kafka系统架构( Broker,Topic, Partition,Replication)
Kafka系统架构( Broker,Topic, Partition,Replication)_kafka broker 和topic_温岚万叶的博客-CSDN博客
Kafka系统架构
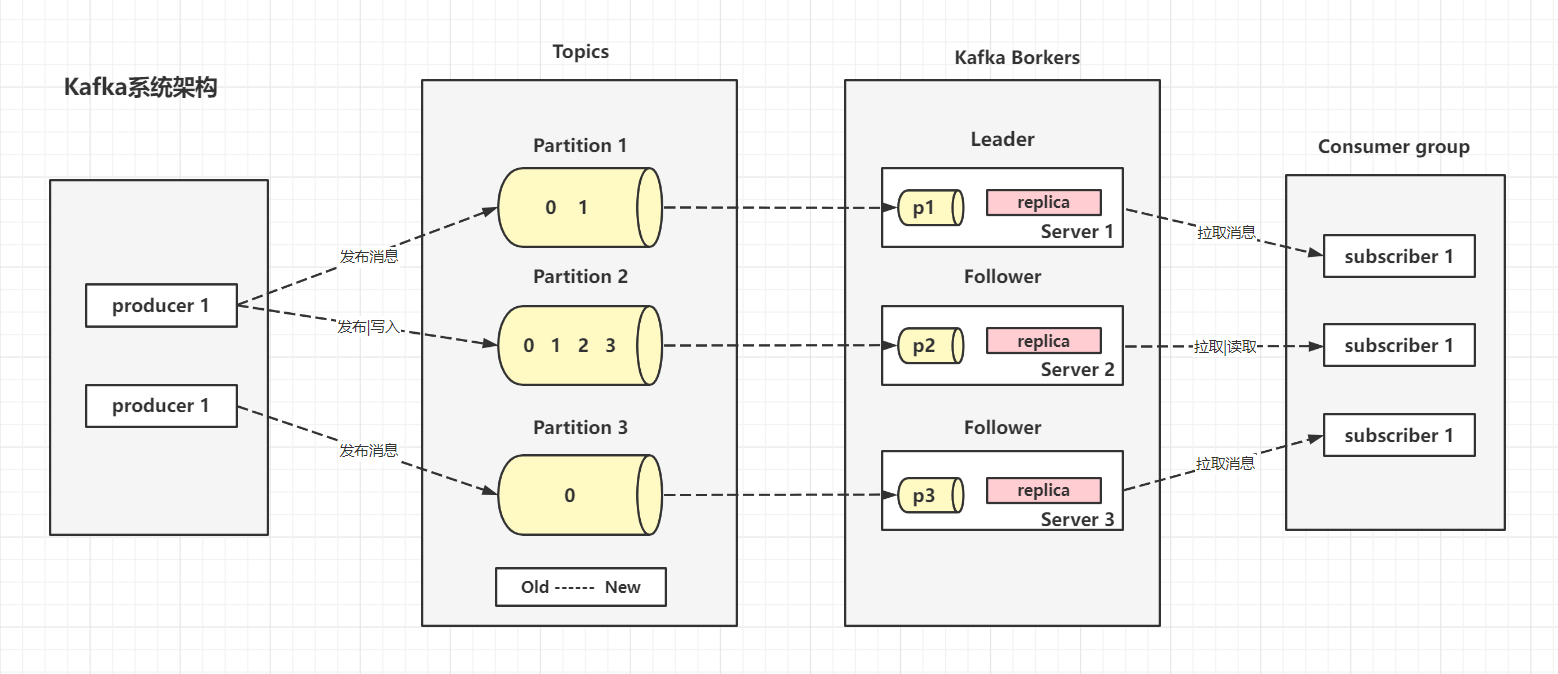
一、Broker 服务器节点
概念
Kafka 集群包含一个或多个服务器,服务器节点称为broker
描述
- 就是Kafka集群replication的名称
二、Topic 主题|消息类别
概念
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic
描述
- 1、在Kafka 中一张表就是一个主题
- 2、类:table index
- 3、将来会根据业务的不同创建不同的主题
- 4、创建流程:
首先创建主题,然后选择 Partition和Replication
说明
- 类似于数据库的 table 或者 ES 的 Index
注意
- 1、物理上不同Topic的消息
分开存储 - 2、逻辑上一个Topic的消息虽然保存于一个或多个broker上,但用户只需指定消息的Topic即可,生产或消费数据,而不必关心数据存于何处。
创建流程
- 1、controller在ZooKeeper的/brokers/topics节点上注册watcher,当topic被创建
- 则 controller会通过watch得到该topic的partition/replica分配
- 2、controller从/brokers/ids读取当前所有可用的broker列表,对于set_p中的每一个 partition
- 1 、从分配给该partition的所有replica(称为AR)中任选一个可用的broker作为新的 leader,并将AR设置为新的ISR
- 2、 将新的leader和ISR写入/brokers/topics/[topic]/partitions/[partition]/state
- 3、controller通过RPC向相关的broker发送LeaderAndISRRequest。
