
X86处理器汇编技术系列4
第23部分- Linux x86 64位汇编 字符串存储加载
除了字符串从一个内存位置传送到另一个内存位置外,还有用于把内存中的字符串值加载到寄存器以及传会至内存位置中的指令。
lods
lods指令把内存中的字符串值传送到EAX寄存器中。
有多种格式:lodsb, lodsw, lodsl,lodsq
使用ESI寄存器作为隐藏的源操作数。
stos
STOS指令可以把EAX寄存器中的数据存放到一个内存位置中。
有STOSB,STOSW,STOSL,STOSQ。
使用EDI寄存器作为隐含的目标操作数。
加载示例
-
.extern printf ;//调用外部的printf函数
-
.section .data
-
space:
-
.ascii "h"
-
oa:
-
.byte 0x0a
-
end:
-
.byte 0
-
.section .bss
-
.lcomm stobuffer, 256
-
.section .text
-
.globl _start
-
_start:
-
nop
-
leal space, %esi
-
leal stobuffer, %edi
-
movl $255, %ecx
-
cld
-
lodsb
-
rep stosb
-
-
leal oa, %esi
-
lodsb
-
stosb
-
leal end, %esi
-
lodsb
-
lodsb
-
-
movq $stobuffer,%rdi
-
call printf
-
-
movq $60,%rax
-
syscall
as -g -o stostest.o stostest.s
ld -o stostest stostest.o -lc -I /lib64/ld-linux-x86-64.so.2
在这里打印的时候,需要注意的是由于引入了printf函数,该函数指向的buffer的指针是48位地址的bss地址,不是32位的。
第24部分- Linux x86 64位汇编 字符串比较
比较字符串可以使用CMPS指令系列。
CMPSB,CMPSW,CMPSL,CMPSQ。
隐含的源和目标操作数的位置同样存储在ESI和EDI寄存器中。每次执行CMPS指令时,根据DF标志的设置。
CMPS指令从源字符串中减去目标字符串,并且适当地设置EFLAGS寄存器的进位、符号、溢出、零、奇偶校验和辅助进位。使用之后可以使用跳转指令跳转到分支。
REP指令也可以用于跨越多个字节重复进行字符串比较。由于REP指令不在两个重复的过程之间检查标志的状态,需要REPE,REPNE,REPZ,REPNZ,这些指令在每次重复过程中检查零标志,如果零标志被设置就停止重复。遇到不匹配的字符对,REP指令就会停止重复。
最常用于比较字符串的方法称为词典式顺序,按照字典对此进行排序。
- 按字母表顺序,较低的字母小于较高的字母
- 大写字母小于小写字母
对于长短 不一的字符串,当短字符串等于长字符串中相同数量的字符,那么长字符串就大于短字符串。例如:test小于test1
比较示例
-
.extern printf ;//调用外部的printf函数
-
.section .data
-
string1:
-
.ascii "test1"
-
length1:
-
.int 5
-
string2:
-
.ascii "test1"
-
length2:
-
.int 5
-
big:
-
.ascii "big"
-
.byte 0x0a,0x00
-
-
small:
-
.ascii "small"
-
.byte 0x0a,0x00
-
-
equ:
-
.ascii "equal"
-
.byte 0x0a,0x00
-
-
.section .text
-
.globl _start
-
_start:
-
nop
-
lea string1, %esi
-
lea string2, %edi
-
movl length1, %ecx
-
movl length2, %eax
-
cmpl %eax, %ecx;//比较两个字符串长度,短的加载到寄存器,供REPE使用
-
ja longer;//如果字符串2长跳转到longer,不用交换
-
xchg %ecx, %eax;//否则,进行交换
-
longer:
-
cld
-
repe cmpsb
-
je equal;//最小长度下都相等,需要比较字符串长度。
-
jg greater
-
-
less:
-
movq $small,%rdi
-
call printf
-
movq $60,%rax
-
syscall
-
-
greater:
-
movq $big,%rdi
-
call printf
-
movq $60,%rax
-
syscall
-
-
equal:;// 比较字符串长度。
-
movl length1, %ecx
-
movl length2, %eax
-
cmpl %ecx, %eax
-
jg greater
-
jl less
-
movq $equ,%rdi
-
call printf
