redisson 使用全解 ——redisson 官方文档 + 注释
官方文档
Redisson 项目介绍
Redisson 是架设在 Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid)。充分的利用了 Redis 键值数据库提供的一系列优势,基于 Java 实用工具包中常用接口,为使用者提供了一系列具有分布式特性的常用工具类。使得原本作为协调单机多线程并发程序的工具包获得了协调分布式多机多线程并发系统的能力,大大降低了设计和研发大规模分布式系统的难度。同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间的协作。
Redisson 采用了基于 NIO 的 Netty 框架,不仅能作为 Redis 底层驱动客户端,具备提供对 Redis 各种组态形式的连接功能,对 Redis 命令能以同步发送、异步形式发送、异步流形式发送或管道形式发送的功能,LUA 脚本执行处理,以及处理返回结果的功能,还在此基础上融入了更高级的应用方案,不但将原生的 Redis Hash,List,Set,String,Geo,HyperLogLog 等数据结构封装为 Java 里大家最熟悉的映射(Map),列表(List),集(Set),通用对象桶(Object Bucket),地理空间对象桶(Geospatial Bucket),基数估计算法(HyperLogLog)等结构,在这基础上还提供了分布式的多值映射(Multimap),本地缓存映射(LocalCachedMap),有序集(SortedSet),计分排序集(ScoredSortedSet),字典排序集(LexSortedSet),列队(Queue),阻塞队列(Blocking Queue),有界阻塞列队(Bounded Blocking Queue),双端队列(Deque),阻塞双端列队(Blocking Deque),阻塞公平列队(Blocking Fair Queue),延迟列队(Delayed Queue),布隆过滤器(Bloom Filter),原子整长形(AtomicLong),原子双精度浮点数(AtomicDouble),BitSet 等 Redis 原本没有的分布式数据结构。不仅如此,Redisson 还实现了 Redis 文档中提到像分布式锁 Lock 这样的更高阶应用场景。事实上 Redisson 并没有不止步于此,在分布式锁的基础上还提供了联锁(MultiLock),读写锁(ReadWriteLock),公平锁(Fair Lock),红锁(RedLock),信号量(Semaphore),可过期性信号量(PermitExpirableSemaphore)和闭锁(CountDownLatch)这些实际当中对多线程高并发应用至关重要的基本部件。正是通过实现基于 Redis 的高阶应用方案,使 Redisson 成为构建分布式系统的重要工具。
在提供这些工具的过程当中,Redisson 广泛的使用了承载于 Redis 订阅发布功能之上的分布式话题(Topic)功能。使得即便是在复杂的分布式环境下,Redisson 的各个实例仍然具有能够保持相互沟通的能力。在以这为前提下,结合了自身独有的功能完善的分布式工具,Redisson 进而提供了像分布式远程服务(Remote Service),分布式执行服务(Executor Service)和分布式调度任务服务(Scheduler Service)这样适用于不同场景的分布式服务。使得 Redisson 成为了一个基于 Redis 的 Java 中间件(Middleware)。
Redisson Node 的出现作为驻内存数据网格的重要特性之一,使 Redisson 能够独立作为一个任务处理节点,以系统服务的方式运行并自动加入 Redisson 集群,具备集群节点弹性增减的能力。然而在真正意义上让 Redisson 发展成为一个完整的驻内存数据网格的,还是具有将基本上任何复杂、多维结构的对象都能变为分布式对象的分布式实时对象服务(Live Object Service),以及与之相结合的,在分布式环境中支持跨节点对象引用(Distributed Object Reference)的功能。这些特色功能使 Redisson 具备了在分布式环境中,为 Java 程序提供了堆外空间(Off-Heap Memory)储存对象的能力。
Redisson 提供了使用 Redis 的最简单和最便捷的方法。Redisson 的宗旨是促进使用者对 Redis 的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。如果您现在正在使用其他的 Redis 的 Java 客户端,希望 Redis 命令和 Redisson 对象匹配列表 能够帮助您轻松的将现有代码迁徙到 Redisson 里来。如果目前 Redis 的应用场景还仅限于作为缓存使用,您也可以将 Redisson 轻松的整合到像 Spring 和 Hibernate 这样的常用框架里。除此外您也可以间接的通过 Java 缓存标准规范 JCache API (JSR-107) 接口来使用 Redisson。
Redisson 生而具有的高性能,分布式特性和丰富的结构等特点恰巧与 Tomcat 这类服务程序对会话管理器(Session Manager)的要求相吻合。利用这样的特点,Redisson 专门为 Tomcat 提供了会话管理器(Tomcat Session Manager)。
在此不难看出,Redisson 同其他 Redis Java 客户端有着很大的区别,相比之下其他客户端提供的功能还仅仅停留在作为数据库驱动层面上,比如仅针对 Redis 提供连接方式,发送命令和处理返回结果等。像上面这些高层次的应用则只能依靠使用者自行实现。
Redisson 支持 Redis 2.8 以上版本,支持 Java1.6 + 以上版本。
一、概述
Redisson 是一个在 Redis 的基础上实现的 Java 驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的 Java 常用对象,还提供了许多分布式服务。其中包括 (BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service) Redisson 提供了使用 Redis 的最简单和最便捷的方法。Redisson 的宗旨是促进使用者对 Redis 的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
关于 Redisson 项目的详细介绍可以在官方网站找到。
每个 Redis 服务实例都能管理多达 1TB 的内存。
能够完美的在云计算环境里使用,并且支持 AWS ElastiCache 主备版,AWS ElastiCache 集群版,Azure Redis Cache 和阿里云(Aliyun)的云数据库 Redis 版
以下是 Redisson 的结构:
Redisson 作为独立节点 可以用于独立执行其他节点发布到分布式执行服务 和 分布式调度任务服务 里的远程任务。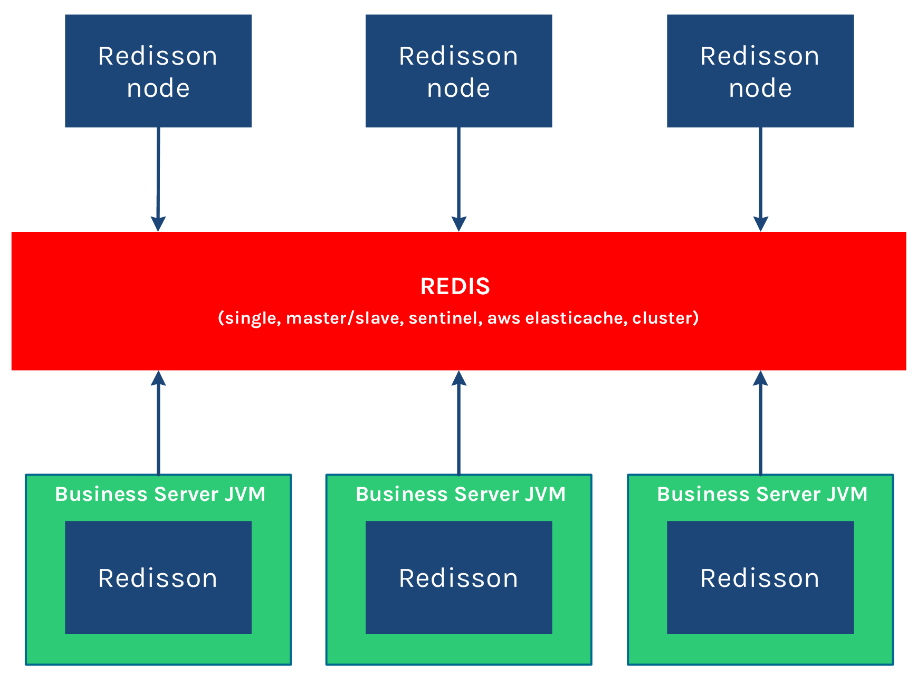
如果你现在正在使用其他的 Redis 的 Java 客户端,那么 Redis 命令和 Redisson 对象匹配列表 能够帮助你轻松的将现有代码迁徙到 Redisson 框架里来。
Redisson 底层采用的是 Netty 框架。支持 Redis 2.8 以上版本,支持 Java1.6 + 以上版本。
欢迎试用高性能 Redisson PRO 版。
二、配置方法
引入 pom:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.3</version>
</dependency>2.1. 程序化配置方法
Redisson 程序化的配置方法是通过构建 Config 对象实例来实现的。例如:
Config config = new Config();
config.setTransportMode(TransportMode.EPOLL); // 默认是NIO的方式
config.useClusterServers()
//可以用"rediss://"来启用SSL连接,前缀必须是redis:// or rediss://
.addNodeAddress("redis://127.0.0.1:7181");2.2. 文件方式配置
Redisson 既可以通过用户提供的 YAML 格式的文本文件来配置
2.2.1 通过 YAML 格式配置
Redisson 的配置文件可以是或 YAML 格式。 也通过调用 config.fromYAML 方法并指定一个 File 实例来实现读取 YAML 格式的配置:
Config config = Config.fromYAML(new File("config-file.yaml"));
RedissonClient redisson = Redisson.create(config);调用 config.toYAML 方法可以将一个 Config 配置实例序列化为一个含有 YAML 数据类型的字符串:
Config config = new Config();
// ... 省略许多其他的设置
String jsonFormat = config.toYAML();2.3. 常用设置
以下是关于 org.redisson.Config 类的配置参数,它适用于所有 Redis 组态模式(单机,集群和哨兵)
codec(编码)
默认值: org.redisson.codec.JsonJacksonCodec
Redisson 的对象编码类是用于将对象进行序列化和反序列化,以实现对该对象在 Redis 里的读取和存储。Redisson 提供了以下几种的对象编码应用,以供大家选择:
| 编码类名称 | 说明 |
|---|---|
| org.redisson.codec.JsonJacksonCodec | Jackson JSON 编码 默认编码 |
| org.redisson.codec.AvroJacksonCodec | Avro 一个二进制的 JSON 编码 |
| org.redisson.codec.SmileJacksonCodec | Smile 另一个二进制的 JSON 编码 |
| org.redisson.codec.CborJacksonCodec | CBOR 又一个二进制的 JSON 编码 |
| org.redisson.codec.MsgPackJacksonCodec | MsgPack 再来一个二进制的 JSON 编码 |
| org.redisson.codec.IonJacksonCodec | Amazon Ion 亚马逊的 Ion 编码,格式与 JSON 类似 |
| org.redisson.codec.KryoCodec | Kryo 二进制对象序列化编码 |
| org.redisson.codec.SerializationCodec | JDK 序列化编码 |
| org.redisson.codec.FstCodec | FST 10 倍于 JDK 序列化性能而且 100% 兼容的编码 |
| org.redisson.codec.LZ4Codec | LZ4 压缩型序列化对象编码 |
| org.redisson.codec.SnappyCodec | Snappy 另一个压缩型序列化对象编码 |
| org.redisson.client.codec.JsonJacksonMapCodec | 基于 Jackson 的映射类使用的编码。可用于避免序列化类的信息,以及用于解决使用 byte [] 遇到的问题。 |
| org.redisson.client.codec.StringCodec | 纯字符串编码(无转换) |
| org.redisson.client.codec.LongCodec | 纯整长型数字编码(无转换) |
| org.redisson.client.codec.ByteArrayCodec | 字节数组编码 |
| org.redisson.codec.CompositeCodec | 用来组合多种不同编码在一起 |
threads(线程池数量)
默认值:当前处理核数量 * 2
这个线程池数量被所有 RTopic 对象监听器,RRemoteService 调用者和 RExecutorService 任务共同共享。
nettyThreads (Netty 线程池数量)
默认值:当前处理核数量 * 2
这个线程池数量是在一个 Redisson 实例内,被其创建的所有分布式数据类型和服务,以及底层客户端所一同共享的线程池里保存的线程数量。
executor(线程池)
单独提供一个用来执行所有 RTopic 对象监听器,RRemoteService 调用者和 RExecutorService 任务的线程池(ExecutorService)实例。
eventLoopGroup
用于特别指定一个 EventLoopGroup. EventLoopGroup 是用来处理所有通过 Netty 与 Redis 服务之间的连接发送和接受的消息。每一个 Redisson 都会在默认情况下自己创建管理一个 EventLoopGroup 实例。因此,如果在同一个 JVM 里面可能存在多个 Redisson 实例的情况下,采取这个配置实现多个 Redisson 实例共享一个 EventLoopGroup 的目的。
只有 io.netty.channel.epoll.EpollEventLoopGroup 或 io.netty.channel.nio.NioEventLoopGroup 才是允许的类型。
transportMode(传输模式)
默认值:TransportMode.NIO
可选参数:
TransportMode.NIO,
TransportMode.EPOLL - 需要依赖里有 netty-transport-native-epoll 包(Linux)
TransportMode.KQUEUE - 需要依赖里有 netty-transport-native-kqueue 包(macOS)
lockWatchdogTimeout(监控锁的看门狗超时,单位:毫秒)
默认值:30000
监控锁的看门狗超时时间单位为毫秒。该参数只适用于分布式锁的加锁请求中未明确使用 leaseTimeout 参数的情况。如果该看门口未使用 lockWatchdogTimeout 去重新调整一个分布式锁的 lockWatchdogTimeout 超时,那么这个锁将变为失效状态。这个参数可以用来避免由 Redisson 客户端节点宕机或其他原因造成死锁的情况。
keepPubSubOrder(保持订阅发布顺序)
默认值:true
通过该参数来修改是否按订阅发布消息的接收顺序出来消息,如果选否将对消息实行并行处理,该参数只适用于订阅发布消息的情况。
performanceMode(高性能模式)
默认值:HIGHER_THROUGHPUT
用来指定高性能引擎的行为。由于该变量值的选用与使用场景息息相关(NORMAL 除外)我们建议对每个参数值都进行尝试。
该参数仅限于 Redisson PRO 版本。
可选模式:
HIGHER_THROUGHPUT - 将高性能引擎切换到 高通量 模式。
LOWER_LATENCY_AUTO - 将高性能引擎切换到 低延时 模式并自动探测最佳设定。
LOWER_LATENCY_MODE_1 - 将高性能引擎切换到 低延时 模式并调整到预设模式 1。
LOWER_LATENCY_MODE_2 - 将高性能引擎切换到 低延时 模式并调整到预设模式 2。
NORMAL - 将高性能引擎切换到 普通 模式
2.4. 集群模式
集群模式除了适用于 Redis 集群环境,也适用于任何云计算服务商提供的集群模式,例如 AWS ElastiCache 集群版、Azure Redis Cache 和阿里云(Aliyun)的云数据库 Redis 版。
程序化配置集群的用法:
Config config = new Config();
config.useClusterServers()
.setScanInterval(2000) // 集群状态扫描间隔时间,单位是毫秒
//可以用"rediss://"来启用SSL连接,前缀必须是redis:// or rediss://
// 以下两种写法效果是一样的
.addNodeAddress("redis://127.0.0.1:7000", "redis://127.0.0.1:7001")
.addNodeAddress("redis://127.0.0.1:7002");
RedissonClient redisson = Redisson.create(config);2.4.1. 集群设置
介绍配置 Redis 集群组态的文档在这里。 Redis 集群组态的最低要求是必须有三个主节点。Redisson 的集群模式的使用方法如下:
ClusterServersConfig clusterConfig = config.useClusterServers();
ClusterServersConfig 类的设置参数如下:
nodeAddresses(添加节点地址)
可以通过 host:port 的格式来添加 Redis 集群节点的地址。多个节点可以一次性批量添加。
scanInterval(集群扫描间隔时间)
默认值: 1000
对 Redis 集群节点状态扫描的时间间隔。单位是毫秒。
slots(分片数量)
默认值: 231 用于指定数据分片过程中的分片数量。支持数据分片 / 框架结构有:集(Set)、映射(Map)、BitSet、Bloom filter, Spring Cache 和 Hibernate Cache 等.
readMode(读取操作的负载均衡模式)
默认值: SLAVE(只在从服务节点里读取)
注:在从服务节点里读取的数据说明已经至少有两个节点保存了该数据,确保了数据的高可用性。
设置读取操作选择节点的模式。 可用值为: SLAVE - 只在从服务节点里读取。 MASTER - 只在主服务节点里读取。 MASTER_SLAVE - 在主从服务节点里都可以读取。
subscriptionMode(订阅操作的负载均衡模式)
默认值:SLAVE(只在从服务节点里订阅)
设置订阅操作选择节点的模式。 可用值为: SLAVE - 只在从服务节点里订阅。 MASTER - 只在主服务节点里订阅。
loadBalancer(负载均衡算法类的选择)
默认值: org.redisson.connection.balancer.RoundRobinLoadBalancer
在多 Redis 服务节点的环境里,可以选用以下几种负载均衡方式选择一个节点: org.redisson.connection.balancer.WeightedRoundRobinBalancer - 权重轮询调度算法 org.redisson.connection.balancer.RoundRobinLoadBalancer - 轮询调度算法
org.redisson.connection.balancer.RandomLoadBalancer - 随机调度算法
subscriptionConnectionMinimumIdleSize(从节点发布和订阅连接的最小空闲连接数)
默认值:1
多从节点的环境里,每个 从服务节点里用于发布和订阅连接的最小保持连接数(长连接)。Redisson 内部经常通过发布和订阅来实现许多功能。长期保持一定数量的发布订阅连接是必须的。
subscriptionConnectionPoolSize(从节点发布和订阅连接池大小)
默认值:50
多从节点的环境里,每个 从服务节点里用于发布和订阅连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
slaveConnectionMinimumIdleSize(从节点最小空闲连接数)
默认值:32
多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时读取反映速度。
slaveConnectionPoolSize(从节点连接池大小)
默认值:64
多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
masterConnectionMinimumIdleSize(主节点最小空闲连接数)
默认值:32
多从节点的环境里,每个 主节点的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时写入反应速度。
masterConnectionPoolSize(主节点连接池大小)
默认值:64
主节点的连接池最大容量。连接池的连接数量自动弹性伸缩。
idleConnectionTimeout(连接空闲超时,单位:毫秒)
默认值:10000
如果当前连接池里的连接数量超过了最小空闲连接数,而同时有连接空闲时间超过了该数值,那么这些连接将会自动被关闭,并从连接池里去掉。时间单位是毫秒。
connectTimeout(连接超时,单位:毫秒)
默认值:10000
同任何节点建立连接时的等待超时。时间单位是毫秒。
timeout(命令等待超时,单位:毫秒)
默认值:3000
等待节点回复命令的时间。该时间从命令发送成功时开始计时。
retryAttempts(命令失败重试次数)
默认值:3
如果尝试达到 retryAttempts(命令失败重试次数) 仍然不能将命令发送至某个指定的节点时,将抛出错误。如果尝试在此限制之内发送成功,则开始启用 timeout(命令等待超时) 计时。
retryInterval(命令重试发送时间间隔,单位:毫秒)
默认值:1500
在某个节点执行相同或不同命令时,连续 失败 failedAttempts(执行失败最大次数) 时,该节点将被从可用节点列表里清除,直到 reconnectionTimeout(重新连接时间间隔) 超时以后再次尝试。
password(密码)
默认值:null
用于节点身份验证的密码。
subscriptionsPerConnection(单个连接最大订阅数量)
默认值:5
每个连接的最大订阅数量。
clientName(客户端名称)
默认值:null
在 Redis 节点里显示的客户端名称。
sslEnableEndpointIdentification(启用 SSL 终端识别)
默认值:true
开启 SSL 终端识别能力。
sslProvider(SSL 实现方式)
默认值:JDK
确定采用哪种方式(JDK 或 OPENSSL)来实现 SSL 连接。
sslTruststore(SSL 信任证书库路径)
默认值:null
指定 SSL 信任证书库的路径。
sslTruststorePassword(SSL 信任证书库密码)
默认值:null
指定 SSL 信任证书库的密码。
sslKeystore(SSL 钥匙库路径)
默认值:null
指定 SSL 钥匙库的路径。
sslKeystorePassword(SSL 钥匙库密码)
默认值:null
指定 SSL 钥匙库的密码。
2.4.2. 通过 YAML 文件配置集群模式
配置集群模式可以通过指定一个 YAML 格式的文件来实现。以下是 YAML 格式的配置文件样本。文件中的字段名称必须与 ClusterServersConfig 和 Config 对象里的字段名称相符。
---
clusterServersConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
password: null
subscriptionsPerConnection: 5
clientName: null
loadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}
slaveSubscriptionConnectionMinimumIdleSize: 1
slaveSubscriptionConnectionPoolSize: 50
slaveConnectionMinimumIdleSize: 32
slaveConnectionPoolSize: 64
masterConnectionMinimumIdleSize: 32
masterConnectionPoolSize: 64
readMode: "SLAVE"
nodeAddresses:
- "redis://127.0.0.1:7004"
- "redis://127.0.0.1:7001"
- "redis://127.0.0.1:7000"
scanInterval: 1000
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"2.5. 云托管模式
云托管模式适用于任何由云计算运营商提供的 Redis 云服务,包括亚马逊云的 AWS ElastiCache、微软云的 Azure Redis 缓存和阿里云(Aliyun)的云数据库 Redis 版
程序化配置云托管模式的方法如下:
Config config = new Config();
config.useReplicatedServers()
.setScanInterval(2000) // 主节点变化扫描间隔时间
//可以用"rediss://"来启用SSL连接
.addNodeAddress("redis://127.0.0.1:7000", "redis://127.0.0.1:7001")
.addNodeAddress("redis://127.0.0.1:7002");
RedissonClient redisson = Redisson.create(config);2.5.1. 云托管模式设置
Redisson 的云托管模式的使用方法如下: ReplicatedServersConfig replicatedConfig = config.useReplicatedServers ();
ReplicatedServersConfig 类的设置参数如下:
nodeAddresses(节点地址)
可以通过 host:port 的格式来指定云托管模式的多个 Redis 集群节点的地址。多个节点可以一次性批量添加。所有的主从节点必须在配置阶段全部体现出来。
scanInterval(主节点变化扫描间隔时间)
默认值: 1000
对主节点变化节点状态扫描的时间间隔。单位是毫秒。
loadBalancer(负载均衡算法类的选择)
默认值: org.redisson.connection.balancer.RoundRobinLoadBalancer
在使用多个 Elasticache Redis 服务节点的环境里,可以选用以下几种负载均衡方式选择一个节点: org.redisson.connection.balancer.WeightedRoundRobinBalancer - 权重轮询调度算法 org.redisson.connection.balancer.RoundRobinLoadBalancer - 轮询调度算法 org.redisson.connection.balancer.RandomLoadBalancer - 随机调度算法
dnsMonitoringInterval(DNS 监控间隔,单位:毫秒)
默认值:5000
用来指定检查节点 DNS 变化的时间间隔。使用的时候应该确保 JVM 里的 DNS 数据的缓存时间保持在足够低的范围才有意义。用 - 1 来禁用该功能。
subscriptionConnectionMinimumIdleSize(从节点发布和订阅连接的最小空闲连接数)
默认值:1
多从节点的环境里,每个 从服务节点里用于发布和订阅连接的最小保持连接数(长连接)。Redisson 内部经常通过发布和订阅来实现许多功能。长期保持一定数量的发布订阅连接是必须的。
subscriptionConnectionPoolSize(从节点发布和订阅连接池大小)
默认值:50
多从节点的环境里,每个 从服务节点里用于发布和订阅连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
slaveConnectionMinimumIdleSize(从节点最小空闲连接数)
默认值:32
多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时读取反映速度。
slaveConnectionPoolSize(从节点连接池大小)
默认值:64
多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
masterConnectionMinimumIdleSize(主节点最小空闲连接数)
默认值:32
多从节点的环境里,每个 主节点的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时写入反应速度。
masterConnectionPoolSize(主节点连接池大小)
默认值:64
主节点的连接池最大容量。连接池的连接数量自动弹性伸缩。
idleConnectionTimeout(连接空闲超时,单位:毫秒)
默认值:10000
如果当前连接池里的连接数量超过了最小空闲连接数,而同时有连接空闲时间超过了该数值,那么这些连接将会自动被关闭,并从连接池里去掉。时间单位是毫秒。
readMode(读取操作的负载均衡模式)
默认值: SLAVE(只在从服务节点里读取)
注:在从服务节点里读取的数据说明已经至少有两个节点保存了该数据,确保了数据的高可用性。
设置读取操作选择节点的模式。 可用值为: SLAVE - 只在从服务节点里读取。 MASTER - 只在主服务节点里读取。 MASTER_SLAVE - 在主从服务节点里都可以读取。
subscriptionMode(订阅操作的负载均衡模式)
默认值:SLAVE(只在从服务节点里订阅)
设置订阅操作选择节点的模式。 可用值为: SLAVE - 只在从服务节点里订阅。 MASTER - 只在主服务节点里订阅。
connectTimeout(连接超时,单位:毫秒)
默认值:10000
同任何节点建立连接时的等待超时。时间单位是毫秒。
timeout(命令等待超时,单位:毫秒)
默认值:3000
等待节点回复命令的时间。该时间从命令发送成功时开始计时。
retryAttempts(命令失败重试次数)
默认值:3
如果尝试达到 retryAttempts(命令失败重试次数) 仍然不能将命令发送至某个指定的节点时,将抛出错误。如果尝试在此限制之内发送成功,则开始启用 timeout(命令等待超时) 计时。
retryInterval(命令重试发送时间间隔,单位:毫秒)
默认值:1500
在某个节点执行相同或不同命令时,连续 失败 failedAttempts(执行失败最大次数) 时,该节点将被从可用节点列表里清除,直到 reconnectionTimeout(重新连接时间间隔) 超时以后再次尝试。
database(数据库编号)
默认值:0
尝试连接的数据库编号。
password(密码)
默认值:null
用于节点身份验证的密码。
subscriptionsPerConnection(单个连接最大订阅数量)
默认值:5
每个连接的最大订阅数量。
clientName(客户端名称)
默认值:null
在 Redis 节点里显示的客户端名称。
sslEnableEndpointIdentification(启用 SSL 终端识别)
默认值:true
开启 SSL 终端识别能力。
sslProvider(SSL 实现方式)
默认值:JDK
确定采用哪种方式(JDK 或 OPENSSL)来实现 SSL 连接。
sslTruststore(SSL 信任证书库路径)
默认值:null
指定 SSL 信任证书库的路径。
sslTruststorePassword(SSL 信任证书库密码)
默认值:null
指定 SSL 信任证书库的密码。
sslKeystore(SSL 钥匙库路径)
默认值:null
指定 SSL 钥匙库的路径。
sslKeystorePassword(SSL 钥匙库密码)
默认值:null
指定 SSL 钥匙库的密码。
2.5.2. 通过 YAML 文件配置集群模式
配置云托管模式可以通过指定一个 YAML 格式的文件来实现。以下是 YAML 格式的配置文件样本。文件中的字段名称必须与 ReplicatedServersConfig 和 Config 对象里的字段名称相符。
---
replicatedServersConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
password: null
subscriptionsPerConnection: 5
clientName: null
loadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}
slaveSubscriptionConnectionMinimumIdleSize: 1
slaveSubscriptionConnectionPoolSize: 50
slaveConnectionMinimumIdleSize: 32
slaveConnectionPoolSize: 64
masterConnectionMinimumIdleSize: 32
masterConnectionPoolSize: 64
readMode: "SLAVE"
nodeAddresses:
- "redis://127.0.0.1:2812"
- "redis://127.0.0.1:2815"
- "redis://127.0.0.1:2813"
scanInterval: 1000
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"2.6. 单 Redis 节点模式
程序化配置方法:
// 默认连接地址 127.0.0.1:6379
RedissonClient redisson = Redisson.create();
Config config = new Config();
config.useSingleServer().setAddress("redis://myredisserver:6379");
RedissonClient redisson = Redisson.create(config);2.6.1. 单节点设置
Redis 程序的配置和架设文档在这里。Redisson 的单 Redis 节点模式的使用方法如下: SingleServerConfig singleConfig = config.useSingleServer ();
SingleServerConfig 类的设置参数如下:
address(节点地址)
可以通过 host:port 的格式来指定节点地址。
subscriptionConnectionMinimumIdleSize(发布和订阅连接的最小空闲连接数)
默认值:1
用于发布和订阅连接的最小保持连接数(长连接)。Redisson 内部经常通过发布和订阅来实现许多功能。长期保持一定数量的发布订阅连接是必须的。
subscriptionConnectionPoolSize(发布和订阅连接池大小)
默认值:50
用于发布和订阅连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
connectionMinimumIdleSize(最小空闲连接数)
默认值:32
最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时写入反应速度。
connectionPoolSize(连接池大小)
默认值:64
在启用该功能以后,Redisson 将会监测 DNS 的变化情况。
dnsMonitoringInterval(DNS 监测时间间隔,单位:毫秒)
默认值:5000
监测 DNS 的变化情况的时间间隔。
idleConnectionTimeout(连接空闲超时,单位:毫秒)
默认值:10000
如果当前连接池里的连接数量超过了最小空闲连接数,而同时有连接空闲时间超过了该数值,那么这些连接将会自动被关闭,并从连接池里去掉。时间单位是毫秒。
connectTimeout(连接超时,单位:毫秒)
默认值:10000
同节点建立连接时的等待超时。时间单位是毫秒。
timeout(命令等待超时,单位:毫秒)
默认值:3000
等待节点回复命令的时间。该时间从命令发送成功时开始计时。
retryAttempts(命令失败重试次数)
默认值:3
如果尝试达到 retryAttempts(命令失败重试次数) 仍然不能将命令发送至某个指定的节点时,将抛出错误。如果尝试在此限制之内发送成功,则开始启用 timeout(命令等待超时) 计时。
retryInterval(命令重试发送时间间隔,单位:毫秒)
默认值:1500
在某个节点执行相同或不同命令时,连续 失败 failedAttempts(执行失败最大次数) 时,该节点将被从可用节点列表里清除,直到 reconnectionTimeout(重新连接时间间隔) 超时以后再次尝试。
database(数据库编号)
默认值:0
尝试连接的数据库编号。
password(密码)
默认值:null
用于节点身份验证的密码。
subscriptionsPerConnection(单个连接最大订阅数量)
默认值:5
每个连接的最大订阅数量。
clientName(客户端名称)
默认值:null
在 Redis 节点里显示的客户端名称。
sslEnableEndpointIdentification(启用 SSL 终端识别)
默认值:true
开启 SSL 终端识别能力。
sslProvider(SSL 实现方式)
默认值:JDK
确定采用哪种方式(JDK 或 OPENSSL)来实现 SSL 连接。
sslTruststore(SSL 信任证书库路径)
默认值:null
指定 SSL 信任证书库的路径。
sslTruststorePassword(SSL 信任证书库密码)
默认值:null
指定 SSL 信任证书库的密码。
sslKeystore(SSL 钥匙库路径)
默认值:null
指定 SSL 钥匙库的路径。
