tk-mybatis和mybatisplus使用和区别
概念:
一.tk-mybatis的使用
1.tk-mybatis需要引入启动器,直接引入即可。
pom.xml中引入如下内容
<!-- 通用 mapper --><dependency><groupId> tk.mybatis </groupId><artifactId> mapper-spring-boot-starter </artifactId><version> 2.0.2 </version></depe
ndency>
2. 创建实体类
tk mybatis 实体类使用的注解是jpa注解 JPA注释详解参考手册
@Table ( name = "tb_user" )public class User implements Serializable {private static final long serialVersionUID = 1L ;@Id@GeneratedValue ( strategy = GenerationType . IDENTITY )private Long id ;// 用户名private String userName ;....
@Mapperpublic interface UserMapper extends tk . mybatis . mapper . common . Mapper < User > {public List < User > findByUser ( User user );}
如果有自定义的映射文件方法,就在接口中设置方法,然后配置对应的xml文件。
没有自定义的方法,此接口中不用写任何内容。
注意:此处的xml文件名称要和接口名称相同,xml中的id要与接口中的方法名称相同。
注意:如果使用mapperScan注解而不是Mapper要把MapperScan类改成tk-mybatis构件的类
例如:@MapperScan("com.lxs.demo.dao") 加到springBoot启动类Application上。
@MapperScan和@Mapper的区别就是 :后者是单个类接口的实现,前者是包扫描的接口的实现的。
此处是自定义的xml方法,通过判断name,和note不为null的情况下,进行对name,note的模糊查询。
-
-
-
<mapper namespace="com.lxs.demo.dao.UserMapper">
-
<select id="findByUser" resultType="user">
-
SELECT *FROM tb_user
-
<where>
-
<if test="name != null">
-
name like '%${name}%'
-
</if>
-
<if test="note != null">
-
and note like '%${note}%'
-
</if>
-
</where>
-
</select>
-
</mapper>
一旦继承了tk-mybatis Mapper,继承的Mapper就拥有了该Mapper所有的通用方法:
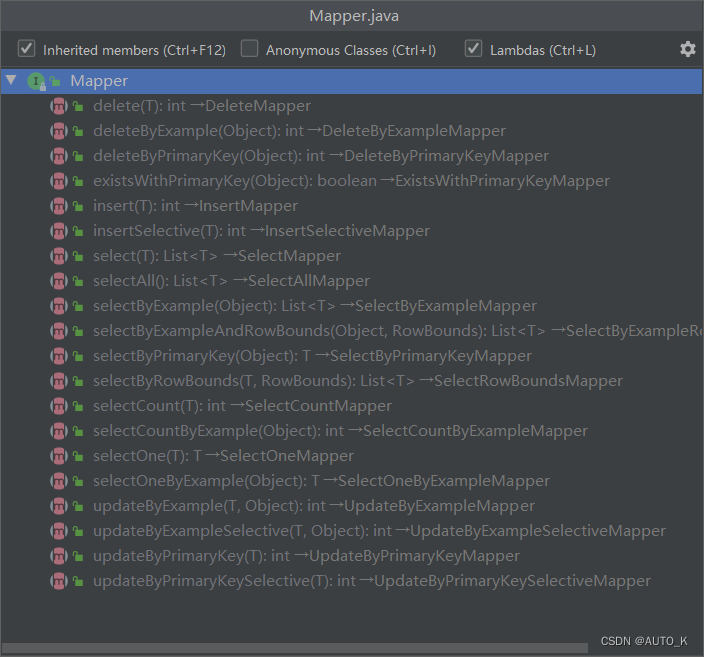
@RunWith(SpringRunner.class)@SpringBootTestpublic class UserDaoTest {@Autowiredprivate UserMapper userMapper;//自定义的方法测试@Testpublic void testFindByUser() {User user = new User();user.setName("a");List<User> list = userMapper.findByUser(user);for (User user : list) {System.out.println(user);}}@Testpublic void testFindAll() {List<User> list = userMapper.selectAll();for (User user : list) {System.out.println(user);}}@Testpublic void testFindById() {User user = userMapper.selectByPrimaryKey(4);System.out.println(user);}@Testpublic void testFindByExample() {Example example = new Example(User.class);example.createCriteria().andLike("name", "%a%");userMapper.selectByExample(example).forEach(user -> {System.out.println(user);});
二.mybatisplus的使用
1.引入mp的启动器。
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.3.2</version></dependency>
2.创建实体类
@Datapublic class User {private Long id;private String name;private Integer age;private String email;}
此处的@data注解是对实体类的get和set方法的简化,使用此注解可以省略get和set方法的创建。使用时候直接使用即可,需要引入lombok依赖和对应的插件,这里不再具体说明。
|
注解名称
|
说明
|
|
@TableName
|
实体类的类名和数据库表名不一致
|
|
@TableId
|
实体类中的成员名称和表中字段名称不一致> |
|
@TableField
|
排除实体类中非表字段
|
3.创建接口继承 BaseMapper
其实是mybatisplus包下的BaseMapper
com.baomidou.mybatisplus.core.mapper.BaseMapperpublic interface UserMapper extends BaseMapper<User> {}
4.测试
@RunWith(SpringRunner.class)@SpringBootTestpublic class SampleTest {@Resourceprivate UserMapper userMapper;@Testpublic void testSelect() {System.out.println(("----- selectAll method test ------"));List<User> userList = userMapper.selectList(null);Assert.assertEquals(6, userList.size());userList.forEach(System.out::println);}}
继承了 MP的 BaseMapper,继承的Mapper就拥有了BaseMapper所有的通用方法:
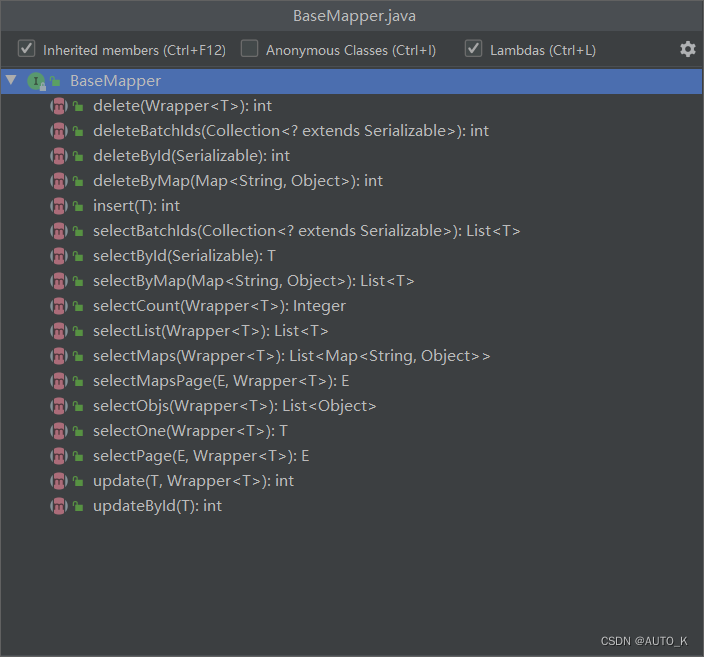
具体使用参考下面博文
gitee上的使用介绍:
mybatisplus:Mybatis-Plus
firstmybaits:firstmybaits
下面tk和mp的区别:
TKMybatis 和 MybatisPlus哪一个好用 - 代码先锋网
TkMybatis Vs MybatisPlus
1.基础CRUD BaseMapper
基本一样,只是方法名不一样,tk和MBG更贴切
2.代码生成器
Mybatis-Plus
通过 AutoGenerator 可以快速生成 Entity、Mapper、Mapper XML、Service、Controller 等各个模块的代码,极大的提升了开发效率。对原生的MBG进行了封装,更友好
Tk-Mybatis
代码生成器是基于 MBG 插件的,所以需要配合 MBG 使用。更贴近原生
3. 全局主键 Sequence主键
Mybatis-Plus
oracle等数据库主键策略配置Sequence
实体类配置主键Sequence,指定主键@TableId(type=IdType.INPUT)//不能使用AUTO
支持父类定义@KeySequence, 子类使用,这样就可以几个表共用一个Sequence
针对各种数据库的策略。
Tk-Mybatis
全局ID生成器 Vesta、UUID
两种策略是不太一样的。@KeySql(genId = UUIdGenId.class) ,Mapper 4.0.2
4. 热加载
Mybatis-Plus
3.0.6版本上移除了该功能,不过最新快照版已加回来并打上废弃标识,3.1.0版本上已完全移除
多数据源配置多个 MybatisMapperRefresh 启动 bean
默认情况下,eclipse保存会自动编译,idea需自己手动编译一次
-
/**
-
* 切莫用于生产环境(后果自负)
-
* <p>Mybatis 映射文件热加载(发生变动后自动重新加载).</p>
-
* <p>方便开发时使用,不用每次修改xml文件后都要去重启应用.</p>
-
*
-
* @author nieqiurong
-
* @since 2016-08-25
-
* @deprecated 2018-11-26
-
*/
哈哈哈哈
TK-Mybatis
不支持
5. 分页
Mybatis-Plus
分页插件
Tk.Mybatis
pagehelper
6. 额外功能
Mybatis-Plus
- 逻辑删除
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
- 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
- 内置性能分析插件:可输出 Sql 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
- 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
- 内置 Sql 注入剥离器:支持 Sql 注入剥离,有效预防 Sql 注入攻击
- 多数据源
Tk.Mybatis
- 乐观锁
- 支持分页 pagehelper
- 多数据源
一、MyBatis-Plus
1、简介
MyBatis-Plus 是一个 Mybatis 增强版工具,在 MyBatis 上扩充了其他功能没有改变其基本功能,为了简化开发提交效率而存在。
官网文档地址:
https://mp.baomidou.com/guide/
MyBatis-Plus 特性:
https://mp.baomidou.com/guide/#%E7%89%B9%E6%80%A7
2、使用 SpringBoot 快速使用 MyBatis-Plus
(1)准备工作
需要 Java 开发环境(JDK)以及相应的开发工具(IDE)。
需要 maven(用来下载相关依赖的 jar 包)。
需要 SpringBoot。
可以使用 IDEA 安装一个 mybatis-plus 插件。

