Spring的JdbcTemplate自动关闭连接
来源:https://blog.csdn.net/partner4java/article/details/7012196
JdbcTemplate类使用DataSource得到一个数据库连接。然后,他调用StatementCreator实例创建要执行的语句。下一步,他调用StatementCallBack完成。
一旦StatementCallBack返回结果,JdbcTemplate类完成所有必要清理工作关闭连接。如果StatementCreator或StatementCallBack抛出异常,JdbcTemplate类会捕获他们,并转换为Spring数据访问异常。

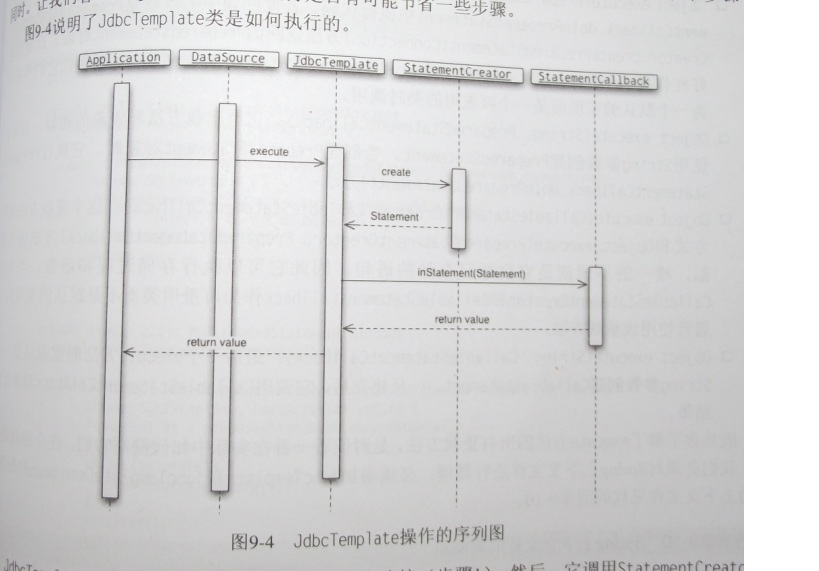
看一个JdbcTemplate里面的比较核心的一个方法:
- //-------------------------------------------------------------------------
- // Methods dealing with prepared statements
- //-------------------------------------------------------------------------
- public Object execute(PreparedStatementCreator psc, PreparedStatementCallback action)
- throws DataAccessException {
- Assert.notNull(psc, "PreparedStatementCreator must not be null");
- Assert.notNull(action, "Callback object must not be null");
- if (logger.isDebugEnabled()) {
- String sql = getSql(psc);
- logger.debug("Executing prepared SQL statement" + (sql != null ? " [" + sql + "]" : ""));
- }
- Connection con = DataSourceUtils.getConnection(getDataSource());
- PreparedStatement ps = null;
- try {
- Connection conToUse = con;
- if (this.nativeJdbcExtractor != null &&
- this.nativeJdbcExtractor.isNativeConnectionNecessaryForNativePreparedStatements()) {
- conToUse = this.nativeJdbcExtractor.getNativeConnection(con);
- }
- ps = psc.createPreparedStatement(conToUse);
- applyStatementSettings(ps);
- PreparedStatement psToUse = ps;
- if (this.nativeJdbcExtractor != null) {
- psToUse = this.nativeJdbcExtractor.getNativePreparedStatement(ps);
- }
- Object result = action.doInPreparedStatement(psToUse);
- handleWarnings(ps);
- return result;
- }
- catch (SQLException ex) {
- // Release Connection early, to avoid potential connection pool deadlock
- // in the case when the exception translator hasn't been initialized yet.
- if (psc instanceof ParameterDisposer) {
- ((ParameterDisposer) psc).cleanupParameters();
- }
- String sql = getSql(psc);
- psc = null;
- JdbcUtils.closeStatement(ps);
- ps = null;
- DataSourceUtils.releaseConnection(con, getDataSource());
- con = null;
- throw getExceptionTranslator().translate("PreparedStatementCallback", sql, ex);
- }
- finally {
- if (psc instanceof ParameterDisposer) {
- ((ParameterDisposer) psc).cleanupParameters();
- }
- JdbcUtils.closeStatement(ps);
- DataSourceUtils.releaseConnection(con, getDataSource());
- }
- }
显然,我们在finally里面看到了关闭调用,在看看这个关闭调用方法内部:
- /**
- * Close the given Connection, obtained from the given DataSource,
- * if it is not managed externally (that is, not bound to the thread).
- * @param con the Connection to close if necessary
- * (if this is <code>null</code>, the call will be ignored)
- * @param dataSource the DataSource that the Connection was obtained from
- * (may be <code>null</code>)
- * @see #getConnection
- */
- public static void releaseConnection(Connection con, DataSource dataSource) {
- try {
