堆外内存 之 DirectByteBuffer 详解
堆外内存
堆外内存是相对于堆内内存的一个概念。堆内内存是由JVM所管控的Java进程内存,我们平时在Java中创建的对象都处于堆内内存中,并且它们遵循JVM的内存管理机制,JVM会采用垃圾回收机制统一管理它们的内存。那么堆外内存就是存在于JVM管控之外的一块内存区域,因此它是不受JVM的管控。
在讲解DirectByteBuffer之前,需要先简单了解两个知识点
java引用类型,因为DirectByteBuffer是通过虚引用(Phantom Reference)来实现堆外内存的释放的。
PhantomReference 是所有“弱引用”中最弱的引用类型。不同于软引用和弱引用,虚引用无法通过 get() 方法来取得目标对象的强引用从而使用目标对象,观察源码可以发现 get() 被重写为永远返回 null。
那虚引用到底有什么作用?其实虚引用主要被用来 跟踪对象被垃圾回收的状态,通过查看引用队列中是否包含对象所对应的虚引用来判断它是否 即将被垃圾回收,从而采取行动。它并不被期待用来取得目标对象的引用,而目标对象被回收前,它的引用会被放入一个 ReferenceQueue 对象中,从而达到跟踪对象垃圾回收的作用。
关于java引用类型的实现和原理可以阅读之前的文章Reference 、ReferenceQueue 详解 和Java 引用类型简述
关于linux的内核态和用户态
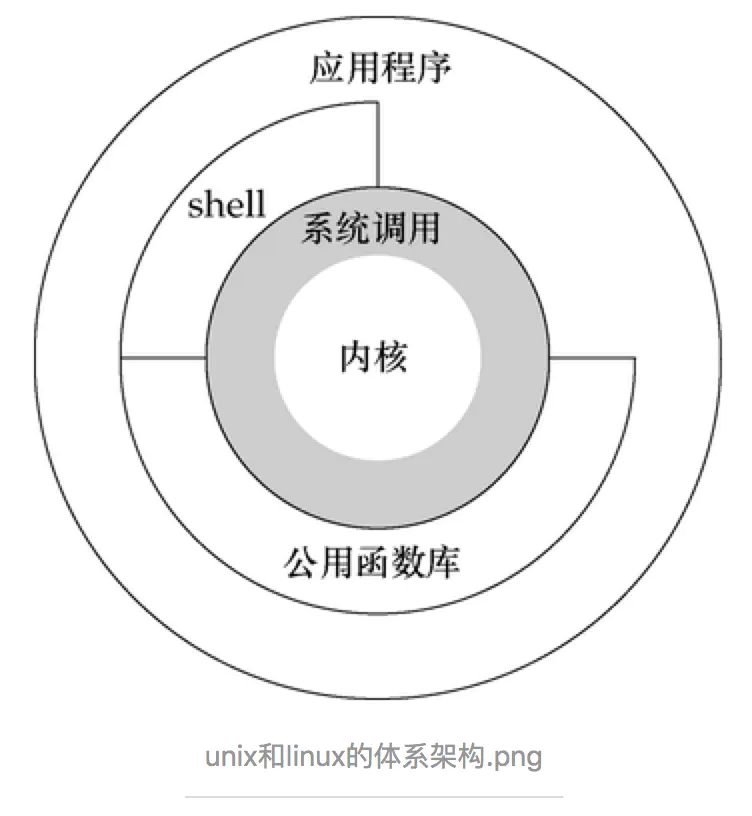
- 内核态:控制计算机的硬件资源,并提供上层应用程序运行的环境。比如socket I/0操作或者文件的读写操作等
- 用户态:上层应用程序的活动空间,应用程序的执行必须依托于内核提供的资源。
- 系统调用:为了使上层应用能够访问到这些资源,内核为上层应用提供访问的接口。

因此我们可以得知当我们通过JNI调用的native方法实际上就是从用户态切换到了内核态的一种方式。并且通过该系统调用使用操作系统所提供的功能。
Q:为什么需要用户进程(位于用户态中)要通过系统调用(Java中即使JNI)来调用内核态中的资源,或者说调用操作系统的服务了?
A:intel cpu提供Ring0-Ring3四种级别的运行模式,Ring0级别最高,Ring3最低。Linux使用了Ring3级别运行用户态,Ring0作为内核态。Ring3状态不能访问Ring0的地址空间,包括代码和数据。因此用户态是没有权限去操作内核态的资源的,它只能通过系统调用外完成用户态到内核态的切换,然后在完成相关操作后再有内核态切换回用户态。
DirectByteBuffer ———— 直接缓冲
DirectByteBuffer是Java用于实现堆外内存的一个重要类,我们可以通过该类实现堆外内存的创建、使用和销毁。
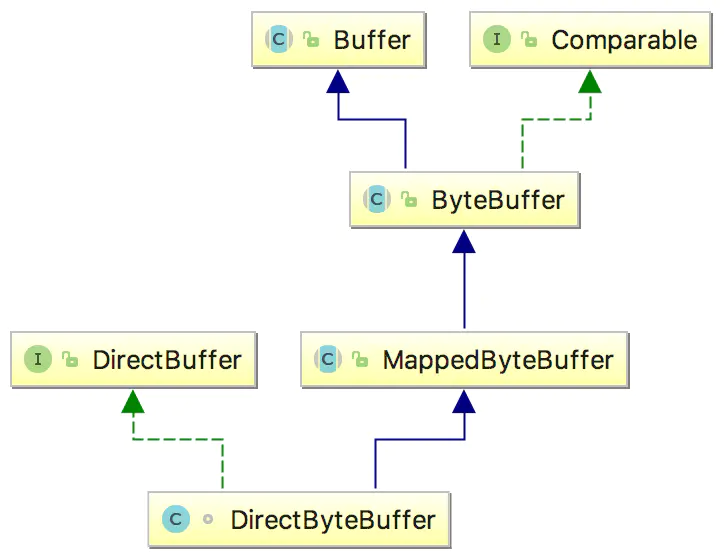
DirectByteBuffer该类本身还是位于Java内存模型的堆中。堆内内存是JVM可以直接管控、操纵。
而DirectByteBuffer中的unsafe.allocateMemory(size);是个一个native方法,这个方法分配的是堆外内存,通过C的malloc来进行分配的。分配的内存是系统本地的内存,并不在Java的内存中,也不属于JVM管控范围,所以在DirectByteBuffer一定会存在某种方式来操纵堆外内存。
在DirectByteBuffer的父类Buffer中有个address属性:
// Used only by direct buffers
// NOTE: hoisted here for speed in JNI GetDirectBufferAddress
long address;address只会被直接缓存给使用到。之所以将address属性升级放在Buffer中,是为了在JNI调用GetDirectBufferAddress时提升它调用的速率。
address表示分配的堆外内存的地址。
unsafe.allocateMemory(size);分配完堆外内存后就会返回分配的堆外内存基地址,并将这个地址赋值给了address属性。这样我们后面通过JNI对这个堆外内存操作时都是通过这个address来实现的了。
在前面我们说过,在linux中内核态的权限是最高的,那么在内核态的场景下,操作系统是可以访问任何一个内存区域的,所以操作系统是可以访问到Java堆的这个内存区域的。
Q:那为什么操作系统不直接访问Java堆内的内存区域了?
A:这是因为JNI方法访问的内存区域是一个已经确定了的内存区域地质,那么该内存地址指向的是Java堆内内存的话,那么如果在操作系统正在访问这个内存地址的时候,Java在这个时候进行了GC操作,而GC操作会涉及到数据的移动操作[GC经常会进行先标志在压缩的操作。即,将可回收的空间做标志,然后清空标志位置的内存,然后会进行一个压缩,压缩就会涉及到对象的移动,移动的目的是为了腾出一块更加完整、连续的内存空间,以容纳更大的新对象],数据的移动会使JNI调用的数据错乱。所以JNI调用的内存是不能进行GC操作的。
Q:如上面所说,JNI调用的内存是不能进行GC操作的,那该如何解决了?
A:①堆内内存与堆外内存之间数据拷贝的方式(并且在将堆内内存拷贝到堆外内存的过程JVM会保证不会进行GC操作):比如我们要完成一个从文件中读数据到堆内内存的操作,即FileChannelImpl.read(HeapByteBuffer)。这里实际上File I/O会将数据读到堆外内存中,然后堆外内存再讲数据拷贝到堆内内存,这样我们就读到了文件中的内存。
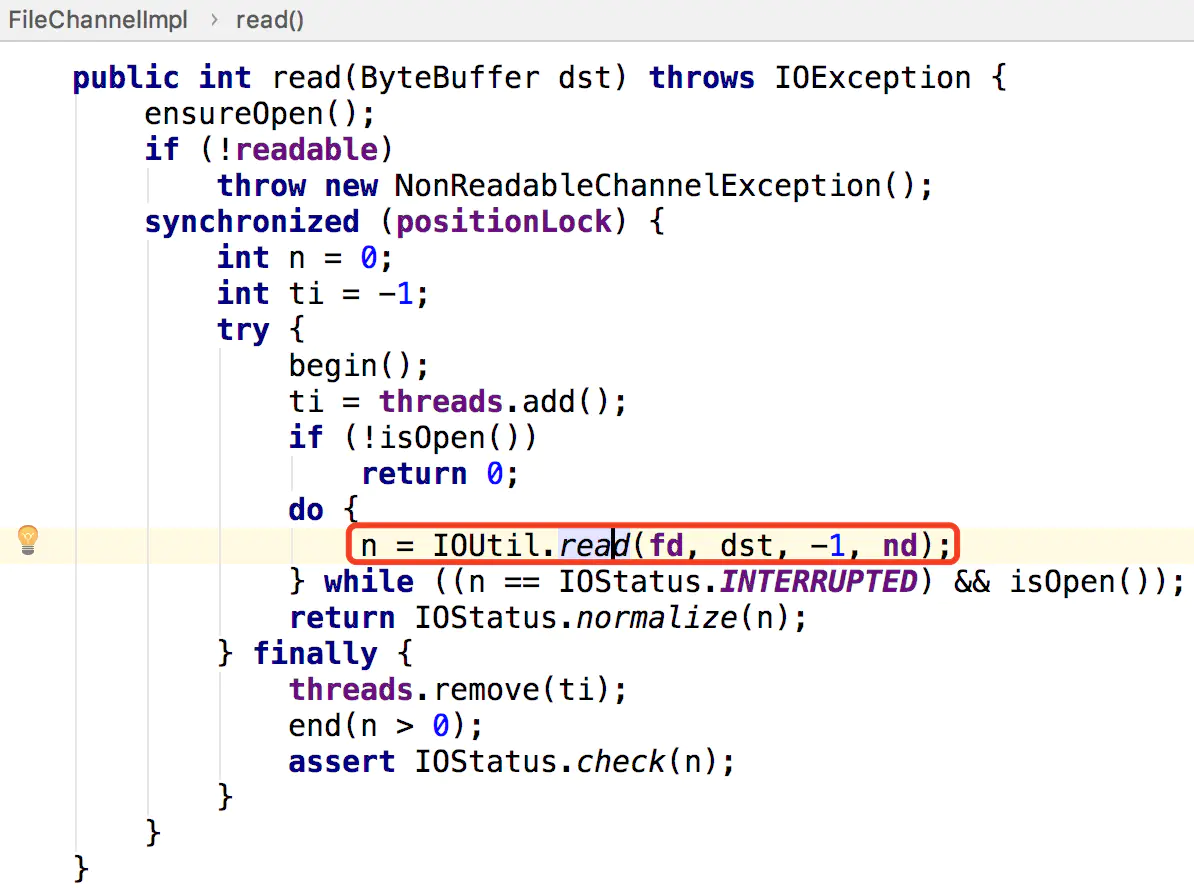
static int read(FileDescriptor var0, ByteBuffer var1, long var2, NativeDispatcher var4) throws IOException {
if (var1.isReadOnly()) {
throw new IllegalArgumentException("Read-only buffer");
} else if (var1 instanceof DirectBuffer) {
return readIntoNativeBuffer(var0, var1, var2, var4);
} else {
// 分配临时的堆外内存
ByteBuffer var5 = Util.getTemporaryDirectBuffer(var1.remaining());
int var7;
try {
// File I/O 操作会将数据读入到堆外内存中
int var6 = readIntoNativeBuffer(var0, var5, var2, var4);
var5.flip();
if (var6 > 0) {
// 将堆外内存的数据拷贝到堆外内存中
var1.put(var5);
}
var7 = var6;
} finally {
// 里面会调用DirectBuffer.cleaner().clean()来释放临时的堆外内存
Util.offerFirstTemporaryDirectBuffer(var5);
}
return var7;
}
}而写操作则反之,我们会将堆内内存的数据线写到对堆外内存中,然后操作系统会将堆外内存的数据写入到文件中。
② 直接使用堆外内存,如DirectByteBuffer:这种方式是直接在堆外分配一个内存(即,native memory)来存储数据,程序通过JNI直接将数据读/写到堆外内存中。因为数据直接写入到了堆外内存中,所以这种方式就不会再在JVM管控的堆内再分配内存来存储数据了,也就不存在堆内内存和堆外内存数据拷贝的操作了。这样在进行I/O操作时,只需要将这个堆外内存地址传给JNI的I/O的函数就好了。
DirectByteBuffer堆外内存的创建和回收的源码解读
堆外内存分配
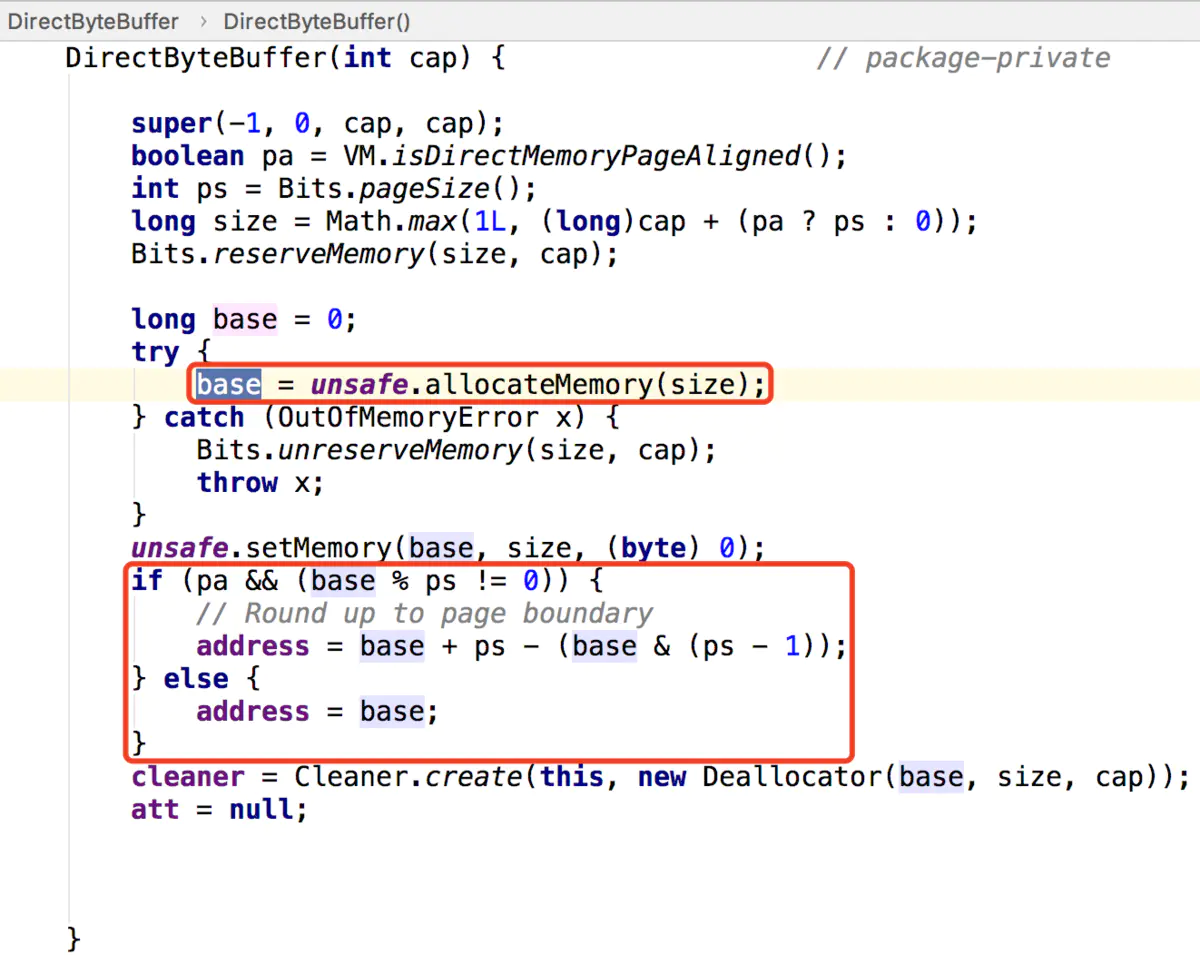
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
// 保留总分配内存(按页分配)的大小和实际内存的大小
Bits.reserveMemory(size, cap);
long base = 0;
try {
// 通过unsafe.allocateMemory分配堆外内存,并返回堆外内存的基地址
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
// 构建Cleaner对象用于跟踪DirectByteBuffer对象的垃圾回收,以实现当DirectByteBuffer被垃圾回收时,堆外内存也会被释放
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}Bits.reserveMemory(size, cap) 方法
static void reserveMemory(long size, int cap) {
if (!memoryLimitSet && VM.isBooted()) {
maxMemory = VM.maxDirectMemory();
memoryLimitSet = true;
}
// optimist!
if (tryReserveMemory(size, cap)) {
return;
}
final JavaLangRefAccess jlra = SharedSecrets.getJavaLangRefAccess();
// retry while helping enqueue pending Reference objects
// which includes executing pending Cleaner(s) which includes
// Cleaner(s) that free direct buffer memory
while (jlra.tryHandlePendingReference()) {
if (tryReserveMemory(size, cap)) {
return;
}
}
// trigger VM's Reference processing
System.gc();
// a retry loop with exponential back-off delays
// (this gives VM some time to do it's job)
boolean interrupted = false;
try {
long sleepTime = 1;
int sleeps = 0;
while (true) {
if (tryReserveMemory(size, cap)) {
return;
}
if (sleeps >= MAX_SLEEPS) {
break;
}