-
-
movq $60,%rax
-
syscall
as -g -o strcomp.o strcomp.s
ld -o strcomp strcomp.o -lc -I /lib64/ld-linux-x86-64.so.2
第25部分- Linux x86 64位汇编 字符串扫描
扫描字符串可以使用SCAS指令。提供了扫描字符串搜索特定的一个字符或者一组字符。
SCAS指令系统包含:SCASB,SCASW,SCASL,SCASQ
使用EDI寄存器作为隐含的目标操作数。EDI寄存器必须包含要扫描的字符串的内存地址。递增和递减取决于DF标志。
比较时,会相应的设置EFLAGS的辅助进位,进位,奇偶校验,溢出、符号和零标志。把EDI寄存器当前指向的字符和AL寄存器的字符进行比较,和CMPS指令类似。和REPE和REPNE前缀一起,才显得方便。REPE和REPNE常常用于找到搜索字符时停止扫描。
扫描字符串示例
-
.extern printf ;//调用外部的printf函数
-
.section .data
-
string1:
-
.ascii "This is a test - a long text string to scan."
-
length:
-
.int 44
-
string2:
-
.ascii "-"
-
noresult:
-
.ascii "No result."
-
.byte 0x0a,0x0
-
yesresult:
-
.ascii "Yes have result."
-
.byte 0x0a,0x0
-
.section .text
-
.globl _start
-
_start:
-
nop
-
leal string1, %edi
-
leal string2, %esi
-
movl length, %ecx
-
lodsb;//加载第一个-到al寄存器
-
cld
-
repne scasb;//扫描字符串string1,知道找到-字符。
-
jne notfound
-
movq $yesresult,%rdi
-
call printf
-
-
movq $60,%rax
-
syscall
-
notfound:
-
movq $noresult,%rdi
-
call printf
-
-
movq $60,%rax
-
syscall
as -g -o scastest.o scastest.s
ld -o scastest scastest.o -lc -I /lib64/ld-linux-x86-64.so.2
搜索字符示例
Scasw和scasl可以用于搜索2个或4个字符,查找AX或者EAX寄存器中的字符序列。
-
.extern printf ;//调用外部的printf函数
-
.section .data
-
string1:
-
.ascii "This is a test - a long text string to scan."
-
length:
-
.int 11
-
string2:
-
.ascii "test"
-
noresult:
-
.ascii "No result."
-
.byte 0x0a,0x0
-
yesresult:
-
.ascii "Yes have result."
-
.byte 0x0a,0x0
-
-
.section .text
-
.globl _start
-
_start:
-
nop
-
leal string1, %edi
-
leal string2, %esi
-
movl length, %ecx
-
lodsl;//加载test到eax寄存器
-
cld
-
repne scasl;//进行比较知道找到位置
-
jne notfound
-
subw length, %cx
-
neg %cx
-
-
movq $yesresult,%rdi
-
call printf
-
-
movq $60,%rax
-
syscall
-
-
notfound:
-
movq $noresult,%rdi
-
call printf
-
-
movq $60,%rax
-
syscall
as -g -o scastest.o scastest2.s
ld -o scastest scastest.o -lc -I /lib64/ld-linux-x86-64.so.2
这里没找到test,是因为11次对比的方式是这样的,一次4个字节,打乱了原先的test。
![]()
将test改成其他图中的4个字符就可以找到了。
计算字符串长度示例
SCAS指令有一个功能是确定零结尾(也称为空结尾)的字符串长度。
搜索零的位置,找到后就可以会到总共搜索了多少个字符,也就是字符的长度。
-
.extern printf ;//调用外部的printf函数
-
.section .data
-
string1:
-
.asciz "Testing, one, two, three, testing.\n"
-
-
noresult:
-
.ascii "No Result."