sslKeystorePassword(SSL 钥匙库密码)
默认值:null
指定 SSL 钥匙库的密码。
2.6.2. 通过 YAML 文件配置集群模式
配置单节点模式可以通过指定一个 YAML 格式的文件来实现。以下是 YAML 格式的配置文件样本。文件中的字段名称必须与 SingleServerConfig 和 Config 对象里的字段名称相符。
---
singleServerConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
password: null
subscriptionsPerConnection: 5
clientName: null
address: "redis://127.0.0.1:6379"
subscriptionConnectionMinimumIdleSize: 1
subscriptionConnectionPoolSize: 50
connectionMinimumIdleSize: 32
connectionPoolSize: 64
database: 0
dnsMonitoringInterval: 5000
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"2.7. 哨兵模式
程序化配置哨兵模式的方法如下:
Config config = new Config();
config.useSentinelServers()
.setMasterName("mymaster")
//可以用"rediss://"来启用SSL连接
.addSentinelAddress("redis://127.0.0.1:26389", "redis://127.0.0.1:26379")
.addSentinelAddress("redis://127.0.0.1:26319");
RedissonClient redisson = Redisson.create(config);2.7.1. 哨兵模式设置
配置 Redis 哨兵服务的官方文档在这里。Redisson 的哨兵模式的使用方法如下: SentinelServersConfig sentinelConfig = config.useSentinelServers ();
SentinelServersConfig 类的设置参数如下:
dnsMonitoringInterval(DNS 监控间隔,单位:毫秒)
默认值:5000
用来指定检查节点 DNS 变化的时间间隔。使用的时候应该确保 JVM 里的 DNS 数据的缓存时间保持在足够低的范围才有意义。用 - 1 来禁用该功能。
masterName(主服务器的名称)
主服务器的名称是哨兵进程中用来监测主从服务切换情况的。
addSentinelAddress(添加哨兵节点地址)
可以通过 host:port 的格式来指定哨兵节点的地址。多个节点可以一次性批量添加。
readMode(读取操作的负载均衡模式)
默认值: SLAVE(只在从服务节点里读取)
注:在从服务节点里读取的数据说明已经至少有两个节点保存了该数据,确保了数据的高可用性。
设置读取操作选择节点的模式。 可用值为: SLAVE - 只在从服务节点里读取。 MASTER - 只在主服务节点里读取。 MASTER_SLAVE - 在主从服务节点里都可以读取。
subscriptionMode(订阅操作的负载均衡模式)
默认值:SLAVE(只在从服务节点里订阅)
设置订阅操作选择节点的模式。 可用值为: SLAVE - 只在从服务节点里订阅。 MASTER - 只在主服务节点里订阅。
loadBalancer(负载均衡算法类的选择)
默认值: org.redisson.connection.balancer.RoundRobinLoadBalancer
在使用多个 Redis 服务节点的环境里,可以选用以下几种负载均衡方式选择一个节点: org.redisson.connection.balancer.WeightedRoundRobinBalancer - 权重轮询调度算法 org.redisson.connection.balancer.RoundRobinLoadBalancer - 轮询调度算法 org.redisson.connection.balancer.RandomLoadBalancer - 随机调度算法
subscriptionConnectionMinimumIdleSize(从节点发布和订阅连接的最小空闲连接数)
默认值:1
多从节点的环境里,每个 从服务节点里用于发布和订阅连接的最小保持连接数(长连接)。Redisson 内部经常通过发布和订阅来实现许多功能。长期保持一定数量的发布订阅连接是必须的。
subscriptionConnectionPoolSize(从节点发布和订阅连接池大小)
默认值:50
多从节点的环境里,每个 从服务节点里用于发布和订阅连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
slaveConnectionMinimumIdleSize(从节点最小空闲连接数)
默认值:32
多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时读取反映速度。
slaveConnectionPoolSize(从节点连接池大小)
默认值:64
多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
masterConnectionMinimumIdleSize(主节点最小空闲连接数)
默认值:32
多从节点的环境里,每个 主节点的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时写入反应速度。
masterConnectionPoolSize(主节点连接池大小)
默认值:64
主节点的连接池最大容量。连接池的连接数量自动弹性伸缩。
idleConnectionTimeout(连接空闲超时,单位:毫秒)
默认值:10000
如果当前连接池里的连接数量超过了最小空闲连接数,而同时有连接空闲时间超过了该数值,那么这些连接将会自动被关闭,并从连接池里去掉。时间单位是毫秒。
connectTimeout(连接超时,单位:毫秒)
默认值:10000
同任何节点建立连接时的等待超时。时间单位是毫秒。
timeout(命令等待超时,单位:毫秒)
默认值:3000
等待节点回复命令的时间。该时间从命令发送成功时开始计时。
retryAttempts(命令失败重试次数)
默认值:3
如果尝试达到 retryAttempts(命令失败重试次数) 仍然不能将命令发送至某个指定的节点时,将抛出错误。如果尝试在此限制之内发送成功,则开始启用 timeout(命令等待超时) 计时。
retryInterval(命令重试发送时间间隔,单位:毫秒)
默认值:1500
在某个节点执行相同或不同命令时,连续 失败 failedAttempts(执行失败最大次数) 时,该节点将被从可用节点列表里清除,直到 reconnectionTimeout(重新连接时间间隔) 超时以后再次尝试。
database(数据库编号)
默认值:0
尝试连接的数据库编号。
password(密码)
默认值:null
用于节点身份验证的密码。
subscriptionsPerConnection(单个连接最大订阅数量)
默认值:5
每个连接的最大订阅数量。
clientName(客户端名称)
默认值:null
在 Redis 节点里显示的客户端名称。
sslEnableEndpointIdentification(启用 SSL 终端识别)
默认值:true
开启 SSL 终端识别能力。
sslProvider(SSL 实现方式)
默认值:JDK
确定采用哪种方式(JDK 或 OPENSSL)来实现 SSL 连接。
sslTruststore(SSL 信任证书库路径)
默认值:null
指定 SSL 信任证书库的路径。
sslTruststorePassword(SSL 信任证书库密码)
默认值:null
指定 SSL 信任证书库的密码。
sslKeystore(SSL 钥匙库路径)
默认值:null
指定 SSL 钥匙库的路径。
sslKeystorePassword(SSL 钥匙库密码)
默认值:null
指定 SSL 钥匙库的密码。
2.7.2. 通过 YAML 文件配置集群模式
配置哨兵模式可以通过指定一个 YAML 格式的文件来实现。以下是 YAML 格式的配置文件样本。文件中的字段名称必须与 SentinelServersConfig 和 Config 对象里的字段名称相符。
---
sentinelServersConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
password: null
subscriptionsPerConnection: 5
clientName: null
loadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}
slaveSubscriptionConnectionMinimumIdleSize: 1
slaveSubscriptionConnectionPoolSize: 50
slaveConnectionMinimumIdleSize: 32
slaveConnectionPoolSize: 64
masterConnectionMinimumIdleSize: 32
masterConnectionPoolSize: 64
readMode: "SLAVE"
sentinelAddresses:
- "redis://127.0.0.1:26379"
- "redis://127.0.0.1:26389"
masterName: "mymaster"
database: 0
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"2.8. 主从模式
程序化配置主从模式的用法:
Config config = new Config();
config.useMasterSlaveServers()
//可以用"rediss://"来启用SSL连接
.setMasterAddress("redis://127.0.0.1:6379")
.addSlaveAddress("redis://127.0.0.1:6389", "redis://127.0.0.1:6332", "redis://127.0.0.1:6419")
.addSlaveAddress("redis://127.0.0.1:6399");
RedissonClient redisson = Redisson.create(config);2.8.1. 主从模式设置
介绍配置 Redis 主从服务组态的文档在这里. Redisson 的主从模式的使用方法如下: MasterSlaveServersConfig masterSlaveConfig = config.useMasterSlaveServers ();
MasterSlaveServersConfig 类的设置参数如下:
dnsMonitoringInterval(DNS 监控间隔,单位:毫秒)
默认值:5000
用来指定检查节点 DNS 变化的时间间隔。使用的时候应该确保 JVM 里的 DNS 数据的缓存时间保持在足够低的范围才有意义。用 - 1 来禁用该功能。
masterAddress(主节点地址)
可以通过 host:port 的格式来指定主节点地址。
addSlaveAddress(添加从主节点地址)
可以通过 host:port 的格式来指定从节点的地址。多个节点可以一次性批量添加。
readMode(读取操作的负载均衡模式)
默认值: SLAVE(只在从服务节点里读取)
注:在从服务节点里读取的数据说明已经至少有两个节点保存了该数据,确保了数据的高可用性。
设置读取操作选择节点的模式。 可用值为: SLAVE - 只在从服务节点里读取。 MASTER - 只在主服务节点里读取。 MASTER_SLAVE - 在主从服务节点里都可以读取。
subscriptionMode(订阅操作的负载均衡模式)
默认值:SLAVE(只在从服务节点里订阅)
设置订阅操作选择节点的模式。 可用值为: SLAVE - 只在从服务节点里订阅。 MASTER - 只在主服务节点里订阅。
loadBalancer(负载均衡算法类的选择)
默认值: org.redisson.connection.balancer.RoundRobinLoadBalancer
在使用多个 Redis 服务节点的环境里,可以选用以下几种负载均衡方式选择一个节点: org.redisson.connection.balancer.WeightedRoundRobinBalancer - 权重轮询调度算法 org.redisson.connection.balancer.RoundRobinLoadBalancer - 轮询调度算法 org.redisson.connection.balancer.RandomLoadBalancer - 随机调度算法
subscriptionConnectionMinimumIdleSize(从节点发布和订阅连接的最小空闲连接数)
默认值:1
多从节点的环境里,每个 从服务节点里用于发布和订阅连接的最小保持连接数(长连接)。Redisson 内部经常通过发布和订阅来实现许多功能。长期保持一定数量的发布订阅连接是必须的。
subscriptionConnectionPoolSize(从节点发布和订阅连接池大小)
默认值:50
多从节点的环境里,每个 从服务节点里用于发布和订阅连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
slaveConnectionMinimumIdleSize(从节点最小空闲连接数)
默认值:32
多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时读取反映速度。
slaveConnectionPoolSize(从节点连接池大小)
默认值:64
多从节点的环境里,每个 从服务节点里用于普通操作(非 发布和订阅)连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
masterConnectionMinimumIdleSize(主节点最小空闲连接数)
默认值:32
多从节点的环境里,每个 主节点的最小保持连接数(长连接)。长期保持一定数量的连接有利于提高瞬时写入反应速度。
masterConnectionPoolSize(主节点连接池大小)
默认值:64
主节点的连接池最大容量。连接池的连接数量自动弹性伸缩。
idleConnectionTimeout(连接空闲超时,单位:毫秒)
默认值:10000
如果当前连接池里的连接数量超过了最小空闲连接数,而同时有连接空闲时间超过了该数值,那么这些连接将会自动被关闭,并从连接池里去掉。时间单位是毫秒。
connectTimeout(连接超时,单位:毫秒)
默认值:10000
同任何节点建立连接时的等待超时。时间单位是毫秒。
timeout(命令等待超时,单位:毫秒)
默认值:3000
等待节点回复命令的时间。该时间从命令发送成功时开始计时。
retryAttempts(命令失败重试次数)
默认值:3
如果尝试达到 retryAttempts(命令失败重试次数) 仍然不能将命令发送至某个指定的节点时,将抛出错误。如果尝试在此限制之内发送成功,则开始启用 timeout(命令等待超时) 计时。
retryInterval(命令重试发送时间间隔,单位:毫秒)
默认值:1500
在某个节点执行相同或不同命令时,连续 失败 failedAttempts(执行失败最大次数) 时,该节点将被从可用节点列表里清除,直到 reconnectionTimeout(重新连接时间间隔) 超时以后再次尝试。
database(数据库编号)
默认值:0
尝试连接的数据库编号。
password(密码)
默认值:null
用于节点身份验证的密码。
subscriptionsPerConnection(单个连接最大订阅数量)
默认值:5
每个连接的最大订阅数量。
clientName(客户端名称)
默认值:null
在 Redis 节点里显示的客户端名称。
sslEnableEndpointIdentification(启用 SSL 终端识别)
默认值:true
开启 SSL 终端识别能力。
sslProvider(SSL 实现方式)
默认值:JDK
确定采用哪种方式(JDK 或 OPENSSL)来实现 SSL 连接。
sslTruststore(SSL 信任证书库路径)
默认值:null
指定 SSL 信任证书库的路径。
sslTruststorePassword(SSL 信任证书库密码)
默认值:null
指定 SSL 信任证书库的密码。
sslKeystore(SSL 钥匙库路径)
默认值:null
指定 SSL 钥匙库的路径。
sslKeystorePassword(SSL 钥匙库密码)
默认值:null
指定 SSL 钥匙库的密码。
2.8.2. 通过 YAML 文件配置集群模式
配置主从模式可以通过指定一个 YAML 格式的文件来实现。以下是 YAML 格式的配置文件样本。文件中的字段名称必须与 MasterSlaveServersConfig 和 Config 对象里的字段名称相符。
---
masterSlaveServersConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
failedAttempts: 3
password: null
subscriptionsPerConnection: 5
clientName: null
loadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}
slaveSubscriptionConnectionMinimumIdleSize: 1
slaveSubscriptionConnectionPoolSize: 50
slaveConnectionMinimumIdleSize: 32
slaveConnectionPoolSize: 64
masterConnectionMinimumIdleSize: 32
masterConnectionPoolSize: 64
readMode: "SLAVE"
slaveAddresses:
- "redis://127.0.0.1:6381"
- "redis://127.0.0.1:6380"
masterAddress: "redis://127.0.0.1:6379"
database: 0
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"三、程序接口调用方式
RedissonClient、RedissonReactiveClient 和 RedissonRxClient 实例本身和 Redisson 提供的所有分布式对象都是线程安全的。
Redisson 为每个操作都提供了自动重试策略,当某个命令执行失败时,Redisson 会自动进行重试。自动重试策略可以通过修改 retryAttempts(默认值:3)参数和 retryInterval(默认值:1000 毫秒)参数来进行优化调整。当等待时间达到 retryInterval 指定的时间间隔以后,将自动重试下一次。全部重试失败以后将抛出错误。
Redisson 框架提供的几乎所有对象都包含了同步和异步相互匹配的方法。这些对象都可以通过 RedissonClient 接口获取。同时还为大部分 Redisson 对象提供了满足异步流处理标准的程序接口 RedissonReactiveClient。除此外还提供了 RxJava2 规范的 RedissonRxClient 程序接口。
以下是关于使用 RAtomicLong 对象的范例:
RedissonClient client = Redisson.create(config);
RAtomicLong longObject = client.getAtomicLong('myLong');
// 同步执行方式
longObject.compareAndSet(3, 401);
// 异步执行方式
RFuture<Boolean> result = longObject.compareAndSetAsync(3, 401);
RedissonReactiveClient client = Redisson.createReactive(config);
RAtomicLongReactive longObject = client.getAtomicLong('myLong');
// 异步流执行方式
Mono<Boolean> result = longObject.compareAndSet(3, 401);
RedissonRxClient client = Redisson.createRx(config);
RAtomicLongRx longObject= client.getAtomicLong("myLong");
// RxJava2方式
Flowable<Boolean result = longObject.compareAndSet(3, 401);3.1. 异步执行方式
几乎所有的 Redisson 对象都实现了一个异步接口,异步接口提供的方法名称与其同步接口的方法名称相互匹配。例如:
// RAtomicLong接口继承了RAtomicLongAsync接口
RAtomicLongAsync longObject = client.getAtomicLong("myLong");
RFuture<Boolean> future = longObject.compareAndSetAsync(1, 401);异步执行的方法都会返回一个实现了 RFuture 接口的对象。该对象同时提供了 java.util.concurrent.CompletionStage 和 java.util.concurrent.Future 两个异步接口。
future.whenComplete((res, exception) -> {
// ...
});
// 或者
future.thenAccept(res -> {
// 处理返回
}).exceptionally(exception -> {
// 处理错误
});3.2. 异步流执行方式
Redisson 为大多数分布式数据结构提供了满足 Reactor 项目的异步流处理标准的程序接口。该接口通过两种方式实现:
1. 基于 Project Reactor 标准的实现方式。使用范例如下:
RedissonReactiveClient client = Redisson.createReactive(config);
RAtomicLongReactive atomicLong = client.getAtomicLong("myLong");
Mono<Boolean> cs = longObject.compareAndSet(10, 91);
Mono<Long> get = longObject.get();
Publisher<Long> getPublisher = longObject.get();2. 基于 RxJava2 标准的实现方式。使用范例如下:
RedissonRxClient client = Redisson.createRx(config);
RAtomicLongRx atomicLong = client.getAtomicLong("myLong");
Single<Boolean> cs = longObject.compareAndSet(10, 91);
Single<Long> get = longObject.get();四、数据序列化
Redisson 的对象编码类是用于将对象进行序列化和反序列化,以实现对该对象在 Redis 里的读取和存储。Redisson 提供了以下几种的对象编码应用,以供大家选择:
| 编码类名称 | 说明 |
|---|---|
| org.redisson.codec.JsonJacksonCodec | Jackson JSON 编码 默认编码 |
| org.redisson.codec.AvroJacksonCodec | Avro 一个二进制的 JSON 编码 |
| org.redisson.codec.SmileJacksonCodec | Smile 另一个二进制的 JSON 编码 |
| org.redisson.codec.CborJacksonCodec | CBOR 又一个二进制的 JSON 编码 |
| org.redisson.codec.MsgPackJacksonCodec | MsgPack 再来一个二进制的 JSON 编码 |
| org.redisson.codec.IonJacksonCodec | Amazon Ion 亚马逊的 Ion 编码,格式与 JSON 类似 |
| org.redisson.codec.KryoCodec | Kryo 二进制对象序列化编码 |
| org.redisson.codec.SerializationCodec | JDK 序列化编码 |
| org.redisson.codec.FstCodec | FST 10 倍于 JDK 序列化性能而且 100% 兼容的编码 |
| org.redisson.codec.LZ4Codec | LZ4 压缩型序列化对象编码 |
| org.redisson.codec.SnappyCodec | Snappy 另一个压缩型序列化对象编码 |
| org.redisson.client.codec.JsonJacksonMapCodec | 基于 Jackson 的映射类使用的编码。可用于避免序列化类的信息,以及用于解决使用 byte [] 遇到的问题。 |
| org.redisson.client.codec.StringCodec | 纯字符串编码(无转换) |
| org.redisson.client.codec.LongCodec | 纯整长型数字编码(无转换) |
| org.redisson.client.codec.ByteArrayCodec | 字节数组编码 |
| org.redisson.codec.CompositeCodec | 用来组合多种不同编码在一起 |
五、单个集合数据分片(Sharding)
在集群模式下,Redisson 为单个 Redis 集合类型提供了自动分片的功能。
Redisson 提供的所有数据结构都支持在集群环境下使用,但每个数据结构只被保存在一个固定的槽内。Redisson PRO 提供的自动分片功能能够将单个数据结构拆分,然后均匀的分布在整个集群里,而不是被挤在单一一个槽里。自动分片功能的优势主要有以下几点:
- 单个数据结构可以充分利用整个集群内存资源,而不是被某一个节点的内存限制。
- 将单个数据结构分片以后分布在集群中不同的节点里,不仅可以大幅提高读写性能,还能够保证读写性能随着集群的扩张而自动提升。
Redisson 通过自身的分片算法,将一个大集合拆分为若干个片段(默认 231 个,分片数量范围是 3 - 16834),然后将拆分后的片段均匀的分布到集群里各个节点里,保证每个节点分配到的片段数量大体相同。比如在默认情况下 231 个片段分到含有 4 个主节点的集群里,每个主节点将会分配到大约 57 个片段,同样的道理如果有 5 个主节点,每个节点会分配到大约 46 个片段。
目前支持的数据结构类型和服务包括集(Set)、映射(Map)、BitSet、布隆过滤器(Bloom Filter)、Spring Cache 和 Hibernate Cache。
该功能仅限于 Redisson PRO 版本。
六、分布式对象
每个 Redisson 对象实例都会有一个与之对应的 Redis 数据实例,可以通过调用 getName 方法来取得 Redis 数据实例的名称(key)。
RMap map = redisson.getMap("mymap");
map.getName(); // = mymap所有与 Redis key 相关的操作都归纳在 RKeys 这个接口里:
RKeys keys = redisson.getKeys();
Iterable<String> allKeys = keys.getKeys();
Iterable<String> foundedKeys = keys.getKeysByPattern('key*');
long numOfDeletedKeys = keys.delete("obj1", "obj2", "obj3");
long deletedKeysAmount = keys.deleteByPattern("test?");
String randomKey = keys.randomKey();
long keysAmount = keys.count();6.1. 通用对象桶(Object Bucket)
Redisson 的分布式 RBucketJava 对象是一种通用对象桶可以用来存放任类型的对象。 除了同步接口外,还提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。
RBucket<AnyObject> bucket = redisson.getBucket("anyObject");
bucket.set(new AnyObject(1));
AnyObject obj = bucket.get();
bucket.trySet(new AnyObject(3));
bucket.compareAndSet(new AnyObject(4), new AnyObject(5));
bucket.getAndSet(new AnyObject(6));还可以通过 RBuckets 接口实现批量操作多个 RBucket 对象:
RBuckets buckets = redisson.getBuckets();
List<RBucket<V>> foundBuckets = buckets.find("myBucket*");
Map<String, V> loadedBuckets = buckets.get("myBucket1", "myBucket2", "myBucket3");
Map<String, Object> map = new HashMap<>();
map.put("myBucket1", new MyObject());
map.put("myBucket2", new MyObject());
// 利用Redis的事务特性,同时保存所有的通用对象桶,如果任意一个通用对象桶已经存在则放弃保存其他所有数据。
buckets.trySet(map);
// 同时保存全部通用对象桶。
buckets.set(map);6.2. 二进制流(Binary Stream)
Redisson 的分布式 RBinaryStream Java 对象同时提供了 InputStream 接口和 OutputStream 接口的实现。流的最大容量受 Redis 主节点的内存大小限制。
RBinaryStream stream = redisson.getBinaryStream("anyStream");
byte[] content = ...
stream.set(content);
InputStream is = stream.getInputStream();
byte[] readBuffer = new byte[512];
is.read(readBuffer);
OutputStream os = stream.getOuputStream();
byte[] contentToWrite = ...
os.write(contentToWrite);6.3. 地理空间对象桶(Geospatial Bucket)
Redisson 的分布式 RGeo Java 对象是一种专门用来储存与地理位置有关的对象桶。除了同步接口外,还提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。
RGeo<String> geo = redisson.getGeo("test");
geo.add(new GeoEntry(13.361389, 38.115556, "Palermo"),
new GeoEntry(15.087269, 37.502669, "Catania"));
geo.addAsync(37.618423, 55.751244, "Moscow");
Double distance = geo.dist("Palermo", "Catania", GeoUnit.METERS);
geo.hashAsync("Palermo", "Catania");
Map<String, GeoPosition> positions = geo.pos("test2", "Palermo", "test3", "Catania", "test1");
List<String> cities = geo.radius(15, 37, 200, GeoUnit.KILOMETERS);
Map<String, GeoPosition> citiesWithPositions = geo.radiusWithPosition(15, 37, 200, GeoUnit.KILOMETERS);6.4. BitSet
Redisson 的分布式 RBitSetJava 对象采用了与 java.util.BiteSet 类似结构的设计风格。可以理解为它是一个分布式的可伸缩式位向量。需要注意的是 RBitSet 的大小受 Redis 限制,最大长度为 4 294 967 295。除了同步接口外,还提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。
RBitSet set = redisson.getBitSet("simpleBitset");
set.set(0, true);
set.set(1812, false);
set.clear(0);
set.addAsync("e");
set.xor("anotherBitset");6.4.1. BitSet 数据分片(Sharding)(分布式 RoaringBitMap)
基于 Redis 的 Redisson 集群分布式 BitSet 通过 RClusteredBitSet 接口,为集群状态下的 Redis 环境提供了 BitSet 数据分片的功能。通过优化后更加有效的分布式 RoaringBitMap 算法,突破了原有的 BitSet 大小限制,达到了集群物理内存容量大小。在这里可以获取更多的内部信息。
RClusteredBitSet set = redisson.getClusteredBitSet("simpleBitset");
set.set(0, true);
set.set(1812, false);
set.clear(0);
set.addAsync("e");
set.xor("anotherBitset");该功能仅限于 Redisson PRO 版本。
6.5. 原子整长形(AtomicLong)
Redisson 的分布式整长形 RAtomicLong 对象和 Java 中的 java.util.concurrent.atomic.AtomicLong 对象类似。除了同步接口外,还提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。
RAtomicLong atomicLong = redisson.getAtomicLong("myAtomicLong");
atomicLong.set(3);
atomicLong.incrementAndGet();
atomicLong.get();6.6. 原子双精度浮点(AtomicDouble)
Redisson 还提供了分布式原子双精度浮点 RAtomicDouble,弥补了 Java 自身的不足。除了同步接口外,还提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。
RAtomicDouble atomicDouble = redisson.getAtomicDouble("myAtomicDouble");
atomicDouble.set(2.81);
atomicDouble.addAndGet(4.11);
atomicDouble.get();6.7. 话题(订阅分发)
Redisson 的分布式话题 RTopic (http://static.javadoc.io/org.redisson/redisson/3.10.0/org/redisson/api/RTopic.html 对象实现了发布、订阅的机制。除了同步接口外,还提供了异步(Async (http://static.javadoc.io/org.redisson/redisson/3.10.0/org/redisson/api/RTopicAsync.html))、反射式(Reactive (http://static.javadoc.io/org.redisson/redisson/3.10.0/org/redisson/api/RTopicReactive.html))和 RxJava2 (http://static.javadoc.io/org.redisson/redisson/3.10.0/org/redisson/api/RTopicRx.html) 标准的接口。
RTopic topic = redisson.getTopic("anyTopic");
topic.addListener(SomeObject.class, new MessageListener<SomeObject>() {
@Override
public void onMessage(String channel, SomeObject message) {
//...
