深入理解 Java 虚拟机到底是什么
什么是 Java 虚拟机
作为一个 Java 程序员,我们每天都在写 Java 代码,我们写的代码都是在一个叫做 Java 虚拟机的东西上执行的。但是如果要问什么是虚拟机,恐怕很多人就会模棱两可了。在本文中,我会写下我对虚拟机的理解。因为能力所限,可能有些地方描述的不够欠当。如果你有不同的理解,欢迎交流。
我们都知道 java 程序必须在虚拟机上运行。那么虚拟机到底是什么呢?先看网上搜索到的比较靠谱的解释:
虚拟机是一种抽象化的计算机,通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java 虚拟机有自己完善的硬体架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 Java 虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。
这种解释应该算是正确的,但是只描述了虚拟机的外部行为和功能,并没有针对内部原理做出说明。一般情况下我们不需要知道虚拟机的运行原理,只要专注写 java 代码就可以了,这也正是虚拟机之所以存在的原因 -- 屏蔽底层操作系统平台的不同并且减少基于原生语言开发的复杂性,使 java 这门语言能够跨各种平台(只要虚拟机厂商在特定平台上实现了虚拟机),并且简单易用。这些都是虚拟机的外部特性,但是从这些信息来解释虚拟机,未免太笼统了,无法让我们知道内部原理。
从进程的角度解释 JVM
让我们尝试从操作系统的层面来理解虚拟机。我们知道,虚拟机是运行在操作系统之中的,那么什么东西才能在操作系统中运行呢?当然是进程,因为进程是操作系统中的执行单位。可以这样理解,当它在运行的时候,它就是一个操作系统中的进程实例,当它没有在运行时(作为可执行文件存放于文件系统中),可以把它叫做程序。
对命令行比较熟悉的同学,都知道其实一个命令对应一个可执行的二进制文件,当敲下这个命令并且回车后,就会创建一个进程,加载对应的可执行文件到进程的地址空间中,并且执行其中的指令。下面对比 C 语言和 Java 语言的 HelloWorld 程序来说明问题。
首先编写 C 语言版的 HelloWorld 程序。
-
-
-
-
int main(void) {
-
printf("hello world\n");
-
return 0;
-
}
编译 C 语言版的 HelloWorld 程序:
gcc HelloWorld.c -o HelloWorld
运行 C 语言版的 HelloWorld 程序:
zhangjg@linux:/deve/workspace/HelloWorld/src$ ./HelloWorld
hello world
gcc 编译器编译后的文件直接就是可被操作系统识别的二进制可执行文件,当我们在命令行中敲下 ./HelloWorld 这条命令的时候, 直接创建一个进程, 并且将可执行文件加载到进程的地址空间中, 执行文件中的指令。
作为对比, 我们看一下 Java 版 HelloWord 程序的编译和执行形式。
首先编写源文件 HelloWord.java :
-
public class HelloWorld {
-
-
public static void main(String[] args) {
-
System.out.println("HelloWorld");
-
}
-
}
编译 Java 版的 HelloWorld 程序:
-
zhangjg:/deve/workspace/HelloJava/src$ javac HelloWorld.java
-
zhangjg:/deve/workspace/HelloJava/src$ ls
-
HelloWorld.class HelloWorld.java
运行 Java 版的 HelloWorld 程序:
zhangjg@linux:/deve/workspace/HelloJava/src$ java -classpath . HelloWorld
HelloWorld
从上面的过程可以看到, 我们在运行 Java 版的 HelloWorld 程序的时候, 敲入的命令并不是 ./HelloWorld.class 。 因为 class 文件并不是可以直接被操作系统识别的二进制可执行文件 。 我们敲入的是 java 这个命令。 这个命令说明, 我们首先启动的是一个叫做 java 的程序, 这个 java 程序在运行起来之后就是一个 JVM 进程实例。
上面的命令执行流程是这样的:
java 命令首先启动虚拟机进程,虚拟机进程成功启动后,读取参数 “HelloWorld”,把他作为初始类加载到内存,对这个类进行初始化和动态链接(关于类的初始化和动态链接会在后面的博客中介绍),然后从这个类的 main 方法开始执行。也就是说我们的.class 文件不是直接被系统加载后直接在 cpu 上执行的,而是被一个叫做虚拟机的进程托管的。首先必须虚拟机进程启动就绪,然后由虚拟机中的类加载器加载必要的 class 文件,包括 jdk 中的基础类(如 String 和 Object 等),然后由虚拟机进程解释 class 字节码指令,把这些字节码指令翻译成本机 cpu 能够识别的指令,才能在 cpu 上运行。
从这个层面上来看,在执行一个所谓的 java 程序的时候,真真正正在执行的是一个叫做 Java 虚拟机的进程,而不是我们写的一个个的 class 文件。这个叫做虚拟机的进程处理一些底层的操作,比如内存的分配和释放等等。我们编写的 class 文件只是虚拟机进程执行时需要的 “原料”。这些 “原料” 在运行时被加载到虚拟机中,被虚拟机解释执行,以控制虚拟机实现我们 java 代码中所定义的一些相对高层的操作,比如创建一个文件等,可以将 class 文件中的信息看做对虚拟机的控制信息,也就是一种虚拟指令。
编程语言也有自己的原理, 学习一门语言, 主要是把它的原理搞明白。 看似一个简单的 HelloWorld 程序, 也有很多深入的内容值得剖析。
JVM 体系结构简介
为了展示虚拟机进程和 class 文件的关系,特意画了下面一张图:
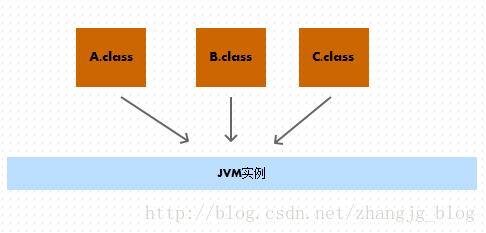
根据上图表达的内容,我们编译之后的 class 文件是作为 Java 虚拟机的原料被输入到 Java 虚拟机的内部的,那么具体由谁来做这一部分工作呢?其实在 Java 虚拟机内部,有一个叫做类加载器的子系统,这个子系统用来在运行时根据需要加载类。注意上面一句话中的 “根据需要” 四个字。在 Java 虚拟机执行过程中,只有他需要一个类的时候,才会调用类加载器来加载这个类,并不会在开始运行时加载所有的类。就像一个人,只有饿的时候才去吃饭,而不是一次把一年的饭都吃到肚子里。一般来说,虚拟机加载类的时机,在第一次使用一个新的类的时候。本专栏后面的文章会具体讨论 Java 中的类加载器。
由虚拟机加载的类,被加载到 Java 虚拟机内存中之后,虚拟机会读取并执行它里面存在的字节码指令。虚拟机中执行字节码指令的部分叫做执行引擎。就像一个人,不是把饭吃下去就完事了,还要进行消化,执行引擎就相当于人的肠胃系统。在执行的过程中还会把各个 class 文件动态的连接起来。关于执行引擎的具体行为和动态链接相关的内容也会在本专栏后续的文章中进行讨论。
我们知道,Java 虚拟机会进行自动内存管理。具体说来就是自动释放没有用的对象,而不需要程序员编写代码来释放分配的内存。这部分工作由垃圾收集子系统负责。
从上面的论述可以知道, 一个 Java 虚拟机实例在运行过程中有三个子系统来保障它的正常运行,分别是类加载器子系统, 执行引擎子系统和垃圾收集子系统。 如下图所示:
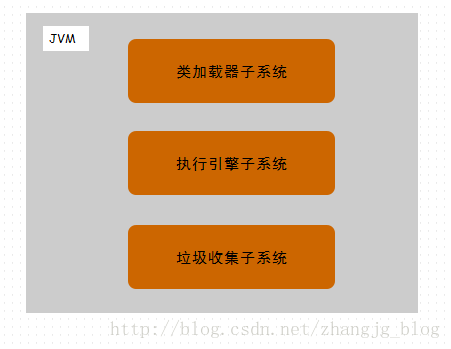
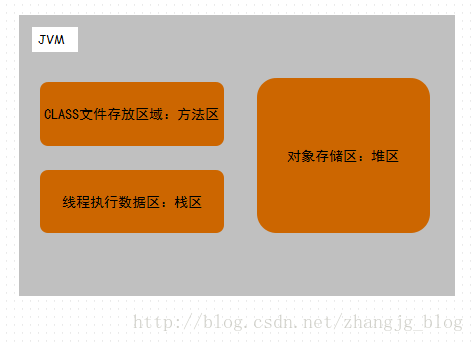
虚拟机的运行,必须加载 class 文件,并且执行 class 文件中的字节码指令。它做这么多事情,必须需要自己的空间。就像人吃下去的东西首先要放在胃中。虚拟机也需要空间来存放个中数据。首先,加载的字节码,需要一个单独的内存空间来存放;一个线程的执行,也需要内存空间来维护方法的调用关系,存放方法中的数据和中间计算结果;在执行的过程中,无法避免的要创建对象,创建的对象需要一个专门的内存空间来存放。关于虚拟机运行时数据区的内容,也会出现在本专栏后续的文章中。虚拟机的运行时内存区大概可以分成下图所示的几个部分。(这里只是大概划分, 并没有划分的很精细)
总结
写到这里,基本上关于我对 java 虚拟机的理解就写完了。这篇文章的主题虽然是深入理解 Java 虚拟机,但是你可能感觉一点也不 “深入”,也只是泛泛而谈。我也有这样的感觉。限于自己水平有限,也只能这样了,要是想深入理解 java 虚拟机,强烈建议读一下三本书:
《深入 Java 虚拟机》
《深入理解 Java 虚拟机 JVM 高级特性与最佳实践》
《Java 虚拟机规范》
