PostgreSQL快速入门 & 与MySQL语法比较
在MySQL中,使用"= NULL"或"IS NULL"来检查NULL值
开篇
本文可帮助具有MySQL基础的小伙伴对PostgreSQL做一个快速的入门,通过语法之间的差异对比,降低学习成本,同样都是数据库,正所谓触类旁通。
模式的概念
模式(Schema)表示数据库中的逻辑容器,用于组织和管理数据库对象,如表、视图、索引等。一个模式可以看作是一组相关对象的命名空间。
模式不同于表,它更多地是对数据库对象进行逻辑分组和隔离的一种方式。一个模式可以包含多个表,每个表又可以属于不同的模式。通过使用模式,可以将相关的数据库对象组织在一起,提供更好的可管理性和安全性。
模式的主要作用有:
- 命名空间隔离:不同模式下的对象可以使用相同的名称,而不会发生冲突。例如,可以在模式A下创建一个名为"
users"的表,在模式B下也可以创建一个名为"users"的表,它们互不冲突。 - 访问控制:可以通过授权不同用户或角色对不同模式中的对象进行访问,从而实现更细粒度的权限控制。
- 代码组织:将相关的数据库对象组织在同一个模式下,便于维护、管理和查询。
和MySQL的语法差异
数据类型差异
整型
- MySQL中的TEXT数据类型最大存储容量为64KB,而PostgreSQL中的
TEXT数据类型没有此限制。 - MySQL中使用
TINYINT、MEDIUMINT和INT表示不同大小的整数,而PostgreSQL使用SMALLINT、INT和BIGINT。
浮点数类型
- MySQL 提供了 FLOAT 和 DOUBLE 类型来表示浮点数,可以指定精度。
- PostgreSQL 提供了 REAL 和 DOUBLE PRECISION 类型来表示浮点数。
字符串差异
- MySQL中可以使用
''或""来表示字符串,而PostgreSQL只接受''来表示字符串。 - PostgreSQL使用
E'…'来表示带有转义序列的字符串。 - 双引号在 PostgreSQL 中用于引用标识符(如表名、列名等),而不是字符串值。
- MySQL 使用
VARCHAR来表示可变长度的字符串,例如VARCHAR(255),
VARCHAR(n)最大只能是64kb。而postgresql中的VARCHAR(n) 最大可以存 1GB。
- PostgreSQL 使用
VARCHAR或TEXT来表示可变长度的字符串,postgresql中的TEXT相当于MySQL中的longtext。
数组类型
- MySQL 不直接支持数组类型,但可以使用逗号分隔的字符串来模拟数组。
- PostgreSQL 支持原生的数组类型,如
integer[]、varchar[]等。
字符串连接
- 在MySQL中,可以使用
"+"或CONCAT函数来连接字符串,而在PostgreSQL中,可以使用"||"来连接字符串。
-- 使用双竖线进行字符串连接
SELECT 'Hello' || ' ' || 'World'; -- 输出结果为 'Hello World'-- 使用 CONCAT 函数进行字符串连接
SELECT CONCAT('Hello', ' ', 'World'); -- 输出结果为 'Hello World'
-- 直接使用空格符号进行字符串连接
SELECT 'Hello' ' ' 'World'; -- 输出结果为 'Hello World'日期和时间函数差异
- MySQL使用
NOW()来获取当前日期时间,而PostgreSQL使用CURRENT_TIMESTAMP或CURRENT_DATE来获取。 - MySQL使用
DATE_ADD()、DATE_SUB()等函数来添加或减少日期时间,而PostgreSQL使用INTERVAL进行类似操作。
-- 在当前日期上添加3天
SELECT DATE_ADD(CURDATE(), INTERVAL 3 DAY);
-- 在当前日期上减去1周
SELECT DATE_SUB(CURDATE(), INTERVAL 1 WEEK);-- 在当前日期上添加3天
SELECT CURRENT_DATE + INTERVAL '3 day';
-- 在当前日期上减去1周
SELECT CURRENT_DATE - INTERVAL '1 week';limit子句的差异
- 在MySQL中,LIMIT子句用于限制结果集中返回的记录数,语法为
"LIMIT offset, count",offset为起始位置,count为返回记录数。 - 在PostgreSQL中,LIMIT子句用于限制结果集中返回的记录数,语法为
"LIMIT count OFFSET offset",count为返回记录数,offset为起始位置。 count表示要返回的记录数,offset 表示返回记录集开始的位置。如果省略 offset 参数,则默认从第一条记录开始。
举例:
SELECT name, score
FROM student
ORDER BY score DESC
LIMIT 5;SELECT name, score
FROM student
ORDER BY score DESC
LIMIT 5 OFFSET 3;
