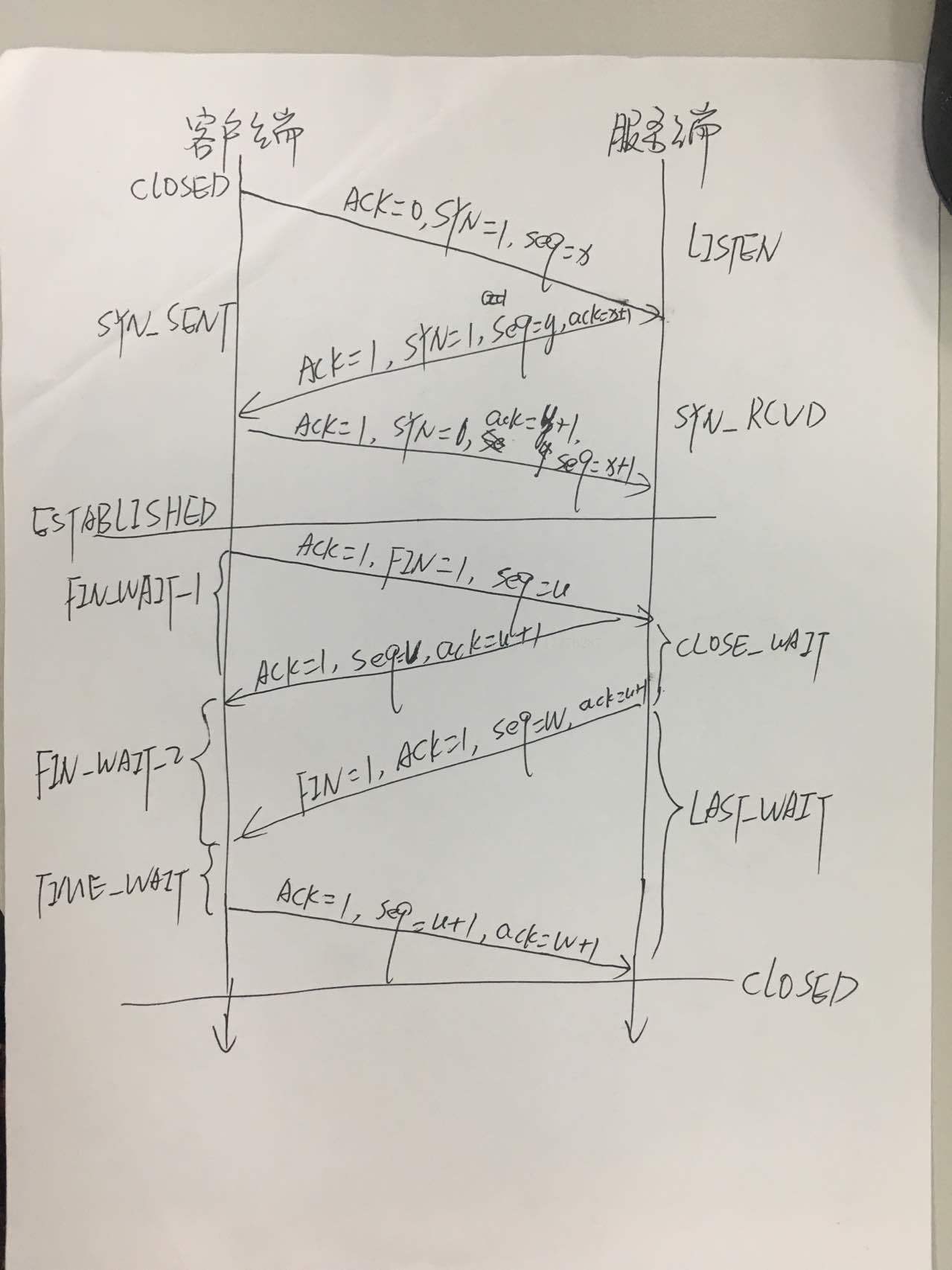
TCP在传输之前会进行三次沟通,一般称为“三次握手”;
传完数据断开时,要进行四次沟通,一般称为“四次挥手”。
为了理解这两个过程详情,我们需要先了解TCP的两个序号和三个标志位的含义:
两个序号:
- seq: sequence number的缩写,表示传输数据的序号。TCP传输时,每一个字节都有一个序号,发送数据时会将数据的第一个序号发送给对方,接收方会按序号检查是否接收完整了,如果没接收完整就需要重新传送,这样就可以保证数据的完整性;
- ack: acknowledgement number的缩写,表示确认号。接收端用它来给发送端反馈已经成功接收到的数据信息的,它的值为希望接收的下一个数据包起始序号,也就是ack值所代表的序号前面数据已经成功接收到了;
- ACK: 确认位,只有ACK=1的时候ack才起作用。正常通信时ACK为1,第一次发起请求时,因为没有需要确认接收的数据,所以此时的ACK为0;
- SYN: 同步位,用于在建立连接时同步序号。刚开始建立连接时,并没有历史接收的数据,所以ack也就没办法设置,这时也就没办法设置,这时按照正常的机制就无法运行了,SYN的作用就是解决这个问题的。当接收端接收到SYN=1的报文时就会直接将ack设置为接收到的seq+1的值,注意这里的值并不是校验后设置的,而是根据SYN直接设置的,这样正常的机制就可以运行了,所以,SYN叫同步位。需要注意的是,SYN会在前两次握手时都为1,这时因为通信的双方的ack都需要设置一个初始值。
- FIN: 终止位,用来在数据传输完毕后释放连接。
- TCP是有连接的,UDP是没有连接的;
- TCP协议传输的数据更可靠,UDP传输的速度更快;
- 视频传输、语音传输等对完整性要求不高而对传输速度要求高并且数据量大的通信使用UDP比较多;
- 邮件、网页等一般使用TCP协议。

- 1XX: 信息性状态码
- 2XX: 成功状态码,如200表示成功
- 3XX: 重定向状态码,如301表示重定向
- 4XX: 客户端错误状态码,如404表示没找到请求的资源
- 5XX: 服务端错误状态码,如500表示内部错误
把DNS地址写到网卡配置文件中:
- 打开网卡配置文件:/etc/sysconfig/network-scripts/ifcfg-eth0
- 添加DNS服务器地址到配置文件中:DNS1=192.168.137.1
- 重启网络服务:service network restart
- 再打开配置文件/etc/resov.conf我们会发现nameserver192.168.137.1被写了进来。
注:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号