Oracle的nlssort函数
-
lssort函数的作用是对字段排序,字符串类型的
1.按拼音排序:
select * from MEMBER t order by NLSSORT(t.b,'NLS_SORT = SCHINESE_PINYIN_M')
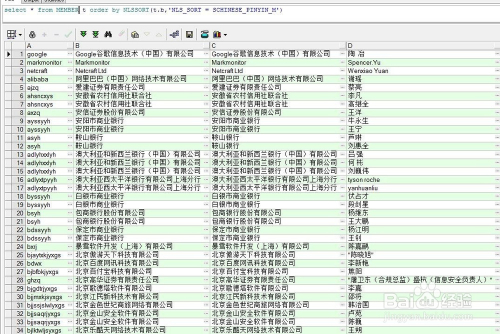
2.按笔画排序:
select * from MEMBER t order by NLSSORT(t.b,'NLS_SORT = SCHINESE_STROKE_M')
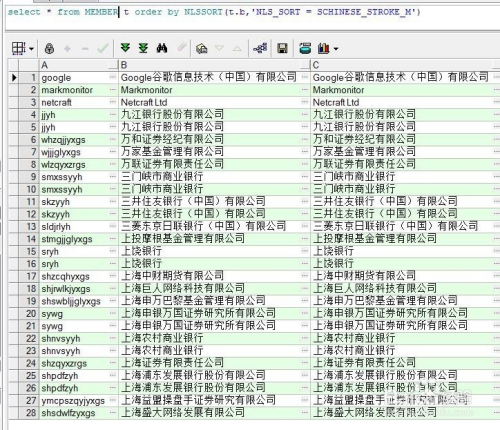
3.按部首排序:
select * from MEMBER t order by NLSSORT(t.b,'NLS_SORT = SCHINESE_RADICAL_M')
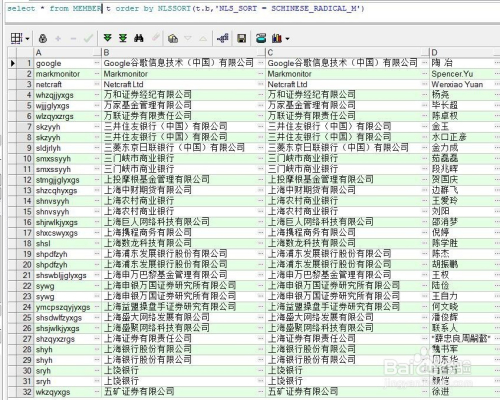
java 汉字按照拼音排序
数据库中按照拼音排序很简单
SELECT DISTINCT province_name, province_code FROM `metadata_township` ORDER BY convert(province_name USING gbk) asc一般的排序都是能正确的,但是有的多音字啥的会有点差别,例如重庆,按理说是重是“chong”,但是排序的时候会按照“zhong”,就会排在靠后的。
Java中按照拼音排序
我的list里面是对象,对象里面含有需要按照拼音排序的字段name,我用的lambda表达式来简化代码。
-
/**
-
*(o1, o2) -> Collator.getInstance(Locale.CHINA).compare(o1.getName(), o2.getName()) 排序规则,根据汉字的拼音来排序(升序)
-
* list 是需要排序的集合
-
*/
-
Collections.sort(list,(o1, o2) -> Collator.getInstance(Locale.CHINA).compare(o1.getName(), o2.getName()));
根据这个得到的排序大部分都是正确的,跟前面sql里面排序的结果差不多,多音字,生僻字会不准确。
- 默认的
Collection.sort()是按照ASCII码排序, 不过, 有第二个重载方法, 第二个参数可以传入Comparator对象 java.text.Collator可以用于本地语言排序, 自身已经实现Comparator接口.Collator.getInstance(Locale.CHINA)获取到我们中文的Collator实例
/** * 按照拼音首字母排序 */ @Test public void test() { List<String> data = new ArrayList<>(Arrays.asList("上海", "天津", "北京", "深圳", "广州", "成都", "西安", "武汉", "郑州", "邯郸", "a", "z", "A", "Z")); Collator collator = Collator.getInstance(Locale.CHINA); Collections.sort(data, collator); for (String str : data) { System.out.print(str + " "); } }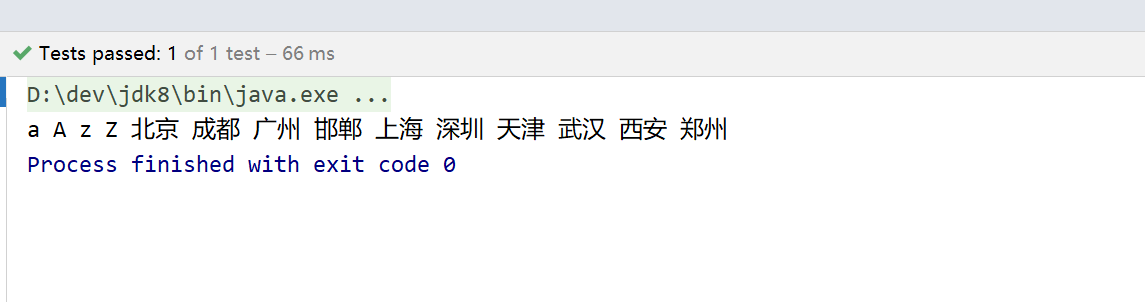
java实现按拼音排序

List<WaPayFileVO> list =(List<WaPayFileVO>) dao.execQueryBeanList(pagesql, params.toArray(), new BeanListProcessor(WaPayFileVO.class)); if("asc".equals(page.getOrder()) && "pk_psnjob__pk_psndoc__name".equals(page.getSort())){ Collections.sort(list, new Comparator<WaPayFileVO>() { @Override public int compare(WaPayFileVO o1, WaPayFileVO o2) { return Collator.getInstance(Locale.CHINESE).compare(o1.getPk_psnjob__pk_psndoc__name(),o2.getPk_psnjob__pk_psndoc__name()); } }); }else