深入理解GOT表和PLT表
0x01 前言
操作系统通常使用动态链接的方法来提高程序运行的效率。在动态链接的情况下,程序加载的时候并不会把链接库中所有函数都一起加载进来,而是程序执行的时候按需加载,如果有函数并没有被调用,那么它就不会在程序生命中被加载进来。这样的设计就能提高程序运行的流畅度,也减少了内存空间。而且现代操作系统不允许修改代码段,只能修改数据段,那么GOT表与PLT表就应运而生。
0x02 初探GOT表和PLT表
我们先简单看一个例子
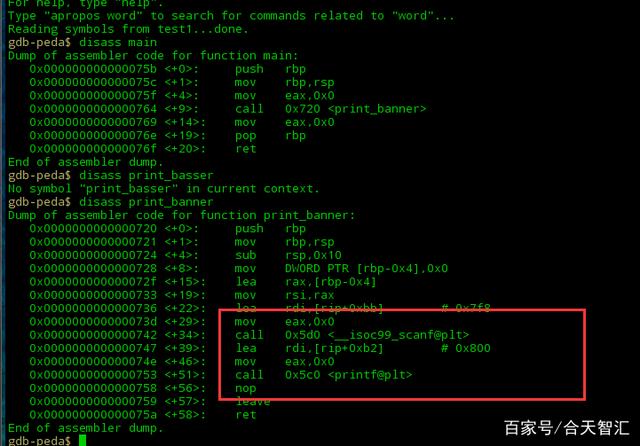
我们跟进一下scanf@plt

会发现,有三行代码

看函数的名字就可以知道这是scanf函数的plt表,先不着急去了解plt是做什么用的,我们继续往下看我们先看一下第一个jmp是什么跳到哪里。
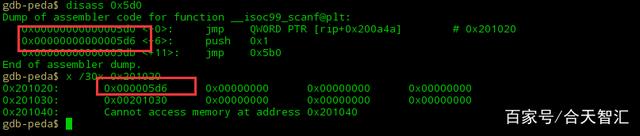
其实这是plt表对应函数的got表,而且我们会发现0x201020的值是压栈命令的地址,其他地方为0,此时就想问:
一、got表与plt表有什么意义,为什么要跳来跳去?
二、got表与plt表有什么联系,有木有什么对应关系?
那么带着疑问先看答案,再去印证我们要明白操作系统通常使用动态链接的方法来提高程序运行的效率,而且不能回写到代码段上。
在上面例子中我们可以看到,call scanf —> scanf的plt表 —>scanf的got表,至于got表的值暂时先不管,我们此刻可以形成这样一个思维,它能从got表中找到真实的scanf函数供程序加载运行。
我们这么认为后,那么这就变成了一个间接寻址的过程
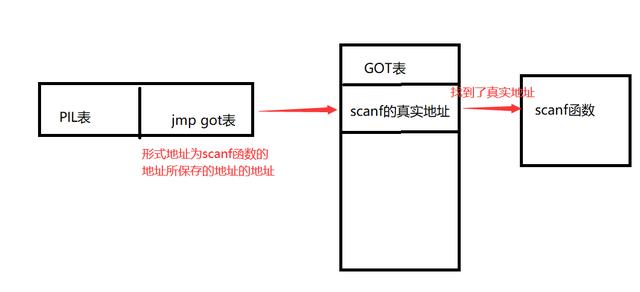
我们就把获取数据段存放函数地址的那一小段代码称为PLT(Procedure Linkage Table)过程链接表存放函数地址的数据段称为GOT(Global Offset Table)全局偏移表。我们形成这么一个思维后,再去仔细理解里面的细节。
0x03 再探GOT表和PLT表
已经明白了这么一个大致过程后,我们来看一下这其中是怎么一步一步调用的上面有几个疑点需要去解决:
一、got表怎么知道scanf函数的真实地址?