-- 跳过前3个记录,然后获取接下来的5个记录请注意,LIMIT 子句需要与 ORDER BY 子句一起使用来保证结果集的正确性。否则,返回的结果可能会是没有排序的任意行。
NULL值的处理
- 在MySQL中,使用"
IS NULL"来检查NULL值,使用"IS NOT NULL"来检查非NULL值。 - 在PostgreSQL中,使用"
IS NULL"来检查NULL值,使用"IS NOT NULL"来检查非NULL值。
自增主键列
- 在MySQL中,可以使用
AUTO_INCREMENT关键字将主键列设置为自增列。 - 在PostgreSQL中,可以使用
SERIAL或BIGSERIAL类型来创建自增主键列。
举例:
-- 使用 SERIAL 类型创建自增主键列
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100)
);
-- 使用 BIGSERIAL 类型创建自增主键列
CREATE TABLE products (
id BIGSERIAL PRIMARY KEY,
name VARCHAR(100),
price DECIMAL(10,2)
);注意:
使用 SERIAL 类型时,自增的主键列将存储 **4 字节大小的整数值,范围从 1 到 2,147,483,647。
而使用 BIGSERIAL 类型时,自增的主键列将存储 8 **字节大小的整数值,范围从 1 到 9,223,372,036,854,775,807。
无论使用 SERIAL 还是 BIGSERIAL 类型,都要将其指定为主键(PRIMARY KEY)以确保唯一性和索引优化。通过使用这些自增类型,可以方便地为表创建带有自动生成的唯一标识符的主键列。
变量和参数差异
- MySQL使用
@符号来声明和使用用户变量,使用?来作为占位符来传递参数。 - PostgreSQL使用冒号(
:)来声明和使用变量,使用$1、$2等占位符来传递参数。
-- 声明一个名为my_var的用户变量,并将其赋值为'Hello World'
SET @my_var := 'Hello World';
-- 打印变量的值
SELECT @my_var;
----------------------------------------------
-- 查询指定用户的信息,使用占位符传递参数
SELECT username, email
FROM users
WHERE id = ?;-- 声明一个名为my_var的变量,并将其赋值为'Hello World'
DO $$
DECLARE
my_var TEXT := 'Hello World';
BEGIN
-- 打印变量的值
RAISE NOTICE 'The value of my_var is: %', my_var;
END $$;
-----------------------------------------
-- 查询指定用户的信息,使用占位符传递参数
SELECT username, email
FROM users
WHERE id = $1;连接查询
- 在MySQL中,可以使用
JOIN、LEFT JOIN、RIGHT JOIN和INNER JOIN来进行不同类型的连接。 - 在PostgreSQL中,使用
JOIN来进行内连接,使用LEFT JOIN和RIGHT JOIN来进行左连接和右连接。
having语法差异
- 字符串比较:在 PostgreSQL 中,字符串比较是区分大小写的,默认情况下使用区分大小写的排序规则。而在 MySQL 中,字符串比较默认是不区分大小写的,可以使用 COLLATE 子句来指定不同的排序规则。
- 聚合函数的引用:在 PostgreSQL 中,HAVING 子句可以直接引用 SELECT 语句中定义的聚合函数,如
HAVING SUM(column) > 100。而在 MySQL 中,默认情况下不允许在 HAVING 子句中直接使用 SELECT 语句中定义的聚合函数结果,需要使用重复的聚合函数表达式,如HAVING SUM(column) > 100和HAVING SUM(column) > 200。 - NULL 值处理:在 PostgreSQL 中,HAVING 子句可以直接使用 NULL 进行比较,如
HAVING column IS NULL。而在 MySQL 中,需要使用特殊函数 IS NULL 或 IS NOT NULL 进行 NULL 值的比较,如HAVING IS NULL(column)。 - 在 PostgreSQL 中,不能直接在 HAVING 子句中使用 SELECT 语句中定义的列别名进行引用。而在 MySQL 中,默认情况下也不支持在 HAVING 子句中直接使用 SELECT 语句中的列别名。然而,从 MySQL 5.7+ 版本开始,已经开始支持使用列别名。
group by差异
- 在选择列表中的非聚合列:
- MySQL 允许在 GROUP BY 子句中不列出选择列表中的非聚合列,而且结果集将使用该组中的任意一个值。这可能会导致不可预测的结果。
- PostgreSQL 要求选择列表中的非聚合列要么包含在
GROUP BY子句中,要么在聚合函数中使用。否则,会引发错误。
- 聚合函数的处理
