
Kafka如何通过层级时间轮实现延时消息队列?
前言
Kafka 中有很多延时操作,比如对于耗时的网络请求(比如 Produce 时等待 ISR 副本复制成功)会被封装成 DelayOperation 进行延迟处理操作,防止阻塞 Kafka请求处理线程。
Kafka 没有使用 JDK 自带的 Timer 和 DelayQueue 实现。因为时间复杂度上这两者插入和删除操作都是 O(logn),不能满足 Kafka 的高性能要求。
冷知识:JDK Timer 和 DelayQueue 底层都是个优先队列,即采用了 minHeap 的数据结构,最快需要执行的任务排在队列第一个,不一样的是 Timer 中有个线程去拉取任务执行,DelayQueue 其实就是个容器,需要配合其他线程工作。ScheduledThreadPoolExecutor 是 JDK 的定时任务实现的一种方式,其实也就是 DelayQueue + 池化线程的一个实现。
Kafka 基于时间轮实现了延时操作,时间轮算法的插入删除操作都是 O(1) 的时间复杂度,满足了 Kafka 对于性能的要求。除了 Kafka 以外,像 Netty 、ZooKeepr、Dubbo 这样的开源项目都有使用到时间轮的实现。
那么时间轮算法是怎么样的,算法思想是什么?Kafka 中又是怎么实现它的。
Kafka 时间轮算法
时间轮的算法思想可以通过我们日常生活中的钟表来理解。
Kafka 中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务(TimerTask)。
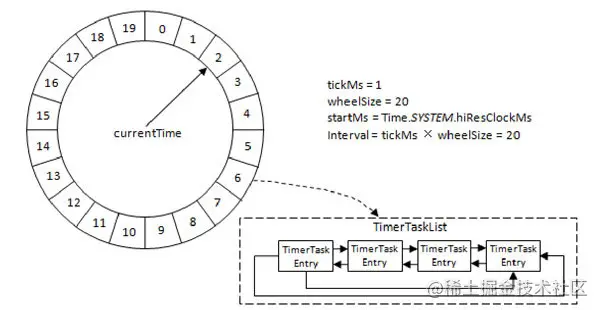
图中的几个参数:
- tickMs: 时间跨度
- wheelSize: 时间轮中 bucket 的个数
- startMs: 开始时间
- interval:时间轮的整体时间跨度 = tickMs * wheelSize
- currentTime: tickMs 的整数倍,代表时间轮当前所处的时间
- currentTime可以将整个时间轮划分为到期部分和未到期部分,currentTime当前指向的时间格也属于到期部分,表示刚好到期,需要处理此时间格所对应的TimerTaskList中的所有任务
整个时间轮的总体跨度是不变的,随着指针currentTime的不断推进,当前时间轮所能处理的时间段也在不断后移,总体时间范围在currentTime和currentTime+interval之间。
现在你可能会有疑问,这个抽象的 currentTime 怎么推进呢,别急看下文
那么如何支持大跨度的定时任务呢?
