skywalking源码解析
在2020年3月份开始接触skywalking到现在,使用skywalking已经一年时间,期间对内部代码进行了详细阅读,并且由于项目需要,我们已经对源码进行了二开,新增了各种个性化需求,可以说,我们对skywalking底层源码了解程度已经相对较高。
本来想通过笔记对这一年来的源码阅读及理解成果进行记录,无意中发现这篇文章写得相当的好,也懒得去写了,因此直接转载,后续该系列文章会夹杂着转载与原创,欢迎各位码友交流探讨
1 . 简介
本文涉及到的源码取自版本 : apache-skywalking-apm-7.0.0 ,不同版本实现差异可能会有一些区别,但是大体框架上没有变化的 , 一些地方为了方便理解,我拆分了 lamda 表达式,或者把一些写在一起的代码给做了拆分,但是整体逻辑是不变的
2. javaAgent
skywalking 是一个 分布式追踪系统 , 他可以帮助我们看到一个请求经过了多少个微服务,中途调用了多少数据库,redis,mq 等中间件, 要实现这样的功能,其实很简单只要在设计系统的时候, 每经过一次请求,每调用一次中间件,都把对应的日志给存起来, 然后提供一个 ui 服务,也同样能实现对应的功能. 但是如果这样做的话, 对代码就有很强的侵入性 , 每一个业务系统都需要修改,在业务代码里去加上对应的日志,对于喜欢偷懒的程序员来说,这是非常不舒服的.
所以 skywalking 使用 agent 的形式去接入 业务系统,这样就不需要在业务系统里添加任何的日志代码,也能记录到对应的调用数据库
那么agent 到底是什么嗯? 这里提一点, idea的破解插件, spring boot热更新插件, jacoco 都是基于 javaAgent 实现的
在JDK1.5以后,我们可以使用agent技术构建一个独立于应用程序的代理程序(即为Agent),用来协助监测、运行甚至替换其他JVM上的程序。使用它可以实现虚拟机级别的AOP功能。
划重点: 虚拟机级别的aop
这样的话,就能在 JVM加载class二进制文件的时候, 修改对应 业务系统的 class文件,动态在class文件里加上记录日志的代码.
小朋友你是否有很多问号,要如何去修改字节码嗯?
如果直接去修改字节码,是非常非常麻烦的,所以这里引入了一个字节码修改框架byte-buddy
应为篇幅的关系,这里就不去赘述了,不了解的同学可以去看看
3. SkyWalkingAgent
如上面所说, 如果下面的内容想看着流畅,那么需要先去了解 javaAgent , ByteBuddy 以及 真正去使用过skywalking
看源码找一个入口很重要
加载命令为 -javaagent:/对应路径/skywalking-agent.jar,及把包 skywalking-agent.jar 当做一个 agent给加载进入虚拟机,根据agent 对应的规则,我们用 解压工具 打开 skywalking-agent.jar ,找到对应目录
在该文件中找到了 agent 的入口类 ,关注 对应key为 Premain-Class 的这一行配置
Manifest-Version: 1.0
Implementation-Title: apm-agent
Implementation-Version: 7.0.0
Built-By: bignosecat
Specification-Vendor: The Apache Software Foundation
Can-Redefine-Classes: true
Specification-Title: apm-agent
Implementation-Vendor-Id: org.apache.skywalking
Implementation-Vendor: The Apache Software Foundation
Premain-Class: org.apache.skywalking.apm.agent.SkyWalkingAgent
Can-Retransform-Classes: true
Created-By: Apache Maven 3.6.3
Build-Jdk: 1.8.0_151
Specification-Version: 7.0
Implementation-URL: http://maven.apache.org该类中确实有一个叫做 premain的方法 作为 agent 的入口方法,那么他会在 应用系统 启动的时候,去执行 SkyWalkingAgent#premain 方法,我们来看看这个方法里他做了什么
对应代码上都有注释, 需要深入讲解的 在注释后面标明了标题序号,可以快速定位
public static void premain(String agentArgs, Instrumentation instrumentation) throws PluginException {
final PluginFinder pluginFinder;
try {
//初始化一些参数
SnifferConfigInitializer.initialize(agentArgs);
//去加载了所有的插件,具体看下面 <3.1> 的解析
List<AbstractClassEnhancePluginDefine> abstractClassEnhancePluginDefines = new PluginBootstrap().loadPlugins();
//把插件对象放入 PluginFinder 容器,在PluginFinder 里面还会给 AbstractClassEnhancePluginDefine 分类
pluginFinder = new PluginFinder(abstractClassEnhancePluginDefines);
} catch (AgentPackageNotFoundException ape) {
logger.error(ape, "Locate agent.jar failure. Shutting down.");
return;
} catch (Exception e) {
logger.error(e, "SkyWalking agent initialized failure. Shutting down.");
return;
}
//创建一个 ByteBuddy对象用于修改字节码
final ByteBuddy byteBuddy = new ByteBuddy().with(TypeValidation.of(Config.Agent.IS_OPEN_DEBUGGING_CLASS));
//去忽略一些不需要修改字节码的包
//可以理解成设置了aop的切面
AgentBuilder agentBuilder = new AgentBuilder.Default(byteBuddy).ignore(
nameStartsWith("net.bytebuddy.").or(nameStartsWith("org.slf4j."))
.or(nameStartsWith("org.groovy."))
.or(nameContains("javassist"))
.or(nameContains(".asm."))
.or(nameContains(".reflectasm."))
.or(nameStartsWith("sun.reflect"))
.or(allSkyWalkingAgentExcludeToolkit())
.or(ElementMatchers.isSynthetic()));
JDK9ModuleExporter.EdgeClasses edgeClasses = new JDK9ModuleExporter.EdgeClasses();
//加载 Bootstrap 相关的插件
try {
agentBuilder = BootstrapInstrumentBoost.inject(pluginFinder, instrumentation, agentBuilder, edgeClasses);
} catch (Exception e) {
logger.error(e, "SkyWalking agent inject bootstrap instrumentation failure. Shutting down.");
return;
}
try {
agentBuilder = JDK9ModuleExporter.openReadEdge(instrumentation, agentBuilder, edgeClasses);
} catch (Exception e) {
logger.error(e, "SkyWalking agent open read edge in JDK 9+ failure. Shutting down.");
return;
}
//从插件里找到哪一些类需要修改字节码,把匹配规则给找出来
//详情看 <3.2>
ElementMatcher<? super TypeDescription> elementMatcher = pluginFinder.buildMatch();
//字节码的修改规则
//详情看 <3.3>
Transformer transformer = new Transformer(pluginFinder);
//使用bytebuddy 去修改字节码
agentBuilder.type(elementMatcher)
.transform(new Transformer(pluginFinder))
.with(AgentBuilder.RedefinitionStrategy.RETRANSFORMATION)
.with(new Listener())
.installOn(instrumentation);
try {
ServiceManager.INSTANCE.boot();
} catch (Exception e) {
logger.error(e, "Skywalking agent boot failure.");
}
Runtime.getRuntime()
.addShutdownHook(new Thread(ServiceManager.INSTANCE::shutdown, "skywalking service shutdown thread"));
}3.1 loadPlugins
因为有不同的
web容器,中间件,记录的方式也非常的多, 所以SkyWalkingAgent引入了插件机制,比如 你只想记录 连接数据相关的记录,那么就引入jdbc的对应插件即可.
那么 SkyWalkingAgent 是如何加载插件的嗯? 入口就是
List<AbstractClassEnhancePluginDefine> abstractClassEnhancePluginDefines = new PluginBootstrap().loadPlugins()
我们进入loadPlugins() 方法看看他都做了什么
public List<AbstractClassEnhancePluginDefine> loadPlugins() throws AgentPackageNotFoundException {
AgentClassLoader.initDefaultLoader();
//生成一个插件加载器
PluginResourcesResolver resolver = new PluginResourcesResolver();
//去指定的路径下去搜索 文件 skywalking-plugin.def
//指定的路径 默认是 skywalking-agent.jar 同目录的 activations和 plugins 文件夹
List<URL> resources = resolver.getResources();
if (resources == null || resources.size() == 0) {
logger.info("no plugin files (skywalking-plugin.def) found, continue to start application.");
return new ArrayList<AbstractClassEnhancePluginDefine>();
}
//去加载了 skywalking-plugin.def ,并且解析该文件
for (URL pluginUrl : resources) {
try {
PluginCfg.INSTANCE.load(pluginUrl.openStream());
} catch (Throwable t) {
logger.error(t, "plugin file [{}] init failure.", pluginUrl);
}
}
//skywalking-plugin.def 文件里指定的插件的 类给集中保存到容器 pluginClassList里
List<PluginDefine> pluginClassList = PluginCfg.INSTANCE.getPluginClassList();
