Nginx 健康检查
Nginx 的健康检查这块笔者在网上看了很多文章,基本都是零零散散的,讲各种实现方式,没有一篇能完整的讲当下的 Nginx 实现健康检查的几种方式,应该选哪一种来使用,于是笔者想总结一篇。
一、目前 Nginx 支持两种主流的健康检查模式
主动检查模式
Nginx 服务端会按照设定的间隔时间主动向后端的 upstream_server 发出检查请求来验证后端的各个 upstream_server 的状态。 如果得到某个服务器失败的返回超过一定次数,比如 3 次就会标记该服务器为异常,就不会将请求转发至该服务器。
一般情况下后端服务器需要为这种健康检查专门提供一个低消耗的接口。
被动检查模式
Nginx 在代理请求过程中会自动的监测每个后端服务器对请求的响应状态,如果某个后端服务器对请求的响应状态在短时间内累计一定失败次数时,Nginx 将会标记该服务器异常。就不会转发流量给该服务器。 不过每间隔一段时间 Nginx 还是会转发少量的一些请求给该后端服务器来探测它的返回状态。 以便识别该服务器是否恢复。
后端服务器不需要专门提供健康检查接口,不过这种方式会造成一些用户请求的响应失败,因为 Nginx 需要用一些少量的请求去试探后端的服务是否恢复正常。 •注:如果是采用 Nginx 被动检查模式,官方原生的 Nginx 就支持,不需要依赖第三方模块或技术,所以下面的探讨都是针对 Nginx 实现主动健康检查的方法
二、目前使用 Nginx 实现健康检查的几种方式
1.使用开源模块 nginx_upstream_check_module
源码地址:https://github.com/yaoweibin/nginx_upstream_check_module
这是我目前找到的让原生 Nginx 通过添加开源模块,免费实现主动健康检查的唯一方法。 下面我会详细介绍这种方式的安装和配置过程
2.使用商业版 Nginx Plus
这种方法需要收费,可获得技术支持
3.使用淘宝开源的 Tengine 代替 Nginx
http://tengine.taobao.org
这种方式也免费,可行。
三、这里我们演示第一种方法的实现,使用开源模块 nginx_upstream_check_module
首先去下载该模块的源码包,放到要编译 Nginx 的服务器上;
操作系统环境:CentOS6.8 ,这里默认已经安装好了编译所需的开发环境
1.安装编译 Nginx 所需的软件包
yum install pcre pcre-devel openssl openssl-devel -y
2.选择 Nginx 版本,编译安装(编译前记得给 Nginx 打对应补丁)
•这里要认真看下,很关键:
这里 Nginx 选择:nginx-1.14.0.tar.gz ,nginx_upstream_check_module 源码就下载最新的主线代码包:nginx_upstream_check_module-master.zip 但是编译前补丁要选对应 Nginx 版本的。 比如这里 nginx-1.14.0 补丁要选择 check_1.14.0+.patch ; 补丁文件就在 nginx_upstream_check_module 源码包里面。
#!/bin/bash
tar xf nginx-1.14.0.tar.gz unzip nginx_upstream_check_module-master.zip
cd nginx-1.14.0
# 打补丁,注意编译前一定要有打补丁这步,不然添加的模块编译不生效 patch -p1 < /root/nginx_upstream_check_module-master/check_1.14.0+.patch
./configure --user=www --group=www --prefix=/alidata/server/nginx --with-http_stub_status_module --with-http_ssl_module --with-http_gzip_static_module --add-module=/root/nginx_upstream_check_module-master
make && make install
3.配置和应用
# nginx.conf
user www www; worker_processes 4;
worker_rlimit_nofile 65535;
events { use epoll; worker_connections 65535; }
http {
# 指定一个 upstream 负载均衡组,名称为 evalue upstream evalue { # 定义组内的节点服务,如果不加 weight 参数,默认就是 Round Robin ,加上了 weight 参数就是加权轮询 server 192.168.90.100:9999 weight=100; server 192.168.90.101:9999 weight=100; # interval=3000 检查间隔 3 秒 , rise=3 连续成功3次认为服务健康 , fall=5 连续失败5次认为服务不健康 , timeout=3000 健康检查的超时时间为 3 秒 , type=http 检查类型 http check interval=3000 rise=3 fall=5 timeout=3000 type=http; # check_http_send 设定检查的行为:请求类型 url 请求协议 -> HEAD /api/v1/chivox/health HTTP/1.0 check_http_send "HEAD /api/v1/chivox/health HTTP/1.0\r\n\r\n"; # 设定认为返回正常的响应状态 check_http_expect_alive http_2xx http_3xx; #check_http_send "GET /test3.html HTTP/2.0\r\n\r\n"; }
}
server { listen 80;
location / { proxy_pass http://evalue; keepalive_timeout 0; }
# 配置健康检查的状态监控页 # check_status [html|csv|json] # 也可以在请求监控页的时候带上参数以输出不同的格式,/status?format=html | /status?format=csv | /status?format=json
location /status { check_status html; access_log off; }
location ~ /.svn/ { deny all; } access_log /alidata/log/nginx/access/evalue.log json; }
Nginx 健康检查详解-腾讯云开发者社区-腾讯云 (tencent.com)
nginx健康检查详解_笔记大全_设计学院 (python100.com)
nginx(三十六)健康检查_nginx健康检查机制_wzj_110的博客-CSDN博客
一 ngx_http_upstream_module 官方自带

