数据仓库分层之ODS、CDM、ADS、DWD、DWS
三层设计:(参考阿里One Data)
ODS 操作数据层
CDM:公共维度模型层 CDM划分为DWD 明细数据层 DWS汇总数据层
ADS 应用数据层
划分原则:
1,高内聚和低耦合
2,核心模型与扩展模型分离 (扩展模型定制化需求)
3,公共处理逻辑下沉及单一
4,成本与性能平衡
5,数据可回滚(多次运行)
6,一致性(上下层,相同名称含义一致)
7,命名清晰,易理解
数据仓库架构分层设计包括STG(数据缓冲层)、ODS(数据操作层)、DWD(数据明细层)、DWS(主题汇总层)和ADM(数据应用层)。
1、STG层
主要完成业务系统结构化数据引入到数据中台,保留业务系统原始数据,缓冲层设计主要保持和数据源的一致性,不做任何类型转换和数据加工处理,为ODS层提供基础数据服务。
2、ODS层
对STG层数据进行类型转换或增量合并处理,得到的全量明细数据,为DWD、DWS和ADM层提供数据服务。
3、DWD层
明细宽表层,用于存放完整详细历史数据。面向业务过程建模,紧紧围绕着业务过程来设计,通过获取描述业务过程的度量来表达业务过程,包含了引用的维度和与业务过程有关的度量。其设计目标是为后续的Data Warehouse Model提供灵活性和扩展性的基础,同时可以在DW层无法支持需求时直接为应用层提供数据。DWD层由于与业务系统耦合程度较高,其稳定性会受到业务系统的影响。
4、DWS层
存放详细历史数据的公共汇总数据层,面向分析主题建模。DWS是核心数据层,是为应用层提供足够的灵活性和扩展性的基础。
5、ADM层
提供直接面向业务或应用的数据,主要对个性化指标数据进行架构处理,如无公用性或复杂性(如指数型、比值型、排名型等指标数据)的指标数据加工。同时为方便实现数据应用、数据消费的诉求,进行面向应用逻辑的数据组装(如打宽表集市、横表转纵表、趋势指标串等)。
数据分层是数仓模型设计中十分重要的环节,优秀的分层设计能够让整个数据体系更易理解和使用。
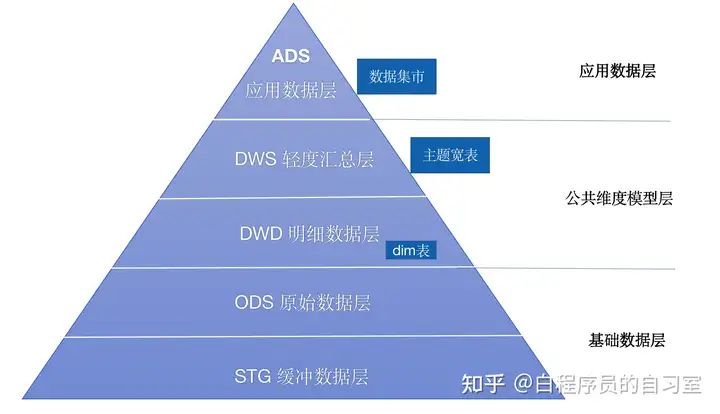
数仓分层意义
数仓分层目的是使用空间换时间,通过大量预处理,提升用户数据加工效率等,故而存在大量数据冗余。如果不分层,源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。
通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
综上所述数据分层将可以给我们带来如下的好处: 1、清晰数据结构:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解 2、减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算 3、统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径 4、复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题
通用可行的数仓分层设计方案
为了满足前面提到数据分层带来的好处,建议将数据模型分为三层:基础数据层( ODS、STG )、公共维度模型层(CDM或EDW)和数据应用层(ADS)。如下图所示。简单来讲,我们可以理解为:基础数据层存放的是接入的原始数据,DW层是存放我们要重点设计的数据仓库中间层数据,数据应用层是面向业务定制的应用数据。
基础数据层
包含 STG(数据缓冲层)与 ODS(原始数据层)两层,这两层数据结构与业务数据几乎一致。
STG 数据准备区或数据缓冲区
定位是缓存来自 DB 抽取、消息、日志解析落地的临时数据,结构与业务系统保持一致;负责对垃圾数据、不规范数据进行清洗转换;该层除为ODS 层服务外,不提供服务,也就是不能被其他更上层次调用。