if (!jlra.tryHandlePendingReference()) {
try {
Thread.sleep(sleepTime);
sleepTime <<= 1;
sleeps++;
} catch (InterruptedException e) {
interrupted = true;
}
}
}
// no luck
throw new OutOfMemoryError("Direct buffer memory");
} finally {
if (interrupted) {
// don't swallow interrupts
Thread.currentThread().interrupt();
}
}
}该方法用于在系统中保存总分配内存(按页分配)的大小和实际内存的大小。
其中,如果系统中内存( 即,堆外内存 )不够的话:
final JavaLangRefAccess jlra = SharedSecrets.getJavaLangRefAccess();
// retry while helping enqueue pending Reference objects
// which includes executing pending Cleaner(s) which includes
// Cleaner(s) that free direct buffer memory
while (jlra.tryHandlePendingReference()) {
if (tryReserveMemory(size, cap)) {
return;
}
}jlra.tryHandlePendingReference()会触发一次非堵塞的Reference#tryHandlePending(false)。该方法会将已经被JVM垃圾回收的DirectBuffer对象的堆外内存释放。
因为在Reference的静态代码块中定义了:
SharedSecrets.setJavaLangRefAccess(new JavaLangRefAccess() {
@Override
public boolean tryHandlePendingReference() {
return tryHandlePending(false);
}
});如果在进行一次堆外内存资源回收后,还不够进行本次堆外内存分配的话,则
// trigger VM's Reference processing
System.gc();System.gc()会触发一个full gc,当然前提是你没有显示的设置-XX:+DisableExplicitGC来禁用显式GC。并且你需要知道,调用System.gc()并不能够保证full gc马上就能被执行。
所以在后面打代码中,会进行最多9次尝试,看是否有足够的可用堆外内存来分配堆外内存。并且每次尝试之前,都对延迟等待时间,已给JVM足够的时间去完成full gc操作。如果9次尝试后依旧没有足够的可用堆外内存来分配本次堆外内存,则抛出OutOfMemoryError("Direct buffer memory”)异常。

注意,这里之所以用使用full gc的很重要的一个原因是:System.gc()会对新生代的老生代都会进行内存回收,这样会比较彻底地回收DirectByteBuffer对象以及他们关联的堆外内存.
DirectByteBuffer对象本身其实是很小的,但是它后面可能关联了一个非常大的堆外内存,因此我们通常称之为冰山对象.
我们做ygc的时候会将新生代里的不可达的DirectByteBuffer对象及其堆外内存回收了,但是无法对old里的DirectByteBuffer对象及其堆外内存进行回收,这也是我们通常碰到的最大的问题。( 并且堆外内存多用于生命期中等或较长的对象 )
如果有大量的DirectByteBuffer对象移到了old,但是又一直没有做cms gc或者full gc,而只进行ygc,那么我们的物理内存可能被慢慢耗光,但是我们还不知道发生了什么,因为heap明明剩余的内存还很多(前提是我们禁用了System.gc – JVM参数DisableExplicitGC)。
总的来说,Bits.reserveMemory(size, cap)方法在可用堆外内存不足以分配给当前要创建的堆外内存大小时,会实现以下的步骤来尝试完成本次堆外内存的创建:
① 触发一次非堵塞的Reference#tryHandlePending(false)。该方法会将已经被JVM垃圾回收的DirectBuffer对象的堆外内存释放。
② 如果进行一次堆外内存资源回收后,还不够进行本次堆外内存分配的话,则进行 System.gc()。System.gc()会触发一个full gc,但你需要知道,调用System.gc()并不能够保证full gc马上就能被执行。所以在后面打代码中,会进行最多9次尝试,看是否有足够的可用堆外内存来分配堆外内存。并且每次尝试之前,都对延迟等待时间,已给JVM足够的时间去完成full gc操作。
注意,如果你设置了-XX:+DisableExplicitGC,将会禁用显示GC,这会使System.gc()调用无效。
③ 如果9次尝试后依旧没有足够的可用堆外内存来分配本次堆外内存,则抛出OutOfMemoryError("Direct buffer memory”)异常。
那么可用堆外内存到底是多少了?,即默认堆外存内存有多大:
① 如果我们没有通过-XX:MaxDirectMemorySize来指定最大的堆外内存。则👇
② 如果我们没通过-Dsun.nio.MaxDirectMemorySize指定了这个属性,且它不等于-1。则👇
③ 那么最大堆外内存的值来自于directMemory = Runtime.getRuntime().maxMemory(),这是一个native方法
JNIEXPORT jlong JNICALL
Java_java_lang_Runtime_maxMemory(JNIEnv *env, jobject this)
{
return JVM_MaxMemory();
}
JVM_ENTRY_NO_ENV(jlong, JVM_MaxMemory(void))
JVMWrapper("JVM_MaxMemory");
size_t n = Universe::heap()->max_capacity();
return convert_size_t_to_jlong(n);
JVM_END其中在我们使用CMS GC的情况下也就是我们设置的-Xmx的值里除去一个survivor的大小就是默认的堆外内存的大小了。
堆外内存回收
Cleaner是PhantomReference的子类,并通过自身的next和prev字段维护的一个双向链表。PhantomReference的作用在于跟踪垃圾回收过程,并不会对对象的垃圾回收过程造成任何的影响。
所以cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); 用于对当前构造的DirectByteBuffer对象的垃圾回收过程进行跟踪。
当DirectByteBuffer对象从pending状态 ——> enqueue状态时,会触发Cleaner的clean(),而Cleaner的clean()的方法会实现通过unsafe对堆外内存的释放。

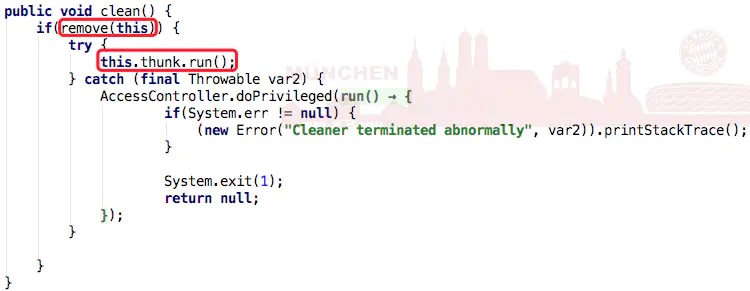
👆虽然Cleaner不会调用到Reference.clear(),但Cleaner的clean()方法调用了remove(this),即将当前Cleaner从Cleaner链表中移除,这样当clean()执行完后,Cleaner就是一个无引用指向的对象了,也就是可被GC回收的对象。
thunk方法:

通过配置参数的方式来回收堆外内存
同时我们可以通过-XX:MaxDirectMemorySize来指定最大的堆外内存大小,当使用达到了阈值的时候将调用System.gc()来做一次full gc,以此来回收掉没有被使用的堆外内存。
堆外内存那些事
使用堆外内存的原因
- 对垃圾回收停顿的改善
因为full gc 意味着彻底回收,彻底回收时,垃圾收集器会对所有分配的堆内内存进行完整的扫描,这意味着一个重要的事实——这样一次垃圾收集对Java应用造成的影响,跟堆的大小是成正比的。过大的堆会影响Java应用的性能。如果使用堆外内存的话,堆外内存是直接受操作系统管理( 而不是虚拟机 )。这样做的结果就是能保持一个较小的堆内内存,以减少垃圾收集对应用的影响。 - 在某些场景下可以提升程序I/O操纵的性能。少去了将数据从堆内内存拷贝到堆外内存的步骤。
什么情况下使用堆外内存
- 堆外内存适用于生命周期中等或较长的对象。( 如果是生命周期较短的对象,在YGC的时候就被回收了,就不存在大内存且生命周期较长的对象在FGC对应用造成的性能影响 )。
- 直接的文件拷贝操作,或者I/O操作。直接使用堆外内存就能少去内存从用户内存拷贝到系统内存的操作,因为I/O操作是系统内核内存和设备间的通信,而不是通过程序直接和外设通信的。
- 同时,还可以使用 池+堆外内存 的组合方式,来对生命周期较短,但涉及到I/O操作的对象进行堆外内存的再使用。( Netty中就使用了该方式 )
堆外内存 VS 内存池
- 内存池:主要用于两类对象:①生命周期较短,且结构简单的对象,在内存池中重复利用这些对象能增加CPU缓存的命中率,从而提高性能;②加载含有大量重复对象的大片数据,此时使用内存池能减少垃圾回收的时间。
- 堆外内存:它和内存池一样,也能缩短垃圾回收时间,但是它适用的对象和内存池完全相反。内存池往往适用于生命期较短的可变对象,而生命期中等或较长的对象,正是堆外内存要解决的。
堆外内存的特点
- 对于大内存有良好的伸缩性
- 对垃圾回收停顿的改善可以明显感觉到
- 在进程间可以共享,减少虚拟机间的复制
堆外内存的一些问题
- 堆外内存回收问题,以及堆外内存的泄漏问题。这个在上面的源码解析已经提到了
- 堆外内存的数据结构问题:堆外内存最大的问题就是你的数据结构变得不那么直观,如果数据结构比较复杂,就要对它进行串行化(serialization),而串行化本身也会影响性能。另一个问题是由于你可以使用更大的内存,你可能开始担心虚拟内存(即硬盘)的速度对你的影响了。
参考
http://lovestblog.cn/blog/2015/05/12/direct-buffer/
http://www.infoq.com/cn/news/2014/12/external-memory-heap-memory
http://www.jianshu.com/p/85e931636f27
圣思园《并发与Netty》课程
jvm是一个进程,堆外内存也属于进程的一部分,怎么不受jvm的管控,你干掉了进程难道堆外内存还存在吗,只不过是受gc间接控制或者手动释放而已。你一个c程序申请的内存还能让系统管理?