-
.byte 0x0a,0x0
-
yesresult:
-
.ascii "Yes have result : %d."
-
.byte 0x0a,0x0
-
-
.section .text
-
.globl _start
-
_start:
-
nop
-
leal string1, %edi
-
movl $0xffff, %ecx;//假设字符串长65535
-
movb $0, %al
-
cld
-
repne scasb
-
jne notfound
-
subw $0xffff, %cx;//减去初始值,变成了负值
-
neg %cx;//取反就是正数了
-
dec %cx;//去掉最后一个空符号,就是字符串长度了。
-
-
movq $yesresult,%rdi
-
movq %rcx,%rsi
-
call printf
-
-
movq $60,%rax
-
syscall
-
-
notfound:
-
movq $noresult,%rdi
-
call printf
-
-
movq $60,%rax
-
syscall
as -g -o strsize.o strsize.s
ld -o strsize strsize.o -lc -I /lib64/ld-linux-x86-64.so.2
第26部分- Linux x86 64位汇编 字符串操作反转实例
有了上面几个深入的语法知识后,我们继续来学习一个例子。
我们出两个版本的例子,实现字符串的反转效果。
AT&T汇编实现
将上诉的Intel汇编程序,我们改写成AT&T语法后汇编如下,这里将原来的mov rdi, $ + 15地方进行的修改,变成jmp命令了,jmp过去jmp回来,就不用涉及到栈中的函数地址了。
因为NASM 提供特殊的变量($ 和 $$ 变量)来操作位置计数器。在 GAS 中,无法操作位置计数器,必须使用标签计算下一个存储位置(数据、指令等等)。
-
.section .data
-
.equ SYS_WRITE,1
-
.equ STD_OUT,1
-
.equ SYS_EXIT,60
-
.equ EXIT_CODE,0
-
.equ NEW_LINE,0xa
-
INPUT: .ascii " Hello world!\n"
-
.section .bss;;//定义buffer缓存
-
.lcomm OUTPUT,12
-
.global _start
-
.section .text
-
_start:
-
movq $INPUT ,%rsi;//将字符串地址赋值为rsi
-
xor %rcx, %rcx;//清零
-
cld;//清空df标志位0
-
-
jmp calculateStrLength;//调用函数计算字符串长度
-
reversePre:
-
xor %rax, %rax;//清空rax
-
xor %rdi, %rdi;//清空rdi
-
jmp reverseStr;//跳转到reverseStr函数进行翻转
-
-
calculateStrLength:;//计算INPUT字符串的长度,并保存在rcx中。
-
cmpb $0 ,(%rsi);//与0对比,字符串最后一个’\0’字符串结束标志
-
je exitFromRoutine;//函数结束
-
lodsb;//从rds:rsi处加载一个字节到al,并增加rsi
-
pushq %rax;/将刚获取到的al进行压栈,不过这会破坏了原本返回地址的位置。返回使用通过push rdi来解决。
-
inc %rcx;//增加计数器
-
jmp calculateStrLength;//循环
-
exitFromRoutine:;//返回到_start主线。
-
pushq %rdi;//压栈return地址到栈中
-
-
jmp reversePre;
-
reverseStr:
-
cmpq $0,%rcx;//对比0,rcx已保存的是字符串的长度
-
je printResult;//相等则跳转到printResult
-
popq %rax;//从栈中弹出一个字符给rax
-
movq %rax,OUTPUT(%rdi);//写到[OUTPUT+rdi]对应的地址
-
dec %rcx;//写一个少一个
-
inc %rdi;//写一个地址加一个
-
jmp reverseStr;//返回循环
-
printResult:
-
mov %rdi, %rdx;//输出的长度赋值到rdx
-
mov $SYS_WRITE,%rax;//调用号
-
mov $STD_OUT, %rdi;//输出句柄
-
mov $OUTPUT, %rsi;//输出字符串地址
-
syscall;//调用sys_write输出OUTPUT保存的反向字符串。
-
jmp printNewLine;//调用函数输出换行符
-
-
printNewLine:
-
mov $SYS_WRITE, %rax;//调用号
-
mov $STD_OUT, %rdi;//输出句柄
-
mov $NEW_LINE, %rsi;//输出字符串地址
-
mov $1,%rdx;//输出的长度赋值到rdx
-
syscall
-
jmp exit
-
-
exit:
-
mov $SYS_EXIT ,%rax
-
mov $EXIT_CODE ,%rdi
-
syscall
编译:
as -g -o reverse_att.o reverse_att.s
ld -o reverse_att reverse_att.o
Intel汇编实现
-
section .data
-
SYS_WRITE equ 1
-
STD_OUT equ 1
-
SYS_EXIT equ 60
-
EXIT_CODE equ 0
-
-
NEW_LINE db 0xa
-
INPUT db "Hello world!"
