Install redis-check-rdb and redis-check-aof as symlinks to redis-server?
https://github.com/redis/redis/issues/7663
the redis-server main() function has the following code:
为什么redis集群的最大槽数是16384个?
Redis 集群并没有使用一致性hash,而是引入了哈希槽的概念。Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。但为什么哈希槽的数量是16384(2^14)个呢,这个问题在github上有人提过,作者也给出了解答(点击查看),下面我们来简单分析一下。
为什么是16384(2^14)个?
在redis节点发送心跳包时需要把所有的槽放到这个心跳包里,以便让节点知道当前集群信息,16384=16k,在发送心跳包时使用char进行bitmap压缩后是2k(2 * 8 (8 bit) * 1024(1k) = 16K),也就是说使用2k的空间创建了16k的槽数。
虽然使用CRC16算法最多可以分配65535(2^16-1)个槽位,65535=65k,压缩后就是8k(8 * 8 (8 bit) * 1024(1k) =65K),也就是说需要需要8k的心跳包,作者认为这样做不太值得;并且一般情况下一个redis集群不会有超过1000个master节点,所以16k的槽位是个比较合适的选择。
The reason is:
- Normal heartbeat packets carry the full configuration of a node, that can be replaced in an idempotent way with the old in order to update an old config. This means they contain the slots configuration for a node, in raw form, that uses 2k of space with16k slots, but would use a prohibitive 8k of space using 65k slots.
- At the same time it is unlikely that Redis Cluster would scale to more than 1000 mater nodes because of other design tradeoffs.
So 16k was in the right range to ensure enough slots per master with a max of 1000 maters, but a small enough number to propagate the slot configuration as a raw bitmap easily. Note that in small clusters the bitmap would be hard to compress because when N is small the bitmap would have slots/N bits set that is a large percentage of bits set.
bitmap 压缩空间
前言:
bitmap是压缩空间的一个好方法。
8bit = >1byte 1024btye=>1KB 1024KB =>1MB 1024MB =>1GB
问题引入:
试想现在有一个场景,如果现在需要实现,在一段时间内,会有10亿的手机用户登录,现在有一个手机登录,怎么知道该手机是否已经登录,并把内存压缩到最小呢
如果使用int数组存储的话大概要10亿*4字节=400000000/1024KB= 3906250KB=3906250/1024MB=3814.697265625MB≈3.7GB
如果用hashmap的key-value存储的话,还会更大。
而bitmap用的是数组的标志位来表达该数是否存在。借用网图,使用byte[i]坐标来表达数字。

对于国内手机用户,11位数,即最多19999999999,约算200亿,200亿*1/8/1024/1024/1024GB=2.3GB
因为国内手机用户都是以1开头,若不算第一位约算100亿,大约是1.15GB
倘若我们继续优化只计算目前市场流行的几种136,156...等开头的能继续节省不少的空间。
因此可以看到使用bitmap能够节省大量的空间。
但是这种bitmap并不是没有弱点:
1.数据碰撞,如果用bitmap存储String类型的时候,有可能出现两个String的int相同情况,这个时候可以使用布隆过滤器(bloom filter)。
2.数据稀疏,如果用bitmap就存储几个数据的时候,可以使用RoaringBitmap(高效压缩位图)
一看就懂系列之 详解redis的bitmap在亿级项目中的应用
前言
这是一篇拖了很久的总结,项目中引入了redis的bitmap的用法,感觉挺高大上的,刨根问底,故留下总结一篇当作纪念。
说清楚几个问题:
1.bitmap的原理、用法。
2.bitmap的优势、限制。
3.bitmap空间、时间粗略计算方式。