(2)创建一个 SpringBoot 项目。
方式一:去官网 https://start.spring.io/ 初始化一个,然后导入 IDE 工具即可。
方式二:直接使用 IDE 工具创建一个。 Spring Initializer。


(3)添加 MyBatis-Plus 依赖(mybatis-plus-boot-starter)
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.1.tmp</version>
</dependency>
(4)为了测试开发,此处使用 mysql 8,需要引入 mysql 相关依赖。
为了简化代码,引入 lombok 依赖(减少 getter、setter 等方法)。

<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.18</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
</dependency>
(5)完整依赖文件(pom.xml)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.6.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.lyh.test</groupId>
<artifactId>test-mybatis-plus</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>test-mybatis-plus</name>
<description>测试 -- 测试 MyBatis-Plus 功能</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.1.tmp</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.18</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
(6)使用一个表进行测试。
仅供参考,可以定义 创建时间、修改时间等字段。
DROP DATABASE IF EXISTS testMyBatisPlus;
CREATE DATABASE testMyBatisPlus;
USE testMyBatisPlus;
DROP TABLE IF EXISTS user;
CREATE TABLE user
(
id BIGINT(20) NOT NULL COMMENT '主键ID',
name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',
age INT(11) NULL DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (id)
);
INSERT INTO user (id, name, age, email) VALUES
(1, 'Jone', 18, 'test1@baomidou.com'),
(2, 'Jack', 20, 'test2@baomidou.com'),
(3, 'Tom', 28, 'test3@baomidou.com'),
(4, 'Sandy', 21, 'test4@baomidou.com'),
(5, 'Billie', 24, 'test5@baomidou.com');

(7)在 application.yml 文件中配置 mysql 数据源信息。
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
url: jdbc:mysql://localhost:3306/testMyBatisPlus?useUnicode=true&characterEncoding=utf8

(8)编写表对应的 实体类。
package entity;
import lombok.Data;
@Data
public class User {
private Long id;
private String name;
private int age;
private String email;
}

(9)编写操作实体类的 Mapper 类。
直接继承 BaseMapper,这是 mybatis-plus 封装好的类。
package mapper;
import bean.User;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
public interface UserMapper extends BaseMapper<User> {
}


(10)实体类、Mapper 类都写好了,就可以使用了。
Step1:先得在启动类里扫描 Mapper 类,即添加 @MapperScan 注解
package com.lyh.test.testmybatisplus;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@MapperScan("mapper")
@SpringBootApplication
public class TestMybatisPlusApplication {
public static void main(String[] args) {
SpringApplication.run(TestMybatisPlusApplication.class, args);
}
}
Step2:写一个测试类测试一下。
package com.lyh.test.testmybatisplus;
import bean.User;
import mapper.UserMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
class TestMybatisPlusApplicationTests {
@Autowired
private UserMapper userMapper;
@Test
public void testSelect() {
System.out.println(("----- selectAll method test ------"));
List<User> userList = userMapper.selectList(null);
for(User user:userList) {
System.out.println(user);
}
}
}

(11)总结:
通过以上简单操作,就能对 user 表进行 CRUD 操作,不需要去编写 xml 文件。
注:
若遇到 @Autowired 标记的变量出现 红色下划线,但是不影响 正常运行。

可以进入 Settings,找到 Inspection,并选择其中的 Spring Core -> Code -> Autowiring for Bean Class,将 Error 改为 Warning,即可。
二、Mybatis-Plus 常用操作
1、配置日志
【参考地址(两种方式配置日志)】
https://blog.csdn.net/dfBeautifulLive/article/details/100700365
想要查看执行的 sql 语句,可以在 yml 文件中添加配置信息,如下。
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
如下图所示:执行时会打印出 sql 语句。

