[转]拜占庭故障 & Paxos 算法
1、拜占庭故障具体是什么分类呢?
2、拜占庭故障出现在哪里?出现在硬件中,还是软件中,出现在操作系统中吗?
比如,拜占庭故障会不会出现在云计算中。
博客一:拜占庭故障(zz)
这个问题是在1982年由Lamport, Shostak, Pease 提出 ——The problem of reaching a consensus among distributed units if some of them give misleading answers. (在分布式单元中的其中几个成员给出错误讯息的条件下,使分布式单元达到一致的难题。)The original problem(原始问题是关于几个将军策划政变。其中有些将军撒谎说可以支持一个具体的计划,或者支持其他将军告诉他们的话。) concerns generals plotting a coup. Some generals lie about whether they will support a particular plan and what other generals told them. What percentage of liars can a decision making algorithm tolerate and still correctly determine a consensus? (一个决策算法可以容忍多少百分比的骗子,然后仍然能够正确确定共识?)
最后结论是:既要想容忍t个判国者,必须保证总的将军的个数大于3t。(数学难题)
一、拜占庭将军算法的背景:
对于系统坏掉的风险,可以这样假设:我们的操作员可能会误操作、可能会被贿赂或背叛,系统本身可能就有木马程序,系统可能会被黑客或病毒占领,我们自己开发的系统可能有漏洞,我们的开发人员可能会留下后门,这些都可以导致系统坏掉。因此,在这些假设在变成可能的残酷现实中,拜占庭故障是应真正被采用的一种信息安全技术。 入侵容忍体系就是生存技术中的核心。如果我们的网络和系统(操作系统,数据库系统,云计算)学会生存,那么也就是建立起一个完善的入侵容忍体系。 入侵容忍的技术在这样的假设空间中实现它的价值:个人的公开行为在一定的概率下是可预知的,系统在一定的概率下能够正确完成基本的功能。一定的概率并不是指全部,所以,可以允许有错误,因此,入侵容忍还有对纠错理论的联想:即利用纠错码可以在一个错误百出、但有信道容量的信道中准确无误地传输数据,网络系统就这样在错误中“生存”下来的,这就是我们说的入侵容忍体系,它的生存技术有两种实现方式:一是攻击响应的入侵容忍方法,它不需要重新设计系统,可通过高效的检测系统发现异常,利用资源配置系统调整系统资源,并对对错误进行修补(修补系统);二是攻击遮蔽的入侵容忍方法,它需要重新设计整个系统,并通过冗余、容错技术,门槛密码学技术及“拜占庭”技术来实现。-----------------------------------------------
二、算法介绍: “拜占庭”技术,起源于拜占廷将军问题,这是入侵容忍体系的一个基本理论问题。在1982年被提出的“拜占廷将军问题”在今天被许多学者看好,然而在商业上还没有体现其价值。特别是中国的产业界把它放在了一个被遗忘的角落。
描述如下:
几个师包围着敌人的一座城市。每一个师都由它自己的司令统帅,司令之间只能通过报信者互相通信。他们必须统一行动 。
某一位或几位司令可能是叛徒,企图破坏忠诚的司令们的统一行动 。
司令们必须有一个算法,使所有忠诚的司令能够达成一致,而且少数几个叛徒不能使忠诚的司令们做出错误的计划,即判国的将军虽然可以传递了虚假消息,也不会影响爱国的将军得到正确的决策。
拜占廷将军问题就是要让爱国的将军达成一致,而不是找叛国的将军。
我们的入侵容忍体系就是这样,只要在众多服务器上得到的正确的计算结果,,那么我们就可以相信这个数据,而不需要去寻找到底谁是间谍。如果要容忍一个捣乱的服务器,在数量上究竟会需要几个服务器?“拜占廷将军”问题可以为我们解答这个问题:在进行混乱真实消息的传播中,两个将军中一个判国,另一个肯定打败仗,三个将军中如果有一个判国,则判国的将军一定有办法让两个爱国的将军不能达成一致,若再增加一个将军,既4个将军中如果只有一个判国,在不知道谁是判国者的情况下,存在一种算法使将军们达成一致,实际上就是三个爱国的将军能够达成一致,而不管判国的将军如何捣乱。既4个将军的团体能够容忍1个叛国将军。同样我们知道,当有t个判国者在捣乱而又无法找出他们的时候,存在一种算法或称做弹性协议,通过这种协议,能够保证爱国的将军达成一致。