4.bitmap的使用场景。
5.使用bitmap过程中可能会遇到的坑。
6.bitmap进阶用法(思考)。
bitmap的原理、用法
原理
8bit = 1b = 0.001kb
bitmap就是通过最小的单位bit来进行0或者1的设置,表示某个元素对应的值或者状态。
一个bit的值,或者是0,或者是1;也就是说一个bit能存储的最多信息是2。
用法
setBit
说明:给一个指定key的值得第offset位 赋值为value。
参数:key offset value: bool or int (1 or 0)
返回值:LONG: 0 or 1
getBit
说明:返回一个指定key的二进制信息
参数:key offset
返回值:LONG
bitCount
说明:返回一个指定key中位的值为1的个数(是以byte为单位不是bit)
参数:key start offset
返回值:LONG
bitOp
说明:对不同的二进制存储数据进行位运算(AND、OR、NOT、XOR)
参数:operation destkey key [key …]
返回值:LONG
bitmap的优势、限制
优势
1.基于最小的单位bit进行存储,所以非常省空间。
2.设置时候时间复杂度O(1)、读取时候时间复杂度O(n),操作是非常快的。
3.二进制数据的存储,进行相关计算的时候非常快。
4.方便扩容
限制
redis中bit映射被限制在512MB之内,所以最大是2^32位。建议每个key的位数都控制下,因为读取时候时间复杂度O(n),越大的串读的时间花销越多。
bitmap空间、时间粗略计算方式
在一台2010MacBook Pro上,offset为232-1(分配512MB)需要~300ms,offset为230-1(分配128MB)需要~80ms,offset为228-1(分配32MB)需要~30ms,offset为226-1(分配8MB)需要8ms。<来自官方文档>
大概的空间占用计算公式是:($offset/8/1024/1024)MB
bitmap的使用场景
使用方式很多,根据不同的业务需求来,但是总的来说就两种,以用户为例子:
1.一种是某一用户的横向扩展,即此个key值中记录这当前用户的各种状态值,允许无限扩展(2^32内)
点评:这种用法基本上是很少用的,因为每个key携带uid信息,如果存储的key的空间大于value,从空间角度看有一定的优化空间,如果是记录长尾的则可以考虑。
2.一种是某一用户的纵向扩展,即每个key只记录当前业务属性的状态,每个uid当作bit位来记录信息(用户超过2^32内需要分片存储)
点评:基本上项目使用的场景都是基于这种方式的,按业务区分方便回收资源,key值就一个,将uid的存储转为了位的存储,十分巧妙的通过uid即可找到相应的值,主要存储量在value上,符合预期。
1.视频属性的无限延伸
需求分析:
一个拥有亿级数据量的短视频app,视频存在各种属性(是否加锁、是否特效等等),需要做各种标记。
可能想到的解决方案:
1.存储在mysql中,肯定不行,一个是随着业务增长属性一直增加,并且存在有时间限制的属性,直接对数据库进行加减字段是非常不合理的做法。即使是存在一个字段中用json等压缩技术存储也存在读效率的问题,并且对于大几亿的数据来说,废弃的字段回收起来非常麻烦。
2.直接记录在redis中,根据业务属性+uid为key来存储。读写效率角度没毛病,但是存储的角度来说key的数据量都大于value了,太耗费空间了。即使是用json等压缩技术来存储。也存在问题,解压需要时间,并且大几亿的数据回收也是难题。
设计方案:
使用redis的bitmap进行存储。
key由属性id+视频分片id组成。value按照视频id对分片范围取模来决定偏移量offset。10亿视频一个属性约120m还是挺划算的。
伪代码:
function set($business_id , $media_id , $switch_status=1){
$switch_status = $switch_status ? 1 : 0;
$key = $this->_getKey($business_id, $media_id);
$offset = $this->_getOffset($media_id);
return $this->redis->setBit($key, $offse, $switch_status);
}
function get($business_id , $media_id){
$key = $this->_getKey($business_id,$media_id);
$offset = $this->_getOffset($media_id);
return $this->redis->getBit($key , $offset);
}
function _getKey($business_id, $media_id){
return 'm:'.$business_id.':'.intval($media_id/10000);
}
function _getOffset($media_id){
return $media_id % 10000;
}
这样基本实现了属性的存储,后续增加新属性也只是business_id再增加一个值。
至于为什么分片呢?分片的粒度怎么衡量?