其实我也读过这几本书,但是它们对虚拟机的解释也是基于一个外部模型,而没有深入剖析虚拟机内部的实现原理。虚拟机是一个大而复杂的东西,实现虚拟机的人都是大牛级别的,如果不是参与过虚拟机的实现,应该很少有人能把它参透。本专栏后面的一些文章也参考了这三本书, 虽然讲解 Java 语法的书不计其数, 但是深入讲解虚拟机的书, 目前为止我就见过这三本,并且网上的资料也不是很多。
最后做一个总结:
1 虚拟机并不神秘,在操作系统的角度看来,它只是一个普通进程。
2 这个叫做虚拟机的进程比较特殊,它能够加载我们编写的 class 文件。如果把 JVM 比作一个人,那么 class 文件就是我们吃的食物。
3 加载 class 文件的是一个叫做类加载器的子系统。就好比我们的嘴巴,把食物吃到肚子里。
4 虚拟机中的执行引擎用来执行 class 文件中的字节码指令。就好比我们的肠胃,对吃进去的食物进行消化。
5 虚拟机在执行过程中,要分配内存创建对象。当这些对象过时无用了,必须要自动清理这些无用的对象。清理对象回收内存的任务由垃圾收集器负责。就好比人吃进去的食物,在消化之后,必须把废物排出体外,腾出空间可以在下次饿的时候吃饭并消化食物。
开篇
在我的上一篇博客 深入理解 Java 中为什么内部类可以访问外部类的成员 中, 通过使用 javap 工具反编译内部类的字节码, 我们知道了为什么内部类中可以访问外部类的成员, 其实是编译器在编译内部类的 class 文件时,偷偷做了一些工作, 使内部类持有外部类的引用, 并且通过在构造方法上添加参数注入这个引用, 在调用构造方法时默认传入了外部类的引用。 我们之所以感到疑惑, 就是因为编译器使用的障眼法。当我们把字节码反编译出来之后, 编译器的这些小伎俩就会清清楚楚的展示在我们面前。 感兴趣的朋友可以移步到上一篇博客, 博客链接: http://blog.csdn.net/zhangjg_blog/article/details/20000769
在本文中, 我们要对定义在方法中的内部类进行分析。 和上一篇博客一样, 我们还是使用 javap 工具对内部类的字节码进行解剖。 并且和上一篇文章进行对比分析, 探究定义在外部类方法中的内部类和定义在外部类中的内部类有哪些相同之处和不同之处。 这篇博客的讲解以上一篇为基础, 对这些知识点不是很熟悉的同学, 强烈建议先读上一篇博客。 博客的链接已经在上面给出。
定义在方法中的内部类
在平时写代码的过程中, 我们经常会写类似下面的代码段:
-
public class Test {
-
-
public static void main(String[] args) {
-
final int count = 0;
-
-
new Thread(){
-
public void run() {
-
int var = count;
-
};
-
}.start();
-
}
-
}
这段代码在 main 方法中定义了一个匿名内部类, 并且创建了匿名内部类的一个对象, 使用这个对象调用了匿名内部类中的方法。 所有这些操作都在 new Thread (){}.start () 这一句代码中完成, 这不禁让人感叹 java 的表达能力还是很强的。 上面的代码和以下代码等价:
-
public class Test {
-
-
public static void main(String[] args) {
-
final int count = 0;
-
-
//在方法中定义一个内部类
-
class MyThread extends Thread{
-
public void run() {
-
int var = count;
-
}
-
}
-
-
new MyThread().start();
-
}
-
}
这里我们不关心方法中匿名内部类和非匿名内部类的区别, 我们只需要知道, 这两种方式都是定义在方法中的内部类, 他们的工作原理是相同的。 在本文中主要根据非匿名内部类讲解。
让我们仔细观察上面的代码都有哪些 “奇怪” 的行为:
1 在外部类的 main 方法中有一个局部变量 count, 并且在内部类的 run 方法中访问了这个 count 变量。 也就是说, 方法中定义的内部类, 可以访问方法中的局部变量(方法的参数也是局部变量);
2 count 变量使用 final 关键字修饰, 如果去掉 final, 则编译失败。 也就是说被方法中的内部类访问的局部变量必须是 final 的。
由于我们经常这样做, 这样写代码, 久而久之养成了习惯, 就成了司空见惯的做法了。 但是如果要问为什么 Java 支持这样的做法, 恐怕很少有人能说的出来。 在下面, 我们就会分析为什么 Java 支持这种做法, 让我们不仅知其然, 还要知其所以然。