-
section .bss;;//定义buffer缓存
-
OUTPUT resb 12
-
global _start
-
section .text
-
_start:
-
mov rsi, INPUT;//将字符串地址赋值为rsi
-
xor rcx, rcx;//清零
-
cld;//清空df标志位0
-
mov rdi, $ + 15;//预处理rdi寄存器,在calculateStrLength函数中会用到。$是表示当前指令的地址。$$是当前段的地址。通过$+15可以计算得到命令xor rax,rax这条指令的地址(可以通过objdump -D命令来数出来),将该地址赋值给rdi进行了保存。在calculateStrLength函数中可以直接获取rdi地址来返回到xor rax,rax命令。
-
call calculateStrLength;//调用函数计算字符串长度
-
xor rax, rax;//清空rax
-
xor rdi, rdi;//清空rdi
-
jmp reverseStr;//跳转到reverseStr函数进行翻转
-
-
calculateStrLength:;//计算INPUT字符串的长度,并保存在rcx中。
-
cmp byte [rsi], 0;//与0对比,字符串最后一个’\0’字符串结束标志
-
je exitFromRoutine;//函数结束
-
lodsb;//从rds:rsi处加载一个字节到al,并增加rsi
-
push rax;/将刚获取到的al进行压栈,不过这会破坏了原本返回地址的位置。返回使用通过push rdi来解决。
-
inc rcx;//增加计数器
-
jmp calculateStrLength;//循环
-
exitFromRoutine:;//返回到_start主线。
-
push rdi;//压栈return地址到栈中
-
ret
-
reverseStr:
-
cmp rcx, 0;//对比0,rcx已保存的是字符串的长度
-
je printResult;//相等则跳转到printResult
-
pop rax;//从栈中弹出一个字符给rax
-
mov [OUTPUT + rdi], rax;写到[OUTPUT+rdi]对应的地址
-
dec rcx;//写一个少一个
-
inc rdi;//写一个地址加一个
-
jmp reverseStr;//返回循环
-
-
printResult:
-
mov rdx, rdi;//输出的长度赋值到rdx
-
mov rax, SYS_WRITE;//调用号
-
mov rdi, STD_OUT;//输出句柄
-
mov rsi, OUTPUT;//输出字符串地址
-
syscall;//调用sys_write输出OUTPUT保存的反向字符串。
-
jmp printNewLine;//调用函数输出换行符
-
-
printNewLine:
-
mov rax, SYS_WRITE;//调用号
-
mov rdi, STD_OUT;//输出句柄
-
mov rsi, NEW_LINE;//输出字符串地址
-
mov rdx, 1;//输出的长度赋值到rdx
-
syscall
-
jmp exit
-
-
exit:
-
mov rax, SYS_EXIT
-
mov rdi, EXIT_CODE
-
syscall
编译和链接:
nasm -g -f elf64 -o reverse.o reverse.asm
ld -o reverse reverse.o
执行后输出如下:
# ./reverse
!dlrow olleH
第27部分- Linux x86 64位汇编 寄存器
64位时候X86处理器的寄存器如下图:

《Computer Systems A Programmer's Perspective, 3rd Edition》文件中有这图。re
64和32位的差异是:
- 64位有16个寄存器,32位只有8个。但是32位前8个都有不同的命名,分别是e开头,而64位前8个使用了r代替e。e开头的寄存器命名依然可以直接运用于相应寄存器的低32位。而剩下的寄存器名则是从r8 - r15,其低位分别用d,w,b指定长度。
- 32位使用栈帧来作为传递的参数的保存位置,而64位使用寄存器,分别用rdi,rsi,rdx,rcx,r8,r9作为第1-6个参数。rax作为返回值
- 64位没有栈帧的指针,32位用ebp作为栈帧指针,64位取消了这个设定,rbp作为通用寄存器使用
- 64位支持一些形式的以PC相关的寻址,而32位只有在jmp的时候才会用到这种寻址方式。
第28部分- Linux x86 64位汇编 宏定义和函数