如果要支持几十万毫秒的定时任务,难不成要扩容时间轮的那个数组?实际上这里有两种解决方案:
- 使用增加轮次/圈数的概念(Netty 的 HashedWheelTimer )
- 举例来说,比如目前是 "0-7" 8个槽,41 % 8 + 1 = 2,即应该放在槽位是 2,下标是 1 的位置。然后 ( 41 - 1 ) / 8 = 5,即轮数记为 5。也就是说当循环 5 轮之后扫到下标的 1 的这个槽位会触发这个任务。
- 具体实现细节这里不详述
- 使用多层时间轮的概念 (Kafka 的 TimingWheel)
- 相较于上个方案,层级时间轮能更好控制时间粒度,可以应对更加复杂的定时任务处理场景,适用的范围更广;
多层时间轮就更像我们钟表的概念了。秒针走的一圈、分针走的一圈和时针走的一圈就形成了一个多层时间轮的关系。
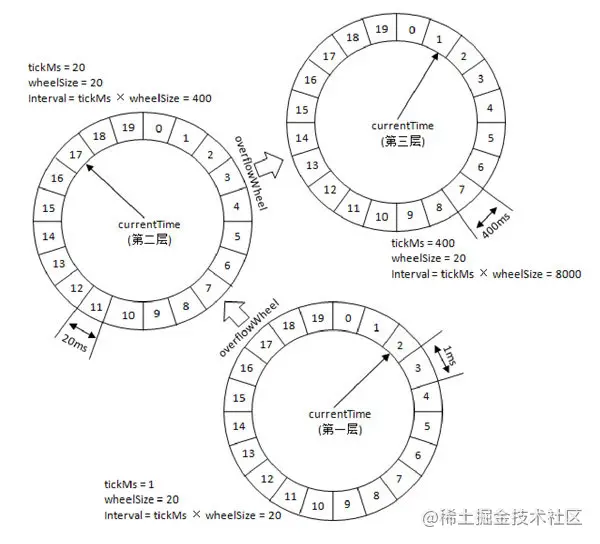
第N层时间轮走了一圈,等于 N+1 层时间轮走一格。即高一层时间轮的时间跨度等于当前时间轮的整体跨度。
在任务插入时,如果第一层时间轮不满足条件,就尝试插入到高一层的时间轮,以此类推。
随着时间推进,也会有一个时间轮降级的操作,原本延时较长的任务会从高一层时间轮重新提交到时间轮中,然后会被放在合适的低层次的时间轮当中等待处理;
在 Kafka 中时间轮之间如何关联呢,如何展现这种高一层的时间轮关系?
其实很简单就是一个内部对象的指针,指向自己高一层的时间轮对象。
另外还有一个问题,如何推进时间轮的前进,让时间轮的时间往前走。
- Netty 中的时间轮是通过工作线程按照固定的时间间隔 tickDuration 推进的
- 如果长时间没有到期任务,这种方案会带来空推进的问题,从而造成一定的性能损耗;
- Kafka 则是通过 DelayQueue 来推进,是一种空间换时间的思想;
- DelayQueue 中保存着所有的 TimerTaskList 对象,根据时间来排序,这样延时越小的任务排在越前面。
- 外部通过一个线程(叫做ExpiredOperationReaper)从 DelayQueue 中获取超时的任务列表 TimerTaskList,然后根据 TimerTaskList 的 过期时间来精确推进时间轮的时间,这样就不会存在空推进的问题啦。
其实 Kafka 采用的是一种权衡的策略,把 DelayQueue 用在了合适的地方。DelayQueue 只存放了 TimerTaskList,并不是所有的 TimerTask,数量并不多,相比空推进带来的影响是利大于弊的。
总结
- Kafka 使用时间轮来实现延时队列,因为其底层是任务的添加和删除是基于链表实现的,是 O(1) 的时间复杂度,满足高性能的要求;
- 对于时间跨度大的延时任务,Kafka 引入了层级时间轮,能更好控制时间粒度,可以应对更加复杂的定时任务处理场景;
- 对于如何实现时间轮的推进和避免空推进影响性能,Kafka 采用空间换时间的思想,通过 DelayQueue 来推进时间轮,算是一个经典的 trade off。
本文通过 Kafka 来讲述了时间轮的算法设计思想,其中还提到了 Netty 时间轮算法的实现,可能会比较偏向理论,推荐去阅读一下 Kafka 和 Netty 时间轮实现的源码,并不是特别难,对比起来看会更有收获。
作者:Richard_Yi
链接:从 Kafka 看时间轮算法设计 - 掘金 (juejin.cn)
Kafka时间轮(TimingWheel)和Kafka中的延时操作_kafka时间轮延迟队列-CSDN博客