- MySQL 允许在 SELECT 语句中使用聚合函数,即使没有使用 GROUP BY 子句。这将导致对整个结果集进行聚合计算并返回单个结果。
- PostgreSQL 要求在使用聚合函数时必须使用 GROUP BY 子句,并按照指定的分组进行计算。
在MySQL中:
SELECT name, AVG(score) AS avg_score
FROM student
GROUP BY name;在postgreSQL中
SELECT name, AVG(score) AS avg_score
FROM student
GROUP BY name;
--- 报错!!!可以看到,MySQL 允许在 SELECT 子句中使用聚合函数,而 PostgreSQL 要求使用 GROUP BY 子句,并确保所有非聚合列都在GROUP BY子句中。
编码和排序方式
- 编码:
- PostgreSQL 提供了许多字符集和编码,其中包括
UTF-8、Latin1、WIN1251等。可以通过创建数据库时指定编码或者修改已有数据库的编码来设置。 - MySQL 也提供了多种字符集和编码,其中包括
UTF-8、GBK、GB2312等。可以通过创建数据库时指定字符集或者修改已有数据库的字符集来设置。
- PostgreSQL 提供了许多字符集和编码,其中包括
- 排序方式:
- PostgreSQL 的默认排序规则是由其设置的区域设置(locale)确定的,可以使用
LC_COLLATE环境变量或SET命令来更改。例如,如果使用以英文为基础的区域设置,则会在排序中将大写字母与小写字母一起处理。此外,PostgreSQL还支持自定义排序规则。 - MySQL 的默认排序规则是根据字符集而不是区域设置确定的。例如,在
utf8字符集下,MySQL 按照Unicode标准进行排序,因此对于不同语言的字符排序可能会有所不同。MySQL支持使用COLLATE关键字来指定排序规则。
- PostgreSQL 的默认排序规则是由其设置的区域设置(locale)确定的,可以使用
PostgreSQL中特有的
几何类型
包括点(point)、直线(line)、线段(lseg)、路径(path)、多边形(polygon)、圆(cycle)等类型。
PostgreSQL中特有的类型,其他数据库中一般没有此类型,可以认为是一种数据库内置的自定义类型。
CREATE TABLE places (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
location GEOMETRY(Point, 4326)
);
INSERT INTO places (name, location) VALUES ('Central Park', ST_GeomFromText('POINT(-73.968500 40.785800)', 4326));网络地址类型
有cidr、inet、macaddr 3种类型
PostgreSQL中特有的类型,其他数据库中一般没有此类型,可以认为是一种数据库内置的自定义类型。
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
ip_address INET
);
INSERT INTO users (name, ip_address) VALUES ('Alice', '192.168.0.1');数组类型
postgresql中可以直接存储一个数组,对应其他数据库中没有此类型。
可以在表中存储和操作多个数值或对象
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
prices INTEGER[]
);
INSERT INTO products (name, prices) VALUES ('Apple', ARRAY[10, 15, 20]);范围类型
range类型,可以存储范围数据,其他数据库中无此类型
用于表示一定范围内的数值或时间戳等数据。
CREATE TABLE events (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
event_time TSRANGE
);
INSERT INTO events (name, event_time) VALUES ('Meeting', '[2023-09-10 09:00, 2023-09-10 10:00]');对象标识符类型
PostgreSQL 具有特殊的对象标识符类型,用于存储和引用数据库对象的标识,如表、列、模式等。
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
order_number OID,
product_name VARCHAR(100)
);
INSERT INTO orders (order_number, product_name) VALUES ('163125', 'Computer');JSON类型
介绍
着重介绍一下该类型,因为经常会碰到postgresql中存储JSON数据。
-
JSON数据类型可以用来存储