如果我们把能够容忍t个叛国者的协议叫t弹性协议,学者证明了,不存在3t个将军下的t弹性协议而一定存在3t+1或以上将军下的t弹性协议。就是说要有3t+1个或以上将军才能保证爱国的将军能够达成一致。既要想容忍t个判国者,必须保证总的将军的个数大于3t。 这样看来,“拜占廷将军”问题应用于信息安全就是入侵容忍体系的重要技术基础之一。以上讲述的仅仅是“拜占廷将军”问题中简化描述,加之以叙述的形式,就是一个描述性的推理,实际上“拜占廷将军”问题程序计算的方法是很复杂的。 据荆老师的介绍,作为入侵容忍体系的理论问题,它可以应用在现实中。实验室开发的CA入侵容忍资料库系统就是应用的案例。当用户查找证书的时候,如何保证得到的是最新的证书而不是过期的证书呢?如果一个服务器保留已经作废的证书欺骗你会如何呢。利用拜占廷法定数目团体系统,实验室很好地解决了这个问题。即使 t个服务器捣乱,输出旧的证书,系统利用拜占廷协议,保证用户一定能够得到最新的证书。 由此看来,入侵容忍技术作为网络生存的重要技术,是保证网络和系统安全的一个新的概念和思路。网络的等级保护不仅仅是空间的,也应该是逻辑上的和技术上的。深层防御就是在不同的地方,用不同的方式,建立多条防线,保护关键网络,入侵容忍技术在这个方面就有这不俗的表现。
最后对于如何更好的开发和利用生存技术、如何建立完善入侵容忍体系的问题,荆老师神情急切,他说,这应该是当前中国信息安全最需要的。-----------------------------------------------
英文解释:这个问题是在1982年由Lamport, Shostak, Pease提出,后少人问津。为了利于对“拜占廷将军”问题原意的理解和避免曲解,把英文解释奉上: Byzantine General Problem ——The problem of reaching a consensus among distributed units if some of them give misleading answers. The original problem concerns generals plotting a coup. Some generals lie about whether they will support a particular plan and what other generals told them. What percentage of liars can a decision making algorithm tolerate and still correctly determine a consensus?
三。具体分析:
1。叛徒数大于或等于1/3,拜占庭问题不可解。
情况一:A,B,C三个司令,C是叛徒。A发消息给B,C“进攻”,C发消息给B“撤退”(因为是叛徒)。B收到两个矛盾的命令,无法作出决策。
情况二:A,B,C三个司令,A是叛徒。A发消息给B“进攻”,发消息给C“撤退”(因为是叛徒)。B。C收到不同的命令。
2.用口头信息,叛徒数少于1/3,拜占庭问题可解.
口头信息三条件
传送正确
接收者知道是谁发的
沉默(不发信息)可被检测
什么叫可解?
IC1:所有忠诚副官(B.C,指消息接受者)遵循同一命令。
IC2:若司令(A,消息)是忠诚的,所有忠诚副官遵循其命令
可以证明,多项式复杂性算法OM(m)可以解决拜占庭问题(L Lamport, R Shostak, and M Pease. The Byzantine generals problem. ACM Transactions on Programming Languages and Systems, 1982, 4(3))
如果记容忍t个叛国者的协议叫t弹性协议(即,在t弹性协议存在的情况下,可以胜利),则:
n如果记容忍t个叛国者的协议叫t弹性协议,则:
当n=3时,不存在1弹性协议
当n>=1,不存在t>=n/3的t弹性协议
发送者发送他的值给每个接收者
如果第i个接收者获得的值是vi, 接收者i执行算法OM(m-1)发送vi给n-2个其他的接收者
第i个接收者会收到从不同n-1人发来的n-1个值, 取多数认同的值就可以 nOM(m),m>0
failure的分类:
1。内容failure:the content of the information delivered at the service interface deviates from implementing the system function.