Kafka中存在大量的延迟操作,比如延迟生产、延迟拉取以及延迟删除等。Kafka并没有使用JDK自带的Timer或者DelayQueue来实现延迟的功能,而是基于时间轮自定义了一个用于实现延迟功能的定时器(SystemTimer)。JDK的Timer和DelayQueue插入和删除操作的平均时间复杂度为O(nlog(n)),并不能满足Kafka的高性能要求,而基于时间轮可以将插入和删除操作的时间复杂度都降为O(1)。时间轮的应用并非Kafka独有,其应用场景还有很多,在Netty、Akka、Quartz、Zookeeper等组件中都存在时间轮的踪影。
参考下图,Kafka中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务TimerTask。
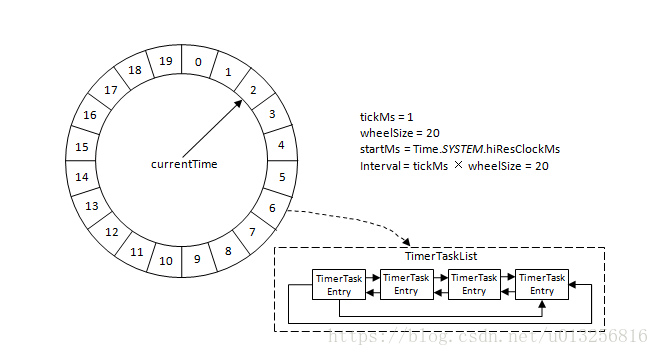
时间轮由多个时间格组成,每个时间格代表当前时间轮的基本时间跨度(tickMs)。时间轮的时间格个数是固定的,可用wheelSize来表示,那么整个时间轮的总体时间跨度(interval)可以通过公式 tickMs × wheelSize计算得出。时间轮还有一个表盘指针(currentTime),用来表示时间轮当前所处的时间,currentTime是tickMs的整数倍。currentTime可以将整个时间轮划分为到期部分和未到期部分,currentTime当前指向的时间格也属于到期部分,表示刚好到期,需要处理此时间格所对应的TimerTaskList的所有任务。
若时间轮的tickMs=1ms,wheelSize=20,那么可以计算得出interval为20ms。初始情况下表盘指针currentTime指向时间格0,此时有一个定时为2ms的任务插入进来会存放到时间格为2的TimerTaskList中。随着时间的不断推移,指针currentTime不断向前推进,过了2ms之后,当到达时间格2时,就需要将时间格2所对应的TimeTaskList中的任务做相应的到期操作。此时若又有一个定时为8ms的任务插入进来,则会存放到时间格10中,currentTime再过8ms后会指向时间格10。如果同时有一个定时为19ms的任务插入进来怎么办?新来的TimerTaskEntry会复用原来的TimerTaskList,所以它会插入到原本已经到期的时间格1中。总之,整个时间轮的总体跨度是不变的,随着指针currentTime的不断推进,当前时间轮所能处理的时间段也在不断后移,总体时间范围在currentTime和currentTime+interval之间。
如果此时有个定时为350ms的任务该如何处理?直接扩充wheelSize的大小么?Kafka中不乏几万甚至几十万毫秒的定时任务,这个wheelSize的扩充没有底线,就算将所有的定时任务的到期时间都设定一个上限,比如100万毫秒,那么这个wheelSize为100万毫秒的时间轮不仅占用很大的内存空间,而且效率也会拉低。Kafka为此引入了层级时间轮的概念,当任务的到期时间超过了当前时间轮所表示的时间范围时,就会尝试添加到上层时间轮中。
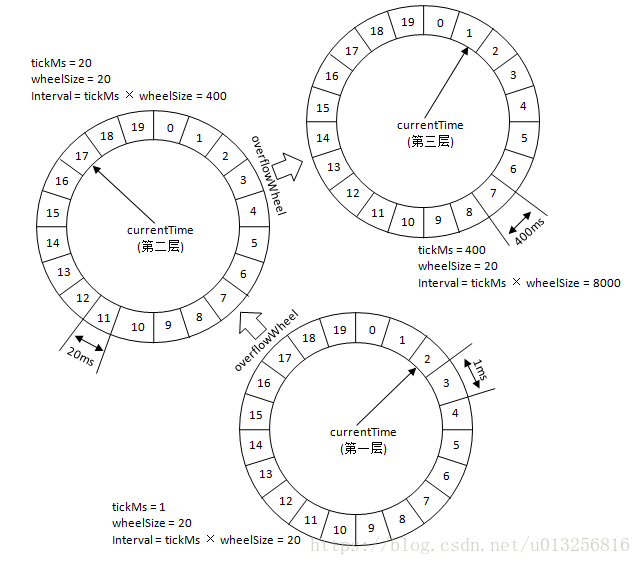
参考上图,复用之前的案例,第一层的时间轮tickMs=1ms, wheelSize=20, interval=20ms。第二层的时间轮的tickMs为第一层时间轮的interval,即为20ms。每一层时间轮的wheelSize是固定的,都是20,那么第二层的时间轮的总体时间跨度interval为400ms。以此类推,这个400ms也是第三层的tickMs的大小,第三层的时间轮的总体时间跨度为8000ms。
