共享对象的技巧-假如需要一百万个对象
这次搞不好真要被砍了,线上一个用户系统内存溢出了,占用内存太高了
--用户基数大,内存占用高正常
高的不太正常了,我觉得可能和我的设计有关
--那说说你的用户设计
设计背景每个平台都会有用户这种基础数据的设计,作为最基础的用户,每个用户都有很多属性,比如性别,姓名,手机号等,每个用户还可以有类似经验值这样的荣誉系统,根据不同的经验值来对应不同的等级,不同的等级对应不同的荣誉UI,比如一级用户可能只显示一个星星,二级用户显示两颗星星,以此类推,类似于QQ等级的星星月亮太阳,这样的荣誉系统随着平台的不断壮大,可能会衍生出很多类型。那么问题来了,用户登录的时候就需要初始化用户的这些荣誉值,以星星数为例,类似于以下代码
public class Star
{
//等级
public int Level{get ;set ;}
//对应的星星数目
public int StarNumber{get ;set ;}
//对应的星星颜色
public int Color{get ;set ;}
... 其他属性
}
//用户信息
public class User{
public Star StarInfo{get ;set ;}
//...用户的其他属性
}
//初始化用户信息
User u=new User(){ StarInfo=new Star(){ Level=1, StarNumber=1,Color=1}};
每一个登录用户都会初始化一个Star属性来表示当前用户的Star信息,当有100万用户甚至更多用户同时在线的时候,内存中就实例化了同样数量的Star对象,以及其他类似的属性对象。这么多重复的对象难道不能优化吗?当然不是!!
问题分析
一个业务出现问题,首先要分析问题的所在。根据以上所说,问题的根本在于产生了大量的对象,首先每个用户对象都有自己独特的状态,这个基本上不可能分解优化,但是类似Star这样的属性就有优化途径了,这些荣誉属性一个最大的共同点就是不可变,换句话说,等级1的用户对应的Star信息是永远不会变的,永远是level=1,starnumber=1,color=1 等。基于这个不变性,我们可以把这个Star抽离出来,供所有等级1的用户使用,假设原来有10万等级1的用户,原来需要10万个对象,现在只需要一个对象,这可是天壤之别。
解决问题
基于以上问题分析,我们需要做的是把对象重复使用,只要是对象重复问题,基本上可以利用一个对象出口来解决问题,类似于以下的对象初始化工厂,但是要注意线程安全问题,因为同时请求并初始化对象的线程会有多个。
public class UserStarFac
{
static object objLock = new object();
static Dictionary<int, Star> UserStarMap = new Dictionary<int, Star>();
public static Star GetUserStar(int level)
{
//利用锁来防止实例化多次,当然这里可以优化
lock (objLock)
{
Star info = null; ;
if(!UserStarMap.TryGetValue(level, out info))
{
info = new Star() { Color = 1, Level = 1, StarNumber = 1 };
UserStarMap.Add(level,info);
}
return info;
}
}
}
编写简单测试程序
static void Main(string[] args)
{
int i = 0;
List<User> userList = new List<User>();
while (i < 100000)
{
// userList.Add(new User() { StarInfo=new Star() { Color=1, Level=1, StarNumber=1} });
userList.Add(new User() { StarInfo= UserStarFac .GetUserStar(1)});
i++;
}
Console.WriteLine("初始化完成");
Console.Read();
}
内存的测试结果:
不执行任何程序:占用内存:2.8 M
无优化初始化10万对象:占用内存:11 M
优化之后初始化10万对象:占用内存:7 M
居然一个小小的优化就减少了4M内存,不要小看这小小的4M,你要看的是比例,居然减少了将近 50%,真实业务中,可以进行这种优化的地方数不胜数,不知道你是否在乎呢?
这种大量重复对象的问题尤其是在游戏编程中经常存在,比如五子棋游戏,棋子的初始化,一个游戏大厅存在成千上百万对局,如果每个局中的棋子都初始化一个对象,那内存使用是相当可怕的,这种需要把通用的对象属性,不变的对象属性抽离出来,做共享是有必要的。
分布式缓存的一条明路
菜菜呀,由于公司业务不断扩大,线上分布式缓存服务器扛不住了呀
--如果加硬件能解决的问题,那就不需要修改程序
我是想加服务器来解决这个问题,但是有个问题呀,你忘了去年分布式缓存服务器也扩容过一次,很多请求都穿透了,DB差点扛不住呀,这次再扩容DB估计就得挂了
--为什么会有这么多请求穿透呢?公司的缓存策略是什么?