JSON(JavaScript Object Notation)数据,而JSON数据格式是在RFC 4627中定义的。当然也可以使用text、varchar等类型来存储JSON数据,但使用这些通用的字符串格式 将无法自动检测字符串是否为合法的JSON数据。而且,JSON数据类型还可以使用丰富的函数。 -
JSON数据类型是从PostgreSQL 9.3版本开始提供的,在9.3版本中 只有一种类型JSON,在PostgreSQL 9.4版本中又提供了一种更高效的类型
JSONB,这两种类型在使用上几乎完全一致,两者主要区别是: -
JSON类型是把输入的数据原封不动地存放到数据库中(当然在存储前会做JSON的语法检查),使用时需要重新解析数据;
-
而JSONB类型是 在存储时就把JSON解析成二进制格式,使用时就无须再次解析,所以 JSONB在使用时性能会更高。
-
另外,JSONB支持在其上建索引,而 JSON则不支持,这是JSONB类型一个很大的优点。 因为JSON类型是把输入的整个字符串原封不改动地保存到数据库 中,因此JSON串中key之间多余的空格也会被保留下来。而且,如果JSON串中有重复的key,这些重复的key也会保留下来(默认处理时以最后一个为准),同时也会保留输入时JSON串中各个key的顺序。而 JSONB类型则恰恰相反,既不会保留多余的空格,也不会保留key的顺序和重复的key。
-
PostgreSQL中每个数据库只允许用一种服务器编码,如果数据库的编码不是UTF-8,PostgreSQL中的JSON类型是无法严格遵循JSON规范中对字符集的要求的。如果输入中包含无法在服务器编码中表示的字符数据,将无法导入数据库中。但是,能在服务器编码中表示的非 UTF-8字符则是被允许的。
-
可以使用
**\uXXXX**形式的转义,从而忽视数据库的字符集编码。 当把一个JSON类型的字符串转换成JSONB类型时,JSON字符串内的数据类型实际上被转换成了PostgreSQL数据库中的类型,两者的映射关系见下表。
需要注意的是,如果是在JSONB中,不能输入超出 PostgreSQL的numeric数据类型范围的值。
| JSON的类型 | PostgreSQL 类型 | 注意事项 |
|---|---|---|
| string | text | 注意字符集的一些限制 |
| number | numeric | JSON中没有PostgreSQL中的“NaN”和“infinity”值 |
| boolean | boolean | JSON仅能接受小写的“true”,和“false” |
| null | (none) | SQL中的NULL代表不同的意思 |
示例
存储JSON数据
-- 创建表
CREATE TABLE students (id SERIAL PRIMARY KEY, info JSONB);
-- 向表中插入 JSON 数据
INSERT INTO students (info)
VALUES ('{"name": "Alice", "age": 20, "major": "Computer Science"}'),
('{"name": "Bob", "age": 22, "major": "Mathematics"}');查找所有学生信息
SELECT info FROM students;查找特定属性的学生信息
SELECT info->>'name' AS name, info->>'age' AS age
FROM students
WHERE info->>'major' = 'Computer Science';这里解释一下箭头符号的使用:
- ->:箭头符号用于提取 JSONB 对象的字段值。例如,
properties->'rotation'表示从 JSONB 字段 “properties” 中提取键为 “rotation” 的子字段的值。 - ->>:双箭头符号用于提取 JSONB 对象的字段值,并将其转换为文本类型。例如,
properties->>'deviceIp'表示从 JSONB 字段 “properties” 中提取键为 “deviceIp” 的子字段的值,并将其作为字符串返回。 - 再看一个例子,这个例子将更加详细,能帮助你快速理解箭头的含义
CREATE TABLE products (
id INT,
details JSONB
);
INSERT INTO products (id, details) VALUES
(1, '{ "name": "iPhone", "price": 999, "specs": {"color": "silver", "storage": "64GB"}}'),
(2, '{ "name": "iPad", "price": 699, "specs": {"color": "gray", "storage": "128GB"}}'),
(3, '{ "name": "MacBook Pro", "price": 1999, "specs": {"color": "space gray", "storage": "256GB"}}');
-- 建好表后看一下数据
现在,我们想从 “details” 字段中提取商品的名称、价格和颜色作为查询结果的列。
SELECT
details -> 'name' AS NAME,