对于之前所说的350ms的定时任务,显然第一层时间轮不能满足条件,所以就升级到第二层时间轮中,最终被插入到第二层时间轮中时间格17所对应的TimerTaskList中。如果此时又有一个定时为450ms的任务,那么显然第二层时间轮也无法满足条件,所以又升级到第三层时间轮中,最终被插入到第三层时间轮中时间格1的TimerTaskList中。注意到在到期时间在[400ms,800ms)区间的多个任务(比如446ms、455ms以及473ms的定时任务)都会被放入到第三层时间轮的时间格1中,时间格1对应的TimerTaskList的超时时间为400ms。随着时间的流逝,当次TimerTaskList到期之时,原本定时为450ms的任务还剩下50ms的时间,还不能执行这个任务的到期操作。这里就有一个时间轮降级的操作,会将这个剩余时间为50ms的定时任务重新提交到层级时间轮中,此时第一层时间轮的总体时间跨度不够,而第二层足够,所以该任务被放到第二层时间轮到期时间为[40ms,60ms)的时间格中。再经历了40ms之后,此时这个任务又被“察觉”到,不过还剩余10ms,还是不能立即执行到期操作。所以还要再有一次时间轮的降级,此任务被添加到第一层时间轮到期时间为[10ms,11ms)的时间格中,之后再经历10ms后,此任务真正到期,最终执行相应的到期操作。
设计源于生活。我们常见的钟表就是一种具有三层结构的时间轮,第一层时间轮tickMs=1s, wheelSize=60,interval=1min,此为秒钟;第二层tickMs=1min,wheelSize=60,interval=1hour,此为分钟;第三层tickMs=1hour,wheelSize为12,interval为12hours,此为时钟。
在Kafka中第一层时间轮的参数同上面的案例一样:tickMs=1ms, wheelSize=20, interval=20ms,各个层级的wheelSize也固定为20,所以各个层级的tickMs和interval也可以相应的推算出来。Kafka在具体实现时间轮TimingWheel时还有一些小细节:
TimingWheel在创建的时候以当前系统时间为第一层时间轮的起始时间(startMs),这里的当前系统时间并没有简单的调用System.currentTimeMillis(),而是调用了Time.SYSTEM.hiResClockMs,这是因为currentTimeMillis()方法的时间精度依赖于操作系统的具体实现,有些操作系统下并不能达到毫秒级的精度,而Time.SYSTEM.hiResClockMs实质上是采用了System.nanoTime()/1_000_000来将精度调整到毫秒级。也有其他的某些骚操作可以实现毫秒级的精度,但是笔者并不推荐,System.nanoTime()/1_000_000是最有效的方法。(如对此有想法,可在留言区探讨。)
TimingWheel中的每个双向环形链表TimerTaskList都会有一个哨兵节点(sentinel),引入哨兵节点可以简化边界条件。哨兵节点也称为哑元节点(dummy node),它是一个附加的链表节点,该节点作为第一个节点,它的值域中并不存储任何东西,只是为了操作的方便而引入的。如果一个链表有哨兵节点的话,那么线性表的第一个元素应该是链表的第二个节点。
除了第一层时间轮,其余高层时间轮的起始时间(startMs)都设置为创建此层时间轮时前面第一轮的currentTime。每一层的currentTime都必须是tickMs的整数倍,如果不满足则会将currentTime修剪为tickMs的整数倍,以此与时间轮中的时间格的到期时间范围对应起来。修剪方法为:currentTime = startMs - (startMs % tickMs)。currentTime会随着时间推移而推荐,但是不会改变为tickMs的整数倍的既定事实。若某一时刻的时间为timeMs,那么此时时间轮的currentTime = timeMs - (timeMs % tickMs),时间每推进一次,每个层级的时间轮的currentTime都会依据此公式推进。