二、got表与plt表的结构是什么?我们先来看plt表刚才发现scanf@plt表低三行代码是 jmp 一个地址 ,跟进看一下是什么
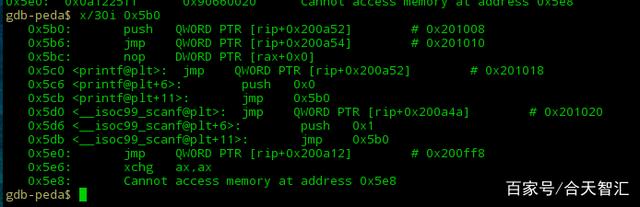
其实这是一个程序PLT表的开始(plt[0]),它做的事情是:

后面是每个函数的plt表。此时我们再看一下这个神秘的GOT表

除了这两个(printf和scanf函数的push 0xn的地址,也就是对应的plt表的第二条代码的地址),其它的got[1], got[2] 为0,那么plt表指向为0的got表干什么呢?因为我们落下了一个条件,现代操作系统不允许修改代码段,只能修改数据段,也就是回写,更专业的称谓应该是运行时重定位。我们把程序运行起来,我们之前的地址和保存的内容就变了在这之前,我们先把链接时的内容保存一下,做一个对比
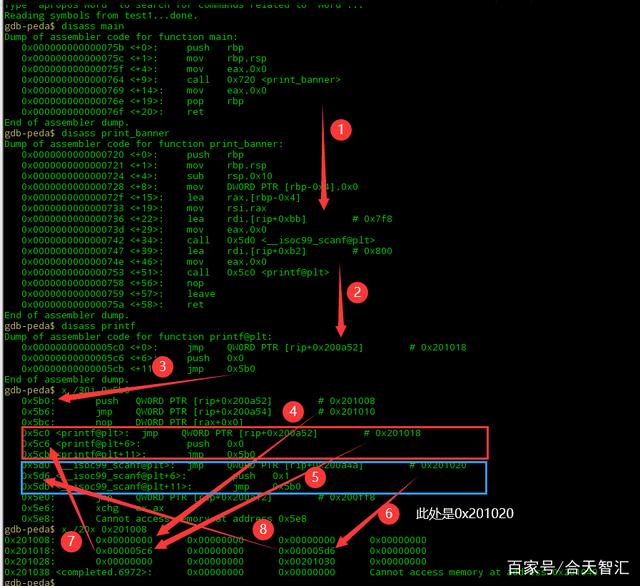

运行程序,在scanf处下断点
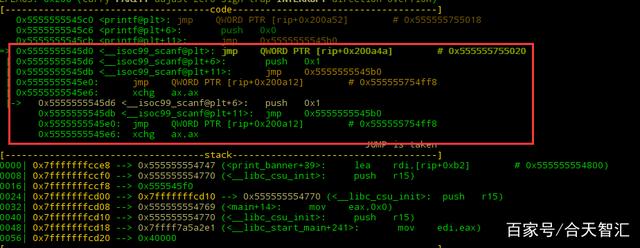
可以发现,此时scanf@plt表变了,查看got[4]里内容

依然是push 0x1所在地址继续调试,直到这里,got[4]地址被修改
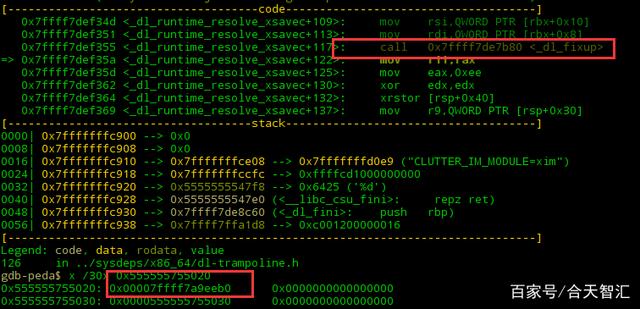
此时想问了,这是哪里?

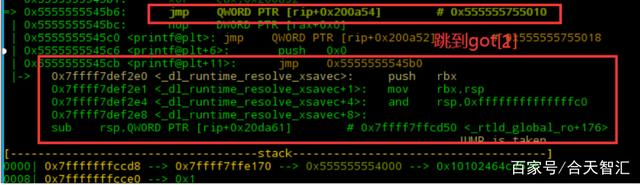
然后就是got[2]中call<_dl_fixup>从而修改got[3]中的地址;
那么问题就来了,刚才got[2]处不是0吗,怎么现在又是这个(_dl_runtime_resolve)?这就是运行时重定位。
其实got表的前三项是:
got[0]:address of .dynamic section 也就是本ELF动态段(.dynamic段)的装载地址
got[1]:address of link_map object( 编译时填充0)也就是本ELF的link_map数据结构描述符地址,作用:link_map结构,结合.rel.plt段的偏移量,才能真正找到该elf的.rel.plt表项。
got[2]:address of _dl_runtime_resolve function (编译时填充为0) 也就是_dl_runtime_resolve函数的地址,来得到真正的函数地址,回写到对应的got表位置中。
那么此刻,got表怎么知道scanf函数的真实地址?