删除流程
- 1、controller在zooKeeper的/brokers/topics节点上注册watcher,当topic被删除
- 则 controller会通过watch得到该topic的partition/replica分配
- 2、若delete.topic.enable=false,结束;否则controller注册在/admin/delete_topics上 的watch被fire
- controller通过回调向对应的broker发送StopReplicaRequest。
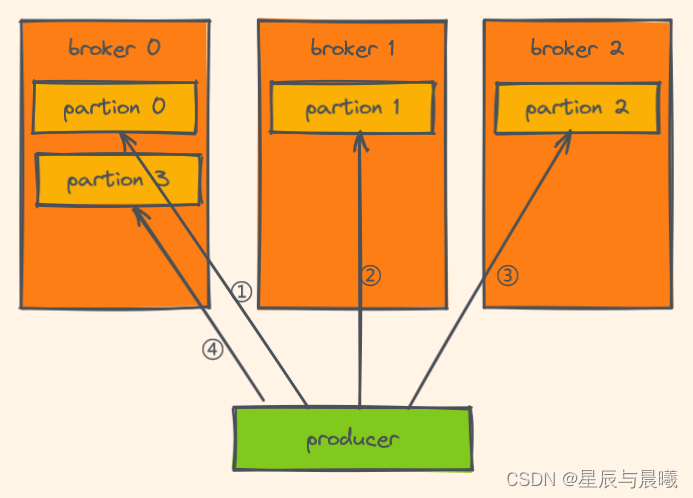
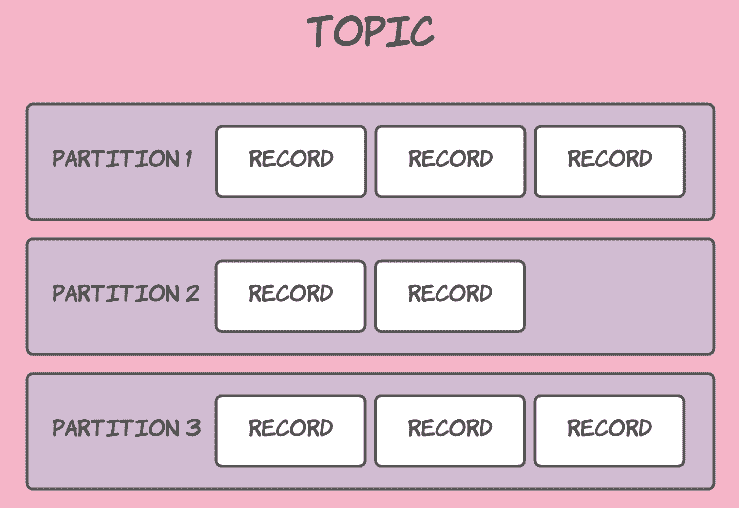
三、Partition 分区
概念
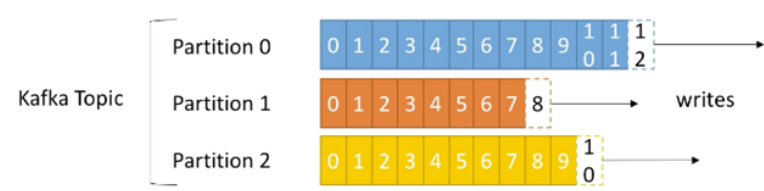
为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
描述
- 1、在Kafka中相当于Topic 的分区
- 2、类似于ES的 shard ,类似于HBase 的 Region
- 3、一般情况下一个 Topic 会拥有多个分区的Partition
- 4、每个分区中的数据都是有序的(数据的插入顺序),新增的数据都会分配到队列尾部
- 5、所以在消费同一个 Partition 的时候可以保证数据有序
路由规则
- 1、指定了Partition,则
直接使用 - 2、未指定Partition 但指定 key ,通过对 key 的value 进行
hash选出一个 partition - 3、partition 和 key 都未指定,使用
轮询选出一个 Partition
注意
-
1、topic中的数据分割为一个或多个partition,每个Partition是一个有序的队列(
分区有序,不能保证全局有序) -
2、每个topic至少有一个partition,当生产者产生数据的时候,根据分配策略,选择分区,然后将消息追加到指定的分区的末尾(队列)
-
3、每条消息都会有一个自增的编号
- 标识顺序