Kafka中的定时器只需持有TimingWheel的第一层时间轮的引用,并不会直接持有其他高层的时间轮,但是每一层时间轮都会有一个引用(overflowWheel)指向更高一层的应用,以此层级调用而可以实现定时器间接持有各个层级时间轮的引用。
关于时间轮的细节就描述到这里,各个组件中时间轮的实现大同小异。读者读到这里是否会好奇文中一直描述的一个情景——“随着时间的流逝”或者“随着时间的推移”,那么在Kafka中到底是怎么推进时间的呢?类似采用JDK中的scheduleAtFixedRate来每秒推进时间轮?显然这样并不合理,TimingWheel也失去了大部分意义。
Kafka中的定时器借助了JDK中的DelayQueue来协助推进时间轮。具体做法是对于每个使用到的TimerTaskList都会加入到DelayQueue中,“每个使用到的TimerTaskList”特指有非哨兵节点的定时任务项TimerTaskEntry的TimerTaskList。DelayQueue会根据TimerTaskList对应的超时时间expiration来排序,最短expiration的TimerTaskList会被排在DelayQueue的队头。Kafka中会有一个线程来获取DelayQueue中的到期的任务列表,有意思的是这个线程所对应的名称叫做“ExpiredOperationReaper”,可以直译为“过期操作收割机”,和“SkimpyOffsetMap”的取名有的一拼。当“收割机”线程获取到DelayQueue中的超时的任务列表TimerTaskList之后,既可以根据TimerTaskList的expiration来推进时间轮的时间,也可以就获取到的TimerTaskList执行相应的操作,对立面的TimerTaskEntry该执行过期操作的就执行过期操作,该降级时间轮的就降级时间轮。
读者读到这里或许又非常的困惑,文章开头明确指明的DelayQueue不适合Kafka这种高性能要求的定时任务,为何这里还要引入DelayQueue呢?注意对于定时任务项TimerTaskEntry插入和删除操作而言,TimingWheel时间复杂度为O(1),性能高出DelayQueue很多,如果直接将TimerTaskEntry插入DelayQueue中,那么性能显然难以支撑。就算我们根据一定的规则将若干TimerTaskEntry划分到TimerTaskList这个组中,然后再将TimerTaskList插入到DelayQueue中,试想下如果这个TimerTaskList中又要多添加一个TimerTaskEntry该如何处理?对于DelayQueue而言,这类操作显然变得力不从心。
分析到这里可以发现,Kafka中的TimingWheel专门用来执行插入和删除TimerTaskEntry的操作,而DelayQueue专门负责时间推进的任务。再试想一下,DelayQueue中的第一个超时任务列表的expiration为200ms,第二个超时任务为840ms,这里获取DelayQueue的队头只需要O(1)的时间复杂度。如果采用每秒定时推进,那么获取到第一个超时的任务列表时执行的200次推进中有199次属于“空推进”,而获取到第二个超时任务时有需要执行639次“空推进”,这样会无故空耗机器的性能资源,这里采用DelayQueue来辅助以少量空间换时间,从而做到了“精准推进”。Kafka中的定时器真可谓是“知人善用”,用TimingWheel做最擅长的任务添加和删除操作,而用DelayQueue做最擅长的时间推进工作,相辅相成。
面试题大致上是这样的:消费者去Kafka里拉去消息,但是目前Kafka中又没有新的消息可以提供,那么Kafka会如何处理?