- doReleaseConnection(con, dataSource);
- }
- catch (SQLException ex) {
- logger.debug("Could not close JDBC Connection", ex);
- }
- catch (Throwable ex) {
- logger.debug("Unexpected exception on closing JDBC Connection", ex);
- }
- }
- /**
- * Actually close the given Connection, obtained from the given DataSource.
- * Same as {@link #releaseConnection}, but throwing the original SQLException.
- * <p>Directly accessed by {@link TransactionAwareDataSourceProxy}.
- * @param con the Connection to close if necessary
- * (if this is <code>null</code>, the call will be ignored)
- * @param dataSource the DataSource that the Connection was obtained from
- * (may be <code>null</code>)
- * @throws SQLException if thrown by JDBC methods
- * @see #doGetConnection
- */
- public static void doReleaseConnection(Connection con, DataSource dataSource) throws SQLException {
- if (con == null) {
- return;
- }
- if (dataSource != null) {
- ConnectionHolder conHolder = (ConnectionHolder) TransactionSynchronizationManager.getResource(dataSource);
- if (conHolder != null && connectionEquals(conHolder, con)) {
- // It's the transactional Connection: Don't close it.
- conHolder.released();
- return;
- }
- }
- // Leave the Connection open only if the DataSource is our
- // special SmartDataSoruce and it wants the Connection left open.
- if (!(dataSource instanceof SmartDataSource) || ((SmartDataSource) dataSource).shouldClose(con)) {
- logger.debug("Returning JDBC Connection to DataSource");
- con.close();
- }
- }
主要下面这几行代码:
- // Leave the Connection open only if the DataSource is our
- // special SmartDataSoruce and it wants the Connection left open.
- if (!(dataSource instanceof SmartDataSource) || ((SmartDataSource) dataSource).shouldClose(con)) {
- logger.debug("Returning JDBC Connection to DataSource");
- con.close();
- }
哦,可以看到大部分情况下是自动关闭,除非你使用的SmartDataSource,且SmartDataSource指定了允许关闭。
有些时候,你引入了JdbcTemplate或者DaoSupport,但是有时还需要自己额外的拿到conn进行操作,如下:
jdbcTemplate.getDataSource().getConnection()
那么,你应该就需要关闭连接了
druid-1.1.23源码分析——getConnection获取连接_xiaozaq的博客-CSDN博客_getconnectioninternal
动机:
项目有些功能页面访问速度很慢,想优化下。这些功能页面不常用,只是一些简单的查询展示。但是经常首次访问速度超慢(>10s)。访问一次,接着访问速度飞快(<100ms).因为是多数据源项目,就是其中的几个页面有这种情况,并且这几个页面都用到同一个数据库。所以怀疑是因为我们单位内部有入网规范管理系统,连接长时间不用,可能会被关闭,所以数据库连接池获取连接,首次访问连接池要新创建一个连接才能获取到可用连接。
有试过很多druid配置:testWhileIdle,timeBetweenEvictionRunsMillis,removeAbandoned,removeAbandonedTimeoutMillis,initialSize,minIdle,maxActive等都试过了,还是会出现这种问题。
通过druid监控发现:
数据源长时间不用,此时数据源信息(物理打开数:1,物理关闭数:0,逻辑打开数:1,逻辑关闭数:1,正在打开连接数:0,连接池空闲数:1),这时因为连接空闲时间过长,已经不可用了。这里特别说明下,我的minIdle设置明明是10,为什么连接池空闲数会小于10呢?
然后,业务中调用数据源的getConnection()方法获取连接,先是获取到空闲连接(其实已不可用),然后配置了testWhileIdle,所以测试发现不可用,又重新创建一个连接。因此导致页面首次访问速度慢。
原因找到了,接下来就是想办法解决。
通过百度查找druid相关配置资料,对这些配置都试过了还是不行,又怀疑是不是druid版本问题,于是升级到当前最新版本1.1.23还是不行。最终决定分析druid源码。
调试解读源码:
1.调用getConnection获取连接。
dataSource.getConnection()2.进入com.alibaba.druid.pool.DruidDataSource.getConnection