2、简单认识一下常用注解
【@TableName 】
@TableName 用于定义表名
注:
常用属性:
value 用于定义表名
【@TableId】
@TableId 用于定义表的主键
注:
常用属性:
value 用于定义主键字段名
type 用于定义主键类型(主键策略 IdType)
主键策略:
IdType.AUTO 主键自增,系统分配,不需要手动输入
IdType.NONE 未设置主键
IdType.INPUT 需要自己输入 主键值。
IdType.ASSIGN_ID 系统分配 ID,用于数值型数据(Long,对应 mysql 中 BIGINT 类型)。
IdType.ASSIGN_UUID 系统分配 UUID,用于字符串型数据(String,对应 mysql 中 varchar(32) 类型)。
【@TableField】
@TableField 用于定义表的非主键字段。
注:
常用属性:
value 用于定义非主键字段名
exist 用于指明是否为数据表的字段, true 表示是,false 为不是。
fill 用于指定字段填充策略(FieldFill)。
字段填充策略:(一般用于填充 创建时间、修改时间等字段)
FieldFill.DEFAULT 默认不填充
FieldFill.INSERT 插入时填充
FieldFill.UPDATE 更新时填充
FieldFill.INSERT_UPDATE 插入、更新时填充。
【@TableLogic】
@TableLogic 用于定义表的字段进行逻辑删除(非物理删除)
注:
常用属性:
value 用于定义未删除时字段的值
delval 用于定义删除时字段的值
【@Version】
@Version 用于字段实现乐观锁
3、代码生成器
(1)AutoGenerator 简介
AutoGenerator 是 MyBatis-Plus 的代码生成器,通过 AutoGenerator 可以快速生成 Entity、Mapper、Mapper XML、Service、Controller 等各个模块的代码,极大的提升了开发效率。
与 mybatis 中的 mybatis-generator-core 类似。
(2)添加依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.3.1.tmp</version>
</dependency>
<!-- 添加 模板引擎 依赖 -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.2</version>
</dependency>
(3)代码分析
Step1:
创建一个 代码生成器。用于生成代码。
此处不用修改。
// Step1:代码生成器 AutoGenerator mpg = new AutoGenerator();
Step2:
配置全局信息。指定代码输出路径,以及包名、作者等信息。
此处按需添加,projectPath 需要修改,setAuthor 需要修改。
// Step2:全局配置
GlobalConfig gc = new GlobalConfig();
// 填写代码生成的目录(需要修改)
String projectPath = "E:\\myProject\\test\\test_mybatis_plus";
// 拼接出代码最终输出的目录
gc.setOutputDir(projectPath + "/src/main/java");
// 配置开发者信息(可选)(需要修改)
gc.setAuthor("lyh");
// 配置是否打开目录,false 为不打开(可选)
gc.setOpen(false);
// 实体属性 Swagger2 注解,添加 Swagger 依赖,开启 Swagger2 模式(可选)
//gc.setSwagger2(true);
// 重新生成文件时是否覆盖,false 表示不覆盖(可选)
gc.setFileOverride(false);
// 配置主键生成策略,此处为 ASSIGN_ID(可选)
gc.setIdType(IdType.ASSIGN_ID);
// 配置日期类型,此处为 ONLY_DATE(可选)
gc.setDateType(DateType.ONLY_DATE);
// 默认生成的 service 会有 I 前缀
gc.setServiceName("%sService");
mpg.setGlobalConfig(gc);
Step3:
配置数据源信息。用于指定 需要生成代码的 数据仓库、数据表。
setUrl、setDriverName、setUsername、setPassword 均需修改。
// Step3:数据源配置(需要修改)
DataSourceConfig dsc = new DataSourceConfig();
// 配置数据库 url 地址
dsc.setUrl("jdbc:mysql://localhost:3306/testMyBatisPlus?useUnicode=true&characterEncoding=utf8");
// dsc.setSchemaName("testMyBatisPlus"); // 可以直接在 url 中指定数据库名
// 配置数据库驱动
dsc.setDriverName("com.mysql.cj.jdbc.Driver");
// 配置数据库连接用户名
dsc.setUsername("root");
// 配置数据库连接密码
dsc.setPassword("123456");
mpg.setDataSource(dsc);
Step4:
配置包信息。
setParent、setModuleName 均需修改。其余按需求修改.
// Step:4:包配置
PackageConfig pc = new PackageConfig();
// 配置父包名(需要修改)
pc.setParent("com.lyh.test");
// 配置模块名(需要修改)
pc.setModuleName("test_mybatis_plus");
// 配置 entity 包名
pc.setEntity("entity");
// 配置 mapper 包名
pc.setMapper("mapper");
// 配置 service 包名
pc.setService("service");
// 配置 controller 包名
pc.setController("controller");
mpg.setPackageInfo(pc);
Step5:
配置数据表映射信息。
setInclude 需要修改,其余按实际开发修改。
// Step5:策略配置(数据库表配置)
StrategyConfig strategy = new StrategyConfig();
// 指定表名(可以同时操作多个表,使用 , 隔开)(需要修改)
strategy.setInclude("test_mybatis_plus_user");
// 配置数据表与实体类名之间映射的策略
strategy.setNaming(NamingStrategy.underline_to_camel);
// 配置数据表的字段与实体类的属性名之间映射的策略
strategy.setColumnNaming(NamingStrategy.underline_to_camel);
// 配置 lombok 模式
strategy.setEntityLombokModel(true);
// 配置 rest 风格的控制器(@RestController)
strategy.setRestControllerStyle(true);
// 配置驼峰转连字符
strategy.setControllerMappingHyphenStyle(true);
// 配置表前缀,生成实体时去除表前缀
// 此处的表名为 test_mybatis_plus_user,模块名为 test_mybatis_plus,去除前缀后剩下为 user。
strategy.setTablePrefix(pc.getModuleName() + "_");
mpg.setStrategy(strategy);
Step6:
执行代码生成操作。
此处不用修改。
// Step6:执行代码生成操作 mpg.execute();
完整配置如下:
package com.lyh.test.test_mybatis_plus;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.generator.AutoGenerator;
import com.baomidou.mybatisplus.generator.config.DataSourceConfig;
import com.baomidou.mybatisplus.generator.config.GlobalConfig;
import com.baomidou.mybatisplus.generator.config.PackageConfig;
import com.baomidou.mybatisplus.generator.config.StrategyConfig;
import com.baomidou.mybatisplus.generator.config.rules.DateType;
import com.baomidou.mybatisplus.generator.config.rules.NamingStrategy;
import org.junit.jupiter.api.Test;
public class TestAutoGenerate {
@Test
public void autoGenerate() {
// Step1:代码生成器
AutoGenerator mpg = new AutoGenerator();
// Step2:全局配置
GlobalConfig gc = new GlobalConfig();
// 填写代码生成的目录(需要修改)
String projectPath = "E:\\myProject\\test\\test_mybatis_plus";
// 拼接出代码最终输出的目录
gc.setOutputDir(projectPath + "/src/main/java");
// 配置开发者信息(可选)(需要修改)
gc.setAuthor("lyh");
// 配置是否打开目录,false 为不打开(可选)
gc.setOpen(false);
// 实体属性 Swagger2 注解,添加 Swagger 依赖,开启 Swagger2 模式(可选)
//gc.setSwagger2(true);
// 重新生成文件时是否覆盖,false 表示不覆盖(可选)
gc.setFileOverride(false);
// 配置主键生成策略,此处为 ASSIGN_ID(可选)
gc.setIdType(IdType.ASSIGN_ID);
// 配置日期类型,此处为 ONLY_DATE(可选)
gc.setDateType(DateType.ONLY_DATE);
// 默认生成的 service 会有 I 前缀
gc.setServiceName("%sService");
mpg.setGlobalConfig(gc);
// Step3:数据源配置(需要修改)
DataSourceConfig dsc = new DataSourceConfig();
// 配置数据库 url 地址
dsc.setUrl("jdbc:mysql://localhost:3306/testMyBatisPlus?useUnicode=true&characterEncoding=utf8");
// dsc.setSchemaName("testMyBatisPlus"); // 可以直接在 url 中指定数据库名
// 配置数据库驱动
dsc.setDriverName("com.mysql.cj.jdbc.Driver");
// 配置数据库连接用户名
dsc.setUsername("root");
// 配置数据库连接密码
dsc.setPassword("123456");
mpg.setDataSource(dsc);
// Step:4:包配置
PackageConfig pc = new PackageConfig();
// 配置父包名(需要修改)
pc.setParent("com.lyh.test");
// 配置模块名(需要修改)
pc.setModuleName("test_mybatis_plus");
// 配置 entity 包名
pc.setEntity("entity");
// 配置 mapper 包名
pc.setMapper("mapper");
// 配置 service 包名
pc.setService("service");
// 配置 controller 包名
pc.setController("controller");
mpg.setPackageInfo(pc);
// Step5:策略配置(数据库表配置)
StrategyConfig strategy = new StrategyConfig();
// 指定表名(可以同时操作多个表,使用 , 隔开)(需要修改)
strategy.setInclude("test_mybatis_plus_user");
// 配置数据表与实体类名之间映射的策略
strategy.setNaming(NamingStrategy.underline_to_camel);
// 配置数据表的字段与实体类的属性名之间映射的策略
strategy.setColumnNaming(NamingStrategy.underline_to_camel);
// 配置 lombok 模式
strategy.setEntityLombokModel(true);
// 配置 rest 风格的控制器(@RestController)
strategy.setRestControllerStyle(true);
// 配置驼峰转连字符
strategy.setControllerMappingHyphenStyle(true);
// 配置表前缀,生成实体时去除表前缀
// 此处的表名为 test_mybatis_plus_user,模块名为 test_mybatis_plus,去除前缀后剩下为 user。
strategy.setTablePrefix(pc.getModuleName() + "_");
mpg.setStrategy(strategy);
// Step6:执行代码生成操作
mpg.execute();
}
}