List<AbstractClassEnhancePluginDefine> plugins = new ArrayList<AbstractClassEnhancePluginDefine>();
//把上面 pluginClassList 中插件的类 全部给实例化了
for (PluginDefine pluginDefine : pluginClassList) {
try {
logger.debug("loading plugin class {}.", pluginDefine.getDefineClass());
AbstractClassEnhancePluginDefine plugin = (AbstractClassEnhancePluginDefine) Class.forName(pluginDefine.getDefineClass(), true, AgentClassLoader
.getDefault()).newInstance();
plugins.add(plugin);
} catch (Throwable t) {
logger.error(t, "load plugin [{}] failure.", pluginDefine.getDefineClass());
}
}
plugins.addAll(DynamicPluginLoader.INSTANCE.load(AgentClassLoader.getDefault()));
return plugins;
}上面代码可以看出,他会先去 加载 skywalking-plugin.def 文件,然后把skywalking-plugin.def 文件里指定的插件给实例化,然后反回出去
这里我们看看 skywalking-plugin.def 里面都是什么内容
比如: spring-mvc 的插件中 skywalking-plugin.def 的内容如下
spring-mvc-annotation-5.x=org.apache.skywalking.apm.plugin.spring.mvc.v5.define.ControllerInstrumentation
spring-mvc-annotation-5.x=org.apache.skywalking.apm.plugin.spring.mvc.v5.define.RestControllerInstrumentation
spring-mvc-annotation-5.x=org.apache.skywalking.apm.plugin.spring.mvc.v5.define.HandlerMethodInstrumentation加载到代码里如下所示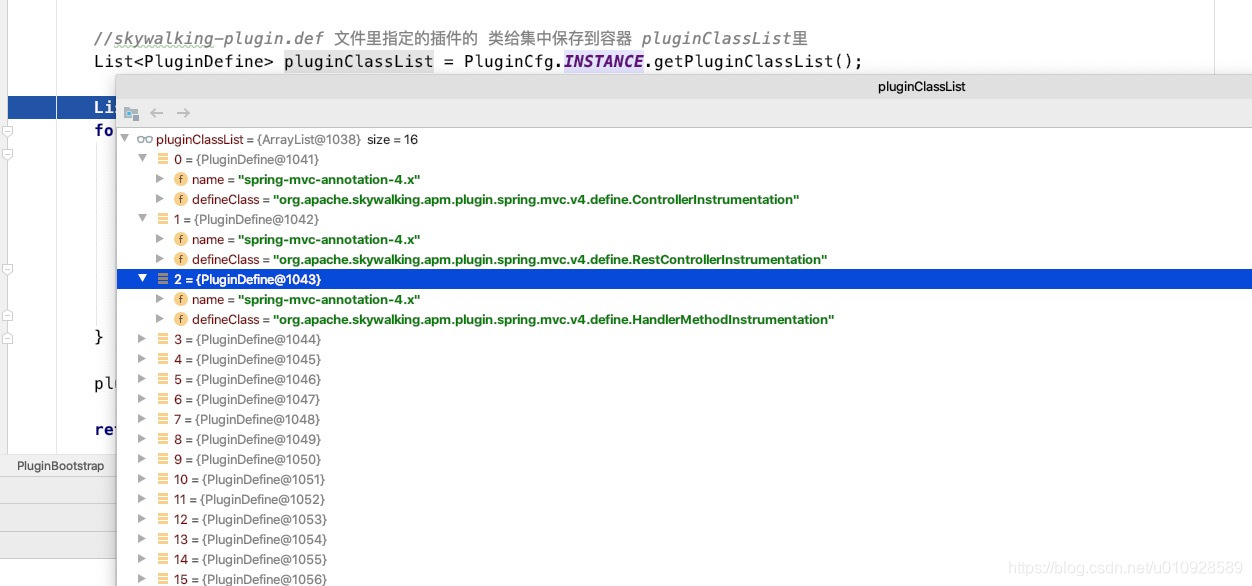
然后根据对应的类路径去实例化插件对象
最终把 容器 plugins 返回出去, loadPlugins() 方法就结束了
3.2 buildMatch
回到 premain 方法中, 并不是,所有的类都需要去修改字节码的,那么什么样的class才有资格去修改字节码,我们看方法 pluginFinder.buildMatch()
首先要先明确一点的是 pluginFinder 持有了所有插件对象的一个容器
public ElementMatcher<? super TypeDescription> buildMatch() {
//建立匹配规则,在内部类中添加第一个规则,对比对应设置的名字是否相同
ElementMatcher.Junction judge = new AbstractJunction<NamedElement>() {
@Override
public boolean matches(NamedElement target) {
return nameMatchDefine.containsKey(target.getActualName());
}
};
//排除所有的接口
judge = judge.and(not(isInterface()));
//有一些插件会设置一些特殊的规则,比如带有某个注解的类什么的
for (AbstractClassEnhancePluginDefine define : signatureMatchDefine) {
//去获取插件自定义的特殊匹配规则
ClassMatch match = define.enhanceClass();
if (match instanceof IndirectMatch) {
judge = judge.or(((IndirectMatch) match).buildJunction());
}
}
return new ProtectiveShieldMatcher(judge);
}上述我们可以看到, 对于有的插件, 他会调用 define.enhanceClass() 方法去获取匹配规则,
这里 我们可以随意打开一个 插件类 AbstractControllerInstrumentation,可以发现里面重写了方法 enhanceClass
@Override
protected ClassMatch enhanceClass() {
return ClassAnnotationMatch.byClassAnnotationMatch(getEnhanceAnnotations());
}
protected abstract String[] getEnhanceAnnotations();篇幅关系,就不进去深究 byClassAnnotationMatch 的实现了,从名字可以看出,这是根据注解去匹配,而getEnhanceAnnotations 是一个抽象方法,他需要 插件开发者 去重写这个方法,
这里我们可以看到
ControllerInstrumentation 是 AbstractControllerInstrumentation 的子类之一,
public class ControllerInstrumentation extends AbstractControllerInstrumentation {
public static final String ENHANCE_ANNOTATION = "org.springframework.stereotype.Controller";
@Override
protected String[] getEnhanceAnnotations() {
return new String[] {ENHANCE_ANNOTATION};
}
}及插件 ControllerInstrumentation 将会把所有打了注解 @Controller 的类修改字节码
3.3 Transformer
skywalking-agent.jar 到底对字节码做了什么,所有的答案就在 Transformer 中
被上述 3.2 buildMatch 命中的类都会执行一次 Transformer#transform 方法来修改class文件的内容
@Override
public DynamicType.Builder<?> transform(final DynamicType.Builder<?> builder,
final TypeDescription typeDescription,
final ClassLoader classLoader,
final JavaModule module) {
//这里 typeDescription 是要被修改class的类
//找到哪几个插件需要去修改对应的class
List<AbstractClassEnhancePluginDefine> pluginDefines = pluginFinder.find(typeDescription);
if (pluginDefines.size() > 0) {
DynamicType.Builder<?> newBuilder = builder;
//这个EnhanceContext 只是为了保证流程的一个记录器,比如执行了某个步骤后就会记录一下,防止重复操作
EnhanceContext context = new EnhanceContext();
for (AbstractClassEnhancePluginDefine define : pluginDefines) {
//真正去修改字节码的逻辑
DynamicType.Builder<?> possibleNewBuilder = define.define(
typeDescription, newBuilder, classLoader, context);
if (possibleNewBuilder != null) {
newBuilder = possibleNewBuilder;
}
}
if (context.isEnhanced()) {
logger.debug("Finish the prepare stage for {}.", typeDescription.getName());
}
//返回修改后的字节码,做替换
return newBuilder;
}
logger.debug("Matched class {}, but ignore by finding mechanism.", typeDescription.getTypeName());
return builder;
}
}
重点在于 DynamicType.Builder<?> possibleNewBuilder = define.define(ypeDescription, newBuilder, classLoader, context); .进入方法 define 中
public DynamicType.Builder<?> define(TypeDescription typeDescription, DynamicType.Builder<?> builder,
ClassLoader classLoader, EnhanceContext context) throws PluginException {
//拿到插件的全路径
String interceptorDefineClassName = this.getClass().getName();
//拿到目标类的全路径
String transformClassName = typeDescription.getTypeName();
if (StringUtil.isEmpty(transformClassName)) {
logger.warn("classname of being intercepted is not defined by {}.", interceptorDefineClassName);
return null;
}
logger.debug("prepare to enhance class {} by {}.", transformClassName, interceptorDefineClassName);
//一些插件需要依赖一些外部的类,他会找是否有对应依赖的类,如果没有就直接 return null,不再去修改字节码了
String[] witnessClasses = witnessClasses();
if (witnessClasses != null) {
for (String witnessClass : witnessClasses) {
if (!WitnessClassFinder.INSTANCE.exist(witnessClass, classLoader)) {
logger.warn("enhance class {} by plugin {} is not working. Because witness class {} is not existed.", transformClassName, interceptorDefineClassName, witnessClass);
return null;
}
}
}
//去修改原来的class,在对应的方法上添加一个拦截器
DynamicType.Builder<?> newClassBuilder = this.enhance(typeDescription, builder, classLoader, context);
context.initializationStageCompleted();
logger.debug("enhance class {} by {} completely.", transformClassName, interceptorDefineClassName);
return newClassBuilder;
}代码都很简单,接着进入 this.enhance(typeDescription, builder, classLoader, context) 去正真修改字节码
protected DynamicType.Builder<?> enhance(TypeDescription typeDescription, DynamicType.Builder<?> newClassBuilder,