2. 时间failure:the time of arrival or the duration of the information delivered at the service interface deviates from implementing the system function.
当时间和内容都发生错误时:
1。停止failure: when the service is halted, a special case of halt is silent failure, or simply silence, when no service at all is delivered at the service interface.
2. Erratic failure: when a service is delivered, but is erratic.胡说错误,哈哈
关于failure是否可以探测到,分两种情况:
1. signaled failures: the system signals service failures to the users.
2. unsignaled failures: no warning from the system is given.
但是探测本身也会有误报,比如:
false alarm: signaling a failure when no failure has actually occurred.
failure本身也有一致性或者非一致性的问题:
consistent failure: the incorrect service is perceived identically by all system users.
inconsistent failures: some or all system users perceive the incorrect service differently, but some users may perceive a correct service;这个就是所说的byzantine failure:)
failure 的严重性:
1. outage duration
2. possibility of human lives being endangered
3. the type of information that may be unduly disclosed.
4. the extent of the corruption of data and the ability to recover from these corruptions
下边来说说拜占庭错误:
拜占庭错误是一个非一致的,不可检测的内容错误;
也可以定义为交互的非一致错误
看一个例子: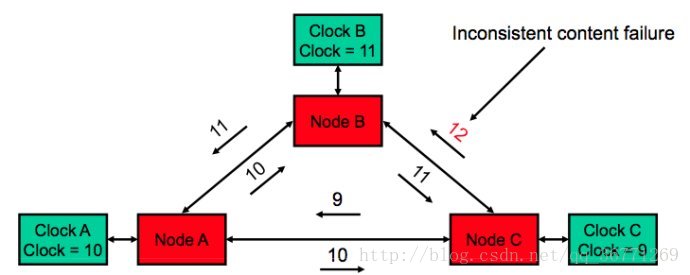
假设三个节点以取中位数的方式同步,三个节点各自持有的数字分别位10 11 12, 但节点c出现了byzatine错误,所以他向节点b发送了错误的数字12,因为节点b自己持有的数字位11,所以它只能在10 11 12中取中位数=11,但实际节点a和c最后决定的中位数是10;
节点c的错误导致了一个无辜的节点b做出了错误的决策;
假设多股军队计划同时攻打某城池,这些军队的commande被一个将军领导,但其中一个或几个可能是叛徒,所以如果想获得胜利,就一定要让忠诚的commander同时发动进攻,但叛徒会用错误的信息扰乱进攻时间,避免的方式就是所有的commander共同交换信息,以判定叛徒;
该算法的目标是:
1。忠诚的commander遵守同样的命令;
2。如果将军也是忠诚的,所有忠诚的commander遵守该将军发布的命令;
算法的需求:
1。如果存在3m+1个unit,则可容错1个unit的byzantine错误
2。至少m+1轮的消息传递
3。所有unit同步;
算法的假设:
1。不会丢失消息;
2。消息接收者知道谁是发送者
3。消息丢失可被探测;
算法开始:
1。将军的命令被送到每个commander
2。每个接收者使用该命令或使用retreat状态;
算法进行;
1。将军的命令被发布到每个节点;
2。每个接收者使用该命令或使用retreat状态(如未收到任何命令),每个接受者如将军般向其他n-2个commander继续转发命令(不发给自己和消息来源)
3。重复以上过程;最后得到命令集合{vi…..vj}
如为了容一个错,使用4个节点: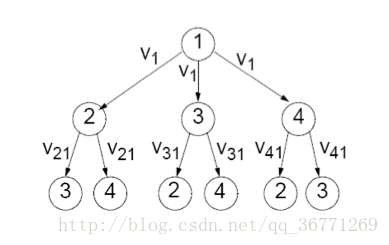
unit2 将向节点3,4继续转发命令,同时也收到节点3,4转发的命令,节点2在{v1 v31 v41}使用少数服从多数的方式获取最终命令;
对于获得一个共识的消息数量:3+2*3=9条
则对于4个节点或许4个共识而言,消息数量是 4*9=36条;
对于一个能容2个错的7节点系统来说
获取一个共识的消息数量:6+6*(5+5*4)=156条
消息总数:7*156
Paxos 算法:https://baike.baidu.com/item/Paxos%20%E7%AE%97%E6%B3%95/10688635
比特币如何达成共识 - 最长链的选择
比特币没有中心机构,几乎所有的完整节点都有一份公共总帐本,那么大家如何达成共识:确认哪一份才是公认权威的总账本呢?
