linux内存管理--用户空间和内核空间
关于虚拟内存有三点需要注意:
- 4G的进程地址空间被人为的分为两个部分--用户空间与内核空间。用户空间从0到3G(0xc0000000),内核空间占据3G到4G。用户进程通常情况下只能访问用户空间的虚拟地址,不能访问内核空间的虚拟地址。例外情况只有用户进程进行系统调用(代表用户进程在内核态执行)等时刻可以访问到内核空间。
- 用户空间对应进程,所以每当进程切换,用户空间就会跟着变化;而内核空间是由内核负责映射,它并不会跟着进程变化,是固定的。内核空间地址有自己对应的页表,用户进程各自有不同的页表。
- 每个进程的用户空间都是完全独立、互不相干的。
一、4G地址空间解析图

上图展示了整个进程地址空间的分布,其中4G的地址空间分为两部分,在用户空间内,对应了内存分布的五个段:数据段、代码段、BSS段、堆、栈。在上篇文章中有详细的介绍。
二、虚拟地址空间分配及其与物理内存对应图
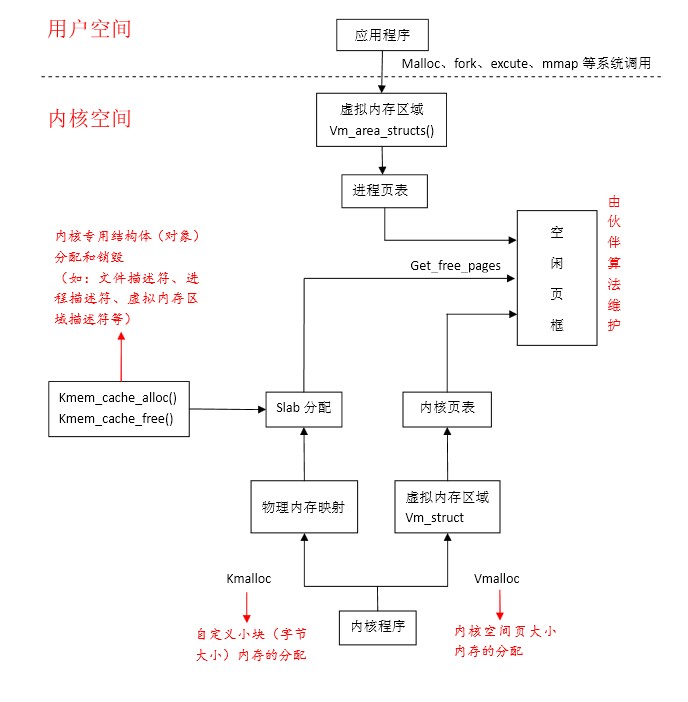
这个图示内核用户空间的划分,图中最重要的就是高端内存的映射
其中kmalloc和vmalloc函数申请的空间对应着不同的区域,同时又不同的含义。
三、物理内存分配图
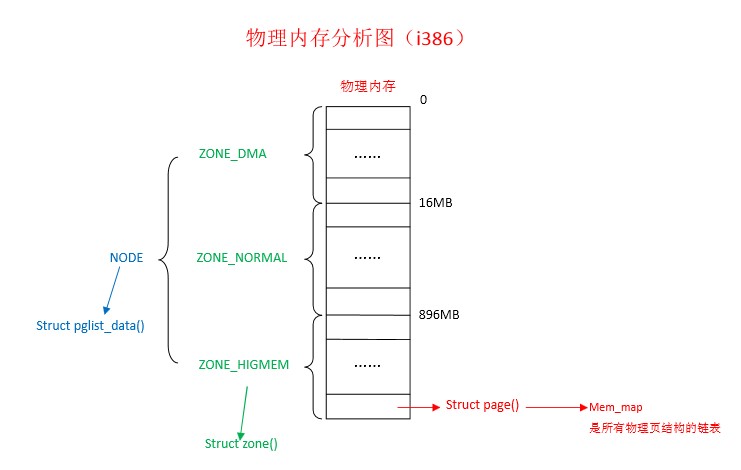
这张图中页解释了三者的不同关系,和上篇文章中的内容有相似之处。
伙伴算法:
一种物理内存分配和回收的方法,物理内存所有空闲页都记录在BUDDY链表中。首选,系统建立一个链表,链表中的每个元素代表一类大小的物理内存,分别为2的0次方、1次方、2次方,个页大小,对应4K、8K、16K的内存,没一类大小的内存又有一个链表,表示目前可以分配的物理内存。例如现在仅存需要分配8K的物理内存,系统首先从8K那个链表中查询有无可分配的内存,若有直接分配;否则查找16K大小的链表,若有,首先将16K一分为二,将其中一个分配给进程,另一个插入8K的链表中,若无,继续查找32K,若有,首先把32K一分为二,其中一个16K大小的内存插入16K链表中,然后另一个16K继续一分为二,将其中一个插入8K的链表中,另一个分配给进程........以此类推。当内存释放时,查看相邻内存有无空闲,若存在两个联系的8K的空闲内存,直接合并成一个16K的内存,插入16K链表中。(伙伴算法用于物理内存分配方案)
SLAB算法:
是一种对伙伴算的一种补充,对于用户进程的内存分配,伙伴算法已经够好了,但对于内核进程,还需要存在一类很小的数据(字节大小,比如进程描述符、虚拟内存描述符等),若每次给几个字节的数据分配一个4KB的页,实在太浪费,于是就有了SLBA算法,SLAB算法其实就是把一个页用力劈成一小块一小块,然后再分配。
linux内存管理--用户空间和内核空间_用户空间和内存空间的关系-CSDN博客

在阅读Linux2.6的内核内存管理这一部分时,我看到page结构中的一个mapping成员,我感到很迷惑,这个成员的属性太复杂了,我们来看看:
struct address_space *mapping;表示该页所在地址空间描述结构指针,用于内容为文件的页帧
(1) 如果page->mapping等于0,说明该页属于交换告诉缓存swap cache
(2) 如果page->mapping不等于0,但第0位为0,说明该页为匿名也,此时mapping指向一个struct anon_vma结构变量;
(3) 如果page->mapping不等于0,但第0位不为0,则apping指向一个struct address_space地址空间结构变量;
这成员也太麻烦了吧,下面我先看看struct address_space是啥东东:
看linux内核很容易被struct address_space 这个结构迷惑,它是代表某个地址空间吗?实际上不是的,它是用于管理文件(struct inode)映射到内存的页面(struct page)的,其实就是每个file都有这么一个结构,将文件系统中这个file对应的数据与这个file对应的内存绑定到一起;与之对应,address_space_operations 就是用来操作该文件映射到内存的页面,比如把内存中的修改写回文件、从文件中读入数据到页面缓冲等。file结构体和inode结构体中都有一个address_space结构体指针,实际上,file->f_mapping是从对应inode->i_mapping而来,inode->i_mapping->a_ops是由对应的文件系统类型在生成这个inode时赋予的。
也就是说address_space结构与文件的对应:一个具体的文件在打开后,内核会在内存中为之建立一个struct inode结构(该inode结构也会在对应的file结构体中引用),其中的i_mapping域指向一个address_space结构。这样,一个文件就对应一个address_space结构,一个 address_space与一个偏移量能够确定一个page cache 或swap cache中的一个页面。因此,当要寻址某个数据时,很容易根据给定的文件及数据在文件内的偏移量而找到相应的页面。看下这张图我们就很了解了:
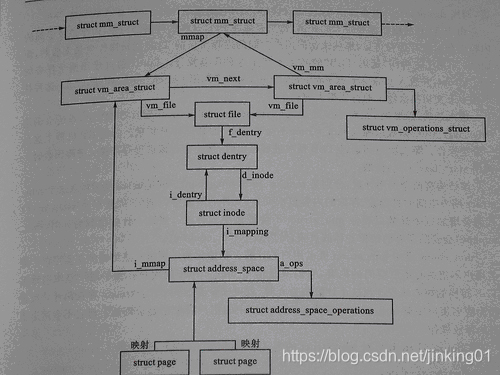
下面先看下address_space结构定义:
-
struct address_space {
-
-
struct inode *host; /* owner: inode, block_device拥有它的节点 */
-
struct radix_tree_root page_tree;/* radix tree of all pages包含全部页面的radix树 */
-
rwlock_t tree_lock; /* and rwlock protecting it保护page_tree的自旋锁 */
-
unsigned int i_mmap_writable;/* count VM_SHARED mappings共享映射数 VM_SHARED记数*/
-
struct prio_tree_root i_mmap; /* tree of private and shared mappings 优先搜索树的树根*/
-
struct list_head i_mmap_nonlinear;/*list VM_NONLINEAR mappings 非线性映射的链表头*/
-
spinlock_t i_mmap_lock; /* protect tree, count, list 保护i_mmap的自旋锁*/
-
unsigned int truncate_count; /* Cover race condition with truncate 将文件截断的记数*/
-
unsigned long nrpages; /* number of total pages 页总数*/
-
pgoff_t writeback_index;/* writeback starts here 回写的起始偏移*/
-
struct address_space_operations *a_ops; /* methods 操作函数表*/
-
unsigned long flags; /* error bits/gfp mask ,gfp_mask掩码与错误标识 */
-
struct backing_dev_info *backing_dev_info; /* device readahead, etc预读信息 */
-
spinlock_t private_lock; /* for use by the address_space 私有address_space锁*/
-
struct list_head private_list; /* ditto 私有address_space链表*/
-
struct address_space *assoc_mapping; /* ditto 相关的缓冲*/
-