3.init()应该是已经初始化过了,可以不用管;因为配置了druid监控和防火墙,所以filters.size()为2,。

4.进入com.alibaba.druid.filter.FilterChainImpl.dataSource_connect。此时this.pos=0 , filterSize=2

5.看nextFilter()方法:他先是返回的时StatFilter过滤器,然后再将pos自增1.



6.进入StatFilter.dataSource_getConnection
 7.chain.dataSource_connect将进入上面的4步那里,但此时的pos为1.所以最终是进入WallFilter.dataSource_getConnection,而WallFilter又是继承的com.alibaba.druid.filter.FilterAdapter,并且没有重写dataSource_getConnection方法。所以实际上是进入了FilterAdapter.dataSource_getConnection。
7.chain.dataSource_connect将进入上面的4步那里,但此时的pos为1.所以最终是进入WallFilter.dataSource_getConnection,而WallFilter又是继承的com.alibaba.druid.filter.FilterAdapter,并且没有重写dataSource_getConnection方法。所以实际上是进入了FilterAdapter.dataSource_getConnection。

8.此时调用chain.dataSource_connect(dataSource, maxWaitMillis)后,又将进入上面的4步那里,但此时的pos为2.所以this.pos < filterSize是false,不会进入if里执行了。
9.执行dataSource.getConnectionDirect(maxWaitMillis),这个有点长,就不截图了。
-
public DruidPooledConnection getConnectionDirect(long maxWaitMillis) throws SQLException {
-
int notFullTimeoutRetryCnt = 0;
-
for (;;) {
-
// handle notFullTimeoutRetry
-
DruidPooledConnection poolableConnection;
-
try {
-
poolableConnection = getConnectionInternal(maxWaitMillis);
-
} catch (GetConnectionTimeoutException ex) {
-
if (notFullTimeoutRetryCnt <= this.notFullTimeoutRetryCount && !isFull()) {
-
notFullTimeoutRetryCnt++;
-
if (LOG.isWarnEnabled()) {
-
LOG.warn("get connection timeout retry : " + notFullTimeoutRetryCnt);
-
}
-
continue;
-
}
-
throw ex;
-
}
-
-
if (testOnBorrow) {
-
boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
-
if (!validate) {
-
if (LOG.isDebugEnabled()) {
-
LOG.debug("skip not validate connection.");
-
}
-
-
discardConnection(poolableConnection.holder);
-
continue;
-
}
-
} else {
-
if (poolableConnection.conn.isClosed()) {
-
discardConnection(poolableConnection.holder); // 传入null,避免重复关闭
-
continue;
-
}
-
-
if (testWhileIdle) {
-
final DruidConnectionHolder holder = poolableConnection.holder;
-
long currentTimeMillis = System.currentTimeMillis();
-
long lastActiveTimeMillis = holder.lastActiveTimeMillis;
-
long lastExecTimeMillis = holder.lastExecTimeMillis;
-
long lastKeepTimeMillis = holder.lastKeepTimeMillis;
-
-
if (checkExecuteTime
-
&& lastExecTimeMillis != lastActiveTimeMillis) {
-
lastActiveTimeMillis = lastExecTimeMillis;
-
}
-
-
if (lastKeepTimeMillis > lastActiveTimeMillis) {
-
lastActiveTimeMillis = lastKeepTimeMillis;
-
}
-
-
long idleMillis = currentTimeMillis - lastActiveTimeMillis;
-
-
long timeBetweenEvictionRunsMillis = this.timeBetweenEvictionRunsMillis;
-
-
if (timeBetweenEvictionRunsMillis <= 0) {
-
timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS;
-
}
-
-
if (idleMillis >= timeBetweenEvictionRunsMillis
-
|| idleMillis < 0 // unexcepted branch
-
) {
-
boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
-
if (!validate) {
-
if (LOG.isDebugEnabled()) {
-
LOG.debug("skip not validate connection.");
-
}
-
-
discardConnection(poolableConnection.holder);
-
continue;
-
}
-
}
-
}
-
}
-
-
if (removeAbandoned) {
-
StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
-
poolableConnection.connectStackTrace = stackTrace;
-
poolableConnection.setConnectedTimeNano();
-
poolableConnection.traceEnable = true;
-
-
activeConnectionLock.lock();
-
try {
-
activeConnections.put(poolableConnection, PRESENT);
-
} finally {
-
activeConnectionLock.unlock();
-
}
-
}
-
-
if (!this.defaultAutoCommit) {
-
poolableConnection.setAutoCommit(false);
-
}
-
-
return poolableConnection;
-
}
-
}
10.调用getConnectionInternal方法获取连接。