}
});
// 在其他线程或JVM节点
RTopic topic = redisson.getTopic("anyTopic");
long clientsReceivedMessage = topic.publish(new SomeObject());在 Redis 节点故障转移(主从切换)或断线重连以后,所有的话题监听器将自动完成话题的重新订阅。
6.7.1. 模糊话题
Redisson 的模糊话题 RPatternTopic 对象可以通过正式表达式来订阅多个话题。除了同步接口外,还提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。
// 订阅所有满足`topic1.*`表达式的话题
RPatternTopic topic1 = redisson.getPatternTopic("topic1.*");
int listenerId = topic1.addListener(Message.class, new PatternMessageListener<Message>() {
@Override
public void onMessage(String pattern, String channel, Message msg) {
Assert.fail();
}
});在 Redis 节点故障转移(主从切换)或断线重连以后,所有的模糊话题监听器将自动完成话题的重新订阅。
6.8. 布隆过滤器(Bloom Filter)
Redisson 利用 Redis 实现了 Java 分布式布隆过滤器(Bloom Filter)。所含最大比特数量为 232。
RBloomFilter<SomeObject> bloomFilter = redisson.getBloomFilter("sample");
// 初始化布隆过滤器,预计统计元素数量为55000000,期望误差率为0.03
bloomFilter.tryInit(55000000L, 0.03);
bloomFilter.add(new SomeObject("field1Value", "field2Value"));
bloomFilter.add(new SomeObject("field5Value", "field8Value"));
bloomFilter.contains(new SomeObject("field1Value", "field8Value"));6.8.1. 布隆过滤器数据分片(Sharding)
基于 Redis 的 Redisson 集群分布式布隆过滤器通过 RClusteredBloomFilter 接口,为集群状态下的 Redis 环境提供了布隆过滤器数据分片的功能。 通过优化后更加有效的算法,通过压缩未使用的比特位来释放集群内存空间。每个对象的状态都将被分布在整个集群中。所含最大比特数量为 2^64。在这里可以获取更多的内部信息。
RClusteredBloomFilter<SomeObject> bloomFilter = redisson.getClusteredBloomFilter("sample");
// 采用以下参数创建布隆过滤器
// expectedInsertions = 255000000
// falseProbability = 0.03
bloomFilter.tryInit(255000000L, 0.03);
bloomFilter.add(new SomeObject("field1Value", "field2Value"));
bloomFilter.add(new SomeObject("field5Value", "field8Value"));
bloomFilter.contains(new SomeObject("field1Value", "field8Value"));该功能仅限于 Redisson PRO 版本。
6.9. 基数估计算法(HyperLogLog)
Redisson 利用 Redis 实现了 Java 分布式基数估计算法(HyperLogLog)对象。该对象可以在有限的空间内通过概率算法统计大量的数据。除了同步接口外,还提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。
RHyperLogLog<Integer> log = redisson.getHyperLogLog("log");
log.add(1);
log.add(2);
log.add(3);
log.count();6.10. 整长型累加器(LongAdder)
基于 Redis 的 Redisson 分布式整长型累加器(LongAdder)采用了与 java.util.concurrent.atomic.LongAdder 类似的接口。通过利用客户端内置的 LongAdder 对象,为分布式环境下递增和递减操作提供了很高得性能。据统计其性能最高比分布式 AtomicLong 对象快 12000 倍。完美适用于分布式统计计量场景。
RLongAdder atomicLong = redisson.getLongAdder("myLongAdder");
atomicLong.add(12);
atomicLong.increment();
atomicLong.decrement();
atomicLong.sum();当不再使用整长型累加器对象的时候应该自行手动销毁,如果 Redisson 对象被关闭(shutdown)了,则不用手动销毁。
RLongAdder atomicLong = ...
atomicLong.destroy();6.11. 双精度浮点累加器(DoubleAdder)
基于 Redis 的 Redisson 分布式双精度浮点累加器(DoubleAdder)采用了与 java.util.concurrent.atomic.DoubleAdder 类似的接口。通过利用客户端内置的 DoubleAdder 对象,为分布式环境下递增和递减操作提供了很高得性能。据统计其性能最高比分布式 AtomicDouble 对象快 12000 倍。完美适用于分布式统计计量场景。
RLongDouble atomicDouble = redisson.getLongDouble("myLongDouble");
atomicDouble.add(12);
atomicDouble.increment();
atomicDouble.decrement();
atomicDouble.sum();当不再使用双精度浮点累加器对象的时候应该自行手动销毁,如果 Redisson 对象被关闭(shutdown)了,则不用手动销毁。
RLongDouble atomicDouble = ...
_b6d2063_
atomicDouble.destroy();6.12. 限流器(RateLimiter)
基于 Redis 的分布式限流器(RateLimiter)可以用来在分布式环境下现在请求方的调用频率。既适用于不同 Redisson 实例下的多线程限流,也适用于相同 Redisson 实例下的多线程限流。该算法不保证公平性。除了同步接口外,还提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。
RRateLimiter rateLimiter = redisson.getRateLimiter("myRateLimiter");
// 初始化
// 最大流速 = 每1秒钟产生10个令牌
rateLimiter.trySetRate(RateType.OVERALL, 10, 1, RateIntervalUnit.SECONDS);
CountDownLatch latch = new CountDownLatch(2);
limiter.acquire(3);
// ...
Thread t = new Thread(() -> {
limiter.acquire(2);
// ...
});七、分布式集合
7.1. 映射(Map)
基于 Redis 的 Redisson 的分布式映射结构的 RMap Java 对象实现了 java.util.concurrent.ConcurrentMap 接口和 java.util.Map 接口。与 HashMap 不同的是,RMap 保持了元素的插入顺序。该对象的最大容量受 Redis 限制,最大元素数量是 4 294 967 295 个。
除了同步接口外,还提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。如果你想用 Redis Map 来保存你的 POJO 的话,可以考虑使用分布式实时对象(Live Object)服务。
在特定的场景下,映射缓存(Map)上的高度频繁的读取操作,使网络通信都被视为瓶颈时,可以使用 Redisson 提供的带有本地缓存功能的映射。
RMap<String, SomeObject> map = redisson.getMap("anyMap");
SomeObject prevObject = map.put("123", new SomeObject());
SomeObject currentObject = map.putIfAbsent("323", new SomeObject());
SomeObject obj = map.remove("123");
map.fastPut("321", new SomeObject());
map.fastRemove("321");
RFuture<SomeObject> putAsyncFuture = map.putAsync("321");
RFuture<Void> fastPutAsyncFuture = map.fastPutAsync("321");
map.fastPutAsync("321", new SomeObject());
map.fastRemoveAsync("321");映射的字段锁的用法:
RMap<MyKey, MyValue> map = redisson.getMap("anyMap");
MyKey k = new MyKey();
RLock keyLock = map.getLock(k);
keyLock.lock();
try {
MyValue v = map.get(k);
// 其他业务逻辑
} finally {
keyLock.unlock();
}
RReadWriteLock rwLock = map.getReadWriteLock(k);
rwLock.readLock().lock();
try {
MyValue v = map.get(k);
// 其他业务逻辑
} finally {
keyLock.readLock().unlock();
}7.1.1. 映射(Map)的元素淘汰(Eviction),本地缓存(LocalCache)和数据分片(Sharding)
Redisson 提供了一系列的映射类型的数据结构,这些结构按特性主要分为三大类:
-
元素淘汰(Eviction) 类 – 带有元素淘汰(Eviction)机制的映射类允许针对一个映射中每个元素单独设定 有效时间 和 最长闲置时间 。
-
本地缓存(LocalCache) 类 – 本地缓存(Local Cache)也叫就近缓存(Near Cache)。这类映射的使用主要用于在特定的场景下,映射缓存(MapCache)上的高度频繁的读取操作,使网络通信都被视为瓶颈的情况。Redisson 与 Redis 通信的同时,还将部分数据保存在本地内存里。这样的设计的好处是它能将读取速度提高最多 45 倍 。 所有同名的本地缓存共用一个订阅发布话题,所有更新和过期消息都将通过该话题共享。
-
数据分片(Sharding) 类 – 数据分片(Sharding)类仅适用于 Redis 集群环境下,因此带有数据分片(Sharding)功能的映射也叫集群分布式映射。它利用分库的原理,将单一一个映射结构切分为若干个小的映射,并均匀的分布在集群中的各个槽里。这样的设计能使一个单一映射结构突破 Redis 自身的容量限制,让其容量随集群的扩大而增长。在扩容的同时,还能够使读写性能和元素淘汰处理能力随之成线性增长。
以下列表是 Redisson 提供的所有映射的名称及其特性: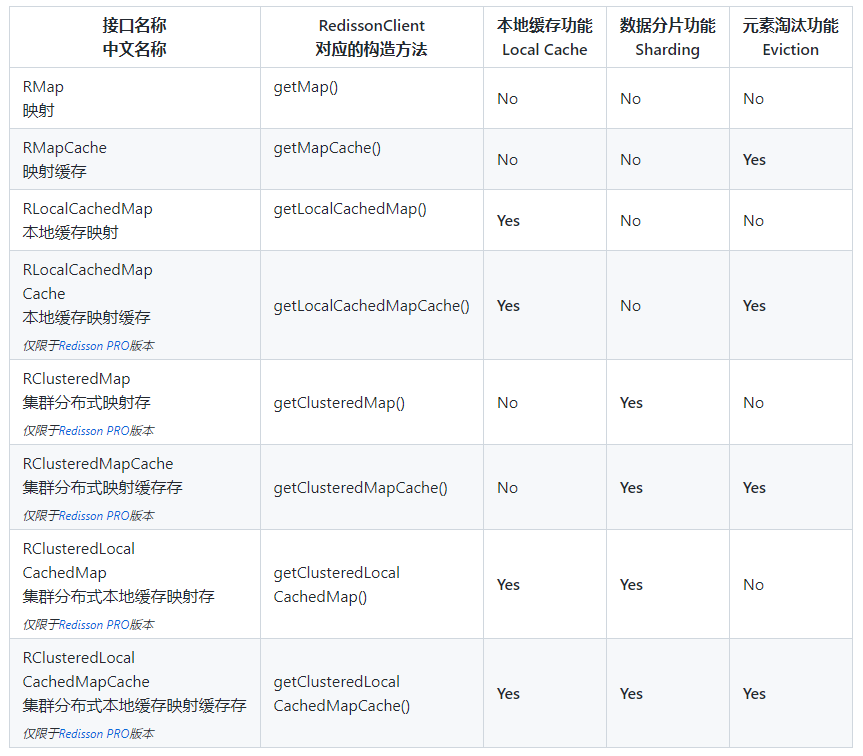
除此以外,Redisson 还提供了 Spring Cache 和 JCache 的实现。
元素淘汰功能(Eviction)
Redisson 的分布式的 RMapCache Java 对象在基于 RMap 的前提下实现了针对单个元素的淘汰机制。同时仍然保留了元素的插入顺序。由于 RMapCache 是基于 RMap 实现的,使它同时继承了 java.util.concurrent.ConcurrentMap 接口和 java.util.Map 接口。Redisson 提供的 Spring Cache 整合以及 JCache 正是基于这样的功能来实现的。
目前的 Redis 自身并不支持散列(Hash)当中的元素淘汰,因此所有过期元素都是通过 org.redisson.EvictionScheduler 实例来实现定期清理的。为了保证资源的有效利用,每次运行最多清理 300 个过期元素。任务的启动时间将根据上次实际清理数量自动调整,间隔时间趋于 1 秒到 1 小时之间。比如该次清理时删除了 300 条元素,那么下次执行清理的时间将在 1 秒以后(最小间隔时间)。一旦该次清理数量少于上次清理数量,时间间隔将增加 1.5 倍。
RMapCache<String, SomeObject> map = redisson.getMapCache("anyMap");
// 有效时间 ttl = 10分钟
map.put("key1", new SomeObject(), 10, TimeUnit.MINUTES);
// 有效时间 ttl = 10分钟, 最长闲置时间 maxIdleTime = 10秒钟
map.put("key1", new SomeObject(), 10, TimeUnit.MINUTES, 10, TimeUnit.SECONDS);
// 有效时间 = 3 秒钟
map.putIfAbsent("key2", new SomeObject(), 3, TimeUnit.SECONDS);
// 有效时间 ttl = 40秒钟, 最长闲置时间 maxIdleTime = 10秒钟
map.putIfAbsent("key2", new SomeObject(), 40, TimeUnit.SECONDS, 10, TimeUnit.SECONDS);本地缓存功能(Local Cache)
在特定的场景下,映射(Map)上的高度频繁的读取操作,使网络通信都被视为瓶颈时,使用 Redisson 提供的带有本地缓存功能的分布式本地缓存映射 RLocalCachedMapJava 对象会是一个很好的选择。它同时实现了 java.util.concurrent.ConcurrentMap 和 java.util.Map 两个接口。本地缓存功能充分的利用了 JVM 的自身内存空间,对部分常用的元素实行就地缓存,这样的设计让读取操作的性能较分布式映射相比提高最多 45 倍 。以下配置参数可以用来创建这个实例:
LocalCachedMapOptions options = LocalCachedMapOptions.defaults()
// 用于淘汰清除本地缓存内的元素
// 共有以下几种选择:
// LFU - 统计元素的使用频率,淘汰用得最少(最不常用)的。
// LRU - 按元素使用时间排序比较,淘汰最早(最久远)的。
// SOFT - 元素用Java的WeakReference来保存,缓存元素通过GC过程清除。
// WEAK - 元素用Java的SoftReference来保存, 缓存元素通过GC过程清除。
// NONE - 永不淘汰清除缓存元素。
.evictionPolicy(EvictionPolicy.NONE)
// 如果缓存容量值为0表示不限制本地缓存容量大小
.cacheSize(1000)
// 以下选项适用于断线原因造成了未收到本地缓存更新消息的情况。
// 断线重连的策略有以下几种:
// CLEAR - 如果断线一段时间以后则在重新建立连接以后清空本地缓存
// LOAD - 在服务端保存一份10分钟的作废日志
// 如果10分钟内重新建立连接,则按照作废日志内的记录清空本地缓存的元素
// 如果断线时间超过了这个时间,则将清空本地缓存中所有的内容
// NONE - 默认值。断线重连时不做处理。
.reconnectionStrategy(ReconnectionStrategy.NONE)
// 以下选项适用于不同本地缓存之间相互保持同步的情况
// 缓存同步策略有以下几种:
// INVALIDATE - 默认值。当本地缓存映射的某条元素发生变动时,同时驱逐所有相同本地缓存映射内的该元素
// UPDATE - 当本地缓存映射的某条元素发生变动时,同时更新所有相同本地缓存映射内的该元素
// NONE - 不做任何同步处理
.syncStrategy(SyncStrategy.INVALIDATE)
// 每个Map本地缓存里元素的有效时间,默认毫秒为单位
.timeToLive(10000)
// 或者
.timeToLive(10, TimeUnit.SECONDS)
// 每个Map本地缓存里元素的最长闲置时间,默认毫秒为单位
.maxIdle(10000)
// 或者
.maxIdle(10, TimeUnit.SECONDS);RLocalCachedMap<String, Integer> map = redisson.getLocalCachedMap("test", options);
String prevObject = map.put("123", 1);
String currentObject = map.putIfAbsent("323", 2);
String obj = map.remove("123");
// 在不需要旧值的情况下可以使用fast为前缀的类似方法
map.fastPut("a", 1);
map.fastPutIfAbsent("d", 32);
map.fastRemove("b");
RFuture<String> putAsyncFuture = map.putAsync("321");
RFuture<Void> fastPutAsyncFuture = map.fastPutAsync("321");
map.fastPutAsync("321", new SomeObject());
map.fastRemoveAsync("321");当不再使用 Map 本地缓存对象的时候应该手动销毁,如果 Redisson 对象被关闭(shutdown)了,则不用手动销毁。
RLocalCachedMap<String, Integer> map = ...
map.destroy();如何通过加载数据的方式来降低过期淘汰事件发布信息对网络的影响
代码范例:
public void loadData(String cacheName, Map<String, String> data) {
RLocalCachedMap<String, String> clearMap = redisson.getLocalCachedMap(cacheName,
LocalCachedMapOptions.defaults().cacheSize(1).syncStrategy(SyncStrategy.INVALIDATE));
RLocalCachedMap<String, String> loadMap = redisson.getLocalCachedMap(cacheName,
LocalCachedMapOptions.defaults().cacheSize(1).syncStrategy(SyncStrategy.NONE));
loadMap.putAll(data);
clearMap.clearLocalCache();
}数据分片功能(Sharding)
Map 数据分片是 Redis 集群模式下的一个功能。Redisson 提供的分布式集群映射 RClusteredMap Java 对象也是基于 RMap 实现的。它同时实现了 java.util.concurrent.ConcurrentMap 和 java.util.Map 两个接口。
RClusteredMap<String, SomeObject> map = redisson.getClusteredMap("anyMap");
SomeObject prevObject = map.put("123", new SomeObject());
SomeObject currentObject = map.putIfAbsent("323", new SomeObject());
SomeObject obj = map.remove("123");
map.fastPut("321", new SomeObject());
map.fastRemove("321");7.1.2. 映射持久化方式(缓存策略)
Redisson 供了将映射中的数据持久化到外部储存服务的功能。主要场景有一下几种:
- 将 Redisson 的分布式映射类型作为业务和外部储存媒介之间的缓存。
- 或是用来增加 Redisson 映射类型中数据的持久性,或是用来增加已被驱逐的数据的寿命。
- 或是用来缓存数据库,Web 服务或其他数据源的数据。
Read-through 策略
通俗的讲,如果一个被请求的数据不存在于 Redisson 的映射中的时候,Redisson 将通过预先配置好的 MapLoader 对象加载数据。
Write-through(数据同步写入)策略
在遇到映射中某条数据被更改时,Redisson 会首先通过预先配置好的 MapWriter 对象写入到外部储存系统,然后再更新 Redis 内的数据。
Write-behind(数据异步写入)策略
对映射的数据的更改会首先写入到 Redis,然后再使用异步的方式,通过 MapWriter 对象写入到外部储存系统。在并发环境下可以通过 writeBehindThreads 参数来控制写入线程的数量,已达到对外部储存系统写入并发量的控制。
以上策略适用于所有实现了 RMap、RMapCache、RLocalCachedMap 和 RLocalCachedMapCache 接口的对象。
配置范例:
MapOptions<K, V> options = MapOptions.<K, V>defaults()
.writer(myWriter)
.loader(myLoader);
RMap<K, V> map = redisson.getMap("test", options);
// 或
RMapCache<K, V> map = redisson.getMapCache("test", options);
// 或
RLocalCachedMap<K, V> map = redisson.getLocalCachedMap("test", options);
// 或
RLocalCachedMapCache<K, V> map = redisson.getLocalCachedMapCache("test", options);7.1.3. 映射监听器(Map Listener)
Redisson 为所有实现了 RMapCache 或 RLocalCachedMapCache 接口的对象提供了监听以下事件的监听器:
事件 | 监听器 元素 添加 事件 | org.redisson.api.map.event.EntryCreatedListener
元素 过期 事件 | org.redisson.api.map.event.EntryExpiredListener
元素 删除 事件 | org.redisson.api.map.event.EntryRemovedListener
元素 更新 事件 | org.redisson.api.map.event.EntryUpdatedListener
使用范例:
RMapCache<String, Integer> map = redisson.getMapCache("myMap");
// 或
RLocalCachedMapCache<String, Integer> map = redisson.getLocalCachedMapCache("myMap", options);
int updateListener = map.addListener(new EntryUpdatedListener<Integer, Integer>() {
@Override
public void onUpdated(EntryEvent<Integer, Integer> event) {
event.getKey(); // 字段名
event.getValue() // 新值
event.getOldValue() // 旧值
// ...
}
});
int createListener = map.addListener(new EntryCreatedListener<Integer, Integer>() {
@Override
public void onCreated(EntryEvent<Integer, Integer> event) {
event.getKey(); // 字段名
event.getValue() // 值
// ...
}
});
int expireListener = map.addListener(new EntryExpiredListener<Integer, Integer>() {
@Override
public void onExpired(EntryEvent<Integer, Integer> event) {
event.getKey(); // 字段名
event.getValue() // 值
// ...
}
});
int removeListener = map.addListener(new EntryRemovedListener<Integer, Integer>() {
@Override
public void onRemoved(EntryEvent<Integer, Integer> event) {
event.getKey(); // 字段名
event.getValue() // 值
// ...