这个问题已经解决了。我们可以看一下其中的装载过程:
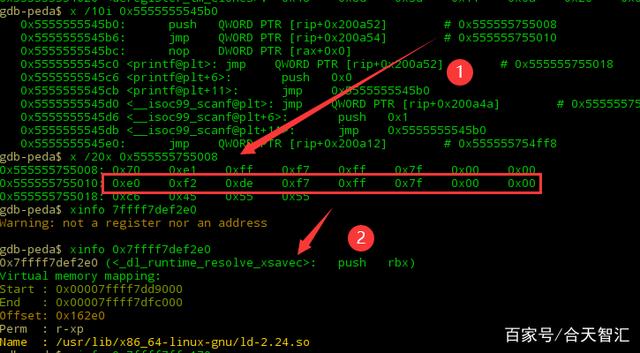
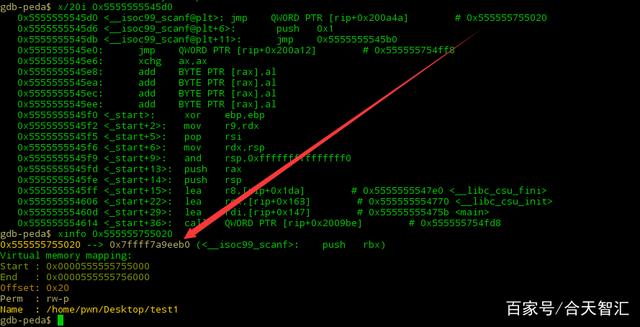
说到这个,可以看到在_dl_runtimw_resolve之前和之后,会将真正的函数地址,也就是glibc运行库中的函数的地址,回写到代码段,就是got[n](n>=3)中。也就是说在函数第一次调用时,才通过连接器动态解析并加载到.got.plt中,而这个过程称之为延时加载或者惰性加载。
到这里,也要接近尾声了,当第二次调用同一个函数的时候,就不会与第一次一样那么麻烦了,因为got[n]中已经有了真实地址,直接jmp该地址即可。
0x04 尾记
只是个人的见解,如有错误,希望各位大佬指
32 | 答疑(四):阻塞、非阻塞 I/O 与同步、异步 I/O 的区别和联系
问题 1:阻塞、非阻塞 I/O 与同步、异步 I/O 的区别和联系
在文件系统的工作原理篇中,介绍了阻塞、非阻塞 I/O 以及同步、异步 I/O 的含义,这里我们再简单回顾一下。
首先我们来看阻塞和非阻塞 I/O。根据应用程序是否阻塞自身运行,可以把 I/O 分为阻塞 I/O 和非阻塞 I/O。
- 所谓阻塞 I/O,是指应用程序在执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,不能执行其他任务。
- 所谓非阻塞 I/O,是指应用程序在执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务。
再来看同步 I/O 和异步 I/O。根据 I/O 响应的通知方式的不同,可以把文件 I/O 分为同步 I/O 和异步 I/O。
- 所谓同步 I/O,是指收到 I/O 请求后,系统不会立刻响应应用程序;等到处理完成,系统才会通过系统调用的方式,告诉应用程序 I/O 结果。
- 所谓异步 I/O,是指收到 I/O 请求后,系统会先告诉应用程序 I/O 请求已经收到,随后再去异步处理;等处理完成后,系统再通过事件通知的方式,告诉应用程序结果。
你可以看出,阻塞 / 非阻塞和同步 / 异步,其实就是两个不同角度的 I/O 划分方式。它们描述的对象也不同,阻塞 / 非阻塞针对的是 I/O 调用者(即应用程序),而同步 / 异步针对的是 I/O 执行者(即系统)。
我举个例子来进一步解释下。比如在 Linux I/O 调用中,
- 系统调用 read 是同步读,所以,在没有得到磁盘数据前,read 不会响应应用程序。
- 而 aio_read 是异步读,系统收到 AIO 读请求后不等处理就返回了,而具体的 read 结果,再通过回调异步通知应用程序。
再如,在网络套接字的接口中,
- 使用 send() 直接向套接字发送数据时,如果套接字没有设置 O_NONBLOCK 标识,那么 send() 操作就会一直阻塞,当前线程也没法去做其他事情。
- 当然,如果你用了 epoll,系统会告诉你这个套接字的状态,那就可以用非阻塞的方式使用。当这个套接字不可写的时候,你可以去做其他事情,比如读写其他套接字。
问题 2:“文件系统”课后思考
| $ vmstat 1 | |
| procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- | |
| r b swpd free buff cache si so bi bo in cs us sy id wa st | |
| 0 1 0 7563744 6024 225944 0 0 3736 0 574 3249 3 5 89 3 0 | |
| 1 0 0 7542792 14736 236856 0 0 8708 0 13494 32335 8 19 66 7 0 | |
| 0 1 0 7494452 27280 272284 0 0 12544 0 4550 17084 5 15 68 13 0 | |
| 0 1 0 7475084 42380 276320 0 0 15096 0 2541 14253 2 6 78 13 0 | |
| 0 1 0 7455728 57600 280436 0 0 15220 0 2025 14518 2 6 70 22 0 |
问题 3:“磁盘 I/O 延迟”课后思考
问题 4:“MySQL 案例”课后思考
| $ vmstat 1 | |
| procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- | |
| r b swpd free buff cache si so bi bo in cs us sy id wa st | |