-
private DruidPooledConnection getConnectionInternal(long maxWait) throws SQLException {
-
if (closed) {
-
connectErrorCountUpdater.incrementAndGet(this);
-
throw new DataSourceClosedException("dataSource already closed at " + new Date(closeTimeMillis));
-
}
-
-
if (!enable) {
-
connectErrorCountUpdater.incrementAndGet(this);
-
-
if (disableException != null) {
-
throw disableException;
-
}
-
-
throw new DataSourceDisableException();
-
}
-
-
final long nanos = TimeUnit.MILLISECONDS.toNanos(maxWait);
-
final int maxWaitThreadCount = this.maxWaitThreadCount;
-
-
DruidConnectionHolder holder;
-
-
for (boolean createDirect = false;;) {
-
if (createDirect) {
-
createStartNanosUpdater.set(this, System.nanoTime());
-
if (creatingCountUpdater.compareAndSet(this, 0, 1)) {
-
PhysicalConnectionInfo pyConnInfo = DruidDataSource.this.createPhysicalConnection();
-
holder = new DruidConnectionHolder(this, pyConnInfo);
-
holder.lastActiveTimeMillis = System.currentTimeMillis();
-
-
creatingCountUpdater.decrementAndGet(this);
-
directCreateCountUpdater.incrementAndGet(this);
-
-
if (LOG.isDebugEnabled()) {
-
LOG.debug("conn-direct_create ");
-
}
-
-
boolean discard = false;
-
lock.lock();
-
try {
-
if (activeCount < maxActive) {
-
activeCount++;
-
holder.active = true;
-
if (activeCount > activePeak) {
-
activePeak = activeCount;
-
activePeakTime = System.currentTimeMillis();
-
}
-
break;
-
} else {
-
discard = true;
-
}
-
} finally {
-
lock.unlock();
-
}
-
-
if (discard) {
-
JdbcUtils.close(pyConnInfo.getPhysicalConnection());
-
}
-
}
-
}
-
-
try {
-
lock.lockInterruptibly();
-
} catch (InterruptedException e) {
-
connectErrorCountUpdater.incrementAndGet(this);
-
throw new SQLException("interrupt", e);
-
}
-
-
try {
-
if (maxWaitThreadCount > 0
-
&& notEmptyWaitThreadCount >= maxWaitThreadCount) {
-
connectErrorCountUpdater.incrementAndGet(this);
-
throw new SQLException("maxWaitThreadCount " + maxWaitThreadCount + ", current wait Thread count "
-
+ lock.getQueueLength());
-
}
-
-
if (onFatalError
-
&& onFatalErrorMaxActive > 0
-
&& activeCount >= onFatalErrorMaxActive) {
-
connectErrorCountUpdater.incrementAndGet(this);
-
-
StringBuilder errorMsg = new StringBuilder();
-
errorMsg.append("onFatalError, activeCount ")
-
.append(activeCount)
-
.append(", onFatalErrorMaxActive ")
-
.append(onFatalErrorMaxActive);
-
-
if (lastFatalErrorTimeMillis > 0) {
-
errorMsg.append(", time '")
-
.append(StringUtils.formatDateTime19(
-
lastFatalErrorTimeMillis, TimeZone.getDefault()))
-
.append("'");
-
}
-
-
