bash – 如何在单引号字符串中转义单引号?grep命令详解
alias rxvt='urxvt'
工作正常。
然而:
alias rxvt='urxvt -fg '#111111' -bg '#111111''
不会工作,也不会:
alias rxvt='urxvt -fg \'#111111\' -bg \'#111111\''
所以,如果你有转义报价后,你最终会匹配字符串中的开始和结束报价?
alias rxvt='urxvt -fg'\''#111111'\'' -bg '\''#111111'\''
似乎不明显,虽然它将代表相同的字符串,如果你允许连接他们这样。
alias rxvt='urxvt -fg '"'"'#111111'"'"' -bg '"'"'#111111'"'"
# ^^^^^ ^^^^^ ^^^^^ ^^^^
# 12345 12345 12345 1234
如何解释’“’”’被解释为只是:
>’End first quotation使用单引号。
>“使用双引号开始第二个引号。
>’引号字符。
>“结束第二个引号,使用双引号。
>’使用单引号开始第三个引号。
如果不在(1)和(2)之间或(4)和(5)之间放置任何空格,shell将把该字符串解释为一个长字。
Let's say, you have a Bash alias like:
alias rxvt='urxvt'
which works fine.
However:
alias rxvt='urxvt -fg '#111111' -bg '#111111''
won't work, and neither will:
alias rxvt='urxvt -fg \'#111111\' -bg \'#111111\''
So how do you end up matching up opening and closing quotes inside a string once you have escaped quotes?
alias rxvt='urxvt -fg'\''#111111'\'' -bg '\''#111111'\''
seems ungainly although it would represent the same string if you're allowed to concatenate them like that.
If you really want to use single quotes in the outermost layer, remember that you can glue both kinds of quotation. Example:
alias rxvt='urxvt -fg '"'"'#111111'"'"' -bg '"'"'#111111'"'"
# ^^^^^ ^^^^^ ^^^^^ ^^^^
# 12345 12345 12345 1234
Explanation of how '"'"' is interpreted as just ':
'End first quotation which uses single quotes."Start second quotation, using double-quotes.'Quoted character."End second quotation, using double-quotes.'Start third quotation, using single quotes.
If you do not place any whitespaces between (1) and (2), or between (4) and (5), the shell will interpret that string as a one long word.
$ echo 'ni'string'hao' nistringhao $ echo 'ni''string''hao' nistringhao $ echo 'ni'''string'''hao' nistringhao
$ echo 'ni'"'"'string'"'"'hao' # ok! ni'string'hao
$ echo "ni'"'"'"string'hao" #ok 2! ni'"string'hao
bash中的转义
转义是引用单字符的方法.在单个字符前面的转义符(\ 倒斜杠)告诉shell不必特殊解释这个字符,只把它当成字面上的意思.
但在一些命令和软件包里,比如说echo和sed,转义一个字符可能会引起一个相反的效果--因为它们可能触发那个字符的特殊意思.
---引自 abs
一些特殊的转义序列:
(以 help echo 的结果为蓝本, 添加部分注释, 别人写的,无为有修改)
\a 终端响铃(小机不支持...同 \x07, \07)
\b 退格, 光标左移一格.
\c 禁止行尾自动换行, 对echo有效, printf无效
\e ESC转义序列(见下, 同\E, \033, \x1b; 就是ESC键按下的效果)
\f 换页(光标移到下一行的相同列)
\n 换行(光标移动下一行行首)
\r 回车(光标回到本行行首)
\t 制表符(TAB键按下的效果...)
\v 纵向制表符(同\f)
\x00 十六机制数的值(两位[0-9a-fA-F]的十六进制数).
\\ 倒斜杠...
\000 八进制数的值(以数字开头, 限最多3位[0-7]的数字)
PS 转义序列 (prompt symbol, bash提示符, 无为未验证):
(出自 http://www.linuxselfhelp.com/how ... h-Prompt-HOWTO.html , 翻译有参考)
\a 响铃
\d 日期, 格式为 "Weekday Month Date", ("Tue May 26")
\e ESC转义序列.
\h 主机名的第一部分. (froms)
\H 完整主机名. (froms.vuuvsoft.com)
\n 换行
\r 回车
\s shell的名称. 根据路径获取. 如/usr/bin/bash --> "bash"
\t 时间, 格式 HH:MM:SS 24小时制. ("23:01:01")
\T 时间, 格式 HH:MM:SS 12小时制. ("11:01:01")
\@ 带有 am/pm 的 12小时制 时间
\u 用户名. ("root")
\v bash版本号 ("2.00")
\V bash版本号及补丁级别 ("2.00.0")
\w 当前工作目录完整路径 ("/home/froms")
\W 当前工作目录目录名 ("froms")
\! 当前命令在历史缓冲区中的位置
\# 命令编号(只要您键入内容,它就会在每次提示时累加)
\$ 如果你是root, 显示 "#"; 否则, "$".
\nnn 八进制数
\\ 倒斜杠
这个序列应该出现在非打印字符序列之后. (
)
(无为注: 当然, 你也可以用命令替换来显示时间日期: PS1="$(date +%x-%X)")
( 以下内容来自 man console_codes 的结果, 翻译有修改, 并删除部分无法在小机使用的序列. )
ESC 转义序列:
c 重置终端.
D 换页(纵向制表符).
E 换行.
H 设置当前列为制表位. (未验证)