如下图所示,两个follower副本都已经拉取到了leader副本的最新位置,此时又向leader副本发送拉取请求,而leader副本并没有新的消息写入,那么此时leader副本该如何处理呢?可以直接返回空的拉取结果给follower副本,不过在leader副本一直没有新消息写入的情况下,follower副本会一直发送拉取请求,并且总收到空的拉取结果,这样徒耗资源,显然不太合理。
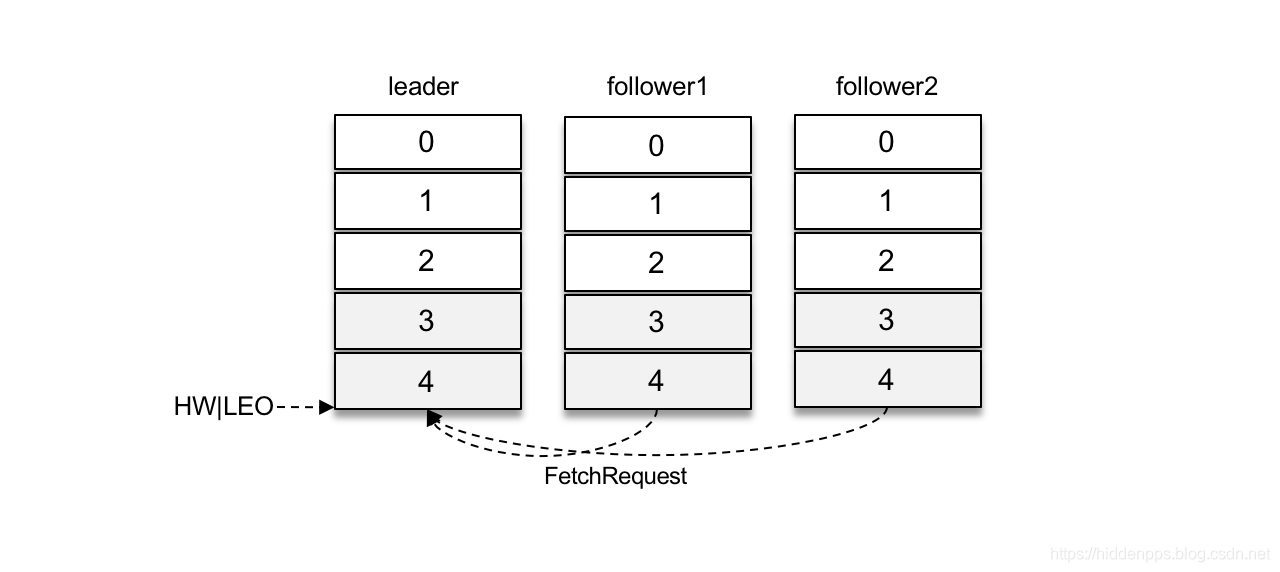
这里就涉及到了Kafka延迟操作的概念。Kafka在处理拉取请求时,会先读取一次日志文件,如果收集不到足够多(fetchMinBytes,由参数fetch.min.bytes配置,默认值为1)的消息,那么就会创建一个延时拉取操作(DelayedFetch)以等待拉取到足够数量的消息。当延时拉取操作执行时,会再读取一次日志文件,然后将拉取结果返回给follower副本。
延迟操作不只是拉取消息时的特有操作,在Kafka中有多种延时操作,比如延时数据删除、延时生产等。
对于延时生产(消息)而言,如果在使用生产者客户端发送消息的时候将acks参数设置为-1,那么就意味着需要等待ISR集合中的所有副本都确认收到消息之后才能正确地收到响应的结果,或者捕获超时异常。
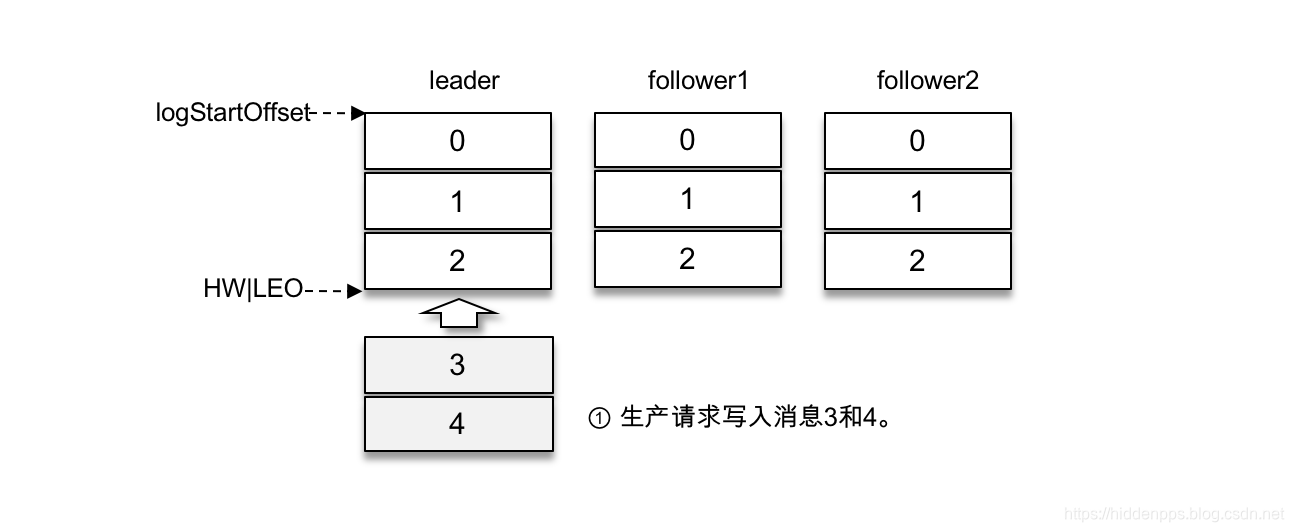