}
});
map.removeListener(updateListener);
map.removeListener(createListener);
map.removeListener(expireListener);
map.removeListener(removeListener);7.1.4. LRU 有界映射
Redisson 提供了基于 Redis 的以 LRU 为驱逐策略的分布式 LRU 有界映射对象。顾名思义,分布式 LRU 有界映射允许通过对其中元素按使用时间排序处理的方式,主动移除超过规定容量限制的元素。
RMapCache<String, String> map = redisson.getMapCache("map");
// 尝试将该映射的最大容量限制设定为10
map.trySetMaxSize(10);
// 将该映射的最大容量限制设定或更改为10
map.setMaxSize(10);
map.put("1", "2");
map.put("3", "3", 1, TimeUnit.SECONDS);7.2. 多值映射(Multimap)
基于 Redis 的 Redisson 的分布式 RMultimap Java 对象允许 Map 中的一个字段值包含多个元素。 字段总数受 Redis 限制,每个 Multimap 最多允许有 4 294 967 295 个不同字段。
7.2.1. 基于集(Set)的多值映射(Multimap)
基于 Set 的 Multimap 不允许一个字段值包含有重复的元素。
RSetMultimap<SimpleKey, SimpleValue> map = redisson.getSetMultimap("myMultimap");
map.put(new SimpleKey("0"), new SimpleValue("1"));
map.put(new SimpleKey("0"), new SimpleValue("2"));
map.put(new SimpleKey("3"), new SimpleValue("4"));
Set<SimpleValue> allValues = map.get(new SimpleKey("0"));
List<SimpleValue> newValues = Arrays.asList(new SimpleValue("7"), new SimpleValue("6"), new SimpleValue("5"));
Set<SimpleValue> oldValues = map.replaceValues(new SimpleKey("0"), newValues);
Set<SimpleValue> removedValues = map.removeAll(new SimpleKey("0"));7.2.2. 基于列表(List)的多值映射(Multimap)
基于 List 的 Multimap 在保持插入顺序的同时允许一个字段下包含重复的元素。
RListMultimap<SimpleKey, SimpleValue> map = redisson.getListMultimap("test1");
map.put(new SimpleKey("0"), new SimpleValue("1"));
map.put(new SimpleKey("0"), new SimpleValue("2"));
map.put(new SimpleKey("0"), new SimpleValue("1"));
map.put(new SimpleKey("3"), new SimpleValue("4"));
List<SimpleValue> allValues = map.get(new SimpleKey("0"));
Collection<SimpleValue> newValues = Arrays.asList(new SimpleValue("7"), new SimpleValue("6"), new SimpleValue("5"));
List<SimpleValue> oldValues = map.replaceValues(new SimpleKey("0"), newValues);
List<SimpleValue> removedValues = map.removeAll(new SimpleKey("0"));7.2.3. 多值映射(Multimap)淘汰机制(Eviction)
Multimap 对象的淘汰机制是通过不同的接口来实现的。它们是 RSetMultimapCache 接口和 RListMultimapCache 接口,分别对应的是 Set 和 List 的 Multimaps。
所有过期元素都是通过 org.redisson.EvictionScheduler 实例来实现定期清理的。为了保证资源的有效利用,每次运行最多清理 100 个过期元素。任务的启动时间将根据上次实际清理数量自动调整,间隔时间趋于 1 秒到 2 小时之间。比如该次清理时删除了 100 条元素,那么下次执行清理的时间将在 1 秒以后(最小间隔时间)。一旦该次清理数量少于上次清理数量,时间间隔将增加 1.5 倍。
RSetMultimapCache 的使用范例:
RSetMultimapCache<String, String> multimap = redisson.getSetMultimapCache("myMultimap");
multimap.put("1", "a");
multimap.put("1", "b");
multimap.put("1", "c");
multimap.put("2", "e");
multimap.put("2", "f");
multimap.expireKey("2", 10, TimeUnit.MINUTES);7.3. 集(Set)
基于 Redis 的 Redisson 的分布式 Set 结构的 RSet Java 对象实现了 java.util.Set 接口。通过元素的相互状态比较保证了每个元素的唯一性。该对象的最大容量受 Redis 限制,最大元素数量是 4 294 967 295 个。
RSet<SomeObject> set = redisson.getSet("anySet");
set.add(new SomeObject());
set.remove(new SomeObject());Redisson PRO 版本中的 Set 对象还可以在 Redis 集群环境下支持单集合数据分片。
7.3.1. 集(Set)淘汰机制(Eviction)
基于 Redis 的 Redisson 的分布式 RSetCache Java 对象在基于 RSet 的前提下实现了针对单个元素的淘汰机制。由于 RSetCache 是基于 RSet 实现的,使它还集成了 java.util.Set 接口。
目前的 Redis 自身并不支持 Set 当中的元素淘汰,因此所有过期元素都是通过 org.redisson.EvictionScheduler 实例来实现定期清理的。为了保证资源的有效利用,每次运行最多清理 100 个过期元素。任务的启动时间将根据上次实际清理数量自动调整,间隔时间趋于 1 秒到 2 小时之间。比如该次清理时删除了 100 条元素,那么下次执行清理的时间将在 1 秒以后(最小间隔时间)。一旦该次清理数量少于上次清理数量,时间间隔将增加 1.5 倍。
RSetCache<SomeObject> set = redisson.getSetCache("anySet");
// ttl = 10 seconds
set.add(new SomeObject(), 10, TimeUnit.SECONDS);7.3.2. 集(Set)数据分片(Sharding)
Set 数据分片是 Redis 集群模式下的一个功能。Redisson 提供的分布式 RClusteredSet Java 对象也是基于 RSet 实现的。在这里可以获取更多的信息。
RClusteredSet<SomeObject> set = redisson.getClusteredSet("anySet");
set.add(new SomeObject());
set.remove(new SomeObject());除了 RClusteredSet 以外,Redisson 还提供了另一种集群模式下的分布式集(Set),它不仅提供了透明的数据分片功能,还为每个元素提供了淘汰机制。RClusteredSetCache 类分别同时提供了 RClusteredSet 和 RSetCache 这两个接口的实现。当然这些都是基于 java.util.Set 的接口实现上的。
该功能仅限于 Redisson PRO 版本。
7.4. 有序集(SortedSet)
基于 Redis 的 Redisson 的分布式 RSortedSet Java 对象实现了 java.util.SortedSet 接口。在保证元素唯一性的前提下,通过比较器(Comparator)接口实现了对元素的排序。
RSortedSet<Integer> set = redisson.getSortedSet("anySet");
set.trySetComparator(new MyComparator()); // 配置元素比较器
set.add(3);
set.add(1);
set.add(2);
set.removeAsync(0);
set.addAsync(5);7.5. 计分排序集(ScoredSortedSet)
基于 Redis 的 Redisson 的分布式 RScoredSortedSet Java 对象是一个可以按插入时指定的元素评分排序的集合。它同时还保证了元素的唯一性。
RScoredSortedSet<SomeObject> set = redisson.getScoredSortedSet("simple");
set.add(0.13, new SomeObject(a, b));
set.addAsync(0.251, new SomeObject(c, d));
set.add(0.302, new SomeObject(g, d));
set.pollFirst();
set.pollLast();
int index = set.rank(new SomeObject(g, d)); // 获取元素在集合中的位置
Double score = set.getScore(new SomeObject(g, d)); // 获取元素的评分7.6. 字典排序集(LexSortedSet)
基于 Redis 的 Redisson 的分布式 RLexSortedSet Java 对象在实现了 java.util.Set 接口的同时,将其中的所有字符串元素按照字典顺序排列。它公式还保证了字符串元素的唯一性。
RLexSortedSet set = redisson.getLexSortedSet("simple");
set.add("d");
set.addAsync("e");
set.add("f");
set.lexRangeTail("d", false);
set.lexCountHead("e");
set.lexRange("d", true, "z", false);7.7. 列表(List)
基于 Redis 的 Redisson 分布式列表(List)结构的 RList Java 对象在实现了 java.util.List 接口的同时,确保了元素插入时的顺序。该对象的最大容量受 Redis 限制,最大元素数量是 4 294 967 295 个。
RList<SomeObject> list = redisson.getList("anyList");
list.add(new SomeObject());
list.get(0);
list.remove(new SomeObject());7.8. 队列(Queue)
基于 Redis 的 Redisson 分布式无界队列(Queue)结构的 RQueue Java 对象实现了 java.util.Queue 接口。尽管 RQueue 对象无初始大小(边界)限制,但对象的最大容量受 Redis 限制,最大元素数量是 4 294 967 295 个。
RQueue<SomeObject> queue = redisson.getQueue("anyQueue");
queue.add(new SomeObject());
SomeObject obj = queue.peek();
SomeObject someObj = queue.poll();7.9. 双端队列(Deque)
基于 Redis 的 Redisson 分布式无界双端队列(Deque)结构的 RDeque Java 对象实现了 java.util.Deque 接口。尽管 RDeque 对象无初始大小(边界)限制,但对象的最大容量受 Redis 限制,最大元素数量是 4 294 967 295 个。
RDeque<SomeObject> queue = redisson.getDeque("anyDeque");
queue.addFirst(new SomeObject());
queue.addLast(new SomeObject());
SomeObject obj = queue.removeFirst();
SomeObject someObj = queue.removeLast();7.10. 阻塞队列(Blocking Queue)
基于 Redis 的 Redisson 分布式无界阻塞队列(Blocking Queue)结构的 RBlockingQueue Java 对象实现了 java.util.concurrent.BlockingQueue 接口。尽管 RBlockingQueue 对象无初始大小(边界)限制,但对象的最大容量受 Redis 限制,最大元素数量是 4 294 967 295 个。
RBlockingQueue<SomeObject> queue = redisson.getBlockingQueue("anyQueue");
queue.offer(new SomeObject());
SomeObject obj = queue.peek();
SomeObject someObj = queue.poll();
SomeObject ob = queue.poll(10, TimeUnit.MINUTES);poll, pollFromAny, pollLastAndOfferFirstTo 和 take 方法内部采用话题订阅发布实现,在 Redis 节点故障转移(主从切换)或断线重连以后,内置的相关话题监听器将自动完成话题的重新订阅。
7.11. 有界阻塞队列(Bounded Blocking Queue)
基于 Redis 的 Redisson 分布式有界阻塞队列(Bounded Blocking Queue)结构的 RBoundedBlockingQueue Java 对象实现了 java.util.concurrent.BlockingQueue 接口。该对象的最大容量受 Redis 限制,最大元素数量是 4 294 967 295 个。队列的初始容量(边界)必须在使用前设定好。
RBoundedBlockingQueue<SomeObject> queue = redisson.getBoundedBlockingQueue("anyQueue");
// 如果初始容量(边界)设定成功则返回`真(true)`,
// 如果初始容量(边界)已近存在则返回`假(false)`。
queue.trySetCapacity(2);
queue.offer(new SomeObject(1));
queue.offer(new SomeObject(2));
// 此时容量已满,下面代码将会被阻塞,直到有空闲为止。
queue.put(new SomeObject());
SomeObject obj = queue.peek();
SomeObject someObj = queue.poll();
SomeObject ob = queue.poll(10, TimeUnit.MINUTES);poll, pollFromAny, pollLastAndOfferFirstTo 和 take 方法内部采用话题订阅发布实现,在 Redis 节点故障转移(主从切换)或断线重连以后,内置的相关话题监听器将自动完成话题的重新订阅。
7.12. 阻塞双端队列(Blocking Deque)
基于 Redis 的 Redisson 分布式无界阻塞双端队列(Blocking Deque)结构的 RBlockingDeque Java 对象实现了 java.util.concurrent.BlockingDeque 接口。尽管 RBlockingDeque 对象无初始大小(边界)限制,但对象的最大容量受 Redis 限制,最大元素数量是 4 294 967 295 个。
RBlockingDeque<Integer> deque = redisson.getBlockingDeque("anyDeque");
deque.putFirst(1);
deque.putLast(2);
Integer firstValue = queue.takeFirst();
Integer lastValue = queue.takeLast();
Integer firstValue = queue.pollFirst(10, TimeUnit.MINUTES);
Integer lastValue = queue.pollLast(3, TimeUnit.MINUTES);poll, pollFromAny, pollLastAndOfferFirstTo 和 take 方法内部采用话题订阅发布实现,在 Redis 节点故障转移(主从切换)或断线重连以后,内置的相关话题监听器将自动完成话题的重新订阅。
7.13. 阻塞公平队列(Blocking Fair Queue)
基于 Redis 的 Redisson 分布式无界阻塞公平队列(Blocking Fair Queue)结构的 RBlockingFairQueue Java 对象在实现 Redisson 分布式无界阻塞队列(Blocking Queue)结构 RBlockingQueue 接口的基础上,解决了多个队列消息的处理者在复杂的网络环境下,网络延时的影响使 “较远” 的客户端最终收到消息数量低于 “较近” 的客户端的问题。从而解决了这种现象引发的个别处理节点过载的情况。
以分布式无界阻塞队列为基础,采用公平获取消息的机制,不仅保证了 poll、pollFromAny、pollLastAndOfferFirstTo 和 take 方法获取消息的先入顺序,还能让队列里的消息被均匀的发布到处在复杂分布式环境中的各个处理节点里。
RBlockingFairQueue queue = redisson.getBlockingFairQueue("myQueue");
queue.offer(new SomeObject());
SomeObject obj = queue.peek();
SomeObject someObj = queue.poll();
SomeObject ob = queue.poll(10, TimeUnit.MINUTES);该功能仅限于 Redisson PRO 版本。
7.14. 阻塞公平双端队列(Blocking Fair Deque)
基于 Redis 的 Redisson 分布式无界阻塞公平双端队列(Blocking Fair Deque)结构的 RBlockingFairDeque Java 对象在实现 Redisson 分布式无界阻塞双端队列(Blocking Deque)结构 RBlockingDeque 接口的基础上,解决了多个队列消息的处理者在复杂的网络环境下,网络延时的影响使 “较远” 的客户端最终收到消息数量低于 “较近” 的客户端的问题。从而解决了这种现象引发的个别处理节点过载的情况。
以分布式无界阻塞双端队列为基础,采用公平获取消息的机制,不仅保证了 poll、take、pollFirst、takeFirst、pollLast 和 takeLast 方法获取消息的先入顺序,还能让队列里的消息被均匀的发布到处在复杂分布式环境中的各个处理节点里。
RBlockingFairDeque deque = redisson.getBlockingFairDeque("myDeque");
deque.offer(new SomeObject());
SomeObject firstElement = queue.peekFirst();
SomeObject firstElement = queue.pollFirst();
SomeObject firstElement = queue.pollFirst(10, TimeUnit.MINUTES);
SomeObject firstElement = queue.takeFirst();
SomeObject lastElement = queue.peekLast();
SomeObject lastElement = queue.pollLast();
SomeObject lastElement = queue.pollLast(10, TimeUnit.MINUTES);
SomeObject lastElement = queue.takeLast();该功能仅限于 Redisson PRO 版本。
7.15. 延迟队列(Delayed Queue)
基于 Redis 的 Redisson 分布式延迟队列(Delayed Queue)结构的 RDelayedQueue Java 对象在实现了 RQueue 接口的基础上提供了向队列按要求延迟添加项目的功能。该功能可以用来实现消息传送延迟按几何增长或几何衰减的发送策略。
RQueue<String> distinationQueue = ...
RDelayedQueue<String> delayedQueue = getDelayedQueue(distinationQueue);
// 10秒钟以后将消息发送到指定队列
delayedQueue.offer("msg1", 10, TimeUnit.SECONDS);
// 一分钟以后将消息发送到指定队列
delayedQueue.offer("msg2", 1, TimeUnit.MINUTES);在该对象不再需要的情况下,应该主动销毁。仅在相关的 Redisson 对象也需要关闭的时候可以不用主动销毁。
RDelayedQueue<String> delayedQueue = ...
delayedQueue.destroy();7.16. 优先队列(Priority Queue)
基于 Redis 的 Redisson 分布式优先队列(Priority Queue)Java 对象实现了 java.util.Queue 的接口。可以通过比较器(Comparator)接口来对元素排序。
RPriorityQueue<Integer> queue = redisson.getPriorityQueue("anyQueue");
queue.trySetComparator(new MyComparator()); // 指定对象比较器
queue.add(3);
queue.add(1);
queue.add(2);
queue.removeAsync(0);
queue.addAsync(5);
queue.poll();7.17. 优先双端队列(Priority Deque)
基于 Redis 的 Redisson 分布式优先双端队列(Priority Deque)Java 对象实现了 java.util.Deque 的接口。可以通过比较器(Comparator)接口来对元素排序。
RPriorityDeque<Integer> queue = redisson.getPriorityDeque("anyQueue");
queue.trySetComparator(new MyComparator()); // 指定对象比较器
queue.addLast(3);
queue.addFirst(1);
queue.add(2);
queue.removeAsync(0);
queue.addAsync(5);
queue.pollFirst();
queue.pollLast();7.18. 优先阻塞队列(Priority Blocking Queue)
基于 Redis 的分布式无界优先阻塞队列(Priority Blocking Queue)Java 对象的结构与 java.util.concurrent.PriorityBlockingQueue 类似。可以通过比较器(Comparator)接口来对元素排序。PriorityBlockingQueue 的最大容量是 4 294 967 295 个元素。
RPriorityBlockingQueue<Integer> queue = redisson.getPriorityBlockingQueue("anyQueue");
queue.trySetComparator(new MyComparator()); // 指定对象比较器
queue.add(3);
queue.add(1);
queue.add(2);
queue.removeAsync(0);
queue.addAsync(5);
queue.take();当 Redis 服务端断线重连以后,或 Redis 服务端发生主从切换,并重新建立连接后,断线时正在使用 poll,pollLastAndOfferFirstTo 或 take 方法的对象 Redisson 将自动再次为其订阅相关的话题。
7.19. 优先阻塞双端队列(Priority Blocking Deque)
基于 Redis 的分布式无界优先阻塞双端队列(Priority Blocking Deque)Java 对象实现了 java.util.Deque 的接口。addLast、 addFirst、push 方法不能再这个对里使用。PriorityBlockingDeque 的最大容量是 4 294 967 295 个元素。
RPriorityBlockingDeque<Integer> queue = redisson.getPriorityBlockingDeque("anyQueue");
queue.trySetComparator(new MyComparator()); // 指定对象比较器
queue.add(2);
queue.removeAsync(0);
queue.addAsync(5);
queue.pollFirst();
queue.pollLast();
queue.takeFirst();
queue.takeLast();当 Redis 服务端断线重连以后,或 Redis 服务端发生主从切换,并重新建立连接后,断线时正在使用 poll,pollLastAndOfferFirstTo 或 take 方法的对象 Redisson 将自动再次为其订阅相关的话题。
八、分布式锁和同步器(重要!)
8.1. 可重入锁(Reentrant Lock)
基于 Redis 的 Redisson 分布式可重入锁 RLock Java 对象实现了 java.util.concurrent.locks.Lock 接口。同时还提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。
RLock lock = redisson.getLock("anyLock");
// 最常见的使用方法
lock.lock();大家都知道,如果负责储存这个分布式锁的 Redisson 节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson 内部提供了一个监控锁的看门狗,它的作用是在 Redisson 实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是 30 秒钟,也可以通过修改 Config.lockWatchdogTimeout 来另行指定。
另外 Redisson 还通过加锁的方法提供了 leaseTime 的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
// 加锁以后10秒钟自动解锁
// 无需调用unlock方法手动解锁
lock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}Redisson 同时还为分布式锁提供了异步执行的相关方法:
RLock lock = redisson.getLock("anyLock");
lock.lockAsync();
lock.lockAsync(10, TimeUnit.SECONDS);
Future<Boolean> res = lock.tryLockAsync(100, 10, TimeUnit.SECONDS);RLock 对象完全符合 Java 的 Lock 规范。也就是说只有拥有锁的进程才能解锁,其他进程解锁则会抛出 IllegalMonitorStateException 错误。但是如果遇到需要其他进程也能解锁的情况,请使用分布式信号量 Semaphore 对象.
使用范例
@ResponseBody
@GetMapping(value = "/hello")
public String hello() {
//1、获取一把锁,只要锁的名字一样,就是同一把锁
RLock myLock = redisson.getLock("my-lock");
//2、加锁
myLock.lock(); //阻塞式等待。默认加的锁都是30s
//1)、锁的自动续期,如果业务超长,运行期间自动锁上新的30s。不用担心业务时间长,锁自动过期被删掉
//2)、加锁的业务只要运行完成,就不会给当前锁续期,即使不手动解锁,锁默认会在30s内自动过期,不会产生死锁问题
// myLock.lock(10,TimeUnit.SECONDS); //10秒钟自动解锁,自动解锁时间一定要大于业务执行时间
//问题:在锁时间到了以后,不会自动续期(不会启动看门狗机制)
//1、如果我们传递了锁的超时时间,就发送给redis执行脚本,进行占锁,默认超时就是 我们指定的时间
//2、如果我们未指定锁的超时时间,就使用 lockWatchdogTimeout = 30 * 1000 【看门狗默认时间】
//只要占锁成功,就会启动一个定时任务【重新给锁设置过期时间,新的过期时间就是看门狗的默认时间】,每隔10秒都会自动的再次续期,续成30秒
// internalLockLeaseTime 【看门狗时间】 / 3, 10s
try {
System.out.println("加锁成功,执行业务..." + Thread.currentThread().getId());
try { TimeUnit.SECONDS.sleep(20); } catch (InterruptedException e) { e.printStackTrace(); }
} catch (Exception ex) {
ex.printStackTrace();
} finally {
//3、解锁 假设解锁代码没有运行,Redisson会不会出现死锁
System.out.println("释放锁..." + Thread.currentThread().getId());
myLock.unlock();
}
return "hello";
}8.2. 公平锁(Fair Lock)
基于 Redis 的 Redisson 分布式可重入公平锁也是实现了 java.util.concurrent.locks.Lock 接口的一种 RLock 对象。同时还提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。它保证了当多个 Redisson 客户端线程同时请求加锁时,优先分配给先发出请求的线程。所有请求线程会在一个队列中排队,当某个线程出现宕机时,Redisson 会等待 5 秒后继续下一个线程,也就是说如果前面有 5 个线程都处于等待状态,那么后面的线程会等待至少 25 秒。
RLock fairLock = redisson.getFairLock("anyLock");
// 最常见的使用方法
fairLock.lock();大家都知道,如果负责储存这个分布式锁的 Redis 节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson 内部提供了一个监控锁的看门狗,它的作用是在 Redisson 实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是 30 秒钟,也可以通过修改 Config.lockWatchdogTimeout 来另行指定。
另外 Redisson 还通过加锁的方法提供了 leaseTime 的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
// 10秒钟以后自动解锁
// 无需调用unlock方法手动解锁
fairLock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = fairLock.tryLock(100, 10, TimeUnit.SECONDS);
...
fairLock.unlock();Redisson 同时还为分布式可重入公平锁提供了异步执行的相关方法:
RLock fairLock = redisson.getFairLock("anyLock");
fairLock.lockAsync();
fairLock.lockAsync(10, TimeUnit.SECONDS);
Future<Boolean> res = fairLock.tryLockAsync(100, 10, TimeUnit.SECONDS);8.3. 联锁(MultiLock)
基于 Redis 的 Redisson 分布式联锁 RedissonMultiLock 对象可以将多个 RLock 对象关联为一个联锁,每个 RLock 对象实例可以来自于不同的 Redisson 实例。
RLock lock1 = redissonInstance1.getLock("lock1");
RLock lock2 = redissonInstance2.getLock("lock2");
RLock lock3 = redissonInstance3.getLock("lock3");
RedissonMultiLock lock = new RedissonMultiLock(lock1, lock2, lock3);
// 同时加锁:lock1 lock2 lock3
// 所有的锁都上锁成功才算成功。
lock.lock();
...
lock.unlock();大家都知道,如果负责储存某些分布式锁的某些 Redis 节点宕机以后,而且这些锁正好处于锁住的状态时,这些锁会出现锁死的状态。为了避免这种情况的发生,Redisson 内部提供了一个监控锁的看门狗,它的作用是在 Redisson 实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是 30 秒钟,也可以通过修改 Config.lockWatchdogTimeout 来另行指定。
另外 Redisson 还通过加锁的方法提供了 leaseTime 的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
RedissonMultiLock lock = new RedissonMultiLock(lock1, lock2, lock3);
// 给lock1,lock2,lock3加锁,如果没有手动解开的话,10秒钟后将会自动解开
lock.lock(10, TimeUnit.SECONDS);
// 为加锁等待100秒时间,并在加锁成功10秒钟后自动解开
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();8.4. 红锁(RedLock)
基于 Redis 的 Redisson 红锁 RedissonRedLock 对象实现了 Redlock 介绍的加锁算法。该对象也可以用来将多个 RLock 对象关联为一个红锁,每个 RLock 对象实例可以来自于不同的 Redisson 实例。
RLock lock1 = redissonInstance1.getLock("lock1");
RLock lock2 = redissonInstance2.getLock("lock2");
RLock lock3 = redissonInstance3.getLock("lock3");
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);
// 同时加锁:lock1 lock2 lock3
// 红锁在大部分节点上加锁成功就算成功。
lock.lock();
...
lock.unlock();大家都知道,如果负责储存某些分布式锁的某些 Redis 节点宕机以后,而且这些锁正好处于锁住的状态时,这些锁会出现锁死的状态。为了避免这种情况的发生,Redisson 内部提供了一个监控锁的看门狗,它的作用是在 Redisson 实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是 30 秒钟,也可以通过修改 Config.lockWatchdogTimeout 来另行指定。
另外 Redisson 还通过加锁的方法提供了 leaseTime 的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);
// 给lock1,lock2,lock3加锁,如果没有手动解开的话,10秒钟后将会自动解开
lock.lock(10, TimeUnit.SECONDS);
// 为加锁等待100秒时间,并在加锁成功10秒钟后自动解开
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();8.5. 读写锁(ReadWriteLock)
基于 Redis 的 Redisson 分布式可重入读写锁 RReadWriteLock Java 对象实现了 java.util.concurrent.locks.ReadWriteLock 接口。其中读锁和写锁都继承了 RLock 接口。
分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。
RReadWriteLock rwlock = redisson.getReadWriteLock("anyRWLock");
// 最常见的使用方法
rwlock.readLock().lock();
// 或
rwlock.writeLock().lock();大家都知道,如果负责储存这个分布式锁的 Redis 节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson 内部提供了一个监控锁的看门狗,它的作用是在 Redisson 实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是 30 秒钟,也可以通过修改 Config.lockWatchdogTimeout 来另行指定。
另外 Redisson 还通过加锁的方法提供了 leaseTime 的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
// 10秒钟以后自动解锁
// 无需调用unlock方法手动解锁
rwlock.readLock().lock(10, TimeUnit.SECONDS);
// 或
rwlock.writeLock().lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = rwlock.readLock().tryLock(100, 10, TimeUnit.SECONDS);
// 或
boolean res = rwlock.writeLock().tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();使用范例
/**
* 保证一定能读到最新数据,修改期间,写锁是一个排它锁(互斥锁、独享锁),读锁是一个共享锁
* 写锁没释放读锁必须等待
* 读 + 读 :相当于无锁,并发读,只会在Redis中记录好,所有当前的读锁。他们都会同时加锁成功
* 写 + 读 :必须等待写锁释放
* 写 + 写 :阻塞方式
* 读 + 写 :有读锁。写也需要等待
* 只要有读或者写的存都必须等待
* @return
*/
@GetMapping(value = "/write")
@ResponseBody
public String writeValue() {
String s = "";
RReadWriteLock readWriteLock = redisson.getReadWriteLock("rw-lock");
RLock rLock = readWriteLock.writeLock();
try {
//1、改数据加写锁,读数据加读锁
rLock.lock();
s = UUID.randomUUID().toString();
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
ops.set("writeValue",s);
TimeUnit.SECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
rLock.unlock();
}
return s;
}
@GetMapping(value = "/read")
@ResponseBody
public String readValue() {
String s = "";
RReadWriteLock readWriteLock = redisson.getReadWriteLock("rw-lock");
//加读锁
RLock rLock = readWriteLock.readLock();
try {
rLock.lock();
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
s = ops.get("writeValue");
try { TimeUnit.SECONDS.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); }
} catch (Exception e) {
e.printStackTrace();
} finally {
rLock.unlock();
}
return s;
}8.6. 信号量(Semaphore)
基于 Redis 的 Redisson 的分布式信号量(Semaphore)Java 对象 RSemaphore 采用了与 java.util.concurrent.Semaphore 相似的接口和用法。同时还提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。
RSemaphore semaphore = redisson.getSemaphore("semaphore");
semaphore.acquire();
//或
semaphore.acquireAsync();
semaphore.acquire(23);
semaphore.tryAcquire();
//或
semaphore.tryAcquireAsync();
semaphore.tryAcquire(23, TimeUnit.SECONDS);
//或
semaphore.tryAcquireAsync(23, TimeUnit.SECONDS);
semaphore.release(10);
semaphore.release();
//或
semaphore.releaseAsync();使用范例
/**
* 车库停车
* 3车位
* 信号量也可以做分布式限流
*/
@GetMapping(value = "/park")
@ResponseBody
public String park() throws InterruptedException {
RSemaphore park = redisson.getSemaphore("park");
park.acquire(); //获取一个信号、获取一个值,占一个车位
boolean flag = park.tryAcquire();
if (flag) {
//执行业务
} else {
return "error";
}
return "ok=>" + flag;
}
@GetMapping(value = "/go")
@ResponseBody
public String go() {
RSemaphore park = redisson.getSemaphore("park");
park.release(); //释放一个车位
return "ok";
}8.7. 可过期性信号量(PermitExpirableSemaphore)
基于 Redis 的 Redisson 可过期性信号量(PermitExpirableSemaphore)是在 RSemaphore 对象的基础上,为每个信号增加了一个过期时间。每个信号可以通过独立的 ID 来辨识,释放时只能通过提交这个 ID 才能释放。它提供了异步(Async)、反射式(Reactive)和 RxJava2 标准的接口。
RPermitExpirableSemaphore semaphore = redisson.getPermitExpirableSemaphore("mySemaphore");
String permitId = semaphore.acquire();
// 获取一个信号,有效期只有2秒钟。
String permitId = semaphore.acquire(2, TimeUnit.SECONDS);
// ...
