nlp跳坑基础
准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F值(F-Measure)、AUC、ROC的理解
一、准确率、精确率、召回率和 F 值 是选出目标的重要评价指标。不妨看看这些指标的定义先:
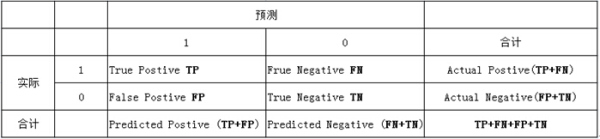
(1)若一个实例是正类,但是被预测成为正类,即为真正类(True Postive TP)
(2)若一个实例是负类,但是被预测成为负类,即为真负类(True Negative TN)
(3)若一个实例是负类,但是被预测成为正类,即为假正类(False Postive FP)
(4)若一个实例是正类,但是被预测成为负类,即为假负类(False Negative FN)
下表中:1代表正类,0代表负类:
TP:正确的匹配数目
FP:误报,没有的匹配不正确
FN:漏报,没有找到正确匹配的数目
TN:正确的非匹配数目
准确率(正确率)=所有预测正确的样本/总的样本 (TP+TN)/总
精确率= 将正类预测为正类 / 所有预测为正类 TP/(TP+FP)
召回率 = 将正类预测为正类 / 所有正真的正类 TP/(TP+FN)
F值 = 精确率 * 召回率 * 2 / ( 精确率 + 召回率) (F 值即为精确率和召回率的调和平均值)
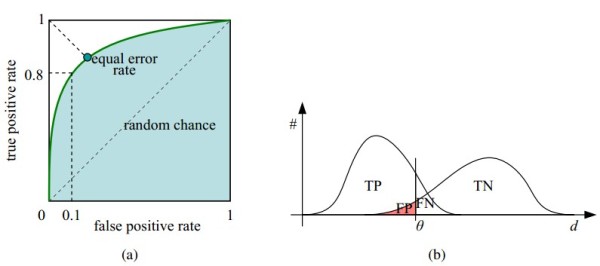
二、ROC曲线:接收者操作特征(receiver operating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性。
纵轴:真正类率(true postive rate TPR),也叫真阳性率
横轴:假正类率(false postive rate FPR),也叫伪阳性率
由上表可得出横,纵轴的计算公式:
(1)真正类率(True Postive Rate)TPR: TP/(TP+FN), 代表分类器 预测为正类中实际为正实例
占 所有正实例 的比例。
(2)假正类率(False Postive Rate)FPR: FP/(FP+TN),代表分类器 预测为正类中实际为负实例 占 所有负实例 的比例。
如下图所示,(a)图中实线为ROC曲线,(深绿色)线上每个点对应一个阈值(threshold)。假设是二分类分类器,输出为每个实例预测为正类的概率。那么通过设定一个特定阈值(threshold),预测为正类的概率值 大于等于 特定阈值的为 正类,小于 特定阈值的为 负类,然后统计TP、TN、FP、FN每个类别的数目,然后根据上面的公式,就能对应的就可以算出一组 特定阈值下(FPR,TPR)的值,即 在平面中得到对应坐标点。如果这里没懂也没关系,下面有详细的例子说明。
右上角的阈值最小,对应坐标点(1,1);左下角阈值最大,对应坐标点为(0,0)。从右上角到左下角,随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。
横轴FPR: FPR越大,预测正类中实际负类越多。
纵轴TPR:TPR越大,预测正类中实际正类越多。
理想目标:TPR=1,FPR=0,即图中(0,1)点,此时ROC曲线越靠拢(0,1)点,越偏离45度对角线越好。
三、如何画roc曲线
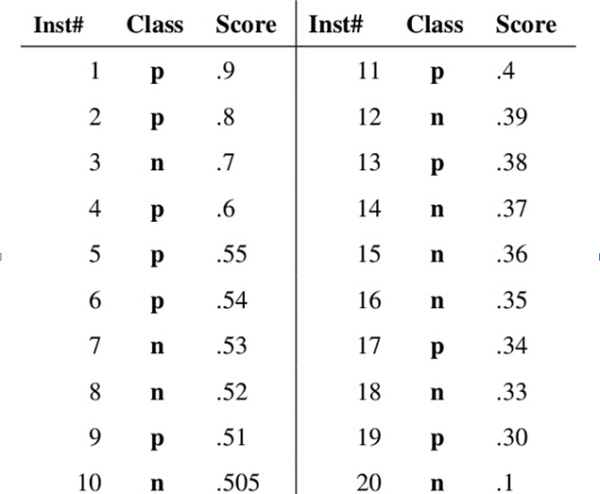
假设已经得出一系列样本被划分为正类的概率,然后按照概率大小排序,如下图所示,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本,10个正样本,10个负样本),“Score”表示每个测试样本预测为正样本的概率。接下来,我们从高到低,依次将“Score”值作为阈值(threshold),当样本的正样本的预测概率大于或等于这个阈值时,我们认为它为正样本,否则为负样本。
举例来说,
1)对于图中的第20个样本,其“Score”值为0.1,那么所有样本都被认为是正样本,因为它们的“Score”值都大于等于0.1,没有负样本。即TP值10(样本1,2,4,5,6,9,11,13,17,19),TN值为0,FP值为10(样本3, 7,8,10,12,14,15,16,18,20),FN值为 0。 TPR值为TP/(TP+FN)=10/(10+0)=1, FPR值为FP/(FP+TN)=10/(10+0)=1 所以阈值为0.1时,对应的点为(1,1)。
2)对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。即TP值为3(样本1,2,4),TN值为9(样本7,8,10,12,14,15,16,18,20),FP值为1(样本3),FN值为 7(样本5,6,9,11,13,17,19)。 TPR值为TP/(TP+FN)=3/(3+7)=0.3, FPR值为FP/(FP+TN)=1/(1+9)=0.1 所以阈值为0.6时,对应的点为(0.1,0.3)。
3)对于图中的第1个样本,其“Score”值为0.9,那么样本1被认为是正样本,因为它们的“Score”值都大于等于0.9,而其他样本则都认为是负样本。即TP值为1(样本1),TN值为0 ,FP值为9,FN值为10(样本3, 7,8,10,12,14,15,16,18,20) TPR值为TP/(TP+FN)=1(1+9)=0.1, FPR值为FP/(FP+TN)=0/(0+10)=0 所以阈值为0.9时,对应的点为(0.1,0)
每次选取一个不同的阈值,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图:
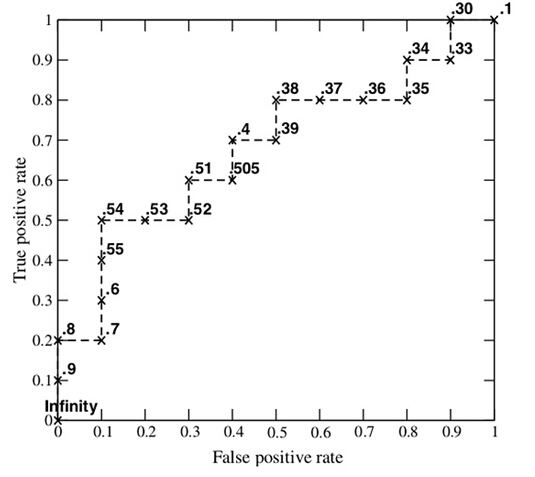
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间。AUC作为数值可以直观的评价分类器的好坏,值越大越好。
首先AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
四、AUC计算
1. 最直观的,根据AUC这个名称,我们知道,计算出ROC曲线下面的面积,就是AUC的值。事实上,这也是在早期 Machine Learning文献中常见的AUC计算方法。由于我们的测试样本是有限的。我们得到的AUC曲线必然是一个阶梯状的。因此,计算的AUC也就是这些阶梯下面的面积之和。这样,我们先把score排序(假设score越大,此样本属于正类的概率越大),然后一边扫描就可以得到我们想要的AUC。但是,这么做有个缺点,就是当多个测试样本的score相等的时候,我们调整一下阈值,得到的不是曲线一个阶梯往上或者往右的延展,而是斜着向上形成一个梯形。此 时,我们就需要计算这个梯形的面积。由此,我们可以看到,用这种方法计算AUC实际上是比较麻烦的
2. 一个关于AUC的很有趣的性质是,它和Wilcoxon-Mann-Witney Test是等价的。而Wilcoxon-Mann-Witney Test就是测试任意给一个正类样本和一个负类样本,正类样本的score有多大的 概率 大于负类样本的score。有了这个定义,我们就得到了另外一个计算AUC的办法:得到这个概率。我们知道,在有限样本中我们常用的得到概率的办法就是通过频率来估计之。这种估计随着样本规模的扩大而逐渐逼近真实值。这和上面的方法中,样本数越多,计算的AUC越准确类似,也和计算积分的时候,小区间划分的越细,计算的越准确是同样的道理。具体来说就是统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以M*N。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)
3. 第三种方法实际上和上述第二种方法是一样的,但是复杂度减小了。它也是首先对score从大到小排序,然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。然后把所有的正类样本的rank相加,再减去M-1种两个正样本组合的情况。得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。然后再除以M×N。即,