if (lastFatalErrorSql != null) {
-
errorMsg.append(", sql \n")
-
.append(lastFatalErrorSql);
-
}
-
-
throw new SQLException(
-
errorMsg.toString(), lastFatalError);
-
}
-
-
connectCount++;
-
-
if (createScheduler != null
-
&& poolingCount == 0
-
&& activeCount < maxActive
-
&& creatingCountUpdater.get(this) == 0
-
&& createScheduler instanceof ScheduledThreadPoolExecutor) {
-
ScheduledThreadPoolExecutor executor = (ScheduledThreadPoolExecutor) createScheduler;
-
if (executor.getQueue().size() > 0) {
-
createDirect = true;
-
continue;
-
}
-
}
-
-
if (maxWait > 0) {
-
holder = pollLast(nanos);
-
} else {
-
holder = takeLast();
-
}
-
-
if (holder != null) {
-
if (holder.discard) {
-
continue;
-
}
-
-
activeCount++;
-
holder.active = true;
-
if (activeCount > activePeak) {
-
activePeak = activeCount;
-
activePeakTime = System.currentTimeMillis();
-
}
-
}
-
} catch (InterruptedException e) {
-
connectErrorCountUpdater.incrementAndGet(this);
-
throw new SQLException(e.getMessage(), e);
-
} catch (SQLException e) {
-
connectErrorCountUpdater.incrementAndGet(this);
-
throw e;
-
} finally {
-
lock.unlock();
-
}
-
-
break;
-
}
-
-
if (holder == null) {
-
long waitNanos = waitNanosLocal.get();
-
-
StringBuilder buf = new StringBuilder(128);
-
buf.append("wait millis ")//
-
.append(waitNanos / (1000 * 1000))//
-
.append(", active ").append(activeCount)//
-
.append(", maxActive ").append(maxActive)//
-
.append(", creating ").append(creatingCount)//
-
;
-
if (creatingCount > 0 && createStartNanos > 0) {
-
long createElapseMillis = (System.nanoTime() - createStartNanos) / (1000 * 1000);
-
if (createElapseMillis > 0) {
-
buf.append(", createElapseMillis ").append(createElapseMillis);
-
}
-
}
-
-
if (createErrorCount > 0) {
-
buf.append(", createErrorCount ").append(createErrorCount);
-
}
-
-
List<JdbcSqlStatValue> sqlList = this.getDataSourceStat().getRuningSqlList();
-
for (int i = 0; i < sqlList.size(); ++i) {
-
if (i != 0) {
-
buf.append('\n');
-
} else {
-
buf.append(", ");
-
}
-
JdbcSqlStatValue sql = sqlList.get(i);
-
buf.append("runningSqlCount ").append(sql.getRunningCount());
-
buf.append(" : ");
-
buf.append(sql.getSql());
-
}
-
-
String errorMessage = buf.toString();
-
-
if (this.createError != null) {
-
throw new GetConnectionTimeoutException(errorMessage, createError);
-
} else {
-
throw new GetConnectionTimeoutException(errorMessage);
-
}
-
}
-
-
holder.incrementUseCount();
-
-
DruidPooledConnection poolalbeConnection = new DruidPooledConnection(holder);
-
return poolalbeConnection;
-
}
11.继续调试,找到了逻辑打开数统计的地方。