semaphore.release(permitId);8.8. 闭锁(CountDownLatch)
基于 Redisson 的 Redisson 分布式闭锁(CountDownLatch)Java 对象 RCountDownLatch 采用了与 java.util.concurrent.CountDownLatch 相似的接口和用法。
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.trySetCount(1);
latch.await();
// 在其他线程或其他JVM里
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.countDown();使用范例
/**
* 放假、锁门
* 1班没人了
* 5个班,全部走完,我们才可以锁大门
* 分布式闭锁
*/
@GetMapping(value = "/lockDoor")
@ResponseBody
public String lockDoor() throws InterruptedException {
RCountDownLatch door = redisson.getCountDownLatch("door");
door.trySetCount(5);
door.await(); //等待闭锁完成
return "放假了...";
}
@GetMapping(value = "/gogogo/{id}")
@ResponseBody
public String gogogo(@PathVariable("id") Long id) {
RCountDownLatch door = redisson.getCountDownLatch("door");
door.countDown(); //计数-1
return id + "班的人都走了...";
}九、分布式服务
9.1. 分布式远程服务(Remote Service)
基于 Redis 的 Java 分布式远程服务,可以用来通过共享接口执行存在于另一个 Redisson 实例里的对象方法。换句话说就是通过 Redis 实现了 Java 的远程过程调用(RPC)。分布式远程服务基于可以用 POJO 对象,方法的参数和返回类不受限制,可以是任何类型。
分布式远程服务(Remote Service)提供了两种类型的 RRemoteService 实例:
(1)服务端(远端)实例 - 用来执行远程方法(工作者实例即 worker instance). 例如:
RRemoteService remoteService = redisson.getRemoteService();
SomeServiceImpl someServiceImpl = new SomeServiceImpl();
// 在调用远程方法以前,应该首先注册远程服务
// 只注册了一个服务端工作者实例,只能同时执行一个并发调用
remoteService.register(SomeServiceInterface.class, someServiceImpl);
// 注册了12个服务端工作者实例,可以同时执行12个并发调用
remoteService.register(SomeServiceInterface.class, someServiceImpl, 12);(2)客户端(本地)实例 - 用来请求远程方法。例如:
RRemoteService remoteService = redisson.getRemoteService();
SomeServiceInterface service = remoteService.get(SomeServiceInterface.class);
String result = service.doSomeStuff(1L, "secondParam", new AnyParam());客户端和服务端必须使用一样的共享接口,生成两者的 Redisson 实例必须采用相同的连接配置。客户端和服务端实例可以运行在同一个 JVM 里,也可以是不同的。客户端和服务端的数量不收限制。(注意:尽管 Redisson 不做任何限制,但是 Redis 的限制仍然有效。)
在服务端工作者可用实例数量 大于 1 的时候,将并行执行并发调用的远程方法。
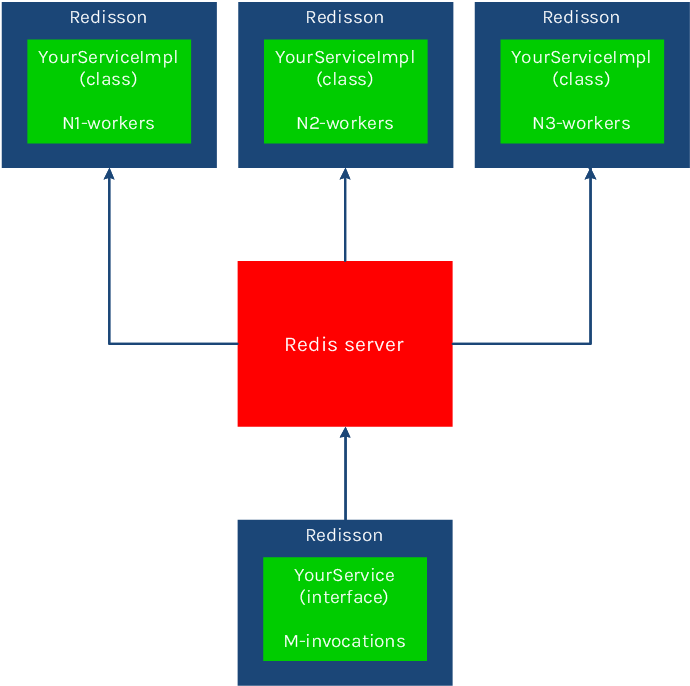
并行执行工作者数量计算方法如下: T = R * N
T - 并行执行工作者总数
R - Redisson 服务端数量
N - 注册服务端时指定的执行工作者数量
超过该数量的并发请求将在列队中等候执行。
在服务端工作者实例可用数量为 1 时,远程过程调用将会按 顺序执行。这种情况下,每次只有一个请求将会被执行,其他请求将在列队中等候执行。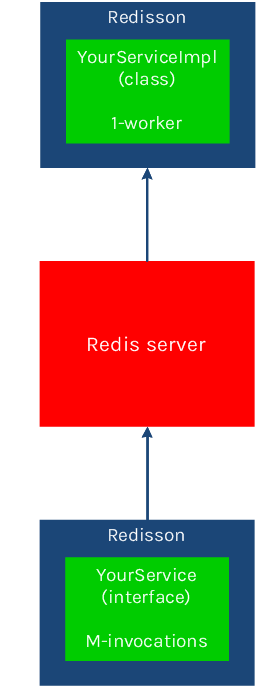
9.1.1. 分布式远程服务工作流程
分布式远程服务为每个注册接口建立了两个列队。一个列队用于请求,由服务端监听,另一个列队用于应答回执和结果回复,由客户端监听。应答回执用于判定该请求是否已经被接受。如果在指定的超时时间内没有被执行工作者执行将会抛出 RemoteServiceAckTimeoutException 错误。
下图描述了每次发起远程过程调用请求的工作流程。
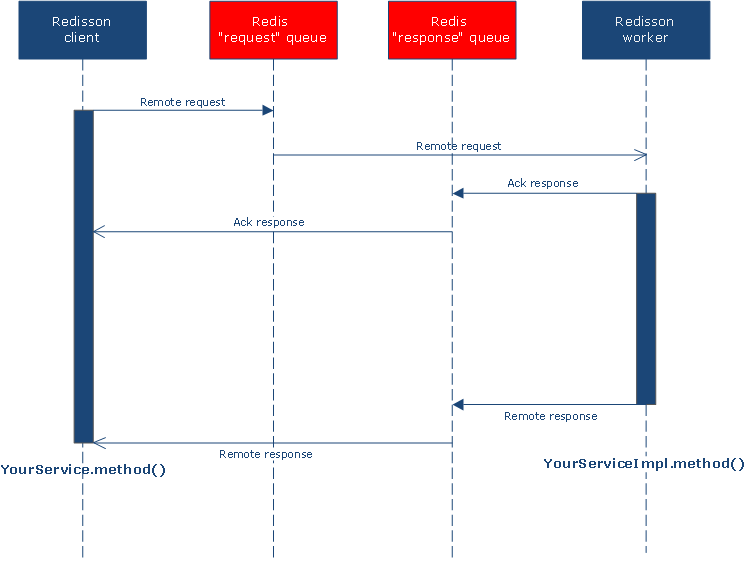
9.1.2. 发送即不管(Fire-and-Forget)模式和应答回执(Ack-Response)模式
分布式远程服务通过 org.redisson.core.RemoteInvocationOptions 类,为每个远程过程调用提供了一些可配置选项。这些选项可以用来指定和修改请求超时和选择跳过应答回执或结果的发送模式。例如:
// 应答回执超时1秒钟,远程执行超时30秒钟
RemoteInvocationOptions options = RemoteInvocationOptions.defaults();
// 无需应答回执,远程执行超时30秒钟
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().noAck();
// 应答回执超时1秒钟,不等待执行结果
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().noResult();
// 应答回执超时1分钟,不等待执行结果
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().expectAckWithin(1, TimeUnit.MINUTES).noResult();
// 发送即不管(Fire-and-Forget)模式,无需应答回执,不等待结果
RemoteInvocationOptions options = RemoteInvocationOptions.defaults().noAck().noResult();
RRemoteService remoteService = redisson.getRemoteService();
YourService service = remoteService.get(YourService.class, options);9.1.3. 异步调用
远程过程调用也可以采用异步的方式执行。异步调用需要单独提交一个带有 @RRemoteAsync 注解(annotation)的异步接口类。异步接口方法签名必须与远程接口的方法签名相符。异步接口的返回类必须是 org.redisson.api.RFuture 对象或其子对象。在调用 RRemoteService.get 方法时将对异步接口的方法进行验证。异步接口无须包含所有的远程接口里的方法,只需要包含要求异步执行的方法即可。
// 远程接口
public interface RemoteInterface {
Long someMethod1(Long param1, String param2);
void someMethod2(MyObject param);
MyObject someMethod3();
}
// 匹配远程接口的异步接口
@RRemoteAsync(RemoteInterface.class)
public interface RemoteInterfaceAsync {
RFuture<Long> someMethod1(Long param1, String param2);
RFuture<Void> someMethod2(MyObject param);
}
RRemoteService remoteService = redisson.getRemoteService();
RemoteInterfaceAsync asyncService = remoteService.get(RemoteInterfaceAsync.class);9.1.4. 取消异步调用
通过调用 Future.cancel () 方法可以非常方便的取消一个异步调用。分布式远程服务允许在三个阶段中任何一个阶段取消异步调用:
- 远程调用请求在列队中排队阶段
- 远程调用请求已经被分布式远程服务接受,还未发送应答回执,执行尚未开始。
- 远程调用请求已经在执行阶段
想要正确的处理第三个阶段,在服务端代码里应该检查 Thread.currentThread ().isInterrupted () 的返回状态。范例如下:
// 远程接口
public interface MyRemoteInterface {
Long myBusyMethod(Long param1, String param2);
}
// 匹配远程接口的异步接口
@RRemoteAsync(MyRemoteInterface.class)
public interface MyRemoteInterfaceAsync {
RFuture<Long> myBusyMethod(Long param1, String param2);
}
// 远程接口的实现
public class MyRemoteServiceImpl implements MyRemoteInterface {
public Long myBusyMethod(Long param1, String param2) {
for (long i = 0; i < Long.MAX_VALUE; i++) {
iterations.incrementAndGet();
if (Thread.currentThread().isInterrupted()) {
System.out.println("interrupted! " + i);
return;
}
}
}
}
RRemoteService remoteService = redisson.getRemoteService();
ExecutorService executor = Executors.newFixedThreadPool(5);
// 注册远程服务的服务端的同时,通过单独指定的ExecutorService来配置执行线程池
MyRemoteInterface serviceImpl = new MyRemoteServiceImpl();
remoteService.register(MyRemoteInterface.class, serviceImpl, 5, executor);
// 异步调用方法
MyRemoteInterfaceAsync asyncService = remoteService.get(MyRemoteInterfaceAsync.class);
RFuture<Long> future = asyncService.myBusyMethod(1L, "someparam");
// 取消异步调用
future.cancel(true);9.2. 分布式实时对象(Live Object)服务
9.2.1. 介绍
一个 分布式实时对象(Live Object) 可以被理解为一个功能强化后的 Java 对象。该对象不仅可以被一个 JVM 里的各个线程相引用,还可以被多个位于不同 JVM 里的线程同时引用。Wikipedia 对这种特殊对象的概述是:
Live distributed object (also abbreviated as live object) refers to a running instance of a distributed multi-party (or peer-to-peer) protocol, viewed from the object-oriented perspective, as an entity that has a distinct identity, may encapsulate internal state and threads of execution, and that exhibits a well-defined externally visible behavior.
Redisson 分布式实时对象(Redisson Live Object,简称 RLO)运用即时生成的代理类(Proxy),将一个指定的普通 Java 类里的所有字段,以及针对这些字段的操作全部映射到一个 Redis Hash 的数据结构,实现这种理念。每个字段的 get 和 set 方法最终被转译为针对同一个 Redis Hash 的 hget 和 hset 命令,从而使所有连接到同一个 Redis 节点的所有可以客户端同时对一个指定的对象进行操作。众所周知,一个对象的状态是由其内部的字段所赋的值来体现的,通过将这些值保存在一个像 Redis 这样的远程共享的空间的过程,把这个对象强化成了一个分布式对象。这个分布式对象就叫做 Redisson 分布式实时对象(Redisson Live Object,简称 RLO)。
通过使用 RLO,运行在不同服务器里的多个程序之间,共享一个对象实例变得和在单机程序里共享一个对象实例一样了。同时还避免了针对任何一个字段操作都需要将整个对象序列化和反序列化的繁琐,进而降低了程序开发的复杂性和其数据模型的复杂性:从任何一个客户端修改一个字段的值,处在其他服务器上的客户端(几乎)即刻便能查看到。而且实现代码与单机程序代码无异。(连接到从节点的客户端仍然受 Redis 的最终一致性的特性限制)
鉴于 Redis 是一个单线程的程序,针对实时对象的所有的字段操作可以理解为全部是原子性操作,也就是说在读取一个字段的过程不会担心被其他线程所修改。
通过使用 RLO,可以把 Redis 当作一个允许被多个 JVM 同时操作且不受 GC 影响的共享堆(Heap Space)。
9.2.2. 使用方法
Redisson 为分布式实时对象提供了一系列不同功能的注解,其中 @REntity 和 @RId 两个注解是分布式实时对象的必要条件。
@REntity
public class MyObject {
@RId
private String id;
@RIndex
private String value;
private MyObject parent;
public MyObject(String id) {
this.id = id;
}
public MyObject() {
}
// getters and setters
}在开始使用分布式实时对象以前,需要先通过 Redisson 服务将指定的对象连接(attach),合并(merge)或持久化(persist)到 Redis 里。
RLiveObjectService service = redisson.getLiveObjectService();
MyLiveObject myObject = new MyLiveObject();
myObject.setId("1");
// 将myObject对象当前的状态持久化到Redis里并与之保持同步。
myObject = service.persist(myObject);
MyLiveObject myObject = new MyLiveObject("1");
// 抛弃myObject对象当前的状态,并与Redis里的数据建立连接并保持同步。
myObject = service.attach(myObject);
MyLiveObject myObject = new MyLiveObject();
myObject.setId("1");
// 将myObject对象当前的状态与Redis里的数据合并之后与之保持同步。
myObject = service.merge(myObject);
myObject.setValue("somevalue");
// 通过ID获取分布式实时对象
MyLiveObject myObject = service.get(MyLiveObject.class, "1");
// 通过索引查找分布式实时对象
Collection<MyLiveObject> myObjects = service.find(MyLiveObject.class, Conditions.in("value", "somevalue", "somevalue2"));
Collection<MyLiveObject> myObjects = service.find(MyLiveObject.class, Conditions.and(Conditions.in("value", "somevalue", "somevalue2"), Conditions.eq("secondfield", "test")));“parent” 字段中包含了指向到另一个分布式实时对象的引用,它可以与包含类是同一类型也可以不同。Redisson 内部采用了与 Java 的引用类似的方式保存这个关系,而非将全部对象序列化,可视为与普通的引用同等效果。
//RLO对象:
MyObject myObject = service.get(MyObject.class, "1");
MyObject myParentObject = service.get(MyObject.class, "2");
myObject.setValue(myParentObject);RLO 的字段类型基本上无限制,可以是任何类型。比如 Java util 包里的集合类,Map 类等,也可以是自定义的对象。只要指定的编码解码器能够对其进行编码和解码操作便可。关于编码解码器的详细信息请查阅高级使用方法章节。
尽管 RLO 的字段类型基本上无限制,个别类型还是受限。注解了 RId 的字段类型不能是数组类(Array),比如 int [],long [],double [],byte [] 等等。更多关于限制有关的介绍和原理解释请查阅使用限制 章节。
为了保证 RLO 的用法和普通 Java 对象的用法尽可能一直,Redisson 分布式实时对象服务自动将以下普通 Java 对象转换成与之匹配的 Redisson 分布式对象 RObject。
| 普通 Java 类 | 转换后的 Redisson 类 |
|---|---|
| SortedSet.class | RedissonSortedSet.class |
| Set.class | RedissonSet.class |
| ConcurrentMap.class | RedissonMap.class |
| Map.class | RedissonMap.class |
| BlockingDeque.class | RedissonBlockingDeque.class |
| Deque.class | RedissonDeque.class |
| BlockingQueue.class | RedissonBlockingQueue.class |
| Queue.class | RedissonQueue.class |
| List.class | RedissonList.class |
类型转换将按照从上至下的顺序匹配类型,例如 LinkedList 类同时实现了 Deque,List 和 Queue,由于 Deque 排在靠上的位置,因此它将会被转换成一个 RedissonDeque 类型。
Redisson 的分布式对象也采用类似的方式,将自身的状态储存于 Redis 当中,(几乎)所有的状态改变都直接映射到 Redis 里,不在本地 JVM 中保留任何赋值。(本地缓存对象除外,比如 RLocalCachedMap)
9.2.3. 高级使用方法
正如上述介绍,RLO 类其实都是按需实时生成的代理(Proxy)类。生成的代理类和原类都一同缓存 Redisson 实例里。这个过程会消耗一些时间,在对耗时比较敏感的情况下,建议通过 RedissonLiveObjectService 提前注册所有的 RLO 类。这个服务也可以用来注销不再需要的 RLO 类,也可以用来查询一个类是否已经注册了。
RLiveObjectService service = redisson.getLiveObjectService();
service.registerClass(MyClass.class);
service.unregisterClass(MyClass.class);
Boolean registered = service.isClassRegistered(MyClass.class);9.2.4. 注解(Annotation)使用方法
@REntity
仅适用于类。通过指定 @REntity 的各个参数,可以详细的对每个 RLO 类实现特殊定制,以达到改变 RLO 对象的行为。
- namingScheme - 命名方案。命名方案规定了每个实例在 Redis 中对应 key 的名称。它不仅被用来与已存在的 RLO 建立关联,还被用来储存新建的 RLO 实例。默认采用 Redisson 自带的 DefaultNamingScheme 对象。
- codec - 编码解码器。在运行当中,Redisson 用编码解码器来对 RLO 中的每个字段进行编码解码。Redisson 内部采用了实例池管理不同类型的编码解码器实例。Redisson 提供了多种不同的编码解码器,默认使用 JsonJacksonCodec。
- fieldTransformation - 字段转换模式。如上所述,为了尽可能的保证 RLO 的用法和普通 Java 对象一致,Redisson 会自动将常用的普通 Java 对象转换成与其匹配的 Redisson 分布式对象。这是由于字段转换模式的默认值是 ANNOTATION_BASED,修改为 IMPLEMENTATION_BASED 就可以不转换。
@RId
仅适用于字段。@RId 注解只能用在具备区分实例的字段上,这类字段可以理解为一个类的 id 字段或主键字段。这个字段的值将被命名方案 namingScheme 用来与事先存在的 RLO 建立引用。加了该注解的字段是唯一在本地 JVM 里同时保存赋值的字段。一个类只能有一个字段包含 @RId 注解。
可以通过指定一个生成器 generator 策略来实现自动生成这个字段的值。默认不提供生成器。
@RIndex
仅适用于字段。用来指定可用于搜索的字段。可以通过 RLiveObjectService.find 方法来根据条件精细查找分布式实时对象。查询条件可以是含(IN),或(OR),和(AND)或相等(EQ)以及它们的任意组合。
使用范例如下:
public class MyObject {
@RIndex
String field1;
@RIndex
String field2;
@RIndex
String field3;
}
Collection<MyObject> objects = RLiveObjectService.find(MyObject.class, Conditions.or(Conditions.and(Conditions.eq("field1", "value"), Conditions.eq("field2", "value")), Conditions.in("field3", "value1", "value2"));@RObjectField
仅适用于字段。允许通过该注解中的 namingScheme 或 codec 来改变该字段的命名或编码方式,用来区别于 @REntity 中指定的预设方式。
@RCascade
仅适用于字段。用来指定包含于分布式实时对象字段内其它对象的级联操作方式。
可选的级联操作方式为如下:
RCascadeType.ALL - 执行所有级联操作
RCascadeType.PERSIST - 仅在执行 RLiveObjectService.persist () 方法时进行级联操作
RCascadeType.DETACH - 仅在执行 RLiveObjectService.detach () 方法时进行级联操作
RCascadeType.MERGE - 仅在执行 RLiveObjectService.merge () 方法时进行级联操作
RCascadeType.DELETE - 仅在执行 RLiveObjectService.delete () 方法时进行级联操作
9.2.5. 使用限制
如上所述,带有 RId 注解字段的类型不能使数组类,这是因为目前默认的命名方案类 DefaultNamingScheme 还不能正确地将数组类序列化和反序列化。在改善了 DefaultNamingScheme 类的不足以后会考虑取消这个限制。另外由于带有 RId 注解的字段是用来指定 Redis 中映射的 key 的名称,因此组建一个只含有唯一一个字段的 RLO 类是毫无意义的。选用 RBucket 会更适合这样的场景。
9.3. 分布式执行服务(Executor Service)
9.3.1. 分布式执行服务概述
Redisson 的分布式执行服务实现了 java.util.concurrent.ExecutorService 接口,支持在不同的独立节点里执行基于 java.util.concurrent.Callable 接口或 java.lang.Runnable 接口或 Lambda 的任务。这样的任务也可以通过使用 Redisson 实例,实现对储存在 Redis 里的数据进行操作。Redisson 分布式执行服务是最快速和有效执行分布式运算的方法。
9.3.2. 任务
Redisson 独立节点不要求任务的类在类路径里。他们会自动被 Redisson 独立节点的 ClassLoader 加载。因此每次执行一个新任务时,不需要重启 Redisson 独立节点。
采用 Callable 任务的范例:
public class CallableTask implements Callable<Long> {
@RInject
private RedissonClient redissonClient;
@Override
public Long call() throws Exception {
RMap<String, Integer> map = redissonClient.getMap("myMap");
Long result = 0;
for (Integer value : map.values()) {
result += value;
}
return result;
}
}采用 Runnable 任务的范例:
public class RunnableTask implements Runnable {
@RInject
private RedissonClient redissonClient;
private long param;
public RunnableTask() {
}
public RunnableTask(long param) {
this.param = param;
}
@Override
public void run() {
RAtomicLong atomic = redissonClient.getAtomicLong("myAtomic");
atomic.addAndGet(param);
}
}在创建 ExecutorService 时可以配置以下参数:
ExecutorOptions options = ExecutorOptions.defaults()
// 指定重新尝试执行任务的时间间隔。
// ExecutorService的工作节点将等待10分钟后重新尝试执行任务
//
// 设定为0则不进行重试
//
// 默认值为5分钟
options.taskRetryInterval(10, TimeUnit.MINUTES);RExecutorService executorService = redisson.getExecutorService("myExecutor", options);
executorService.submit(new RunnableTask(123));
RExecutorService executorService = redisson.getExecutorService("myExecutor", options);
Future<Long> future = executorService.submit(new CallableTask());
Long result = future.get();使用 Lambda 任务的范例:
RExecutorService executorService = redisson.getExecutorService("myExecutor", options);
Future<Long> future = executorService.submit((Callable & Serializable)() -> {
System.out.println("task has been executed!");
});
Long result = future.get();可以通过 @RInject 注解来为任务实时注入 Redisson 实例依赖。
9.3.3. 取消任务
通过 Future.cancel () 方法可以很方便的取消所有已提交的任务。通过对 Thread.currentThread ().isInterrupted () 方法的调用可以在已经处于运行状态的任务里实现任务中断:
public class CallableTask implements Callable<Long> {
@RInject
private RedissonClient redissonClient;
@Override
public Long call() throws Exception {
RMap<String, Integer> map = redissonClient.getMap("myMap");
Long result = 0;
// map里包含了许多的元素
for (Integer value : map.values()) {
if (Thread.currentThread().isInterrupted()) {
// 任务被取消了
return null;
}
result += value;
}
return result;
}
}
RExecutorService executorService = redisson.getExecutorService("myExecutor");
Future<Long> future = executorService.submit(new CallableTask());
// 或
RFuture<Long> future = executorService.submitAsync(new CallableTask());
// ...
future.cancel(true);9.4. 分布式调度任务服务(Scheduler Service)
9.4.1. 分布式调度任务服务概述
Redisson 的分布式调度任务服务实现了 java.util.concurrent.ScheduledExecutorService 接口,支持在不同的独立节点里执行基于 java.util.concurrent.Callable 接口或 java.lang.Runnable 接口的任务。Redisson 独立节点按顺序运行 Redis 列队里的任务。调度任务是一种需要在未来某个指定时间运行一次或多次的特殊任务。
9.4.2. 设定任务计划
Redisson 独立节点不要求任务的类在类路径里。他们会自动被 Redisson 独立节点的 ClassLoader 加载。因此每次执行一个新任务时,不需要重启 Redisson 独立节点。
采用 Callable 任务的范例:
public class CallableTask implements Callable<Long> {
@RInject
private RedissonClient redissonClient;
@Override
public Long call() throws Exception {
RMap<String, Integer> map = redissonClient.getMap("myMap");
Long result = 0;
for (Integer value : map.values()) {
result += value;
}
return result;
}
}在创建 ExecutorService 时可以配置以下参数:
ExecutorOptions options = ExecutorOptions.defaults()
// 指定重新尝试执行任务的时间间隔。
// ExecutorService的工作节点将等待10分钟后重新尝试执行任务
//
// 设定为0则不进行重试
//
// 默认值为5分钟
options.taskRetryInterval(10, TimeUnit.MINUTES);RScheduledExecutorService executorService = redisson.getExecutorService("myExecutor");
ScheduledFuture<Long> future = executorService.schedule(new CallableTask(), 10, TimeUnit.MINUTES);
Long result = future.get();使用 Lambda 任务的范例:
RExecutorService executorService = redisson.getExecutorService("myExecutor", options);
ScheduledFuture<Long> future = executorService.schedule((Callable & Serializable)() -> {
System.out.println("task has been executed!");
}, 10, TimeUnit.MINUTES);
Long result = future.get();采用 Runnable 任务的范例:
public class RunnableTask implements Runnable {
@RInject
private RedissonClient redissonClient;
private long param;
public RunnableTask() {
}
public RunnableTask(long param) {
this.param= param;
}
@Override
public void run() {
RAtomicLong atomic = redissonClient.getAtomicLong("myAtomic");
atomic.addAndGet(param);
}
}
RScheduledExecutorService executorService = redisson.getExecutorService("myExecutor");
ScheduledFuture<?> future1 = executorService.schedule(new RunnableTask(123), 10, TimeUnit.HOURS);
// ...