| # 备注: DataService 正在运行 | |
| 0 1 0 7293416 132 366704 0 0 32516 12 36 546 1 3 49 48 0 | |
| 0 1 0 7260772 132 399256 0 0 32640 0 37 463 1 1 49 48 0 | |
| 0 1 0 7228088 132 432088 0 0 32640 0 30 477 0 1 49 49 0 | |
| 0 0 0 7306560 132 353084 0 0 20572 4 90 574 1 4 69 27 0 | |
| 0 2 0 7282300 132 368536 0 0 15468 0 32 304 0 0 79 20 0 | |
| # 备注:DataService 从这里开始停止 | |
| 0 0 0 7241852 1360 424164 0 0 864 320 133 1266 1 1 94 5 0 | |
| 0 1 0 7228956 1368 437400 0 0 13328 0 45 366 0 0 83 17 0 | |
| 0 1 0 7196320 1368 470148 0 0 32640 0 33 413 1 1 50 49 0 | |
| ... | |
| 0 0 0 6747540 1368 918576 0 0 29056 0 42 568 0 0 56 44 0 | |
| 0 0 0 6747540 1368 918576 0 0 0 0 40 141 1 0 100 0 0 |
24丨基础篇:Linux磁盘I-O是怎么工作的(上)
- 目录项,记录了文件的名字,以及文件与其他目录项之间的目录关系。
- 索引节点,记录了文件的元数据。
- 逻辑块,是由连续磁盘扇区构成的最小读写单元,用来存储文件数据。
- 超级块,用来记录文件系统整体的状态,如索引节点和逻辑块的使用情况等。
磁盘
根据存储介质
机械磁盘
固态磁盘
- 对机械磁盘来说,我们刚刚提到过的,由于随机 I/O 需要更多的磁头寻道和盘片旋转,它的性能自然要比连续 I/O 慢。
- 而对固态磁盘来说,虽然它的随机性能比机械硬盘好很多,但同样存在“先擦除再写入”的限制。随机读写会导致大量的垃圾回收,所以相对应的,随机 I/O 的性能比起连续 I/O 来,也还是差了很多。
- 此外,连续 I/O 还可以通过预读的方式,来减少 I/O 请求的次数,这也是其性能优异的一个原因。很多性能优化的方案,也都会从这个角度出发,来优化 I/O 性能。
- 机械磁盘的最小读写单位是扇区,一般大小为 512 字节。
- 而固态磁盘的最小读写单位是页,通常大小是 4KB、8KB 等。
按照接口来分类
- RAID0 有最优的读写性能,但不提供数据冗余的功能。
- 而其他级别的 RAID,在提供数据冗余的基础上,对读写性能也有一定程度的优化。
通用块层
- 第一个功能跟虚拟文件系统的功能类似。向上,为文件系统和应用程序,提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
- 第二个功能,通用块层还会给文件系统和应用程序发来的 I/O 请求排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
四种 I/O 调度算法
- 第一种 NONE ,更确切来说,并不能算 I/O 调度算法。因为它完全不使用任何 I/O 调度器,对文件系统和应用程序的 I/O 其实不做任何处理,常用在虚拟机中(此时磁盘 I/O 调度完全由物理机负责)。
- 第二种 NOOP ,是最简单的一种 I/O 调度算法。它实际上是一个先入先出的队列,只做一些最基本的请求合并,常用于 SSD 磁盘。
- 第三种 CFQ(Completely Fair Scheduler),也被称为完全公平调度器,是现在很多发行版的默认 I/O 调度器,它为每个进程维护了一个 I/O 调度队列,并按照时间片来均匀分布每个进程的 I/O 请求。类似于进程 CPU 调度,CFQ 还支持进程 I/O 的优先级调度,所以它适用于运行大量进程的系统,像是桌面环境、多媒体应用等。
- 最后一种 DeadLine 调度算法,分别为读、写请求创建了不同的 I/O 队列,可以提高机械磁盘的吞吐量,并确保达到最终期限(deadline)的请求被优先处理。DeadLine 调度算法,多用在 I/O 压力比较重的场景,比如数据库等。
I/O 栈
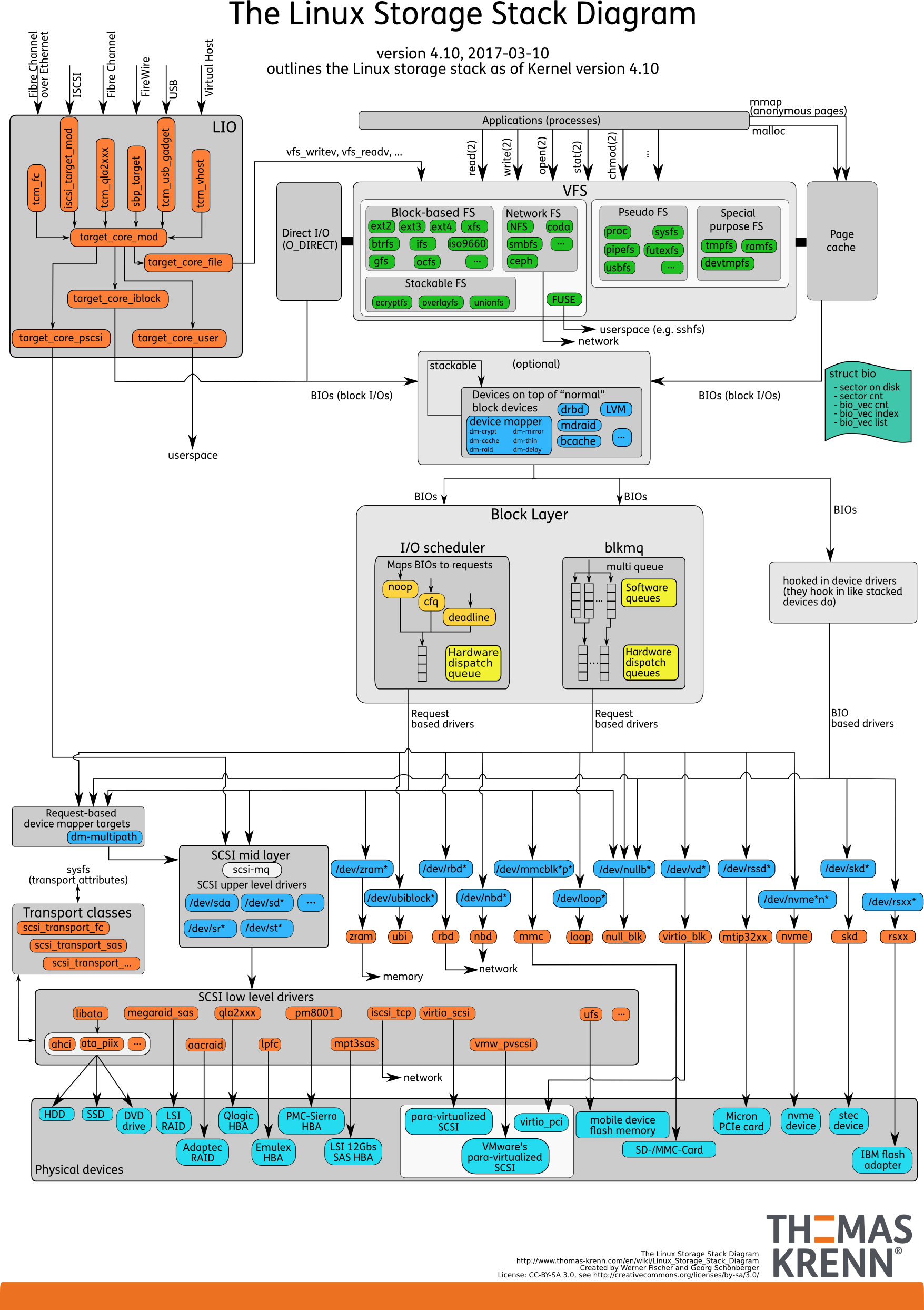