分片有两个原因:1.读取的时候时间复杂度是O(n)存储越长读取时间越多 2.bitmap有长度限制2^32。
分片粒度怎么衡量:1.如果主键id存在的断层那么请尽可能选择的粒度可以避开此段id范围,防止空间浪费,因为来一个00000…9999个0…01,那么因为存一个属性而存了全部的,就浪费了。2.分片粒度可参考某一单位时间的增长值来判断,这样也有利于预算占了多少空间,虽然空间不会占很多。
2.用户在线状态
需求分析:
需要对子项目提供一个接口,来提供某用户是否在线?
设计方案:
使用bitmap是一个节约空间效率又高的一种方法,只需要一个key,然后用户id为偏移量offset,如果在线就设置为1,不在线就设置为0,3亿用户只需要36MB的空间。
伪代码:
$status = 1;
$redis->setBit('online', $uid, $status);
$redis->getBit('online', $uid);
需要加上如例子1一样分片的方式。10亿真的太多了。10w分一片。
3.统计活跃用户
需求分析:
需要计算活跃用户的数据情况。
设计方案:
使用时间作为缓存的key,然后用户id为offset,如果当日活跃过就设置为1。之后通过bitOp进行二进制计算算出在某段时间内用户的活跃情况。
伪代码:
$status = 1;
$redis->setBit('active_20170708', $uid, $status);
$redis->setBit('active_20170709', $uid, $status);
$redis->bitOp('AND', 'active', 'active_20170708', 'active_20170709');
上亿用户需要加上如例子1一样分片的方式。几十万或者以下,可无需分片省的业务变复杂。
4.用户签到
需求分析:
用户需要进行签到,对于签到的数据需要进行分析与相应的运运营策略。
设计方案:
使用redis的bitmap,由于是长尾的记录,所以key主要由uid组成,设定一个初始时间,往后没加一天即对应value中的offset的位置。
伪代码:
$start_date = '20170708';
$end_date = '20170709';
$offset = floor((strtotime($start_date) - strtotime($end_date)) / 86400);
$redis->setBit('sign_123456', $offset, 1);
//算活跃天数
$redis->bitCount('sign_123456', 0, -1)
无需分片,一年365天,3亿用户约占300000000*365/8/1000/1000/1000=13.68g。存储成本是不是很低。
使用bitmap过程中可能会遇到的坑
1.bitcout的陷阱
如果你有仔细看前文的用法,会发现有这么一个备注“返回一个指定key中位的值为1的个数(是以byte为单位不是bit)”,这就是坑的所在。
有图有真相: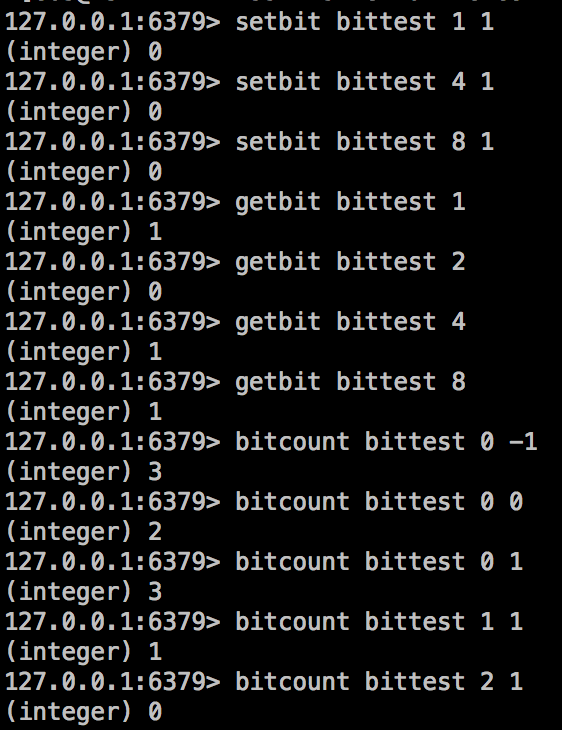
所以bitcount 0 0 那么就应该是第一个字节中1的数量的,注意是字节,第一个字节也就是1,2,3,4,5,6,7,8这八个位置上。
bitmap进阶用法(思考)
以下内容来自此文的笔记:http://www.infoq.com/cn/articles/the-secret-of-bitmap/
1.空间
redis的bitmap已经是最小单位的存储了,有没有办法对二进制存储的信息再进行压缩呢?进一步省空间?