在前面的例子移植中,我们知道NASM 使用 resb、resw 和 resd 关键字在 BSS 部分中分配字节、字和双字空间。GAS 使用 .lcomm 关键字分配字节级空间。
Gas汇编器宏
Linux 平台的标准汇编器是 GAS。
GAS 提供 .macro 和 .endm 指令来创建宏。.macro 指令后面跟着宏名称,后面可以有参数,也可以没有参数。宏参数是按名称指定的。
-
.macro write_string p1,p2
-
movq $1,%rax;//调用号sys_write
-
movq $1,%rdi;//输出到stdout
-
movq \p1,%rsi;//字符串地址
-
movq \p2,%rdx;//字符串长度
-
syscall
-
.endm
-
-
.section .data
-
msg1: .ascii "Hello,programmers!\n"
-
len1: .quad len1-msg1
-
-
msg2: .asciz "Welcome to the world of,\n"
-
len2: .quad len2-msg2
-
-
msg3: .asciz "Linux assembly programming!\n"
-
len3: .quad len3-msg3
-
-
.section .text
-
.global _start
-
_start:
-
write_string $msg1,len1;//第一个参数是字符串地址,第二个参数是字符串长度不是其地址。
-
write_string $msg2,len2
-
write_string $msg3,len3
-
-
movq $1,%rax ;//系统调用号(sys_exit)
-
int $0x80 ;//调用内核
编译:
as -g -o macro_att.o macro_att.s
ld -o macro_att macro_att.o
Gas数据结构
数据结构如下:
-
.extern printf ;//调用外部的printf函数
-
.section .data
-
fmt: .ascii "name = %s, high = %ld \n"
-
-
.set name_size,20
-
.set high_size,4
-
-
people:
-
name: .space name_size
-
high: .space high_size
-
-
xiaoming:
-
xm_name: .ascii "xiaoming"
-
xm_null: .byte 0
-
xm_high: .quad 0xaf
-
-
.section .text
-
.global _start
-
_start:
-
movq $fmt, %rdi
-
movq $xm_name,%rsi
-
movq xm_high, %rdx
-
movq $0, %rax
-
call printf
-
-
movq $60, %rax
-
syscall
as -g -o struc_att.o struc_att.s
ld -o struc_att struc_att.o -lc -I /lib64/ld-linux-x86-64.so.2
同样gas也可以使用.include来包含其他文件。
Nasm汇编器宏和外部函数
单行宏定义如下:
%define macro_name(parameter) value
可以看到NASM 使用 %begin macro 指令声明宏。
多行宏定义以%macro指令开头,以%endmacro结尾。
|
宏名称后面是一个数字,是宏需要的宏参数数量。在 NASM 中,宏参数是从 1 开始连续编号的。宏的第一个参数是 %1,第二个是 %2,第三个是 %3,以此类推。
例子代码如下:
-
; A macro with two parameters
-
; Implements the write system call
-
%macro write_string 2
-
mov rax, 4
-
mov rbx, 1
-
mov rcx, %1
-
mov rdx, %2
-
int 80h
-
%endmacro
-
-
section .text
-
global _start ;must be declared for using gcc
-
-
_start: ;tell linker entry point
-
write_string msg1, len1
-
write_string msg2, len2
-
write_string msg3, len3
-
-
mov rax,1 ;system call number (sys_exit)
-
int 0x80 ;call kernel
-
-
section .data
-