为什么定义在方法中的内部类可以访问方法中的局部变量?
1 当被访问的局部变量是编译时可确定的字面常量时
-
public class Outer {
-
-
void outerMethod(){
-
final String localVar = "abc";
-
-
/*定义在方法中的内部类*/
-
class Inner{
-
void innerMethod(){
-
String a = localVar;
-
}
-
}
-
}
-
}
在外部类的方法 outerMethod 中定义了成员变量 String localVar, 并且用一个编译时字面量 "abc" 给他赋值。在 outerMethod 方法中定义了内部类 Inner, 并且在内部类的方法 innerMethod 中访问了 localVar 变量。 接下来我们就根据这个例子来讲解为什么可以这样做。
Constant pool:
#1 = Class #2 // Outer$1Inner
#2 = Utf8 Outer$1Inner
#3 = Class #4 // java/lang/Object
#4 = Utf8 java/lang/Object
#5 = Utf8 this$0
#6 = Utf8 LOuter;
#7 = Utf8 <init>
#8 = Utf8 (LOuter;)V
#9 = Utf8 Code
#10 = Fieldref #1.#11 // Outer$1Inner.this$0:LOuter;
#11 = NameAndType #5:#6 // this$0:LOuter;
#12 = Methodref #3.#13 // java/lang/Object."<init>":()V
#13 = NameAndType #7:#14 // "<init>":()V
#14 = Utf8 ()V
#15 = Utf8 LineNumberTable
#16 = Utf8 LocalVariableTable
#17 = Utf8 this
#18 = Utf8 LOuter$1Inner;
#19 = Utf8 innerMethod
#20 = String #21 // abc
#21 = Utf8 abc
#22 = Utf8 a
#23 = Utf8 Ljava/lang/String;
#24 = Utf8 SourceFile
#25 = Utf8 Outer.java
#26 = Utf8 EnclosingMethod
#27 = Class #28 // Outer
#28 = Utf8 Outer
#29 = NameAndType #30:#14 // outerMethod:()V
#30 = Utf8 outerMethod
#31 = Utf8 InnerClasses
#32 = Utf8 Inner
{
final Outer this$0;
flags: ACC_FINAL, ACC_SYNTHETIC
Outer$1Inner(Outer);
flags:
Code:
stack=2, locals=2, args_size=2
0: aload_0
1: aload_1
2: putfield #10 // Field this$0:LOuter;
5: aload_0
6: invokespecial #12 // Method java/lang/Object."<init>":()V
9: return
LineNumberTable:
line 8: 0
LocalVariableTable:
Start Length Slot Name Signature
0 10 0 this LOuter$1Inner;
void innerMethod();
flags:
Code:
stack=1, locals=2, args_size=1
0: ldc #20 // String abc
2: astore_1
3: return
LineNumberTable:
line 10: 0
line 11: 3
LocalVariableTable:
Start Length Slot Name Signature
0 4 0 this LOuter$1Inner;
3 1 1 a Ljava/lang/String;
}innerMethod 方法中一共就以下有三个指令:
2: astore_1
3: return

......