答案是有的。
可以对记录的二进制数据进行压缩。常见的二进制压缩技术都是基于RLE(Run Length Encoding,详见http://en.wikipedia.org/wiki/Run-length_encoding)。
RLE编码很简单,比较适合有很多连续字符的数据,比如以下边的Bitmap为例: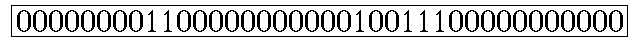
可以编码为0,8,2,11,1,2,3,11
其意思是:第一位为0,连续有8个,接下来是2个1,11个0,1个1,2个0,3个1,最后是11个0(当然此处只是对RLE的基本原理解释,实际应用中的编码并不完全是这样的)。
可以预见,对于一个很大的Bitmap,如果里边的数据分布很稀疏(说明有很多大片连续的0),采用RLE编码后,占用的空间会比原始的Bitmap小很多。
2.时间
redis虽然是在内存操作,但是超过redis指定存储在内存的阀值之后,会被搞到磁盘中。要是进行大范围的计算还需要从磁盘中取出到内存在计算比较耗时,效率也不高,有没有办法尽可能内存中多放一些数据,缩短时间?
答案是有的。
基于第一点同时引入一些对齐的技术,可以让采用RLE编码的Bitmap不需要进行解压缩,就可以直接进行AND/OR/XOR等各类计算;因此采用这类压缩技术的Bitmap,加载到内存后还是以压缩的方式存在,从而可以保证计算时候的低内存消耗;而采用word(计算机的字长,64位系统就是64bit)对齐等技术又保证了对CPU资源的高效利用。因此采用这类压缩技术的Bitmap,保持了Bitmap数据结构最重要的一个特性,就是高效的针对每个bit的逻辑运算。
常见的压缩技术包括BBC(有专利保护,WAH(http://code.google.com/p/compressedbitset/)和EWAH(http://code.google.com/p/javaewah/)
扩展阅读
Bitmap的秘密
Redis内存压缩实战
Redis中bitmap的妙用
Redis中BitMap是如何储存的,以及PHP如何处理
使用redis的setbit和bitcount来进行区间统计的坑
Geohash算法原理及实现
最近需要实现一个功能,查找车辆附近的加油站,如果车和加油站距离在200米以内,则查找成功。
加油站数量肯定不小,能否缩小查找范围,否则以遍历形式,效率肯定高不了。
Geohash算法就是将经纬度编码,将二维变一维,给地址位置分区的一种算法。
基本原理
GeoHash是一种地址编码方法。他能够把二维的空间经纬度数据编码成一个字符串
我们知道,经度范围是东经180到西经180,纬度范围是南纬90到北纬90,我们设定西经为负,南纬为负,所以地球上的经度范围就是[-180, 180],纬度范围就是[-90,90]。如果以本初子午线、赤道为界,地球可以分成4个部分。
如果纬度范围[-90°, 0°)用二进制0代表,(0°, 90°]用二进制1代表,经度范围[-180°, 0°)用二进制0代表,(0°, 180°]用二进制1代表,那么地球可以分成如下4个部分

如果在小块范围内递归对半划分呢?