msg1 db 'Hello, programmers!',0xA,0xD
-
len1 equ $ - msg1
-
-
msg2 db 'Welcome to the world of,', 0xA,0xD
-
len2 equ $- msg2
-
-
msg3 db 'Linux assembly programming! ',0xA,0xD
-
len3 equ $- msg3
nasm -g -f elf64 -o macro.o macro.asm
ld -o macro macro.o
Nasm结构使用
在C语言中可以使用struct声明结构体,而在nasm汇编中,也可以使用结构体,通过使用伪指令来声明结构体。
使用数据结构例子如下,还实现了外部函数的调用:
-
.extern printf ;//调用外部的printf函数
-
.section .data
-
fmt: .ascii "name = %s, high = %ld \n"
-
-
.set name_size,20
-
.set high_size,4
-
-
people:
-
name: .space name_size
-
high: .space high_size
-
-
xiaoming:
-
xm_name: .ascii "xiaoming"
-
xm_null: .byte 0
-
xm_high: .quad 0xaf
-
-
.section .text
-
.global _start
-
_start:
-
movq $fmt, %rdi
-
movq $xm_name,%rsi
-
movq xm_high, %rdx
-
movq $0, %rax
-
call printf
-
-
movq $60, %rax
-
syscall
nasm -g -f elf64 -o struc.o struc.asm
ld -o struc struc.o -lc -I /lib64/ld-linux-x86-64.so.2
也可以使用%include来包含其他汇编文件。
此外,还可以有条件预编译宏如下:
%ifdef _BOOT_DEBUG
org 0100h
%else
org 07c00h
%endif
第29部分-Linux x86 64位汇编 加法指令
adc指令可以执行两个无符号或者带符号整数值的加法,并且把前一个ADD指令产生的进位标志的值包含在其中。为了执行多组多字节的加法操作,可以把多个ADC指令链接在一起。
示例
代码如下:
-
.section .data
-
data1:
-
.quad 11111111,7252051615;//16字节整数
-
data2:
-
.quad 22222222,5732348928;//16字节整数
-
output:
-
.asciz "The result is %qd\n"
-
.section .text
-
.globl _start
-
_start:
-
movq data1, %rbx;//保存data1的前8个字节到ebx
-
movq data1+8, %rax;//保存data1的后8个字节到ebx
-
movq data2, %rdx;//保存data2的前8个字节到ebx
-
movq data2+8, %rcx;//保存data2的后8个字节到ebx
-
addq %rbx, %rdx;//前8个字节相加
-
adcq %rcx, %rax;//后8个字节相加
-
adcq %rdx, %rax;//全部相加
-
movq $output,%rdi
-
movq %rax ,%rsi
-
call printf
-
movq $60,%rax
-
movq $0,%rdi
-
syscall
as -o adctest.o adctest.s
ld -o adctest adctest.o -lc -I /lib64/ld-linux-x86-64.so.2
减法也是类型,减法中有类似adc的功能,是sbb指令。
第30部分-Linux x86 64位汇编 乘法/除法
乘法
无符号整数乘法mul如下,目标操作数总是eax寄存器的某种形式。

使用IMUL可以进行有符号乘法。
在只有一个操作数的情况下,结果保存到指定的目标寄存器EAX或寄存器的某种形式,这个同MUL。
IMUL支持2个操作数。
imul source,destination
IMUL支持3个操作数。
imul multiplier,source,destination
其中multiplier是一个立即值。
乘法实例
-
.section .data
-
output:
-
.asciz "The result is %d, %ld\n"
-
value1:
-
.int 10
-