if("desc".equals(page.getOrder()) && "pk_psnjob__pk_psndoc__name".equals(page.getSort())){ Collections.sort(list, new Comparator<WaPayFileVO>() { @Override public int compare(WaPayFileVO o1, WaPayFileVO o2) { return -Collator.getInstance(Locale.CHINESE).compare(o1.getPk_psnjob__pk_psndoc__name(),o2.getPk_psnjob__pk_psndoc__name()); } }); }
jdk自带的Collator包涵的汉字太少了,对一些生僻的姓氏不能进行排序。推荐使用:
import com.ibm.icu.text.Collator;
是ibm开发的针对编码的工具包,非常好用。附pom文件:
<dependency> <groupId>com.ibm.icu</groupId> <artifactId>icu4j</artifactId> <version>57.1</version> </dependency>业务场景:
一个list集合,里面add了若干个实体类,针对该实体类排序的属性为String。
使用技术,自定义list排序(JDK自带),重写Comparator接口的compare方法,汉字转拼音技术:使用的pinyin4j。
pinyin4j官网地址:http://pinyin4j.sourceforge.net/
不想去官网下载的我这里也有,地址为:
//tempRateList 为需要进行自定义排序的集合,SpRate为该集合的实体类,riskName为排序的属性。
直接上方案:
1、导入pinyin4j-2.5.0.jar;
2、对自定义排序的类使用以下方法进行自定义排序;
- Collections.sort(tempRateList,new Comparator<SpRate>() {
- @Override
- public int compare(SpRate s1, SpRate s2) {
- String o1 = s1.getRiskName();
- String o2 = s2.getRiskName();
- for (int i = 0; i < o1.length() && i < o2.length(); i++) {
- int codePoint1 = o1.charAt(i);
- int codePoint2 = o2.charAt(i);
- if (Character.isSupplementaryCodePoint(codePoint1)
- || Character.isSupplementaryCodePoint(codePoint2)) {
- i++;
- }
- if (codePoint1 != codePoint2) {
- if (Character.isSupplementaryCodePoint(codePoint1)
- || Character.isSupplementaryCodePoint(codePoint2)) {
- return codePoint1 - codePoint2;
- }
- String pinyin1 = PinyinHelper.toHanyuPinyinStringArray((char) codePoint1) == null
- ? null : PinyinHelper.toHanyuPinyinStringArray((char) codePoint1)[0];
- String pinyin2 = PinyinHelper.toHanyuPinyinStringArray((char) codePoint2) == null
- ? null : PinyinHelper.toHanyuPinyinStringArray((char) codePoint2)[0];
- if (pinyin1 != null && pinyin2 != null) { // 两个字符都是汉字
- if (!pinyin1.equals(pinyin2)) {
- return pinyin1.compareTo(pinyin2);
- }
- } else {
- return codePoint1 - codePoint2;
- }
- }
- }
- return o1.length() - o2.length();
- }
- });
3、方法结束后 tempRateList 对象就完成了自定义排序 -

 浙公网安备 33010602011771号
浙公网安备 33010602011771号