jni 跟内核态并没有什么关系,作者请三思,以免给不明白的人造成更大困惑。还有JVM的内存和普通内存并没有本质区别,可以理解为一个内存池,其内部实现对操作系统来说是完全透明的,所以内核根本没法直接访问其内部数据,与gc无关。
如果说在NIO中默认使用DirectByteBuffer拷贝原来的HeapByteBuffer是为了避免GC造成对象移动带来的数据错乱,那为什么在BIO中,SocketOutputStream就可以直接将一个字节数组直接作为参数传入底层的native方法,包括FileInputStream,FileOutputStream之类的的read和write方法最终调用的都是一个native方法,而参数也有字节数组的,,难道他们不怕GC造成的影响么???
正因为是字节数组,所以只要获得移动后的数组引用就能找到整个数据,注意数组是相当于对象被放在堆里的,所以是像对象一样整个移动
DirectByteBuffer的实际数据是在用户态还是内核态?用户态,只是不再JVM管控范围之内。内核态的数据是操作系统常规应用无法直接访问的。所有才有数据从内核空间拷贝到用户空间的操作
DirectByteBuffer继承了MappedByteBuffer,MappedByteBuffer使用了操作系统的虚拟内存技术,使得java进程(用户进程)持有的虚拟地址跟内核持有的虚拟地址(它们各自的虚拟地址,是不同的)经过MMU转换后,得到了同一个物理地址。也就是说,通过使用MappedByteBuffer,可以让java进程与内核共享同一块物理内存(实际上不是连续的物理),进而避免了用户态缓冲和内核态缓冲之间的内存拷贝(因为现在这两块缓冲根本就是同一个)。
感觉你和作者讲的有出入,现在有几个疑惑,
1.在使用阻塞I/O下,文件拷贝流程是什么样的
2.堆外内存是在用户态还是内核态
3.MappedByteBuffer使用了操作系统的虚拟内存映射,避免了用户态缓冲和内核态缓冲之间的内存拷贝,DirectByteBuffer既然继承了MappedByteBuffer,那应该也避免了用户态到内核态之间的内存拷贝吧
不知道有没有推荐的书籍看一下,零星的知识加上各种网络资料整的我有点懵了
我最近在看周志明的《深入JVM》,里面对本机内存,即DirectMemroySize的默认大小,说是与Java堆一样大的(Xmx)。而您在上边说,还要去除一个Survivor,是不是记错了?
通过JNI调用的native方法实际上就是从用户态切换到了内核态的一种方式。
native方法只是方法体用C/C++实现,和内核态没什么关系。。。具体是否要切换还是看这部分代码中是否进入了内核态。。
这里结合上下文想要表达的是,通过native方法执行的C++操作是涉及 I/O 的C++操作,因为涉及 I/O 的C++操作 是设计用户态和内核态的切换的。
用户态与内核态
unix和linux的体系架构:分为用户态和内核态
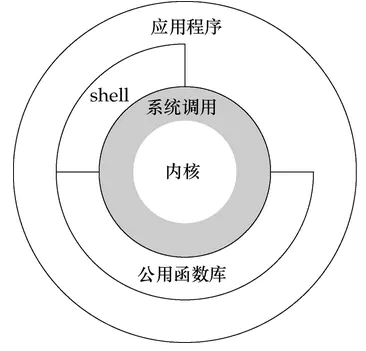
- 内核态:控制计算机的硬件资源,并提供上层应用程序运行的环境。
- 用户态:上层应用程序的活动空间,应用程序的执行必须依托于内核提供的资源。
- 系统调用:为了使上层应用能够访问到这些资源,内核为上层应用提供访问的接口。
三者之间的关系如下:
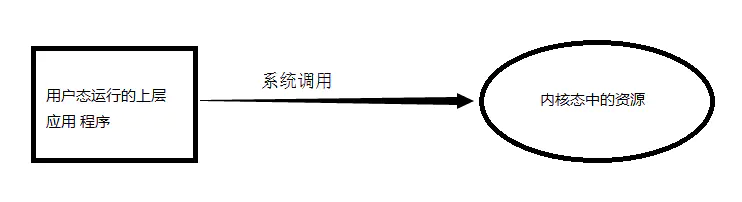
系统调用是操作系统中的最小功能单位。
- 系统调用与上层应用程序的关系:
如果将系统调用比作是一个“比画”,那么上层应用就是一个“汉字”。如果完成一个“汉字”,就需要通过多个系统调用。
- 系统调用与公用函数库的关系:
公用函数库实现对系统调用的封装,将简单的业务逻辑接口呈现给用户,方便用户调用,从这个角度上看,库函数就像是组成汉字的“偏旁”。
从特权级来区分内核态和用户态:
在CPU的所有指令中,有一些指令是非常危险的,如果错用,将导致整个系统崩溃。所以,CPU将指令分为特权指令和非特权指令,对于那些危险的指令,只允许操作系统及其相关模块使用,普通的应用程序只能使用那些不会造成灾难的指令。
intel cpu提供Ring0-Ring3四种级别的运行模式,Ring0级别最高,Ring3最低。Linux使用了Ring3级别运行用户态,Ring0作为 内核态。
用户态切换为内核态的三种情况:
- 系统调用
- 异常事件: 当CPU正在执行运行在用户态的程序时,突然发生某些预先不可知的异常事件,这个时候就会触发从当前用户态执行的进程转向内核态执行相关的异常事件,典型的如缺页异常。
- 外围设备的中断:当外围设备完成用户的请求操作后,会像CPU发出中断信号,此时,CPU就会暂停执行下一条即将要执行的指令,转而去执行中断信号对应的处理程序,如果先前执行的指令是在用户态下,则自然就发生从用户态到内核态的转换。
系统调用的本质其实也是中断,相对于外围设备的硬中断,这种中断称为软中断。从触发方式和效果上来看,这三种切换方式是完全一样的,都相当于是执行了一个中断响应的过程。但是从触发的对象来看,系统调用是进程主动请求切换的,而异常和硬中断则是被动的。
参考资料:
Linux探秘之用户态与内核态
Linux用户态和内核态
linux操作系统的内核态和用户态
首先明确下什么是缺页异常,CPU通过地址总线可以访问连接在地址总线上的所有外设,包括物理内存、IO设备等等,但从CPU发出的访问地址并非是这些外设在地址总线上的物理地址,而是一个虚拟地址,由MMU将虚拟地址转换成物理地址再从地址总线上发出,MMU上的这种虚拟地址和物理地址的转换关系是需要创建的,并且MMU还可以设置这个物理页是否可以进行写操作,当没有创建一个虚拟地址到物理地址的映射,或者创建了这样的映射,但那个物理页不可写的时候,MMU将会通知CPU产生了一个缺页异常。
下面总结下缺页异常的几种情况:
1、当MMU中确实没有创建虚拟页物理页映射关系,并且在该虚拟地址之后再没有当前进程的线性区vma的时候,可以肯定这是一个编码错误,这将杀掉该进程;
2、当MMU中确实没有创建虚拟页物理页映射关系,并且在该虚拟地址之后存在当前进程的线性区vma的时候,这很可能是缺页异常,并且可能是栈溢出导致的缺页异常;
3、当使用malloc/mmap等希望访问物理空间的库函数/系统调用后,由于linux并未真正给新创建的vma映射物理页,此时若先进行写操作,将如上面的2的情况产生缺页异常,若先进行读操作虽也会产生缺页异常,将被映射给默认的零页(zero_pfn),等再进行写操作时,仍会产生缺页异常,这次必须分配物理页了,进入写时复制的流程;
4、当使用fork等系统调用创建子进程时,子进程不论有无自己的vma,“它的”vma都有对于物理页的映射,但它们共同映射的这些物理页属性为只读,即linux并未给子进程真正分配物理页,当父子进程任何一方要写相应物理页时,导致缺页异常的写时复制;
目前来看,应该就是这四种情况,还是比较清晰的,可发现一个重要规律就是,linux是直到实在不行的时候才会分配物理页,把握这个原则理解的会好一些,下面详细的看缺页处理:
arm的缺页处理函数为arch/arm/mm/fault.c文件中的do_page_fault函数,关于缺页异常是怎么一步步调到这个函数的,同上一篇位置进程地址空间创建说的一样,后面会有专题文章描述这个问题,现在只关心缺页异常的处理,下面是函数do_page_fault:
static int __kprobes
do_page_fault(unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
struct task_struct *tsk;
struct mm_struct *mm;
int fault, sig, code;
/*空函数*/
if (notify_page_fault(regs, fsr))
return 0;
/*获取到缺页异常的进程描述符和其内存描述符*/
tsk = current;
mm = tsk->mm;
/*
* If we're in an interrupt or have no user
* context, we must not take the fault..
*/
/*1、判断当前是否是在原子操作中(中断、可延迟函数、临界区)发生的异常
2、通过mm是否存在判断是否是内核线程,对于内核线程,进程描述符的mm总为NULL
一旦成立,说明是在内核态中发生的异常,跳到标号no_context*/
if (in_atomic() || !mm)
goto no_context;
/*
* As per x86, we may deadlock here. However, since the kernel only
* validly references user space from well defined areas of the code,
* we can bug out early if this is from code which shouldn't.
*/
if (!down_read_trylock(&mm->mmap_sem)) {
if (!user_mode(regs) && !search_exception_tables(regs->ARM_pc))
goto no_context;
down_read(&mm->mmap_sem);
} else {
/*
* The above down_read_trylock() might have succeeded in
* which case, we'll have missed the might_sleep() from
* down_read()
*/
might_sleep();
#ifdef CONFIG_DEBUG_VM
if (!user_mode(regs) &&
!search_exception_tables(regs->ARM_pc))
goto no_context;
#endif
}
fault = __do_page_fault(mm, addr, fsr, tsk);
up_read(&mm->mmap_sem);
/*
* Handle the "normal" case first - VM_FAULT_MAJOR / VM_FAULT_MINOR
*/
/*如果返回值fault不是这里面的值,那么应该会是VM_FAULT_MAJOR或VM_FAULT_MINOR,说明问题解决了,返回,一般正常情况下,__do_page_fault的返回值fault会是0(VM_FAULT_MINOR)或者其他一些值,都不是下面之后会看到的这些*/
if (likely(!(fault & (VM_FAULT_ERROR | VM_FAULT_BADMAP | VM_FAULT_BADACCESS))))
return 0;
/*如果fault是VM_FAULT_OOM这个级别的错误,那么这要杀掉进程*/
if (fault & VM_FAULT_OOM) {
/*
* We ran out of memory, call the OOM killer, and return to
* userspace (which will retry the fault, or kill us if we
* got oom-killed)
*/
pagefault_out_of_memory();
return 0;
}
/*
* If we are in kernel mode at this point, we
* have no context to handle this fault with.
*/
/*再次判断是否是内核空间出现了页异常,并且通过__do_page_fault没有没有解决,跳到到no_context*/
if (!user_mode(regs))
goto no_context;
/*下面两个情况,通过英文注释可以理解,
一个是无法修复,另一个是访问非法地址,都是要杀掉进程的错误*/
if (fault & VM_FAULT_SIGBUS) {
/*
* We had some memory, but were unable to
* successfully fix up this page fault.
*/
sig = SIGBUS;
code = BUS_ADRERR;
} else {
/*
* Something tried to access memory that
* isn't in our memory map..
*/
sig = SIGSEGV;
code = fault == VM_FAULT_BADACCESS ?