ScheduledFuture<?> future2 = executorService.scheduleAtFixedRate(new RunnableTask(123), 10, 25, TimeUnit.HOURS);
// ...
ScheduledFuture<?> future3 = executorService.scheduleWithFixedDelay(new RunnableTask(123), 5, 10, TimeUnit.HOURS);9.4.3. 通过 CRON 表达式设定任务计划
在分布式调度任务中,可以通过 CRON 表达式来为任务设定一个更复杂的计划。表达式与 Quartz 的 CRON 格式完全兼容。
例如:
RScheduledExecutorService executorService = redisson.getExecutorService("myExecutor");
executorService.schedule(new RunnableTask(), CronSchedule.of("10 0/5 * * * ?"));
// ...
executorService.schedule(new RunnableTask(), CronSchedule.dailyAtHourAndMinute(10, 5));
// ...
executorService.schedule(new RunnableTask(), CronSchedule.weeklyOnDayAndHourAndMinute(12, 4, Calendar.MONDAY, Calendar.FRIDAY));9.4.4. 取消计划任务
分布式调度任务服务提供了两张取消任务的方式:通过调用 ScheduledFuture.cancel () 方法或调用 RScheduledExecutorService.cancelScheduledTask 方法。通过对 Thread.currentThread ().isInterrupted () 方法的调用可以在已经处于运行状态的任务里实现任务中断:
public class RunnableTask implements Callable<Long> {
@RInject
private RedissonClient redissonClient;
@Override
public Long call() throws Exception {
RMap<String, Integer> map = redissonClient.getMap("myMap");
Long result = 0;
// map里包含了许多的元素
for (Integer value : map.values()) {
if (Thread.currentThread().isInterrupted()) {
// 任务被取消了
return null;
}
result += value;
}
return result;
}
}
RScheduledExecutorService executorService = redisson.getExecutorService("myExecutor");
RScheduledFuture<Long> future = executorService.scheduleAsync(new RunnableTask(), CronSchedule.dailyAtHourAndMinute(10, 5));
// ...
future.cancel(true);
// 或
String taskId = future.getTaskId();
// ...
executorService.cancelScheduledTask(taskId);9.5. 分布式映射归纳服务(MapReduce)
9.5.1 介绍
Redisson 提供了通过映射归纳(MapReduce)编程模式来处理储存在 Redis 环境里的大量数据的服务。这个想法来至于其他的类似实现方式和谷歌发表的研究。所有 映射(Map) 和 归纳(Reduce) 阶段中的任务都是被分配到各个独立节点(Redisson Node)里并行执行的。以下所有接口均支持映射归纳(MapReduce)功能: RMap、 RMapCache、 RLocalCachedMap、 RSet、 RSetCache、 RList、 RSortedSet、 RScoredSortedSet、 RQueue、 RBlockingQueue、 RDeque、 RBlockingDeque、 RPriorityQueue 和 RPriorityDeque
映射归纳(MapReduce)的功能是通过 RMapper、 RCollectionMapper、 RReducer 和 RCollator 这几个接口实现的。
1. RMapper 映射器接口适用于映射(Map)类,它用来把映射(Map)中的每个元素转换为另一个作为归纳(Reduce)处理用的键值对。
public interface RMapper<KIn, VIn, KOut, VOut> extends Serializable {
void map(KIn key, VIn value, RCollector<KOut, VOut> collector);
}2. RCollectionMapper 映射器接口仅适用于集合(Collection)类型的对象,它用来把集合(Collection)中的元素转换成一组作为归纳(Reduce)处理用的键值对。
public interface RCollectionMapper<VIn, KOut, VOut> extends Serializable {
void map(VIn value, RCollector<KOut, VOut> collector);
}3. RReducer 归纳器接口用来将上面这些,由映射器生成的键值对列表进行归纳整理。
public interface RReducer<K, V> extends Serializable {
V reduce(K reducedKey, Iterator<V> values);
}4. RCollator 收集器接口用来把归纳整理以后的结果化简为单一一个对象。
public interface RCollator<K, V, R> extends Serializable {
R collate(Map<K, V> resultMap);
}以上每个阶段的任务都可以用 @RInject 注解的方式来获取 RedissonClient 实例:
public class WordMapper implements RMapper<String, String, String, Integer> {
@RInject
private RedissonClient redissonClient;
@Override
public void map(String key, String value, RCollector<String, Integer> collector) {
// ...
redissonClient.getAtomicLong("mapInvocations").incrementAndGet();
}
}9.5.2 映射(Map)类型的使用范例
Redisson 提供的 RMap、 RMapCache 和 RLocalCachedMap 这三种映射(Map)类型的对象均可以使用这种分布式映射归纳(MapReduce)服务。
以下是在映射(Map)类型的基础上采用映射归纳(MapReduce)来实现字数统计的范例:
(1)Mapper 对象将每个映射的值用空格且分开。
public class WordMapper implements RMapper<String, String, String, Integer> {
@Override
public void map(String key, String value, RCollector<String, Integer> collector) {
String[] words = value.split("[^a-zA-Z]");
for (String word : words) {
collector.emit(word, 1);
}
}
}(2)Reducer 对象计算统计所有单词的使用情况。
public class WordReducer implements RReducer<String, Integer> {
@Override
public Integer reduce(String reducedKey, Iterator<Integer> iter) {
int sum = 0;
while (iter.hasNext()) {
Integer i = (Integer) iter.next();
sum += i;
}
return sum;
}
}(3)Collator 对象统计所有单词的使用情况。
public class WordCollator implements RCollator<String, Integer, Integer> {
@Override
public Integer collate(Map<String, Integer> resultMap) {
int result = 0;
for (Integer count : resultMap.values()) {
result += count;
}
return result;
}
}(4)把上面的各个对象串起来使用:
RMap<String, String> map = redisson.getMap("wordsMap");
map.put("line1", "Alice was beginning to get very tired");
map.put("line2", "of sitting by her sister on the bank and");
map.put("line3", "of having nothing to do once or twice she");
map.put("line4", "had peeped into the book her sister was reading");
map.put("line5", "but it had no pictures or conversations in it");
map.put("line6", "and what is the use of a book");
map.put("line7", "thought Alice without pictures or conversation");
RMapReduce<String, String, String, Integer> mapReduce
= map.<String, Integer>mapReduce()
.mapper(new WordMapper())
.reducer(new WordReducer());
// 统计词频
Map<String, Integer> mapToNumber = mapReduce.execute();
// 统计字数
Integer totalWordsAmount = mapReduce.execute(new WordCollator());9.5.3 集合(Collection)类型的使用范例
Redisson 提供的 RSet、 RSetCache、 RList、 RSortedSet、 RScoredSortedSet、 RQueue、 RBlockingQueue、 RDeque、 RBlockingDeque、 RPriorityQueue 和 RPriorityDeque 这几种集合(Collection)类型的对象均可以使用这种分布式映射归纳(MapReduce)服务。
以下是在集合(Collection)类型的基础上采用映射归纳(MapReduce)来实现字数统计的范例:
public class WordMapper implements RCollectionMapper<String, String, Integer> {
@Override
public void map(String value, RCollector<String, Integer> collector) {
String[] words = value.split("[^a-zA-Z]");
for (String word : words) {
collector.emit(word, 1);
}
}
} public class WordReducer implements RReducer<String, Integer> {
@Override
public Integer reduce(String reducedKey, Iterator<Integer> iter) {
int sum = 0;
while (iter.hasNext()) {
Integer i = (Integer) iter.next();
sum += i;
}
return sum;
}
} public class WordCollator implements RCollator<String, Integer, Integer> {
@Override
public Integer collate(Map<String, Integer> resultMap) {
int result = 0;
for (Integer count : resultMap.values()) {
result += count;
}
return result;
}
} RList<String> list = redisson.getList("myList");
list.add("Alice was beginning to get very tired");
list.add("of sitting by her sister on the bank and");
list.add("of having nothing to do once or twice she");
list.add("had peeped into the book her sister was reading");
list.add("but it had no pictures or conversations in it");
list.add("and what is the use of a book");
list.add("thought Alice without pictures or conversation");
RCollectionMapReduce<String, String, Integer> mapReduce
= list.<String, Integer>mapReduce()
.mapper(new WordMapper())
.reducer(new WordReducer());
// 统计词频
Map<String, Integer> mapToNumber = mapReduce.execute();
// 统计字数
Integer totalWordsAmount = mapReduce.execute(new WordCollator());十、额外功能
10.1. 对 Redis 节点的操作
Redisson 的 NodesGroup 对象提供了许些对 Redis 节点的操作。
NodesGroup nodesGroup = redisson.getNodesGroup();
nodesGroup.addConnectionListener(new ConnectionListener() {
public void onConnect(InetSocketAddress addr) {
// Redis节点连接成功
}
public void onDisconnect(InetSocketAddress addr) {
// Redis节点连接断开
}
});也可以用来 PING 单个 Redis 节点或全部节点。
NodesGroup nodesGroup = redisson.getNodesGroup();
Collection<Node> allNodes = nodesGroup.getNodes();
for (Node n : allNodes) {
n.ping();
}
// 或者
nodesGroup.pingAll();10.2. 复杂多维对象结构和对象引用的支持
Redisson 突破了 Redis 数据结构维度的限制,通过一个特殊引用对象的帮助,Redisson 允许以任意的组合方式构建多维度的复杂对象结构,实现了对象之间的类似传统数据库里的关联关系。使用范例如下:
RMap<RSet<RList>, RList<RMap>> map = redisson.getMap("myMap");
RSet<RList> set = redisson.getSet("mySet");
RList<RMap> list = redisson.getList("myList");
map.put(set, list);
// 在特殊引用对象的帮助下,我们甚至可以构建一个循环引用,这是通过普通序列化方式实现不了的。
set.add(list);
list.add(map);可能您已经注意到了,在 map 包含的元素发生改变以后,我们无需再次 “保存 / 持久” 这些对象。因为 map 对象所记录的并不是序列化以后的值,而是元素对象的引用。这让 Redisson 提供的对象在使用方法上,与普通 Java 对象的使用方法一致。从而让 Redis 成为内存的一部分,而不仅仅是一个储存空间。
以上范例中,一共创建了三个 Redis 数据结构:一个 Redis HASH,一个 Redis SET 和一个 Redis LIST。
10.3. 命令的批量执行
多个连续命令可以通过 RBatch 对象在一次网络会话请求里合并发送,这样省去了产生多个请求消耗的时间和资源。这在 Redis 中叫做管道。
用户可以通过以下方式调整通过管道方式发送命令的方式:
BatchOptions options = BatchOptions.defaults()
// 指定执行模式
//
// ExecutionMode.REDIS_READ_ATOMIC - 所有命令缓存在Redis节点中,以原子性事务的方式执行。
//
// ExecutionMode.REDIS_WRITE_ATOMIC - 所有命令缓存在Redis节点中,以原子性事务的方式执行。
//
// ExecutionMode.IN_MEMORY - 所有命令缓存在Redisson本机内存中统一发送,但逐一执行(非事务)。默认模式。
//
// ExecutionMode.IN_MEMORY_ATOMIC - 所有命令缓存在Redisson本机内存中统一发送,并以原子性事务的方式执行。
//
.executionMode(ExecutionMode.IN_MEMORY)
// 告知Redis不用返回结果(可以减少网络用量)
.skipResult()
// 将写入操作同步到从节点
// 同步到2个从节点,等待时间为1秒钟
.syncSlaves(2, 1, TimeUnit.SECONDS)
// 处理结果超时为2秒钟
.responseTimeout(2, TimeUnit.SECONDS)
// 命令重试等待间隔时间为2秒钟
.retryInterval(2, TimeUnit.SECONDS);
// 命令重试次数。仅适用于未发送成功的命令
.retryAttempts(4);使用方式如下:
RBatch batch = redisson.createBatch();
batch.getMap("test").fastPutAsync("1", "2");
batch.getMap("test").fastPutAsync("2", "3");
batch.getMap("test").putAsync("2", "5");
batch.getAtomicLongAsync("counter").incrementAndGetAsync();
batch.getAtomicLongAsync("counter").incrementAndGetAsync();
BatchResult res = batch.execute();
// 或者
Future<BatchResult> asyncRes = batch.executeAsync();
List<?> response = res.getResponses();
res.getSyncedSlaves();在集群模式下,所有的命令会按各个槽所在的节点,筛选分配到各个节点并同时发送。每个节点返回的结果将会汇总到最终的结果列表里。
10.4. Redisson 事务
Redisson 为 RMap、RMapCache、RLocalCachedMap、RSet、RSetCache 和 RBucket 这样的对象提供了具有 ACID 属性的事务功能。Redisson 事务通过分布式锁保证了连续写入的原子性,同时在内部通过操作指令队列实现了 Redis 原本没有的提交与滚回功能。当提交与滚回遇到问题的时候,将通过 org.redisson.transaction.TransactionException 告知用户。
目前支持的环境如下: SINGLE, MASTER/SLAVE, SENTINEL, ELASTICACHE REPLICATED, AZURE CACHE, RLEC。
Redisson 事务支持的事务隔离等级为: READ_COMMITTED,即仅读取提交后的结果。
另见 Spring 事务管理器 和本章 XA 事务(XA Transactions)。
以下选项可以用来配置事务属性:
TransactionOptions options = TransactionOptions.defaults()
// 设置参与本次事务的主节点与其从节点同步的超时时间。
// 默认值是5秒。
.syncSlavesTimeout(5, TimeUnit.SECONDS)
// 处理结果超时。
// 默认值是3秒。
.responseTimeout(3, TimeUnit.SECONDS)
// 命令重试等待间隔时间。仅适用于未发送成功的命令。
// 默认值是1.5秒。
.retryInterval(2, TimeUnit.SECONDS)
// 命令重试次数。仅适用于未发送成功的命令。
// 默认值是3次。
.retryAttempts(3)
// 事务超时时间。如果规定时间内没有提交该事务则自动滚回。
// 默认值是5秒。
.timeout(5, TimeUnit.SECONDS);代码范例:
RTransaction transaction = redisson.createTransaction(TransactionOptions.defaults());
RMap<String, String> map = transaction.getMap("myMap");
map.put("1", "2");
String value = map.get("3");
RSet<String> set = transaction.getSet("mySet")
set.add(value);
try {
transaction.commit();
} catch(TransactionException e) {
transaction.rollback();
}10.5. XA 事务(XA Transactions)
Redisson 提供了 XAResource 标准的实现。该实现可用于 JTA 事务中。
另见本章 Redisson 事务和 Spring 事务管理器。
该功能仅适用于 Redisson PRO 版本
代码范例:
// Transaction对象可以从所有兼容JTA接口的事务管理器中获取。
Transaction globalTransaction = transactionManager.getTransaction();
RXAResource xaResource = redisson.getXAResource();
globalTransaction.enlistResource(xaResource);
RTransaction transaction = xaResource.getTransaction();
RBucket<String> bucket = transaction.getBucket("myBucket");
bucket.set("simple");
RMap<String, String> map = transaction.getMap("myMap");
map.put("myKey", "myValue");
transactionManager.commit();10.6. 脚本执行
redisson.getBucket("foo").set("bar");
String r = redisson.getScript().eval(Mode.READ_ONLY,
"return redis.call('get', 'foo')", RScript.ReturnType.VALUE);
// 通过预存的脚本进行同样的操作
RScript s = redisson.getScript();
// 首先将脚本保存到所有的Redis主节点
String res = s.scriptLoad("return redis.call('get', 'foo')");
// 返回值 res == 282297a0228f48cd3fc6a55de6316f31422f5d17
// 再通过SHA值调用脚本
Future<Object> r1 = redisson.getScript().evalShaAsync(Mode.READ_ONLY,
"282297a0228f48cd3fc6a55de6316f31422f5d17",
RScript.ReturnType.VALUE, Collections.emptyList());10.7. 底层 Redis 客户端
Redisson 在底层采用了高性能异步非阻塞式 Java 客户端,它同时支持异步和同步两种通信模式。如果有哪些命令 Redisson 还没提供支持,也可以直接通过调用底层 Redis 客户端来实现。Redisson 支持的命令在 Redis 命令和 Redisson 对象匹配列表里做了详细对比参照。
// 在使用多个客户端的情况下可以共享同一个EventLoopGroup
EventLoopGroup group = new NioEventLoopGroup();
RedisClientConfig config = new RedisClientConfig();
config.setAddress("redis://localhost:6379") // 或者用rediss://使用加密连接
.setPassword("myPassword")
.setDatabase(0)
.setClientName("myClient")
.setGroup(group);
RedisClient client = RedisClient.create(config);
RedisConnection conn = client.connect();
// 或
RFuture<RedisConnection> connFuture = client.connectAsync();
conn.sync(StringCodec.INSTANCE, RedisCommands.SET, "test", 0);
// 或
conn.async(StringCodec.INSTANCE, RedisCommands.GET, "test");
conn.close()
// 或
conn.closeAsync()
client.shutdown();
// 或
client.shutdownAsync();十一、Redis 命令和 Redisson 对象匹配列表
| Redis 命令 | Redisson 对象方法 |
|---|---|
| AUTH | Config.setPassword(); |
| APPEND | RBinaryStream.getOutputStream().write() |
| BITCOUNT | RBitSet.cardinality(), RBitSet.cardinalityAsync(), RBitSetReactive.cardinality() |
| BITOP | RBitSet.or(), RBitSet.orAsync(), RBitSetReactive.or(); RBitSet.and(), RBitSet.andAsync(), RBitSetReactive.and(); RBitSet.not(); RBitSet.xor(), RBitSet.xorAsync(), RBitSetReactive.xor() |
| BITPOS | RBitSet.length(), RBitSet.lengthAsync(), RBitSetReactive.length() |
| BLPOP | RBlockingQueue.take(), RBlockingQueue.takeAsync(), RBlockingQueueReactive.take(); RBlockingQueue.poll(), RBlockingQueue.pollAsync(), RBlockingQueueReactive.poll(); RBlockingQueue.pollFromAny(), RBlockingQueue.pollFromAnyAsync(), RBlockingQueueReactive.pollFromAny(); |
| BRPOP | RBlockingDeque.takeLast(), RBlockingDeque.takeLastAsync(), RBlockingDequeReactive.takeLast(); |
| BRPOPLPUSH | RBlockingQueue.pollLastAndOfferFirstTo(), RBlockingQueue.pollLastAndOfferFirstToAsync(), RBlockingQueueReactive.pollLastAndOfferFirstTo(); |
| COPY | RObject.copy, RObject.copyAsync, RObjectReactive.copy(); |
| CLIENT SETNAME | Config.setClientName(); |
| CLUSTER INFO | ClusterNode.info(); |
| CLUSTER KEYSLOT | RKeys.getSlot(), RKeys.getSlotAsync(), RKeysReactive.getSlot(); |
| CLUSTER NODES | Used in ClusterConnectionManager |
| DUMP | RObject.dump(), RObject.dumpAsync(), RObjectReactive.dump(); |
| DBSIZE | RKeys.count(), RKeys.countAsync(), RKeysReactive.count(); |
| DECR | RAtomicLong.decrementAndGet(), RAtomicLong.decrementAndGetAsync(), RAtomicLongReactive.decrementAndGetAsync(); |
| DEL | RObject.delete(), RObject.deleteAsync(), RObjectReactive.delete(); RKeys.delete(), RKeys.deleteAsync(); |
| STRLEN | RBucket.size(), RBucket.sizeAsync(), RBucketReactive.size(); |
| EVAL | RScript.eval(), RScript.evalAsync(), RScriptReactive.eval(); |
| CLIENT REPLY | RBatch.executeSkipResult(); |
| EVALSHA | RScript.evalSha(), RScript.evalShaAsync(), RScriptReactive.evalSha(); |
| EXEC | RBatch.execute(), RBatch.executeAsync(), RBatchReactive.execute(); |
| EXISTS | RObject.isExists(), RObject.isExistsAsync(), RObjectReactive.isExists(); |
| FLUSHALL | RKeys.flushall(), RKeys.flushallAsync(), RKeysReactive.flushall(); |
| FLUSHDB | RKeys.flushdb(), RKeys.flushdbAsync(), RKeysReactive.flushdb(); |
| GEOADD | RGeo.add(), RGeo.addAsync(), RGeoReactive.add(); |
| GEODIST | RGeo.dist(), RGeo.distAsync(), RGeoReactive.dist(); |
| GEOHASH | RGeo.hash(), RGeo.hashAsync(), RGeoReactive.hash(); |
| GEOPOS | RGeo.pos(), RGeo.posAsync(), RGeoReactive.pos(); |
| GEORADIUS | RGeo.radius(), RGeo.radiusAsync(), RGeoReactive.radius(); RGeo.radiusWithDistance(), RGeo.radiusWithDistanceAsync(), RGeoReactive.radiusWithDistance(); RGeo.radiusWithPosition(), RGeo.radiusWithPositionAsync(), RGeoReactive.radiusWithPosition(); |
| GEORADIUSBYMEMBER | RGeo.radius(), RGeo.radiusAsync(), RGeoReactive.radius(); RGeo.radiusWithDistance(), RGeo.radiusWithDistanceAsync(), RGeoReactive.radiusWithDistance(); RGeo.radiusWithPosition(), RGeo.radiusWithPositionAsync(), RGeoReactive.radiusWithPosition(); |
| GET | RBucket.get(), RBucket.getAsync(), RBucketReactive.get(); |
| GETBIT | RBitSet.get(), RBitSet.getAsync(), RBitSetReactive.get(); |
| GETSET | RBucket.getAndSet(), RBucket.getAndSetAsync(), RBucketReactive.getAndSet(); RAtomicLong.getAndSet(), RAtomicLong.getAndSetAsync(), RAtomicLongReactive.getAndSet(); RAtomicDouble.getAndSet(), RAtomicDouble.getAndSetAsync(), RAtomicDoubleReactive.getAndSet(); |
| HDEL | RMap.fastRemove(), RMap.fastRemoveAsync(), RMapReactive.fastRemove(); |
| HEXISTS | RMap.containsKey(), RMap.containsKeyAsync(), RMapReactive.containsKey(); |
| HGET | RMap.get(), RMap.getAsync(), RMapReactive.get(); |
| HSTRLEN | RMap.valueSize(), RMap.valueSizeAsync(), RMapReactive.valueSize(); |
| HGETALL | RMap.readAllEntrySet(), RMap.readAllEntrySetAsync(), RMapReactive.readAllEntrySet(); |
| HINCRBY | RMap.addAndGet(), RMap.addAndGetAsync(), RMapReactive.addAndGet(); |
| HINCRBYFLOAT | RMap.addAndGet(), RMap.addAndGetAsync(), RMapReactive.addAndGet(); |
| HKEYS | RMap.readAllKeySet(), RMap.readAllKeySetAsync(), RMapReactive.readAllKeySet(); |
| HLEN | RMap.size(), RMap.sizeAsync(), RMapReactive.size(); |
| HMGET | RMap.getAll(), RMap.getAllAsync(), RMapReactive.getAll(); |
| HMSET | RMap.putAll(), RMap.putAllAsync(), RMapReactive.putAll(); |
| HSET | RMap.put(), RMap.putAsync(), RMapReactive.put(); |
| HSETNX | RMap.fastPutIfAbsent(), RMap.fastPutIfAbsentAsync, RMapReactive.fastPutIfAbsent(); |
| HVALS | RMap.readAllValues(), RMap.readAllValuesAsync(), RMapReactive.readAllValues(); |
| INCR | RAtomicLong.incrementAndGet(), RAtomicLong.incrementAndGetAsync(), RAtomicLongReactive.incrementAndGet(); |
| INCRBY | RAtomicLong.addAndGet(), RAtomicLong.addAndGetAsync(), RAtomicLongReactive.addAndGet(); |
| KEYS | RKeys.findKeysByPattern(), RKeys.findKeysByPatternAsync(), RKeysReactive.findKeysByPattern(); RedissonClient.findBuckets(); |
| LINDEX | RList.get(), RList.getAsync(), RListReactive.get(); |
| LLEN | RList.size(), RList.sizeAsync(), RListReactive.Size(); |
| LPOP | RQueue.poll(), RQueue.pollAsync(), RQueueReactive.poll(); |
| LPUSH | RDeque.addFirst(), RDeque.addFirstAsync(); RDequeReactive.addFirst(), RDeque.offerFirst(), RDeque.offerFirstAsync(), RDequeReactive.offerFirst(); |
| LRANGE | RList.readAll(), RList.readAllAsync(), RListReactive.readAll(); |
| LREM | RList.fastRemove(), RList.fastRemoveAsync(), RList.remove(), RList.removeAsync(), RListReactive.remove(); RDeque.removeFirstOccurrence(), RDeque.removeFirstOccurrenceAsync(), RDequeReactive.removeFirstOccurrence(); RDeque.removeLastOccurrence(), RDeque.removeLastOccurrenceAsync(), RDequeReactive.removeLastOccurrence(); |
| LSET | RList.fastSet(), RList.fastSetAsync(), RListReactive.fastSet(); |
| LTRIM | RList.trim(), RList.trimAsync(), RListReactive.trim(); |
| LINSERT | RList.addBefore(), RList.addBeforeAsync(), RList.addAfter(), RList.addAfterAsync(), RListReactive.addBefore(), RListReactive.addAfter(); |
| MULTI | RBatch.execute(), RBatch.executeAsync(), RBatchReactive.execute(); |
| MGET | RedissonClient.loadBucketValues(); |
| MIGRATE | RObject.migrate(), RObject.migrateAsync(); |
| MOVE | RObject.move(), RObject.moveAsync(); |
| MSET | RedissonClient.saveBuckets(); |
| PERSIST | RExpirable.clearExpire(), RExpirable.clearExpireAsync(), RExpirableReactive.clearExpire(); |
| PEXPIRE | RExpirable.expire(), RExpirable.expireAsync(), RExpirableReactive.expire(); |
| PEXPIREAT | RExpirable.expireAt(), RExpirable.expireAtAsync(), RExpirableReactive.expireAt(); |
| PFADD | RHyperLogLog.add(), RHyperLogLog.addAsync(), RHyperLogLogReactive.add(); RHyperLogLog.addAll(), RHyperLogLog.addAllAsync(), RHyperLogLogReactive.addAll(); |
| PFCOUNT | RHyperLogLog.count(), RHyperLogLog.countAsync(), RHyperLogLogReactive.count(); RHyperLogLog.countWith(), RHyperLogLog.countWithAsync(), RHyperLogLogReactive.countWith(); |
| PFMERGE | RHyperLogLog.mergeWith(), RHyperLogLog.mergeWithAsync(), RHyperLogLogReactive.mergeWith(); |
| PING | Node.ping(); NodesGroup.pingAll(); |
| PSUBSCRIBE | RPatternTopic.addListener(); |
| PTTL | RExpirable.remainTimeToLive(), RExpirable.remainTimeToLiveAsync(), RExpirableReactive.remainTimeToLive(); |
| PUBLISH | RTopic.publish |
| PUNSUBSCRIBE | RPatternTopic.removeListener(); |
| RANDOMKEY | RKeys.randomKey(), RKeys.randomKeyAsync(), RKeysReactive.randomKey(); |
| RESTORE | RObject.restore(), RObject.restoreAsync, RObjectReactive.restore(); |
| RENAME | RObject.rename(), RObject.renameAsync(), RObjectReactive.rename(); |
| RENAMENX | RObject.renamenx(), RObject.renamenxAsync(), RObjectReactive.renamenx(); |
| RPOP | RDeque.pollLast(), RDeque.pollLastAsync(), RDequeReactive.pollLast(); RDeque.removeLast(), RDeque.removeLastAsync(), RDequeReactive.removeLast(); |