① server
-
1. 该指令用于'指定后端服务器'的名称和'optional'参数
-
-
2. 服务器的名称可以是一个'域名'、一个'ip地址'+端口号或'unix socket'
-
-
upstream backend {
-
server wzj.example.com weight=5;
-
server 127.0.0.1.8080 max_fails=3 fail_timeout=30s;
-
server unix:/tmp/wzj
-
}

② parameters解读
1)常用max_fails和fail_timeout

-
max_fails和fail_timeout:最大失败次数和失败时间段,两个参数需要'一起使用'
-
-
默认值:分别为1'次'和10s
-
-
+++++++++++++++ "案例解读" +++++++++++++++
-
-
server 172.25.2.100:8081 max_fails=2 fail_timeout=10s;
-
-
[1] 在10s内'访问到此服务器'2次,若'都访问'失败,则认为此服务器暂时不可用,nginx则会把'请求分发'到其他服务器
-
-
[2] 等待'10s后'继续访问此服务器,若'该时间段'内'2次都失败'继续执行'上述'过程;若成功,则'正常'运行
-
-
细节点:只有'请求过来的'时候,才会'尝试','不会'主动探测与后端的'连通性'

down:'节点下线用','不让'流量'转发'到这个'后端'节点2)不常用
-
说明:涉及'参数比较多',需要时'查找'即可
-
-
max_conns 节点服务器的最大连接数,服务器的并发最大连接数 可以设置合理范围 相当于'限流'

-
proxy_next_upstream 指定出现'何种错误或异常',将请求'转到'下一个节点
-
-
invalid_header: 后端服务器返回'空响应'或者'非法响应头'
-
-
细节点:只有在"没有"向客户端发送任何数据"以前",将请求转给'下一台后端服务器'才是可行的.也就是说,如果在传输响应到客户端时出现'错误或者超时',这类错误是'不可能恢复'的

三 nginx_upstream_check_module第三方模块
-
1. 服务'治理'的一个重要任务是'感知服务的变更',完成服务'自动注册'及'异常例程'的自动摘除
-
-
2. 这就需要'服务治理平台'能够:及时、准确的感知服务例程的'健康'状况