ODS原始数据层或操作数据层
操作数据层定位于业务明细数据保留区,负责保留数据接入时点后历史变更数据,数据原则上全量保留。可以在此层对增量数据或者拉链表数据进行合并。
公共维度模型层CDM(Common Data Model)或者 企业级数据仓库EDW (Enterprise Data Warehouse)
公共维度模型层主要用于存放明细事实数据、维表数据及公共指标汇总数据,其中明细事实数据、维表数据一般根据ODS层数据加工生成;公共指标汇总数据一般根据维表数据和明细事实数据加工生成。本层采用维度模型作为建模方法的理论基础,更多的是通过采用一些维度退化手段,将维度退化至事实表中,减少维表和事实表的关联,提高数据易用性。
明细数据层:DWD(Data Warehouse Detail)
该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。同时在此层会采用明细宽表,复用关联计算,极少数据扫描。举例:订单主表以及订单明细表,可以以订单明细表作为最小粒度,连表整合订单表数据,生成dwd层订单事实表。
数据汇总层:DWS(Data WareHouse Summary)
该层会在DWD层的数据基础上,对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。
公共维度模型层CDM主要作用
1、组合相关和相识数据,采用明细宽表,复用关联计算,减少数据扫描 2、公共指标统一加工,为上层数据产品应用,服务提供公共指标,建立逻辑汇总宽表 3、建立一致性维度,一致性的数据分析维度,降低数据计算口径,解决算法不同意的风险
应⽤层 ADS(Application Data Mart-应⽤数据集市)
数据应用层,也叫DM(数据集市)或APP层等,面试实际的数据需求,可以直接给业务人员使用,以DWD或者DWS层的数据为基础,组成各种统计报表。除此之外还有一些直接的表现形式,例如主题大宽度表集市,以及横表转纵表等。
宽表
宽表这块我的理解是,基于维度模型的扩展,采用退化维度的方式,将不同维度的度量放入数据表的不同列中,同时将于主分析维度相关的指标进行整合,更利于理解,以及较好的查询性能。
宽表物理设计结构: 1、基本属性 2、日行为汇总指标 3、周期行为汇总指标 4、历史累计属性和指标
思考和总结一下
从数据应用理解上来讲,目的是希望越上层次,对使用者约友好。比如ADS层,基本是完全为应用来设计的,很易懂,DWS层的话,相对来讲就会有一点点理解成本,然后DWD层就比较难理解了,因为它的维度可能会比较多,而且一个需求可能要多张表经过很复杂的计算才能完成。
从能力范围来讲,我们希望80%需求由20%的表来支持。直接点讲,就是大部分(80%以上)的需求,都用DWS的表来支持就行,DWS支持不了的,就用DWD的表来支持,这些都支持不了的极少一部分数据需要从原始日志中后去。
详解数仓中的数据分层:ODS、DWD、DWM、DWS、ADS - 简书

何为数仓DW
Data warehouse(可简写为DW或者DWH)数据仓库,是在数据库已经大量存在的情况下,它是一整套包括了etl、调度、建模在内的完整的理论体系。
数据仓库的方案建设的目的,是为前端查询和分析作为基础,主要应用于OLAP(on-line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。目前行业比较流行的有:AWS Redshift,Greenplum,Hive等。
数据仓库并不是数据的最终目的地,而是为数据最终的目的地做好准备,这些准备包含:清洗、转义、分类、重组、合并、拆分、统计等
为何要分层
数据仓库中涉及到的问题:
- 为什么要做数据仓库?
- 为什么要做数据质量管理?
- 为什么要做元数据管理?
- 数仓分层中每个层的作用是什么?
- …...