ClassLoader classLoader, EnhanceContext context) throws PluginException {
//去增强静态方法
newClassBuilder = this.enhanceClass(typeDescription, newClassBuilder, classLoader);
//去增强实例方法
newClassBuilder = this.enhanceInstance(typeDescription, newClassBuilder, classLoader, context);
return newClassBuilder;
}这里我们只看 this.enhanceInstance(typeDescription, newClassBuilder, classLoader, context) 2个方法其实都差不多
接下来终于到底,没有套娃了,因为方法比较长,我删减了部分代码,为了让读者能看懂主要逻辑
private DynamicType.Builder<?> enhanceInstance(TypeDescription typeDescription,
DynamicType.Builder<?> newClassBuilder, ClassLoader classLoader,
EnhanceContext context) throws PluginException {
//目标类 在执行构造器之前,可能会去执行一些其他的方法,要执行的方法是什么,给找出来放入数组,其实就是 aop构造器
ConstructorInterceptPoint[] constructorInterceptPoints = getConstructorsInterceptPoints();
//目标类 在执行方法的时候,可能会去执行一些其他的方法,要执行的方法是什么,给找出来放入数组
InstanceMethodsInterceptPoint[] instanceMethodsInterceptPoints = getInstanceMethodsInterceptPoints();
//目标类 的全路径
String enhanceOriginClassName = typeDescription.getTypeName();
//下面都是设置一些标识,用来判断后续是否增强,比如上面的 constructorInterceptPoints和instanceMethodsInterceptPoints 都没有增强方法,那么就直接结束整个方法了
boolean existedConstructorInterceptPoint = false;
boolean existedMethodsInterceptPoints = false;
if (constructorInterceptPoints != null && constructorInterceptPoints.length > 0) {
existedConstructorInterceptPoint = true;
}
if (instanceMethodsInterceptPoints != null && instanceMethodsInterceptPoints.length > 0) {
existedMethodsInterceptPoints = true;
}
/**
* nothing need to be enhanced in class instance, maybe need enhance static methods.
*/
if (!existedConstructorInterceptPoint && !existedMethodsInterceptPoints) {
return newClassBuilder;
}
//会向 目标类里面 写入一个属性 叫做 _$EnhancedClassField_ws,类型Object
//然后会让目标类去实现接口 EnhancedInstance, 实现这个接口的意义就是在于可以去获取 _$EnhancedClassField_ws 属性,可以理解成 getter/setter 了_$EnhancedClassField_ws
//这个 context 前面提到过时用来 控制整个流程,防止流程多次执行,所以一个类只会写入一次 _$EnhancedClassField_ws 属性,就算有多个插件作用于了同一个 目标类, 也只会执行一次
if (!context.isObjectExtended()) {
newClassBuilder = newClassBuilder.defineField(CONTEXT_ATTR_NAME, Object.class, ACC_PRIVATE | ACC_VOLATILE)
.implement(EnhancedInstance.class)
.intercept(FieldAccessor.ofField(CONTEXT_ATTR_NAME));
context.extendObjectCompleted();
}
//去增强 构造器,也就是把上面 constructorInterceptPoints 中定义好的 增强方法给代理到构造器上面
if (existedConstructorInterceptPoint) {
for (ConstructorInterceptPoint constructorInterceptPoint : constructorInterceptPoints) {
//这里被我删减了,就是用 constructorInterceptPoint去操作 newClassBuilder 对象修改字节码
}
}
//去增强 方法 把instanceMethodsInterceptPoints 中定义好的 增强方法给代理到指定方法上面
if (existedMethodsInterceptPoints) {
for (InstanceMethodsInterceptPoint instanceMethodsInterceptPoint : instanceMethodsInterceptPoints) {
//这里被我删减了,就是用 instanceMethodsInterceptPoint去操作 newClassBuilder 对象修改字节码
}
}
return newClassBuilder;
}其实说白了 上述 步骤就是 3步
- 向目标类写入一个属性
_$EnhancedClassField_ws,然后让目标类实现接口EnhancedInstance让他有set/get_$EnhancedClassField_ws属性的能力,具体这个属性有什么用,后面系列会讲到,这里就不做过多说明了,然后我们来验证一下是否真的写入了属性_$EnhancedClassField_ws,
我这里有一个非常简单的 目标类,我加载了spring-mvc 插件,所有打了@Controller的类都会成为目标类
@Controller
public class TestController {
@RequestMapping("/wx/chy")
public String test(){
return "hehe";
}
}然后我打上断点在 return "hehe" 访问 /wx/chy 进入断点
使用反射可以看到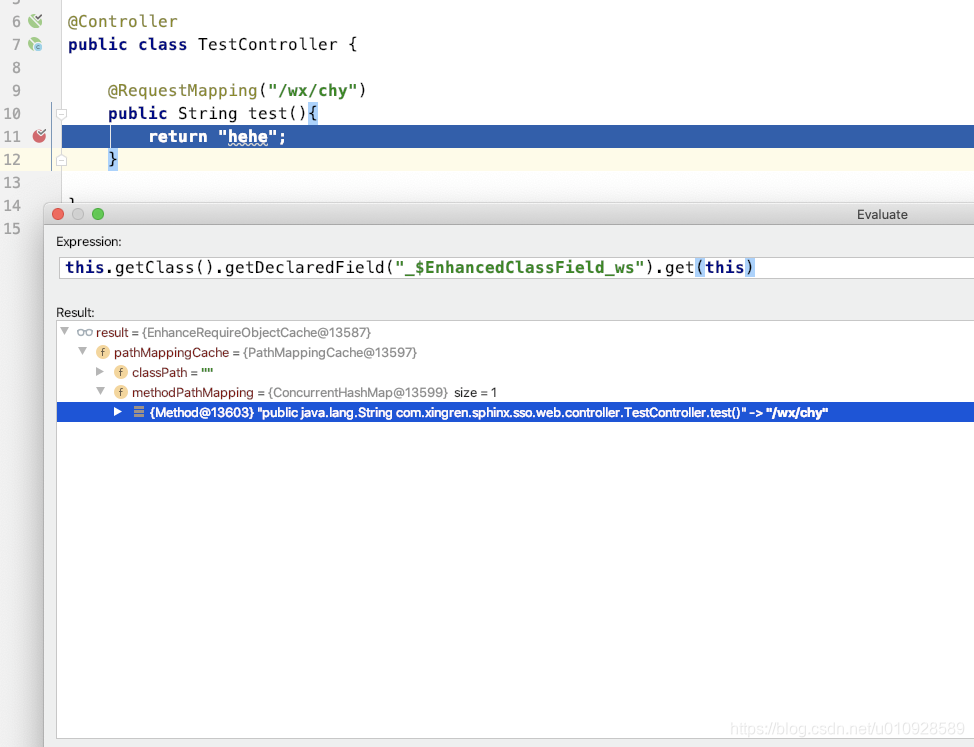
确实有一个 叫做 _$EnhancedClassField_ws 的属性
- 给构造器设置代理方法,代理方法来自
getConstructorsInterceptPoints() - 给实例方法设置代理方法,代理方法来自
getInstanceMethodsInterceptPoints()
这边我们大概看下 spring-mvc 插件的 getInstanceMethodsInterceptPoints() 方法
public InstanceMethodsInterceptPoint[] getInstanceMethodsInterceptPoints() {
return new InstanceMethodsInterceptPoint[] {
new DeclaredInstanceMethodsInterceptPoint() {
@Override
public ElementMatcher<MethodDescription> getMethodsMatcher() {
return byMethodInheritanceAnnotationMatcher(named("org.springframework.web.bind.annotation.RequestMapping"));
}
@Override
public String getMethodsInterceptor() {
return "org.apache.skywalking.apm.plugin.spring.mvc.commons.interceptor.RequestMappingMethodInterceptor";
}
@Override
public boolean isOverrideArgs() {
return false;
}
},
new DeclaredInstanceMethodsInterceptPoint() {
@Override
public ElementMatcher<MethodDescription> getMethodsMatcher() {
return byMethodInheritanceAnnotationMatcher(named("org.springframework.web.bind.annotation.GetMapping"))
.or(byMethodInheritanceAnnotationMatcher(named("org.springframework.web.bind.annotation.PostMapping")))
.or(byMethodInheritanceAnnotationMatcher(named("org.springframework.web.bind.annotation.PutMapping")))
.or(byMethodInheritanceAnnotationMatcher(named("org.springframework.web.bind.annotation.DeleteMapping")))
.or(byMethodInheritanceAnnotationMatcher(named("org.springframework.web.bind.annotation.PatchMapping")));
}
@Override
public String getMethodsInterceptor() {
return "org.apache.skywalking.apm.plugin.spring.mvc.commons.interceptor.RequestMappingMethodInterceptor";
}
@Override
public boolean isOverrideArgs() {
return false;
}
}
};
}整个方法非常的简单,就是把打了注解 @RequestMapping 的方法给加上一个代理方法 RequestMappingMethodInterceptor
由上可见,要自定义个skywalking 插件非常简单,只要继承抽象类 AbstractClassEnhancePluginDefine 然后去实现 里面的 getConstructorsInterceptPoints() , getInstanceMethodsInterceptPoints() 等方法就行
这里还是以 spring-mvc 插件为例
4 . 结尾
到此,整个 skywalkingAgent插件 的加载流程就结束,到此为止,仅仅是揭露了 skywalking 如何去加载插件,如何去修改应用的字节码. 但是和分布式链路追踪 好像还没有半毛钱关系,具体skywalkingAgent插件 如何去记录调用信息,如何跨进程传递数据,如何发送数据给skywalkingServer 请看下回分解
skywalking源码解析系列二 : agent采集trace数据_skywalking采不到方法trace-CSDN博客
1. 简介
本文源码解析使用的版本是 skywalking 7.0 , 不同版本实现上可能由一定差异,但是思想上大致相同
上篇文章介绍了skywalking-agent的整体架构以及插件的加载原理。
skywalking源码解析系列一: agent插件加载原理
但是仅仅知道了他如何去加载插件,那至于在他使用agent去修改业务代码后如何去收集trace数据 那么请继续往下看
2. trace数据结构
在看源码之前,我们先来了解一下 在skywalking中trace数据 是以什么样的数据结构去保存的,这里为了更清晰展示,这里选择从前端查看trace数据的结构