| RPOPLPUSH | RDeque.pollLastAndOfferFirstTo(), RDeque.pollLastAndOfferFirstToAsync(); |
| RPUSH | RList.add(), RList.addAsync(), RListReactive.add(); |
| SADD | RSet.add(), RSet.addAsync(), RSetReactive.add(); |
| SCARD | RSet.size(), RSet.sizeAsync(), RSetReactive.size(); |
| SCRIPT EXISTS | RScript.scriptExists(), RScript.scriptExistsAsync(), RScriptReactive.scriptExists(); |
| SCRIPT FLUSH | RScript.scriptFlush(), RScript.scriptFlushAsync(), RScriptReactive.scriptFlush(); |
| SCRIPT KILL | RScript.scriptKill(), RScript.scriptKillAsync(), RScriptReactive.scriptKill(); |
| SCRIPT LOAD | RScript.scriptLoad(), RScript.scriptLoadAsync(), RScriptReactive.scriptLoad(); |
| SDIFFSTORE | RSet.diff(), RSet.diffAsync(), RSetReactive.diff(); |
| SELECT | Config.setDatabase(); |
| SET | RBucket.set(); RBucket.setAsync(); RBucketReactive.set(); |
| SETBIT | RBitSet.set(); RBitSet.setAsync(); RBitSet.clear(); RBitSet.clearAsync(); |
| SETEX | RBucket.set(); RBucket.setAsync(); RBucketReactive.set(); |
| SETNX | RBucket.trySet(); RBucket.trySetAsync(); RBucketReactive.trySet(); |
| SISMEMBER | RSet.contains(), RSet.containsAsync(), RSetReactive.contains(); |
| SINTERSTORE | RSet.intersection(), RSet.intersectionAsync(), RSetReactive.intersection(); |
| SINTER | RSet.readIntersection(), RSet.readIntersectionAsync(), RSetReactive.readIntersection(); |
| SMEMBERS | RSet.readAll(), RSet.readAllAsync(), RSetReactive.readAll(); |
| SMOVE | RSet.move(), RSet.moveAsync(), RSetReactive.move(); |
| SPOP | RSet.removeRandom(), RSet.removeRandomAsync(), RSetReactive.removeRandom(); |
| SREM | RSet.remove(), RSet.removeAsync(), RSetReactive.remove(); |
| SUBSCRIBE | RTopic.addListener(), RTopicReactive.addListener(); |
| SUNION | RSet.readUnion(), RSet.readUnionAsync(), RSetReactive.readUnion(); |
| SUNIONSTORE | RSet.union(), RSet.unionAsync(), RSetReactive.union(); |
| TTL | RExpirable.remainTimeToLive(), RExpirable.remainTimeToLiveAsync(), RExpirableReactive.remainTimeToLive(); |
| TYPE | RKeys.getType(); |
| UNSUBSCRIBE | RTopic.removeListener(), RTopicReactive.removeListener(); |
| WAIT | RBatch.syncSlaves, RBatchReactive.syncSlaves(); |
| ZADD | RScoredSortedSet.add(), RScoredSortedSet.addAsync(), RScoredSortedSetReactive.add(); |
| ZCARD | RScoredSortedSet.size(), RScoredSortedSet.sizeAsync(), RScoredSortedSetReactive.size(); |
| ZCOUNT | RScoredSortedSet.count(), RScoredSortedSet.countAsync(); |
| ZINCRBY | RScoredSortedSet.addScore(), RScoredSortedSet.addScoreAsync(), RScoredSortedSetReactive.addScore(); |
| ZLEXCOUNT | RLexSortedSet.lexCount(), RLexSortedSet.lexCountAsync(), RLexSortedSetReactive.lexCount(); RLexSortedSet.lexCountHead(), RLexSortedSet.lexCountHeadAsync(), RLexSortedSetReactive.lexCountHead(); RLexSortedSet.lexCountTail(), RLexSortedSet.lexCountTailAsync(), RLexSortedSetReactive.lexCountTail(); |
| ZRANGE | RScoredSortedSet.valueRange(), RScoredSortedSet.valueRangeAsync(), RScoredSortedSetReactive.valueRange(); |
| ZREVRANGE | RScoredSortedSet.valueRangeReversed(), RScoredSortedSet.valueRangeReversedAsync(), RScoredSortedSetReactive.valueRangeReversed(); |
| ZUNIONSTORE | RScoredSortedSet.union(), RScoredSortedSet.unionAsync(), RScoredSortedSetReactive.union(); |
| ZINTERSTORE | RScoredSortedSet.intersection(), RScoredSortedSet.intersectionAsync(), RScoredSortedSetReactive.intersection(); |
| ZRANGEBYLEX | RLexSortedSet.lexRange(), RLexSortedSet.lexRangeAsync(), RLexSortedSetReactive.lexRange(); RLexSortedSet.lexRangeHead(), RLexSortedSet.lexRangeHeadAsync(), RLexSortedSetReactive.lexRangeHead(); RLexSortedSet.lexRangeTail(), RLexSortedSet.lexRangeTailAsync(), RLexSortedSetReactive.lexRangeTail(); |
| ZRANGEBYSCORE | RScoredSortedSet.valueRange(), RScoredSortedSet.valueRangeAsync(), RScoredSortedSetReactive.valueRange(); RScoredSortedSet.entryRange(), RScoredSortedSet.entryRangeAsync(), RScoredSortedSetReactive.entryRange(); |
| TIME | RedissonClient.getNodesGroup().getNode().time(), RedissonClient.getClusterNodesGroup().getNode().time(); |
| ZRANK | RScoredSortedSet.rank(), RScoredSortedSet.rankAsync(), RScoredSortedSetReactive.rank(); |
| ZREM | RScoredSortedSet.remove(), RScoredSortedSet.removeAsync(), RScoredSortedSetReactive.remove(); RScoredSortedSet.removeAll(), RScoredSortedSet.removeAllAsync(), RScoredSortedSetReactive.removeAll(); |
| ZREMRANGEBYLEX | RLexSortedSet.removeRangeByLex(), RLexSortedSet.removeRangeByLexAsync(), RLexSortedSetReactive.removeRangeByLex(); RLexSortedSet.removeRangeHeadByLex(), RLexSortedSet.removeRangeHeadByLexAsync(), RLexSortedSetReactive.removeRangeHeadByLex(); RLexSortedSet.removeRangeTailByLex(), RLexSortedSet.removeRangeTailByLexAsync(), RLexSortedSetReactive.removeRangeTailByLex(); |
| ZREMRANGEBYLEX | RScoredSortedSet.removeRangeByRank(), RScoredSortedSet.removeRangeByRankAsync(), RScoredSortedSetReactive.removeRangeByRank(); |
| ZREMRANGEBYSCORE | RScoredSortedSet.removeRangeByScore(), RScoredSortedSet.removeRangeByScoreAsync(), RScoredSortedSetReactive.removeRangeByScore(); |
| ZREVRANGEBYSCORE | RScoredSortedSet.entryRangeReversed(), RScoredSortedSet.entryRangeReversedAsync(), RScoredSortedSetReactive.entryRangeReversed(), RScoredSortedSet.valueRangeReversed(), RScoredSortedSet.valueRangeReversedAsync(), RScoredSortedSetReactive.valueRangeReversed(); |
| ZREVRANK | RScoredSortedSet.revRank(), RScoredSortedSet.revRankAsync(), RScoredSortedSetReactive.revRank(); |
| ZSCORE | RScoredSortedSet.getScore(), RScoredSortedSet.getScoreAsync(), RScoredSortedSetReactive.getScore(); |
| SCAN | RKeys.getKeys(), RKeysReactive.getKeys(); |
| SSCAN | RSet.iterator(), RSetReactive.iterator(); |
| HSCAN | RMap.keySet().iterator(), RMap.values().iterator(), RMap.entrySet().iterator(), RMapReactive.keyIterator(), RMapReactive.valueIterator(), RMapReactive.entryIterator(); |
| ZSCAN | RScoredSortedSet.iterator(), RScoredSortedSetReactive.iterator(); |
十二、独立节点模式
12.1. 概述
Redisson Node 指的是 Redisson 在分布式运算环境中作为独立节点运行的一种模式。Redisson Node 的功能可以用来执行通过分布式执行服务或分布式调度执行服务发送的远程任务,也可以用来为分布式远程服务提供远端服务。 所有这些功能全部包含在一个 JAR 包里,您可以从这里下载。
12.2. 配置方法
12.2.1. 配置参数
Redisson Node 采用的是与 Redisson 框架同样的配置方法,并同时还增加了以下几个专用参数。值得注意的是 ExecutorService 使用的线程数量可以通过 threads 参数来设定。
mapReduceWorkers (MapReduce 的工作者数量)
默认值:0 用来指定执行 MapReduce 任务的工作者的数量 0 代表当前 CPU 核的数量
executorServiceWorkers(执行服务的工作者数量)
默认值:null 用一个 Map 结构来指定某个服务的工作者数量,Map 的 Key 是服务名称,用 value 指定数量。
redissonNodeInitializer(初始化监听器)
默认值:null
Redisson Node 启动完成后调用的初始化监听器。
12.2.2. 通过 JSON 和 YAML 配置文件配置独立节点
以下是 JSON 格式的配置文件范例,该范例是在集群模式配置方法基础上,增加了 Redisson Node 的配置参数。
{
"clusterServersConfig":{
"nodeAddresses":[
"//127.0.0.1:7004",
"//127.0.0.1:7001",
"//127.0.0.1:7000"
],
},
"threads":0,
"executorServiceThreads": 0,
"executorServiceWorkers": {"myExecutor1":3, "myExecutor2":5},
"redissonNodeInitializer": {"class":"org.mycompany.MyRedissonNodeInitializer"}
}以下是 YAML 格式的配置文件范例,该范例是在集群模式配置方法基础上,增加了 Redisson Node 的配置参数。
---
clusterServersConfig:
nodeAddresses:
- "//127.0.0.1:7004"
- "//127.0.0.1:7001"
- "//127.0.0.1:7000"
scanInterval: 1000
threads: 0
executorServiceThreads: 0
executorServiceWorkers:
myService1: 123
myService2: 421
redissonNodeInitializer: !<org.mycompany.MyRedissonNodeInitializer> {}12.3. 初始化监听器
Redisson Node 提供了在启动完成后,执行 RedissonNodeInitializer 指定的初始化监听器的机制。这个机制可以用在启动完成时执行注册在类路径(classpath)中分布式远程服务的实现,或其他必要业务逻辑。比如,通知其他订阅者关于一个新节点上线的通知:
public class MyRedissonNodeInitializer implements RedissonNodeInitializer {
@Override
public void onStartup(RedissonNode redissonNode) {
RMap<String, Integer> map = redissonNode.getRedisson().getMap("myMap");
// ...
// 或
redisson.getRemoteService("myRemoteService").register(MyRemoteService.class, new MyRemoteServiceImpl(...));
// 或
reidsson.getTopic("myNotificationTopic").publish("New node has joined. id:" + redissonNode.getId() + " remote-server:" + redissonNode.getRemoteAddress());
}
}12.4. 嵌入式运行方法
Redisson Node 也可以以嵌入式方式运行在其他应用当中。
// Redisson程序化配置代码
Config config = ...
// Redisson Node 程序化配置方法
RedissonNodeConfig nodeConfig = new RedissonNodeConfig(config);
Map<String, Integer> workers = new HashMap<String, Integer>();
workers.put("test", 1);
nodeConfig.setExecutorServiceWorkers(workers);
// 创建一个Redisson Node实例
RedissonNode node = RedissonNode.create(nodeConfig);
// 或者通过指定的Redisson实例创建Redisson Node实例
RedissonNode node = RedissonNode.create(nodeConfig, redisson);
node.start();
//...
node.shutdown();12.5. 命令行运行方法
下载 Redisson Node 的 JAR 包。
编写一个 JSON 或 YAML 格式的配置文件。
通过以下方式之一运行 Redisson Node: java -jar redisson-all.jar config.json 或 java -jar redisson-all.jar config.yaml
另外不要忘记添加 - Xmx 或 - Xms 之类的参数。
12.6. Docker 方式运行方法
无现有 Redis 环境:
首先运行 Redis: docker run -d --name redis-node redis
再运行 Redisson Node: docker run -d --network container:redis-node -e JAVA_OPTS=“” -v :/opt/redisson-node/redisson.conf redisson/redisson-node
- Redisson Node 的 JSON 或 YAML 配置文件路径 - JAVA 虚拟机的运行参数
有现有 Redis 环境:
运行 Redisson Node: docker run -d -e JAVA_OPTS=“” -v :/opt/redisson-node/redisson.conf redisson/redisson-node
- Redisson Node 的 JSON 或 YAML 配置文件路径 - JAVA 虚拟机的运行参数
十三、工具
13.1. 集群管理工具
Redisson 集群管理工具提供了通过程序化的方式,像 redis-trib.rb 脚本一样方便地管理 Redis 集群的工具。
13.1.1 创建集群
以下范例展示了如何创建三主三从的 Redis 集群。
ClusterNodes clusterNodes = ClusterNodes.create()
.master("127.0.0.1:7000").withSlaves("127.0.0.1:7001", "127.0.0.1:7002")
.master("127.0.0.1:7003").withSlaves("127.0.0.1:7004")
.master("127.0.0.1:7005");
ClusterManagementTool.createCluster(clusterNodes);主节点 127.0.0.1:7000 的从节点有 127.0.0.1:7001 和 127.0.0.1:7002。
主节点 127.0.0.1:7003 的从节点是 127.0.0.1:7004。
主节点 127.0.0.1:7005 没有从节点。
13.1.2 踢出节点
以下范例展示了如何将一个节点踢出集群。
ClusterManagementTool.removeNode("127.0.0.1:7000", "127.0.0.1:7002");
// 或
redisson.getClusterNodesGroup().removeNode("127.0.0.1:7002");将从节点 127.0.0.1:7002 从其主节点 127.0.0.1:7000 里踢出。
13.1.3 数据槽迁移
以下范例展示了如何将数据槽在集群的主节点之间迁移。
ClusterManagementTool.moveSlots("127.0.0.1:7000", "127.0.0.1:7002", 23, 419, 4712, 8490);
// 或
redisson.getClusterNodesGroup().moveSlots("127.0.0.1:7000", "127.0.0.1:7002", 23, 419, 4712, 8490);将番号为 23,419,4712 和 8490 的数据槽从 127.0.0.1:7002 节点迁移至 127.0.0.1:7000 节点。
以下范例展示了如何将一个范围的数据槽在集群的主节点之间迁移。
ClusterManagementTool.moveSlotsRange("127.0.0.1:7000", "127.0.0.1:7002", 51, 9811);
// 或
redisson.getClusterNodesGroup().moveSlotsRange("127.0.0.1:7000", "127.0.0.1:7002", 51, 9811);将番号范围在 [51, 9811](含)之间的数据槽从 127.0.0.1:7002 节点移动到 127.0.0.1:7000 节点。
13.1.4 添加从节点
以下范例展示了如何向集群中添加从节点。
ClusterManagementTool.addSlaveNode("127.0.0.1:7000", "127.0.0.1:7003");
// 或
redisson.getClusterNodesGroup().addSlaveNode("127.0.0.1:7003");将 127.0.0.1:7003 作为从节点添加至 127.0.0.1:7000 所在的集群里。
13.2.5 添加主节点
以下范例展示了如何向集群中添加主节点。
ClusterManagementTool.addMasterNode("127.0.0.1:7000", "127.0.0.1:7004");
// 或
redisson.getClusterNodesGroup().addMasterNode("127.0.0.1:7004");将 127.0.0.1:7004 作为主节点添加至 127.0.0.1:7000 所在的集群里。 Adds master node 127.0.0.1:7004 to cluster where 127.0.0.1:7000 participate in
该功能仅限于 Redisson PRO 版本。
十四、第三方框架整合
14.1. Spring 框架整合
(1)引入 pom
<!-- 以后使用Redisson作为所有分布式锁 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.0</version>
</dependency>(2)配置类
/**
* 所有对Redisson的使用都是通过RedissonClient
*/
@Bean(destroyMethod="shutdown")
public RedissonClient redisson() throws IOException {
//1、创建单节点配置
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.56.10:6379");
//2、根据Config创建出RedissonClient实例
//Redis url should start with redis:// or rediss://
//可以用"rediss://"来启用SSL连接
RedissonClient redissonClient = Redisson.create(config);
return redissonClient;
}注意:此处为单机实例,集群、哨兵等实例请查看二、配置方法
(3)使用
直接 @Autoware 注入 RedissonClient 即可使用。
14.2. Spring Cache 整合
Redisson 提供了将 Redis 无缝整合到 Spring 框架的能力。Redisson 依照 Spring Cache 标准提供了基于 Redis 的 Spring 缓存实现。 每个缓存(Cache)实例都提供了了两个重要的可配置参数:过期时间(ttl)和最长空闲时间(maxIdleTime),如果这两个参数都未指定或值为 0,那么实例管理的数据将永久保存。 配置范例:
@Configuration
@ComponentScan
@EnableCaching
public static class Application {
@Bean(destroyMethod="shutdown")
RedissonClient redisson() throws IOException {
Config config = new Config();
config.useClusterServers()
.addNodeAddress("127.0.0.1:7004", "127.0.0.1:7001");
return Redisson.create(config);
}
@Bean
CacheManager cacheManager(RedissonClient redissonClient) {
Map<String, CacheConfig> config = new HashMap<String, CacheConfig>();
// 创建一个名称为"testMap"的缓存,过期时间ttl为24分钟,同时最长空闲时maxIdleTime为12分钟。
config.put("testMap", new CacheConfig(24*60*1000, 12*60*1000));
return new RedissonSpringCacheManager(redissonClient, config);
}
}Spring Cache 也可以通过 JSON 或 YAML 配置文件来配置:
@Configuration
@ComponentScan
@EnableCaching
public static class Application {
@Bean(destroyMethod="shutdown")
RedissonClient redisson(@Value("classpath:/redisson.json") Resource configFile) throws IOException {
Config config = Config.fromJSON(configFile.getInputStream());
return Redisson.create(config);
}
@Bean
CacheManager cacheManager(RedissonClient redissonClient) throws IOException {
return new RedissonSpringCacheManager(redissonClient, "classpath:/cache-config.json");
}
}14.2.1. Spring Cache - 本地缓存和数据分片
Redisson 提供了几种不同的 Spring Cache Manager,按功能可以分为以下两大类:
-
本地缓存(Local Cache) 类 – 本地缓存(Local Cache)也叫就近缓存(Near Cache)。这类 Spring Cache 的使用主要用于在特定的场景下,映射缓存(MapCache)上的高度频繁的读取操作,使网络通信都被视为瓶颈的情况。Redisson 与 Redis 通信的同时,还将部分数据保存在本地内存里。这样的设计的好处是它能将读取速度提高最多 45 倍 。
-
数据分片(Sharding) 类 – 数据分片(Sharding)类仅适用于 Redis 集群环境下,因此带有数据分片(Sharding)功能的 Spring Cache 也叫集群分布式 Spring 缓存。它利用分库的原理,将单一一个缓存结构切分为若干个小的缓存,并均匀的分布在集群中的各个槽里。这样的设计能使 Spring 缓存突破 Redis 自身的容量限制,让其容量随集群的扩大而增长。在扩容的同时,还能够使读写性能和元素淘汰处理能力随之成线性增长。
以下列表是 Redisson 提供的所有 Spring Cache Manager 的名称及其特性:
| 类名 | 本地缓存功能 Local Cache |
数据分片功能 Sharding |
|---|---|---|
| RedissonSpringCacheManager | No | No |
| RedissonClusteredSpringLocalCachedCacheManager 仅限于 Redisson PRO 版本 |
Yes | No |
| RedissonClusteredSpringCacheManager 仅限于 Redisson PRO 版本 |
No | Yes |
| RedissonSpringClusteredLocalCachedCacheManager 仅限于 Redisson PRO 版本 |
Yes | Yes |
在初始化 org.redisson.spring.cache.RedissonSpringLocalCachedCacheManager 对象和 org.redisson.spring.cache.RedissonSpringClusteredLocalCachedCacheManager 对象的时候可以通过 LocalCachedMapOptions 对象来配置选项。
LocalCachedMapOptions options = LocalCachedMapOptions.defaults()
// 淘汰机制有LFU, LRU和NONE这几种算法策略可供选择
.evictionPolicy(EvictionPolicy.LFU)
.cacheSize(1000)
// 如果该值是`真(true)`时,在该实例执行更新和删除操作的同时,将向其他所有的相同实例发
// 送针对该元素的淘汰消息。其他相同实例在收到该消息以后,会同时删除自身的缓存。下次读取
// 该元素时会从Redis服务器获取。
.invalidateEntryOnChange(false)
// 每个Map本地缓存里元素的有效时间,默认毫秒为单位
.timeToLive(10000)
// 或者
.timeToLive(10, TimeUnit.SECONDS)
// 每个Map本地缓存里元素的最长闲置时间,默认毫秒为单位
.maxIdle(10000)
// 或者
.maxIdle(10, TimeUnit.SECONDS);Redisson 为每个 Spring 缓存实例都提供了两个很重要的参数:ttl 和 maxIdleTime,当两个参数设为 0 或为指定值时,缓存数据将永久保留。
完整的使用范例如下:
@Configuration
@ComponentScan
@EnableCaching
public static class Application {
@Bean(destroyMethod="shutdown")
RedissonClient redisson() throws IOException {
Config config = new Config();
config.useClusterServers()
.addNodeAddress("127.0.0.1:7004", "127.0.0.1:7001");
return Redisson.create(config);
}
@Bean
CacheManager cacheManager(RedissonClient redissonClient) {
Map<String, CacheConfig> config = new HashMap<String, CacheConfig>();
LocalCachedMapOptions options = LocalCachedMapOptions.defaults()
.evictionPolicy(EvictionPolicy.LFU)
.cacheSize(1000);
// 创建一个名称为"testMap"的缓存,过期时间ttl为24分钟,同时最长空闲时maxIdleTime为12分钟。
config.put("testMap", new LocalCachedCacheConfig(24*60*1000, 12*60*1000, options));
return new RedissonSpringLocalCachedCacheManager(redissonClient, config);
}
}也可以通过 JSON 或 YAML 配置文件来设置相关缓存参数:
@Configuration
@ComponentScan
@EnableCaching
public static class Application {
@Bean(destroyMethod="shutdown")
RedissonClient redisson(@Value("classpath:/redisson.yaml") Resource configFile) throws IOException {
Config config = Config.fromYAML(configFile.getInputStream());
return Redisson.create(config);
}
@Bean
CacheManager cacheManager(RedissonClient redissonClient) throws IOException {
return new RedissonSpringLocalCachedCacheManager(redissonClient, "classpath:/cache-config.yaml");
}
}14.2.2. Spring Cache - JSON 和 YAML 配置文件格式:
JSON:
{
"testMap": {
"ttl": 1440000,
"maxIdleTime": 720000,
"localCacheOptions": {
"invalidationPolicy": "ON_CHANGE",
"evictionPolicy": "NONE",
"cacheSize": 0,
"timeToLiveInMillis": 0,
"maxIdleInMillis": 0
}
}
}YAML:
---
testMap:
ttl: 1440000
maxIdleTime: 720000
localCacheOptions:
invalidationPolicy: "ON_CHANGE"
evictionPolicy: "NONE"
cacheSize: 0
timeToLiveInMillis: 0
maxIdleInMillis: 0以上内容是名叫 testMap 的 Spring 缓存实例的配置方式。
需要注意的是:localCacheOptions 配置实例仅适用于 org.redisson.spring.cache.RedissonSpringLocalCachedCacheManager 类和 org.redisson.spring.cache.RedissonSpringClusteredLocalCachedCacheManager 类。
14.3. Hibernate 整合
hibernate-redis 项目实现了 Redisson 与 Hibernate 的完美整合。
14.3.1. Hibernate 二级缓存 - 本地缓存和数据分片
Redisson 提供了几种不同的 Hibernate Cache Factory,按功能主要分为两大类:
-
本地缓存 类 – 本地缓存(Local Cache)也叫就近缓存(Near Cache)。这类 Hibernate Cache 的使用主要用于在特定的场景下,映射缓存(MapCache)上的高度频繁的读取操作,使网络通信都被视为瓶颈的情况。Redisson 与 Redis 通信的同时,还将部分数据保存在本地内存里。这样的设计的好处是它能将读取速度提高最多 5 倍 。
-
数据分片 类 – 数据分片(Sharding)类仅适用于 Redis 集群环境下,因此带有数据分片(Sharding)功能的 Hibernate Cache 也叫集群分布式 Hibernate 二级缓存。它利用分库的原理,将单一一个缓存结构切分为若干个小的缓存,并均匀的分布在集群中的各个槽里。这样的设计能使 Hibernate 缓存突破 Redis 自身的容量限制,让其容量随集群的扩大而增长。在扩容的同时,还能够使读写性能和元素淘汰处理能力随之成线性增长。
以下列表是 Redisson 提供的所有 Hibernate Cache Factory 的名称及其特性:
| 类名 | 本地缓存功能 Local Cache |
数据分片功能 Sharding |
|---|---|---|
| SingletonRedisRegionFactory | No | No |
| LocalCachedRedisRegionFactory 仅限于 Redisson PRO 版本 |
Yes | No |
| ClusteredRedisRegionFactory 仅限于 Redisson PRO 版本 |
No | Yes |
| ClusteredLocalCachedRedisRegionFactory 仅限于 Redisson PRO 版本 |
Yes | Yes |
配置范例如下:
// 二级缓存
props.put(Environment.USE_SECOND_LEVEL_CACHE, true);
props.put(Environment.USE_QUERY_CACHE, true);
props.put(Environment.CACHE_REGION_FACTORY, org.redisson.hibernate.v52.LocalCachedRedisRegionFactory.class.getName());
props.put(Environment.CACHE_REGION_PREFIX, "hibernate");
// 为Hibernate提供Redis相关的配置
props.put(Environment.CACHE_PROVIDER_CONFIG, "hibernate-redis.properties");hibernate-redis.properties 文件范例:
hibernate-redis.properties 文件
# redisson配置文件地址
redisson-config=conf/redisson.yaml
# 为缓存指定默认过期时间
redis.expiryInSeconds.default=120
# 为缓存指定默认过期策略
# 如果过期策略采用了`ON_CHANGE`、`ON_CHANGE_WITH_CLEAR_ON_RECONNECT`或是`ON_CHANGE_WITH_LOAD_ON_RECONNECT`
# 那么在修改或删除映射元素的时候,相应的映射元素将被从所有掌握该缓存的Hibernate本地缓存实例中驱除
redis.localCache.invalidationPolicy.default=ON_CHANGE_WITH_CLEAR_ON_RECONNECT
# 如果本地缓存最大数量设定为`0`则表示默认缓存的元素数量不受限制
redis.localCache.cacheSize.default=10000
# 有`LFU`、`LRU`、`SOFT`、`WEAK`以及`NONE`这几种默认驱逐策略可供选择
redis.localCache.evictionPolicy.default=LFU
# 默认每个本地缓存中的元素过期时间
redis.localCache.timeToLiveInMillis.default=1000000
# 默认每个本地缓存中的元素最大闲置时间
redis.localCache.maxIdleInMillis.default=1000000
# 指定`player`区域的过期时间
redis.expiryInSeconds.hibernate.player=900
# `player`区域的本地缓存相关设定
redis.localCache.invalidationPolicy.hibernate.player=ON_CHANGE_WITH_CLEAR_ON_RECONNECT
redis.localCache.cacheSize.hibernate.player=10000
redis.localCache.evictionPolicy.hibernate.player=LFU
redis.localCache.timeToLiveInMillis.hibernate.player=1000000
redis.localCache.maxIdleInMillis.hibernate.player=1000000需要注意的是: redis.localCache.* 配置参数仅适用于 ClusteredLocalCachedRedisRegionFactory 类和 LocalCachedRedisRegionFactory 类。
14.4. Java 缓存标准规范 JCache API (JSR-107)
Redisson 在 Redis 的基础上实现了 Java 缓存标准规范(JCache API JSR-107)
以下范例展示了使用 Java 缓存标准的用法。范例采用了保存在默认路径 /redisson-jcache.json 或 /redisson-jcache.yaml 下的配置文件构造实例。
MutableConfiguration<String, String> config = new MutableConfiguration<>();
CacheManager manager = Caching.getCachingProvider().getCacheManager();
Cache<String, String> cache = manager.createCache("namedCache", config);也可以采用指定配置文件路径的方式构造实例:
MutableConfiguration<String, String> config = new MutableConfiguration<>();
// JSON格式的配置文件
URI redissonConfigUri = getClass().getResource("redisson-jcache.json").toURI();
// YAML格式的配置文件
URI redissonConfigUri = getClass().getResource("redisson-jcache.yaml").toURI();
CacheManager manager = Caching.getCachingProvider().getCacheManager(redissonConfigUri, null);
Cache<String, String> cache = manager.createCache("namedCache", config);还可以通过程序化的方式来构造:
MutableConfiguration<String, String> jcacheConfig = new MutableConfiguration<>();
Config redissonCfg = ...