在实际的工作中,我们都希望自己的数据能够有顺序地流转,设计者和使用者能够清晰地知道数据的整个声明周期,比如下面左图。
但是,实际情况下,我们所面临的数据状况很有可能是复杂性高、且层级混乱的,我们可能会做出一套表依赖结构混乱,且出现循环依赖的数据体系,比如下面的右图。
为了解决我们可能面临的问题,需要一套行之有效的数据组织、管理和处理方法,来让我们的数据体系更加有序,这就是数据分层。数据分层的好处:
- 清晰数据结构:让每个数据层都有自己的作用和职责,在使用和维护的时候能够更方便和理解
- 复杂问题简化:将一个复杂的任务拆解成多个步骤来分步骤完成,每个层只解决特定的问题
- 统一数据口径:通过数据分层,提供统一的数据出口,统一输出口径
- 减少重复开发:规范数据分层,开发通用的中间层,可以极大地减少重复计算的工作
数据分层
每个公司的业务都可以根据自己的业务需求分层不同的层次;目前比较流行的数据分层:数据运营层、数据仓库层、数据服务层。
数据运营层ODS
数据运营层:Operation Data Store 数据准备区,也称为贴源层。数据源中的数据,经过抽取、洗净、传输,也就是ETL过程之后进入本层。该层的主要功能:
- ODS是后面数据仓库层的准备区
- 为DWD层提供原始数据
- 减少对业务系统的影响
为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可
这层的数据是后续数据仓库加工数据的来源。数据来源的方式:
- 业务库:sqoop定时抽取数据;实时方面考虑使用canal监听mysql的binlog日志,实时接入即可
- 埋点日志:日志一般是以文件的形式保存,可以选择使用flume来定时同步;可以使用spark streaming或者Flink、Kafka来实时接入
- 消息队列:来自ActiveMQ、Kafka的数据等
数据仓库层
数据仓库层从上到下,又可以分为3个层:数据细节层DWD、数据中间层DWM、数据服务层DWS。
数据细节层DWD
数据细节层:data warehouse details,DWD
该层是业务层和数据仓库的隔离层,保持和ODS层一样的数据颗粒度;主要是对ODS数据层做一些数据的清洗和规范化的操作,比如去除空数据、脏数据、离群值等。
为了提高数据明细层的易用性,该层通常会才采用一些维度退化方法,将维度退化至事实表中,减少事实表和维表的关联。
数据中间层DWM
数据中间层:Data Warehouse Middle,DWM;
该层是在DWD层的数据基础上,对数据做一些轻微的聚合操作,生成一些列的中间结果表,提升公共指标的复用性,减少重复加工的工作。
简答来说,对通用的核心维度进行聚合操作,算出相应的统计指标
数据服务层DWS
数据服务层:Data Warehouse Service,DWS;
该层是基于DWM上的基础数据,整合汇总成分析某一个主题域的数据服务层,一般是宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
一般来说,该层的数据表会相对较少;一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
数据应用层ADS
数据应用层:Application Data Service,ADS;
该层主要是提供给数据产品和数据分析使用的数据,一般会存放在ES、Redis、PostgreSql等系统中供线上系统使用;也可能存放在hive或者Druid中,供数据分析和数据挖掘使用,比如常用的数据报表就是存在这里的。
事实表 Fact Table
事实表是指存储有事实记录的表,比如系统日志、销售记录等。事实表的记录在不断地增长,比如电商的商品订单表,就是类似的情况,所以事实表的体积通常是远大于其他表。
维表层Dimension
维度表(Dimension Table)或维表,有时也称查找表(Lookup Table),是与事实表相对应的一种表;它保存了维度的属性值,可以跟事实表做关联,相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进行管理。维度表主要是包含两个部分:
-
高基数维度数据:一般是用户资料表、商品资料表类似的资料表,数据量可能是千万级或者上亿级别
-
低基数维度数据:一般是配置表,比如枚举字段对应的中文含义,或者日期维表等;数据量可能就是个位数或者几千几万。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号