} __attribute__((aligned(sizeof(long))));
了解了struct address_space这个东东,我们就知道“一个 address_space与一个偏移量能够确定一个page cache 或swap cache中的一个页面”,那么page cache和swap cache又是什么东东呢?
page cache是与文件映射对应的,而swap cache是与匿名页对应的。如果一个内存页面不是文件映射,则在换入换出的时候加入到swap cache,如果是文件映射,则不需要交换缓冲。
这两个的相同点就是它们都是address_space,都有相对应的文件操作:一个被访问的文件的物理页面都驻留在page cache或swap cache中,一个页面的所有信息由struct page来描述。struct page中有一个域为指针mapping ,它指向一个struct address_space类型结构。page cache或swap cache中的所有页面就是根据address_space结构以及一个偏移量来区分的。而在这里我可以负责任的告诉大家这个偏移量就是进程线性空间中某个线性地址对应的二级描述符(注意:我这里说的是以SEP4020这个arm结构为例的,它只有二级映射,另外这个二级描述符也是Linux版的,而不是硬件版的描述符)。
一般情况下用户进程调用mmap()时,只是在进程空间内新增了一块相应大小的缓冲区,并设置了相应的访问标识,但并没有建立进程空间到物理页面的映射。因此,第一次访问该空间时,会引发一个缺页异常。对于共享内存映射情况,缺页异常处理程序首先在swap cache中寻找目标页(符合address_space以及偏移量的物理页),如果找到,则直接返回地址;如果没有找到,则判断该页是否在交换区 (swap area),如果在,则执行一个换入操作;如果上述两种情况都不满足,处理程序将分配新的物理页面,并把它插入到page cache中。进程最终将更新进程页表。注:对于映射普通文件情况(非共享映射),缺页异常处理程序首先会在page cache中根据address_space以及数据偏移量寻找相应的页面。如果没有找到,则说明文件数据还没有读入内存,处理程序会从磁盘读入相应的页面,并返回相应地址,同时,进程页表也会更新。
当将页面交换到交换文件中时,Linux总是避免页面写,除非必须这样做。当页面已经被交换出内存但是当有进程再次访问时又要将它重新调入内存。只要页面在内存中没有被写过,则交换文件中的拷贝是有效的。
Linux使用swap cache来跟踪这些页面。这个swap cache是一个页表入口链表,每个对应于系统中的物理页面。这是一个对应于交换出页面的页表入口并且描叙页面放置在哪个交换文件中以及在交换文件中的位置。如果swap cache入口为非0值,则表示在交换文件中的这一页没有被修改。如果此页被修改(或者写入)。 则其入口从swap cache中删除。
当Linux需要将一个物理页面交换到交换文件(文件类型之一)时,它将检查swap cache,如果对应此页面存在有效入口,则不必将这个页面写到交换文件中。这是因为自从上次从交换文件中将其读出来,内存中的这个页面还没有被修改。
swap cache中的入口是已换出页面的页表入口。它们虽被标记为无效但是为Linux提供了页面在哪个交换文件中以及文件中的位置等信息。
保存在交换文件中的dirty页 面可能被再次使用到,例如,当应用程序向包含在已交换出物理页面上的虚拟内存区域写入时。对不在物理内存中的虚拟内存页面的访问将引发页面错误。由于处理 器不能将此虚拟地址转换成物理地址,处理器将通知操作系统。由于已被交换出去,此时描叙此页面的页表入口被标记成无效。处理器不能处理这种虚拟地址到物理 地址的转换,所以它将控制传递给操作系统,同时通知操作系统页面错误的地址与原因。这些信息的格式以及处理器如何将控制传递给操作系统与具体硬件有关。