......
#13 = Utf8 LOuter;
#14 = Utf8 outerMethod
#15 = String #16 // abc
#16 = Utf8 abc
......
......我们可以看到, “abc” 这个字符串确实出现在 Outer.class 常量池的第 15 项。 这就奇怪了, 明明是定义在外部类的字面量, 为什么会出现在 内部类的常量池中呢? 其实这正是编译器在编译方法中定义的内部类时, 所做的额外工作。
-
public class Outer {
-
-
void outerMethod(){
-
final int localVar = 1;
-
-
/*定义在方法中的内部类*/
-
class Inner{
-
void innerMethod(){
-
int a = localVar;
-
}
-
}
-
}
-
}
内部类反编译后的 class 文件如下: (由于在这里常量池不是重点, 所以省略了常量池信息)
-
{
-
final Outer this$0;
-
flags: ACC_FINAL, ACC_SYNTHETIC
-
-
Outer$1Inner(Outer);
-
flags:
-
Code:
-
stack=2, locals=2, args_size=2
-
0: aload_0
-
1: aload_1
-
2: putfield #10 // Field this$0:LOuter;
-
5: aload_0
-
6: invokespecial #12 // Method java/lang/Object."<init>":()V
-
9: return
-
LineNumberTable:
-
line 8: 0
-
LocalVariableTable:
-
Start Length Slot Name Signature
-
0 10 0 this LOuter$1Inner;
-
-
void innerMethod();
-
flags:
-
Code:
-
stack=1, locals=2, args_size=1
-
0: iconst_1
-
1: istore_1
-
2: return
-
LineNumberTable:
-
line 10: 0
-
line 11: 2
-
LocalVariableTable:
-
Start Length Slot Name Signature
-
0 3 0 this LOuter$1Inner;
-
2 1 1 a I
-
}
从上面的输出可以看到, innerMethod 方法中的第一句字节码为:
iconst_1这句字节码的意义是:将 int 类型的常量 1 压入操作数栈。 这就是在内部类中访问外部类方法中的局部变量 int localVar = 1 的原理。 由此可见, 当内部类中访问的局部变量是 int 型的字面量时, 编译器直接将对该变量的访问嵌入到内部类的字节码中, 也就是说, 在运行时, 方法中的内部类和外部类, 和外部类方法中的局部变量就没有任何关系了。 这也是编译器所做的额外工作。
final String localVar = "abc";final int localVar = 1;他们之所以被称为字面常量, 是因为他们被 final 修饰, 运行时不可改变, 当编译器在编译源文件时, 可以确定他们的值, 也可以确定他们在运行时不会被修改, 所以可以实现类似 C 语言宏替换的功能。也就是说虽然在编写源代码时, 在另一个类中访问的是当前类定义的这个变量, 但是在编译成字节码时, 却把这个变量的值放入了访问这个变量的另一个类的常量池中, 或直接将这个变量的值嵌入另一个类的字节码指令中。 运行时这两个类各不相干, 各自访问各自的常量池, 各自执行各自的字节码指令。在编译方法中定义的内部类时, 编译器的行为就是这样的。
-
public class Outer {
-
-
void outerMethod(){
-
final String localVar = getString();
-
-
/*定义在方法中的内部类*/
-
class Inner{
-
void innerMethod(){
-
String a = localVar;
-
}
-
}
-
-
new Inner();
-
}
-
-
String getString(){
-
return "aa";
-
}
-
}
由于使用 getString 方法的返回值为 localVar 赋值, 所以在编译时期, 编译器不可确定 localVar 的值, 必须在运行时执行了 getString 方法之后才能确定它的值。 既然编译时不不可确定, 那么像上面那样的处理就行不通了。 那么在这种情况下, 内部类是通过什么机制访问方法中的局部变量的呢? 让我们继续反编译内部类的字节码:
Constant pool:
#1 = Class #2 // Outer$1Inner
#2 = Utf8 Outer$1Inner