SEGV_ACCERR : SEGV_MAPERR;
}
/*给用户进程发送相应的信号,杀掉进程*/
__do_user_fault(tsk, addr, fsr, sig, code, regs);
return 0;
no_context:
/*内核引发的异常处理,如修复不畅,内核也要杀掉*/
__do_kernel_fault(mm, addr, fsr, regs);
return 0;
}
首先看第一个重点,源码片段如下:
/*1、判断当前是否是在原子操作中(中断、可延迟函数、临界区)发生的异常
2、通过mm是否存在判断是否是内核线程,对于内核线程,进程描述符的mm总为NULL,一旦成立,说明是在内核态中发生的异常,跳到标号no_context*/
if (in_atomic() || !mm)
goto no_context;
如果当前执行流程在内核态,不论是在临界区(中断/推后执行/临界区)还是内核进程本身(内核的mm为NULL),说明在内核态出了问题,跳到标号no_context进入内核态异常处理,由函数__do_kernel_fault完成,这个函数首先尽可能的设法解决这个异常,通过查找异常表中和目前的异常对应的解决办法并调用执行,这个部分的细节一直没有找到在哪里,如果找到的话留言告我一下吧!如果无法通过异常表解决,那么内核就要在打印其页表等内容后退出了!其源码如下:
static void
__do_kernel_fault(struct mm_struct *mm, unsigned long addr, unsigned int fsr,
struct pt_regs *regs)
{
/*
* Are we prepared to handle this kernel fault?
*/
/*fixup_exception()用于搜索异常表,并试图找到一个对应该异常的例程来进行修正,这个例程在fixup_exception()返回后执行*/
if (fixup_exception(regs))
return;
/*
* No handler, we'll have to terminate things with extreme prejudice.
*/
/*走到这里就说明异常确实是由于内核的程序设计缺陷导致的了,内核将产生一个oops,下面的工作就是打印CPU寄存器和内核态堆栈的信息到控制台并终结当前的进程*/
bust_spinlocks(1);
printk(KERN_ALERT
"Unable to handle kernel %s at virtual address %08lx\n",
(addr < PAGE_SIZE) ? "NULL pointer dereference" :
"paging request", addr);
/*打印内核一二级页表信息*/
show_pte(mm, addr);
/*内核产生一个oops,打印一堆东西准备退出*/
die("Oops", regs, fsr);
bust_spinlocks(0);
/*内核退出了!*/
do_exit(SIGKILL);
}
接上一篇
回到函数do_page_fault,如果不是内核的缺页异常而是用户进程的缺页异常,那么调用函数__do_page_fault,这个应该是本文的重点,主要讨论的是用户进程的缺页异常,结合最前面说的用户进程产生缺页异常的四种情况,函数__do_page_fault都会排查到,源码如下:
__do_page_fault(struct mm_struct *mm, unsigned long addr, unsigned int fsr,
struct task_struct *tsk)
{
struct vm_area_struct *vma;
int fault;
/*搜索出现异常的地址前向最近的的vma*/
vma = find_vma(mm, addr);
fault = VM_FAULT_BADMAP;
/*如果vma为NULL,说明addr之后没有vma,所以这个addr是个错误地址*/
if (unlikely(!vma))
goto out;
/*如果addr后面有vma,但不包含addr,不能断定addr是错误地址,还需检查*/
if (unlikely(vma->vm_start > addr))
goto check_stack;
/*
* Ok, we have a good vm_area for this
* memory access, so we can handle it.
*/
good_area:
/*权限错误也要返回,比如缺页报错(由参数fsr标识)报的是不可写/不可执行的错误,但addr所属vma线性区本身就不可写/不可执行,那么就直接返回,因为问题根本不是缺页,而是vma就已经有问题*/
if (access_error(fsr, vma)) {
fault = VM_FAULT_BADACCESS;
goto out;
}
/*
* If for any reason at all we couldn't handle the fault, make
* sure we exit gracefully rather than endlessly redo the fault.
*/
/*为引发缺页的进程分配一个物理页框,它先确定与引发缺页的线性地址对应的各级页目录项是否存在,如不存在则分进行分配。具体如何分配这个页框是通过调用handle_pte_fault完成的*/
fault = handle_mm_fault(mm, vma, addr & PAGE_MASK, (fsr & FSR_WRITE) ? FAULT_FLAG_WRITE : 0);
if (unlikely(fault & VM_FAULT_ERROR))
return fault;
if (fault & VM_FAULT_MAJOR)
tsk->maj_flt++;
else
tsk->min_flt++;
return fault;
check_stack:
/*addr后面的vma的vm_flags含有VM_GROWSDOWN标志,这说明这个vma是属于栈的vma,所以addr是在栈中,有可能是栈空间不够时再进栈导致的访问错误,同时查看栈是否还能扩展,如果不能扩展(expand_stack返回非0)则确认确实是栈溢出导致,即addr确实是栈中地址,不是非法地址,应该进入缺页中的请求调页*/
if (vma->vm_flags & VM_GROWSDOWN && !expand_stack(vma, addr))
goto good_area;
out:
return fault;
}
l 首先,查看缺页异常的这个虚拟地址addr,找它后面最近的vma,如果真的没有找到,那么说明访问的地址是真的错误了,因为它根本不在所分配的任何一个vma线性区;这是一种严重错误,将返回错误码(fault)VM_FAULT_BADMAP,内核会杀掉这个进程;
l 如果addr后面有vma,但addr并未落在这个vma的区间内,这存在一种可能,要知道栈的增长方向和堆是相反的即栈是向下增长,所以也许addr实际上是栈的一个地址,它后面的vma实际上是栈的vma,栈已无法扩展,即访问addr时,这个addr并没有落在vma中所以更无二级页表映射,导致缺页异常,所以查看addr后面的vma是否是向下增长并且栈是否无法扩展,以此界定addr是不是栈地址,如果是则进入缺页异常处理流程,否则同样返回错误码(fault)VM_FAULT_BADMAP,内核会杀掉这个进程;
l 权限错误也就返回,比如缺页报错(fsr)报的是不可写,但vma本身就不可写,那么就直接返回,因为问题根本不是缺页,而是vma就已经有问题;返回错误码(fault) VM_FAULT_BADACCESS,这也是一种严重错误,内核会杀掉这个进程;s
l 最后是对确实缺页异常的情况进行处理,调用函数handle_mm_fault,正常情况下将返回VM_FAULT_MAJOR或VM_FAULT_MINOR,返回错误码fault并加一task的maj_flt或min_flt成员;
函数handle_mm_fault,就是为引发缺页的进程分配一个物理页框,它先确定与引发缺页的线性地址对应的各级页目录项是否存在,如不存在则分进行分配。具体如何分配这个页框是通过调用handle_pte_fault()完成的,注意最后一个参数flag,它来源于fsr,标识写异常和非写异常,这是为了达到进一步推后分配物理内存的一个铺垫;源码如下:
int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
__set_current_state(TASK_RUNNING);
count_vm_event(PGFAULT);
if (unlikely(is_vm_hugetlb_page(vma)))
return hugetlb_fault(mm, vma, address, flags);
/*返回addr对应的一级页表条目*/
pgd = pgd_offset(mm, address);
/*对于arm,pud就是pgd*/
pud = pud_alloc(mm, pgd, address);
if (!pud)
return VM_FAULT_OOM;
/*对于arm,pmd就是pud就是pgd*/
pmd = pmd_alloc(mm, pud, address);
if (!pmd)
return VM_FAULT_OOM;
/*返回addr对应的二级页表条目*/
pte = pte_alloc_map(mm, pmd, address);
if (!pte)
return VM_FAULT_OOM;
/*该函数根据页表项pte所描述的物理页框是否在物理内存中,分为两大类:
请求调页:被访问的页框不在主存中,那么此时必须分配一个页框,分为线性(匿名/文件)映射、非线性映射、swap情况下映射
写时复制:被访问的页存在,但是该页是只读的,内核需要对该页进行写操作,
此时内核将这个已存在的只读页中的数据复制到一个新的页框中*/
return handle_pte_fault(mm, vma, address, pte, pmd, flags);
}
首先注意下个细节,在二级页表条目不存在时,会先创建条目;最终会调用函数handle_pte_fault,该函数功能注释已经描述很清楚,源码如下:
static inline int handle_pte_fault(struct mm_struct *mm,
struct vm_area_struct *vma, unsigned long address,
pte_t *pte, pmd_t *pmd, unsigned int flags)
{
pte_t entry;
spinlock_t *ptl;
entry = *pte;
/*调页请求:分为线性(匿名/文件)映射、非线性映射、swap情况下映射
注意,pte_present(entry)为0说明二级页表条目pte映射的物理地址(即*pte)不存在,很可能是调页请求*/
if (!pte_present(entry)) {
/*(pte_none(entry))为1说明二级页表条目pte尚且没有写入任何物理地址,说明还根本从未分配物理页*/
if (pte_none(entry)) {
/*如果该vma的操作函数集合实现了fault函数,说明是文件映射而不是匿名映射,将调用do_linear_fault分配物理页*/
if (vma->vm_ops) {
if (likely(vma->vm_ops->fault))
return do_linear_fault(mm, vma, address,
pte, pmd, flags, entry);
}
/*匿名映射的情况分配物理页,最终调用alloc_pages*/
return do_anonymous_page(mm, vma, address,
pte, pmd, flags);
}
/*(pte_file(entry))说明是非线性映射,调用do_nonlinear_fault分配物理页*/
if (pte_file(entry))
return do_nonlinear_fault(mm, vma, address,
pte, pmd, flags, entry);
/*如果页框事先被分配,但是此刻已经由主存换出到了外存,则调用do_swap_page()完成页框分配*/
return do_swap_page(mm, vma, address,
pte, pmd, flags, entry);
}
/*写时复制
COW的场合就是访问映射的页不可写,有两种情况、:
一种是之前给vma映射的是零页(zero_pfn),
另外一种是访问fork得到的进程空间(子进程与父进程共享父进程的只读页)
共同特点就是: 二级页表条目不允许写,简单说就是该页不可写*/
ptl = pte_lockptr(mm, pmd);
spin_lock(ptl);
if (unlikely(!pte_same(*pte, entry)))
goto unlock;
/*是写操作时发生的缺页异常*/
if (flags & FAULT_FLAG_WRITE) {
/*二级页表条目不允许写,引发COW*/
if (!pte_write(entry))
return do_wp_page(mm, vma, address,
pte, pmd, ptl, entry);
/*标志本页已脏*/
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
if (ptep_set_access_flags(vma, address, pte, entry, flags & FAULT_FLAG_WRITE)) {
update_mmu_cache(vma, address, entry);
} else {
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (flags & FAULT_FLAG_WRITE)
flush_tlb_page(vma, address);
}
unlock:
pte_unmap_unlock(pte, ptl);
return 0;
}
回过头看下那四个异常的情况,上面的内容会比较好理解些,首先获取到二级页表条目值entry,对于写时复制的情况,它的异常addr的二级页表条目还是存在的(就是说起码存在标志L_PTE_PRESENT),只是说映射的物理页不可写,所以由(!pte_present(entry))可界定这是请求调页的情况;
在请求调页情况下,如果这个二级页表条目的值为0,即什么都没有,那么说明这个地址所在的vma是完完全全没有做过映射物理页的操作,那么根据该vma是否存在vm_ops成员即操作函数,并且vm_ops存在fault成员,这说明是文件映射而非匿名映射,反之是匿名映射,分别调用函数do_linear_fault、do_anonymous_page;
仍然在请求调页的情况下,如果二级页表条目的值含有L_PTE_FILE标志,说明这是个非线性文件映射,将调用函数do_nonlinear_fault分配物理页;其他情况视为物理页曾被分配过,但后来被linux交换出内存,将调用函数do_swap_page再分配物理页;
文件线性/非线性映射和交换分区的映射除请求调页方面外,还涉及文件、交换分区的很多内容,为简化起见,下面仅以匿名映射为例描述用户空间缺页异常的实际处理,而事实上日常使用的malloc都是匿名映射;
匿名映射体现了linux为进程分配物理空间的基本态度,不到实在不行的时候不分配物理页,当使用malloc/mmap申请映射一段物理空间时,内核只是给该进程创建了段线性区vma,但并未映射物理页,然后如果试图去读这段申请的进程空间,由于未创建相应的二级页表映射条目,MMU会发出缺页异常,而这时内核依然只是把一个默认的零页zero_pfn(这是在初始化时创建的,前面的内存页表的文章描述过)给vma映射过去,当应用程序又试图写这段申请的物理空间时,这就是实在不行的时候了,内核才会给vma映射物理页,源码如下:
static int do_anonymous_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
unsigned int flags)
{
struct page *page;
spinlock_t *ptl;
pte_t entry;
/*如果不是写操作的话(即读操作),那么非常简单,把zero_pfn的二级页表条目赋给entry,因为这里已经是缺页异常的请求调页的处理,又是读操作,所以肯定是本进程第一次访问这个页,所以这个页里面是什么内容无所谓,分配个默认全零页就好,进一步推迟物理页的分配,这就会让entry带着zero_pfn跳到标号setpte*/
if (!(flags & FAULT_FLAG_WRITE)) {
entry = pte_mkspecial(pfn_pte(my_zero_pfn(address),
vma->vm_page_prot));
ptl = pte_lockptr(mm, pmd);
spin_lock(ptl);
/*如果这个缺页的虚拟地址对应的二级页表条目所映射的内容居然在内存中,直接跳到标号unlock准备解锁返回*/
if (!pte_none(*page_table))
goto unlock;
/*跳到标号setpte就是写二级页表条目的内容即映射内容,对于这类就是把entry即zero_pfn写进去了*/
goto setpte;
}
/*如果是写操作,就要分配一个新的物理页了*/
/* Allocate our own private page. */
/*这里为空函数*/
pte_unmap(page_table);
/*分配一个anon_vma实例,反向映射相关,可暂不关注*/
if (unlikely(anon_vma_prepare(vma)))
goto oom;
/*它将调用alloc_page,这个页被0填充*/
page = alloc_zeroed_user_highpage_movable(vma, address);
if (!page)
goto oom;
__SetPageUptodate(page);
/*空函数*/
if (mem_cgroup_newpage_charge(page, mm, GFP_KERNEL))
goto oom_free_page;
/*把该页的物理地址加属性的值赋给entry,这是二级页表映射内容的基础值*/
entry = mk_pte(page, vma->vm_page_prot);
/*如果是写访问,那么设置这个二级页表条目属性还要加入:脏且可写*/
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
/*把page_table指向虚拟地址addr的二级页表条目地址*/
page_table = pte_offset_map_lock(mm, pmd, address, &ptl);
/*如果这个缺页的虚拟地址对应的二级页表条目所映射的内容居然在内存中,报错返回*/
if (!pte_none(*page_table))
goto release;
/*mm的rss成员加一,用于记录分配给本进程的物理页总数*/
inc_mm_counter(mm, anon_rss);
/*page_add_new_anon_rmap用于建立线性区和匿名页的反向映射,可暂不关注*/
page_add_new_anon_rmap(page, vma, address);
setpte:
/*给page_table这个二级页表条目写映射内容,内容是entry*/
set_pte_at(mm, address, page_table, entry);
/* No need to invalidate - it was non-present before */
/*更新MMU*/
update_mmu_cache(vma, address, entry);
unlock:
pte_unmap_unlock(page_table, ptl);
return 0;
release:
mem_cgroup_uncharge_page(page);
page_cache_release(page);
goto unlock;
oom_free_page:
page_cache_release(page);
oom:
return VM_FAULT_OOM;
}
结合上面的描述和源码注释应该比较容易能理解请求调页的原理和流程;
现在分析写时复制COW,对于写时复制,首先把握一点就是只有写操作时才有可能触发写时复制,所以首先总要判断异常flag是否含有标志FAULT_FLAG_WRITE,然后判断二级页表条目值是否含有L_PTE_WRITE标志,这是意味着这个物理页是否可写,如果不可写则说明应该进入写时复制流程,调用处理函数do_wp_page;
可见,COW的应用场合就是访问映射的页不可写,它包括两种情况,第一种是fork导致,第二种是如malloc后第一次对他进行读操作,获取到的是zero_pfn零页,当再次写时需要写时复制,共同特点都是虚拟地址的二级页表映射内容在内存中,但是对应的页不可写,在函数do_wp_page中对于这两种情况的处理基本相似的;
另外一个应该知道的是,如果该页只有一个进程在用,那么就直接修改这个页可写就行了,不要搞COW,总之,不到不得以的情况下是不会进行COW的,这也是内核对于COW使用的原则,就是尽量不使用;
函数do_wp_page源码如下:
static int do_wp_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
spinlock_t *ptl, pte_t orig_pte)
{
struct page *old_page, *new_page;
pte_t entry;
int reuse = 0, ret = 0;
int page_mkwrite = 0;
struct page *dirty_page = NULL;
/*返回不可写的页的页描述符,如果是COW的第一种情况即zero_pfn可读页,返回NULL,将进入下面的if流程;第二种情况即(父子进程)共享页将正常返回其页描述符*/
old_page = vm_normal_page(vma, address, orig_pte);
if (!old_page) {
/*
* VM_MIXEDMAP !pfn_valid() case
*
* We should not cow pages in a shared writeable mapping.