4、自动填充数据功能
(1)简介
添加、修改数据时,每次都会使用相同的方式进行填充。比如 数据的创建时间、修改时间等。
Mybatis-plus 支持自动填充这些字段的数据。
给之前的数据表新增两个字段:创建时间、修改时间。
CREATE TABLE test_mybatis_plus_user
(
id BIGINT NOT NULL COMMENT '主键ID',
name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',
age INT(11) NULL DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',
create_time timestamp NULL DEFAULT NULL COMMENT '创建时间',
update_time timestamp NULL DEFAULT NULL COMMENT '最后修改时间',
PRIMARY KEY (id)
);
并使用 代码生成器生成代码。

(2)未使用自动填充时
未使用 自动填充时,每次添加、修改数据都可以手动对其进行添加。
@SpringBootTest
class TestMybatisPlusApplicationTests {
@Autowired
private UserService userService;
@Test
public void testUpdate() {
User user = new User();
user.setName("tom").setAge(20).setEmail("tom@163.com");
// 手动添加数据
user.setCreateTime(new Date()).setUpdateTime(new Date());
if (userService.save(user)) {
userService.list().forEach(System.out::println);
} else {
System.out.println("添加数据失败");
}
}
}

(3)使用自动填充功能。
Step1:
使用 @TableField 注解,标注需要进行填充的字段。
/** * 创建时间 */ @TableField(fill = FieldFill.INSERT) private Date createTime; /** * 最后修改时间 */ @TableField(fill = FieldFill.INSERT_UPDATE) private Date updateTime;

Step2:
自定义一个类,实现 MetaObjectHandler 接口,并重写方法。
添加 @Component 注解,交给 Spring 去管理。
package com.lyh.test.test_mybatis_plus.handler;
import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;
import org.apache.ibatis.reflection.MetaObject;
import org.springframework.stereotype.Component;
import java.util.Date;
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
this.strictInsertFill(metaObject, "createTime", Date.class, new Date());
this.strictInsertFill(metaObject, "updateTime", Date.class, new Date());
}
@Override
public void updateFill(MetaObject metaObject) {
this.strictUpdateFill(metaObject, "updateTime", Date.class, new Date());
}
}

Step3:
简单测试一下。
@Test
public void testAutoFill() {
User user = new User();
user.setName("tom").setAge(20).setEmail("tom@163.com");
if (userService.save(user)) {
userService.list().forEach(System.out::println);
} else {
System.out.println("添加数据失败");
}
}

5、逻辑删除
(1)简介
删除数据,可以通过物理删除,也可以通过逻辑删除。
物理删除指的是直接将数据从数据库中删除,不保留。
逻辑删除指的是修改数据的某个字段,使其表示为已删除状态,而非删除数据,保留该数据在数据库中,但是查询时不显示该数据(查询时过滤掉该数据)。
给数据表增加一个字段:delete_flag,用于表示该数据是否被逻辑删除。
CREATE TABLE test_mybatis_plus_user
(
id BIGINT NOT NULL COMMENT '主键ID',
name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',
age INT(11) NULL DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',
create_time timestamp NULL DEFAULT NULL COMMENT '创建时间',
update_time timestamp NULL DEFAULT NULL COMMENT '最后修改时间',
delete_flag tinyint(1) NULL DEFAULT NULL COMMENT '逻辑删除(0 未删除、1 删除)',
PRIMARY KEY (id)
);
(2)使用逻辑删除。
可以定义一个自动填充规则,初始值为 0。0 表示未删除, 1 表示删除。
/**
* 逻辑删除(0 未删除、1 删除)
*/
@TableLogic(value = "0", delval = "1")
@TableField(fill = FieldFill.INSERT)
private Integer deleteFlag;
@Override
public void insertFill(MetaObject metaObject) {
this.strictInsertFill(metaObject, "deleteFlag", Integer.class, 0);
}

(3)简单测试
使用 mybatis-plus 封装好的方法时,会自动添加逻辑删除的功能。
若是自定义的 sql 语句,需要手动添加逻辑。
@Test
public void testDelete() {
if (userService.removeById(1258924257048547329L)) {
System.out.println("删除数据成功");
userService.list().forEach(System.out::println);
} else {
System.out.println("删除数据失败");
}
}
现有数据

执行 testDelete 进行逻辑删除。


若去除 TableLogic 注解,再执行 testDelete 时进行物理删除,直接删除这条数据。


6、分页插件的使用
(1)简介
与 mybatis 的插件 pagehelper 用法类似。
通过简单的配置即可使用。
(2)使用
Step1:
配置分页插件。
编写一个 配置类,内部使用 @Bean 注解将 PaginationInterceptor 交给 Spring 容器管理。
package com.lyh.test.test_mybatis_plus.config;
import com.baomidou.mybatisplus.extension.plugins.PaginationInterceptor;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 自定义一个配置类,mapper 扫描也可在此写上
*/
@Configuration
@MapperScan("com.lyh.test.test_mybatis_plus.mapper")
public class Myconfig {
/**
* 分页插件
* @return 分页插件的实例
*/
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}
}

Step2:
编写分页代码。
直接 new 一个 Page 对象,对象需要传递两个参数(当前页,每页显示的条数)。
调用 mybatis-plus 提供的分页查询方法,其会将 分页查询的数据封装到 Page 对象中。
@Test
public void testPage() {
// Step1:创建一个 Page 对象
Page<User> page = new Page<>();
// Page<User> page = new Page<>(2, 5);
// Step2:调用 mybatis-plus 提供的分页查询方法
userService.page(page, null);
// Step3:获取分页数据
System.out.println(page.getCurrent()); // 获取当前页
System.out.println(page.getTotal()); // 获取总记录数
System.out.println(page.getSize()); // 获取每页的条数
System.out.println(page.getRecords()); // 获取每页数据的集合
System.out.println(page.getPages()); // 获取总页数
System.out.println(page.hasNext()); // 是否存在下一页
System.out.println(page.hasPrevious()); // 是否存在上一页
}

7、乐观锁的实现
(1)首先认识一下 读问题、写问题?
操作数据库数据时,遇到的最基本问题就是 读问题与写问题。
读问题 指的是从数据库中读取数据时遇到的问题,比如:脏读、幻读、不可重复读。
【脏读、幻读、不可重复读 参考地址:】
https://www.cnblogs.com/l-y-h/p/12458777.html#_label0_3
写问题 指的是数据写入数据库时遇到的问题,比如:丢失更新(多个线程同时对某条数据更新,无论执行顺序如何,都会丢失其他线程更新的数据)
(2)如何解决写问题?
乐观锁、悲观锁就是为了解决 写问题而存在的。
乐观锁:总是假设最好的情况,每次读取数据时认为数据不会被修改(即不加锁),当进行更新操作时,会判断这条数据是否被修改,未被修改,则进行更新操作。若被修改,则数据更新失败,可以对数据进行重试(重新尝试修改数据)。
悲观锁:总是假设最坏的情况,每次读取数据时认为数据会被修改(即加锁),当进行更新操作时,直接更新数据,结束操作后释放锁(此处才可以被其他线程读取)。
(3)乐观锁、悲观锁使用场景?
乐观锁一般用于读比较多的场合,尽量减少加锁的开销。
悲观锁一般用于写比较多的场合,尽量减少 类似 乐观锁重试更新引起的性能开销。
(4)乐观锁两种实现方式
方式一:通过版本号机制实现。
在数据表中增加一个 version 字段。
取数据时,获取该字段,更新时以该字段为条件进行处理(即set version = newVersion where version = oldVersion),若 version 相同,则更新成功(给新 version 赋一个值,一般加 1)。若 version 不同,则更新失败,可以重新尝试更新操作。
方式二:通过 CAS 算法实现。
CAS 为 Compare And Swap 的缩写,即比较交换,是一种无锁算法(即在不加锁的情况实现多线程之间的变量同步)。
CAS 操作包含三个操作数 —— 内存值(V)、预期原值(A)和新值(B)。如果内存地址里面的值 V 和 A 的值是一样的,那么就将内存里面的值更新成B。若 V 与 A 不一致,则不执行任何操作(可以通过自旋操作,不断尝试修改数据直至成功修改)。即 V == A ? V = B : V = V。
CAS 可能导致 ABA 问题(两次读取数据时值相同,但不确定值是否被修改过),比如两个线程操作同一个变量,线程 A、线程B 初始读取数据均为 A,后来 线程B 将数据修改为 B,然后又修改为 A,此时线程 A 再次读取到的数据依旧是 A,虽然值相同但是中间被修改过,这就是 ABA 问题。可以加一个额外的标志位 C,用于表示数据是否被修改。当标志位 C 与预期标志位相同、且 V == A 时,则更新值 B。
(5)mybatis-plus 实现乐观锁(通过 version 机制)
实现思路:
Step1:取出记录时,获取当前version
Step2:更新时,带上这个version
Step3:执行更新时, set version = newVersion where version = oldVersion
Step4:如果version不对,就更新失败
(6)mybatis-plus 代码实现乐观锁
Step1:
配置乐观锁插件。
编写一个配置类(可以与上例的分页插件共用一个配置类),将 OptimisticLockerInterceptor 通过 @Bean 交给 Spring 管理。
/**
* 乐观锁插件
* @return 乐观锁插件的实例
*/
@Bean
public OptimisticLockerInterceptor optimisticLockerInterceptor() {
return new OptimisticLockerInterceptor();
}