首先先来一个最简单的例子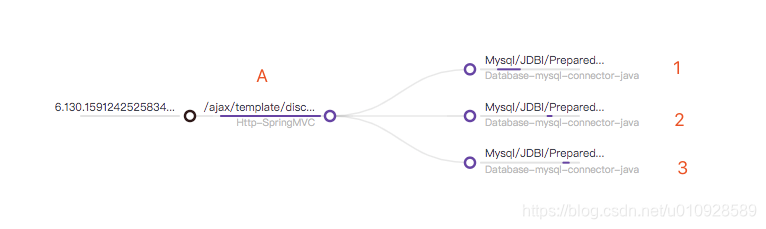 其实就是一个 请求,访问的三次数据库,对应方法大概如下
其实就是一个 请求,访问的三次数据库,对应方法大概如下
请求A(){
访问数据库1()
访问数据库2()
访问数据库3()
}然后我们来看看要显示这样一条 调用链 需要多少数据,这里把断点打在 trace-detail-chart-tree.vue 文件的 changeTree()方法上面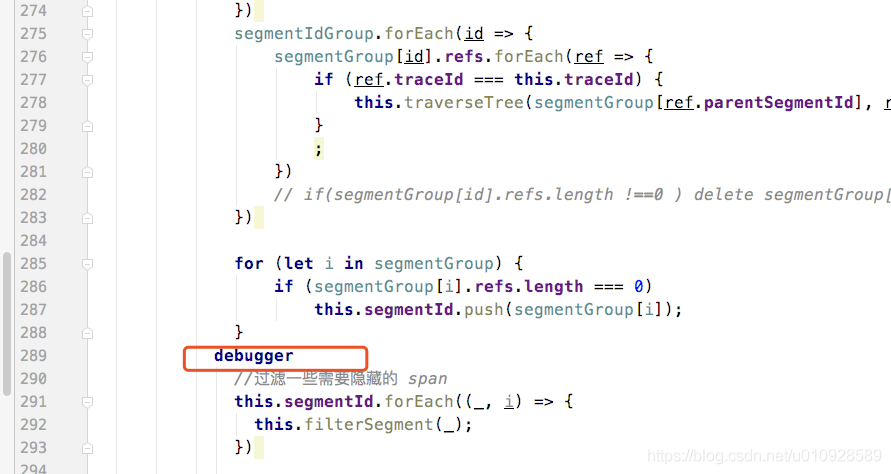
然后我们来查看 this.segmentId 中的数据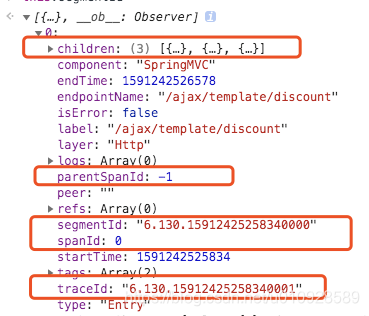
这里需要关注的数据我已经标注出来,但名字也大概能猜出这几个参数是干什么的,children 这个属性是用JS算出来挂载上去的对象,在实际的skywalking中并不是这么存储的,那么他是如何计算出children是谁,这里就要去关注一下那几个ID了
这里为了结构更清晰 我精简了一下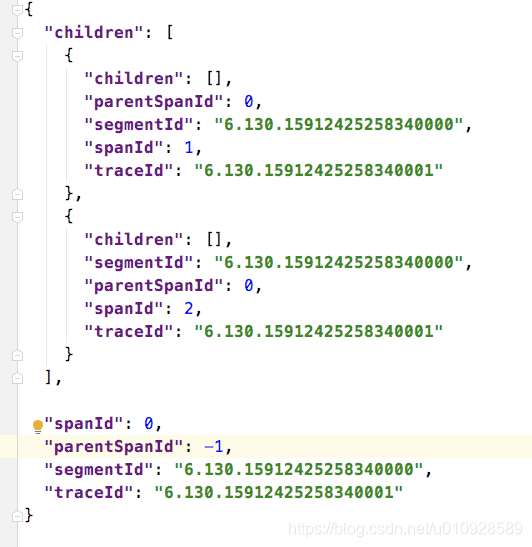
从上图可以看出 traceId / segmentId 都是相同的,不同的只是 spanId和parentSpanId 这里 可以看出 children的parentSpanId 属性指向了 父节点的 spanId属性。
嗯 这里可以看出 spanId 和 parentSpanId 的作用,就上面这个 例子来说可以认为 每一个记录点就是一个 span 他的唯一标识是 spanId , 然后父子关系通过parentSpanId 去关联。
然而真的是这样的吗?
我们看下面一个例子
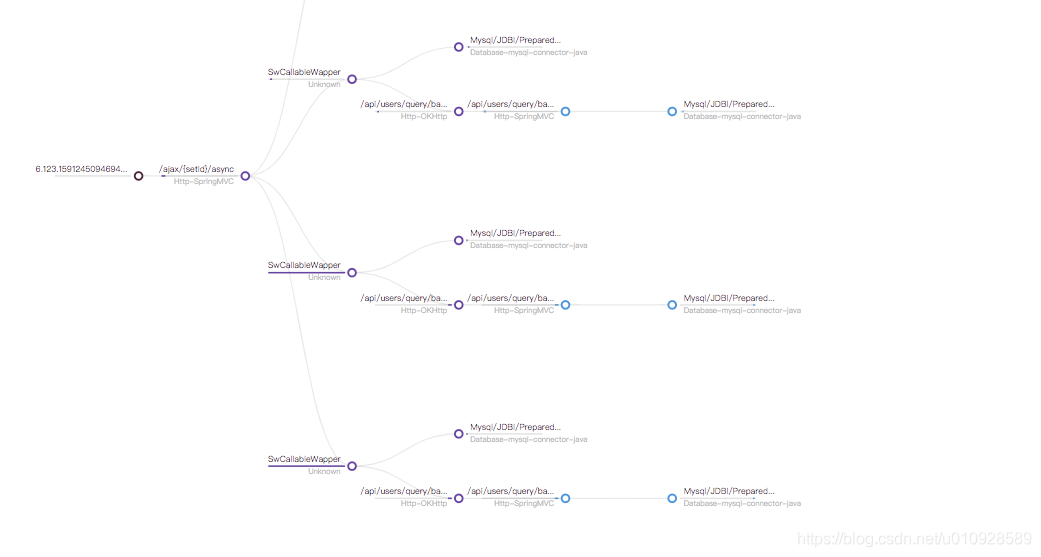
这个调用链比较复杂 和上面最大的不同在于 SwCallableWapper 这是我自己封装的跨线程的插件(skywalking线程池插件,解决lamdba使用问题),也就是说 我这里的调用链上是跨了线程,同时 蓝色的点是远程调用了另外一个服务,也就是说我这边还跨了进程,
如果转成对应的方法就是
链路方法(){
多线程异步方法(){
访问数据库()
远程调用服务() --> 在远程服务这边执行了数据库
}
...后面同样的 异步方法 调用了 3次
}那我们来看看他有什么不同
下面我只截取了 从链路入口到 SwCallableWapper 也就是跨线程 的一段数据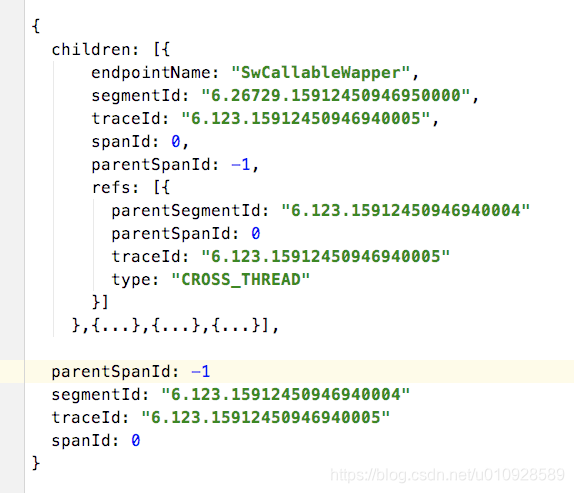
可以看出 segmentId 不同了,但是 traceId 父子还是相同的 , 同时 spanId 2个都是从 0 开始的,而parentSpandId 指向都是 -1 ,那么最开始那个例子的 使用spanId 来关联 父子 关系的逻辑失效了,同时为了标识出 children 的父亲到底是谁,新增加了一个属性 refs,这个属性里关联上了 父节点的所有 ID 信息。 同样跨进程 的远程调用也是一样的。
其实可以大概看出来 spanId 就像一个 链条一样把 一条链路 给串起来,但是如果是 跨线程/进程 又会创建出一个新的链条,然后用 refs 把这几段链条给接连接起来
那么最后调用实际上的链路结构是这样的
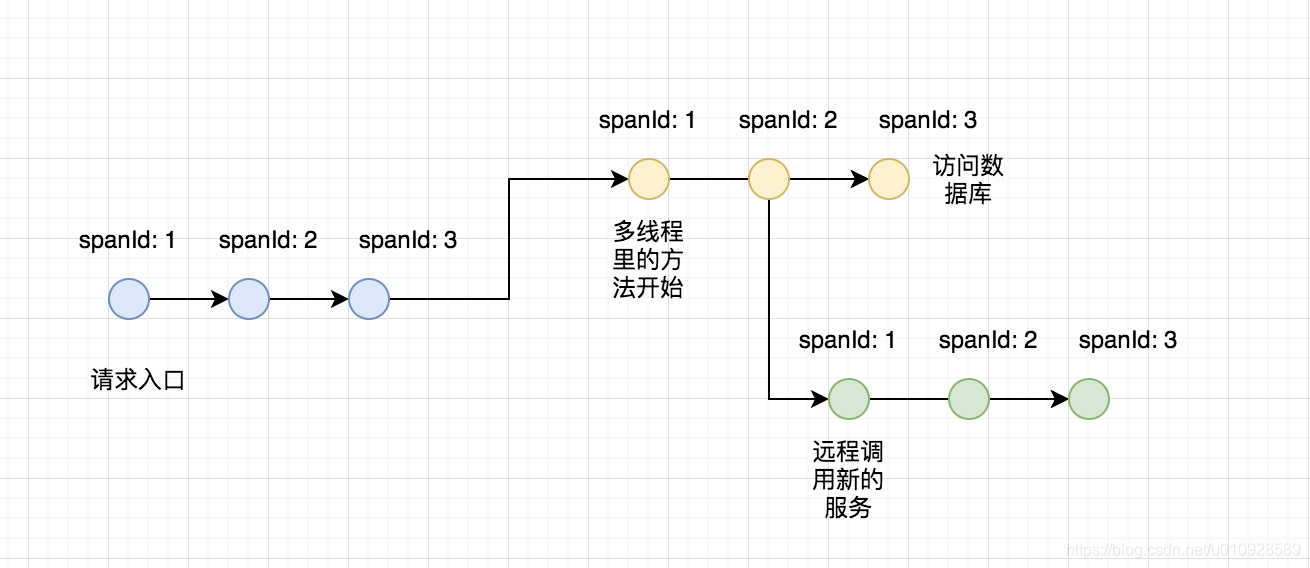
相同颜色的小球可以任何 是在同一个线程中 , 在同一个线程中 的 segmentId 都是相同的,并且在同一个线程中 , 使用 spanId以及parentSpanId去连接链路,线程、进程中不同的链路使用refs去连接,同时多个 线程链路 组成一个 trace,他们的 traceID 都是相同的
至于为什么 不同线程的链路 需要用refs连接而不是 spanId一直传递下去的方式连接,后面会给出答案
下面就总结一下 上面出现的 几个 ID 都是什么含义
spanId: 同一个线程中唯一, 从0始,按照调用链路从0递增parentSpanId: 在同一个线程的链路中,用来连接spansegmentId: 同一个线程链路中,这个值都是相同的,不同线程链路中 这个值不同traceId: 在一个链路中traceId唯一
3. trace 数据采集
上面讲了这么多,那么agent 到底怎么去采集数据嗯, 接下来将会已 spring-mvc-plugin 插件为例子 来讲解
以下 源码来源于 agent 插件 mvc-annotation-commons,这个插件是官方自带的
这个插件会去 代理 所有打了 @requestMapping 注解的方法,让其在进入对应前以及方法结束后做一些事件,至于他怎么代理请看 skywalking源码解析 (1) : agent插件加载原理
在类 AbstractMethodInterceptor#beforeMethod 方法里可以看到 当执行 @requestMapping 标注的的方法前将会做些什么 , 下面的代码是我删除过一些 代码,一遍能更清晰体现流程
@Override
public void beforeMethod(EnhancedInstance objInst, Method method, Object[] allArguments, Class<?>[] argumentsTypes,
MethodInterceptResult result) throws Throwable {
String operationName;
//在之前提到过,在agent修改字节码的时候,会在对应的业务类里去 写入一个属性,然后让业务类实现接口 EnhancedInstance ,从此能有能力去获取这个属性
EnhanceRequireObjectCache pathMappingCache = (EnhanceRequireObjectCache) objInst.getSkyWalkingDynamicField();
//pathMappingCache 这个属性里存放是的是 method -> url 的数据,如果没有对应的缓存,就重新获取一下,然后存入缓存里
String requestURL = pathMappingCache.findPathMapping(method);
if (requestURL == null) {
requestURL = getRequestURL(method);
pathMappingCache.addPathMapping(method, requestURL);
requestURL = getAcceptedMethodTypes(method) + pathMappingCache.findPathMapping(method);
}
operationName = requestURL;
//获取了当前请求的 request
HttpServletRequest request = (HttpServletRequest) ContextManager.getRuntimeContext()
.get(REQUEST_KEY_IN_RUNTIME_CONTEXT);
if (request != null) {
// 获取 stackDepth, 用来记录本次调用链的深度
//比如 如果这个请求 第一站进入了这个 interceptor 那么他的深度就是0/null , 如果在此之前有其他的 interceptor提前执行了,那么深度 +1, 例如: tomcat 的插件
StackDepth stackDepth = (StackDepth) ContextManager.getRuntimeContext().get(CONTROLLER_METHOD_STACK_DEPTH);
//等于null 说明是入口 span
if (stackDepth == null) {
//获取了跨进程的 context
ContextCarrier contextCarrier = new ContextCarrier();
CarrierItem next = contextCarrier.items();
while (next.hasNext()) {
next = next.next();
//从header 里获取了远程调用时候传送过来的数据,塞入contextCarrier
//setHeadValue 的时候会自动反序列化
next.setHeadValue(request.getHeader(next.getHeadKey()));
}
//创建一个入口 span
//下面都是在给这个span去塞入一些信息
AbstractSpan span = ContextManager.createEntrySpan(operationName, contextCarrier);
Tags.URL.set(span, request.getRequestURL().toString());
Tags.HTTP.METHOD.set(span, request.getMethod());
span.setComponent(ComponentsDefine.SPRING_MVC_ANNOTATION);
SpanLayer.asHttp(span);
//如果这个是入口类,那么创建一个新的 stackDepth
stackDepth = new StackDepth();
ContextManager.getRuntimeContext().put(CONTROLLER_METHOD_STACK_DEPTH, stackDepth);
} else {
AbstractSpan span = ContextManager.createLocalSpan(buildOperationName(objInst, method));
span.setComponent(ComponentsDefine.SPRING_MVC_ANNOTATION);
}
//深度 +1,在afterMethod 的时候会去 -1
stackDepth.increment();
}
}
上面代码其实要关注的是 span 的创建上面,从上面代码可以看出 如果 进入这个方法之前没有创建过任何一个 span那么就将会使用一个 ContextManager.createEntrySpan() 去创建span,如果在之前就已经创建过 span(比如如果使用了 tomcat 的插件,那么 tomcat 才将是 这次调用链的第一站),那么使用ContextManager.createLocalSpan() 去创建 span,那么看名字是否猜到还有一个 ContextManager.createExitSpan() , 从这这三者 从名字上看 也就是标识 了 入口 -> 本地 -> 出口 上面,这也 暗示了 如果我们写插件,也需要 这么去定义 span
ContextManager.createEntrySpan(): 如果在一个进程内 这是第一个生成的span那么使用createEntrySpan()方法去创建,他除了会生成span还会帮你把之前短接的调用链给连接起来(比如 远程调用 A - > B 在 B服务 调用createEntrySpan才能和A 关联起来)ContextManager.createLocalSpan(): 本地span, 最普通的创建span的方法ContextManager.createExitSpan(): 如果在一个进程内 发现这已经是这个进程最后一个调用span, 使用createExitSpan去创建对应的span, 比如 使用okhttp去调用别的服务,那么在okhttp发送之前就已经是最后一个span了,方法createExitSpan除了 会帮你创建一个span,还会帮你把 一些id信息带给 被调用方(okhttp是把ID信息给序列化放在 header里),被调用方使用createEntrySpan()就能把整个请求给 连接起来,这里需要留意的是 这里带给的 id 其实就是上问提到的traceId/segmentId/spanId,这三者组成了一个 完成的refs属性,刚好对应上上文所讲,如果看不懂可以再回过去看一遍
既然有前置代理方法,那就肯定有 后置 代理方法,在后置代理方法上面,聪明的小伙伴都能想到会把方法执行的结果,异常 等信息存入 span, 那么如果我没有对应的 放回数据 , 也不想记录异常,那么是否可以不写后置处理方法嗯? 答案是 不可以
因为可以 把在同一线程中的 调用链路 看做是一个 栈 , 执行createSpan() 是入栈的过程,那么执行ContextManager.stopSpan() 就是出栈的过程
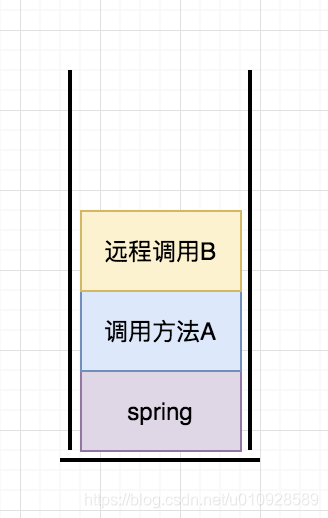
入上图所示, 在这个情况下 如果我直接 ContextManager.stopSpan() 那么 停止的就是远程调用B创建出来的 span,所以如果自定义插件,一定要确保自己的 span成功出栈
4. trace 数据采集
上面讲了如何去创建 span 那么 这些数据会如何发送到 skywalking ?