* Just mark the pages writable as we can't do any dirty
* accounting on raw pfn maps.
*/
/*如果这个vma是可写且共享的,跳到标号reuse,这就不会COW
否则跳到标号gotten*/
if ((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))
goto reuse;
goto gotten;
}
/*
* Take out anonymous pages first, anonymous shared vmas are
* not dirty accountable.
*/
/*下面的if和else流程,都是为了尽可能不进行COW,它们试图进入标号reuse*/
/*如果该页old_page是匿名页(由页描述符的mapping),
并且只有一个进程使用该页(reuse_swap_page,由页描述符的_mapcount值是否为0),那么不要搞什么COW了,这个进程就是可以使用该页*/
if (PageAnon(old_page) && !PageKsm(old_page)) {
/*排除其他进程在使用该页的情况,由页描述符的flag*/
if (!trylock_page(old_page)) {
page_cache_get(old_page);
pte_unmap_unlock(page_table, ptl);
lock_page(old_page);
page_table = pte_offset_map_lock(mm, pmd, address,
&ptl);
if (!pte_same(*page_table, orig_pte)) {
unlock_page(old_page);
page_cache_release(old_page);
goto unlock;
}
page_cache_release(old_page);
}
/*判断该页描述符的_mapcount值是否为0*/
reuse = reuse_swap_page(old_page);
unlock_page(old_page);
}
/*如果vma是共享且可写,看看这种情况下有没有机会不COW*/
else if (unlikely((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))) {
/*
* Only catch write-faults on shared writable pages,
* read-only shared pages can get COWed by
* get_user_pages(.write=1, .force=1).
*/
if (vma->vm_ops && vma->vm_ops->page_mkwrite) {
struct vm_fault vmf;
int tmp;
vmf.virtual_address = (void __user *)(address &
PAGE_MASK);
vmf.pgoff = old_page->index;
vmf.flags = FAULT_FLAG_WRITE|FAULT_FLAG_MKWRITE;
vmf.page = old_page;
/*
* Notify the address space that the page is about to
* become writable so that it can prohibit this or wait
* for the page to get into an appropriate state.
*
* We do this without the lock held, so that it can
* sleep if it needs to.
*/
page_cache_get(old_page);
pte_unmap_unlock(page_table, ptl);
tmp = vma->vm_ops->page_mkwrite(vma, &vmf);
if (unlikely(tmp &
(VM_FAULT_ERROR | VM_FAULT_NOPAGE))) {
ret = tmp;
goto unwritable_page;
}
if (unlikely(!(tmp & VM_FAULT_LOCKED))) {
lock_page(old_page);
if (!old_page->mapping) {
ret = 0; /* retry the fault */
unlock_page(old_page);
goto unwritable_page;
}
} else
VM_BUG_ON(!PageLocked(old_page));
/*
* Since we dropped the lock we need to revalidate
* the PTE as someone else may have changed it. If
* they did, we just return, as we can count on the
* MMU to tell us if they didn't also make it writable.
*/
page_table = pte_offset_map_lock(mm, pmd, address,
&ptl);
if (!pte_same(*page_table, orig_pte)) {
unlock_page(old_page);
page_cache_release(old_page);
goto unlock;
}
page_mkwrite = 1;
}
dirty_page = old_page;
get_page(dirty_page);
reuse = 1;
}
/*reuse: 不进行COW,直接操作该页old_page*/
if (reuse) {
reuse:
flush_cache_page(vma, address, pte_pfn(orig_pte));
entry = pte_mkyoung(orig_pte);
/*写该页的二级页表属性,加入可写且脏*/
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
if (ptep_set_access_flags(vma, address, page_table, entry,1))
update_mmu_cache(vma, address, entry);
ret |= VM_FAULT_WRITE;
goto unlock;
}
/*
* Ok, we need to copy. Oh, well..
*/
/*真正的COW即将开始*/
/*首先增加之前的页的被映射次数(get_page(), page->_count)*/
page_cache_get(old_page);
gotten:
pte_unmap_unlock(page_table, ptl);
if (unlikely(anon_vma_prepare(vma)))
goto oom;
/*COW的第一种情况(zero_pfn),将分配新页并清零该页*/
if (is_zero_pfn(pte_pfn(orig_pte))) {
new_page = alloc_zeroed_user_highpage_movable(vma, address);
if (!new_page)
goto oom;
}
/*COW的第二种情况(fork),申请一个页,并把old_page页的内容拷贝到新页new_page(4K字节的内容)*/
else {
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address);
if (!new_page)
goto oom;
cow_user_page(new_page, old_page, address, vma);
}
__SetPageUptodate(new_page);
/*
* Don't let another task, with possibly unlocked vma,
* keep the mlocked page.
*/
/*COW第二种情况下,如果vma还是锁定的,那还需要解锁*/
if ((vma->vm_flags & VM_LOCKED) && old_page) {
lock_page(old_page); /* for LRU manipulation */
clear_page_mlock(old_page);
unlock_page(old_page);
}
/*空函数*/
if (mem_cgroup_newpage_charge(new_page, mm, GFP_KERNEL))
goto oom_free_new;
/*
* Re-check the pte - we dropped the lock
*/
/*再获取下访问异常的地址addr对应的二级页表条目地址page_table*/
page_table = pte_offset_map_lock(mm, pmd, address, &ptl);
if (likely(pte_same(*page_table, orig_pte))) {
if (old_page) {
if (!PageAnon(old_page)) {
dec_mm_counter(mm, file_rss);
inc_mm_counter(mm, anon_rss);
}
} else
inc_mm_counter(mm, anon_rss);
flush_cache_page(vma, address, pte_pfn(orig_pte));
/*写新页的二级页表条目内容为脏*/
entry = mk_pte(new_page, vma->vm_page_prot);
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
/*
* Clear the pte entry and flush it first, before updating the
* pte with the new entry. This will avoid a race condition
* seen in the presence of one thread doing SMC and another
* thread doing COW.
*/
ptep_clear_flush(vma, address, page_table);
page_add_new_anon_rmap(new_page, vma, address);
/*
* We call the notify macro here because, when using secondary
* mmu page tables (such as kvm shadow page tables), we want the
* new page to be mapped directly into the secondary page table.
*/
set_pte_at_notify(mm, address, page_table, entry);
update_mmu_cache(vma, address, entry);
if (old_page) {
/*
* Only after switching the pte to the new page may
* we remove the mapcount here. Otherwise another
* process may come and find the rmap count decremented
* before the pte is switched to the new page, and
* "reuse" the old page writing into it while our pte
* here still points into it and can be read by other
* threads.
*
* The critical issue is to order this
* page_remove_rmap with the ptp_clear_flush above.
* Those stores are ordered by (if nothing else,)
* the barrier present in the atomic_add_negative
* in page_remove_rmap.
*
* Then the TLB flush in ptep_clear_flush ensures that
* no process can access the old page before the
* decremented mapcount is visible. And the old page
* cannot be reused until after the decremented
* mapcount is visible. So transitively, TLBs to
* old page will be flushed before it can be reused.
*/
page_remove_rmap(old_page);
}
/* Free the old page.. */
new_page = old_page;
ret |= VM_FAULT_WRITE;
}
else
mem_cgroup_uncharge_page(new_page);
if (new_page)
page_cache_release(new_page);
if (old_page)
page_cache_release(old_page);
unlock:
pte_unmap_unlock(page_table, ptl);
if (dirty_page) {
/*
* Yes, Virginia, this is actually required to prevent a race
* with clear_page_dirty_for_io() from clearing the page dirty
* bit after it clear all dirty ptes, but before a racing
* do_wp_page installs a dirty pte.
*
* do_no_page is protected similarly.
*/
if (!page_mkwrite) {
wait_on_page_locked(dirty_page);
set_page_dirty_balance(dirty_page, page_mkwrite);
}
put_page(dirty_page);
if (page_mkwrite) {
struct address_space *mapping = dirty_page->mapping;
set_page_dirty(dirty_page);
unlock_page(dirty_page);
page_cache_release(dirty_page);
if (mapping) {
/*
* Some device drivers do not set page.mapping
* but still dirty their pages
*/
balance_dirty_pages_ratelimited(mapping);
}
}
/* file_update_time outside page_lock */
if (vma->vm_file)
file_update_time(vma->vm_file);
}
return ret;
oom_free_new:
page_cache_release(new_page);
oom:
if (old_page) {
if (page_mkwrite) {
unlock_page(old_page);
page_cache_release(old_page);
}
page_cache_release(old_page);
}
return VM_FAULT_OOM;
unwritable_page:
page_cache_release(old_page);
return ret;
}
一级一级返回,最终返回到函数__do_page_fault,会根据返回值fault累计task的相应异常类型次数(maj_flt或min_flt),并最终把fault返回给函数do_page_fault,释放信号量mmap_sem,正常情况下就返回0,缺页异常处理完毕。
堆内内存还是堆外内存?