#3 = Class #4 // java/lang/Object
#4 = Utf8 java/lang/Object
#5 = Utf8 this$0
#6 = Utf8 LOuter;
#7 = Utf8 val$localVar
#8 = Utf8 Ljava/lang/String;
#9 = Utf8 <init>
#10 = Utf8 (LOuter;Ljava/lang/String;)V
#11 = Utf8 Code
#12 = Fieldref #1.#13 // Outer$1Inner.this$0:LOuter;
#13 = NameAndType #5:#6 // this$0:LOuter;
#14 = Fieldref #1.#15 // Outer$1Inner.val$localVar:Ljava/la
ng/String;
#15 = NameAndType #7:#8 // val$localVar:Ljava/lang/String;
#16 = Methodref #3.#17 // java/lang/Object."<init>":()V
#17 = NameAndType #9:#18 // "<init>":()V
#18 = Utf8 ()V
#19 = Utf8 LineNumberTable
#20 = Utf8 LocalVariableTable
#21 = Utf8 this
#22 = Utf8 LOuter$1Inner;
#23 = Utf8 innerMethod
#24 = Utf8 a
#25 = Utf8 SourceFile
#26 = Utf8 Outer.java
#27 = Utf8 EnclosingMethod
#28 = Class #29 // Outer
#29 = Utf8 Outer
#30 = NameAndType #31:#18 // outerMethod:()V
#31 = Utf8 outerMethod
#32 = Utf8 InnerClasses
#33 = Utf8 Inner
{
final Outer this$0;
flags: ACC_FINAL, ACC_SYNTHETIC
Outer$1Inner(Outer, java.lang.String);
flags:
Code:
stack=2, locals=3, args_size=3
0: aload_0
1: aload_1
2: putfield #12 // Field this$0:LOuter;
5: aload_0
6: aload_2
7: putfield #14 // Field val$localVar:Ljava/lang/String;
10: aload_0
11: invokespecial #16 // Method java/lang/Object."<init>":()V
14: return
LineNumberTable:
line 8: 0
LocalVariableTable:
Start Length Slot Name Signature
0 15 0 this LOuter$1Inner;
void innerMethod();
flags:
Code:
stack=1, locals=2, args_size=1
0: aload_0
1: getfield #14 // Field val$localVar:Ljava/lang/String;
4: astore_1
5: return
LineNumberTable:
line 10: 0
line 11: 5
LocalVariableTable:
Start Length Slot Name Signature
0 6 0 this LOuter$1Inner;
5 1 1 a Ljava/lang/String;
}首先来看它的构造方法。 方法的签名为:
Outer$1Inner(Outer, java.lang.String);我们只到, 如果不定义构造方法, 那么编译器会为这个类自动生成一个无参数的构造方法。 这个说法在这里就行不通了, 因为我们看到, 这个内部类的构造方法又两个参数。 至于第一个参数, 是指向外部类对象的引用, 在前面一篇博客中已经详细的介绍过了, 不明白的可以先看上一篇博客, 这里就不再重复叙述。 这也说明了方法中的内部类和类中定义的内部类有相同的地方, 既然他们都是内部类, 就都持有指向外部类对象的引用。 我们来分析第二个参数, 他是 String 类型的, 和在内部类中访问的局部变量 localVar 的类型相同。 再看构造方法中编号为 6 和 7 的字节码指令:
6: aload_2
7: putfield #14 // Field val$localVar:Ljava/lang/String; 0: aload_0