Step2:
定义一个数据库字段 version。
CREATE TABLE test_mybatis_plus_user
(
id BIGINT NOT NULL COMMENT '主键ID',
name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',
age INT(11) NULL DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',
create_time timestamp NULL DEFAULT NULL COMMENT '创建时间',
update_time timestamp NULL DEFAULT NULL COMMENT '最后修改时间',
delete_flag tinyint(1) NULL DEFAULT NULL COMMENT '逻辑删除(0 未删除、1 删除)',
version int NULL DEFAULT NULL COMMENT '版本号(用于乐观锁, 默认为 1)',
PRIMARY KEY (id)
);
Step3:
使用 @Version 注解标注对应的实体类。
可以通过 @TableField 进行数据自动填充。
/**
* 版本号(用于乐观锁, 默认为 1)
*/
@Version
@TableField(fill = FieldFill.INSERT)
private Integer version;
@Override
public void insertFill(MetaObject metaObject) {
this.strictInsertFill(metaObject, "version", Integer.class, 1);
}

Step4:
简单测试一下,可以看一下 控制台 打印的 sql 语句。
@Test
public void testVersion() {
User user = new User();
user.setName("tom").setAge(20).setEmail("tom@163.com");
userService.save(user);
userService.list().forEach(System.out::println);
user.setName("jarry");
userService.update(user, null);
userService.list().forEach(System.out::println);
}

三、Mybatis-Plus CRUD 操作简单了解一下
1、Mapper 接口方法(CRUD)简单了解一下
(1)简介
使用代码生成器生成的 mapper 接口中,其继承了 BaseMapper 接口。
而 BaseMapper 接口中封装了一系列 CRUD 常用操作,可以直接使用,而不用自定义 xml 与 sql 语句进行 CRUD 操作(当然根据实际开发需要,自定义 sql 还是有必要的)。
此处简单介绍一下 BaseMapper 接口中的常用方法。


(2)方法介绍
混个眼熟,用多了就记得了。
【添加数据:(增)】
int insert(T entity); // 插入一条记录
注:
T 表示任意实体类型
entity 表示实体对象
【删除数据:(删)】
int deleteById(Serializable id); // 根据主键 ID 删除
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap); // 根据 map 定义字段的条件删除
int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper); // 根据实体类定义的 条件删除对象
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList); // 进行批量删除
注:
id 表示 主键 ID
columnMap 表示表字段的 map 对象
wrapper 表示实体对象封装操作类,可以为 null。
idList 表示 主键 ID 集合(列表、数组),不能为 null 或 empty
【修改数据:(改)】
int updateById(@Param(Constants.ENTITY) T entity); // 根据 ID 修改实体对象。
int update(@Param(Constants.ENTITY) T entity, @Param(Constants.WRAPPER) Wrapper<T> updateWrapper); // 根据 updateWrapper 条件修改实体对象
注:
update 中的 entity 为 set 条件,可以为 null。
updateWrapper 表示实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句)
【查询数据:(查)】
T selectById(Serializable id); // 根据 主键 ID 查询数据
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList); // 进行批量查询
List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap); // 根据表字段条件查询
T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 根据实体类封装对象 查询一条记录
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询记录的总条数
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(返回 entity 集合)
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(返回 map 集合)
List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(但只保存第一个字段的值)
<E extends IPage<T>> E selectPage(E page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(返回 entity 集合),分页
<E extends IPage<Map<String, Object>>> E selectMapsPage(E page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(返回 map 集合),分页
注:
queryWrapper 表示实体对象封装操作类(可以为 null)
page 表示分页查询条件
2、Service 接口方法(CRUD)简单了解一下
(1)简介
使用 代码生成器 生成的 service 接口中,其继承了 IService 接口。
IService 内部进一步封装了 BaseMapper 接口的方法(当然也提供了更详细的方法)。
使用时,可以通过 生成的 mapper 类进行 CRUD 操作,也可以通过 生成的 service 的实现类进行 CRUD 操作。(当然,自定义代码执行也可)
此处简单介绍一下 IService 中封装的常用方法。


(2)方法介绍
混个眼熟,用多了就记得了。
内部封装了 BaseMapper 的方法,也提供了新的方法。
比如:
添加了 批量更新 方法、更新或修改方法等。
对 查询方法 做了细化,使用 get 命名的方法查询一条数据,使用 list 命名的方法查询多条数据等。
增加了链式调用的方法。
【添加数据:(增)】
default boolean save(T entity); // 调用 BaseMapper 的 insert 方法,用于添加一条数据。
boolean saveBatch(Collection<T> entityList, int batchSize); // 批量插入数据
注:
entityList 表示实体对象集合
batchSize 表示一次批量插入的数据量,默认为 1000
【添加或修改数据:(增或改)】
boolean saveOrUpdate(T entity); // id 若存在,则修改, id 不存在则新增数据
default boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper); // 先根据条件尝试更新,然后再执行 saveOrUpdate 操作
boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize); // 批量插入并修改数据
【删除数据:(删)】
default boolean removeById(Serializable id); // 调用 BaseMapper 的 deleteById 方法,根据 id 删除数据。
default boolean removeByMap(Map<String, Object> columnMap); // 调用 BaseMapper 的 deleteByMap 方法,根据 map 定义字段的条件删除
default boolean remove(Wrapper<T> queryWrapper); // 调用 BaseMapper 的 delete 方法,根据实体类定义的 条件删除对象。
default boolean removeByIds(Collection<? extends Serializable> idList); // 用 BaseMapper 的 deleteBatchIds 方法, 进行批量删除。
【修改数据:(改)】
default boolean updateById(T entity); // 调用 BaseMapper 的 updateById 方法,根据 ID 选择修改。
default boolean update(T entity, Wrapper<T> updateWrapper); // 调用 BaseMapper 的 update 方法,根据 updateWrapper 条件修改实体对象。
boolean updateBatchById(Collection<T> entityList, int batchSize); // 批量更新数据
【查找数据:(查)】
default T getById(Serializable id); // 调用 BaseMapper 的 selectById 方法,根据 主键 ID 返回数据。
default List<T> listByIds(Collection<? extends Serializable> idList); // 调用 BaseMapper 的 selectBatchIds 方法,批量查询数据。
default List<T> listByMap(Map<String, Object> columnMap); // 调用 BaseMapper 的 selectByMap 方法,根据表字段条件查询
default T getOne(Wrapper<T> queryWrapper); // 返回一条记录(实体类保存)。
Map<String, Object> getMap(Wrapper<T> queryWrapper); // 返回一条记录(map 保存)。
default int count(Wrapper<T> queryWrapper); // 根据条件返回 记录数。
default List<T> list(); // 返回所有数据。
default List<T> list(Wrapper<T> queryWrapper); // 调用 BaseMapper 的 selectList 方法,查询所有记录(返回 entity 集合)。
default List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper); // 调用 BaseMapper 的 selectMaps 方法,查询所有记录(返回 map 集合)。
default List<Object> listObjs(); // 返回全部记录,但只返回第一个字段的值。
default <E extends IPage<T>> E page(E page, Wrapper<T> queryWrapper); // 调用 BaseMapper 的 selectPage 方法,分页查询
default <E extends IPage<Map<String, Object>>> E pageMaps(E page, Wrapper<T> queryWrapper); // 调用 BaseMapper 的 selectMapsPage 方法,分页查询
注:
get 用于返回一条记录。
list 用于返回多条记录。
count 用于返回记录总数。
page 用于分页查询。
【链式调用:】
default QueryChainWrapper<T> query(); // 普通链式查询
default LambdaQueryChainWrapper<T> lambdaQuery(); // 支持 Lambda 表达式的修改
default UpdateChainWrapper<T> update(); // 普通链式修改
default LambdaUpdateChainWrapper<T> lambdaUpdate(); // 支持 Lambda 表达式的修改
注:
query 表示查询
update 表示修改
Lambda 表示内部支持 Lambda 写法。
形如:
query().eq("column", value).one();
lambdaQuery().eq(Entity::getId, value).list();
update().eq("column", value).remove();
lambdaUpdate().eq(Entity::getId, value).update(entity);
3、条件构造器(Wrapper,定义 where 条件)
(1)简介
上面介绍的 接口方法的参数中,会出现各种 wrapper,比如 queryWrapper、updateWrapper 等。wrapper 的作用就是用于定义各种各样的查询条件(where)。
Wrapper 条件构造抽象类
-- AbstractWrapper 查询条件封装,用于生成 sql 中的 where 语句。
-- QueryWrapper Entity 对象封装操作类,用于查询。
-- UpdateWrapper Update 条件封装操作类,用于更新。
-- AbstractLambdaWrapper 使用 Lambda 表达式封装 wrapper
-- LambdaQueryWrapper 使用 Lambda 语法封装条件,用于查询。
-- LambdaUpdateWrapper 使用 Lambda 语法封装条件,用于更新。