比特币没有中心机构,几乎所有的完整节点都有一份公共总帐本,那么大家如何达成共识:确认哪一份才是公认权威的总账本呢?
为什么要遵守协议
这其实是一个经济问题,在经济活动中的每个人都是自私自利的,追求的是利益的最大化,一个节点工作量只有在其他的节点认同其是有效的(打包的新区块,其他的节点只有验证通过才会加入到区块链中,并在网络上传播),才能够过得收益,
而只有遵守规则才会得到其他的节点认同。
因此,基于逐利,节点就会自发的遵守协议。共识就是数以万计的独立节点遵守了简单的规则(通过异步交互)自发形成的。
共识:共同遵守的协议规范
去中心化共识
在工作量证明一篇,我们了解通过工作量证明来竞争记账,权威的总帐本是怎么达到共识的,没有完全说清楚,今天补上,
实际上,比特币的共识由所有节点的 4 个独立过程相互作用而产生:
- 每个节点(挖矿节点)依据标准对每个交易进行独立验证
- 挖矿节点通过完成工作量证明,将交易记录独立打包进新区块
- 每个节点独立的对新区块进行校验并组装进区块链
- 每个节点对区块链进行独立选择,在工作量证明机制下选择累计工作量最大的区块链
共识最终目的是保证比特币不停的在工作量最大的区块链上运转,工作量最大的区块链就是权威的公共总帐本。
第 1 2 3 步在比特币如何挖矿-工作量证明一篇有提到过,下面着重讲第 4 步。
最长链的选择
先来一个定义,把累计了最多难度的区块链。在一般情况下,也是包含最多区块的那个链称为主链
每一个(挖矿)节点总是选择并尝试延长主链。
分叉
当有两名矿工在几乎在相同的时间内,各自都算得了工作量证明解,便立即传播自己的“获胜”区块到网络中,先是传播给邻近的节点而后传播到整个网络。每个收到有效区块的节点都会将其并入并延长区块链。
当这个两个区块传播时,一些节点首先收到#3458A, 一些节点首先收到#3458B,这两个候选区块(通常这两个候选区块会包含几乎相同的交易)都是主链的延伸,分叉就会产生,这时分叉出有竞争关系的两条链,如图: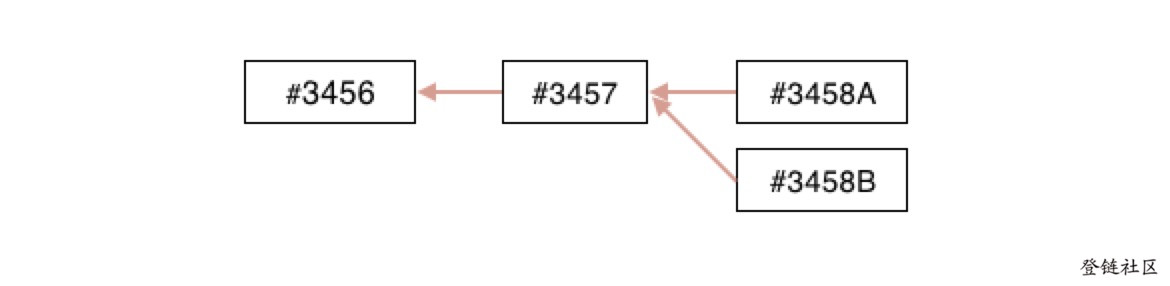
两个块都收到的节点,会把其中有更多工作量的一条会继续作为主链,另一条作为备用链保存(保存是因为备用链将来可能会超过主链难度称为新主链)。
分叉解决