首先,要发送这些span 数据不能够阻塞 我们的业务线程,而然后有一定的数据量,需要批量发送等功能,所以这边 skywalking 使用了 生产-消费 的模型
4.1 生产者
上面提到,每当一个方法结束后 都需要调用一下 ContextManager.stopSpan() 方法,没错这个方法就是 将 span塞入队列的 方法,但是 并不是 每次调用 ContextManager.stopSpan() 都会把出栈的 span扔入队列的
在 TracingContext#finish() 中可以看到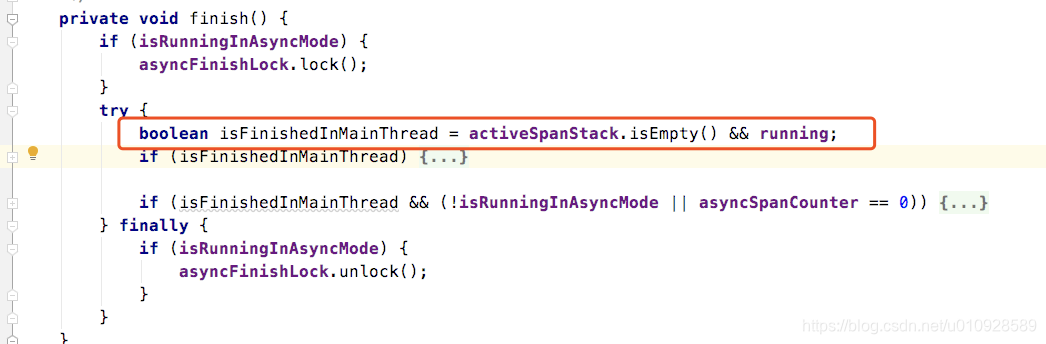
这里其实他就是去检查了一下 上面的 span栈空了 才会执行后面的方法 . 换句话说就是,需要等同一个线程里面所有的span 都出栈了,才会去把这整个 segment 给放入 消费队列中。
同样在 TracingContext#finish() 的方法中可以看到他如何塞入消费队列的
//这里会去通知所有注册了的 listener,本TraceSegment成功结束了
// 这里会有一个叫做 TraceSegmentServiceClient 的listener 收到这个事件后,会把 TraceSegment 放入队列 等待消费
TracingContext.ListenerManager.notifyFinish(finishedSegment);4.2 消费者
在agent 启动的时候会去 加载 模块apm-agent-core中一个 叫做 TraceSegmentServiceClient( 至于他是如何加载的 下篇文章会讲,这里就不赘述了) 的类
在这个类初始化的时候,执行了boot() 方法。
@Override
public void boot() {
lastLogTime = System.currentTimeMillis();
segmentUplinkedCounter = 0;
segmentAbandonedCounter = 0;
//这里会去创建 消费队列 可以使用 buffer.channel_size 来指定 消费队列的长度,以及 buffer.buffer_size 来指定消费队列的大小
carrier = new DataCarrier<>(CHANNEL_SIZE, BUFFER_SIZE);
carrier.setBufferStrategy(BufferStrategy.IF_POSSIBLE);
//定义了消费者,Trace 的数据将会由这个消费者去发送给 skywalking,这里传了 this 消费者就是自己
//参数2 定义了有几个消费线程,每个线程会持有不同的队列
carrier.consume(this, 1);
}
从上面可以看出 他可以配置 多个 队列以及多个线程,但实际上他写死了 使用 1个线程去发送数据,其实我觉得多个队列也没多少意义
但是如果有多个 多线的话 每个线程有自己的所属队列 去发送数据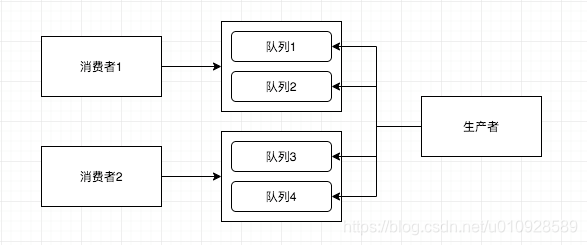
消费者的 远程调用 直接逻辑 在 TraceSegmentServiceClient#consume(List<TraceSegment> data)
@Override
public void consume(List<TraceSegment> data) {
if (CONNECTED.equals(status)) {
final GRPCStreamServiceStatus status = new GRPCStreamServiceStatus(false);
StreamObserver<UpstreamSegment> upstreamSegmentStreamObserver = serviceStub.withDeadlineAfter(
Config.Collector.GRPC_UPSTREAM_TIMEOUT, TimeUnit.SECONDS
).collect(new StreamObserver<Commands>() {..GRPC 的一些回调..});
for (TraceSegment segment : data) {
//转换一下 segment 成 proto 数据
UpstreamSegment upstreamSegment = segment.transform();
//GRPC 发送
upstreamSegmentStreamObserver.onNext(upstreamSegment);
}
//告诉 GRPC 流已经完全写入进去了,等待他全部把数据发送后会回调上面的 StreamObserver定义的回调方法
upstreamSegmentStreamObserver.onCompleted();
status.wait4Finish();
segmentUplinkedCounter += data.size();
} else {
segmentAbandonedCounter += data.size();
}
}
直接用的 GRPC 批量发送了所有的 span 数据
skywalking源码解析系列三 : agent启动服务分析以及性能影响_skywalking agent-CSDN博客
1. 简介
前2篇介绍了 agent 如何去修改我们的业务代码,以及如何去收集、发送 trace 数据,但是agent的作用不仅如此,那么他还对我们的代码做了一些什么事情,会对我们的程序造成什么样的性能影响,本文将为你揭晓
skywalking源码解析系列一: agent插件加载原理
skywalking源码解析系列二 : agent采集trace数据
2 . BootService 接口
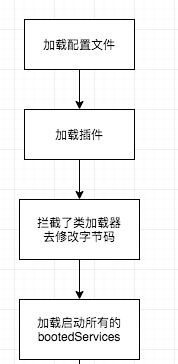
方法 SkyWalkingAgent#premain 之前讲解过这是 agent 的入口方法,这个方法的 前半部分都是在 加载配置文件、加载插件以及拦截了类加载器以便后面去修改字节码,在此之外agent还有最后一个步骤,就是去加载所有BootService接口的实现类
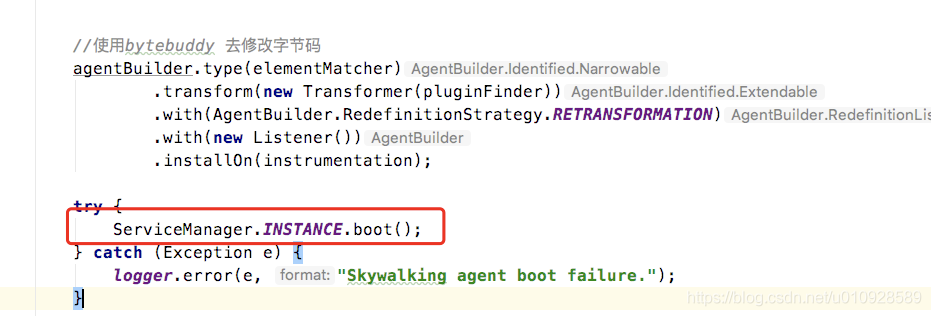
如上图所示,ServiceManager.INSTANCE.boot() 就是去加载所有的BootService 实现类,以及启动这些实现类,这个方法也非常的简单
public void boot() {
//去加载 BootService接口的实现类
bootedServices = loadAllServices();
//调用 BootService接口 的prepare 方法
prepare();
//调用 BootService接口 boot 方法
startup();
//调用 BootService接口 onComplete 方法
onComplete();
}比起如何去加载BootService实现类 这种繁琐的无价值的操作,我更关心的 BootService 的实现类有什么,他们都干了什么事,这里可以看到类的实现有如下所示
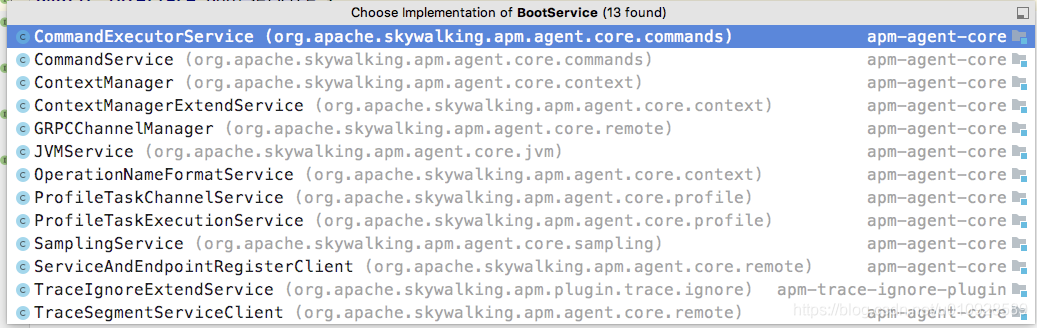
下面会挑选几个重要的实现类做重点讲解。
2.1 GRPC 连接管理 : GRPCChannelManager
skywalking 的agent和 采集器用的 GRPC 作为通讯手段, 那么我们的agent是如何知道我们的skywalking采集器 所在服务器的IP和端口是什么,又或者当 服务器失联了,又如何重新连接,答案都在GRPCChannelManager
上面讲过,在agent启动的时候会自动调用 BootService接口的prepare,boot,onComplete 三个方法,从名字可以看出,大概是干什么的,这里就不赘述了,我们直接找到 GRPCChannelManager#boot() 方法
@Override
public void boot() {
//解析用户配置的 skywalking.collector.backend_service 参数,如果写了多个IP地址用逗号分隔
grpcServers = Arrays.asList(Config.Collector.BACKEND_SERVICE.split(","));
//这里开了一个 定时任务,去连接 skywalking ,这里开了定时器去重连接 默认30s 连接一次
connectCheckFuture = Executors.newSingleThreadScheduledExecutor(new DefaultNamedThreadFactory("GRPCChannelManager"))
.scheduleAtFixedRate(new RunnableWithExceptionProtection(this,t -> logger.error("unexpected exception.", t)),
0, Config.Collector.GRPC_CHANNEL_CHECK_INTERVAL, TimeUnit.SECONDS);
}代码很简单,就是把我们传进去的 服务器的IP地址 转成数组,以及开了一个 默认30S(可以使用配置collector.grpc_channel_check_interval修改)间隔的 定时器,我们来看看这个定时器干什么什么,因为定时器传入的执行对象是this所以,还是这个类,找到他的 run 方法
public void run() {
if (reconnect) {
if (grpcServers.size() > 0) {
String server = "";
try {
//如果是设置了集群,那么服务端可能会有多个 Ip
//这里随机在这些服务器里面选出一个倒霉蛋
int index = Math.abs(random.nextInt()) % grpcServers.size();
//如果这次选到的IP和上次选到的不同就生成 GRPCChannel 对象
if (index != selectedIdx) {
selectedIdx = index;
server = grpcServers.get(index);
String[] ipAndPort = server.split(":");
if (managedChannel != null) {
managedChannel.shutdownNow();
}
//用上面选出来的 ip地址转成 managedChannel
managedChannel = GRPCChannel.newBuilder(ipAndPort[0], Integer.parseInt(ipAndPort[1]))
.addManagedChannelBuilder(new StandardChannelBuilder())
.addManagedChannelBuilder(new TLSChannelBuilder())
.addChannelDecorator(new AgentIDDecorator())
.addChannelDecorator(new AuthenticationDecorator())
.build();
//这边构建完成就 就当做连接成功了,但是实际上这里并没有真正连接到服务器去检查是否连接
//这里改变状态后,所有注册到 GRPCChannelManager 的listener 都会收到 事件变更的事件
//其中有一个 Listener ServiceAndEndpointRegisterClient 在收到 status转成CONNECTED 后,他会有一个线程去真正检查服务连接是否通。
notify(GRPCChannelStatus.CONNECTED);
reconnectCount = 0;
reconnect = false;
//
} else if (managedChannel.isConnected(++reconnectCount > Config.Agent.FORCE_RECONNECTION_PERIOD)) {
// Reconnect to the same server is automatically done by GRPC,
// therefore we are responsible to check the connectivity and
// set the state and notify listeners
reconnectCount = 0;
notify(GRPCChannelStatus.CONNECTED);
reconnect = false;
}
return;
} catch (Throwable t) {
logger.error(t, "Create channel to {} fail.", server);
}
}
}
}代码上我也写了注释,他会随机从用户写的 服务器地址里面挑选一个,然后去生成一个 ManagedChannel 对象,需要注意的是,这里ManagedChannel 创建成功不代表 已经和 skywalking 成功连接 , 然后调用了 notify(GRPCChannelStatus.CONNECTED); 去通知实现了监听接口GRPCChannelListener 的类
这里只要记住,他使用ip/端口生成了ManagedChannel 对象,以及通知了所有的 监控接口 , skywalking已经连接成功(其实可能并没有连接成功),当做完这些所有事情后 把reconnect设置为false,也就是说 下一次定时器再次执行的时候就不会再去生成 ManagedChannel了。
流程如下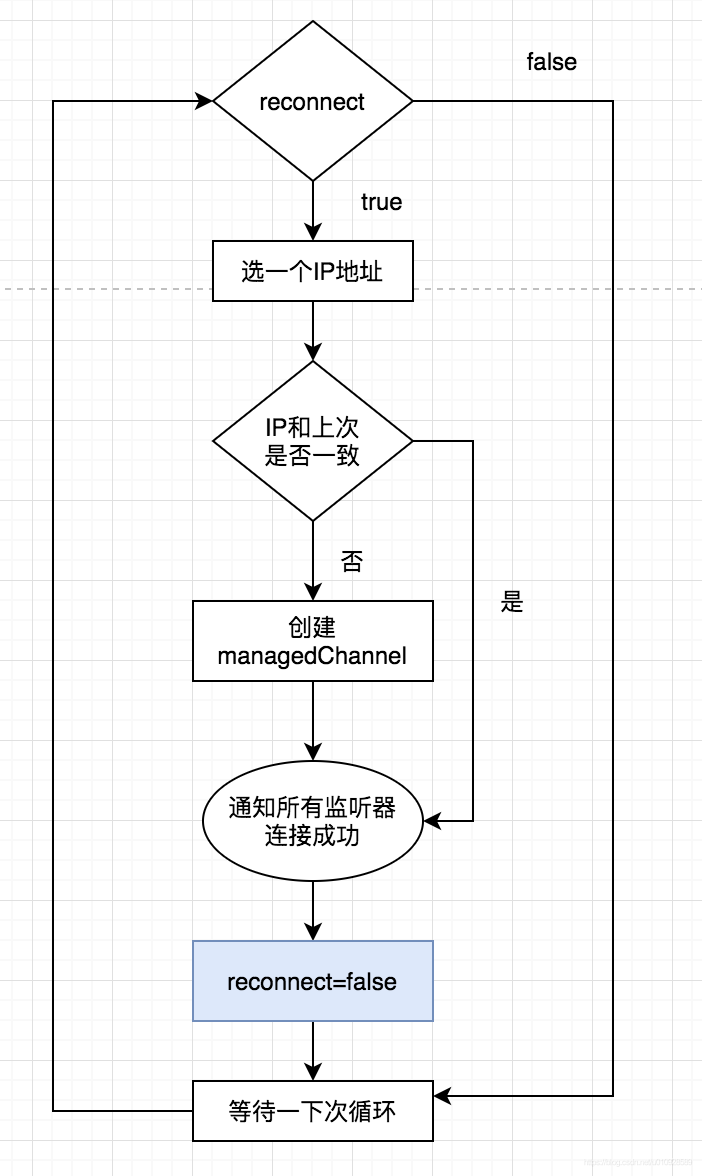
那么看到这里是不是很困惑,他并没有去判断连接到底 能不能真正连接到skywalking ,ManagedChannel 也只是生成一次就结束了,那么要这个定时器有何用?