12.继续调试,找到了正在打开连接数统计的地方。holder里包含了druid封装好的数据库连接对象conn。

13.接着调试,运行到1692行的break命令,跳出for循环。

14.poolableConnection返回给了第10步中的poolableConnection。接着往下调试。testOnBorrow一般默认都是false,开启检查影响性能。

15.接下来测试连接是否被关闭,以及空闲检查。testWhileIdle

16.进入了DruidAbstractDataSource.testConnectionInternal
-
protected boolean testConnectionInternal(DruidConnectionHolder holder, Connection conn) {
-
String sqlFile = JdbcSqlStat.getContextSqlFile();
-
String sqlName = JdbcSqlStat.getContextSqlName();
-
-
if (sqlFile != null) {
-
JdbcSqlStat.setContextSqlFile(null);
-
}
-
if (sqlName != null) {
-
JdbcSqlStat.setContextSqlName(null);
-
}
-
try {
-
if (validConnectionChecker != null) {
-
boolean valid = validConnectionChecker.isValidConnection(conn, validationQuery, validationQueryTimeout);
-
long currentTimeMillis = System.currentTimeMillis();
-
if (holder != null) {
-
holder.lastValidTimeMillis = currentTimeMillis;
-
holder.lastExecTimeMillis = currentTimeMillis;
-
}
-
-
if (valid && isMySql) { // unexcepted branch
-
long lastPacketReceivedTimeMs = MySqlUtils.getLastPacketReceivedTimeMs(conn);
-
if (lastPacketReceivedTimeMs > 0) {
-
long mysqlIdleMillis = currentTimeMillis - lastPacketReceivedTimeMs;
-
if (lastPacketReceivedTimeMs > 0 //
-
&& mysqlIdleMillis >= timeBetweenEvictionRunsMillis) {
-
discardConnection(holder);
-
String errorMsg = "discard long time none received connection. "
-
+ ", jdbcUrl : " + jdbcUrl
-
+ ", jdbcUrl : " + jdbcUrl
-
+ ", lastPacketReceivedIdleMillis : " + mysqlIdleMillis;
-
LOG.error(errorMsg);
-
return false;
-
}
-
}
-
}
-
-
if (valid && onFatalError) {
-
lock.lock();
-
try {
-
if (onFatalError) {
-
onFatalError = false;
-
}
-
} finally {
-
lock.unlock();
-
}
-
}
-
-
return valid;
-
}
-
-
if (conn.isClosed()) {
-
return false;
-
}
-
-
if (null == validationQuery) {
-
return true;
-
}
-
-
Statement stmt = null;
-
ResultSet rset = null;
-
try {
-
stmt = conn.createStatement();
-
if (getValidationQueryTimeout() > 0) {
-
stmt.setQueryTimeout(validationQueryTimeout);
-
}
-
rset = stmt.executeQuery(validationQuery);
-
if (!rset.next()) {
-
return false;
-
}
-
} finally {
-
JdbcUtils.close(rset);
-
JdbcUtils.close(stmt);
-
}
-
-
if (onFatalError) {
-
lock.lock();
-
try {
-
if (onFatalError) {
-
onFatalError = false;
-
}
-
} finally {
-
lock.unlock();
-
}
-
}
-
-
return true;
-
} catch (Throwable ex) {
-
// skip
-
return false;
-
} finally {
-
if (sqlFile != null) {
-
JdbcSqlStat.setContextSqlFile(sqlFile);
-
}
-
if (sqlName != null) {
-
JdbcSqlStat.setContextSqlName(sqlName);
-
}
-
}
-
}
17.发送sql测试连接,具体里面是如何测试的就不深入了。这里如果测试正常就返回true,否则返回false,或者抛出异常。

18.下面主要分析调试抛出异常的情况。这个是因为我们上了入网规范管理系统,连接超时闲置会被断掉。
(ps:数据库服务器主动断了连接可能testWhileIdle之前就判断连接是否关闭就检查出来了,不会运行到这了。)

18.所以接着返回false值到16步那里,即validate=false。接着往下走:

19.discardConnection丢弃连接。
-
public void discardConnection(DruidConnectionHolder holder) {
-
if (holder == null) {
-
return;
-
}
-
//这里是获取jdbc的conn(即不是被druid封装的conn)
-
Connection conn = holder.getConnection();
-
if (conn != null) {
-
JdbcUtils.close(conn);//物理关闭连接
-
}
-
-
lock.lock();
-
try {
-
if (holder.discard) {
-
return;
-
}
-
-
if (holder.active) {
-
activeCount--;//正在打开连接数-1
-
holder.active = false;
-
}
-
discardCount++;//丢弃连接数+1
-
-
holder.discard = true;
-
-
if (activeCount <= minIdle) {//正在打开连接数小于等于最小空闲数
-
emptySignal();//唤醒CreateConnectionThread线程。
-
}
-
} finally {
-
lock.unlock();
-
}
-
}
20.唤醒CreateConnectionThread线程,新创建连接到连接池。CreateConnectionThread线程做了什么,相关分析以后有时间在分享了。

21.将不可用的连接丢弃后,执行continue,跳转到for循环开始位置。即又从第10步开始了。


22.getConnectionInternal中获取连接是通过takeList()获取的。这里获取逻辑猜测是如果连接池中有空闲连接,则直接返回空闲连接,没有的话需要等CreateConnectionThread线程创建好新线程后才能获取可用连接。