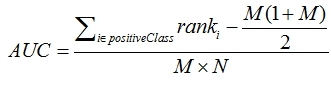
公式解释:
1、为了求的组合中正样本的score值大于负样本,如果所有的正样本score值都是大于负样本的,那么第一位与任意的进行组合score值都要大,我们取它的rank值为n,但是n-1中有M-1是正样例和正样例的组合这种是不在统计范围内的(为计算方便我们取n组,相应的不符合的有M个),所以要减掉,那么同理排在第二位的n-1,会有M-1个是不满足的,依次类推,故得到后面的公式M*(M+1)/2,我们可以验证在正样本score都大于负样本的假设下,AUC的值为 2、根据上面的解释,不难得出,rank的值代表的是能够产生score前大后小的这样的组合数,但是这里包含了(正,正)的情况,所以要减去这样的组(即排在它后面正例的个数),即可得到上面的公式 另外,特别需要注意的是,再存在score相等的情况时,对相等score的样本,需要 赋予相同的rank(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是再把所有这些score相等的样本 的rank取平均。然后再使用上述公式。
“无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。”
NLP-准确率、精确率、召回率和F1值
记录准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F-Measure)计算公式,和如何使用TensorFlow实现
一、计算公式
- True Positive(TP):将正类预测为正类数
- True Negative(TN):将负类预测为负类数
- False Positive(FP):将负类预测为正类数
- False Negative(FN):将正类预测为负类数
1.准确率:
Accuracy=TP+TNTP+TN+FP+FNAccuracy= \frac{TP+TN}{TP+TN+FP+FN}Accuracy=TP+TN+FP+FNTP+TN

2.精确率:
Precision=TPTP+FPPrecision= \frac{TP}{TP+FP}Precision=TP+FPTP
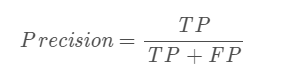
3.召回率:
Recall=TPTP+FNRecall= \frac{TP}{TP+FN}Recall=TP+FNTP
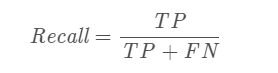
4.F1值
F1=2∗Pre∗RecPre+Rec=2∗TP2∗TP+FP+FNF1= \frac{2*Pre*Rec}{Pre+Rec}= \frac{2*TP}{2*TP+FP+FN}F1=Pre+Rec2∗Pre∗Rec=2∗TP+FP+FN2∗TP

二、TensorFlow实现
- Accuracy
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions,self.input_y)
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
- TN;TP;FN;FP
with tf.name_scope("tn"):
tn = tf.metrics.true_negatives(labels=self.input_y, predictions=self.predictions)
self.tn = tf.reduce_sum(tf.cast(tn, "float"), name="tn")
with tf.name_scope("tp"):
tp = tf.metrics.true_positives(labels=self.input_y, predictions=self.predictions)
self.tp = tf.reduce_sum(tf.cast(tn, "float"), name="tp")
with tf.name_scope("fp"):
fp = tf.metrics.false_positives(labels=self.input_y, predictions=self.predictions)
self.fp = tf.reduce_sum(tf.cast(fp, "float"), name="fp")
with tf.name_scope("fn"):
fn = tf.metrics.false_negatives(labels=self.input_y, predictions=self.predictions)
self.fn = tf.reduce_sum(tf.cast(fn, "float"), name="fn")
- Recall;Precision;F1
with tf.name_scope("recall"):
self.recall = self.tp / (self.tp + self.fn)
with tf.name_scope("precision"):
self.precision = self.tp / (self.tp + self.fp)
with tf.name_scope("F1"):
self.F1 = (2 * self.precision * self.recall) / (self.precision + self.recall)
自然语言处理之准确率、召回率、F1理解
在信息检索、分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常重要。
1、准确率与召回率(Precision & Recall)
准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中精度是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数
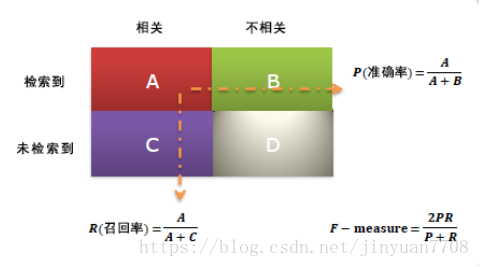
注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。通常,我们希望准确率和召回率均越高越好,但事实上这两者在某些情况下是矛盾的。
比如我们只搜出了一个结果,此结果是正确的,求得precisin等于1。但是由于只搜出一个结果,recall值反而很低,接近于0。所以需要综合考量,下面介绍F-measure。
2、F-measure
F-measure又称F-score,其公式为:

其中F2值,更加注重召回率;F0.5值更加重视准确率。
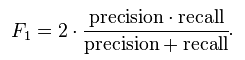
F-measure综合了precision和recall,其值越高,通常表示算法性能越好。
精度和召回率
https://en.wikipedia.org/wiki/Precision_and_recall

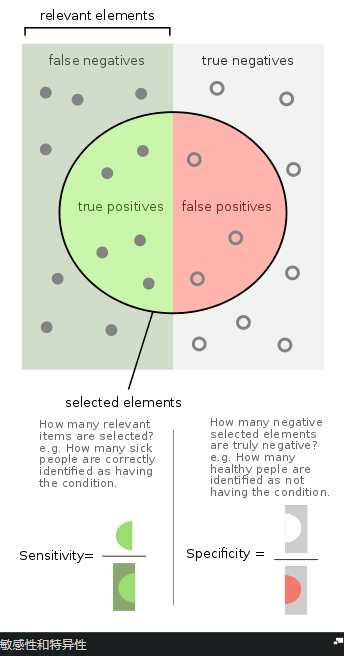
精度precision和召回率recall
在模式识别,信息检索information retrieval和分类classification(机器学习)中,
精度(也称为正预测值,正向预测值positive predictive value)是 相关实例relevant instances在 检索实例retrieved instances中的占比,
relevant elements相关元素
false negatives假阴性,漏报率
true negatives真阴性
true positives真阳性
false positives假阳性,主动误报率
selected elements选中的元素
How many selected items are relevant?多少选中的元素是相关的?
Precision精度,精密度,精准度
How many relevant items are selected?多少相关的元素被选中?