假设某个分区有3个副本:leader、follower1和follower2,它们都在分区的ISR集合中。为了简化说明,这里我们不考虑ISR集合伸缩的情况。Kafka在收到客户端的生产请求后,将消息3和消息4写入leader副本的本地日志文件,如上图所示。
由于客户端设置了acks为-1,那么需要等到follower1和follower2两个副本都收到消息3和消息4后才能告知客户端正确地接收了所发送的消息。如果在一定的时间内,follower1副本或follower2副本没能够完全拉取到消息3和消息4,那么就需要返回超时异常给客户端。生产请求的超时时间由参数request.timeout.ms配置,默认值为30000,即30s。
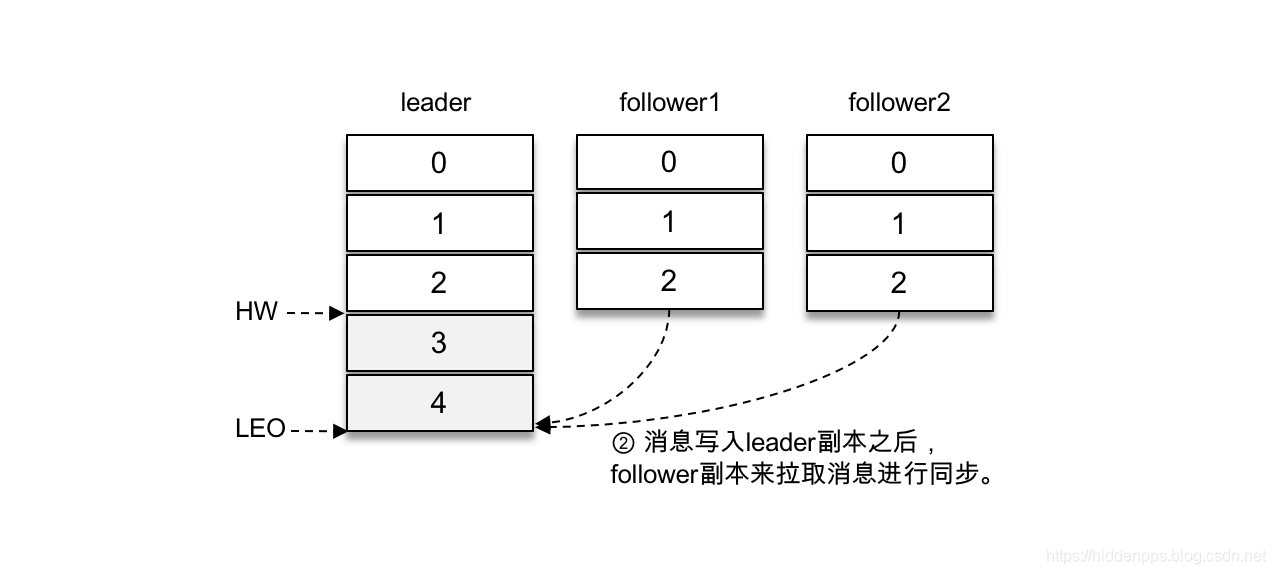
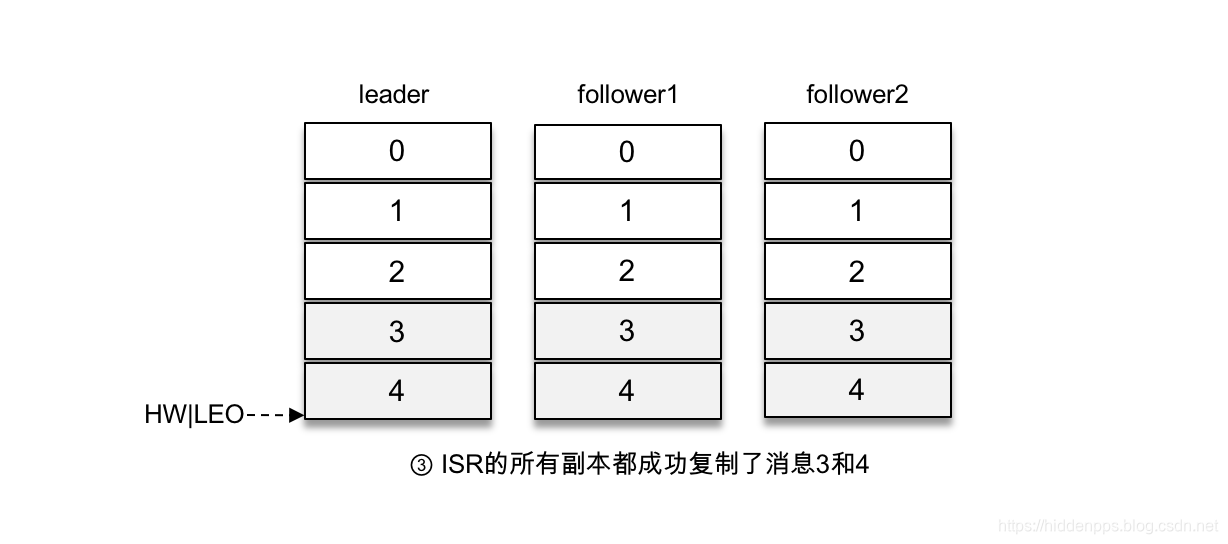
那么这里等待消息3和消息4写入follower1副本和follower2副本,并返回相应的响应结果给客户端的动作是由谁来执行的呢?在将消息写入leader副本的本地日志文件之后,Kafka会创建一个延时的生产操作(DelayedProduce),用来处理消息正常写入所有副本或超时的情况,以返回相应的响应结果给客户端。