收到#3458A 的(挖矿)节点,会立刻以这个区块为父区块来产生新的候选区块,并尝试寻找这个候选区块的工作量证明解。同样地,接受#3458B 区块的节点会以这个区块为链的顶点开始生成新块,延长这个链(下面称为 B 链)。
这时总会有一方抢先发现工作量证明解并将其传播出去,假设以#3458B 为父区块的工作量证明首先解出,如图: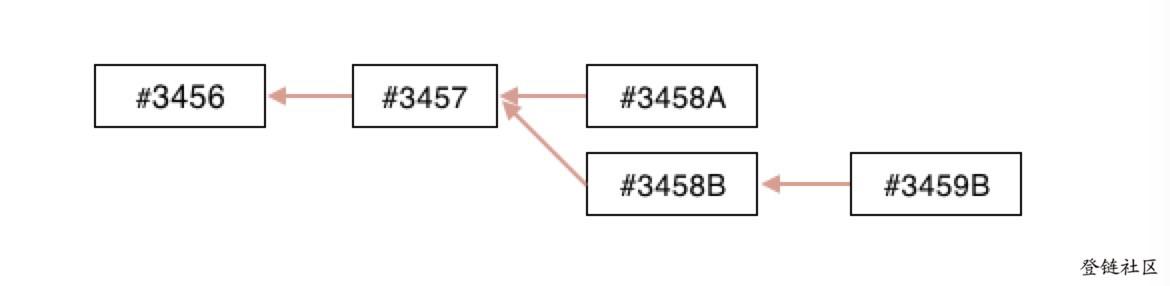
当原本以#3458A 为父区块求解的节点在收到#3458B, #3459B 之后,会立刻将 B 链作为主链(因为#3458A 为顶点的链已经不是最长链了)继续挖矿。
节点也有可能先收到#3459B,再收到#3458B,收到#3459B 时,会被认为是“孤块“(因为还找不到#3459B 的父块#3458B)保存在孤块池中,一旦收到父块#3458B 时,节点就会将孤块从孤块池中取出,并且连接到它的父区块,让它作为区块链的一部分。
比特币将区块间隔设计为 10 分钟,是在更快速的交易确认和更低的分叉概率间作出的妥协。更短的区块产生间隔会让交易确认更快地完成,也会导致更加频繁地区块链分叉。与之相对地,长的间隔会减少分叉数量,却会导致更长的确认时间。
比特币如何挖矿(挖矿原理)-工作量证明
在区块链记账原理一篇,我们了解到记账是把交易记录、交易时间、账本序号、上一个Hash值等信息计算Hash打包的过程。 我们知道所有的计算和存贮是需要消耗计算机资源的,既然要付出成本,那节点为什么还要参与记账呢?在中本聪(比特币之父)的设计里,完成记账的节点可以获得系统给与的一定数量的比特币奖励,这个奖励的过程也就是比特币的发行过程,因此大家形象的把记账称为“挖矿”,本文将详细讨论这个过程。
在 区块链记账原理 一篇,我们了解到记账是把交易记录、交易时间、账本序号、上一个 Hash 值等信息计算 Hash 打包的过程。
我们知道所有的计算和存贮是需要消耗计算机资源的,既然要付出成本,那节点为什么还要参与记账呢?在中本聪(比特币之父)的设计里,完成记账的节点可以获得系统给与的一定数量的比特币奖励,这个奖励的过程也就是比特币的发行过程,因此大家形象的把记账称为“挖矿”,本文将详细讨论这个过程。
记账工作