- 文件系统层,包括虚拟文件系统和其他各种文件系统的具体实现。它为上层的应用程序,提供标准的文件访问接口;对下会通过通用块层,来存储和管理磁盘数据。
- 通用块层,包括块设备 I/O 队列和 I/O 调度器。它会对文件系统的 I/O 请求进行排队,再通过重新排序和请求合并,然后才要发送给下一级的设备层。
- 设备层,包括存储设备和相应的驱动程序,负责最终物理设备的 I/O 操作。
小结
25 | 基础篇:Linux 磁盘I/O是怎么工作的(下)
磁盘性能指标
- 使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
- 饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
- IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。
- 响应时间,是指 I/O 请求从发出到收到响应的间隔时间。
性能测试工具 fio
磁盘 I/O 观测
iostat
| # -d -x 表示显示所有磁盘 I/O 的指标 | |
| $ iostat -d -x 1 | |
| Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util | |
| loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 | |
| loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 | |
| sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 | |
| sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 |
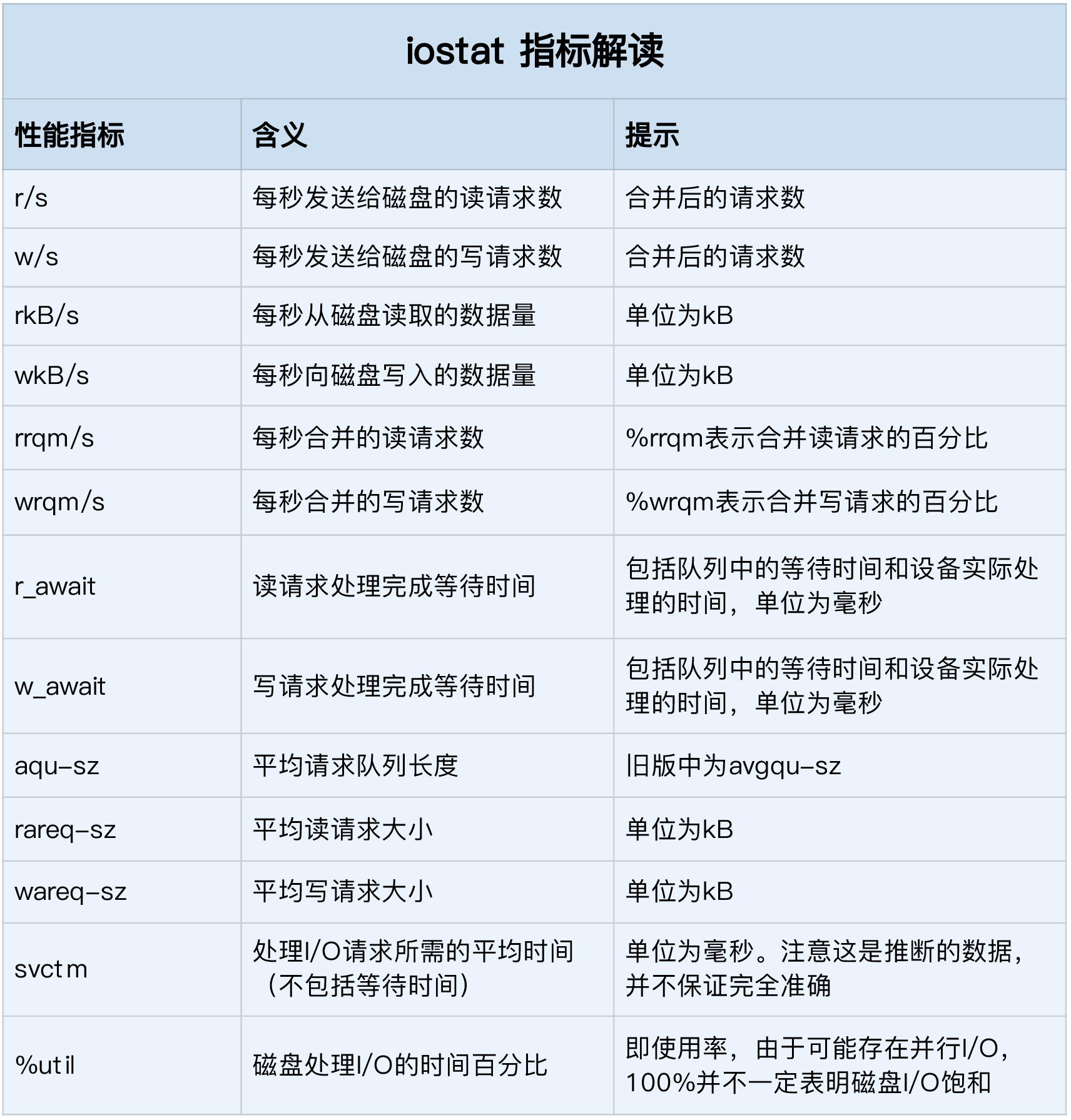
- %util ,就是我们前面提到的磁盘 I/O 使用率;
- r/s+ w/s ,就是 IOPS;
- rkB/s+wkB/s ,就是吞吐量;
- r_await+w_await ,就是响应时间。
进程 I/O 观测
pidstat
| $ pidstat -d 1 | |
| 13:39:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command | |
| 13:39:52 102 916 0.00 4.00 0.00 0 rsyslogd |
- 用户 ID(UID)和进程 ID(PID) 。
- 每秒读取的数据大小(kB_rd/s) ,单位是 KB。
- 每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
- 每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
- 块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
iotop
| $ iotop | |
| Total DISK READ : 0.00 B/s | Total DISK WRITE : 7.85 K/s | |
| Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s | |
| TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND | |
| 15055 be/3 root 0.00 B/s 7.85 K/s 0.00 % 0.00 % systemd-journald |
小结
23 | 基础篇:Linux 文件系统是怎么工作的?
索引节点和目录项
- 索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
- 目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
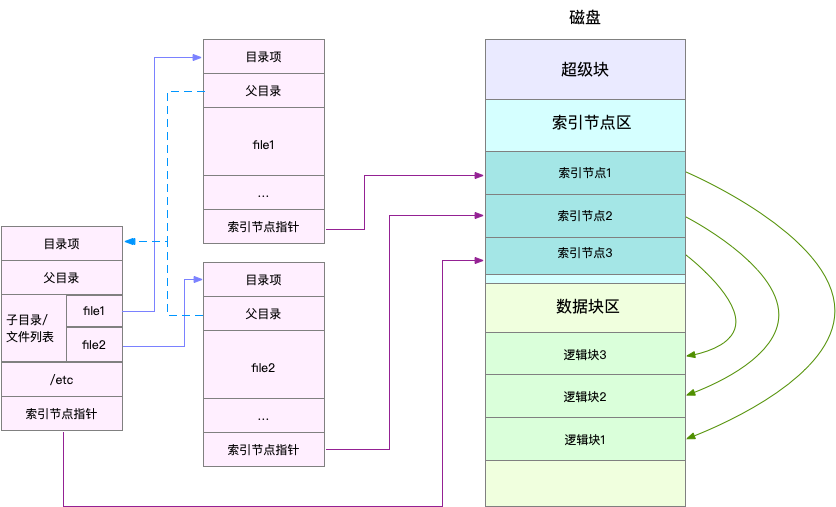
- 超级块,存储整个文件系统的状态。
- 索引节点区,用来存储索引节点。
- 数据块区,则用来存储文件数据。
虚拟文件系统
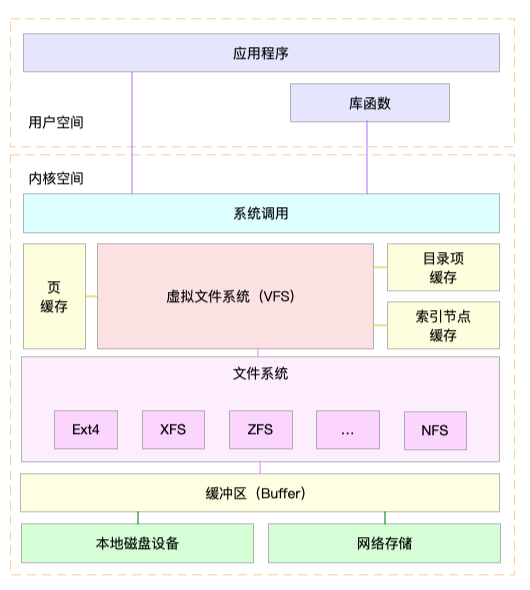
文件系统可以分为三类
- 第一类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的 Ext4、XFS、OverlayFS 等,都是这类文件系统。