1: getfield #14 // Field val$localVar:Ljava/lang/String;这两条指令的意思是, 访问成员变量 val$localVar 的值。 而源代码中是访问外部类方法中局部变量的值。 所以, 在这里 将编译时对外部类方法中的局部变量的访问, 转化成运行时对当前内部类对象中成员变量的访问。
在源代码层面上, 它的工作方式有点像这样: (注意, 下面的代码不符合 Java 的语法, 只是模拟编译器的行为)
-
public class Outer {
-
-
void outerMethod(){
-
final String localVar = getString();
-
-
/*定义在方法中的内部类*/
-
class Inner{
-
/*下面两个成员变量都是编译器自动加上的*/
-
final Outer this$0; //指向外部类对象的引用
-
final String val$localVar; //被访问的外部类方法中的局部变量的值
-
-
/*构造方法, 两个参数都是编译器添加的*/
-
public Inner(Outer outer, String outerMethodLocal){
-
this.this$0 = outer;
-
this.val$localVar = outerMethodLocal;
-
super();
-
}
-
-
void innerMethod(){
-
-
/*将对外部类方法中的变量的访问, 转换成对当前对象的成员变量的访问*/
-
//String a = localVar;
-
String a = val$localVar;
-
}
-
}
-
-
/*在外部类方法中创建内部类对象时, 传入相应的参数,
-
这两个参数分别是当前外部类的引用, 和当前方法中的局部变量*/
-
//new Inner();
-
new Inner(this, localVar);
-
-
}
-
-
String getString(){
-
return "aa";
-
}
-
}
讲到这里, 内部类的行为就比较清晰了。 总结一下就是: 当方法中定义的内部类访问的方法局部变量的值, 不是在编译时能确定的字面常量时, 编译器会为内部类增加一个成员变量, 在运行时, 将对外部类方法中局部变量的访问。 转换成对这个内部类成员变量的方法。 这就要求内部类中的这个新增的成员变量和外部类方法中的局部变量具有相同的值。 编译器通过为内部类的构造方法增加参数, 并在调用构造器初始化内部类对象时传入这个参数, 来初始化内部类中的这个成员变量的值。 所以, 虽然在源文件中看起来是访问的外部类方法的局部变量, 其实运行时访问的是内部类对象自己的成员变量。
为什么被方法内的内部类访问的局部变量必须是 final 的
-
public class Outer {
-
-
void outerMethod(){
-
final int localVar = getInt();
-
-
/*定义在方法中的内部类*/
-
class Inner{
-
void innerMethod(){
-
int a = localVar;
-
}
-
}
-
-
new Inner();
-
}
-
-
int getInt(){ return 1; }
-
}

如果这个局部变量是引用数据类型时, 拷贝外部类方法中的引用值给内部类对象的成员变量, 这样的话, 他们就指向了同一个对象。 代码示例和运行时的内存布局如下:
-
public class Outer {
-
-
void outerMethod(){
-
final Person localVar = getPerson();
-
-
/*定义在方法中的内部类*/
-
class Inner{
-
void innerMethod(){
-
Person a = localVar;
-
}
-
}
-
-
new Inner();
-
}
-
-
Person getPerson(){ return new Person("zhangjg", 30); }
-
}
深入理解为什么 Java 中方法内定义的内部类可以访问方法中的局部变量_int local var-CSDN 博客
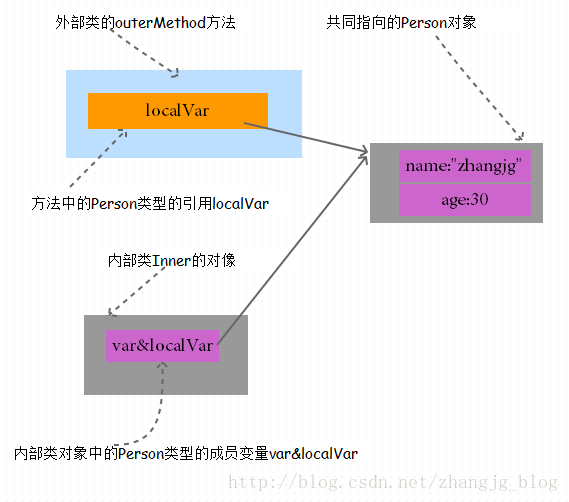
由于这两个引用变量指向同一个对象, 所以通过引用访问的对象的数据是一样的, 由于他们都不能再指向其他对象(被 final 修饰), 所以可以保证内部类和外部类数据访问的一致性。
内部类简介
虽然 Java 是一门相对比较简单的编程语言,但是对于初学者, 还是有很多东西感觉云里雾里, 理解的不是很清晰。内部类就是一个经常让初学者感到迷惑的特性。 即使现在我自认为 Java 学的不错了, 但是依然不是很清楚。其中一个疑惑就是为什么内部类对象可以访问外部类对象中的成员(包括成员变量和成员方法)? 早就想对内部类这个特性一探究竟了,今天终于抽出时间把它研究了一下。