由于记账是有奖励的,每次记账都可以给自己凭空增加一定数量的个比特币(当前是 12.5 比特币,博文写作时每个比特币是 4 万人民币以上,大家可以算算多少钱),因此就出现大家争相记账,大家一起记账就会引起问题:出现记账不一致的问题,比特币系统引入工作量证明来解决这个问题,规则如下:
- 一段时间内(10 分钟左右,具体时间会与密码学难题难度相互影响)只有一人可以记账成功
- 通过解决密码学难题(即工作量证明)竞争获得唯一记账权
- 其他节点复制记账结果
不过在进行工作量证明之前,记账节点会做进行如下准备工作:
- 收集广播中还没有被记录账本的原始交易信息
- 检查每个交易信息中付款地址有没有足够的余额
- 验证交易是否有正确的签名
- 把验证通过的交易信息进行打包记录
- 添加一个奖励交易:给自己的地址增加 12.5 比特币
如果节点争夺记账权成功的话,就可以得到 12.5 比特币的奖励。
工作量证明
{% post_link whatbc 区块链记账原理 %}我们了解到,每次记账的时候会把上一个块的 Hash 值和当前的账页信息一起作为原始信息进行 Hash。
如果仅仅是这样,显然每个人都可以很轻松的完成记账。
为了保证 10 分钟左右只有一个人可以记账,就必须要提高记账的难度,使得 Hash 的结果必须以若干个 0 开头。同时为了满足这个条件,在进行 Hash 时引入一个随机数变量。
用伪代码表示一下:
Hash(上一个Hash值,交易记录集) = 456635BCD
Hash(上一个Hash值,交易记录集,随机数) = 0000aFD635BCD
我们知道改变 Hash 的原始信息的任何一部分,Hash 值也会随之不断的变化,因此在运算 Hash 时,不断的改变随机数的值,总可以找到一个随机数使的 Hash 的结果以若干个 0 开头(下文把这个过程称为猜谜),率先找到随机数的节点就获得此次记账的唯一记账权。
计算量分析
(这部分可选阅读)我们简单分析下记账难度有多大,
Hash 值是由数字和大小写字母构成的字符串,每一位有 62 种可能性(可能为 26 个大写字母、26 个小写字母,10 个数字中任一个),假设任何一个字符出现的概率是均等的,那么第一位为 0 的概率是 1/62(其他位出现什么字符先不管),理论上需要尝试 62 次 Hash 运算才会出现一次第一位为 0 的情况,如果前两 2 位为 0,就得尝试 62 的平方次 Hash 运算,以 n 个 0 开头就需要尝试 62 的 n 次方次运算。我们结合当前实际区块#493050 信息来看看:
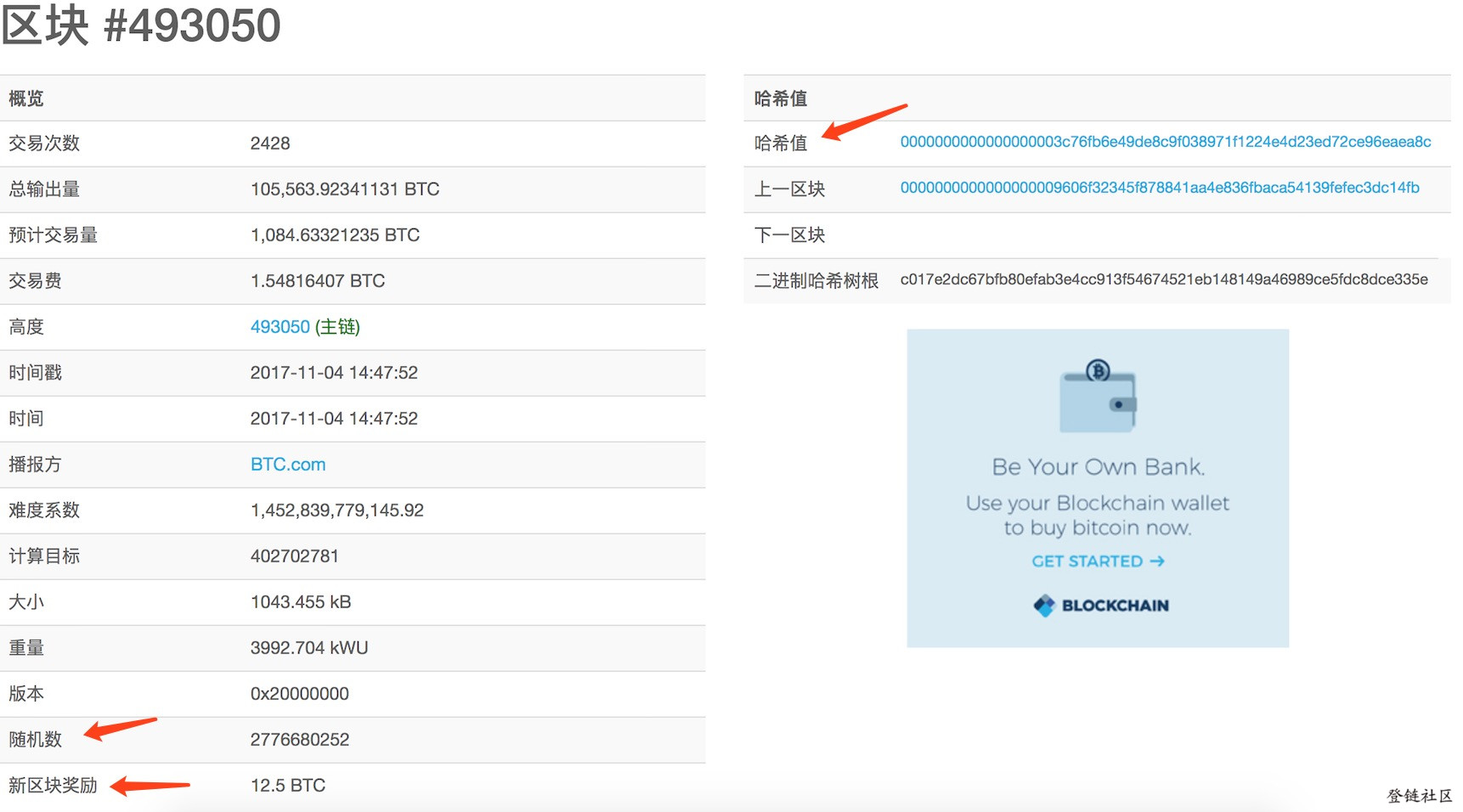
注:数据来源于 https://blockchain.info
我们可以看到 Hash 值以 18 个 0 开头,理论上需要尝试 62 的 18 次方次,这个数是非常非常巨大的,我已经算不清楚了,应该是亿亿级别以上了。如此大的计算量需要投入大量的计算设备、电力等,
目前应该没有单矿工独立参与挖矿了,基本都是由矿工联合起来组成矿池进行挖矿(矿池里的矿工按算力百分比来分收益)。
从经济的角度讲,只有挖矿还有收益(比特币价格不断上涨也让收益变大),就会有新的矿工加入,从而加剧竞争,提高算力难度,挖矿就需要耗费更多的运算和电力,相互作用引起最终成本会接近收益。
题外话:国内由于电力成本较低,相对收益更高,中国的算力占整个网络的一半以上
验证
在节点成功找到满足的 Hash 值之后,会马上对全网进行广播打包区块,网络的节点收到广播打包区块,会立刻对其进行验证。
如果验证通过,则表明已经有节点成功挖出区块,自己就不再竞争当前区块打包,而是选择接受这个区块,记录到自己的账本中,然后进行下一个区块的竞争猜谜。
网络中只有最快解谜的区块,才会添加的账本中,其他的节点进行复制,这样就保证了整个账本的唯一性。
假如节点有任何的作弊行为,都会导致网络的节点验证不通过,直接丢弃其打包的区块,这个区块就无法记录到总账本中,作弊的节点耗费的成本就白费了,因此在巨大的挖矿成本下,也使得矿工自觉自愿的遵守比特币系统的共识协议,也就确保了整个系统的安全。
进阶阅读比特币区块结构 Merkle 树及简单支付验证分析,可以详细了解区块结构如何验证交易。
说明
矿工的收益其实不仅仅包含新发行的 12.5 比特币奖励,同时还有交易费收益(本文忽略一些细节是为了让主干更清晰)。
有兴趣的同学可以看看图中区块都包含了那些信息,红箭头标示出的是本文涉及的信息。
本文中有提到共识协议,比特币共识协议主要是由工作量证明和最长链机制 两部分组成,请阅读比特币如何达成共识 - 最长链的选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号