- 第二类是基于内存的文件系统,也就是我们常说的虚拟文件系统。这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc 文件系统,其实就是一种最常见的虚拟文件系统。此外,/sys 文件系统也属于这一类,主要向用户空间导出层次化的内核对象。
- 第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如 NFS、SMB、iSCSI 等。
文件系统 I/O
| int open(const char *pathname, int flags, mode_t mode); | |
| ssize_t read(int fd, void *buf, size_t count); | |
| ssize_t write(int fd, const void *buf, size_t count); |
是否利用标准库缓存
- 缓冲 I/O,是指利用标准库缓存来加速文件的访问,而标准库内部再通过系统调度访问文件。
- 非缓冲 I/O,是指直接通过系统调用来访问文件,不再经过标准库缓存。
是否利用操作系统的页缓存
- 直接 I/O,是指跳过操作系统的页缓存,直接跟文件系统交互来访问文件。
- 非直接 I/O 正好相反,文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用,真正写入磁盘。
应用程序是否阻塞自身运行
- 所谓阻塞 I/O,是指应用程序执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务。
- 所谓非阻塞 I/O,是指应用程序执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务,随后再通过轮询或者事件通知的形式,获取调用的结果。
是否等待响应结果
- 所谓同步 I/O,是指应用程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应。
- 所谓异步 I/O,是指应用程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,告诉应用程序。
性能观测
容量
| $ df /dev/sda1 | |
| Filesystem 1K-blocks Used Available Use% Mounted on | |
| /dev/sda1 30308240 3167020 27124836 11% / |
| $ df -h /dev/sda1 | |
| Filesystem Size Used Avail Use% Mounted on | |
| /dev/sda1 29G 3.1G 26G 11% / |
| $ df -i /dev/sda1 | |
| Filesystem Inodes IUsed IFree IUse% Mounted on | |
| /dev/sda1 3870720 157460 3713260 5% / |
缓存
| $ cat /proc/meminfo | grep -E "SReclaimable|Cached" | |
| Cached: 748316 kB | |
| SwapCached: 0 kB | |
| SReclaimable: 179508 kB |
| $ cat /proc/slabinfo | grep -E '^#|dentry|inode' | |
| # name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail> | |
| xfs_inode 0 0 960 17 4 : tunables 0 0 0 : slabdata 0 0 0 | |
| ... | |
| ext4_inode_cache 32104 34590 1088 15 4 : tunables 0 0 0 : slabdata 2306 2306 0hugetlbfs_inode_cache 13 13 624 13 2 : tunables 0 0 0 : slabdata 1 1 0 | |
| sock_inode_cache 1190 1242 704 23 4 : tunables 0 0 0 : slabdata 54 54 0 | |
| shmem_inode_cache 1622 2139 712 23 4 : tunables 0 0 0 : slabdata 93 93 0 | |