很简单,根据缓存数据key的哈希值然后和缓存服务器个数取模,即:服务器信息=hash(key)%服务器数量
--这样的话,增加一台服务器,岂不是大部分的缓存几乎都命中不了了?
问题分析
过以上对话,各位是否能够猜到所有缓存穿透的原因呢?回答之前我们先来看一下缓存策略的具体代码:
缓存服务器IP=hash(key)%服务器数量
这里还要多说一句,key的取值可以根据具体业务具体设计。比如,我想要做负载均衡,key可以为调用方的服务器IP;获取用户信息,key可以为用户ID;等等。
在服务器数量不变的情况下,以上设计没有问题。但是要知道,程序员的现实世界是悲惨的,唯一不变的就是业务一直在变。我本无奈,只能靠技术来改变这种状况。
假如我们现在服务器的数量为10,当我们请求key为6的时候,结果是4,现在我们增加一台服务器,服务器数量变为11,当再次请求key为6的服务器的时候,结果为5.不难发现,不光是key为6的请求,几乎大部分的请求结果都发生了变化,这就是我们要解决的问题, 这也是我们设计分布式缓存等类似场景时候主要需要注意的问题。
我们终极的设计目标是:在服务器数量变动的情况下
1. 尽量提高缓存的命中率(转移的数据最少)
2. 缓存数据尽量平均分配
解决方案
通过以上的分析我们明白了,造成大量缓存失效的根本原因是公式分母的变化,如果我们把分母保持不变,基本上可以减少大量数据被移动
如果基于公式:缓存服务器IP=hash(key)%服务器数量 我们保持分母不变,基本上可以改善现有情况。我们选择缓存服务器的策略会变为:
缓存服务器IP=hash(key)%N (N为常数)
N的数值选择,可以根据具体业务选择一个满足情况的值。比如:我们可以肯定将来服务器数量不会超过100台,那N完全可以设定为100。那带来的问题呢?
目前的情况可以认为服务器编号是连续的,任何一个请求都会命中一个服务器,还是以上作为例子,我们服务器现在无论是10还是增加到11,key为6的请求总是能获取到一台服务器信息,但是现在我们的策略公式分母为100,如果服务器数量为11,key为20的请求结果为20,编号为20的服务器是不存在的。
以上就是简单哈希策略带来的问题(简单取余的哈希策略可以抽象为连续的数组元素,按照下标来访问的场景)
为了解决以上问题,业界早已有解决方案,那就是一致性哈希。
一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
一致性哈希具体的特点,请各位百度,这里不在详细介绍。至于解决问题的思路这里还要强调一下:
1. 首先求出服务器(节点)的哈希值,并将其配置到环上,此环有2^32个节点。
2. 采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
3. 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过2^32仍然找不到服务器,就会保存到第一台服务器上
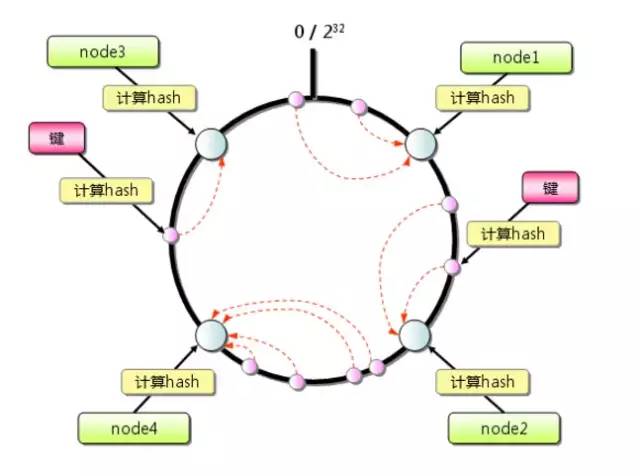
当增加新的服务器的时候会发生什么情况呢?