Configuration<String, String> config = RedissonConfiguration.fromConfig(redissonCfg, jcacheConfig);
CacheManager manager = Caching.getCachingProvider().getCacheManager();
Cache<String, String> cache = manager.createCache("namedCache", config);甚至可以用 Redisson 实例来构造:
MutableConfiguration<String, String> jcacheConfig = new MutableConfiguration<>();
RedissonClient redisson = ...
Configuration<String, String> config = RedissonConfiguration.fromInstance(redisson, jcacheConfig);
CacheManager manager = Caching.getCachingProvider().getCacheManager();
Cache<String, String> cache = manager.createCache("namedCache", config);关于配置 Redisson 的方式详见二、配置方法。
由 Redisson 提供的 JCache (JSR-107) 完全符合标准要求并全部通过 TCK 标准检测。标准检验代码在这里。
14.5. Tomcat 会话管理器(Tomcat Session Manager)
Redisson 为 Apache Tomcat 集群提供了基于 Redis 的非黏性会话管理功能。该功能支持 Apache Tomcat 的 6.x、7.x、8.x 和 9.x 版。
Redisson 实现的方式有别于现有的其他的 Tomcat 会话管理器(Tomcat Session Manager)。在每次调用 HttpSession.setAttribute 接口方法时,以每一条会话的字段属性(Attribute)为单位,将修改内容记录在 Redis 的一个 Hash 结构里。相比之下,其他的现有解决方案都普遍采用的是:在任何一个字段属性更改时,将整个会话序列化后保存。Redisson 的实现方式产生的优势显而易见:在为 Tomcat 集群提供高效的非黏性会话管理的同时,避免了同一客户端的多个并发请求造成业务逻辑混乱。
使用方法:
(1)首先将 RedissonSessionManager 添加到相关的 context.xml 里:
<Manager className="org.redisson.tomcat.RedissonSessionManager"
configPath="${catalina.base}/redisson.conf" updateMode="DEFAULT" />readMode - 用来设定读取会话里各个属性的方式。主要分为以下两种:
- MEMORY - 内存读取模式。直接从本地 Tomcat 中的会话里读取。这是默认情况。
- REDIS - Redis 读取模式。绕过本地会话信息,直接从 Redis 里读取。
updateMode - 用来设定更新会话属性的方式。主要有以下两种:
- DEFAULT - 会话的属性只能通过 setAttribute 方法来储存到 Redis 里。这是默认请况。
- AFTER_REQUEST - 再每次请求结束以后进行一次所有属性全量写入 Redis。
configPath - 是指的 Redisson 的 JSON 或 YAML 格式的配置文件路径。配置文件详见这里。
(2)拷贝相应的 两个 JAR 包到指定的 TOMCAT_BASE/lib 目录下:
(3)JDK 1.8 + 适用
redisson-all-3.6.4.jar
Tomcat 6.x 适用 redisson-tomcat-6-3.6.4.jar
Tomcat 7.x 适用 redisson-tomcat-7-3.6.4.jar
Tomcat 8.x 适用 redisson-tomcat-8-3.6.4.jar
Tomcat 9.x 适用 redisson-tomcat-9-3.6.4.jar
(4)JDK 1.6 + 适用
redisson-all-2.11.4.jar
Tomcat 6.x 适用 redisson-tomcat-6-2.11.4.jar
Tomcat 7.x 适用 redisson-tomcat-7-2.11.4.jar
Tomcat 8.x 适用 redisson-tomcat-8-2.11.4.jar
14.6. Spring 会话管理器(Spring Session Manager)
Redisson 提供的 Spring 会话管理器(Spring Session Manager)实现了跨机 Web 会话共享的功能。
在每次调用 HttpSession.setAttribute 接口方法时,以每一条会话的字段属性(Attribute)为单位,将修改内容记录在 Redis 的一个 Hash 结构里。需要注意的是 Redis 服务端的 notify-keyspace-events 参数设置中需要包含 Exg 这三个字符。
使用方法:
(1)首先请确保 Spring Session library 版本号为 1.2.2 + 的依赖已经添加到了您的项目中:
Maven:
<!-- for Redisson 2.x -->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session</artifactId>
<version>1.3.2.RELEASE</version>
</dependency>
<!-- for Redisson 3.x -->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-core</artifactId>
<version>2.1.2.RELEASE</version>
</dependency>Gradle:
// for Redisson 2.x
compile 'org.springframework.session:spring-session:1.3.2.RELEASE'
// for Redisson 3.x
compile 'org.springframework.session:spring-session-core:2.1.2.RELEASE' (2)然后将 @EnableRedissonHttpSession 注释和 Redisson 实例添加到 Spring 的配置里:
@EnableRedissonHttpSession
public class Config {
@Bean
public RedissonClient redisson() {
return Redisson.create();
}
}(3)然后提供一个启动器 AbstractHttpSessionApplicationInitializer 的扩展就行了:
public class Initializer extends AbstractHttpSessionApplicationInitializer {
public Initializer() {
super(Config.class);
}
}14.7. Spring 事务管理器(Spring Transaction Manager)
Redisson 为 Spring 事务(Spring Transaction)提供了基于 org.springframework.transaction.PlatformTransactionManager 接口的功能实现。另请查阅事务(Transaction) 章节。
代码范例:
@Configuration
@EnableTransactionManagement
public class RedissonTransactionContextConfig {
@Bean
public TransactionalBean transactionBean() {
return new TransactionalBean();
}
@Bean
public RedissonTransactionManager transactionManager(RedissonClient redisson) {
return new RedissonTransactionManager(redisson);
}
@Bean
public RedissonClient redisson() {
return BaseTest.createInstance();
}
@PreDestroy
public void destroy() {
redisson().shutdown();
}
}
public class TransactionalBean {
@Autowired
private RedissonTransactionManager transactionManager;
@Transactional
public void commitData() {
RTransaction transaction = transactionManager.getCurrentTransaction();
RMap<String, String> map = transaction.getMap("test1");
map.put("1", "2");
}
}14.8. Spring Data Redis 集成
(1)添加 redisson-spring-data 依赖
Maven:
<dependency>
<groupId>org.redisson</groupId>
<!-- for Spring Data Redis v.1.6.x -->
<artifactId>redisson-spring-data-16</artifactId>
<!-- for Spring Data Redis v.1.7.x -->
<artifactId>redisson-spring-data-17</artifactId>
<!-- for Spring Data Redis v.1.8.x -->
<artifactId>redisson-spring-data-18</artifactId>
<!-- for Spring Data Redis v.2.0.x -->
<artifactId>redisson-spring-data-20</artifactId>
<!-- for Spring Data Redis v.2.1.x -->
<artifactId>redisson-spring-data-21</artifactId>
<!-- for Spring Data Redis v.2.2.x -->
<artifactId>redisson-spring-data-22</artifactId>
<!-- for Spring Data Redis v.2.3.x -->
<artifactId>redisson-spring-data-23</artifactId>
<!-- for Spring Data Redis v.2.4.x -->
<artifactId>redisson-spring-data-24</artifactId>
<!-- for Spring Data Redis v.2.5.x -->
<artifactId>redisson-spring-data-25</artifactId>
<!-- for Spring Data Redis v.2.6.x -->
<artifactId>redisson-spring-data-26</artifactId>
<!-- for Spring Data Redis v.2.7.x -->
<artifactId>redisson-spring-data-27</artifactId>
<version>3.17.4</version>
</dependency>Gradle:
// for Spring Data Redis v.1.6.x
compile 'org.redisson:redisson-spring-data-16:3.17.4'
// for Spring Data Redis v.1.7.x
compile 'org.redisson:redisson-spring-data-17:3.17.4'
// for Spring Data Redis v.1.8.x
compile 'org.redisson:redisson-spring-data-18:3.17.4'
// for Spring Data Redis v.2.0.x
compile 'org.redisson:redisson-spring-data-20:3.17.4'
// for Spring Data Redis v.2.1.x
compile 'org.redisson:redisson-spring-data-21:3.17.4'
// for Spring Data Redis v.2.2.x
compile 'org.redisson:redisson-spring-data-22:3.17.4'
// for Spring Data Redis v.2.3.x
compile 'org.redisson:redisson-spring-data-23:3.17.4'
// for Spring Data Redis v.2.4.x
compile 'org.redisson:redisson-spring-data-24:3.17.4'
// for Spring Data Redis v.2.5.x
compile 'org.redisson:redisson-spring-data-25:3.17.4'
// for Spring Data Redis v.2.6.x
compile 'org.redisson:redisson-spring-data-26:3.17.4'
// for Spring Data Redis v.2.7.x
compile 'org.redisson:redisson-spring-data-27:3.17.4'(2)在 spring 容器中注册 RedissonConnectionFactory
@Configuration
public class RedissonSpringDataConfig {
@Bean
public RedissonConnectionFactory redissonConnectionFactory(RedissonClient redisson) {
return new RedissonConnectionFactory(redisson);
}
@Bean(destroyMethod = "shutdown")
public RedissonClient redisson(@Value("classpath:/redisson.yaml") Resource configFile) throws IOException {
Config config = Config.fromYAML(configFile.getInputStream());
return Redisson.create(config);
}
}14.9. Spring Boot Starter 集成
支持 Spring Boot 1.3.x - 2.7.x
(1)将 redisson-spring-boot-starter 依赖添加到项目中
Maven:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.17.4</version>
</dependency>Gradle:
compile 'org.redisson:redisson-spring-boot-starter:3.17.4'如果需要的话,降级 redisson-spring-data 模块以支持所需的 Spring Boot 版本:
| redisson-spring-data module name |
Spring Boot version |
|---|---|
| redisson-spring-data-16 | 1.3.y |
| redisson-spring-data-17 | 1.4.y |
| redisson-spring-data-18 | 1.5.y |
| redisson-spring-data-2x | 2.x.y |
(2)添加配置文件 application.settings
使用通用的 springboot 配置:
spring:
redis:
database:
host:
port:
password:
ssl:
timeout:
cluster:
nodes:
sentinel:
master:
nodes:使用 Redisson 的配置:
spring:
redis:
redisson:
file: classpath:redisson.yaml
config: |
clusterServersConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
failedSlaveReconnectionInterval: 3000
failedSlaveCheckInterval: 60000
password: null
subscriptionsPerConnection: 5
clientName: null
loadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}
subscriptionConnectionMinimumIdleSize: 1
subscriptionConnectionPoolSize: 50
slaveConnectionMinimumIdleSize: 24
slaveConnectionPoolSize: 64
masterConnectionMinimumIdleSize: 24
masterConnectionPoolSize: 64
readMode: "SLAVE"
subscriptionMode: "SLAVE"
nodeAddresses:
- "redis://127.0.0.1:7004"
- "redis://127.0.0.1:7001"
- "redis://127.0.0.1:7000"
scanInterval: 1000
pingConnectionInterval: 0
keepAlive: false
tcpNoDelay: false
threads: 16
nettyThreads: 32
codec: !<org.redisson.codec.MarshallingCodec> {}
transportMode: "NIO"可用的 spring 的 beans:
RedissonClient
RedissonRxClient
RedissonReactiveClient
RedisTemplate
ReactiveRedisTemplate
14.10. 统计与监控 (JMX 和其它监控系统)
该功能仅适用于 Redisson PRO 版本 Redisson 为各大知名监控系统提供了集成:
| 监控系统 | 适配类 从属于’org.redisson.config.metrics’包 |
参数 | 依赖包的 artifactId * |
|---|---|---|---|
| AppOptics | AppOpticsMeterRegistryProvider | uri, hostTag, apiToken | micrometer-registry-appoptics |
| Atlas | AtlasMeterRegistryProvider | uri, configUri, evalUri | micrometer-registry-atlas |
| Azure | AzureMonitorMeterRegistryProvider | instrumentationKey | micrometer-registry-azure-monitor |
| CloudWatch | CloudWatchMeterRegistryProvider | accessKey, secretKey, namespace | micrometer-registry-cloudwatch |
| Datadog | DatadogMeterRegistryProvider | uri, hostTag, apiKey | micrometer-registry-datadog |
| Dropwizard | DropwizardMeterRegistryProvider | sharedRegistryName | - |
| Dynatrace | DynatraceMeterRegistryProvider | apiToken, uri, deviceId | micrometer-registry-dynatrace |
| Elastic | ElasticMeterRegistryProvider | host, userName, password | micrometer-registry-elastic |
| Ganglia | GangliaMeterRegistryProvider | host, port | micrometer-registry-ganglia |
| Graphite | GraphiteMeterRegistryProvider | host, port | micrometer-registry-graphite |
| Humio | HumioMeterRegistryProvider | uri, repository, apiToken | micrometer-registry-humio |
| Influx | InfluxMeterRegistryProvider | uri, db, userName, password | micrometer-registry-influx |
| JMX | JmxMeterRegistryProvider | domain, sharedRegistryName | micrometer-registry-jmx |
| Kairos | KairosMeterRegistryProvider | uri, userName, password | micrometer-registry-kairos |
| NewRelic | NewRelicMeterRegistryProvider | uri, apiKey, accountId | micrometer-registry-new-relic |
| Prometheus | PrometheusMeterRegistryProvider | - | micrometer-registry-prometheus |
| SingnalFx | SingnalFxMeterRegistryProvider | accessToken, apiHost, source | micrometer-registry-signalfx |
| Stackdriver | StackdriverMeterRegistryProvider | projectId | micrometer-registry-stackdriver |
| Statsd | StatsdMeterRegistryProvider | flavor, host, port | micrometer-registry-statsd |
| Wavefront | WavefrontMeterRegistryProvider | uri, source, apiToken | micrometer-registry-wavefront |
- groupId 统一为 ‘io.micrometer’
配置方法
Config config = ... // Redisson的Config对象
DropwizardMeterRegistryProvider provider = new DropwizardMeterRegistryProvider();
provider.setSharedRegistryName("mySharedRegistry");
config.setMeterRegistryProvider(provider);也可以在 YAML 格式的配置文件中添加以下配置参数:
meterRegistryProvider: !<org.redisson.config.metrics.DropwizardMeterRegistryProvider>
sharedRegistryName: "mySharedRegistry"Redisson 提供了以下这些性能监控指标
客户端配置相关指标
- redisson.executor-pool-size - [Gauge] 用于展示 Executor 线程池大小的度量值
- redisson.netty-pool-size - [Gauge] 用于展示 Netty 线程池大小的度量值
每个 Redis 节点的指标
名称前缀格式:redisson.redis.<host>:< port>
-
status - [Gauge] 用于展示连接状态,连接 和 断开 状态的值分别为:[connected, disconnected]
-
type - [Gauge] 用于展示节点类型,主节点 和 从节点 的状态值分别为:[MASTER, SLAVE]
-
total-response-bytes - [Meter] 用于统计从该节点收到的总字节量
-
response-bytes - [Histogram] 用于统计从该节点收到的字节量
-
total-request-bytes - [Meter] 用于统计写入到该节点的总字节量
-
request-bytes - [Histogram] 用于统计写入到该节点的字节量
-
connections.active - [Counter] 用于显示客户端到该 Redis 节点的连接池当前 正在使用 的连接数量
-
connections.free - [Counter] 用于显示客户端到该 Redis 节点的连接池当前 空闲 的连接数量
-
connections.max-pool-size - [Counter] 用于显示客户端到该 Redis 节点的连接池大小
-
connections.total - [Counter] 用于显示客户端到该 Redis 节点的连接池当前 所有 的连接数量
-
operations.total - [Meter] 用于统计客户端到该 Redis 节点所有 已发送 的指令数量
-
operations.total-failed - [Meter] 用于统计客户端到该 Redis 节点所有 发送失败 的指令数量
-
operations.total-successful - [Meter] 用于统计客户端到该 Redis 节点所有 发送成功 的指令数量
-
publish-subscribe-connections.active - [Counter] 用于显示客户端到该 Redis 节点用于订阅发布的连接池 正在使用 的连接数量
-
publish-subscribe-connections.free - [Counter] 用于显示客户端到该 Redis 节点用于订阅发布的连接池 空闲 的连接数量
-
publish-subscribe-connections.max-pool-size - [Counter] 用于显示客户端到该 Redis 节点用于订阅发布的连接池大小
-
publish-subscribe-connections.total - [Counter] 用于显示客户端到该 Redis 节点用于订阅发布的连接池 所有 的连接数量
每个分布式远程服务(RRemoteService)对象的指标
名称前缀格式:redisson.remote-service.<name>
- invocations.total - [Meter] 用于统计该远程服务对象所有 已执行 的请求数量
- invocations.total-failed - [Meter] 用于统计该远程服务对象 执行失败 的请求数量
- invocations.total-successful - [Meter] 用于统计该远程服务对象 执行成功 的请求数量
每个分布式执行服务(RExecutorService)对象的指标
名称前缀格式:redisson.executor-service.<name>
-
tasks.submitted - [Meter] 用于统计 已提交 的任务数量
-
tasks.executed - [Meter] 用于统计 已执行 的任务数量
-
workers.active - [Gauge] 用于统计 工作中 的任务线程(Workers)数量
-
workers.free - [Gauge] 用于统计 空闲 的任务线程(Workers)数量
-
workers.total - [Gauge] 用于统计 所有 的任务线程(Workers)数量
-
workers.tasks-executed.total - [Meter] 用于统计任务线程(Workers) 已执行 的任务数量
-
workers.tasks-executed.total-failed - [Meter] 用于统计任务线程(Workers) 执行失败 的任务数量
-
workers.tasks-executed.total-successful - [Meter] 用于统计任务线程(Workers) 执行成功 的任务数量
每个分布式映射(RMap)对象的指标
名称前缀:redisson.map.<name>
- hits - [Meter] 用于统计 Redis 命中(Redis 内 有 需要的数据)的次数
- misses - [Meter] 用于统计 Redis 未命中(Redis 内 没有 需要的数据)的次数
- puts - [Meter] 用于统计 写入 操作次数
- removals - [Meter] 用于统计 擦除 操作次数
每个集群分布式映射缓存(RClusteredMapCache)对象的指标
名称前缀:redisson.clustered-map-cache.<name>
- hits - [Meter] 用于统计 Redis 命中(Redis 内 有 需要的数据)的次数
- misses - [Meter] 用于统计 Redis 命中(Redis 内 没有 需要的数据)的次数
- puts - [Meter] 用于统计 写入 操作次数
- removals - [Meter] 用于统计 擦除 操作次数
每个分布式本地缓存映射(RLocalCachedMap)对象的指标
名称前缀:redisson.local-cached-map.<name>
-
hits - [Meter] 用于统计 Redis 命中(Redis 内 有 需要的数据)的次数
-
misses - [Meter] 用于统计 Redis 未命中(Redis 内 没有 需要的数据)的次数
-
puts - [Meter] 用于统计 写入 操作次数
-
removals - [Meter] 用于统计 擦除 操作次数
-
local-cache.hits - [Meter] 用于统计 本地命中(JVM 内 有 需要的数据)的次数
-
local-cache.misses - [Meter] 用于统计 本地未命中(Redis 内 没有 需要的数据)的次数
-
local-cache.evictions - [Meter] 用于统计 驱逐 发生次数
-
local-cache.size - [Gauge] 用于统计 本地缓存 的容量大小
每个集群分布式本地缓存映射(RClusteredLocalCachedMap)对象的指标
名称前缀:redisson.clustered-local-cached-map.<name>
-
hits - [Meter] 用于统计 Redis 命中(Redis 内 有 需要的数据)的次数
-
misses - [Meter] 用于统计 Redis 未命中(Redis 内 没有 需要的数据)的次数
-
puts - [Meter] 用于统计 写入 操作次数
-
removals - [Meter] 用于统计 擦除 操作次数
-
local-cache.hits - [Meter] 用于统计 本地命中(JVM 内 有 需要的数据)的次数
-
local-cache.misses - [Meter] 用于统计 本地未命中(Redis 内 没有 需要的数据)的次数
-
local-cache.evictions - [Meter] 用于统计 驱逐 发生次数
-
local-cache.size - [Gauge] 用于统计 本地缓存 的容量大小
每个分布式本地缓存映射缓存(RLocalCachedMapCache)对象的指标
名称前缀:redisson.local-cached-map-cache.
-
hits - [Meter] 用于统计 Redis 命中(Redis 内 有 需要的数据)的次数
-
misses - [Meter] 用于统计 Redis 未命中(Redis 内 没有 需要的数据)的次数
-
puts - [Meter] 用于统计 写入 操作次数
-
removals - [Meter] 用于统计 擦除 操作次数
-
local-cache.hits - [Meter] 用于统计 本地命中(JVM 内 有 需要的数据)的次数
-
local-cache.misses - [Meter] 用于统计 本地未命中(Redis 内 没有 需要的数据)的次数
-
local-cache.evictions - [Meter] 用于统计 驱逐 发生次数
-
local-cache.size - [Gauge] 用于统计 本地缓存 的容量大小
每个集群分布式本地缓存映射缓存(RClusteredLocalCachedMapCache)对象的指标
名称前缀:redisson.clustered-local-cached-map-cache.
-
hits - [Meter] 用于统计 Redis 命中(Redis 内 有 需要的数据)的次数
-
misses - [Meter] 用于统计 Redis 未命中(Redis 内 没有 需要的数据)的次数
-
puts - [Meter] 用于统计 写入 操作次数
-
removals - [Meter] 用于统计 擦除 操作次数
-
local-cache.hits - [Meter] 用于统计 本地命中(JVM 内 有 需要的数据)的次数
-
local-cache.misses - [Meter] 用于统计 本地未命中(Redis 内 没有 需要的数据)的次数
-
local-cache.evictions - [Meter] 用于统计 驱逐 发生次数
-
local-cache.size - [Gauge] 用于统计 本地缓存 的容量大小
每个分布式话题(RTopic)对象的指标
名称前缀:redisson.topic.
- messages-sent - [Meter] 用于统计向该话题 发送 出的消息数量
- messages-received - [Meter] 用于统计从该话题 接收 到的消息数量
每个分布式通用对象桶(RBucket)对象的指标
名称前缀:redisson.bucket.
- gets - [Meter] 用于该统计分布式通用对象桶 读取 操作的次数
- sets - [Meter] 用于该统计分布式通用对象桶 写入 操作的次数
该功能仅适用于 Redisson PRO 版本
十五、项目依赖列表
以下是所有被 Redisson 使用到的依赖:
| 组名(Group ID) | 项目名(Artifact ID) | 版本(version) | 依赖需求 |
|---|---|---|---|
| io.netty | netty-common | 4.1+ | 必要 |
| io.netty | netty-codec | 4.1+ | 必要 |
| io.netty | netty-buffer | 4.1+ | 必要 |
| io.netty | netty-transport | 4.1+ | 必要 |
| io.netty | netty-handler | 4.1+ | 必要 |
| com.fasterxml.jackson.dataformat | jackson-core | 2.7+ | 必要 |
| com.fasterxml.jackson.dataformat | jackson-databind | 2.7+ | 必要 |
| com.fasterxml.jackson.dataformat | jackson-annotations | 2.7+ | 必要 |
| com.fasterxml.jackson.dataformat | jackson-dataformat-yaml | 2.7+ | 必要 |
| org.yaml | snakeyaml | 1.0+ | 必要 |
| net.bytebuddy | byte-buddy | 1.6+ | 可选 (实时对象服务需要) |
| org.jodd | jodd-bean | 3.7+ | 可选 (实时对象服务需要) |
| javax.cache | cache-api | 1.0.0 | 可选(JCache JSR107 需要) |
| io.projectreactor | reactor-stream | 2.0.8 | 可选(使用 2.x 版本的 RedissonReactiveClient 的时候需要) |
| io.projectreactor | reactor-core | 3.1.1 | 可选(使用 3.5 + 版本的 RedissonReactiveClient 的时候需要) |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号