(2)常用条件
参考源码以及官方文档总结的,还是一句话,混个眼熟,多用用就熟练了。
【通用条件:】
【比较大小: ( =, <>, >, >=, <, <= )】
eq(R column, Object val); // 等价于 =,例: eq("name", "老王") ---> name = '老王'
ne(R column, Object val); // 等价于 <>,例: ne("name", "老王") ---> name <> '老王'
gt(R column, Object val); // 等价于 >,例: gt("name", "老王") ---> name > '老王'
ge(R column, Object val); // 等价于 >=,例: ge("name", "老王") ---> name >= '老王'
lt(R column, Object val); // 等价于 <,例: lt("name", "老王") ---> name < '老王'
le(R column, Object val); // 等价于 <=,例: le("name", "老王") ---> name <= '老王'
【范围:(between、not between、in、not in)】
between(R column, Object val1, Object val2); // 等价于 between a and b, 例: between("age", 18, 30) ---> age between 18 and 30
notBetween(R column, Object val1, Object val2); // 等价于 not between a and b, 例: notBetween("age", 18, 30) ---> age not between 18 and 30
in(R column, Object... values); // 等价于 字段 IN (v0, v1, ...),例: in("age",{1,2,3}) ---> age in (1,2,3)
notIn(R column, Object... values); // 等价于 字段 NOT IN (v0, v1, ...), 例: notIn("age",{1,2,3}) ---> age not in (1,2,3)
inSql(R column, Object... values); // 等价于 字段 IN (sql 语句), 例: inSql("id", "select id from table where id < 3") ---> id in (select id from table where id < 3)
notInSql(R column, Object... values); // 等价于 字段 NOT IN (sql 语句)
【模糊匹配:(like)】
like(R column, Object val); // 等价于 LIKE '%值%',例: like("name", "王") ---> name like '%王%'
notLike(R column, Object val); // 等价于 NOT LIKE '%值%',例: notLike("name", "王") ---> name not like '%王%'
likeLeft(R column, Object val); // 等价于 LIKE '%值',例: likeLeft("name", "王") ---> name like '%王'
likeRight(R column, Object val); // 等价于 LIKE '值%',例: likeRight("name", "王") ---> name like '王%'
【空值比较:(isNull、isNotNull)】
isNull(R column); // 等价于 IS NULL,例: isNull("name") ---> name is null
isNotNull(R column); // 等价于 IS NOT NULL,例: isNotNull("name") ---> name is not null
【分组、排序:(group、having、order)】
groupBy(R... columns); // 等价于 GROUP BY 字段, ..., 例: groupBy("id", "name") ---> group by id,name
orderByAsc(R... columns); // 等价于 ORDER BY 字段, ... ASC, 例: orderByAsc("id", "name") ---> order by id ASC,name ASC
orderByDesc(R... columns); // 等价于 ORDER BY 字段, ... DESC, 例: orderByDesc("id", "name") ---> order by id DESC,name DESC
having(String sqlHaving, Object... params); // 等价于 HAVING ( sql语句 ), 例: having("sum(age) > {0}", 11) ---> having sum(age) > 11
【拼接、嵌套 sql:(or、and、nested、apply)】
or(); // 等价于 a or b, 例:eq("id",1).or().eq("name","老王") ---> id = 1 or name = '老王'
or(Consumer<Param> consumer); // 等价于 or(a or/and b),or 嵌套。例: or(i -> i.eq("name", "李白").ne("status", "活着")) ---> or (name = '李白' and status <> '活着')
and(Consumer<Param> consumer); // 等价于 and(a or/and b),and 嵌套。例: and(i -> i.eq("name", "李白").ne("status", "活着")) ---> and (name = '李白' and status <> '活着')
nested(Consumer<Param> consumer); // 等价于 (a or/and b),普通嵌套。例: nested(i -> i.eq("name", "李白").ne("status", "活着")) ---> (name = '李白' and status <> '活着')
apply(String applySql, Object... params); // 拼接sql(若不使用 params 参数,可能存在 sql 注入),例: apply("date_format(dateColumn,'%Y-%m-%d') = {0}", "2008-08-08") ---> date_format(dateColumn,'%Y-%m-%d') = '2008-08-08'")
last(String lastSql); // 无视优化规则直接拼接到 sql 的最后,可能存若在 sql 注入。
exists(String existsSql); // 拼接 exists 语句。例: exists("select id from table where age = 1") ---> exists (select id from table where age = 1)
【QueryWrapper 条件:】
select(String... sqlSelect); // 用于定义需要返回的字段。例: select("id", "name", "age") ---> select id, name, age
select(Predicate<TableFieldInfo> predicate); // Lambda 表达式,过滤需要的字段。
lambda(); // 返回一个 LambdaQueryWrapper
【UpdateWrapper 条件:】
set(String column, Object val); // 用于设置 set 字段值。例: set("name", null) ---> set name = null
etSql(String sql); // 用于设置 set 字段值。例: setSql("name = '老李头'") ---> set name = '老李头'
lambda(); // 返回一个 LambdaUpdateWrapper
(3)简单使用,测试一下 QueryWrapper
@Test
public void testQueryWrapper() {
// Step1:创建一个 QueryWrapper 对象
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// Step2: 构造查询条件
queryWrapper
.select("id", "name", "age")
.eq("age", 20)
.like("name", "j");
// Step3:执行查询
userService
.list(queryWrapper)
.forEach(System.out::println);
}
当前数据库数据如下:

执行测试方法输出如下:

tkmybatis 是对底层 sql 进行了抽象封装,不需要考虑 sql 怎么写,只需要按照逻辑思维,遵循 tkmybatis 的语法即可实现数据库操作。
本文适合对springboot项目结构有一定了解的读者。
本文的项目基础是一个demo项目(多模块的)。
1. 配置
1、添加 tkmybatis 的依赖
-
<dependency>
-
<groupId>tk.mybatis</groupId>
-
<artifactId>mapper-spring-boot-starter</artifactId>
-
<version>2.1.5</version>
-
</dependency>
2、创建 dao 层的 mapper 接口,每个接口都要继承 tk.mybatis.mapper.common.Mapper 接口。此接口的形式为 Mapper<T>,带了个泛型,此泛型一般指的是对应的 pojo 或者 domain。比如:
-
public interface HouseMapper extends Mapper<House> {
-
}
3、在 Application 启动类上添加 mapper 扫描注解,表示要扫描到 dao 层的 mapper 接口。
比如本项目的mapper接口就统一放在 com.dgh.dao 下面,用 @MapperScan(basePackages = "包名") 来指定。
附注:在项目启动时,springboot 会自动扫描 Application 启动类所在的当前目录以及下一级目录,一般 Application 启动类都放在根目录,所以在单一项目下,只要是在 Java 类上添加了注解,都能够默认被 springboot 扫描到,并被添加到 springboot 的容器中,一般不需要特别用 @ComponentScan 去指定 springboot 要扫描哪些目录。
本文之所以特地用 @ComponentScan 去指定了 service 层和 controller 层的目录,是因为本文的项目是一个多模块项目,service 层和 controller 层各自都是一个独立的模块,与 Application 启动类不在同一目录下。
-
-
-
-
-
public class ControllerApplication {
-
public static void main(String[] args) {
-
SpringApplication.run(ControllerApplication.class, args);
-
}
-
}
4、tkmybatis 具体的使用是在 service 层,service 层又分为接口和接口实现类,具体就在接口实现类里面。
5、其它的代码、配置与普通的springboot项目一样。
2. tkmybatis的结构
下图是 tkmybatis 的结构图,圈中的是 Mapper 接口,是最底层的,也就意味着它继承了所有的功能。因此才有了 “配置” 中第2步继承Mapper<T>接口。
它定义各种 sql 语句的基础,通过灵活的拼接,查询参数的设置,可以满足开发者各种的数据库查询要求。
既然如此,那我猜 tkmybatis 的底层是动态代理实现的。