-
nginx'自带'的check模块相对来说比较"粗糙",推荐使用'淘宝技术团队'开发的nginx_upstream_check_module
-
-
特点:
-
-
1、'主动'地健康检查,nignx'定时'主动地去ping后端的服务列表
-
-
2、当发现某'服务出现异常'时,把该服务从健康列表中'移除'
-
-
3、当发现某服务'恢复'时,又能够将该服务'加回'健康列表中
-
-
思考:这个过程有'日志'记录没有?
-
-
++++++++ "说明" ++++++++
-
-
1. 需要'源码'编译,目前'rpm'包'没有'自带
-
-
2. 支持'多种维度'的健康检查,粒度更'细'
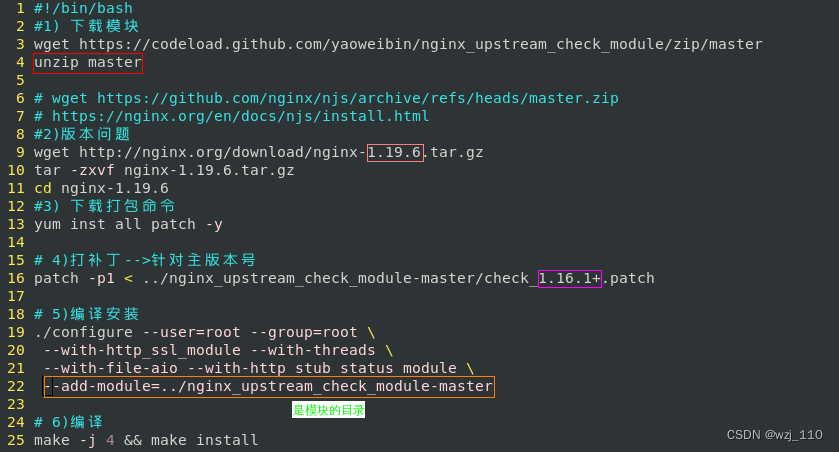
② 编译安装
-
补丁版本的选择:'nginx版本' > '补丁版本'
-
-
关注:check_1.12.1+.patch、check_1.14.0+.patch、check_1.16.1+.patch、check_1.20.1+.patch即可
 ③
③ 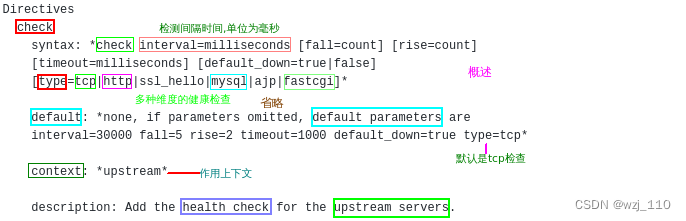
+++++++++ 'check指令'参数'细讲' +++++++++
④ check_http_send和check_http_expect_alive
在采用" GET"方法的情况下,请求uri的'大小不宜过大',确保可以在'1个间隔内'传输完成,否则会被健康检查模块'替换'服务器或'网络异常'