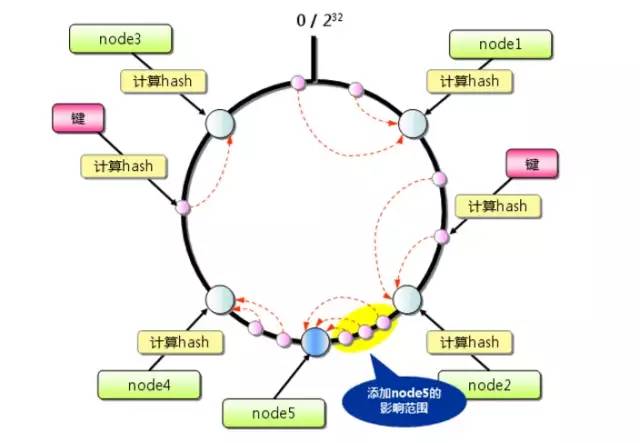
通过上图我们可以发现发生变化的只有如黄色部分所示。删除服务器情况类似。
通过以上介绍,一致性哈希正是解决我们目前问题的一种方案。解决方案千万种,能解决问题即为好
优化方案
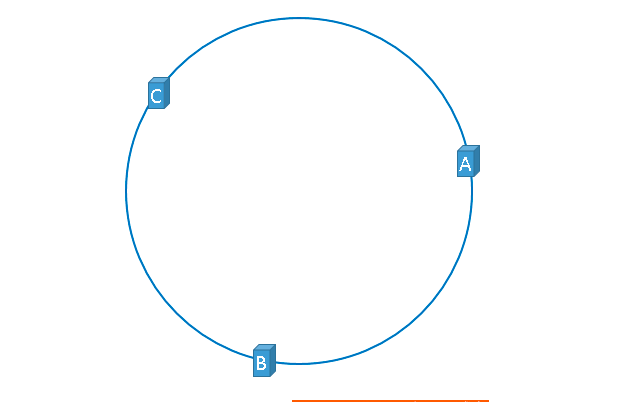
到目前为止方案都看似完美,但现实是残酷的。以上方案虽好,但还存在瑕疵。假如我们有3台服务器,理想状态下服务器在哈希环上的分配如下图:
但是现实往往是这样:
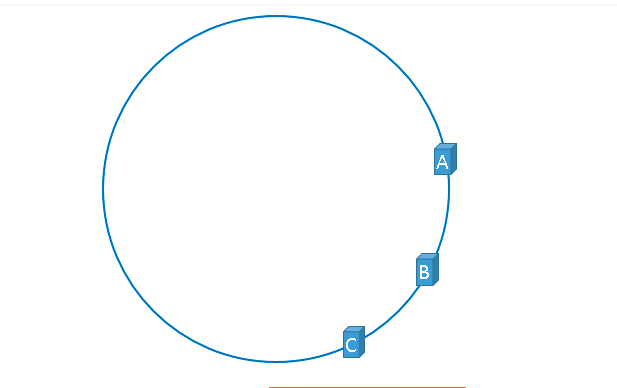
这就是所谓的哈希环偏斜。分布不均匀在某些场景下会依次压垮服务器,实际生产环境一定要注意这个问题。为了解决这个问题,虚拟节点应运而生。
如上图,哈希环上不再是实际的服务器信息,而是服务器信息的映射信息,比如:ServerA-1,ServerA-2 都映射到服务器A,在环上是服务器A的一个复制品。这种解决方法是利用数量来达到均匀分布的目的,随之需要的内存可能会稍微大一点,算是空间换取设计的一种方案。
扩展阅读
1. 既然是哈希就会有哈希冲突,那多个服务器节点的哈希值相同该怎么办呢?我们可以采用散列表寻址的方案:从当前位置顺时针开始查找空位置,直到找到一个空位置。如果未找到,菜菜认为你的哈希环是不是该扩容了,或者你的分母参数是不是太小了呢。
2. 在实际的业务中,增加服务器或者减少服务器的操作要比查找服务器少的多,所以我们存储哈希环的数据结构的查找速度一定要快,具体说来本质是:自哈希环的某个值起,能快速查找第一个不为空的元素。
3. 如果你度娘过你就会发现,网上很多介绍虚拟哈希环节点个数为2^32(2的32次方),千篇一律。难道除了这个个数就不可以吗?在菜菜看来,这个数目完全必要这么大,只要符合我们的业务需求,满足业务数据即可。
4. 一致性哈希用到的哈希函数,不止要保证比较高的性能,还要保持哈希值的尽量平均分布,这也是一个工业级哈希函数的要求,一下代码实例的哈希函数其实不是最佳的,有兴趣的同学可以优化一下。
5. 有些语言自带的GetHashCode()方法应用于一致性哈希是有问题的,例如c#。程序重启之后同一个字符串的哈希值是变动的。所有需要一个更加稳定的字符串转int的哈希算法
一致性哈希解决的本质问题是:相同的key通过相同的哈希函数,能正确路由到相同的目标。像我们平时用的数据库分表策略,分库策略,负载均衡,数据分片等都可以用一致性哈希来解决。
理论结合实际才是真谛(NetCore代码)
以下代码经过少许修改可直接应用于中小项目生产环境。
//真实节点的信息
public abstract class NodeInfo
{
public abstract string NodeName { get; }
}
测试程序所用节点信息:
class Server : NodeInfo
{
public string IP { get; set; }
public override string NodeName
{
get => IP;
}
}
以下为一致性哈希核心代码:
/// <summary>
/// 1.采用虚拟节点方式 2.节点总数可以自定义 3.每个物理节点的虚拟节点数可以自定义
/// </summary>
public class ConsistentHash
{
//哈希环的虚拟节点信息
public class VirtualNode
{
public string VirtualNodeName { get; set; }
public NodeInfo Node { get; set; }
}
//添加元素 删除元素时候的锁,来保证线程安全,或者采用读写锁也可以
private readonly object objLock = new object();
//虚拟环节点的总数量,默认为100
int ringNodeCount;
//每个物理节点对应的虚拟节点数量
int virtualNodeNumber;
//哈希环,这里用数组来存储
public VirtualNode[] nodes = null;
public ConsistentHash(int _ringNodeCount = 100, int _virtualNodeNumber = 3)
{
if (_ringNodeCount <= 0 || _virtualNodeNumber <= 0)
{
throw new Exception("_ringNodeCount和_virtualNodeNumber 必须大于0");
}