一般情况下,Java 中分配的非空对象都是由 Java 虚拟机的垃圾收集器管理的,也称为堆内内存(on-heap memory)。虚拟机会定期对垃圾内存进行回收,在某些特定的时间点,它会进行一次彻底的回收(full gc)。彻底回收时,垃圾收集器会对所有分配的堆内内存进行完整的扫描,这意味着一个重要的事实——这样一次垃圾收集对 Java 应用造成的影响,跟堆的大小是成正比的。过大的堆会影响 Java 应用的性能。
对于这个问题,一种解决方案就是使用堆外内存(off-heap memory)。堆外内存意味着把内存对象分配在 Java 虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
但是 Java 本身也在不断对堆内内存的实现方式做改进。两者各有什么优缺点? Vanilla Java 博客作者 Peter Lawrey 撰写了一篇文章,在文中他对三种方式:用 new 来分配对象、对象池(object pool)和堆外内存,进行了详细的分析。
用 new 来分配对象内存是最基本的一种方式,Lawery 提到:
在 Java 5.0 之前,分配对象的代价很大,以至于大家都使用内存池。但是从 5.0 开始,对象分配和垃圾回收变得快多了,研发人员发现了性能的提升,纷纷简化他们的代码,不再使用内存池,而直接用 new 来分配对象。从 5.0 开始,只有一些分配代价较大的对象,比如线程、套接字和数据库链接,用内存池才会有明显的性能提升。
对于内存池,Lawery 认为它主要用于两类对象。第一类是生命周期较短,且结构简单的对象,在内存池中重复利用这些对象能增加 CPU 缓存的命中率,从而提高性能。第二种情况是加载含有大量重复对象的大片数据,此时使用内存池能减少垃圾回收的时间。对此,Lawery 还以 StringInterner 为例进行了说明。
最后 Lawery 分析了堆外内存,它和内存池一样,也能缩短垃圾回收时间,但是它适用的对象和内存池完全相反。内存池往往适用于生命期较短的可变对象,而生命期中等或较长的对象,正是堆外内存要解决的。堆外内存有以下特点:
- 对于大内存有良好的伸缩性
- 对垃圾回收停顿的改善可以明显感觉到
- 在进程间可以共享,减少虚拟机间的复制
Lawery 还提到对外内存最重要的还不是它能改进性能,而是它的确定性。
当然堆外内存也有它自己的问题,最大的问题就是你的数据结构变得不那么直观,如果数据结构比较复杂,就要对它进行串行化(serialization),而串行化本身也会影响性能。另一个问题是由于你可以使用更大的内存,你可能开始担心虚拟内存(即硬盘)的速度对你的影响了。
Lawery 还介绍了 OpenHFT 公司提供三个开源库: Chronicle Queue 、 Chronicle Map 和 Thread Affinity ,这些库可以帮助开发人员使用堆外内存来保存数据。采用堆外内存有很多好处,同时也带来挑战,对堆外内存感兴趣的读者可以阅读 Lawery 的原文来了解更多信息。
JVM源码分析之堆外内存完全解读
概述
广义的堆外内存
说到堆外内存,那大家肯定想到堆内内存,这也是我们大家接触最多的,我们在jvm参数里通常设置-Xmx来指定我们的堆的最大值,不过这还不是我们理解的Java堆,-Xmx的值是新生代和老生代的和的最大值,我们在jvm参数里通常还会加一个参数-XX:MaxPermSize来指定持久代的最大值,那么我们认识的Java堆的最大值其实是-Xmx和-XX:MaxPermSize的总和,在分代算法下,新生代,老生代和持久代是连续的虚拟地址,因为它们是一起分配的,那么剩下的都可以认为是堆外内存(广义的)了,这些包括了jvm本身在运行过程中分配的内存,codecache,jni里分配的内存,DirectByteBuffer分配的内存等等
狭义的堆外内存
而作为java开发者,我们常说的堆外内存溢出了,其实是狭义的堆外内存,这个主要是指java.nio.DirectByteBuffer在创建的时候分配内存,我们这篇文章里也主要是讲狭义的堆外内存,因为它和我们平时碰到的问题比较密切
JDK/JVM里DirectByteBuffer的实现
DirectByteBuffer通常用在通信过程中做缓冲池,在mina,netty等nio框架中屡见不鲜,先来看看JDK里的实现:
|
|
通过上面的构造函数我们知道,真正的内存分配是使用的Bits.reserveMemory方法
|
|
通过上面的代码我们知道可以通过-XX:MaxDirectMemorySize来指定最大的堆外内存,那么我们首先引入两个问题
- 堆外内存默认是多大
- 为什么要主动调用System.gc()
堆外内存默认是多大
如果我们没有通过-XX:MaxDirectMemorySize来指定最大的堆外内存,那么默认的最大堆外内存是多少呢,我们还是通过代码来分析
上面的代码里我们看到调用了sun.misc.VM.maxDirectMemory()
|
|
看到上面的代码之后是不是误以为默认的最大值是64M?其实不是的,说到这个值得从java.lang.System这个类的初始化说起
|
|
上面这个方法在jvm启动的时候对System这个类做初始化的时候执行的,因此执行时间非常早,我们看到里面调用了sun.misc.VM.saveAndRemoveProperties(props):
|
|
如果我们通过-Dsun.nio.MaxDirectMemorySize指定了这个属性,只要它不等于-1,那效果和加了-XX:MaxDirectMemorySize一样的,如果两个参数都没指定,那么最大堆外内存的值来自于directMemory = Runtime.getRuntime().maxMemory(),这是一个native方法
|
|
其中在我们使用CMS GC的情况下的实现如下,其实是新生代的最大值-一个survivor的大小+老生代的最大值,也就是我们设置的-Xmx的值里除去一个survivor的大小就是默认的堆外内存的大小了
|
|
为什么要主动调用System.gc
既然要调用System.gc,那肯定是想通过触发一次gc操作来回收堆外内存,不过我想先说的是堆外内存不会对gc造成什么影响(这里的System.gc除外),但是堆外内存的回收其实依赖于我们的gc机制,首先我们要知道在java层面和我们在堆外分配的这块内存关联的只有与之关联的DirectByteBuffer对象了,它记录了这块内存的基地址以及大小,那么既然和gc也有关,那就是gc能通过操作DirectByteBuffer对象来间接操作对应的堆外内存了。DirectByteBuffer对象在创建的时候关联了一个PhantomReference,说到PhantomReference它其实主要是用来跟踪对象何时被回收的,它不能影响gc决策,但是gc过程中如果发现某个对象除了只有PhantomReference引用它之外,并没有其他的地方引用它了,那将会把这个引用放到java.lang.ref.Reference.pending队列里,在gc完毕的时候通知ReferenceHandler这个守护线程去执行一些后置处理,而DirectByteBuffer关联的PhantomReference是PhantomReference的一个子类,在最终的处理里会通过Unsafe的free接口来释放DirectByteBuffer对应的堆外内存块
JDK里ReferenceHandler的实现:
|
|
可见如果pending为空的时候,会通过lock.wait()一直等在那里,其中唤醒的动作是在jvm里做的,当gc完成之后会调用如下的方法VM_GC_Operation::doit_epilogue(),在方法末尾会调用lock的notify操作,至于pending队列什么时候将引用放进去的,其实是在gc的引用处理逻辑中放进去的,针对引用的处理后面可以专门写篇文章来介绍
|
|
对于System.gc的实现,之前写了一篇文章来重点介绍,JVM源码分析之SystemGC完全解读,它会对新生代的老生代都会进行内存回收,这样会比较彻底地回收DirectByteBuffer对象以及他们关联的堆外内存,我们dump内存发现DirectByteBuffer对象本身其实是很小的,但是它后面可能关联了一个非常大的堆外内存,因此我们通常称之为『冰山对象』,我们做ygc的时候会将新生代里的不可达的DirectByteBuffer对象及其堆外内存回收了,但是无法对old里的DirectByteBuffer对象及其堆外内存进行回收,这也是我们通常碰到的最大的问题,如果有大量的DirectByteBuffer对象移到了old,但是又一直没有做cms gc或者full gc,而只进行ygc,那么我们的物理内存可能被慢慢耗光,但是我们还不知道发生了什么,因为heap明明剩余的内存还很多(前提是我们禁用了System.gc)。
为什么要使用堆外内存
DirectByteBuffer在创建的时候会通过Unsafe的native方法来直接使用malloc分配一块内存,这块内存是heap之外的,那么自然也不会对gc造成什么影响(System.gc除外),因为gc耗时的操作主要是操作heap之内的对象,对这块内存的操作也是直接通过Unsafe的native方法来操作的,相当于DirectByteBuffer仅仅是一个壳,还有我们通信过程中如果数据是在Heap里的,最终也还是会copy一份到堆外,然后再进行发送,所以为什么不直接使用堆外内存呢。对于需要频繁操作的内存,并且仅仅是临时存在一会的,都建议使用堆外内存,并且做成缓冲池,不断循环利用这块内存。
为什么不能大面积使用堆外内存
如果我们大面积使用堆外内存并且没有限制,那迟早会导致内存溢出,毕竟程序是跑在一台资源受限的机器上,因为这块内存的回收不是你直接能控制的,当然你可以通过别的一些途径,比如反射,直接使用Unsafe接口等,但是这些务必给你带来了一些烦恼,Java与生俱来的优势被你完全抛弃了—开发不需要关注内存的回收,由gc算法自动去实现。另外上面的gc机制与堆外内存的关系也说了,如果一直触发不了cms gc或者full gc,那么后果可能很严重。
Reference 、ReferenceQueue 详解
ReferenceQueue
引用队列,在检测到适当的可到达性更改后,垃圾回收器将已注册的引用对象添加到该队列中
实现了一个队列的入队(enqueue)和出队(poll还有remove)操作,内部元素就是泛型的Reference,并且Queue的实现,是由Reference自身的链表结构( 单向循环链表 )所实现的。
ReferenceQueue名义上是一个队列,但实际内部并非有实际的存储结构,它的存储是依赖于内部节点之间的关系来表达。可以理解为queue是一个类似于链表的结构,这里的节点其实就是reference本身。可以理解为queue为一个链表的容器,其自己仅存储当前的head节点,而后面的节点由每个reference节点自己通过next来保持即可。
- 属性
head:始终保存当前队列中最新要被处理的节点,可以认为queue为一个后进先出的队列。当新的节点进入时,采取以下的逻辑:
r.next = (head == null) ? r : head;
head = r;然后,在获取的时候,采取相应的逻辑:
Reference<? extends T> r = head;
if (r != null) {
head = (r.next == r) ?
null :
r.next; // Unchecked due to the next field having a raw type in Reference
r.queue = NULL;
r.next = r;- 方法
enqueue():待处理引用入队
boolean enqueue(Reference<? extends T> r) { /* Called only by Reference class */
synchronized (lock) {
// Check that since getting the lock this reference hasn't already been
// enqueued (and even then removed)
ReferenceQueue<?> queue = r.queue;
if ((queue == NULL) || (queue == ENQUEUED)) {
return false;
}
assert queue == this;
r.queue = ENQUEUED;
r.next = (head == null) ? r : head;
head = r;
queueLength++;
if (r instanceof FinalReference) {
sun.misc.VM.addFinalRefCount(1);
}
lock.notifyAll(); // ①
return true;
}
}① lock.notifyAll(); 👈通知外部程序之前阻塞在当前队列之上的情况。( 即之前一直没有拿到待处理的对象,如ReferenceQueue的remove()方法 )
Reference
java.lang.ref.Reference 为 软(soft)引用、弱(weak)引用、虚(phantom)引用的父类。
因为Reference对象和垃圾回收密切配合实现,该类可能不能被直接子类化。
可以理解为Reference的直接子类都是由jvm定制化处理的,因此在代码中直接继承于Reference类型没有任何作用。但可以继承jvm定制的Reference的子类。
例如:Cleaner 继承了 PhantomReferencepublic class Cleaner extends PhantomReference<Object>
构造函数
其内部提供2个构造函数,一个带queue,一个不带queue。其中queue的意义在于,我们可以在外部对这个queue进行监控。即如果有对象即将被回收,那么相应的reference对象就会被放到这个queue里。我们拿到reference,就可以再作一些事务。
而如果不带的话,就只有不断地轮询reference对象,通过判断里面的get是否返回null( phantomReference对象不能这样作,其get始终返回null,因此它只有带queue的构造函数 )。这两种方法均有相应的使用场景,取决于实际的应用。如weakHashMap中就选择去查询queue的数据,来判定是否有对象将被回收。而ThreadLocalMap,则采用判断get()是否为null来作处理。
/* -- Constructors -- */
Reference(T referent) {
this(referent, null);
}
Reference(T referent, ReferenceQueue<? super T> queue) {
this.referent = referent;
this.queue = (queue == null) ? ReferenceQueue.NULL : queue;
}如果我们在创建一个引用对象时,指定了ReferenceQueue,那么当引用对象指向的对象达到合适的状态(根据引用类型不同而不同)时,GC 会把引用对象本身添加到这个队列中,方便我们处理它,因为“引用对象指向的对象 GC 会自动清理,但是引用对象本身也是对象(是对象就占用一定资源),所以需要我们自己清理。”
Reference链表结构内部主要的成员有
① pending 和 discovered
/* List of References waiting to be enqueued. The collector adds
* References to this list, while the Reference-handler thread removes
* them. This list is protected by the above lock object. The
* list uses the discovered field to link its elements.