value2:
-
.int -35
-
value3:
-
.int 400
-
.section .text
-
.globl _start
-
_start:
-
nop
-
movl value1, %ebx;//移动value1到ebx
-
movl value2, %ecx;//移动value2到ecx
-
imull %ebx, %ecx;//将ebx和ecx相乘结果保存到ecx
-
movl value3, %edx;//移动value3到edx
-
imull $2, %edx, %eax;//继续相差
-
movq $output,%rdi
-
movl %ecx ,%esi;//商
-
movl %eax ,%edx;//余数
-
call printf
-
movl $1, %eax
-
movl $0, %ebx
-
int $0x80
as -g -o imultest.o imultest_att.s
ld -o imultest imultest.o -lc -I /lib64/ld-linux-x86-64.so.2
除法
除法也和乘法类似。无符号除法使用div,有符号是idiv。
不过idiv只有一个参数值。
除法操作如下:

除法实例
-
.section .data
-
dividend:
-
.quad 8335
-
divisor:
-
.int 25
-
quotient:
-
.int 0
-
remainder:
-
.int 0
-
output:
-
.asciz "<93>The quotient is %d, and the remainder is %d\n<94>"
-
.section .text
-
.globl _start
-
_start:
-
nop
-
movl dividend, %eax
-
movl dividend+4, %edx
-
divw divisor ;//除数
-
movl %eax, quotient
-
movl %edx, remainder
-
-
movq $output,%rdi
-
movl quotient,%esi;//商
-
movl remainder,%edx;//余数
-
-
call printf
-
movl $1, %eax
-
movl $0, %ebx
-
int $0x80
as -g -o divtest.o divtest.s
ld -o divtest divtest.o -lc -I /lib64/ld-linux-x86-64.so.2
第31部分-Linux x86 64位汇编 移位指令
乘法和除法是处理器上最为耗费时间的两种指令,但是运用移位指令可以提供快速的方法。
移位乘法
为了使整数乘以2的乘方,必须把值向左移位。可以使用两个指令使得整数值向左移位:SAL(向左算术位移)和SHL(向左逻辑位移)。

移位除法
通过移位进行除法操作涉及把二进制值向右移位。
当把整数值向右移位时,必须要注意整数的符号。
无符号整数,向右移位产生的空位可以被填充为零,而且不会有任何问题。
不幸的事,对于带符号整数,使用零填充高位部分会对负数产生有害的影响。
有两个向右移位指令,SHR指令清空移位造成的空位,只能用于对无符号整数进行移位操作。SAR指令根据整数的符号,要么清空,要么设置移位造成的空位。对于负数,空位被设置为1,对于正数,被清空为0.
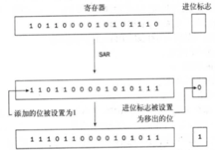
循环移位
循环移位指令执行的功能和移位指令一样,只不过溢出位被存放回值的另一端,而不是被丢弃。

第32部分-Linux x86 64位汇编 数据传输
无符号条件传送指令

无符号条件传送指令依靠进位、零和奇偶校验标志来确定两个操作数之间的区别。
带符号条件传送指令如下:

带符号条件传送指令使用符号和溢出标志表示操作数之间比较的状态。
示例
实例如下,查找数组中一系列整数中最大的一个。
-
.section .data
-
output:
-
.asciz "The largest value is %d\n";//定义字符串
-
values:
-
.int 105, 235, 61, 315, 134, 221, 53, 145, 117, 5;//定义整型
-
.section .text
-
.globl _start
-
_start:
-
nop
-
movl values, %ebx;//ebx保存最大的整数,第一个是105
-
movl $1, %edi;//移动计数
-
loop:
-
movl values(, %edi, 4), %eax;//逐个加载到eax寄存器。
-
cmp %ebx, %eax;//和ebx比较
-