其实在所有使用到 ManagedChannel 对象的地方,其实也就是发送GRPC的地方,如果发送失败了,都会去调用一个叫做 reportError() 的方法
public void reportError(Throwable throwable) {
if (isNetworkError(throwable)) {
reconnect = true;
notify(GRPCChannelStatus.DISCONNECT);
}
}这个方法很简单,就是重新设置reconnect = true 这样这个定时器就又能再次去创建 连接对象ManagedChannel 了(这里可能会选择到其他的IP从而复活),然后去通知所有的监听器 ,skywalking失联了
2.2 服务注册器 : ServiceAndEndpointRegisterClient
假设 agent和 skywalking 第一时间连通了,那么第一件事情是干什么嗯? 不是迫切的去发送 trace 等数据信息,而是要告诉skywalking 我是谁,这样后续发送过去的数据才能有迹可循,所以这就是 ServiceAndEndpointRegisterClient 的功能,把自己给注册进入skywalking
和前面一样还是 进入 ServiceAndEndpointRegisterClient#boot() 方法
@Override
public void boot() {
applicationRegisterFuture = Executors.newSingleThreadScheduledExecutor(
new DefaultNamedThreadFactory("ServiceAndEndpointRegisterClient")
).scheduleAtFixedRate(
new RunnableWithExceptionProtection(
this,
t -> logger.error("unexpected exception.", t)
), 0, Config.Collector.APP_AND_SERVICE_REGISTER_CHECK_INTERVAL,
TimeUnit.SECONDS
);
}
还是去开启了一个定时器,执行周期默认是 3S , 执行类还是他自己,所以继续看 ServiceAndEndpointRegisterClient#run() 方法
@Override
public void run() {
if (coolDownStartTime > 0) {
final long coolDownDurationInMillis = TimeUnit.MINUTES.toMillis(Config.Agent.COOL_DOWN_THRESHOLD);
if (System.currentTimeMillis() - coolDownStartTime < coolDownDurationInMillis) {
return;
} else {
}
}
coolDownStartTime = -1;
boolean shouldTry = true;
//这个 while 里 用if 分隔了 3个任务,每次进入 while 只会执行其中一个,这里吧里面的任务分成 A B C三个
//A:去注册应用信息 B:去注册实例信息 C:执行ping
// 如果是 第一次 状态变为 connect (A -> B) -> (C) -> (C) -> (C) ...
// 如果一直都是 connect 状态 那么 (C) -> (C) -> (C) ...
while (GRPCChannelStatus.CONNECTED.equals(status) && shouldTry) {
shouldTry = false;
try {
if (RemoteDownstreamConfig.Agent.SERVICE_ID == DictionaryUtil.nullValue()) {
if (registerBlockingStub != null) {
//生成一个只有 30S 生命周期的 客户端
RegisterGrpc.RegisterBlockingStub registerBlockingStub =
this.registerBlockingStub.withDeadlineAfter(GRPC_UPSTREAM_TIMEOUT, TimeUnit.SECONDS);
//发送消息给skywalking 告诉他本大爷的服务名字是什么 也就是 skywalking.agent.service_name 配置的名字
ServiceRegisterMapping serviceRegisterMapping = registerBlockingStub.doServiceRegister(...);
if (serviceRegisterMapping != null) {
// skywalking 把所有注册进去的服务的名称都返回回来了,这里会去遍历如果发现有自己就算注册成功了
for (KeyIntValuePair registered : serviceRegisterMapping.getServicesList()) {
if (Config.Agent.SERVICE_NAME.equals(registered.getKey())) {
RemoteDownstreamConfig.Agent.SERVICE_ID = registered.getValue();
//这个设置成 true 那么这个 while 将会再执行一次,下一次将会去注册实例信息
shouldTry = true;
}
}
}
}
} else {
if (registerBlockingStub != null) {
if (RemoteDownstreamConfig.Agent.SERVICE_INSTANCE_ID == DictionaryUtil.nullValue()) {
// 把实例名称给注册进去了
ServiceInstanceRegisterMapping instanceMapping = registerBlockingStub.withDeadlineAfter(
GRPC_UPSTREAM_TIMEOUT, TimeUnit.SECONDS
).doServiceInstanceRegister(...);
//同样如果注册成功设置一下值
for (KeyIntValuePair serviceInstance : instanceMapping.getServiceInstancesList()) {
if (INSTANCE_UUID.equals(serviceInstance.getKey())) {
int serviceInstanceId = serviceInstance.getValue();
if (serviceInstanceId != DictionaryUtil.nullValue()) {
RemoteDownstreamConfig.Agent.SERVICE_INSTANCE_ID = serviceInstanceId;
RemoteDownstreamConfig.Agent.INSTANCE_REGISTERED_TIME = System.currentTimeMillis();
}
}
}
} else {
//ping 一下告诉 skywalking 自己还活着,算一个心跳机制
final Commands commands = serviceInstancePingStub.withDeadlineAfter(
GRPC_UPSTREAM_TIMEOUT, TimeUnit.SECONDS
).doPing(...);
//把 GRPC 的句柄给了 NetworkAddressDictionary 以及 EndpointNameDictionary ,都是只有30S的使用时间
NetworkAddressDictionary.INSTANCE.syncRemoteDictionary(
registerBlockingStub.withDeadlineAfter(GRPC_UPSTREAM_TIMEOUT, TimeUnit.SECONDS));
EndpointNameDictionary.INSTANCE.syncRemoteDictionary(
registerBlockingStub.withDeadlineAfter(GRPC_UPSTREAM_TIMEOUT, TimeUnit.SECONDS));
ServiceManager.INSTANCE.findService(CommandService.class).receiveCommand(commands);
}
}
}
} catch (Throwable t) {
//这里会把连接状态改成 DISCONNECT
ServiceManager.INSTANCE.findService(GRPCChannelManager.class).reportError(t);
}
}
}方法有点长,这边在总结一下,实际上 他做了 3件事 注册服务,注册实例,心跳
- 服务 : 使用参数
skywalking.agent.service_name来指定服务的名称 - 实例 : 同一个服务,可能会开不同的节点,每个节点就是一个实例
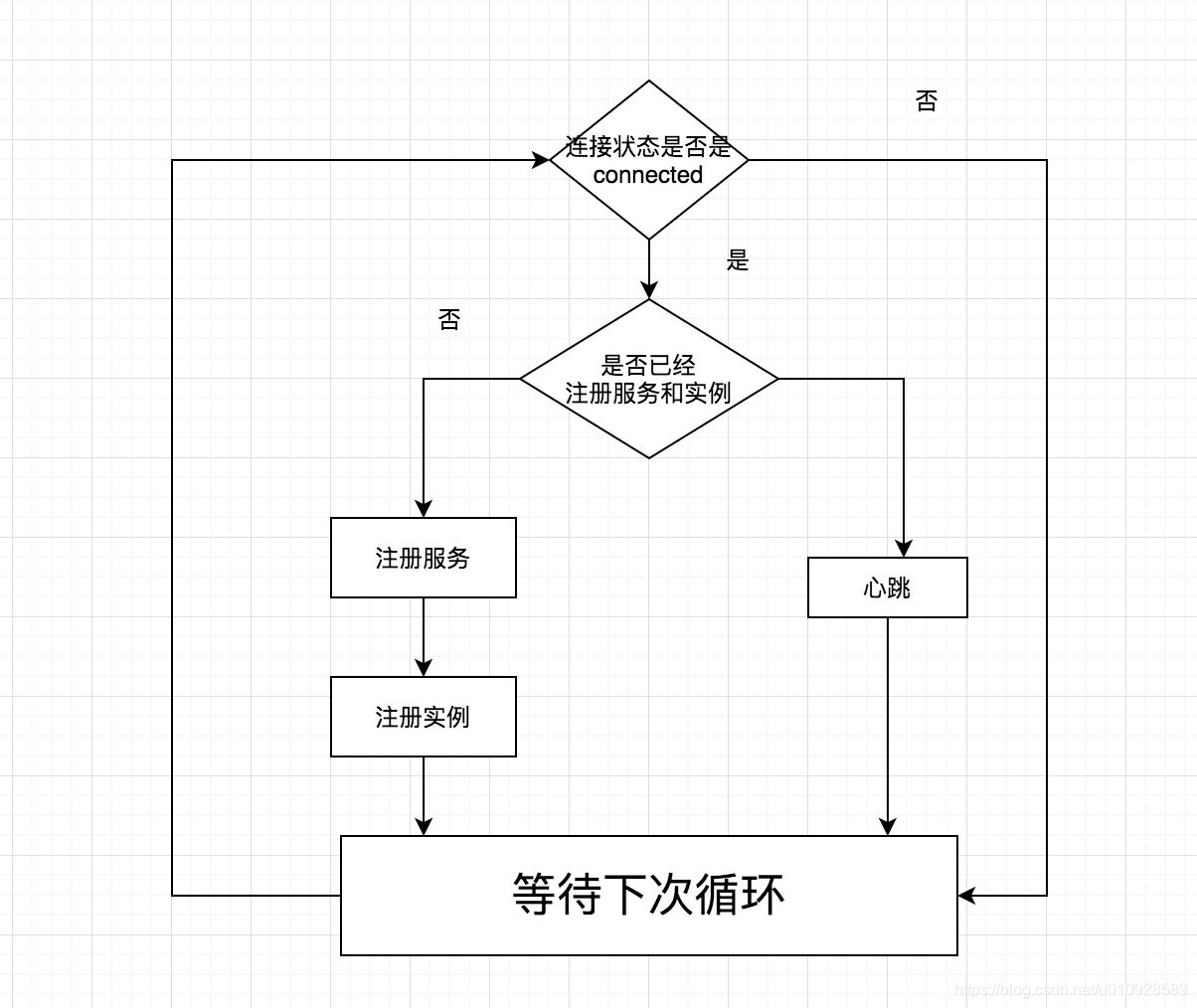
2.3 指令服务:CommandService
对于上面的服务注册,有的同学可能会有点困惑 ,他使用全局静态变量RemoteDownstreamConfig.Agent.SERVICE_ID 和 RemoteDownstreamConfig.Agent.SERVICE_INSTANCE_ID 是否有值来判断 skywalking 是否成功注册了服务信息,这2个全局静态变量 的值都是在成功注册信息后 设置上去的,但是如果在成功设置 这2个静态变量后,skywalking服务重启了怎么办? 要解决这个问题就有请我们的CommandExecutorService
同样来看他的CommandService#boot() 方法
private ExecutorService executorService = Executors.newSingleThreadExecutor();
@Override
public void boot() throws Throwable {
executorService.submit(new RunnableWithExceptionProtection(this, t -> LOGGER.error(t, "CommandService failed to execute commands")));
}同样也是启动了一个 单线程线程池, 然后把自己给搭进去了,继续看他的 run() 方法
@Override
public void run() {
final CommandExecutorService commandExecutorService = ServiceManager.INSTANCE.findService(CommandExecutorService.class);
while (isRunning) {
BaseCommand command = commands.take();
if (isCommandExecuted(command)) {
continue;
}
commandExecutorService.execute(command);
}
}简单的不行,就是阻塞去管道里拿东西,拿到了就去 执行CommandExecutorService#execute 方法,方法如下
@Override
public void execute(final BaseCommand command) throws CommandExecutionException {
executorForCommand(command).execute(command);
}一个很典型的策略模式,也就是根据 command 的类型是什么去执行对应的执行器
我们来看看他都有什么样的执行器,这里可以从CommandExecutorService#prepare() 方法可以看到,注意的是prepare() 方法也是BootService 的接口方法,在我们老朋友boot()之前执行
@Override
public void prepare() throws Throwable {
commandExecutorMap = new HashMap<String, CommandExecutor>();
// Register all the supported commands with their executors here
commandExecutorMap.put(ServiceResetCommand.NAME, new ServiceResetCommandExecutor());
// Profile task executor