this.ringNodeCount = _ringNodeCount;
this.virtualNodeNumber = _virtualNodeNumber;
nodes = new VirtualNode[_ringNodeCount];
}
//根据一致性哈希key 获取node信息,查找操作请业务方自行处理超时问题,因为多线程环境下,环的node可能全被清除
public NodeInfo GetNode(string key)
{
var ringStartIndex = Math.Abs(GetKeyHashCode(key) % ringNodeCount);
var vNode = FindNodeFromIndex(ringStartIndex);
return vNode == null ? null : vNode.Node;
}
//虚拟环添加一个物理节点
public void AddNode(NodeInfo newNode)
{
var nodeName = newNode.NodeName;
int virtualNodeIndex = 0;
lock (objLock)
{
//把物理节点转化为虚拟节点
while (virtualNodeIndex < virtualNodeNumber)
{
var vNodeName = $"{nodeName}#{virtualNodeIndex}";
var findStartIndex = Math.Abs(GetKeyHashCode(vNodeName) % ringNodeCount);
var emptyIndex = FindEmptyNodeFromIndex(findStartIndex);
if (emptyIndex < 0)
{
// 已经超出设置的最大节点数
break;
}
nodes[emptyIndex] = new VirtualNode() { VirtualNodeName = vNodeName, Node = newNode };
virtualNodeIndex++;
}
}
}
//删除一个虚拟节点
public void RemoveNode(NodeInfo node)
{
var nodeName = node.NodeName;
int virtualNodeIndex = 0;
List<string> lstRemoveNodeName = new List<string>();
while (virtualNodeIndex < virtualNodeNumber)
{
lstRemoveNodeName.Add($"{nodeName}#{virtualNodeIndex}");
virtualNodeIndex++;
}
//从索引为0的位置循环一遍,把所有的虚拟节点都删除
int startFindIndex = 0;
lock (objLock)
{
while (startFindIndex < nodes.Length)
{
if (nodes[startFindIndex] != null && lstRemoveNodeName.Contains(nodes[startFindIndex].VirtualNodeName))
{
nodes[startFindIndex] = null;
}
startFindIndex++;
}
}
}
//哈希环获取哈希值的方法,因为系统自带的gethashcode,重启服务就变了
protected virtual int GetKeyHashCode(string key)
{
var sh = new SHA1Managed();
byte[] data = sh.ComputeHash(Encoding.Unicode.GetBytes(key));
return BitConverter.ToInt32(data, 0);
}
#region 私有方法
//从虚拟环的某个位置查找第一个node
private VirtualNode FindNodeFromIndex(int startIndex)
{
if (nodes == null || nodes.Length <= 0)
{
return null;
}
VirtualNode node = null;
while (node == null)
{
startIndex = GetNextIndex(startIndex);
node = nodes[startIndex];
}
return node;
}
//从虚拟环的某个位置开始查找空位置