Recall召回率
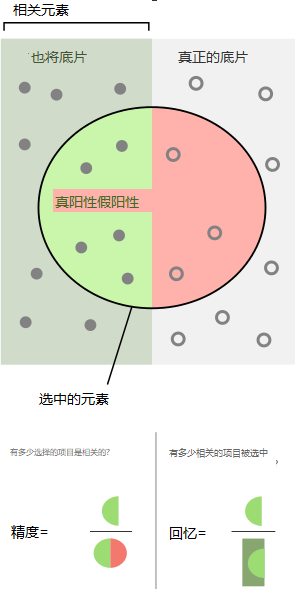
而召回recall(也称为敏感度sensitivity)是实际检索到的actually retrieved在 相关实例relevant instances总数 中的占比。
准确性precision和召回recall都是基于对相关性relevance的理解和衡量。
假设 识别照片中狗数量 的程序 在包含12条狗和10条猫的图片中 识别出8条狗(实际上5只是真狗(真阳性),其余部分是猫(假阳性)),该程序的精度为5/8,而召回率(查全率)为5/12
当搜索引擎返回30个页面,其中只有20个相关页面(有用页面),而未能返回其他40个相关页面时,其精度为20/30 = 2/3,而其召回率为20/60 = 1/3。
因此在这种情况下,精度是“搜索结果的有效性how valid the search results are”,召回率(查全率)是“结果的完成度how complete the results are”。
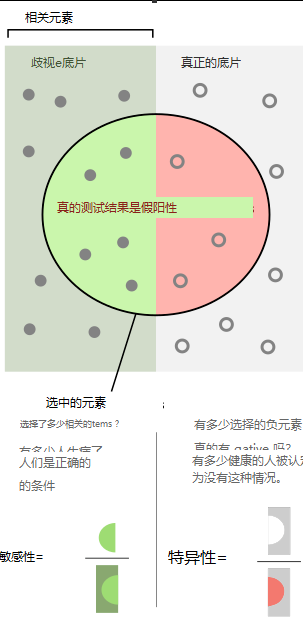
从统计中采用假设检验的方法,在这种情况下,零假设null hypothesis是给定的无关项,即不是狗,
没有(absence)I类(假阳性)和II类(假阴性)的错误(即完美的100%敏感性和100%特异性sensitivity and specificity)分别对应完美精度(无假阳性误报)和完美召回(查全,无漏报,假阴性误报)。
https://zh.wikipedia.org/zh-cn/%E9%9D%88%E6%95%8F%E5%BA%A6%E5%92%8C%E7%89%B9%E7%95%B0%E5%BA%A6
精度和召回率
Confusion Matrix(混淆矩阵) 解释
在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是错误矩阵。它是一种特定的矩阵用来呈现算法性能的可视化效果,通常是监督学习(非监督学习,通常用匹配矩阵:matching matrix)。其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。
Example
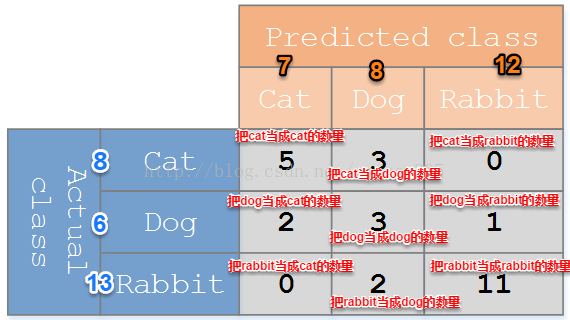
假设有一个用来对猫(cats)、狗(dogs)、兔子(rabbits)进行分类的系统,混淆矩阵就是为了进一步分析性能而对该算法测试结果做出的总结。假设总共有 27 只动物:8只猫, 6条狗, 13只兔子。结果的混淆矩阵如下图:
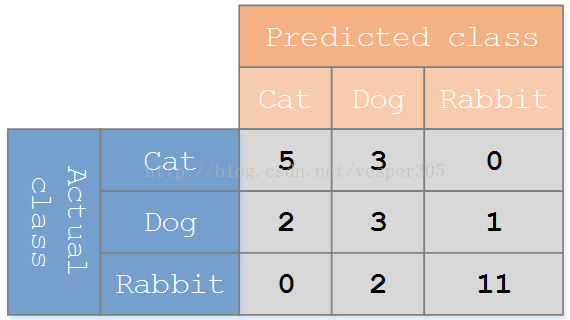
在这个混淆矩阵中,实际有 8只猫,但是系统将其中3只预测成了狗;对于 6条狗,其中有 1条被预测成了兔子,2条被预测成了猫。从混淆矩阵中我们可以看出系统对于区分猫和狗存在一些问题,但是区分兔子和其他动物的效果还是不错的。所有正确的预测结果都在对角线上,所以从混淆矩阵中可以很方便直观的看出哪里有错误,因为他们呈现在对角线外面。
Table of confusion
在预测分析中,混淆表格(有时候也称为混淆矩阵),是由false positives(正面,阳性;误报,假阳性),false negatives(负面,假阴性),true positives【真阳性】和true negatives【真阴性】组成的两行两列的表格。它允许我们做出更多的分析,而不仅仅是局限在正确率。准确率对于分类器的性能分析来说,并不是一个很好地衡量指标,因为如果数据集不平衡(每一类的数据样本数量相差太大),很可能会出现误导性的结果。例如,如果在一个数据集中有95只猫,但是只有5条狗,那么某些分类器很可能偏向于将所有的样本预测成猫。整体准确率为95%,但是实际上该分类器对猫的识别率是100%,而对狗的识别率是0%。
对于上面的混淆矩阵,其对应的对猫这个类别的混淆表格如下:

5 true positives:5真阳,真正的猫被正确地分类为猫;
2 false positives:2假阳,狗被错误地标记为猫;
3 false negatives:3加阴,猫被错误地标记为狗;
17 true negatives:17真阴,所有剩下的动物,正确地分类为非猫;
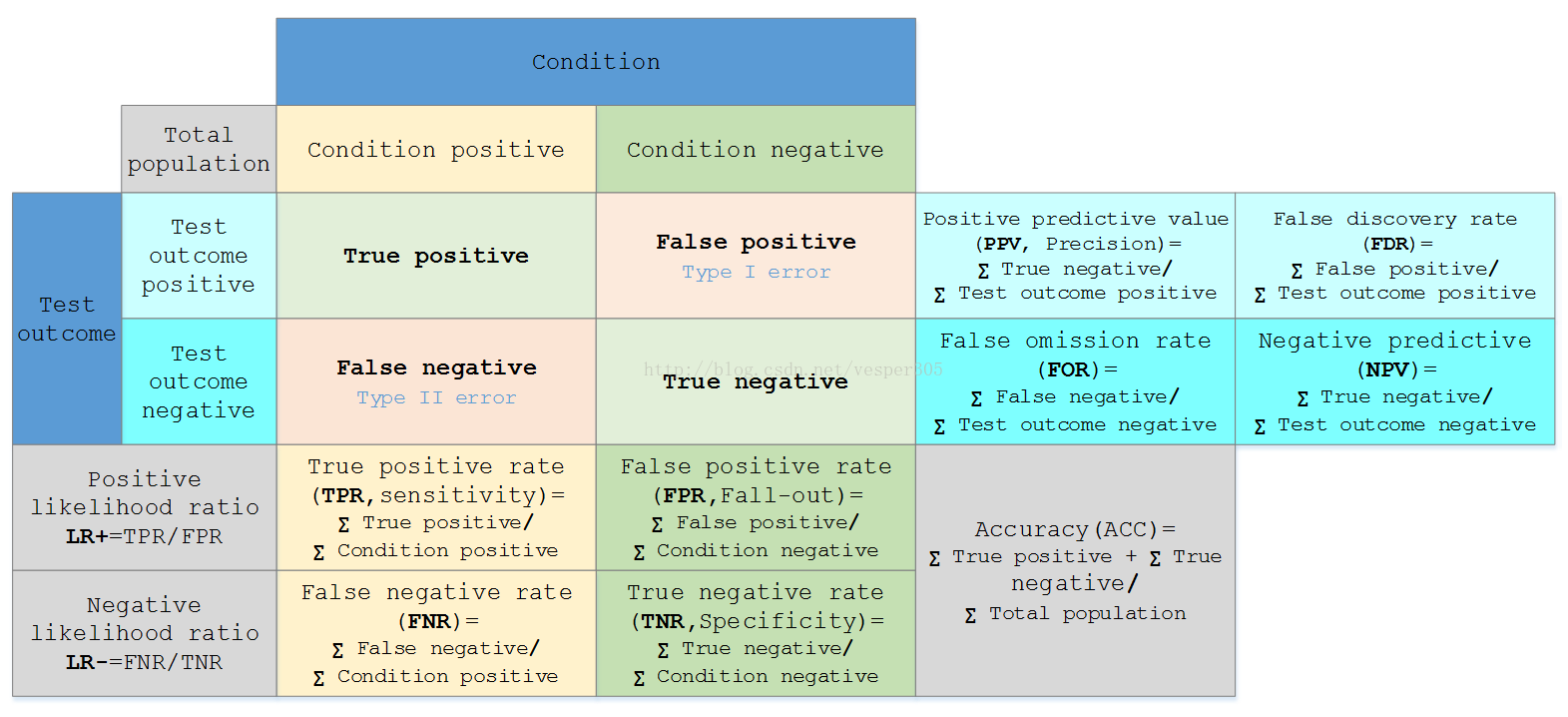
假定一个实验有 P个positive实例,在某些条件下有 N 个negative实例。那么上面这四个输出可以用下面的偶然性表格(或混淆矩阵)来表示:
公式陈列、定义如下:
|
True positive(TP) |
eqv. with hit |
|
True negative(TN) |
eqv. with correct rejection |
|
False positive(FP) |
eqv. with false alarm, Type I error |
|
False negative(FN) |
eqv. with miss, Type II error |
|
Sensitivity ortrue positive rate(TPR) eqv. with hit rate, recall |
TPR = TP/P = TP/(TP + FN) |
|
Specificity(SPC)ortrue negative rate(TNR) |
SPC = TN/N = TN/(FP + TN) |
|
Precision orpositive prediction value(PPV) |
PPV = TP/(TP + FP) |
|
Negative predictive value(NPV) |
NPV = TN/(TN + FN) |
|
Fall-out orfalse positive rate(FPR) |
FPR = FP/N = FP/(FP + TN) |
|
False discovery rate(FDR) |
FDR = FP/(FP + TP) = 1 - PPV |
|
Miss Rate orFalse Negative Rate(FNR) |
FNR = FN/P = FN/(FN + TP) |
|
|
|
|
Accuracy(ACC) |
ACC = (TP + TN)/(P + N)
|
一个完美的分类模型就是,如果一个客户实际上(Actual)属于类别good,也预测成(Predicted)good,处于类别bad,也就预测成bad。但从上面我们看到,一些实际上是good的客户,根据我们的模型,却预测他为bad,对一些原本是bad的客户,却预测他为good。我们需要知道,这个模型到底预测对了多少,预测错了多少,混淆矩阵就把所有这些信息,都归到一个表里:
预测 1 0 实 1 d, True Positive c, False Negative c+d, Actual Positive 际 0 b, False Positive a, True Negative a+b, Actual Negative b+d, Predicted Positive a+c, Predicted Negative
其中,
- a是正确预测到的负例的数量, True Negative(TN,0->0)
- b是把负例预测成正例的数量, False Positive(FP, 0->1)
- c是把正例预测成负例的数量, False Negative(FN, 1->0)
- d是正确预测到的正例的数量, True Positive(TP, 1->1)
- a+b是实际上负例的数量,Actual Negative
- c+d是实际上正例的个数,Actual Positive
- a+c是预测的负例个数,Predicted Negative
- b+d是预测的正例个数,Predicted Positive
以上似乎一下子引入了许多概念,其实不必像咋一看那么复杂,有必要过一下这里的概念。实际的数据中,客户有两种可能{good, bad},模型预测同样这两种可能,可能匹配可能不匹配。匹配的好说,0->0(读作,实际是Negative,预测成Negative),或者 1->1(读作,实际是Positive,预测成Positive),这就是True Negative(其中Negative是指预测成Negative)和True Positive(其中Positive是指预测成Positive)的情况。
同样,犯错也有两种情况。实际是Positive,预测成Negative (1->0) ,这就是False Negative;实际是Negative,预测成Positive (0->1) ,这就是False Positive;
我们可以通过SAS的proc freq得到以上数字:
proc freq data=valid_p; tables good_bad*good_bad_predicted/nopercent nocol norow; run;
对照上表,结果如下:
预测 1 0 实 1,bad d, True Positive,48 c, False Negative,98 c+d, Actual Positive,146 际 0,good b, False Positive,25 a, True Negative,229 a+b, Actual Negative,254 b+d, Predicted Positive,7 a+c, Predicted Negative,327 400
根据上表,以下就有几组常用的评估指标(每个指标分中英文两行):
1. 准确(分类)率VS.误分类率
准确(分类)率=正确预测的正反例数/总数
Accuracy=true positive and true negative/total cases= a+d/a+b+c+d=(48+229)/(48+98+25+229)=69.25%
误分类率=错误预测的正反例数/总数
Error rate=false positive and false negative/total cases=b+c/a+b+c+d=1-Accuracy=30.75%
2. (正例的)覆盖率VS. (正例的)命中率
覆盖率=正确预测到的正例数/实际正例总数,
Recall(True Positive Rate,or Sensitivity)=true positive/total actual positive=d/c+d=48/(48+98)=32.88%
/*注:覆盖率(Recall)这个词比较直观,在数据挖掘领域常用。因为感兴趣的是正例(positive),比如在信用卡欺诈建模中,我们感兴趣的是有高欺诈倾向的客户,那么我们最高兴看到的就是,用模型正确预测出来的欺诈客户(True Positive)cover到了大多数的实际上的欺诈客户,覆盖率,自然就是一个非常重要的指标。这个覆盖率又称Sensitivity, 这是生物统计学里的标准词汇,SAS系统也接受了(谁有直观解释?)。 以后提到这个概念,就表示为, Sensitivity(覆盖率,True Positive Rate)。 */
命中率=正确预测到的正例数/预测正例总数
Precision(Positive Predicted Value,PV+)=true positive/ total predicted positive=d/b+d=48/(48+25)=65.75%
/*注:这是一个跟覆盖率相对应的指标。对所有的客户,你的模型预测,有b+d个正例,其实只有其中的d个才击中了目标(命中率)。在数据库营销里,你预测到b+d个客户是正例,就给他们邮寄传单发邮件,但只有其中d个会给你反馈(这d个客户才是真正会响应的正例),这样,命中率就是一个非常有价值的指标。 以后提到这个概念,就表示为PV+(命中率,Positive Predicted Value)*。/
3.Specificity VS. PV-
负例的覆盖率=正确预测到的负例个数/实际负例总数
Specificity(True Negative Rate)=true negative/total actual negative=a/a+b=229/(25+229)=90.16%
/*注:Specificity跟Sensitivity(覆盖率,True Positive Rate)类似,或者可以称为“负例的覆盖率”,也是生物统计用语。以后提到这个概念,就表示为Specificity(负例的覆盖率,True Negative Rate) 。*/
负例的命中率=正确预测到的负例个数/预测负例总数
Negative predicted value(PV-)=true negative/total predicted negative=a/a+c=229/(98+229)=70.03%
/*注:PV-跟PV+(命中率,Positive Predicted value)类似,或者可以称为“负例的命中率”。 以后提到这个概念,就表示为PV-(负例的命中率,Negative Predicted Value)。*/
以上6个指标,可以方便地由上面的提到的proc freq得到:
proc freq data=valid_p; tables good_bad*good_bad_predicted ; run;
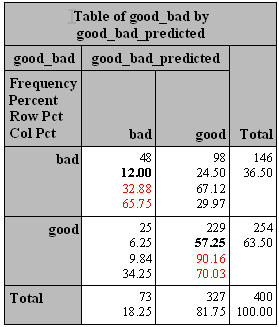
其中,准确率=12.00%+57.25%=69.25% ,覆盖率=32.88% ,命中率=65.75% ,Specificity=90.16%,PV-=70.03% 。
或者,我们可以通过SAS logistic回归的打分程序(score)得到一系列的Sensitivity和Specificity,
proc logistic data=train; model good_bad=checking history duration savings property; score data=valid outroc=valid_roc; run;
数据valid_roc中有几个我们感兴趣的变量:
- _PROB_:阈值,比如以上我们选定的0.5
- _SENSIT_:sensitivity(覆盖率,true positive rate)
- _1MSPEC_ :1-Specificity,为什么提供1-Specificity而不是Specificity,下文有讲究。
_PROB_ _SENSIT_ _1MSPEC_
0.54866 0.26712 0.07087
0.54390 0.27397 0.07874
0.53939 0.28767 0.08661
0.52937 0.30137 0.09055
0.51633 0.31507 0.09449
0.50583 0.32877 0.09843
0.48368 0.36301 0.10236
0.47445 0.36986 0.10630
如果阈值选定为0.50583,sensitivity(覆盖率,true positive rate)就为0.32877,Specificity就是1-0.098425=0.901575,与以上我们通过列联表计算出来的差不多(阈值0.5)。
NLP任务中的基本指标(precision and recall )
https://en.wikipedia.org/wiki/Precision_and_recall

- 精确度 precision = (true positive)/(selected elements) = tp/(tp+fp) ,表示预测为正例的样本中,真正的正例所占的比例。
- 召回率 recall = (true positive)/(relevant elements) = tp/(tp+fn) ,表示被预测出的真正的正例,占真正的正例的比例。
注:实际任务中经常使用这两个基本指标的加权组合(即,F-measure,也称F-score),至于权值根据不同任务酌情使用。
经常使用的而是两者的调和平均数,即(其中p表示precision, r表示recall):
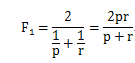
对于多分类(如N分类),可以看成是N分类,对N个类别的p,r,F1值的平均方法有两种:marco-(即宏平均),micro-(即微平均)。
macro-: 先分别计算出各类的指标,再取平均值。如macro_p= (p1+p2+...+pN)/N
micro-:先计算出所有类别的tp, fp等的平均值,再代入指标计算公式中求出结果。如micro_p= ave_tp/(ave_tp+ave_fp)
类似方法计算得 macro-r, micro-r
最后:
macro_f1 = 2*macro_p*macro_r / (macro_p+macro_r)
micro_f1 = 2*micro_p*micro_r / (micro_p+micro_r)
补充机器学习分类任务中其他指标:
- 准确率(accuracy)
其定义是: 对于给定的测试数据集,正确分类的样本数与总样本数之比。
accuracy = (true positive + true negative) / (tp + tn + fp + fn)
- 混淆矩阵(Confusion Matrix)
在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是错误矩阵。
例如:
- 对数损失(Log-Loss)
- 曲线下面积(AUC)
NLP基础知识: F1-score, 混淆矩阵和语料库
先了解如何看懂一个模型评估的指标,譬如 F1-score, Confusion matrix.