-
DruidConnectionHolder takeLast() throws InterruptedException, SQLException {
-
try {
-
while (poolingCount == 0) {
-
emptySignal(); // send signal to CreateThread create connection
-
-
if (failFast && isFailContinuous()) {
-
throw new DataSourceNotAvailableException(createError);
-
}
-
-
notEmptyWaitThreadCount++;
-
if (notEmptyWaitThreadCount > notEmptyWaitThreadPeak) {
-
notEmptyWaitThreadPeak = notEmptyWaitThreadCount;
-
}
-
try {
-
notEmpty.await(); // signal by recycle or creator
-
} finally {
-
notEmptyWaitThreadCount--;
-
}
-
notEmptyWaitCount++;
-
-
if (!enable) {
-
connectErrorCountUpdater.incrementAndGet(this);
-
if (disableException != null) {
-
throw disableException;
-
}
-
-
throw new DataSourceDisableException();
-
}
-
}
-
} catch (InterruptedException ie) {
-
notEmpty.signal(); // propagate to non-interrupted thread
-
notEmptySignalCount++;
-
throw ie;
-
}
-
-
decrementPoolingCount();
-
DruidConnectionHolder last = connections[poolingCount];
-
connections[poolingCount] = null;
-
-
return last;
-
}
23.最后getConnectionDirect终于获取到一个可用的连接,然后返回给了dataSource.getConnection()。
总结
通过分析我可以选择以下3个方案:
1.继续深入研究druid。实现数据库连接池中空闲连接数定时检测,保证空闲连接不可用的连接丢弃,创建新的连接。好像这个功能可以通过removeAbandoned配置实现,但我配置了,好像没效果。还得研究研究。还有连接池空闲连接数<minIdle数也有待研究。
优点:优化页面访问速度,提升了用户使用体验。
缺点:1.对性能有影响。长时间不用也会自动创建连接,然后又销毁连接。不停的循环。2.花费精力研究druid。
2.配置入网规范管理系统(准入系统)。延长服务器的数据库连接空闲时间,比如延长至3天或者7天。
优点:1.优化页面访问速度,提升了用户使用体验。2.不用修改项目。
缺点:1.对性能有影响。为了长时间保持连接,对准入系统性能有影响。2.需要联系准入系统管理员配置。
3.将该问题保留,待以后处理。
优点:大脑可以休息休息了,最近研究这个头发又掉了些。
缺点:1.用户首次访问页面时可能有点慢,体验不好。
最终我决定采用第3种方案,反正这些页面用的机会少,并且首次访问后速度还是很快的,影响不大。以后扩展该数据源相关的功能后,在看情况是否优化。
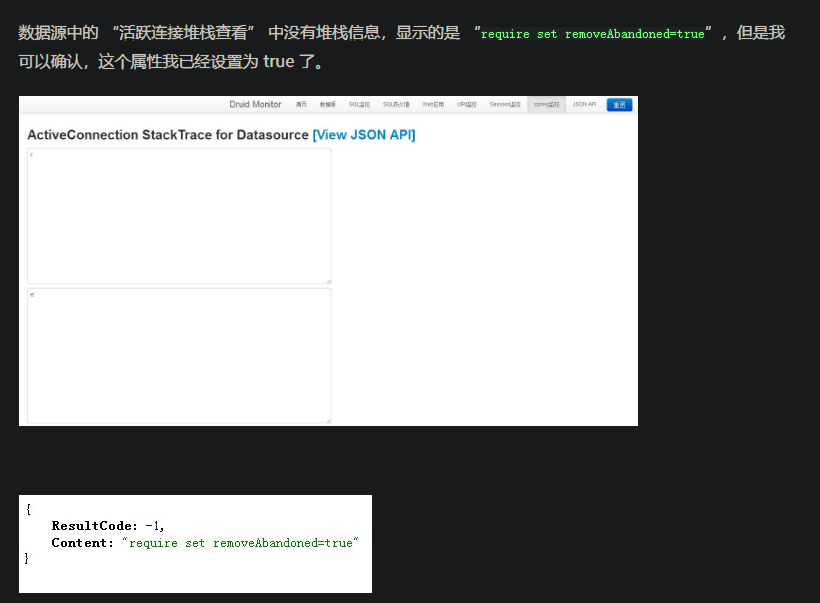

如图所示:是点击右边的[View JSON API]进行查看,而不是点击左边的View

 浙公网安备 33010602011771号
浙公网安备 33010602011771号