private int FindEmptyNodeFromIndex(int startIndex)
{
while (true)
{
if (nodes[startIndex] == null)
{
return startIndex;
}
var nextIndex = GetNextIndex(startIndex);
//如果索引回到原地,说明找了一圈,虚拟环节点已经满了,不会添加
if (nextIndex == startIndex)
{
return -1;
}
startIndex = nextIndex;
}
}
//获取一个位置的下一个位置索引
private int GetNextIndex(int preIndex)
{
int nextIndex = 0;
//如果查找的位置到了环的末尾,则从0位置开始查找
if (preIndex != nodes.Length - 1)
{
nextIndex = preIndex + 1;
}
return nextIndex;
}
#endregion
}
测试生成的节点
ConsistentHash h = new ConsistentHash(200, 5);
h.AddNode(new Server() { IP = "192.168.1.1" });
h.AddNode(new Server() { IP = "192.168.1.2" });
h.AddNode(new Server() { IP = "192.168.1.3" });
h.AddNode(new Server() { IP = "192.168.1.4" });
h.AddNode(new Server() { IP = "192.168.1.5" });
for (int i = 0; i < h.nodes.Length; i++)
{
if (h.nodes[i] != null)
{
Console.WriteLine($"{i}===={h.nodes[i].VirtualNodeName}");
}
}
输出结果(还算比较均匀):
2====192.168.1.3#4
10====192.168.1.1#0
15====192.168.1.3#3
24====192.168.1.2#2
29====192.168.1.3#2
33====192.168.1.4#4
64====192.168.1.5#1
73====192.168.1.4#3
75====192.168.1.2#0
77====192.168.1.1#3
85====192.168.1.1#4
88====192.168.1.5#4
117====192.168.1.4#1
118====192.168.1.2#4
137====192.168.1.1#1
152====192.168.1.2#1
157====192.168.1.5#2
158====192.168.1.2#3
159====192.168.1.3#0
162====192.168.1.5#0
165====192.168.1.1#2
166====192.168.1.3#1
177====192.168.1.5#3
185====192.168.1.4#0
196====192.168.1.4#2
测试一下性能
Stopwatch w = new Stopwatch();
w.Start();
for (int i = 0; i < 100000; i++)
{
var aaa = h.GetNode("test1");
}
w.Stop();
Console.WriteLine(w.ElapsedMilliseconds);
输出结果(调用10万次耗时657毫秒):
657
写在最后
以上代码实有优化空间
1. 哈希函数
2. 很多for循环的临时变量
不懂算法的程序员不是好工程师--选择排序
算法主要衡量标准
时间复杂度(运行时间)
在算法时间复杂度维度,我们主要对比较和交换的次数做对比,其他不交换元素的算法,主要会以访问数组的次数的维度做对比。
其实有很多同学对于算法的时间复杂度有点模糊,分不清什么所谓的 O(n),O(nlogn),O(logn)...等,也许下图对一些人有一些更直观的认识。

空间复杂度(额外的内存使用)
排序算法的额外内存开销和运行时间同等重要。 就算一个算法时间复杂度比较优秀,空间复杂度非常差,使用的额外内存非常大,菜菜认为它也算不上一个优秀的算法。
结果的正确性
这个指标是菜菜自己加上的,我始终认为一个优秀的算法最终得到的结果必须是正确的。就算一个算法拥有非常优秀的时间和空间复杂度,但是结果不正确,又有什么意义呢?