- 用于标识消息的偏移量
- 每个Partition都有自己独立的编号
-
4、每个partition中的数据使用多个segment文件存储
图解
四、Leader 负责读写的分区
概念
每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
注意
- 每个partition有多个副本,其中
有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
流程
- producer 先从 zookeeper 的 “/brokers/…/state” 节点找到该 partition 的 leader
- producer 将消息发送给该 leader
- leader 将消息写入本地 log
- followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK
- leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
五、Follower 同步数据备份
概念
每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。- ISR 判断是否能称为主的标准
注意
- 1、Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,
Follower与Leader保持数据同步 - 2、如果Leader失效,则从Follower中选举出一个新的Leader。
- 3、当Follower挂掉、卡住或者同步太慢,
leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
六、Replication 副本
概念
副本Replication,为保证集群中某个节点发生故障
描述
- 1、Kafka提供了
副本机制,每一个分区都会拥有副本,为保证集群中某个节点发生故障,节点上的Partition数据的安全 - 2、类似于 ES 的 replication
- 3、
Partition的功能是为了数据的读写 - 4、
Replication是为了数据的备份,没有读取的功能 - 5、一个Topic的每个分区有若干个副本,
一个Leader和多个Follower
注意
-
1、数据会存放到 topic 的 partation 中,但会有数据丢失的风险
-
2、需要对分区的数据进行备份(备份多少取决于你对数据的重视程度)
-
3、我们将分区的分为Leader(1)和Follower(N)
Leader负责写入和读取数据Follower只负责备份- 保证了数据的一致性
-
4、备份数设置为N,表示
主+备=N(参考HDFS)
七、producer 生产者
概念
消息生产者,向Kafka中发布消息的角色
描述
- 1、数据的生产者,将产生的消息存放到对应的 Topic
- 2、消息根据分区规则存放到不同的 Partition ,然后同步到 Replication
注意
- 1、生产者即数据的发布者,该角色将消息发布到Kafka的topic中。
- 2、broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。
- 3、生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
七、Consumer 消费者
概念
消息消费者,即从Kafka中拉取消息消费的客户端
注意
- 消费者可以从broker中读取数据。消费者可以消费多个topic中的数据
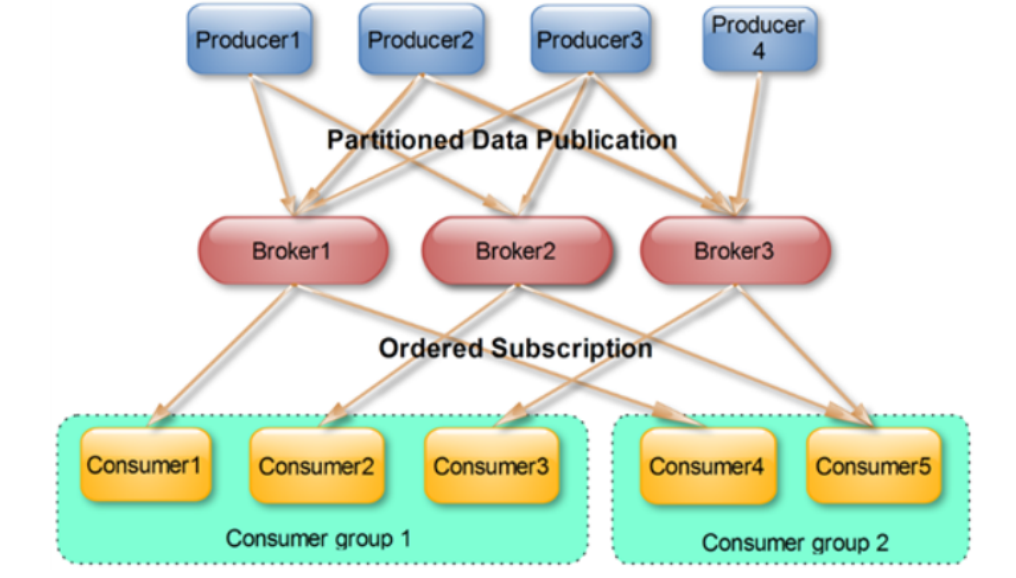
八、Consumer Group 消费者组
描述
- 1、消费者就是从 Topic 读取数据
- 2、消费者组一组共享一个Topic的偏移量
- 3、一个消费者组内包含一个或者多个消费者
- 4、不同的组可以同时消费相同的Topic
注意
- 1、每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
- 2、将多个消费者集中到一起去处理某一个Topic的数据,可以更快的提高数据的消费能力
- 3、整个消费者组共享一组偏移量(防止数据被重复读取),因为一个Topic有多个分区
图解
九、Offset 偏移量