| proc_inode_cache 3560 4080 680 12 2 : tunables 0 0 0 : slabdata 340 340 0 | |
| inode_cache 25172 25818 608 13 2 : tunables 0 0 0 : slabdata 1986 1986 0 | |
| dentry 76050 121296 192 21 1 : tunables 0 0 0 : slabdata 5776 5776 0 |
slabtop
| # 按下 c 按照缓存大小排序,按下 a 按照活跃对象数排序 | |
| $ slabtop | |
| Active / Total Objects (% used) : 277970 / 358914 (77.4%) | |
| Active / Total Slabs (% used) : 12414 / 12414 (100.0%) | |
| Active / Total Caches (% used) : 83 / 135 (61.5%) | |
| Active / Total Size (% used) : 57816.88K / 73307.70K (78.9%) | |
| Minimum / Average / Maximum Object : 0.01K / 0.20K / 22.88K | |
| OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME | |
| 69804 23094 0% 0.19K 3324 21 13296K dentry | |
| 16380 15854 0% 0.59K 1260 13 10080K inode_cache | |
| 58260 55397 0% 0.13K 1942 30 7768K kernfs_node_cache | |
| 485 413 0% 5.69K 97 5 3104K task_struct | |
| 1472 1397 0% 2.00K 92 16 2944K kmalloc-2048 |
小结
思考
Cache和Buffer的区别
1. Cache:缓存区,是高速缓存,是位于CPU和主内存之间的容量较小但速度很快的存储器,因为CPU的速度远远高于主内存的速度,CPU从内存中读取数据需等待很长的时间,而 Cache保存着CPU刚用过的数据或循环使用的部分数据,这时从Cache中读取数据会更快,减少了CPU等待的时间,提高了系统的性能。
Cache并不是缓存文件的,而是缓存块的(块是I/O读写最小的单元);Cache一般会用在I/O请求上,如果多个进程要访问某个文件,可以把此文件读入Cache中,这样下一个进程获取CPU控制权并访问此文件直接从Cache读取,提高系统性能。
2. Buffer:缓冲区,用于存储速度不同步的设备或优先级不同的设备之间传输数据;通过buffer可以减少进程间通信需要等待的时间,当存储速度快的设备与存储速度慢的设备进行通信时,存储慢的数据先把数据存放到buffer,达到一定程度存储快的设备再读取buffer的数据,在此期间存储快的设备CPU可以干其他的事情。
Buffer:一般是用在写入磁盘的,例如:某个进程要求多个字段被读入,当所有要求的字段被读入之前已经读入的字段会先放到buffer中。
cache 是为了弥补高速设备和低速设备的鸿沟而引入的中间层,最终起到**加快访问速度**的作用。
而 buffer 的主要目的进行流量整形,把突发的大数量较小规模的 I/O 整理成平稳的小数量较大规模的 I/O,以**减少响应次数**(比如从网上下电影,你不能下一点点数据就写一下硬盘,而是积攒一定量的数据以后一整块一起写,不然硬盘都要被你玩坏了)。
1、Buffer(缓冲区)是系统两端处理速度平衡(从长时间尺度上看)时使用的。它的引入是为了减小短期内突发I/O的影响,起到流量整形的作用。比如生产者——消费者问题,他们产生和消耗资源的速度大体接近,加一个buffer可以抵消掉资源刚产生/消耗时的突然变化。
2、Cache(缓存)则是系统两端处理速度不匹配时的一种折衷策略。因为CPU和memory之间的速度差异越来越大,所以人们充分利用数据的局部性(locality)特征,通过使用存储系统分级(memory hierarchy)的策略来减小这种差异带来的影响。
3、假定以后存储器访问变得跟CPU做计算一样快,cache就可以消失,但是buffer依然存在。比如从网络上下载东西,瞬时速率可能会有较大变化,但从长期来看却是稳定的,这样就能通过引入一个buffer使得OS接收数据的速率更稳定,进一步减少对磁盘的伤害。
4、TLB(Translation Lookaside Buffer,翻译后备缓冲器)名字起错了,其实它是一个cache.