延时操作需要延时返回响应的结果,首先它必须有一个超时时间(delayMs),如果在这个超时时间内没有完成既定的任务,那么就需要强制完成以返回响应结果给客户端。其次,延时操作不同于定时操作,定时操作是指在特定时间之后执行的操作,而延时操作可以在所设定的超时时间之前完成,所以延时操作能够支持外部事件的触发。
就延时生产操作而言,它的外部事件是所要写入消息的某个分区的HW(高水位)发生增长。也就是说,随着follower副本不断地与leader副本进行消息同步,进而促使HW进一步增长,HW每增长一次都会检测是否能够完成此次延时生产操作,如果可以就执行以此返回响应结果给客户端;如果在超时时间内始终无法完成,则强制执行。
回顾一下文中开头的延时拉取操作,它也同样如此,也是由超时触发或外部事件触发而被执行的。超时触发很好理解,就是等到超时时间之后触发第二次读取日志文件的操作。外部事件触发就稍复杂了一些,因为拉取请求不单单由follower副本发起,也可以由消费者客户端发起,两种情况所对应的外部事件也是不同的。如果是follower副本的延时拉取,它的外部事件就是消息追加到了leader副本的本地日志文件中;如果是消费者客户端的延时拉取,它的外部事件可以简单地理解为HW的增长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号