可以看到,划分的区域更多了,也更精确了。geohash算法就是基于这种思想,划分的次数更多,区域更多,区域面积更小了。通过将经纬度编码,给地理位置分区
Geohash算法
Geohash算法一共有三步。
首先将经纬度变成二进制。
比如这样一个点(39.923201, 116.390705)
纬度的范围是(-90,90),其中间值为0。对于纬度39.923201,在区间(0,90)中,因此得到一个1;(0,90)区间的中间值为45度,纬度39.923201小于45,因此得到一个0,依次计算下去,即可得到纬度的二进制表示,如下表:

最后得到纬度的二进制表示为:
10111000110001111001
同理可以得到经度116.390705的二进制表示为:
11010010110001000100
第2步,就是将经纬度合并。
经度占偶数位,纬度占奇数位,注意,0也是偶数位。
11100 11101 00100 01111 00000 01101 01011 00001
第3步,按照Base32进行编码
Base32编码表的其中一种如下,是用0-9、b-z(去掉a, i, l, o)这32个字母进行编码。具体操作是先将上一步得到的合并后二进制转换为10进制数据,然后对应生成Base32码。需要注意的是,将5个二进制位转换成一个base32码。上例最终得到的值为
wx4g0ec1
Geohash比直接用经纬度的高效很多,而且使用者可以发布地址编码,既能表明自己位于北海公园附近,又不至于暴露自己的精确坐标,有助于隐私保护。
- GeoHash用一个字符串表示经度和纬度两个坐标。在数据库中可以实现在一列上应用索引(某些情况下无法在两列上同时应用索引)
- GeoHash表示的并不是一个点,而是一个矩形区域
- GeoHash编码的前缀可以表示更大的区域。例如wx4g0ec1,它的前缀wx4g0e表示包含编码wx4g0ec1在内的更大范围。 这个特性可以用于附近地点搜索
编码越长,表示的范围越小,位置也越精确。因此我们就可以通过比较GeoHash匹配的位数来判断两个点之间的大概距离。

问题
geohash算法有两个问题。首先是边缘问题。

如图,如果车在红点位置,区域内还有一个黄点。相邻区域内的绿点明显离红点更近。但因为黄点的编码和红点一样,最终找到的将是黄点。这就有问题了。
要解决这个问题,很简单,只要再查找周边8个区域内的点,看哪个离自己更近即可。
另外就是曲线突变问题。
本文第2张图片比较好地解释了这个问题。其中0111和1000两个编码非常相近,但它们的实际距离确很远。所以编码相近的两个单位,并不一定真实距离很近,这需要实际计算两个点的距离才行。
代码实现
geohash原理清楚后,代码实现就比较简单了。不过仍然有一个问题需要解决,就是如何计算周边的8个区域key值呢
假设我们计算的key值是6位,那么二进制位数就是 6*5 = 30位,所以经纬度分别是15位。我们以纬度为例,纬度会均分15次。这样我们很容易能够算出15次后,划分的最小单位是多少
private void setMinLatLng() {
minLat = MAXLAT - MINLAT;
for (int i = 0; i < numbits; i++) {
minLat /= 2.0;
}
minLng = MAXLNG - MINLNG;
for (int i = 0; i < numbits; i++) {
minLng /= 2.0;
}
}
得到了最小单位,那么周边区域的经纬度也可以计算得到了。比如说左边区域的经度肯定是自身经度减去最小经度单位。纬度也可以通过加减,得到上下的纬度值,最终周围8个单位也可以计算得到。
可以到 http://geohash.co/ 进行geohash编码,以确定自己代码是否写错
整体代码如下所示:
public class GeoHash {
public static final double MINLAT = -90;
public static final double MAXLAT = 90;
public static final double MINLNG = -180;
public static final double MAXLNG = 180;
private static int numbits = 3 * 5; //经纬度单独编码长度
private static double minLat;
private static double minLng;
private final static char[] digits = { '0', '1', '2', '3', '4', '5', '6', '7', '8',
'9', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'j', 'k', 'm', 'n', 'p',
'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z' };
//定义编码映射关系
final static HashMap<Character, Integer> lookup = new HashMap<Character, Integer>();
//初始化编码映射内容
static {
int i = 0;
for (char c : digits)
lookup.put(c, i++);
}
public GeoHash(){
setMinLatLng();
}
public String encode(double lat, double lon) {
BitSet latbits = getBits(lat, -90, 90);
BitSet lonbits = getBits(lon, -180, 180);
StringBuilder buffer = new StringBuilder();
for (int i = 0; i < numbits; i++) {
buffer.append( (lonbits.get(i))?'1':'0');
buffer.append( (latbits.get(i))?