概念
记录当前 Topic 消息消费的进度,就是 Offset 偏移量可以唯一的标识一条消息
描述
- 1、Kafka 是一个消息中间件不同于 Mysql ,ES 这种数据库
- 2、既然是消息中间件,消息时需要被消费的,而且
一个消息只能被一个组消费一次 - 3、这个组需要记录当前 Topic 消息消费的进度,
这个进度就是 Offset 偏移量 - 4、每一种组合,都会有一个 Offset 的位置,特殊情况下消费者可以适当调整 Offset 的位置。 侧面证明消费者的数据不会被立马删除。
注意
- 1、可以唯一的标识一条消息
- 2、偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息
- 3、
消息被消费之后,并不被马上删除,这样多个业务就可以重复使用kafka的消息 - 4、我们某一个业务也可以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制
- 5、
消息最终还是会被删除的,默认生命周期为1周(7*24小时)
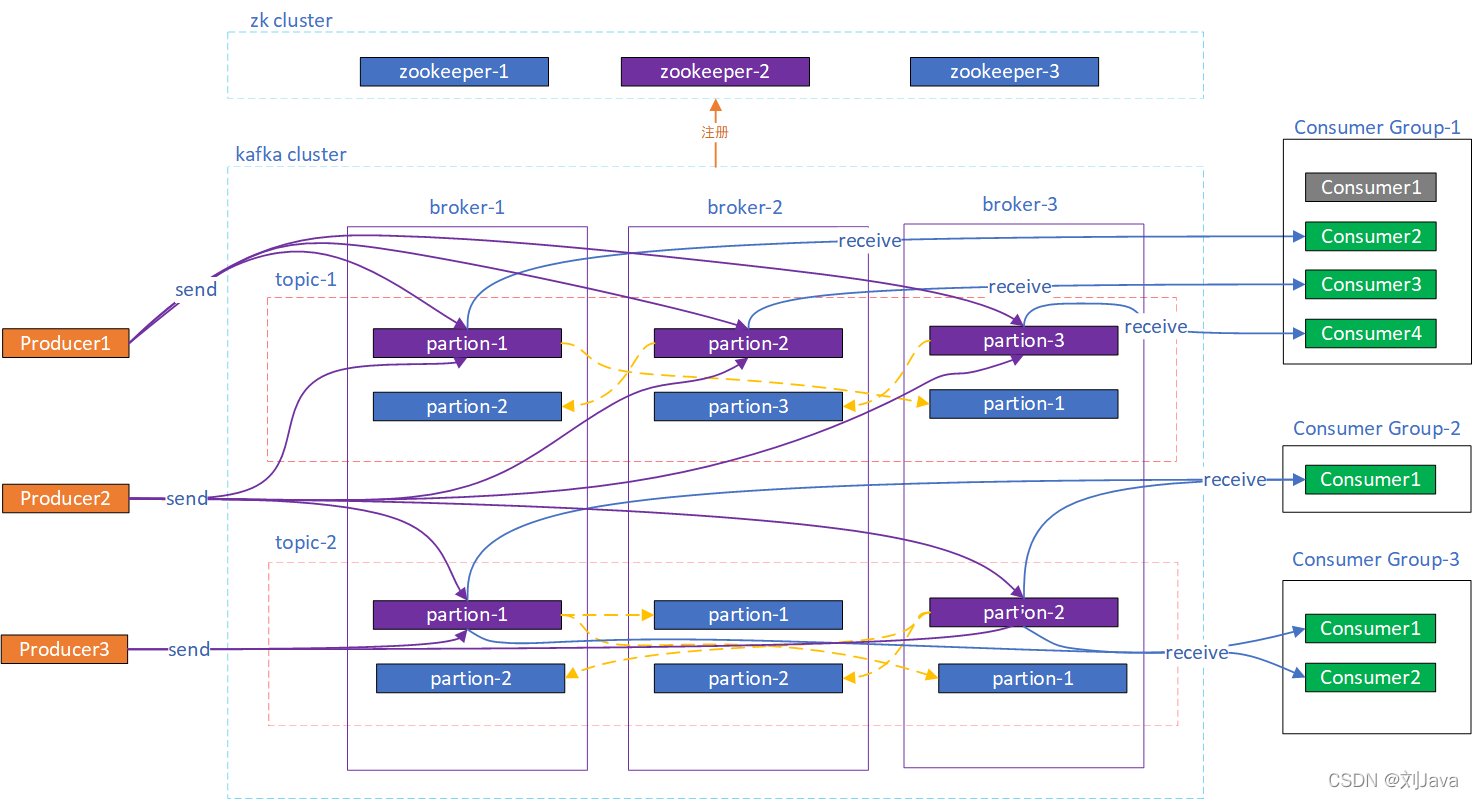
十、Zookeeper 存储元数据
描述
- 1、
存储 Kafka 的元数据信息 - 2、帮助进行选举
注意
- kafka 通过 zookeeper 来存储集群的 meta 信息
Kafka的基本架构以及Replica多副本机制_kafka replica_刘Java的博客-CSDN博客
Kafka:Topic概念与API介绍_kafka topic_ITKaven的博客-CSDN博客
Kafka的分区和副本机制_kafka分区和副本_星辰与晨曦的博客-CSDN博客
Introduction to Apache Kafka Partitions (confluent.io)
Best practices and strategies for Kafka topic partitioning | New Relic
摘抄自网络,便于检索查找。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号