*/
private static Reference<Object> pending = null;
/* When active: next element in a discovered reference list maintained by GC (or this if last)
* pending: next element in the pending list (or null if last)
* otherwise: NULL
*/
transient private Reference<T> discovered; /* used by VM */可以理解为jvm在gc时会将要处理的对象放到这个静态字段上面。同时,另一个字段discovered:表示要处理的对象的下一个对象。即可以理解要处理的对象也是一个链表,通过discovered进行排队,这边只需要不停地拿到pending,然后再通过discovered不断地拿到下一个对象赋值给pending即可,直到取到了最有一个。因为这个pending对象,两个线程都可能访问,因此需要加锁处理。
if (pending != null) {
r = pending;
// 'instanceof' might throw OutOfMemoryError sometimes
// so do this before un-linking 'r' from the 'pending' chain...
c = r instanceof Cleaner ? (Cleaner) r : null;
// unlink 'r' from 'pending' chain
pending = r.discovered;
r.discovered = null;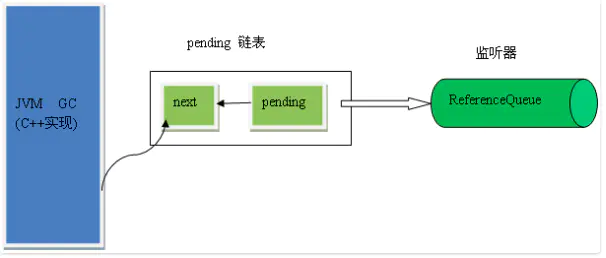
② referentprivate T referent; /* Treated specially by GC */
👆referent字段由GC特别处理
referent:表示其引用的对象,即我们在构造的时候需要被包装在其中的对象。对象即将被回收的定义:此对象除了被reference引用之外没有其它引用了( 并非确实没有被引用,而是gcRoot可达性不可达,以避免循环引用的问题 )。如果一旦被回收,则会直接置为null,而外部程序可通过引用对象本身( 而不是referent,这里是reference#get() )了解到回收行为的产生( PhntomReference除外 )。
③ next
/* When active: NULL
* pending: this
* Enqueued: next reference in queue (or this if last)
* Inactive: this
*/
@SuppressWarnings("rawtypes")
Reference next;next:即描述当前引用节点所存储的下一个即将被处理的节点。但next仅在放到queue中才会有意义( 因为,只有在enqueue的时候,会将next设置为下一个要处理的Reference对象 )。为了描述相应的状态值,在放到队列当中后,其queue就不会再引用这个队列了。而是引用一个特殊的ENQUEUED。因为已经放到队列当中,并且不会再次放到队列当中。
④ discovered
/* When active: next element in a discovered reference list maintained by GC (or this if last)
* pending: next element in the pending list (or null if last)
* otherwise: NULL
*/
transient private Reference<T> discovered; /* used by VM */👆被VM使用
discovered:当处于active状态时:discoverd reference的下一个元素是由GC操纵的( 如果是最后一个了则为this );当处于pending状态:discovered为pending集合中的下一个元素( 如果是最后一个了则为null );其他状态:discovered为null
⑤ lock
static private class Lock { }
private static Lock lock = new Lock();lock:在垃圾收集中用于同步的对象。收集器必须获取该锁在每次收集周期开始时。因此这是至关重要的:任何持有该锁的代码应该尽快完成,不分配新对象,并且避免调用用户代码。
⑥ pending
/* List of References waiting to be enqueued. The collector adds
* References to this list, while the Reference-handler thread removes
* them. This list is protected by the above lock object. The
* list uses the discovered field to link its elements.
*/
private static Reference<Object> pending = null;pending:等待被入队的引用列表。收集器会添加引用到这个列表,直到Reference-handler线程移除了它们。这个列表被上面的lock对象保护。这个列表使用discovered字段来连接它自己的元素( 即pending的下一个元素就是discovered对象 )。
⑦ queuevolatile ReferenceQueue<? super T> queue;
queue:是对象即将被回收时所要通知的队列。当对象即被回收时,整个reference对象( 而不是被回收的对象 )会被放到queue里面,然后外部程序即可通过监控这个queue拿到相应的数据了。
这里的queue( 即,ReferenceQueue对象 )名义上是一个队列,但实际内部并非有实际的存储结构,它的存储是依赖于内部节点之间的关系来表达。可以理解为queue是一个类似于链表的结构,这里的节点其实就是reference本身。可以理解为queue为一个链表的容器,其自己仅存储当前的head节点,而后面的节点由每个reference节点自己通过next来保持即可。
- Reference 实例( 即Reference中的真是引用对象referent )的4中可能的内部状态值
Queue的另一个作用是可以区分不同状态的Reference。Reference有4种状态,不同状态的reference其queue也不同:- Active:新创建的引用对象都是这个状态,在 GC 检测到引用对象已经到达合适的reachability时,GC 会根据引用对象是否在创建时制定ReferenceQueue参数进行状态转移,如果指定了,那么转移到Pending,如果没指定,转移到Inactive。
- Pending:pending-Reference列表中的引用都是这个状态,它们等着被内部线程ReferenceHandler处理入队(会调用ReferenceQueue.enqueue方法)。没有注册的实例不会进入这个状态。
- Enqueued:相应的对象已经为待回收,并且相应的引用对象已经放到queue当中了。准备由外部线程来询问queue获取相应的数据。调用ReferenceQueue.enqueued方法后的Reference处于这个状态中。当Reference实例从它的ReferenceQueue移除后,它将成为Inactive。没有注册的实例不会进入这个状态。
- Inactive:即此对象已经由外部从queue中获取到,并且已经处理掉了。即意味着此引用对象可以被回收,并且对内部封装的对象也可以被回收掉了( 实际的回收运行取决于clear动作是否被调用 )。可以理解为进入到此状态的肯定是应该被回收掉的。一旦一个Reference实例变为了Inactive,它的状态将不会再改变。
jvm并不需要定义状态值来判断相应引用的状态处于哪个状态,只需要通过计算next和queue即可进行判断。
- Active:queue为创建一个Reference对象时传入的ReferenceQueue对象;如果ReferenceQueue对象为空或者没有传入ReferenceQueue对象,则为ReferenceQueue.NULL;next==null;
- Pending:queue为初始化时传入ReferenceQueue对象;next==this(由jvm设置);
- Enqueue:当queue!=null && queue != ENQUEUED 时;设置queue为ENQUEUED;next为下一个要处理的reference对象,或者若为最后一个了next==this;
- Inactive:queue = ReferenceQueue.NULL; next = this.
通过这个组合,收集器只需要检测next属性为了决定是否一个Reference实例需要特殊的处理:如果next==null,则实例是active;如果next!=null,为了确保并发收集器能够发现active的Reference对象,而不会影响可能将enqueue()方法应用于这些对象的应用程序线程,收集器应通过discovered字段链接发现的对象。discovered字段也用于链接pending列表中的引用对象。


👆外部从queue中获取Reference
- WeakReference对象进入到queue之后,相应的referent为null。
- SoftReference对象,如果对象在内存足够时,不会进入到queue,自然相应的referent不会为null。如果需要被处理( 内存不够或其它策略 ),则置相应的referent为null,然后进入到queue。通过debug发现,SoftReference是pending状态时,referent就已经是null了,说明此事referent已经被GC回收了。
- FinalReference对象,因为需要调用其finalize对象,因此其reference即使入queue,其referent也不会为null,即不会clear掉。
- PhantomReference对象,因为本身get实现为返回null。因此clear的作用不是很大。因为不管enqueue还是没有,都不会清除掉。
Q:👆如果PhantomReference对象不管enqueue还是没有,都不会清除掉reference对象,那么怎么办?这个reference对象不就一直存在这了??而且JVM是会直接通过字段操作清除相应引用的,那么是不是JVM已经释放了系统底层资源,但java代码中该引用还未置null??
A:不会的,虽然PhantomReference有时候不会调用clear,如Cleaner对象 。但Cleaner的clean()方法只调用了remove(this),这样当clean()执行完后,Cleaner就是一个无引用指向的对象了,也就是可被GC回收的对象。
active ——> pending :Reference#tryHandlePending
pending ——> enqueue :ReferenceQueue#enqueue
enqueue ——> inactive :Reference#clear

重要方法
① clear()
/**
* Clears this reference object. Invoking this method will not cause this
* object to be enqueued.
*
* <p> This method is invoked only by Java code; when the garbage collector
* clears references it does so directly, without invoking this method.
*/
public void clear() {
this.referent = null;
}调用此方法不会导致此对象入队。此方法仅由Java代码调用;当垃圾收集器清除引用时,它直接执行,而不调用此方法。
clear的语义就是将referent置null。
清除引用对象所引用的原对象,这样通过get()方法就不能再访问到原对象了( PhantomReference除外 )。从相应的设计思路来说,既然都进入到queue对象里面,就表示相应的对象需要被回收了,因为没有再访问原对象的必要。此方法不会由JVM调用,而JVM是直接通过字段操作清除相应的引用,其具体实现与当前方法相一致。
② ReferenceHandler线程
static {
ThreadGroup tg = Thread.currentThread().getThreadGroup();
for (ThreadGroup tgn = tg;
tgn != null;
tg = tgn, tgn = tg.getParent());
Thread handler = new ReferenceHandler(tg, "Reference Handler");
/* If there were a special system-only priority greater than
* MAX_PRIORITY, it would be used here
*/
handler.setPriority(Thread.MAX_PRIORITY);
handler.setDaemon(true);
handler.start();
// provide access in SharedSecrets
SharedSecrets.setJavaLangRefAccess(new JavaLangRefAccess() {
@Override
public boolean tryHandlePendingReference() {
return tryHandlePending(false);
}
});
}其优先级最高,可以理解为需要不断地处理引用对象。
private static class ReferenceHandler extends Thread {
private static void ensureClassInitialized(Class<?> clazz) {
try {
Class.forName(clazz.getName(), true, clazz.getClassLoader());
} catch (ClassNotFoundException e) {
throw (Error) new NoClassDefFoundError(e.getMessage()).initCause(e);
}
}
static {
// pre-load and initialize InterruptedException and Cleaner classes
// so that we don't get into trouble later in the run loop if there's
// memory shortage while loading/initializing them lazily.
ensureClassInitialized(InterruptedException.class);
ensureClassInitialized(Cleaner.class);
}
ReferenceHandler(ThreadGroup g, String name) {
super(g, name);
}
public void run() {
while (true) {
tryHandlePending(true);
}
}
}③ tryHandlePending()
/**
* Try handle pending {@link Reference} if there is one.<p>
* Return {@code true} as a hint that there might be another
* {@link Reference} pending or {@code false} when there are no more pending
* {@link Reference}s at the moment and the program can do some other
* useful work instead of looping.
*
* @param waitForNotify if {@code true} and there was no pending
* {@link Reference}, wait until notified from VM
* or interrupted; if {@code false}, return immediately
* when there is no pending {@link Reference}.
* @return {@code true} if there was a {@link Reference} pending and it
* was processed, or we waited for notification and either got it
* or thread was interrupted before being notified;
* {@code false} otherwise.
*/
static boolean tryHandlePending(boolean waitForNotify) {
Reference<Object> r;
Cleaner c;
try {
synchronized (lock) {
if (pending != null) {
r = pending;
// 'instanceof' might throw OutOfMemoryError sometimes
// so do this before un-linking 'r' from the 'pending' chain...
c = r instanceof Cleaner ? (Cleaner) r : null;
// unlink 'r' from 'pending' chain
pending = r.discovered;
r.discovered = null;
} else {
// The waiting on the lock may cause an OutOfMemoryError
// because it may try to allocate exception objects.
if (waitForNotify) {
lock.wait();
}
// retry if waited
return waitForNotify;
}
}
} catch (OutOfMemoryError x) {
// Give other threads CPU time so they hopefully drop some live references
// and GC reclaims some space.
// Also prevent CPU intensive spinning in case 'r instanceof Cleaner' above
// persistently throws OOME for some time...