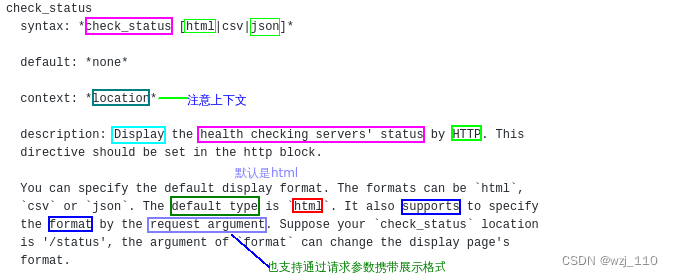

⑤ tcp的健康检查
-
upstream wzj {
-
-
server 172.25.2.100 max_fails=0 fail_timeout=0;
-
-
check internal=1500 rise=1 fall=3 timeout=3000 type=tcp;
-
}
-
-
解读:'禁止'nginx'自带'的检测机制,使用'第三方模块'的,上面是常见的'tcp'涉及的参数
-
-
附加:每隔'1.5s'就向'后端server'发一次'tcp'的健康检查包,如果'连续失败三次',则认为后端出现故障;如果'成功一次'则认为'后端'成功
-
-
备注:每次'请求响应的超时时间'不能超过'3000ms'
-
-
遗留点:nginx 'access.log'或'error.log'是否会'记录'日志?
-
说明:健康检查的'颗粒度'更细,防止'后端进程僵死(port还通)',但是服务'不通(后端处理不了HTTP请求)'
-
-
+++++++++++++ "http健康检查的案例" +++++++++++++
-
-
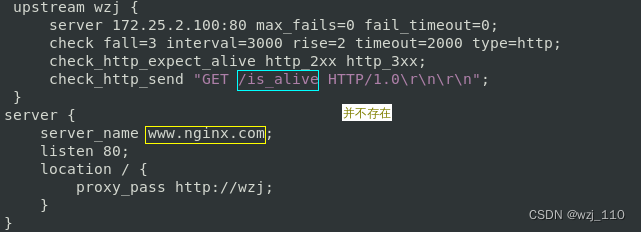
upstream wzj {
-
server 172.25.2.100:80 max_fails=0 fail_timeout=0;
-
check fall=3 interval=3000 rise=2 timeout=2000 type=http;
-
check_http_expect_alive http_2xx http_3xx ;
-
# 探针'路径' --> /is_alive
-
check_http_send "GET /is_alive HTTP/1.0\r\n\r\n" ;
-
}
-
-
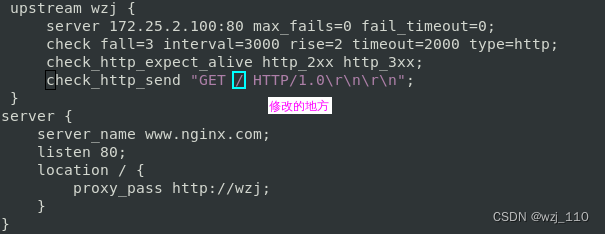
补充:可以加'请求头'满足复杂的'认证'之类的;注意多个请求头以'\r\n'分割
1)nginx准备配置段
2)请求1
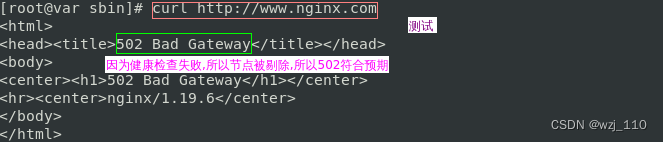
-
+++++++ 后端查看是否有'探测'请求 +++++++
-
-
遗留: 会产生大量的探测'日志',注意日志'防爆'

4)请求2


⑦ 健康状态页面
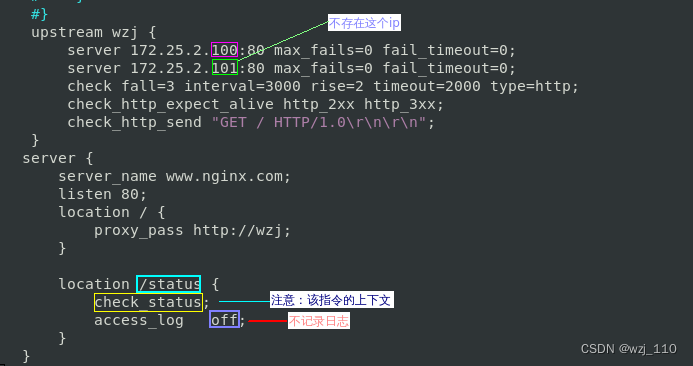

-
+++++++++++++ "排查down的原因" +++++++++++++
-
-
1)首先从nginx侧telnet或者curl或者wget测试下'端口'的连通性
-
-
2)如果四层是ok的,再看nginx的后端是否记录日志
-
-
3)如果后端有日志,可能'业务逻辑不支持HEAD请求方式'或者HTTP1.0低协议版本(替换这个两个信息),或者'后端处理请求超时'(超过timeout的阈值),导致非2xx和3xx的报错
-
-
辅助排查:修改check_http_expect_alive为某个'指定的xx'
-
-
4)只能tcpdump抓包
⑧ 注意事项

Nginx主动健康检查upstream (kingdee.com)
Nginx 健康检查 | 运维笔记 (centosdoc.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号