commandExecutorMap.put(ProfileTaskCommand.NAME, new ProfileTaskCommandExecutor());
}从名字可以看到一个叫做 ServiceResetCommandExecutor() 的执行器 ,点进去一看
/**
* 如果 oap 给重启了,那么就会执行这个方法,在这个方法里最主要的就是把各种 参数给置空了,回到了初始状态
* @param command the command that is to be executed
* @throws CommandExecutionException
*/
@Override
public void execute(final BaseCommand command) throws CommandExecutionException {
LOGGER.warn("Received ServiceResetCommand, a re-register task is scheduled.");
//这里把 心跳检查都暂时关闭了,因为 oap那边可能正在重启中
ServiceManager.INSTANCE.findService(ServiceAndEndpointRegisterClient.class).coolDown();
//置空各种数据
RemoteDownstreamConfig.Agent.SERVICE_ID = DictionaryUtil.nullValue();
RemoteDownstreamConfig.Agent.SERVICE_INSTANCE_ID = DictionaryUtil.nullValue();
RemoteDownstreamConfig.Agent.INSTANCE_REGISTERED_TIME = DictionaryUtil.nullValue();
NetworkAddressDictionary.INSTANCE.clear();
EndpointNameDictionary.INSTANCE.clear();
}是不是到此为止,上面的疑惑就解开了,在skywalking重启的时候会向我们的agent发送一个重启命令,告诉agent 爷我重启了,快去清除以前的那些数据
如果杠精同学看到这里,可能又会问,skywalking 都重启了,如果GRPC用的是长连接,那么连接句柄早已经失效了,他如何通知agent的,如果GRPC用的是短连接,那更没理由能够通知agent了,其实要解决这个问题很简单,不需要skywalking来主动通知我们,只要agent发送的数据的时候,skywalking 发现发送过来的数据是一个不存在的服务名称发送过来的,就会返回一个ResetCommand,回到上一章将的心跳机制上面,在执行ping的时候他是不是返回了一个 commands 对象,其实不仅仅是ping,还有很多GRPC的接口都返回的commands

如果细心的同学 可以看到除了 ServiceResetCommand还有一个叫做 ProfileTaskCommand 的命令,这个具体干什么我们看一下个BootService
2.4 性能剖析 : ProfileTaskChannelService
先说个结论:这个玩意在笔者看来比较鸡肋,还占用3个线程,如果没需要可以把他关闭(默认是打开的)
在skywalking的页面上可以新建一个性能剖析 的任务,然后你可以看到对应线程现在的调用栈信息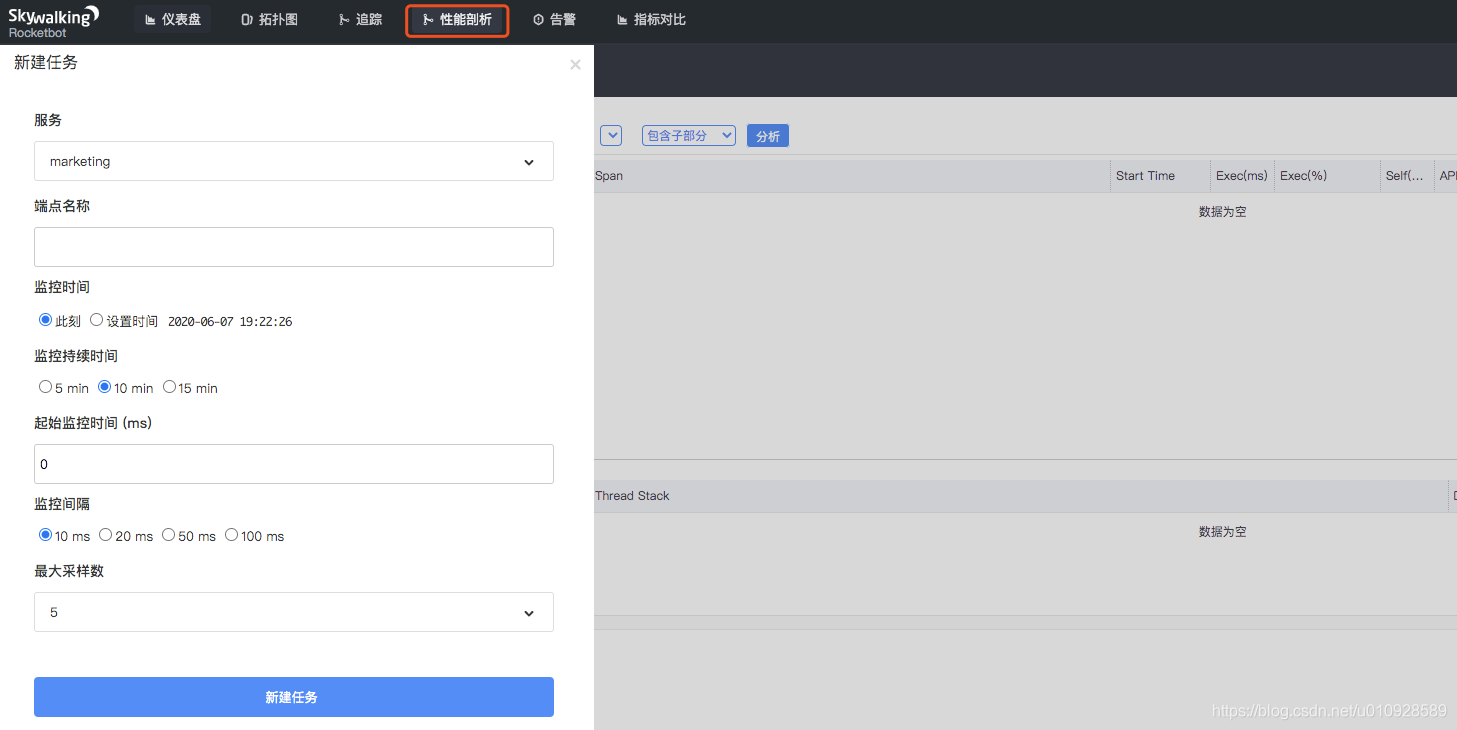
还是进去 ProfileTaskChannelService#boot() 方法
if (Config.Profile.ACTIVE) {
// query task list
getTaskListFuture = Executors.newSingleThreadScheduledExecutor(
new DefaultNamedThreadFactory("ProfileGetTaskService")
).scheduleWithFixedDelay(
new RunnableWithExceptionProtection(
this,
t -> logger.error("Query profile task list failure.", t)
), 0, Config.Collector.GET_PROFILE_TASK_INTERVAL, TimeUnit.SECONDS
);
sendSnapshotFuture = Executors.newSingleThreadScheduledExecutor(
new DefaultNamedThreadFactory("ProfileSendSnapshotService")
).scheduleWithFixedDelay(
new RunnableWithExceptionProtection(
new SnapshotSender(),
t -> logger.error("Profile segment snapshot upload failure.", t)
), 0, 500, TimeUnit.MILLISECONDS
);
}可以看出 可以用配置 profile.active 来控制是否开启(默认开启),创建了2个定时器,一个 20S执行一次一个 500ms 执行一次
我们先看 20S执行一次的,他的名字叫做 getTaskListFuture,从名字上看是获取任务列表 , 我来看他的 run 方法,下面是精简过的代码
@Override
public void run() {
if (RemoteDownstreamConfig.Agent.SERVICE_ID != DictionaryUtil.nullValue()
&& RemoteDownstreamConfig.Agent.SERVICE_INSTANCE_ID != DictionaryUtil.nullValue()) {
if (status == GRPCChannelStatus.CONNECTED) {
ProfileTaskCommandQuery.Builder builder = ProfileTaskCommandQuery.newBuilder();
// 把服务ID和实例ID传给skywalking 看看有没对应的 ProfileTask
builder.setServiceId(RemoteDownstreamConfig.Agent.SERVICE_ID)
.setInstanceId(RemoteDownstreamConfig.Agent.SERVICE_INSTANCE_ID);
builder.setLastCommandTime(ServiceManager.INSTANCE.findService(ProfileTaskExecutionService.class)
.getLastCommandCreateTime());
Commands commands = profileTaskBlockingStub.withDeadlineAfter(GRPC_UPSTREAM_TIMEOUT, TimeUnit.SECONDS)
.getProfileTaskCommands(builder.build());
ServiceManager.INSTANCE.findService(CommandService.class).receiveCommand(commands);
}
}
}代码非常的简单,就是把 服务ID和实例ID传给skywalking 看看有没对应的 ProfileTask , 如果有的话就让 CommandService 去执行对应的 commands,这里的 commands 其实也就是上面提到的 ProfileTaskCommand , 也就是说这是一个 20S周期的轮询器
这里我们继续往下看,如果收到了 ProfileTaskCommand 指令 他会去干什么
ProfileTaskCommandExecutor#execute 方法
@Override
public void execute(BaseCommand command) throws CommandExecutionException {
final ProfileTaskCommand profileTaskCommand = (ProfileTaskCommand) command;
// build profile task
final ProfileTask profileTask = new ProfileTask();
profileTask.setTaskId(profileTaskCommand.getTaskId());
profileTask.setFistSpanOPName(profileTaskCommand.getEndpointName());
profileTask.setDuration(profileTaskCommand.getDuration());
profileTask.setMinDurationThreshold(profileTaskCommand.getMinDurationThreshold());
profileTask.setThreadDumpPeriod(profileTaskCommand.getDumpPeriod());
profileTask.setMaxSamplingCount(profileTaskCommand.getMaxSamplingCount());
profileTask.setStartTime(profileTaskCommand.getStartTime());
profileTask.setCreateTime(profileTaskCommand.getCreateTime());
// send to executor
ServiceManager.INSTANCE.findService(ProfileTaskExecutionService.class).addProfileTask(profileTask);
}这里又把任务饶了一个圈 到了 ProfileTaskExecutionService#addProfileTask 里面,这个 addProfileTask很简单,就是把任务加入队列,然后开启一个定时器,在指定时间后去执行任务(可以看上面页面,用户是可以指定开始时间的)
public void addProfileTask(ProfileTask task) {
// 把ProfileTaskCommand 任务存入队列
profileTaskList.add(task);
//到达用户设置的时间后开启任务
long timeToProcessMills = task.getStartTime() - System.currentTimeMillis();
PROFILE_TASK_SCHEDULE.schedule(() -> processProfileTask(task), timeToProcessMills, TimeUnit.MILLISECONDS);
}如果时间到了,就会执行下面的方法
private synchronized void processProfileTask(ProfileTask task) {
// 确保上一个 任务已经停止
stopCurrentProfileTask(taskExecutionContext.get());
// 创建一个新的任务
final ProfileTaskExecutionContext currentStartedTaskContext = new ProfileTaskExecutionContext(task);
taskExecutionContext.set(currentStartedTaskContext);
// 开了一个线程去执行对应的性能剖析任务
currentStartedTaskContext.startProfiling(PROFILE_EXECUTOR);
PROFILE_TASK_SCHEDULE.schedule(
() -> stopCurrentProfileTask(currentStartedTaskContext), task.getDuration(), TimeUnit.MINUTES);
}他在这个定时器中去开启了一个线程去执行这个性能 剖析任务,最后又开启了一个定时器到达指定时间后关闭这个性能剖析任务(这线程一层套一层这个套娃行为也是醉了),同时这里还有一个重要的信息,就是同一个agent只能开启一个 性能剖析任务,因为开启新的任务前,都会去关闭老的任务
接下来就是去看看那个 性能剖析任务 的任务都干了什么,这里就不贴代码,我贴累了 如果想看的去ProfileThread#profiling, 稍稍简述一下就是,里面有个死循环,不断去一个队列里获取currentProfiler (这个算业务线程的包装类,里面是保存了业务线程的句柄), 如果获取到了 判断一下状态,如果状态是 PROFILING 就 从currentProfiler获取业务线程对象,然后把他的 dump给保存下来 ,
那么 currentProfiler 对象又是从什么地方保存进去的嗯?