内部类就是定义在一个类内部的类。定义在类内部的类有两种情况:一种是被 static 关键字修饰的, 叫做静态内部类, 另一种是不被 static 关键字修饰的, 就是普通内部类。 在下文中所提到的内部类都是指这种不被 static 关键字修饰的普通内部类。 静态内部类虽然也定义在外部类的里面, 但是它只是在形式上(写法上)和外部类有关系, 其实在逻辑上和外部类并没有直接的关系。而一般的内部类,不仅在形式上和外部类有关系(写在外部类的里面), 在逻辑上也和外部类有联系。 这种逻辑上的关系可以总结为以下两点:
1 内部类对象的创建依赖于外部类对象;
2 内部类对象持有指向外部类对象的引用。
上边的第二条可以解释为什么在内部类中可以访问外部类的成员。就是因为内部类对象持有外部类对象的引用。但是我们不禁要问, 为什么会持有这个引用? 接着向下看, 答案在后面。
通过反编译字节码获得答案
-
public class Outer {
-
int outerField = 0;
-
-
class Inner{
-
void InnerMethod(){
-
int i = outerField;
-
}
-
}
-
}
该文件很简单, 就不用过多介绍了。 在外部类 Outer 中定义了内部类 Inner, 并且在 Inner 的方法中访问了 Outer 的成员变量 outerField。
javap -classpath . -v Outer$Inner-classpath . 说明在当前目录下寻找要反编译的 class 文件
javap -classpath . -v com.baidu.Outer$Inner{
final Outer this$0;
flags: ACC_FINAL, ACC_SYNTHETIC
Outer$Inner(Outer);
flags:
Code:
stack=2, locals=2, args_size=2
0: aload_0
1: aload_1
2: putfield #10 // Field this$0:LOuter;
5: aload_0
6: invokespecial #12 // Method java/lang/Object."<init>":()V
9: return
LineNumberTable:
line 5: 0
LocalVariableTable:
Start Length Slot Name Signature
0 10 0 this LOuter$Inner;
void InnerMethod();
flags:
Code:
stack=1, locals=2, args_size=1
0: aload_0
1: getfield #10 // Field this$0:LOuter;
4: getfield #20 // Field Outer.outerField:I
7: istore_1
8: return
LineNumberTable:
line 7: 0
line 8: 8
LocalVariableTable:
Start Length Slot Name Signature
0 9 0 this LOuter$Inner;
8 1 1 i I
}final Outer this$0; Outer$Inner(Outer);
flags:
Code:
stack=2, locals=2, args_size=2
0: aload_0
1: aload_1
2: putfield #10 // Field this$0:LOuter;
5: aload_0
6: invokespecial #12 // Method java/lang/Object."<init>":()V
9: return
LineNumberTable:
line 5: 0
LocalVariableTable:
Start Length Slot Name Signature
0 10 0 this LOuter$Inner;我们知道, 如果在一个类中, 不声明构造方法的话, 编译器会默认添加一个无参数的构造方法。 但是这句话在这里就行不通了, 因为我们明明看到, 这个构造函数有一个构造方法, 并且类型为 Outer。 所以说,编译器会为内部类的构造方法添加一个参数, 参数的类型就是外部类的类型。
-
class Outer$Inner{
-
final Outer this$0;
-
-
public Outer$Inner(Outer outer){
-
this.this$0 = outer;
-
super();
-
}
-
}

void InnerMethod();
flags:
Code:
stack=1, locals=2, args_size=1
0: aload_0
1: getfield #10 // Field this$0:LOuter;
4: getfield #20 // Field Outer.outerField:I
7: istore_1
8: returngetfield #10 // Field this$0:LOuter;
总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号