机器学习中的 F1-score
在理解 F1-store 之前,首先定义几个概念:
TP(True Positive): 预测答案正确
FP(False Positive): 错将其他类预测为本类
FN(False Negative): 本类标签预测为其他类标
F1分数(F1-score)是分类问题的一个衡量指标, 在 0~1 之间,公式如下:
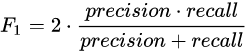
通过第一步的统计值计算每个类别下的 precision 和 recall
精准度/查准率(precision):指被分类器判定正例中的正样本的比重
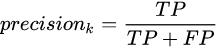
召回率/查全率(recall): 指的是被预测为正例的占总的正例的比重
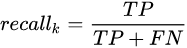
每个类别下的f1-score,计算方式如下:
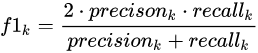
通过对第三步求得的各个类别下的F1-score求均值,得到最后的评测结果,计算方式如下:
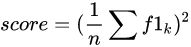
Confusion Matrix 混淆矩阵
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目。
如有150个样本数据,预测为1,2,3类各为50个。分类结束后得到的混淆矩阵为:
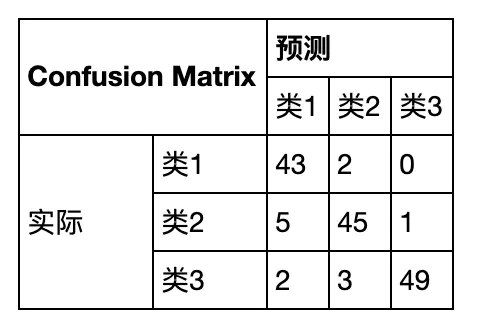
每一行之和表示该类别的真实样本数量,每一列之和表示被预测为该类别的样本数量.
Corpus 语料库
巧妇难为无米之炊,语料库就是 NLP 项目中的 "米"。这里使用的是 awesome-chinese-nlp 中列出的中文wikipedia dump和百度百科语料。其中关于wikipedia dump的处理可以参考这篇帖子。
我们需要一个规模比较大的中文语料。最好的方法是用对应自己需求的语料,比如做金融的chatbot就多去爬取些财经新闻,做医疗的chatbot就多获取些医疗相关文章。
知识图谱
1、什么是知识图谱?
知识图谱(Knowledge Graph)旨在描述真实世界中存在的各种实体或概念及其关系,其构成一张巨大的语义网络图,节点表示实体或概念,边则由属性或关系构成。
2012年5月,Google推出Google知识图谱(Google Knowledge Graph),并利用其在搜索引擎中增强搜索结果。这是“知识图谱”名称的由来,也标志着大规模知识图谱在互联网语义搜索中的成功应用。
可以说,知识图谱的升温,是AI对数据处理和理解需求逐日增加所导致的必然结果,而其发展有赖于专家系统、语言学、语义网、数据库,以及信息抽取等众多领域,是一个交叉融合的产物。
2、知识图谱的定义
知识图谱主要目标是用来描述真实世界中存在的各种实体和概念,以及他们之间的强关系,我们用关系去描述两个实体之间的关联,例如姚明和火箭队之间的关系,他们的属性,我们就用“属性--值对“来刻画它的内在特性,比如说我们的人物,他有年龄、身高、体重属性。
知识图谱可以通过人为构建与定义,去描述各种概念之间的弱关系,例如:“忘了订单号”和“找回订单号”之间的关系。
3、知识图谱的应用
通过知识图谱,不仅可以将互联网的信息表达成更接近人类认知世界的形式,而且提供了一种更好的组织、管理和利用海量信息的方式。下图是笔者整理的知识图谱有关的应用,接下来的一些文章笔者会对下面的应用进行剖析。
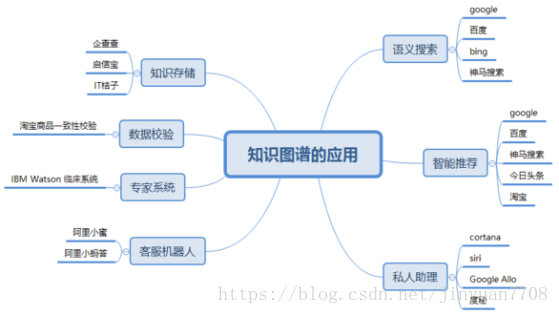
从图4上看,知识图谱的应用主要集中在搜索与推荐领域,robot(客服机器人,私人助理)是问答系统,本质上也是搜索与推荐的延伸。可能是因为知识图谱这项技术(特指freebase)诞生之初就是为了解决搜索问题的。知识存储这一块可能是企查查和启信宝这些企业发现使用图结构的数据比较好清洗加工。
在语义搜索这一块,知识图谱的搜索不同于常规的搜索,常规的搜索是根据keyword找到对应的网页集合,然后通过page rank等算法去给网页集合内的网页进行排名,然后展示给用户;基于知识图谱的搜索是在已有的图谱知识库中遍历知识,然后将查询到的知识返回给用户,通常如果路径正确,查询出来的知识只有1个或几个,相当精准。
问答系统这一块,系统同样会首先在知识图谱的帮助下对用户使用自然语言提出的问题进行语义分析和语法分析,进而将其转化成结构化形式的查询语句,然后在知识图谱中查询答案。
什么是fine-tuning?