cmova %eax, %ebx;//eax大于ebx,则将eax移动到ebx。
-
inc %edi;//增加edi
-
cmp $10, %edi;//是否已经对比了10个。
-
jne loop
-
movq $output,%rdi
-
movq %rbx,%rsi
-
call printf
-
movq $60,%rax
-
movq $0,%rdi
-
syscall
as -g -o hello.o hello.s
ld -o hello hello.o -lc -I /lib64/ld-linux-x86-64.so.2
第33部分-Linux x86 64位汇编 交换数据-冒泡算法实现
数据交换指令如下:

冒泡排序示例
冒泡排序有两个循环逻辑,内层循环遍历数组,检查相邻的了两个数组值,找出哪个更大。外层循环控制总共执行了多少次内层循环。
使用两个计数器ebx和ecx,ebx是内层循环,ecx是外层循环。
如下:
-
.section .data
-
-
values:
-
.int 105, 235, 61, 315, 134, 221, 53, 145, 117, 5
-
.int 0
-
.section .text
-
.globl _start
-
_start:
-
movl $values, %esi;//数组地址存放于esi
-
movl $9, %ecx;//外层循环次数
-
movl $9, %ebx;//内层循环次数
-
loop:
-
movl (%esi), %eax;//第一个值或当前数值移动给eax
-
cmp %eax, 4(%esi) ;//第一个值或当前数值和下一个值进行比较
-
jge skip;//如果大于等于第二个值则跳转到skip,否则用下面两条命令进行交换,将小的值往后冒泡
-
xchg %eax, 4(%esi)
-
movl %eax, (%esi)
-
skip:
-
add $4, %esi;//继续指向下一个值
-
dec %ebx;//内存循环递减
-
jnz loop
-
dec %ecx;//内存循环结束,外层循环递减
-
jz end;//外层循环结束
-
movl $values, %esi;//内存循环重新开始前重置esi,并设置ecx,ebx。
-
movl %ecx, %ebx
-
jmp loop
-
end:
-
movl $1, %eax
-
movl $0, %ebx
-
int $0x80
as -g -o bubble_att.o bubble_att.s
ld -o bubble_att bubble_att.o -lc -I /lib64/ld-linux-x86-64.so.2
使用gdb进行调试观察:
gdb -q ./bubble_att
在end标记处设置断点:
(gdb)break *end
先显示values标记处的值:
(gdb)x /10d &values
然后启动运行如下:
(gdb)run
最后查看values标记处,可以看到已经排好序。
(gdb)x /10d &values
第34部分-Linux x86 64位汇编 优化
内存优化
编写高性能的汇编语言程序时,最好尽可能地避免内存访问。最快的方式是通过寄存器,但是不可能所有应用程序数据都保存在寄存器中。
对于有数据缓存的处理器来说,内存中按照连续的顺序访问内存能够帮助提高缓存命中率,内存块会一次被读取到缓存中。
目前X86的缓冲块就是cacheline长度是64位,如果数据元素超过64位块必须是要次缓存操作才能获取或者存储内存中的数据元素。
Gas汇编器支持.align命令,用于在特定的内存边界对准定义的数据元素。在数据段中,.align命令紧贴在数据定义的前面,指示汇编器按照内存边界安置数据元素。
优化分支指令
分支指令严重影响应用程序性能,大多数现代处理器利用指令预取缓存提高性能。在程序运行时,指令预取缓存被填充上顺序的指令。
乱序引擎试图尽可能快地执行指令。分支指令对乱序引擎有严重的破坏作用。
编译器创建汇编语言代码时候,猜测if语句的then部分比else部分更可能被执行,试图优化代码的性能。
消除分支,例如在使用cmova前先试用cmp指令。有时候重复几个额外的指令能够消除跳转。
编写可预测分支的代码,把最可能采用的代码安排在向前跳转的顺序执行语句中。
展开循环,一般循环都可以通过向后分支规则预测,但是正确预测分支仍然有性能损失。简单的循环也需要每次迭代时检查计数器,还有必须计算的跳转指令,根据循环内程序逻辑指令的数量,可能开销也很大。对于比较小的循环,展开循环能够解决这个问题,展开循环意味着手动地多次编写每条指令的代码,而不是使用循环返回相同的指令。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号