https://www.zhihu.com/question/26190832
Buffer和Cache的区别

现在不都是只有page cache了吗? buffer pages其实也是page cache里面的页。只是多了一层抽象,通过buffer_head来进行一些访问管理
对,从Linux算法实现的角度,page cache和buffer cache目前是一样的,但是从功能抽象和具体应用来讲,这两者还是存在区别的,这一点可以从top工具的统计信息中看得出来,关注一下buffer和 cache这两个统计量。
增加一些资料:
A buffer is something that has yet to be “written” to disk. A cache is something that has been “read” from the disk and stored for later use.
在终端中敲入:free
显 示: total used free shared buffers cached
Mem: 255268 238332 16936 0 85540 126384
-/+ buffers/cache:26408 228860
系统的总物理内存:255268Kb(256M),但系统 当前真正可用的内存并不是第一行free 标记的 16936Kb,它仅代表未被分配的内存。
我们使用total1、used1、 free1、used2、free2 等名称来代表上面统计数据的各值,1、2 分别代表第一行和第二行的数据。
total1:表示物理 内存总量。
used1:表示总计分配给缓存(包含buffers 与cache )使用的数量,但其中可能部分缓存并未实际使用。
free1:未被分配的内存。
shared1:共享内存,一般系统不会用到,这里也不讨论。
buffers1: 系统分配但未被使用的buffers 数量。
cached1:系统分配但未被使用的cache 数量。buffer 与cache 的区别见后面。
used2:实际使用的buffers 与cache 总量,也是实际使用的内存总量。
free2:未被 使用的buffers 与cache 和未被分配的内存之和,这就是系统当前实际可用内存。
可以整理出如下等式:
total1 = used1 + free1
total1 = used2 + free2
used1 = buffers1 + cached1 + used2
free2 = buffers1 + cached1 + free1
---------------------------------------------------------------------------------------------------------------------------------------------------
缓存(cached)是把读取过的数据保存起来,重新读取时若命中(找到需要的数据)就不要去读硬盘了,若没有命中就读硬盘。其中的数据会根据读取频率进行组织,把最频繁读取的内容放在最容易找到的位置,把不再读的内容不断往后排,直至从中删除。缓 冲(buffers)是根据磁盘的读写设计的,把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。linux有一个守护进程定期 清空缓冲内容(即写入磁盘),也可以通过sync命令手动清空缓冲。举个例子吧:我这里有一个ext2的U盘,我往里面cp一个3M的MP3,但U盘的灯 没有跳动,过了一会儿(或者手动输入sync)U盘的灯就跳动起来了。卸载设备时会清空缓冲,所以有些时候卸载一个设备时要等上几秒钟。
修改/etc/sysctl.conf中的vm.swappiness右边的数字可以在下次开机时调节swap使用策略。该数字范围是0~100,数字越大越倾向于使用swap。默认为60,可以改一下试试。–两者都是RAM中的数据。
cache经常被用在磁盘的I/O请求上,如果有多个进程都要访问某个文件,于是该文件便被做成cache以方便下次被访问,这样可提高系统性能。
Buffer Cachebuffer cache,又称bcache,其中文名称为缓冲器高速缓冲存储器,简称缓冲器高缓。另外,buffer cache按照其工作原理,又被称为块高缓。
。。。。。。。。。。。。。。
引用url:http://www.cnblogs.com/zwl715/p/3964963.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号