在实践中,由于数据集不够大,很少有人从头开始训练网络。常见的做法是使用预训练的网络(例如在ImageNet上训练的分类1000类的网络)来重新fine-tuning(也叫微调),或者当做特征提取器。
以下是常见的两类迁移学习场景:
1 卷积网络当做特征提取器。使用在ImageNet上预训练的网络,去掉最后的全连接层,剩余部分当做特征提取器(例如AlexNet在最后分类器前,是4096维的特征向量)。这样提取的特征叫做CNN codes。得到这样的特征后,可以使用线性分类器(Liner SVM、Softmax等)来分类图像。
2 Fine-tuning卷积网络。替换掉网络的输入层(数据),使用新的数据继续训练。Fine-tune时可以选择fine-tune全部层或部分层。通常,前面的层提取的是图像的通用特征(generic features)(例如边缘检测,色彩检测),这些特征对许多任务都有用。后面的层提取的是与特定类别有关的特征,因此fine-tune时常常只需要Fine-tuning后面的层。
预训练模型
在ImageNet上训练一个网络,即使使用多GPU也要花费很长时间。因此人们通常共享他们预训练好的网络,这样有利于其他人再去使用。例如,Caffe有预训练好的网络地址Model Zoo。
何时以及如何Fine-tune
决定如何使用迁移学习的因素有很多,这是最重要的只有两个:新数据集的大小、以及新数据和原数据集的相似程度。有一点一定记住:网络前几层学到的是通用特征,后面几层学到的是与类别相关的特征。这里有使用的四个场景:
1、新数据集比较小且和原数据集相似。因为新数据集比较小,如果fine-tune可能会过拟合;又因为新旧数据集类似,我们期望他们高层特征类似,可以使用预训练网络当做特征提取器,用提取的特征训练线性分类器。
2、新数据集大且和原数据集相似。因为新数据集足够大,可以fine-tune整个网络。
3、新数据集小且和原数据集不相似。新数据集小,最好不要fine-tune,和原数据集不类似,最好也不使用高层特征。这时可是使用前面层的特征来训练SVM分类器。
4、新数据集大且和原数据集不相似。因为新数据集足够大,可以重新训练。但是实践中fine-tune预训练模型还是有益的。新数据集足够大,可以fine-tine整个网络。
实践建议
预训练模型的限制。使用预训练模型,受限于其网络架构。例如,你不能随意从预训练模型取出卷积层。但是因为参数共享,可以输入任意大小图像;卷积层和池化层对输入数据大小没有要求(只要步长stride fit),其输出大小和属于大小相关;全连接层对输入大小没有要求,输出大小固定。
学习率。与重新训练相比,fine-tune要使用更小的学习率。因为训练好的网络模型权重已经平滑,我们不希望太快扭曲(distort)它们(尤其是当随机初始化线性分类器来分类预训练模型提取的特征时)。
Windows下安装TensorFlow GPU版本教程
一、确认显卡是否支持CUDA
1.1、查看支持CUDA的显卡
网址:http://developer.nvidia.com/cuda-gpus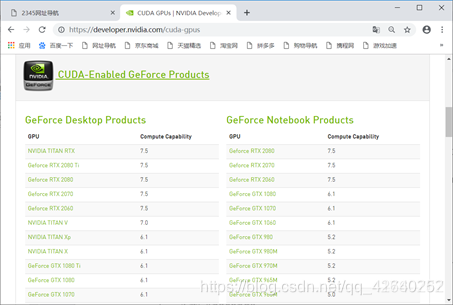
1.2、查看系统信息
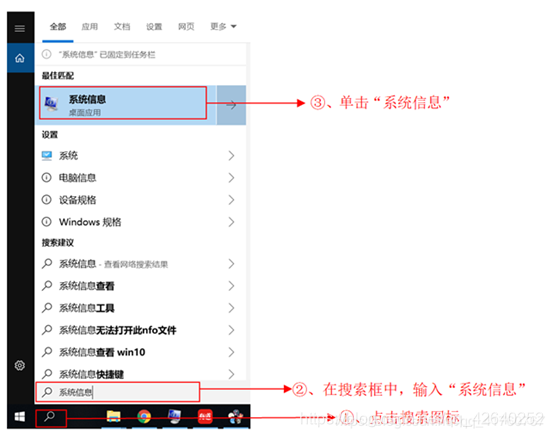
1.3、查看显卡信息
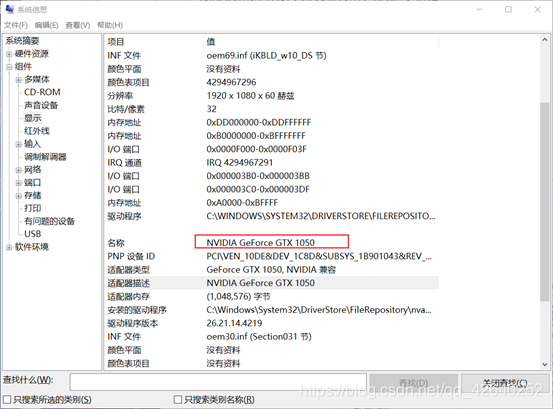
由上图知,本电脑的显卡为GeForce GTX 1050,支持CUDA软件,如下图所示:
https://developer.nvidia.com/cuda-gpus#compute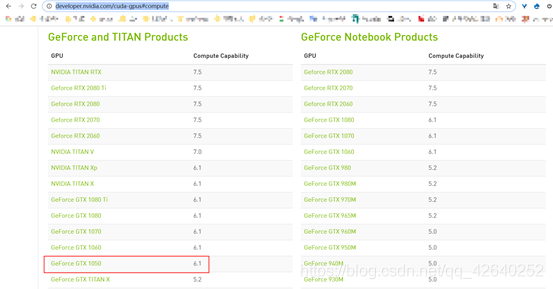
二、安装CUDA
2.1、确定 Tensorflow-GPU CUDA CUDNN的版本
确定要下载的Tensorflow-GPU的版本并查看对应的CUDA CUDNN的版本
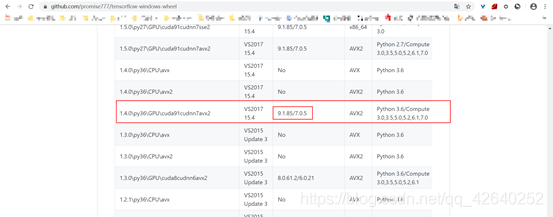
网址:https://github.com/promise777/tensorflow-windows-wheel
我这边下载的是1.4.0\py36\GPU\cuda91 cudnn7 avx2
对应的CUDA 9.1.85 CUDNN是7.0.5
2.2、下载并安装CUDA
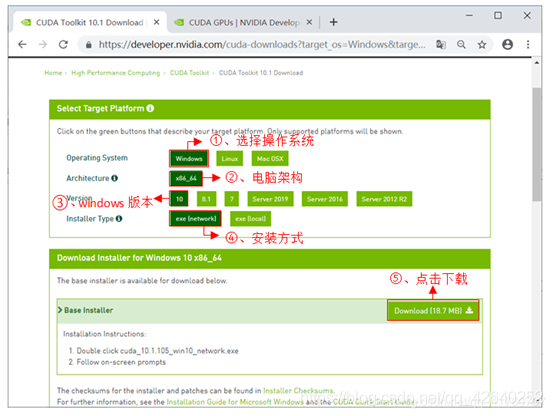
网址:https://developer.nvidia.com/cuda-downloads
安装步骤如下图所示: 用迅雷下载挺快的
安装路径,选择OK(安装完成后路径会自动变化,所以这里路径选择默认就好)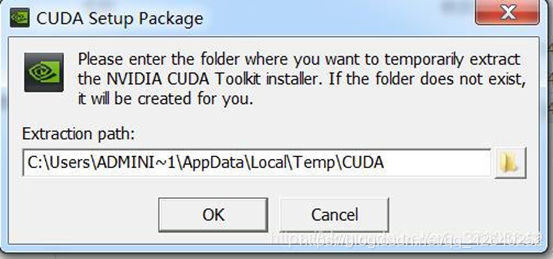
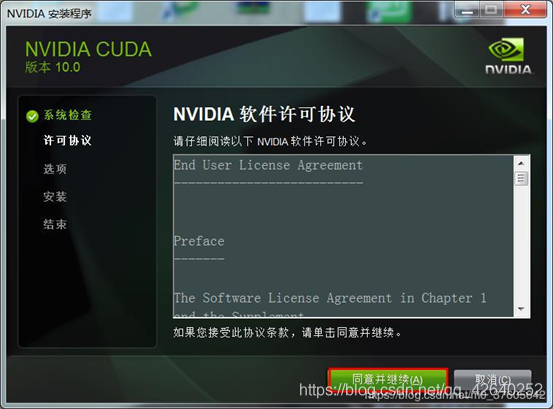
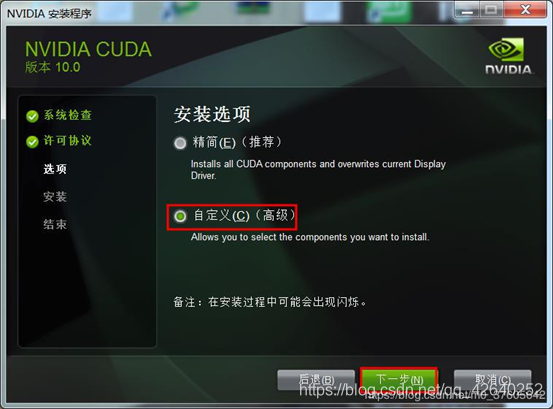
2.3、自定义安装
取消勾选GeForce Experience
如果电脑上本身就有Visual Studio Integration,要将这个取消勾选,避免冲突了
点开Driver comonents,Display Driver这一行,前面显示的是Cuda本身包含的驱动版本是411.31
如果你电脑目前安装的驱动版本号新于Cuda本身自带的驱动版本号,那一定要把这个勾去掉。否则会安装失败(相同的话,就不用去取勾了)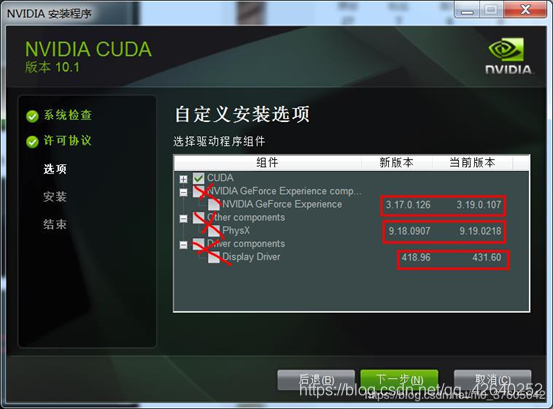
只选CUDA不然会失败
CUDA的安装位置可以自定义,系统默认是在系统盘C盘,为了方便日后管理,可以安装到非系统盘的其他盘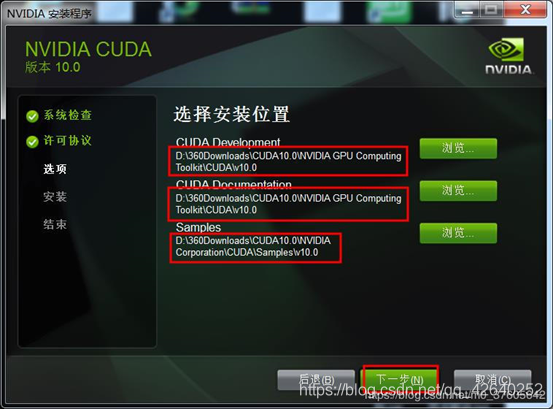

2.4、检查安装状态
打开路径 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin ,查看nvcc.exe
有这个nvcc.exe就说明CUDA安装已成功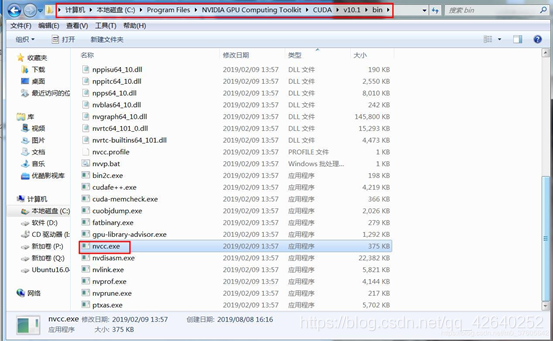
打开路径 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\CUPTI\lib64,查看有没有cuti64_101.dll
有这个cuti64_101.dll就说明CUPT1已成功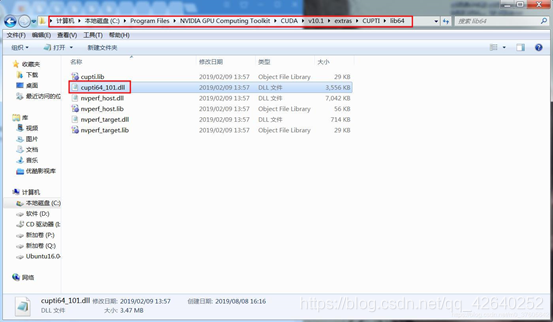
三、安装cuDNN
3.1、下载cuDNN
网址:https://developer.nvidia.com/cudnn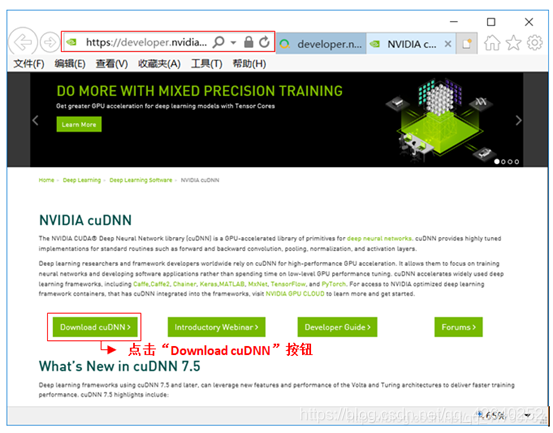
3.2、加入会员
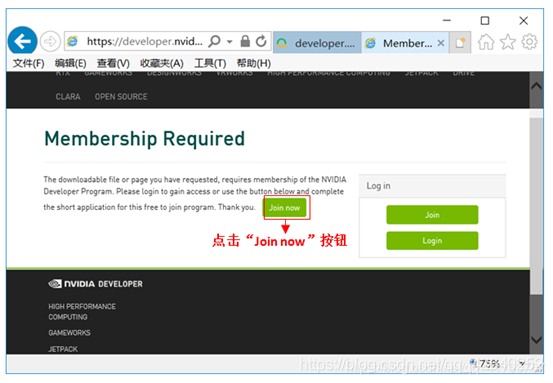
进入注册步骤:
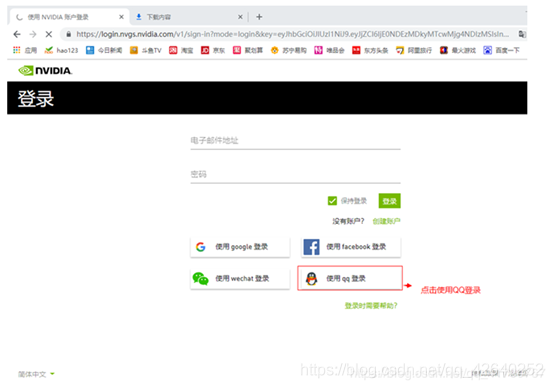
3.3、进入下载页面
网址:https://developer.nvidia.com/rdp/cudnn-download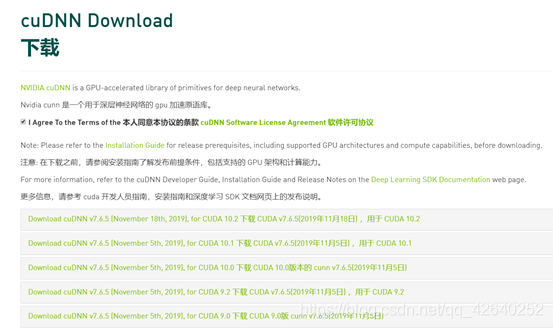
