最新java框架有哪些
介绍
在当前软件开发的领域中,Java依然是主流语言之一。Java的流行得益于其广泛应用的领域和强大的生态系统。在Java生态系统中,不断涌现着各种新的框架,这些框架提供了更加高效、安全和灵活的开发方式。下面将为大家介绍Java框架。
Spring Boot
Spring Boot是由Spring框架派生而来的开发框架。它通过自动化配置的方式,让Java可以更加轻松、高效地构建独立的、生产级别的Spring应用程序。Spring Boot不需要编写复杂的配置文件,而是通过默认值和相应的约定来工作。这个框架可以非常快速地构建一个Web应用程序,并按照实践进行开发。Spring Boot还支持各种数据存储和消息队列系统,例如Hadoop、Redis、RabbitMQ等,这让工程师可以更容易地构建复杂的微服务。
Vert.x
Vert.x是一款高性能的、分布式的应用程序开发框架。它由纯Java写成,提供了一套完备的异步API,可以构建高扩展性的网络应用程序,支持多种语言(如Java、Groovy、Kotlin、Scala等)。
Vert.x基于事件驱动体系架构(EDA)构建,可以在单线程内完成成千上万的并发请求处理。它还提供了广泛的编程语言支持,包括Java、JavaScript、Ruby、Python和C。Vert.x还提供了一个扩展点机制,可以增强框架的功能,例如:提供编写Web应用程序、WebSocket、TCP、UDP、JDBC和MongoDB等的支持。
Quarkus
Quarkus 是一个 Kubernetes Native Java 框架,可以构建轻量级Java应用程序。Quarkus基于Eclipse Vert.x和Hibernate等开源项目,提供了RESTful API的支持、JPA、Hibernate 基础设施、JAX-RS、自动化Swagger文档生成。它使用GraalVM 技术,可以在少量的内存中以非常快的速度运行,这让 Quarkus成为低内存、低延时、高度可扩展的微服务架构的选择。
Quarkus与Spring Boot比较
尽管Quarkus和Spring Boot两者都是Java开发框架,但是他们不同的设计理念和技术架构很大程度上影响了他们的特性和应用场景。
,Spring Boot适用于中等大小和较大的应用程序,而Quarkus适用于轻量级应用程序和云时代。如果您正在构建一个较大的Web应用程序并需要使用JPA、Hibernate等等,您可能需要倾向于使用Spring Boot;但如果您正在构建一个轻量级的Micro Server,那么你可能需要考虑 Quarkus。
其次,Quarkus的特性更简单,适用于云架构。它具有轻量级、快速部署的特性,可以容易地构建和部署Kubernetes原生应用程序。Quarkus内置了超过50个扩展,对Java应用程序的各种需求提供了支持,并且可以使用GraalVM构建Oracle或OpenJDK运行时的本地镜像。这非常适合微服务和无服务器架构,并且为这些框架提供了额外的无缝集成。
结语
Java生态系统中一直都有很多很棒的开发框架,而这些框架也在不断地演变和新生,让我们可以更加快速、高效、安全地构建各种应用程序。而的Java框架则更加贴近云时代的应用程序构建。你可以根据自己的需求选择适合的框架。
Overview
Impala raises the bar for SQL query performance on Apache Hadoop while retaining a familiar user experience. With Impala, you can query data, whether stored in HDFS or Apache HBase – including SELECT, JOIN, and aggregate functions – in real time. Furthermore, Impala uses the same metadata, SQL syntax (Hive SQL), ODBC driver, and user interface (Hue Beeswax) as Apache Hive, providing a familiar and unified platform for batch-oriented or real-time queries. (For that reason, Hive users can utilize Impala with little setup overhead.)
Architecture
To avoid latency, Impala circumvents MapReduce to directly access the data through a specialized distributed query engine that is very similar to those found in commercial parallel RDBMSs. The result is order-of-magnitude faster performance than Hive, depending on the type of query and configuration.
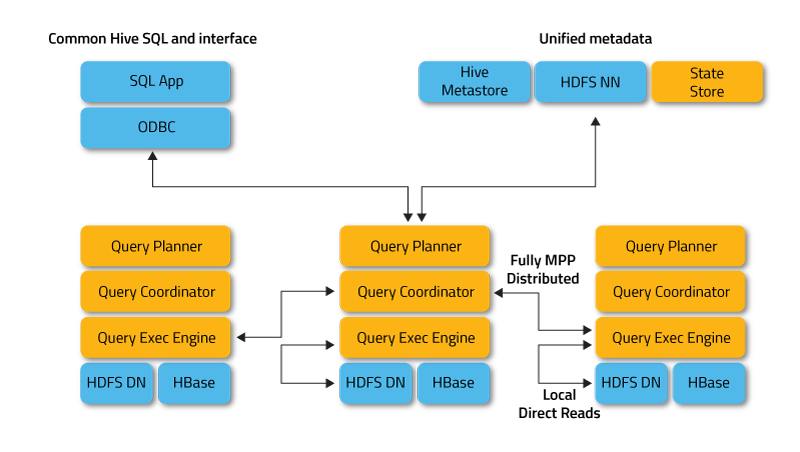
There are many advantages to this approach over alternative approaches for querying Hadoop data, including::
- Thanks to local processing on data nodes, network bottlenecks are avoided.
- A single, open, and unified metadata store can be utilized.
- Costly data format conversion is unnecessary and thus no overhead is incurred.
- All data is immediately query-able, with no delays for ETL.
- All hardware is utilized for Impala queries as well as for MapReduce.
- Only a single machine pool is needed to scale.
We encourage you to read "Impala: A Modern, Open-Source SQL Engine for Hadoop" for details about Impala's architecture.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号