他在 创建 TracingContext 对象的构造器的时候就会生成 currentProfiler 塞入队列里, TracingContext 对象的生成其实就是在 createSpan() 的时候(具体详情可以看 skywalking源码解析系列二 : agent采集trace数据),也就是在 创建 链路开始的时候生成了 currentProfiler, 同时也会在 链路 结束的时候把队列给清除掉,并且第一次生成的 currentProfiler 状态是 READY,在下次循环的时候才会升级成PROFILING , 那么如果 在升级到PROFILING 之前链路就结束了,那么你就无法看到 对应的调用栈
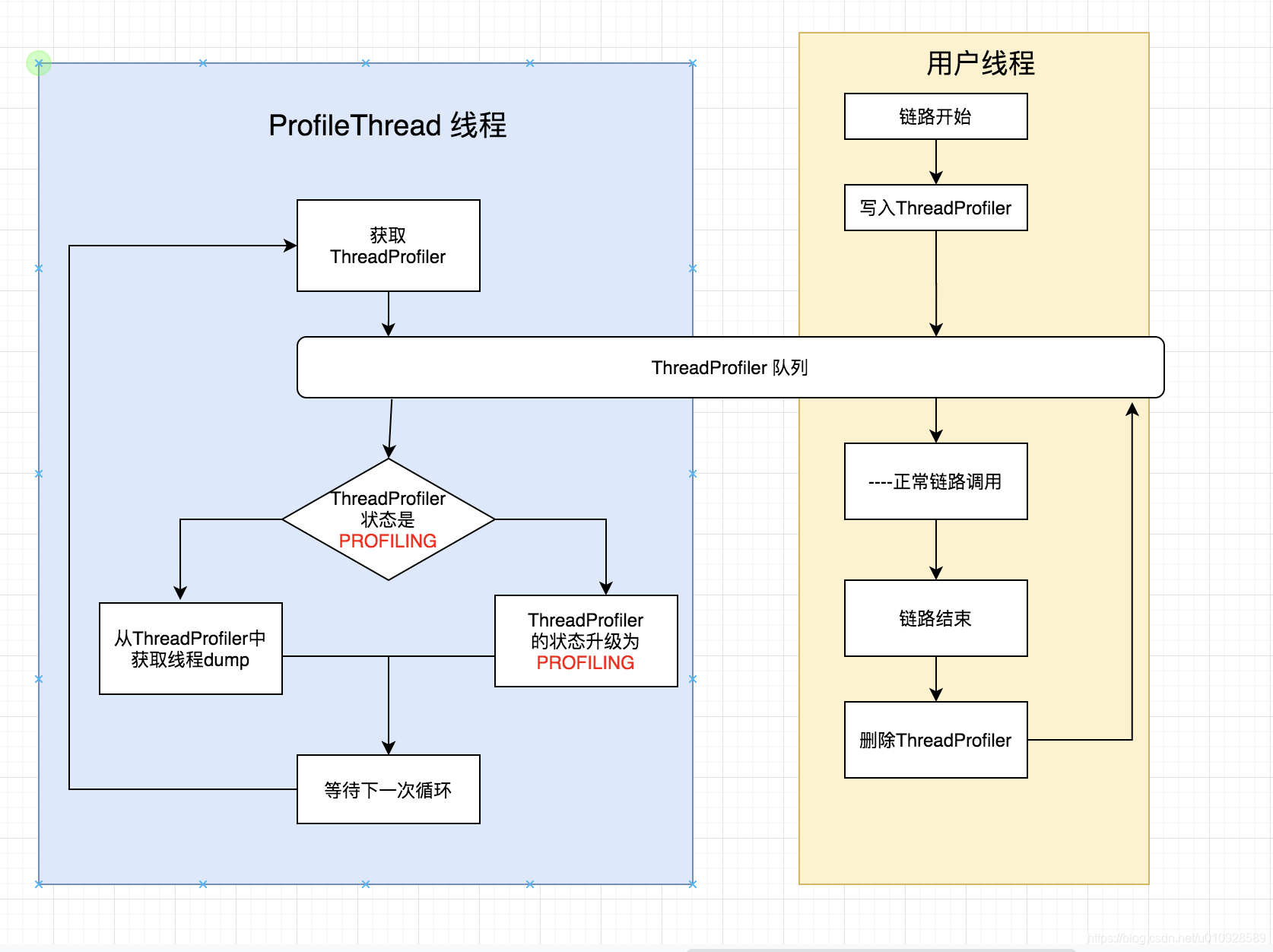
从上来看,开启一个 ProfileTask 最差可能会额外启动 4个线程
这里需要补充的是,并不是这个功能没有价值了,这个功能的本身就是用来去定位那些特别慢的方法,可以通过调用栈来定位到底这个方法卡在什么地方,但是如果是一个正常的调用,别乱加任务即可
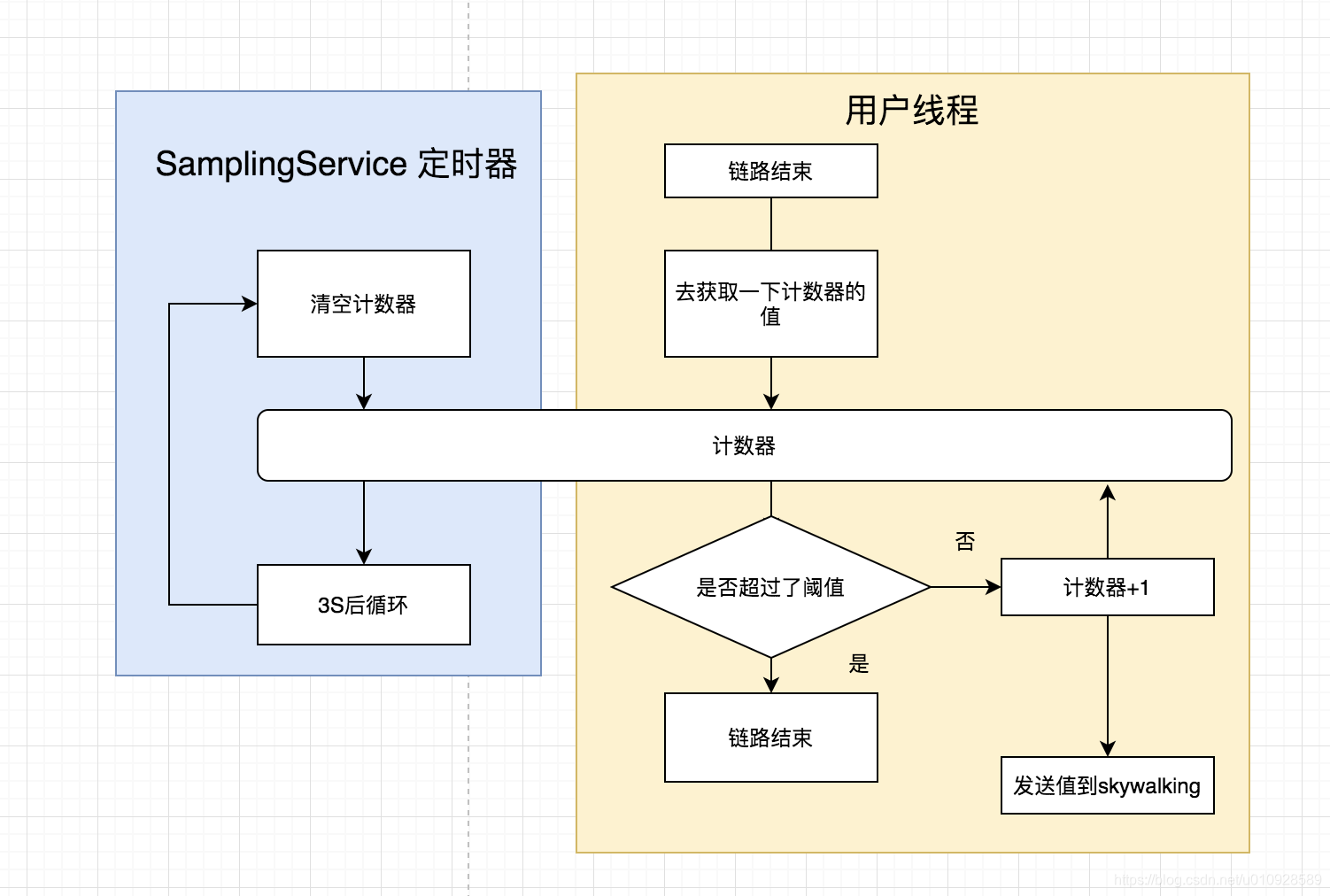
2.4 采样收集 : SamplingService
正常的情况下,每一次的 调用信息都会发送给 skywalking,但是这样可能会对系统性能造成一定的影响,SamplingService 的作用就是可以限定 3S内发送多少 trace 数据,超过的数据将会被丢弃
老规矩,入口先看 SamplingService#boot()
@Override
public void boot() {
if (Config.Agent.SAMPLE_N_PER_3_SECS > 0) {
on = true;
this.resetSamplingFactor();
ScheduledExecutorService service = Executors.newSingleThreadScheduledExecutor(
new DefaultNamedThreadFactory("SamplingService"));
scheduledFuture = service.scheduleAtFixedRate(new RunnableWithExceptionProtection(
this::resetSamplingFactor, t -> logger.error("unexpected exception.", t)), 0, 3, TimeUnit.SECONDS);
}
}如果设置了属性 sample_n_per_3_secs(默认是-1 也就是不开启) 开启了一个 周期是 3S的定时器,需要注意的是这个定时器是用了 清空记录的
在SamplingService内使用了一个AtomicInteger 来计数,保证了并发问题,在每次 调用链 结束,准备发送数据到 skywalking的时候,就会去调用一下 SamplingService#trySampling 方法来看看超过上限没有,如果没有就能够正常发送,同时计数器+1 , 如果已经达到上限了,那么就会把这个Segment 设置成 Ignore,也自然不会发送给 skywalking了

然后如果到达了 3s 的周期,定时器会把计数器里的值给清空
2.5 JVM数据采集 : JVMService
skywalking 在页面上也能看到可以看到 一些JVM的信息,这些信息都是 JVMService 采集的
还是看 boot() 方法
@Override
public void boot() throws Throwable {
//间隔1秒 搜集一次 jvm的信息
collectMetricFuture = Executors.newSingleThreadScheduledExecutor(new DefaultNamedThreadFactory("JVMService-produce"))
.scheduleAtFixedRate(new RunnableWithExceptionProtection(this, t -> logger.error("JVMService produces metrics failure.", t)), 0, 1, TimeUnit.SECONDS);
//间隔1秒,发送一次 jvm的信息
sendMetricFuture = Executors.newSingleThreadScheduledExecutor(new DefaultNamedThreadFactory("JVMService-consume"))
.scheduleAtFixedRate(new RunnableWithExceptionProtection(sender, t -> logger.error("JVMService consumes and upload failure.", t)), 0, 1, TimeUnit.SECONDS);
}同样开了2个线程 一个采集一个发送,典型的生产消费模式,这里就不赘述了,套路和上面那些都是一样的
3. 总结
agent 在我们应用程序 最坏的情况下 开启了 10 个左右的线程去监控/发送 数据,对性能还是有一定影响,如果有的功能基本用不到的,建议可以关闭对应的线程,来节约对应的资源,没错说的就是你ProfileTaskChannelService
快速集成Skywalking 9(Windows系统、JavaAgent、Logback)_skywalking windows-CSDN博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号