M 翻转换行, 向上换页(Reverse linefeed).
7 存储当前状态(光标坐标, 属性).
8 恢复上一次储存的设置
[ (见下)
#8 屏幕校准测试 - 以E填充屏幕.
例: printf "\e#8"
ESC[ 转义序列:
A 光标上移指定行.
B 光标下移指定行.
C 光标右移指定列. \e[3C 右移3列
D 光标左移指定列.
G 光标移动到当前行的指定列.
H 光标移动到指定行和列(行列起始计数为1, tput cup 的起始计数为0).
\e[y;xH y=3; x=5 第三行第五列.
J 删除内容(默认从当前光标处到结尾).
\e[1J: 删除从开始到光标处的内容.
\e[2J: 清空整个屏幕.
K 删除行(默认从当前光标处到行尾).
\e[1K: 删除从行首到当前光标处的内容.
\e[2K: 删除整行.
d 光标移动到当前列指定行
f 同\H.
h 设置模式(见下).
l 重置模式(见下).
m 设置属性(见下).
n 状态报告(见下).
r 设置滚动范围; 参数为首行和末行.(好像不能用...)
s 存储光标位置.
u 恢复光标位置.
设置图形属性:
\e[ <属性数值> m 设置显示属性. 同样的序列可以设置一个或多个属性, 以 ";" 分开.
特效代码:
0 清除所有属性
1 高亮(并加粗, 可惜小机没有加粗)
2 暗色(以一般亮度显示, 小机不支持)
4 下划线
5 闪烁(小机闪烁频率太低, 无用)
7 反显.
8 消隐(一段字不显示, 小机不支持)
22 正常亮度
24 关闭下划线
25 不闪烁
27 不反显
颜色代码前缀:
3: 前景 9: 加亮前景
4: 背景 10: 加亮背景
颜色代码后缀(加亮效果):
0 黑(深灰)
1 红(亮红)
2 绿(亮绿)
3 棕(黄色)
4 蓝(浅蓝)
5 紫(淡紫)(这个看不出来)
6 青(亮青)
7 浅灰(白)
9 默认颜色(限3,4前缀)
示例: 绿色前景, 亮青背景, 下划线. 0表示清除之前设置的所有属性.
\e[0;32;106;4m
打印一段内容后, 不要下划线了
\e[24m
又想反显了(就是绿色背景, 亮青前景)
\e[7m
那么, 怎么除去反显呢?
状态报告:
\e[5n
设备状态报告(DSR): 以\e[0n 应答(终端准备好).
\e[6n
光标位置报告(CPR): 以\e[y;xR 应答, 这里 x,y 指光标位置.
设置模式( 用l替换最后一个h就是重置模式 )
\e[?5h 全屏反显.
\e[?25h 显示终端光标
https://blog.csdn.net/forgetbook/article/details/8770231
grep命令详解
grep命令是文本搜索命令,它可以正则表达式搜索文本,也可从一个文件中的内容作为搜索关键字。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
语法:
grep [option] pattern file
参数:
用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用,使用上十分灵活。
-a --text #不要忽略二进制的数据。
-A<显示行数> --after-context=<显示行数> #除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b --byte-offset #在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> --before-context=<显示行数> #除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count #计算符合样式的列数。
-C<显示行数> --context=<显示行数>或-<显示行数> #除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> --directories=<动作> #当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> #指定字符串做为查找文件内容的样式。
-E --extended-regexp #将样式为延伸的普通表示法来使用。
-f<规则文件> --file=<规则文件> #指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F --fixed-regexp #将样式视为固定字符串的列表。
-G --basic-regexp #将样式视为普通的表示法来使用。
-h --no-filename #在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H --with-filename #在显示符合样式的那一行之前,表示该行所属的文件名称。
-i --ignore-case #忽略字符大小写的差别。
-l --file-with-matches #列出文件内容符合指定的样式的文件名称。
-L --files-without-match #列出文件内容不符合指定的样式的文件名称。
-n --line-number #在显示符合样式的那一行之前,标示出该行的列数编号。
-q --quiet或--silent #不显示任何信息。
-r --recursive #此参数的效果和指定“-d recurse”参数相同。
-s --no-messages #不显示错误信息。
-v --revert-match #显示不包含匹配文本的所有行。
-V --version #显示版本信息。
-w --word-regexp #只显示全字符合的列。
-x --line-regexp #只显示全列符合的列。
-y #此参数的效果和指定“-i”参数相同。
规则表达式:
^ #锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ #锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
. #匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* #匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表任意字符。
[] #匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) #标记匹配字符,如'\(love\)',love被标记为1。
\< #锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> #锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} #重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} #重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b #单词锁定符,如: '\bgrep\b'只匹配grep。
使用实例:
实例1:查找指定进程
命令:
ps -ef | grep svn
输出:

说明:
第一条记录是查找出的进程;第二条结果是grep进程本身,并非真正要找的进程。
实例2:查找指定进程个数
命令:
ps -ef|grep -c svn
输出:

实例3:从文件中读取关键词进行搜索
命令:
grep -f test file
输出:
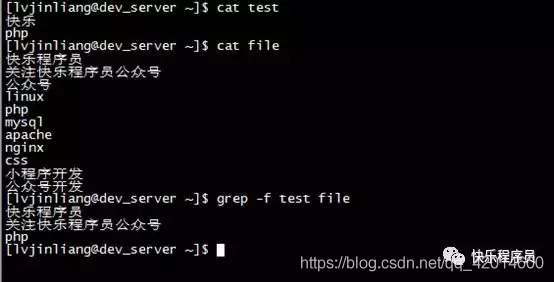
实例4:从文件中读取关键词进行搜索且显示行号
命令:
grep -f test -n file
输出:

实例5:从文件中查找关键词
命令:
grep 快乐程序员 file
输出:
实例6:从多个文件中查找关键词
命令:
grep php file file1
输出:


说明:
多文件时,输出查询到的信息内容行时,会把文件的命名在行最前面输出并且加上":"作为标示符
实例7:grep不显示本身进程
命令:
ps -ef | grep svn | grep -v “grep”
输出:

实例8:找出以”快乐”开头的行内容
命令:
grep ^快乐 file
输出:

实例9:找出以非”快乐”开头的行内容
命令:
grep [快乐] file
输出:
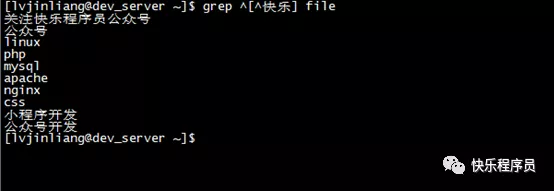
grep可用于shell脚本,grep通过返回一个状态值来说明搜索的状态,
结果{0:成功,1:不成功,2:搜索的文件不存在}
Linux中grep命令详解
grep命令
grep
1.作用
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
2.格式及主要参数
grep [options]
主要参数: grep --help可查看
-c:只输出匹配行的计数。
-i:不区分大小写。
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及 行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
--color=auto :可以将找到的关键词部分加上颜色的显示。
pattern正则表达式主要参数:
\: 忽略正则表达式中特殊字符的原有含义。
^:匹配正则表达式的开始行。
$: 匹配正则表达式的结束行。
\<:从匹配正则表达 式的行开始。
\>:到匹配正则表达式的行结束。
[ ]:单个字符,如[A]即A符合要求 。
[ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。
.:所有的单个字符。
*:所有字符,长度可以为0。
3.grep命令使用简单实例
itcast$ grep ‘test’ d*
显示所有以d开头的文件中包含 test的行
itcast $ grep ‘test’ aa bb cc
显示在aa,bb,cc文件中匹配test的行。
itcast $ grep ‘[a-z]\{5\}’ aa
显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
itcast $ grep ‘wesest.*\1′ aa
如果west被匹配,则es就被存储到内存中,并标记为1,然后搜索任意个字符(.*),这些字符后面紧跟着 另外一个es(\1),找到就显示该行。如果用egrep或grep -E,就不用”\”号进行转义,直接写成’w(es)t.*\1′就可以了。
4.grep命令使用复杂实例
明确要求搜索子目录:
grep -r
或忽略子目录
grep -d skip
如果有很多输出时,您可以通过管道将其转到’less’上阅读:
itcast$ grep magic /usr/src/Linux/Documentation/* | less
这样,您就可以更方便地阅读。
有一点要注意,您必需提供一个文件过滤方式(搜索全部文件的话用 *)。如果您忘了,’grep’会一直等着,直到该程序被中断。如果您遇到了这样的情况,按 ,然后再试。
下面还有一些有意思的命令行参数:
grep -i pattern files :不区分大小写地搜索。默认情况区分大小写,
grep -l pattern files :只列出匹配的文件名,
grep -L pattern files :列出不匹配的文件名,
grep -w pattern files :只匹配整个单词,而不是字符串的一部分(如匹配’magic’,而不是’magical’),
grep -C number pattern files :匹配的上下文分别显示[number]行,
grep pattern1 | pattern2 files :显示匹配 pattern1 或 pattern2 的行,
例如:grep "abc\|xyz" testfile 表示过滤包含abc或xyz的行
grep pattern1 files | grep pattern2 :显示既匹配 pattern1 又匹配 pattern2 的行。
grep -n pattern files 即可显示行号信息
grep -c pattern files 即可查找总行数
还有些用于搜索的特殊符号:\< 和 \> 分别标注单词的开始与结尾。
例如:
grep man * 会匹配 ‘Batman’、’manic’、’man’等,
grep ‘\<man’ * 匹配’manic’和’man’,但不是’Batman’,
grep ‘\<man\>’ 只匹配’man’,而不是’Batman’或’manic’等其他的字符串。
‘^’: 指匹配的字符串在行首,
‘$’: 指匹配的字符串在行 尾,
用grep查找结构体 grep -R "struct task_struct {" /usr/src 加-n可以显示行号
PS1=$ 进入到家目录在.bashrc 中
https://blog.csdn.net/qq_40797605/article/details/89075918

 浙公网安备 33010602011771号
浙公网安备 33010602011771号