Thread.yield();
// retry
return true;
} catch (InterruptedException x) {
// retry
return true;
}
// Fast path for cleaners
if (c != null) {
c.clean();
return true;
}
ReferenceQueue<? super Object> q = r.queue;
if (q != ReferenceQueue.NULL) q.enqueue(r);
return true;
}这个线程在Reference类的static构造块中启动,并且被设置为高优先级和daemon状态。此线程要做的事情,是不断的检查pending 是否为null,如果pending不为null,则将pending进行enqueue,否则线程进入wait状态。
由此可见,pending是由jvm来赋值的,当Reference内部的referent对象的可达状态改变时,jvm会将Reference对象放入pending链表。并且这里enqueue的队列是我们在初始化( 构造函数 )Reference对象时传进来的queue,如果传入了null( 实际使用的是ReferenceQueue.NULL ),则ReferenceHandler则不进行enqueue操作,所以只有非RefernceQueue.NULL的queue才会将Reference进行enqueue。
ReferenceQueue是作为 JVM GC与上层Reference对象管理之间的一个消息传递方式,它使得我们可以对所监听的对象引用可达发生变化时做一些处理
参考
http://www.importnew.com/21633.html
http://hongjiang.info/java-referencequeue/
http://www.cnblogs.com/jabnih/p/6580665.html
http://www.importnew.com/20468.html
http://liujiacai.net/blog/2015/09/27/java-weakhashmap/
Java 引用类型简述
强引用 ( Strong Reference )
强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足的问题。 ps:强引用其实也就是我们平时A a = new A()这个意思。
- 强引用特性
- 强引用可以直接访问目标对象。
- 强引用所指向的对象在任何时候都不会被系统回收。
- 强引用可能导致内存泄漏。
Final Reference
- 当前类是否是finalizer类,注意这里finalizer是由JVM来标志的( 后面简称f类 ),并不是指java.lang.ref.Finalizer类。但是f类是会被JVM注册到java.lang.ref.Finalizer类中的。
① 当前类或父类中含有一个参数为空,返回值为void的名为finalize的方法。
② 并且该finalize方法必须非空
- GC 回收问题
- 对象因为Finalizer的引用而变成了一个临时的强引用,即使没有其他的强引用,还是无法立即被回收;
- 对象至少经历两次GC才能被回收,因为只有在FinalizerThread执行完了f对象的finalize方法的情况下才有可能被下次GC回收,而有可能期间已经经历过多次GC了,但是一直还没执行对象的finalize方法;
- CPU资源比较稀缺的情况下FinalizerThread线程有可能因为优先级比较低而延迟执行对象的finalize方法;
- 因为对象的finalize方法迟迟没有执行,有可能会导致大部分f对象进入到old分代,此时容易引发old分代的GC,甚至Full GC,GC暂停时间明显变长,甚至导致OOM;
- 对象的finalize方法被调用后,这个对象其实还并没有被回收,虽然可能在不久的将来会被回收。
详见:JVM源码分析之FinalReference完全解读 - 你假笨
软引用 ( Soft Reference )
是用来描述一些还有用但并非必须的对象。对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围之中进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。
对于软引用关联着的对象,如果内存充足,则垃圾回收器不会回收该对象,如果内存不够了,就会回收这些对象的内存。在 JDK 1.2 之后,提供了 SoftReference 类来实现软引用。软引用可用来实现内存敏感的高速缓存。软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。
注意:Java 垃圾回收器准备对SoftReference所指向的对象进行回收时,调用对象的 finalize() 方法之前,SoftReference对象自身会被加入到这个 ReferenceQueue 对象中,此时可以通过 ReferenceQueue 的 poll() 方法取到它们。
/**
* 软引用:对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围之中进行第二次回收( 因为是在第一次回收后才会发现内存依旧不充足,才有了这第二次回收 )。如果这次回收还没有足够的内存,才会抛出内存溢出异常。
* 对于软引用关联着的对象,如果内存充足,则垃圾回收器不会回收该对象,如果内存不够了,就会回收这些对象的内存。
* 通过debug发现,软引用在pending状态时,referent就已经是null了。
*
* 启动参数:-Xmx5m
*
*/
public class SoftReferenceDemo {
private static ReferenceQueue<MyObject> queue = new ReferenceQueue<>();
public static void main(String[] args) throws InterruptedException {
Thread.sleep(3000);
MyObject object = new MyObject();
SoftReference<MyObject> softRef = new SoftReference(object, queue);
new Thread(new CheckRefQueue()).start();
object = null;
System.gc();
System.out.println("After GC : Soft Get = " + softRef.get());
System.out.println("分配大块内存");
/**
* ====================== 控制台打印 ======================
* After GC : Soft Get = I am MyObject.
* 分配大块内存
* MyObject's finalize called
* Object for softReference is null
* After new byte[] : Soft Get = null
* ====================== 控制台打印 ======================
*
* 总共触发了 3 次 full gc。第一次有System.gc();触发;第二次在在分配new byte[5*1024*740]时触发,然后发现内存不够,于是将softRef列入回收返回,接着进行了第三次full gc。
*/
// byte[] b = new byte[5*1024*740];
/**
* ====================== 控制台打印 ======================
* After GC : Soft Get = I am MyObject.
* 分配大块内存
* Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
* at com.bayern.multi_thread.part5.SoftReferenceDemo.main(SoftReferenceDemo.java:21)
* MyObject's finalize called
* Object for softReference is null
* ====================== 控制台打印 ======================
*
* 也是触发了 3 次 full gc。第一次有System.gc();触发;第二次在在分配new byte[5*1024*740]时触发,然后发现内存不够,于是将softRef列入回收返回,接着进行了第三次full gc。当第三次 full gc 后发现内存依旧不够用于分配new byte[5*1024*740],则就抛出了OutOfMemoryError异常。
*/
byte[] b = new byte[5*1024*790];
System.out.println("After new byte[] : Soft Get = " + softRef.get());
}
public static class CheckRefQueue implements Runnable {
Reference<MyObject> obj = null;
@Override
public void run() {
try {
obj = (Reference<MyObject>) queue.remove();
} catch (InterruptedException e) {
e.printStackTrace();
}
if (obj != null) {
System.out.println("Object for softReference is " + obj.get());
}
}
}
public static class MyObject {
@Override
protected void finalize() throws Throwable {
System.out.println("MyObject's finalize called");
super.finalize();
}
@Override
public String toString() {
return "I am MyObject.";
}
}
}
弱引用 ( Weak Reference )
用来描述非必须的对象,但是它的强度比软引用更弱一些,被弱引用关联的对象只能生存到下一次垃圾收集发生之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。一旦一个弱引用对象被垃圾回收器回收,便会加入到一个注册引用队列中。
注意:Java 垃圾回收器准备对WeakReference所指向的对象进行回收时,调用对象的 finalize() 方法之前,WeakReference对象自身会被加入到这个 ReferenceQueue 对象中,此时可以通过 ReferenceQueue 的 poll() 方法取到它们。
/**
* 用来描述非必须的对象,但是它的强度比软引用更弱一些,被弱引用关联的对象只能生存到下一次垃圾收集发送之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。一旦一个弱引用对象被垃圾回收器回收,便会加入到一个注册引用队列中。
*/
public class WeakReferenceDemo {
private static ReferenceQueue<MyObject> queue = new ReferenceQueue<>();
public static void main(String[] args) {
MyObject object = new MyObject();
Reference<MyObject> weakRef = new WeakReference<>(object, queue);
System.out.println("创建的弱引用为 : " + weakRef);
new Thread(new CheckRefQueue()).start();
object = null;
System.out.println("Before GC: Weak Get = " + weakRef.get());
System.gc();
System.out.println("After GC: Weak Get = " + weakRef.get());
/**
* ====================== 控制台打印 ======================
* 创建的弱引用为 : java.lang.ref.WeakReference@1d44bcfa
* Before GC: Weak Get = I am MyObject
* After GC: Weak Get = null
* MyObject's finalize called
* 删除的弱引用为 : java.lang.ref.WeakReference@1d44bcfa , 获取到的弱引用的对象为 : null
* ====================== 控制台打印 ======================
*/
}
public static class CheckRefQueue implements Runnable {
Reference<MyObject> obj = null;
@Override
public void run() {
try {
obj = (Reference<MyObject>)queue.remove();
} catch (InterruptedException e) {
e.printStackTrace();
}
if(obj != null) {
System.out.println("删除的弱引用为 : " + obj + " , 获取到的弱引用的对象为 : " + obj.get());
}
}
}
public static class MyObject {
@Override
protected void finalize() throws Throwable {
System.out.println("MyObject's finalize called");
super.finalize();
}
@Override
public String toString() {
return "I am MyObject";
}
}
}
虚引用 ( Phantom Reference )
PhantomReference 是所有“弱引用”中最弱的引用类型。不同于软引用和弱引用,虚引用无法通过 get() 方法来取得目标对象的强引用从而使用目标对象,观察源码可以发现 get() 被重写为永远返回 null。
那虚引用到底有什么作用?其实虚引用主要被用来 跟踪对象被垃圾回收的状态,通过查看引用队列中是否包含对象所对应的虚引用来判断它是否 即将被垃圾回收,从而采取行动。它并不被期待用来取得目标对象的引用,而目标对象被回收前,它的引用会被放入一个 ReferenceQueue 对象中,从而达到跟踪对象垃圾回收的作用。
当phantomReference被放入队列时,说明referent的finalize()方法已经调用,并且垃圾收集器准备回收它的内存了。
注意:PhantomReference 只有当 Java 垃圾回收器对其所指向的对象真正进行回收时,会将其加入到这个 ReferenceQueue 对象中,这样就可以追综对象的销毁情况。这里referent对象的finalize()方法已经调用过了。
所以具体用法和之前两个有所不同,它必须传入一个 ReferenceQueue 对象。当虚引用所引用对象准备被垃圾回收时,虚引用会被添加到这个队列中。
Demo1:
/**
* 虚引用也称为幽灵引用或者幻影引用,它是最弱的一种引用关系。一个持有虚引用的对象,和没有引用几乎是一样的,随时都有可能被垃圾回收器回收。
* 虚引用必须和引用队列一起使用,它的作用在于跟踪垃圾回收过程。
* 当phantomReference被放入队列时,说明referent的finalize()方法已经调用,并且垃圾收集器准备回收它的内存了。
*/
public class PhantomReferenceDemo {
private static ReferenceQueue<MyObject> queue = new ReferenceQueue<>();
public static void main(String[] args) throws InterruptedException {
MyObject object = new MyObject();
Reference<MyObject> phanRef = new PhantomReference<>(object, queue);
System.out.println("创建的虚拟引用为 : " + phanRef);
new Thread(new CheckRefQueue()).start();
object = null;
int i = 1;
while (true) {
System.out.println("第" + i++ + "次GC");
System.gc();
TimeUnit.SECONDS.sleep(1);
}
/**
* ====================== 控制台打印 ======================
* 创建的虚拟引用为 : java.lang.ref.PhantomReference@1d44bcfa
* 第1次GC
* MyObject's finalize called
* 第2次GC
* 删除的虚引用为: java.lang.ref.PhantomReference@1d44bcfa , 获取虚引用的对象 : null
* ====================== 控制台打印 ======================
*
* 再经过一次GC之后,系统找到了垃圾对象,并调用finalize()方法回收内存,但没有立即加入PhantomReference Queue中。因为MyObject对象重写了finalize()方法,并且该方法是一个非空实现,所以这里MyObject也是一个Final Reference。所以第一次GC完成的是Final Reference的事情。
* 第二次GC时,该对象(即,MyObject)对象会真正被垃圾回收器进行回收,此时,将PhantomReference加入虚引用队列( PhantomReference Queue )。
* 而且每次gc之间需要停顿一些时间,已给JVM足够的处理时间;如果这里没有TimeUnit.SECONDS.sleep(1); 可能需要gc到第5、6次才会成功。
*/
}
public static class MyObject {
@Override
protected void finalize() throws Throwable {
System.out.println("MyObject's finalize called");
super.finalize();
}
@Override
public String toString() {
return "I am MyObject";
}
}
public static class CheckRefQueue implements Runnable {
Reference<MyObject> obj = null;
@Override
public void run() {
try {
obj = (Reference<MyObject>)queue.remove();
System.out.println("删除的虚引用为: " + obj + " , 获取虚引用的对象 : " + obj.get());
System.exit(0);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}Q:👆了解下System.gc()操作,如果连续调用,若前一次没完成,后一次可能会失效,所以连接调用System.gc()其实作用不大?
A:关于上面例子的问题我们要补充两点
① 首先我们先来看下System.gc()的doc文档:
/**
* Runs the garbage collector.
* <p>
* Calling the <code>gc</code> method suggests that the Java Virtual
* Machine expend effort toward recycling unused objects in order to
* make the memory they currently occupy available for quick reuse.
* When control returns from the method call, the Java Virtual
* Machine has made a best effort to reclaim space from all discarded
* objects.
* <p>
* The call <code>System.gc()</code> is effectively equivalent to the
* call:
* <blockquote><pre>
* Runtime.getRuntime().gc()
* </pre></blockquote>
*
* @see java.lang.Runtime#gc()
*/
public static void gc() {
Runtime.getRuntime().gc();
}当这个方法返回的时候,Java虚拟机已经尽最大努力去回收所有丢弃对象的空间了。
因此不存在这System.gc()操作连续调用时,若前一次没完成,后一次可能会失效的情况。以及“所以连接调用System.gc()其实作用不大”这个说法不对,应该说连续调用System.gc()对性能可定是有影响的,但作用之一就是可以清除“漂浮垃圾”。
② 同时需要特别注意的是对于已经没有地方引用的这些f对象,并不会在最近的那一次gc里马上回收掉,而是会延迟到下一个或者下几个gc时才被回收,因为执行finalize方法的动作无法在gc过程中执行,万一finalize方法执行很长呢,所以只能在这个gc周期里将这个垃圾对象重新标活,直到执行完finalize方法将Final Reference从queue里删除,这样下次gc的时候就真的是漂浮垃圾了会被回收。
Demo2:
public class PhantomReferenceDemo2 {
public static void main(String[] args) {
ReferenceQueue<MyObject> queue = new ReferenceQueue<>();
MyObject object = new MyObject();
Reference<MyObject> phanRef = new PhantomReference<>(object, queue);
System.out.println("创建的虚拟引用为 : " + phanRef);
object = null;
System.out.println(phanRef.get());
System.gc();
System.out.println("referent : " + phanRef);
System.out.println(queue.poll() == phanRef); //true
/**
* ====================== 控制台打印 ======================
* 创建的虚拟引用为 : java.lang.ref.PhantomReference@1d44bcfa
* null
* referent : java.lang.ref.PhantomReference@1d44bcfa
* true
* ====================== 控制台打印 ======================
*
* 这里因为MyObject没有重写finalize()方法,所以这里的在System.gc()后就会处理PhantomReference加入到PhantomReference Queue中。
*/
}
public static class MyObject {
@Override
public String toString() {
return "I am MyObject";
}
}
}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号