处理器相关页面错误处理代码将定位描叙包含出错虚拟地址对应的虚拟内存区域的vm_area_struct数据结构。它通过在此进程的vm_area_struct中查找包含出错虚拟地址的位置直到找到为止。这些代码与时间关系重大,进程的vm_area_struct数据结构特意安排成使查找操作时间更少。
执行完这些处理器相关操作并且找到出错虚拟地址的有效内存区域后,页面错处理过程其余部分和前面类似。
通用页面错处理代码为出错虚拟地址寻找页表入口。如果找到的页表入口是一个已换出页面,Linux必须将其交换进入物理内存。已换出页面的页表入口的格式与处理器类型有关,但是所有的处理器将这些页面标记成无效并把定位此页面的必要信息放入页表入口中。Linux利用这些信息以便将页面交换进物理入内存。
此时Linux知道出错虚拟内存地址并且拥有一个包含页面位置信息的页表入口。vm_area_struct数据结构可能包含将此虚拟内存区域交换到物理内存中的子程序:swapin。如果对此虚拟内存区域存在swapin则Linux会使用它。这是已换出系统V共享内存页面的处理过程-因为已换出系统V共享页面和普通的已换出页面有少许不同。如果没有swapin操作,这可能是Linux假定普通页面无须特殊处理。
系统将分配物理页面并将已换出页面读入。关于页面在交换文件中位置信息从页表入口中取出。如果引起页面错误的访问不是写操作则页面被保留在swap cache中并且它的页表入口不再标记为可写。如果页面随后被写入,则将产生另一个页面错误,这时页面被标记为dirty,同时其入口从swap cache中删除。如果页面没有被写并且被要求重新换出,Linux可以免除这次写,因为页面已经存在于交换文件中。
如果引起页面从交换文件中读出的操作是写操作,这个页面将被从swap cache中删除并且其页表入口被标记成dirty且可写。
说到page cache我们很容易就与buffer cache混淆,
在这里我需要说的是page cache是VFS的一部分,buffer cache是块设备驱动的一部分,或者说page cache是面向用户IO的cache,buffer cache是面向块设备IO的cache,page cache按照文件的逻辑页进行缓冲,buffer cache按照文件的物理块进行缓冲。page cache与buffer cache并不相互独立而是相互融合的,同一文件的cache页即可存在于page cache中,又可存在于buffer cache中,它们在物理内存中只有一份拷贝。文件系统接口就处于page cache和buffer cache之间,它完成page cache的逻辑页与buffer cache的物理块之间的相互转换,再交给统一的块设备IO进行调度处理,文件的逻辑块与物理块的关系就表现为page cache与buffer cache的关系。
Page cache实际上是针对文件系统的,是文件的缓存,在文件层面上的数据会缓存到page cache。文件的逻辑层需要映射到实际的物理磁盘,这种映射关系由文件系统来完成。当page cache的数据需要刷新时,page cache中的数据交给buffer cache,但是这种处理在2.6版本的内核之后就变的很简单了,没有真正意义上的cache操作。
Buffer cache是针对磁盘块的缓存,也就是在没有文件系统的情况下,直接对磁盘进行操作的数据会缓存到buffer cache中,例如,文件系统的元数据都会缓存到buffer cache中。
简单说来,page cache用来缓存文件数据,buffer cache用来缓存磁盘数据。在有文件系统的情况下,对文件操作,那么数据会缓存到page cache,如果直接采用dd等工具对磁盘进行读写,那么数据会缓存到buffer cache。
linux内核中的address_space 结构解析_linux kernel address_space_operations readahead-CSDN博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号