details -> 'price' AS price,
details -> 'specs' ->> 'color'
FROM
products区别如下:
- 单箭头 “->”:用于从 JSONB 对象中提取指定键的值。例如,“details->‘name’” 表示从 JSONB 字段 “details” 中提取键为 “name” 的子字段的值。
- 双箭头 “->>”:用于从 JSONB 对象中提取指定键的值,并将其作为文本类型返回。例如,“details->‘specs’->>‘color’” 表示从 JSONB 字段 “details” 中的 “specs” 子字段中提取键为 “color” 的值,并将其作为字符串返回。
- 单箭头符号 “->” 提取的是带有子字段的 JSONB 对象,而双箭头符号 “->>” 则提取的是子字段的具体值作为文本类型。
看我下面这个例子,上面的可能看起来难以理解,但是都是理论,接着看下实操: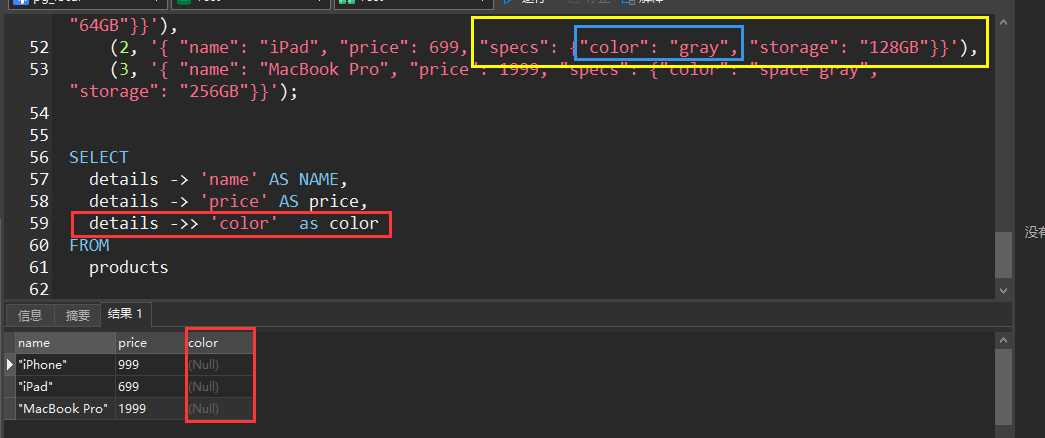
看我标注出来的地方,可以看到,如果是一个对象,直接用->>是取不出来的,直接为null了,虽然不会报错。
所以必须先拿到父级,再从中取出子字段。
以上代码分别从 JSONB 类型的字段中提取了特定的键值对,并将其作为查询结果的列。这种用法适用于 PostgreSQL 数据库中存储了 JSONB 类型数据的情况。
使用JSONB函数进行更为复杂的查询
SELECT info->>'name' AS name, info->>'age' AS age
FROM students
WHERE info @> '{"major": "Computer Science"}'
ORDER BY (info->>'age')::INTEGER;@> 运算符用于检查 JSON 对象包含某个特定键或值。
这里顺便补充一下这个@>的语法
@>的用法
@> 操作符是 PostgreSQL 中针对 JSON 数据类型的操作符之一,它表示“包含”。具体而言,它用来检查一个 JSON 对象是否包含另一个 JSON 对象中的所有键值对。
使用 @> 操作符时,需要提供两个参数。第一个参数是查询对象,通常是一个 JSONB 列名或者一个 JSON 字面量。**第二个参数是要匹配的对象,也通常是一个 JSON 字面量。**如果查询对象中包含第二个参数中所有的键值对,则返回 true,否则返回 false。
示例:
SELECT * FROM my_table WHERE my_column @> '{"name": "Alice"}'这一句sql会检查 my_column 列中的 JSONB 数据是否包含 { "name": "Alice" } 这个 JSON 对象中的所有键值对。如果匹配成功,则返回匹配行的所有内容。
在 JSON 值之间深度比较时,@> 操作符也可以与其他 JSON 操作符(如 ->, ->>, #>, #>> 等)结合使用,以实现更复杂的 JSON 查询。
#> 和 #>>
- #>:用于获取 JSONB 对象中指定键路径的值。
- 示例:
data #> '{key1, key2, key3}',其中 data 是一个 JSONB 列,'{key1, key2, key3}'是表示键路径的文本数组。 - 返回结果:如果存在指定的键路径,则返回路径最终键的值,否则返回 NULL。
- 示例:
- #>>:用于获取 JSONB 对象中指定键路径的文本值。
- 示例:
data #>> '{key1, key2, key3}',其中 data 是一个 JSONB 列,'{key1, key2, key3}'是表示键路径的文本数组。 - 返回结果:如果存在指定的键路径,并且路径最终键的值是文本类型,则返回该文本值,否则返回 NULL。
- 示例:
区别
- #> 操作符返回一个 JSONB 对象,表示指定键路径的子对象。
- #>> 操作符返回一个文本字符串,表示指定键路径的文本值。
SELECT data #> '{key1, key2}' AS sub_object
FROM my_table;
-- 这将返回 JSONB 列 data 中,键路径为 key1 -> key2 的子对象。SELECT data #>> '{key1, key2}' AS text_value
FROM my_table;
-- 这将返回 JSONB 列 data 中,键路径为 key1 -> key2 的文本值。总结
->和->>只能获取单个键的值或文本值,而#>和#>>可以获取嵌套键的值或文本值。->和#>使用相似的方式,都需要指定一个键或键路径来访问 JSONB 对象中的值。->>和#>>类似于->和#>,但返回的是文本值而不是原始 JSONB 值。
数据类型别名
为了提高SQL的兼容性,部分数据类型还有很多别名,如integer类型,可以用int、int4表示,smallint也可以用int2表示;char varying(n)可以用varchar(n)表示,numeric(m,n)也可以用decimal(m,n)表示,等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号