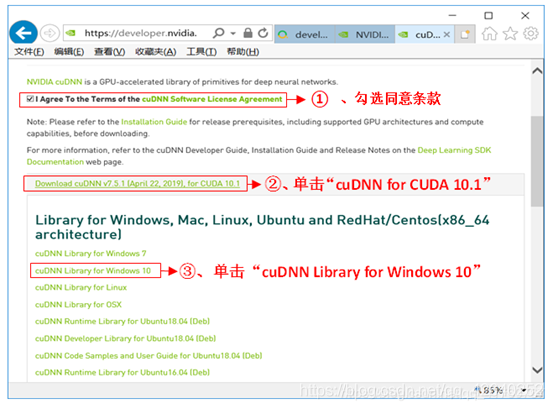
3.4、查看下载后的文件
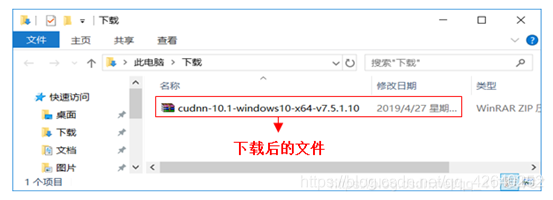
3.5、配置CUDNN
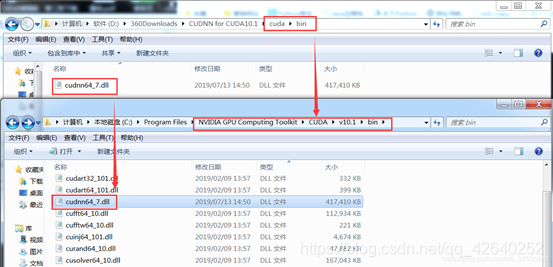
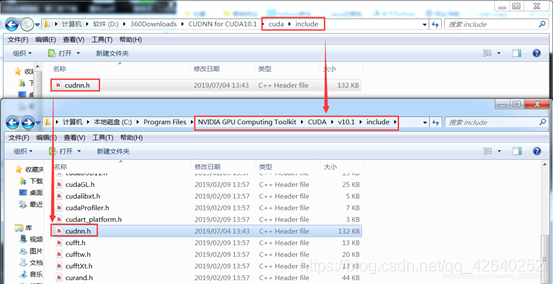
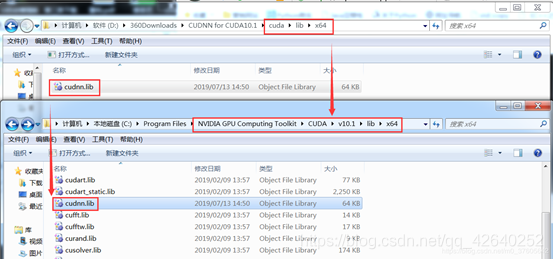
解压CUDNN后,将对应的bin、lib、include与CUDA9.1对应的bin、lib、include进行合并。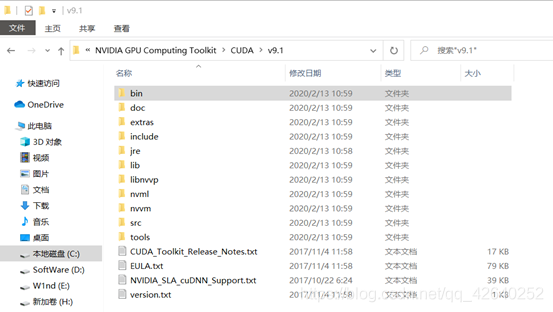
3.6、编辑系统环境变量
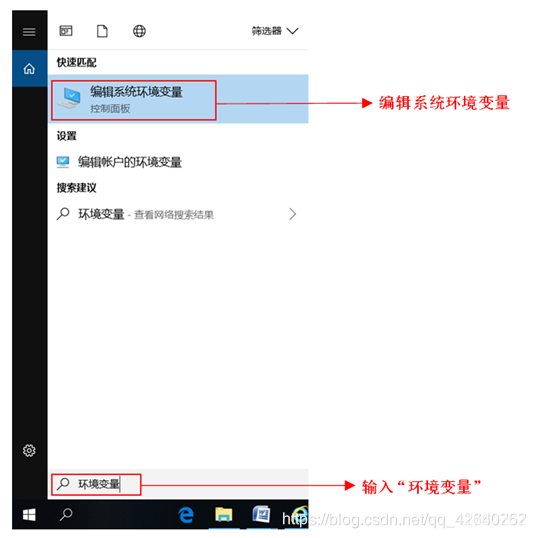
单击“环境变量”按钮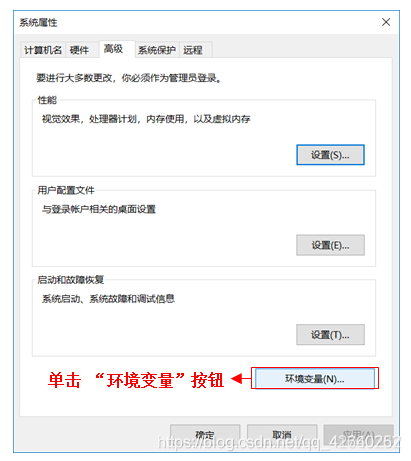
编辑环境变量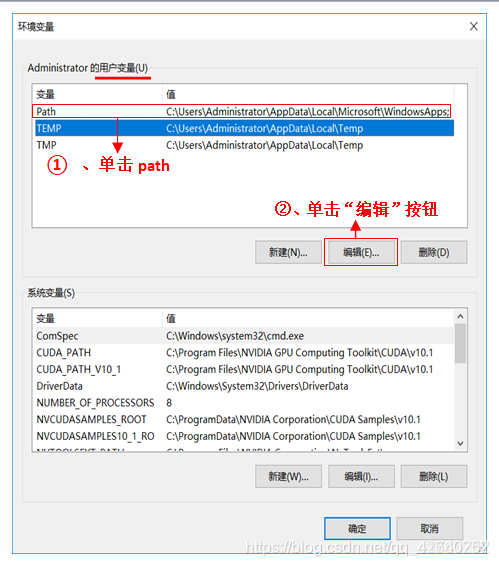
编辑用户变量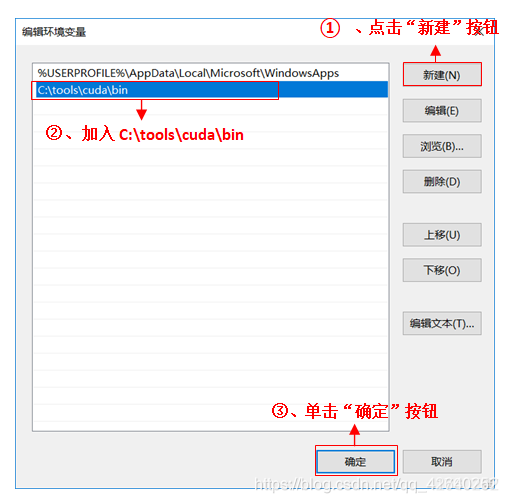
把以下路径都添加到PATH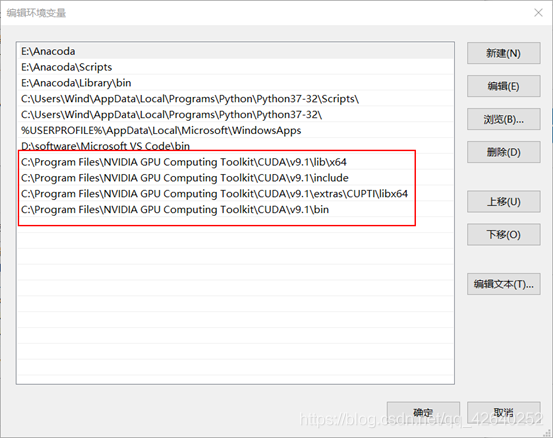
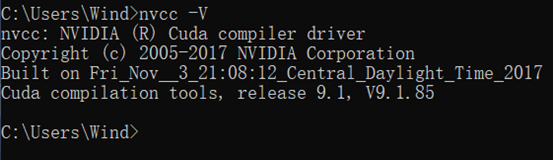
四、测试CUDA
五、Andconda测试
然后在Anaconda创建新的环境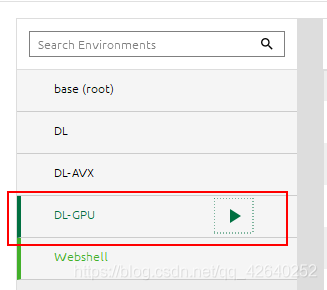
安装在github下载的tensorflow-gpu
pip install tensorflow
然后重新安装numpy
pip uninstall numpy
pip install numpy == 1.16.1
import tensorflow
没报错 安装成功
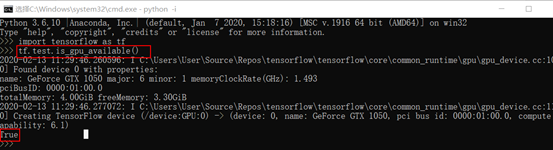
tf.test.is_gpu_available()
查看是否安装成功
六、卸载CUDA
卸载开始:
- 对于含cuda字眼的,和结尾版本号是9.0的可以卸载。
- 如果不确定那个程序能不能删除,可以搜索试试看,程序什么用途的。
- NVIDIA的软件一个个都有其独立卸载程序,不用担心卸载顺序。
具体的:
- 留下:NVIDIA的图形驱动程序、NVIDIA Physx系统软件,如果你有这2个软件,就别卸载。
卸载:
- 推荐排序。 点击顶部时间小三角排序,可发现一个叫NVIDIA Nsight HUD Launcher
的带眼睛图标的排列在上面,挺大的。然后从下往上卸载,跳过保留的NVIDIA图形驱动、NVIDIA Physx系统软件。 - 软件名含cuda的,9.0的,sdk,NVIDIA Nsight HUD、NVIDIA GeForce
Experience、等,这些都可以卸载掉。 - 卸载完后,你会发现电脑—开始—所有程序,里面那个关于NVIDIA的程序文件不见了。存在的话,也可以看看里面还剩下什么,可以搜索看看。当然,C盘里面
C:\Program Files\NVIDIA GPU Computing Toolkit文件也可以删除了。 - 用杀毒软件垃圾扫描下,清理下电脑,主要是清理注册表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号