3. 增删查改——基础方法
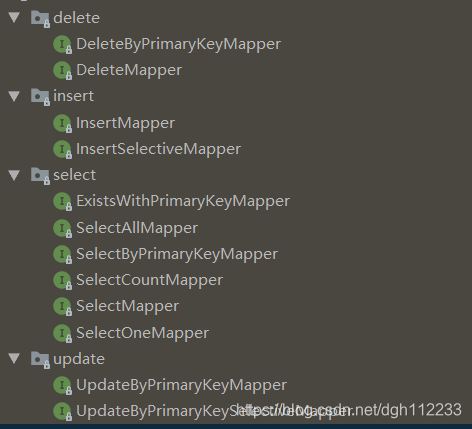
3.1 删除
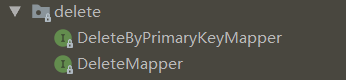
DeleteByPrimaryKeyMapper接口有一个方法 deleteByPrimaryKey,顾名思义,以表的主键字段作为条件判断,进行删除。
delete from table where id = ?
int deleteByPrimaryKey(Object var1);DeleteMapper接口有一个方法 delete,参数就是数据库表对应的Java实体类,参数实体中哪些字段不为null,就会被作为删除sql语句的条件字段,且条件关系是 and,而不是 or。
delete from table where 字段1 = ?and 字段2 = ?
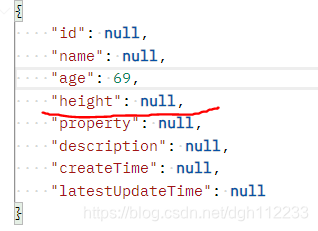
int delete(T var1);注意:在定义实体类时,每个成员变量的类型都应该是Java类,不能是基本类型,比如整型,应该用 Integer,而不是 int。如果用 int 的话,在没有给 int 成员变量赋值时,ava 会默认给它赋值为 0,由于 0 不是 null,所以会被 tkmybatis 当做是删除条件。
比如前段发送的删除请求,参数实体如下,height字段为 null,本来意思是不把 height 字段作为删除的条件字段,如果 Java 实体类的 height 字段类型定义为 Integer,那一切正常,但是如果定义为 int 类型,那么在实例化对象并赋值时,默认赋值 height = 0,sql语句将变成 delete from house where age = 69 and height = 0; 这样就违背了本意,容易造成错误的删除后果。
3.2 插入
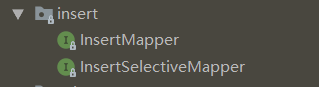
InsertMapper 接口有一个方法 insert 方法,往数据库表插入一条记录,表有多少个字段,在 tkmybatis 生成的 insert sql 语句中就有多少个字段。
insert into table (所有字段) values (?,?...,?)
int insert(T var1);InsertSelectiveMapper 接口有一个方法 insertSelective,实体类参数中不为 null 的字段就会被考虑,在 tkmybatis 生成的 insert sql 语句中只会包含这些不为 null 的字段。
insert into table (部分字段) values (?,..?)
int insertSelective(T var1);3.3 查询
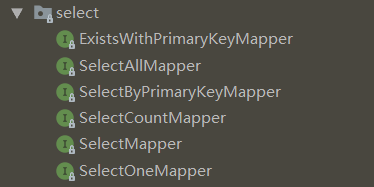
SelectMapper 接口有一个方法 select,参数实体类中哪些字段不为 null,就会被作为 select sql 语句中的条件字段,且字段之间的关系是 and。
select 所有字段 from table where 字段1 = ? and 字段2 = ?
List<T> select(T var1);SelectOneMapper 接口有一个方法 selectOne,与 select 方法一样,只是返回结果只能为空或者一个,如果有多个,则抛出异常。
同上
T selectOne(T var1);SelectCountMapper 接口有一个方法 selectCount,查询满足条件的记录有多少条。
select count(id) from table where 字段1 = ? and 字段2 = ?
int selectCount(T var1);SelectAllMapper 接口有一个方法 selectAll,查询全表所有记录。
select 所有字段 from table;
List<T> selectAll();SelectByPrimaryKeyMapper 接口有一个方法 selectByPrimaryKey,根据主键进行查询。
select 所有字段 from table where 主键字段 = ?
T selectByPrimaryKey(Object var1);ExistsWithPrimaryKeyMapper 接口有一个方法 existsWithPrimaryKey,根据主键查询某条记录是否存在。
select case when count(主键字段) > 0 then 1 else 0 end as result from table where 主键字段 = ?
boolean existsWithPrimaryKey(Object var1);3.4 修改
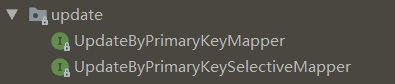
UpdateByPrimaryKeyMapper 接口有一个方法 updateByPrimaryKey,根据主键字段准确地修改某一条记录。
update table set 所有字段
int updateByPrimaryKey(T var1);UpdateByPrimaryKeySelectiveMapper 接口有一个方法 updateByPrimaryKeySelective,根据主键字段准确地修改某一条记录的部分字段(实体类参数的不为 null 的字段)。
update table set 部分字段
int updateByPrimaryKeySelective(T var1);4 批量增删查改——基础方法
4.1 批量插入
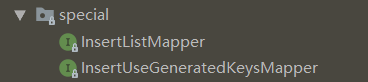
这两个功能有一个要求,那就是操作的数据库表必须有一个自增主键,因为它要求主键必须要有一个默认值,否则就抛出异常。
这两个接口是集成到 MySqlMapper 接口中了,所以 dao 层的 mapper 接口还要继承 MySqlMapper 接口才能使用批量插入功能。
-
public interface HouseMapper extends Mapper<House>, MySqlMapper<House> {
-
}
InsertListMapper 接口有一个方法 insertList,批量插入。
insert into table (所有字段,除了自增主键) values (?,..,?), ...,(?,...,?)
int insertList(List<? extends T> var1);InsertUseGeneratedKeysMapper 接口有一个方法 insertUserGeneratedKeys,单个插入。
int insertUseGeneratedKeys(T var1);4.2 批量查询与批量删除
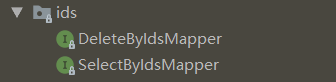
SelectByIdsMapper 接口有一个方法 selectByIds,按照多个主键 id 值进行查询,但是方法的参数是 String,那么主键id之间用逗号隔开就行。
select 所有字段 from table where id in (id值1,id值2,...,id值n)
List<T> selectByIds(String var1);DeleteByIdsMapper 接口有一个方法 deleteByIds,按照多个主键 id 值进行删除。
delete from table where id in (id值1,id值2,...,id值n)
int deleteByIds(String var1);5 自定义查询条件
5.1 删改查方法
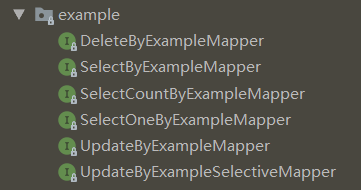
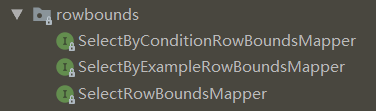
图中接口都有一个共同点,就是需要 Example 对象作为方法的参数,Example 对象包含了我们各种自定义的查询条件,相当于 sql 语句中 where 部分的条件。
每个接口都包含了一个方法,供我们调用。总结如下表:
| 方法 | 功能描述 |
| int deleteByExample(Object var1); | 一般参数就是Example对象,按照条件进行删除,返回删除的记录数 |
| List<T> selectByExample(Object var1); | 一般参数就是Example对象,按照条件进行查询,返回查询结果集 |
| int selectCountByExample(Object var1); | 一般参数就是Example对象,按照条件进行查询,返回符合查询条件的记录数 |
| T selectOneByExample(Object var1); | 一般参数就是Example对象,按照条件进行查询,结果只能为空或者一个,否则抛出异常 |
| int updateByExample(@Param("record") T var1, @Param("example") Object var2); | 第一个参数是新记录,第二参数是example对象,用新记录替换掉符合条件的旧记录 |
| int updateByExampleSelective(@Param("record") T var1, @Param("example") Object var2); | 功能同上,只是可以仅替换掉记录的部分字段 |
| List<T> selectByRowBounds(T var1, RowBounds var2); | 第一个参数是查询条件,第二个参数是 RowBounds 对象(包含2个属性,offset 和 limit),offset 表示起始行,limit 表示需要的记录数;方法的功能是按照查询条件进行查询,再按照 offset 和 limit 在结果集中取相应数量的记录。 |
| List<T> selectByExampleAndRowBounds(Object var1, RowBounds var2); | 第一个参数是 Example 对象,第二个参数是 RowBounds 对象,先根据 example 条件进行查询,再按照 offset 和 limit 取相应数量的记录。 |
| List<T> selectByConditionAndRowBounds(Object var1, RowBounds var2); | 同上 |
5.2 Example 条件设置
先创建 Example 对象,再创建 Example.criteria 对象,借助这两个对象,可以灵活地设置各种条件。Example 对象可以理解为 sql 语句层次的设置, 而 Example.criteria 对象可以理解为 sql 语句中的一个单一的条件表达式设置。
原理上可以理解为:一个 example 包含了若干个 criteria ,每个 criteria 就是 sql 语句中条件部分的一个括号部分(没有嵌套),比如 (id = 5),criteria 包含了一个方法 void setAndOr(String andOr),它的意思相当于在括号前面加上 and 还是 or,比如执行了方法 setAndOr("and"),那么 criteria 相当于 and (id = 5),而 example 就把这些 criteria 拼凑起了,比如 example 包含了 2 个 criteria,分别是 (id = 5) 和 and (name = "张三"),那么此 example 的效果就是 (id = 5) and (name = "张三")。
-
Example example = new Example(House.class);
-
Example.Criteria criteria = example.createCriteria();
具体可以怎么设置呢?criteria 包含的方法总结如下表:
| 方法 | 功能描述 |
| andAllEqualTo(Object param) | 所有字段都作为 where 后面的判断条件,判断值就是参数实体对象 |
| andBetween(String property, Object value1, Object value2) | where property between value1 and value2 ,范围条件,包含两端 |
| andEqualTo(Object param) | 实体对象中不为 null 的字段作为 where 后面的判断条件 |
| andEqualTo(String property, Object value) | 某一个<字段,值>作为 where 后面的判等条件 |
| andGreaterThan(String property, Object value) | 大于条件,某个字段大于某个值 |
| andGreaterThanOrEqualTo(String property, Object value) | 大于等于条件,某个字段大于等于某个值 |
| andIn(String property, Iterable values) | where property in (),范围条件 |
| andIsNotNull(String property) | where property is not null,判空条件 |
| andIsNull(String property) | where property is null,判空条件 |
| andLessThan(String property, Object value) | 小于条件 |
| andLessThanOrEqualTo(String property, Object value) | 小于等于条件 |
| andLike(String property, String value) | where property like value,注意 value 应该是一个匹配表达式 |
| andNotBetween(String property, Object value1, Object value2) | 范围条件,不包含两端 |
| andNotEqualTo(String property, Object value) | 要求字段不等于某个值 |
| andNotIn(String property, Iterable values) | 要求字段不在某个范围内 |
| andNotLike(String property, String value) | 模糊查询,要求不 like。 |
| void setAndOr(String andOr) | 上面已经介绍过了 |
上表的方法都是“与”关系,即 and。 同样的,有相应的 “或” 关系,即 or。比如 orAllEqualTo、orGreaterThan 等等,都是将方法名中的 “and” 换成 “or”。
那 criteria 能否嵌套呢?能否有更方便的使用方式呢?回答:能,有。如下表:
| Example.Criteria orCondition(String condition, Object value) | condition参数是个sql字符串,可以拼接进 sql 语句的,value 是一个值,会拼接到 condition 后面的,此方法的最终结果为 or condition + value。 |
| Example.Criteria orCondition(String condition) | 功能同上,只是更加直接,一个字符串搞定,只是字符串参数可以写成类似这种 “id = ”+getId(),"( id = "+getId()+")",一样灵活,此方法的最终结果为 or condition。 |
| Example.Criteria andCondition(String condition) | 不再赘述 |
| Example.Criteria andCondition(String condition, Object value) | 不再赘述 |
Example 类包含的方法总结如下表:
| 方法 | 功能描述 |
| void setDistinct(boolean distinct) | 查询的结果是否要进行唯一性过滤,true表示过滤,false(默认)表示不过滤。 |
| void setOrderByClause(String orderByClause) | 查询结果按照某个,或者某些字段进行升序,降序。比如参数是 “id asc” 就是按照 id 进行升序,“id asc,age desc” 就是按照 id 升序,在 id 相等的情况下,按照 age 降序。 |
| Example selectProperties(String... properties) | 当利用 example 进行查询时,此方法可以设置想要查询的字段是哪些,比如我只需要查询一张表的部分字段。 |
| Example.OrderBy orderBy(String property) | 排序,与 setOrderByClause 功能一样,只是用法不同,比如 orderBy("id").asc() 表示按照 id 升序, orderBy("id").asc().orderBy("age").desc() 表示按照 id 升序,再按照 age 降序 |
| Example.Criteria or() | 创建一个 or 方式的、空的criteria,具体的 criteria 内容可以稍后设置。 |
| void or(Example.Criteria criteria) | 直接以 or 的方式添加一个现有的 criteria |
| Example.Criteria and() | 同上,不过是 and 方式 |
| void and(Example.Criteria criteria) | 同上,and 方式 |
Example 类还有其它的一些方法,本人觉得都有些鸡肋或者重复,也就不再介绍了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号