原理
在起始位置右侧(或左侧)找出最小的那个元素,然后和起始位置的元素交换。
选择排序是一个不稳定的排序算法。
具体步骤如下:
在一个数据列表中找到最小的那个元素,将它和列表的第一个元素交换位置。
在第二个元素位置开始再次寻找最小的那个元素,然后和列表的第二个位置的元素交换。
在第三个元素位置开始再次寻找最小的那个元素,然后和列表的第三个位置的元素交换
如此反复,直到开始查找起始位置到达列表末尾。
如果查找过程中最小的元素就是起止位置的元素,那么它就和它自己交换。
因为这种算法总是在不断的选择剩余元素中最小者,因此得名选择排序
复杂度
时间复杂度
比较次数
对于长度为N的列表,选择排序需要大约n² /2次比较.即:O(n²)平方级别。
交换次数
对于长度为N的列表,选择排序需要大约N次交换.即:O(N) 线性级别。
性能和特点
总体来说,选择排序是一种比较简单的排序算法,很容易理解也很好用代码实现,当然他的特点也很明显:
运行时间和数据初始状态无关
为什么这么说呢?算法进行中为了查找最小的元素而遍历列表并不能为下次遍历带来任何信息,这个特性在大部分情况下是缺点。如果一个数据列表初始状态是有序的或者部分有序的,选择排序仍然需要全部扫描一次和交换。因此和一个完全无序的列表排序所花的时间相差不大。
数据移动次数是最少的
每次交换只会改变两个列表元素,因此长度为N的列表只会发生N次交换,交换次数和列表的长度是线性关系,其他算法都不具备这个特性。
适用场景
由于选择排序的对比次数在平方级别,但是移动次数在线性级别,所以当N比较小的时候比较适用。
其他
为什么选择排序不稳定呢?
首先我们要明白算法稳定是什么意思呢?
在待排序的数据中,存在多个相同的数据,经过排序之后,他们的相对顺序依旧保持不变,实际上就是说array[i]=array[j],i<j.就是array[i]在array[j]之前,那么经过排序之后array[i]依旧在array[j]之前,那么这个排序算法稳定,否则,这个排序算法不稳定。
根据以上定义很容易可以得出这样的结论:
我们举出一个实例,序列5 8 5 2 9, 这个在执行选择排序的时候,第一遍,肯定会将array[0]=5,交换到2所在的位置,也就是 2 8 5 5 9,那么很显然,之后的排序我们就会发现,array[2]中的5会出现在原先的array[0]之前,所以选择排序不是一个稳定的排序
实现案例
c#
static void Main(string[] args) {
List<int> data = new List<int>() ; for (int i = 0; i < 10; i++)
{
data.Add(new Random(Guid.NewGuid().GetHashCode()).Next(1, 100));
} //打印原始数组值
Console.WriteLine($"原始数据: {string.Join(",", data)}"); int n = data.Count; for (int i = 0; i < n; i++)
{ int minIndex = i; //查找最小的元素的索引
for (int j = i+1; j < n; j++)
{ if (data[j] < data[minIndex])
{
minIndex = j;
}
} //交换最小的元素和当前位置的元素,当然这里可以加入一个最小元素是否是当前位置元素的判断来较少交换次数
int tempItem = data[i];
data[i] = data[minIndex];
data[minIndex] = tempItem;
} //打印排序后的数组
Console.WriteLine($"排序数据: {string.Join(",", data)}");
Console.Read();
}
运行结果:
原始数据:97,85,61,22,62,12,67,22,68,42
排序数据:12,22,22,42,61,62,67,68,85,97
程序员修仙之路--高性能排序多个文件
我看服务器上写了很多个日志文件,我看着太费劲了,能不能按照日期排序整合成一个文件呀?
作为一个技术人员,技术的问题还是要解决。经过线上日志的分析,日志采用小时机制,一个小时一个日志文件,同一个小时的日志文件有多个,也就是说同一时间内的日志有可能分散在多个日志文件中,这也是Y总要合并的主要原因。每个日志文件大约有500M,大约有100个。此时,如果你阅读到此文章,该怎么做呢?不如先静心想2分钟!!
问题分析要想实现Y总的需求其实还是有几个难点的:
1. 如何能把所有的日志文件按照时间排序
2. 日志文件的总大小为500M*100 ,大约50G,所以全部加载到内存是不可能的
3. 程序执行过程中,要频繁排序并查找最小元素。
那我们该怎么做呢?其中一个解决方案就是它:堆
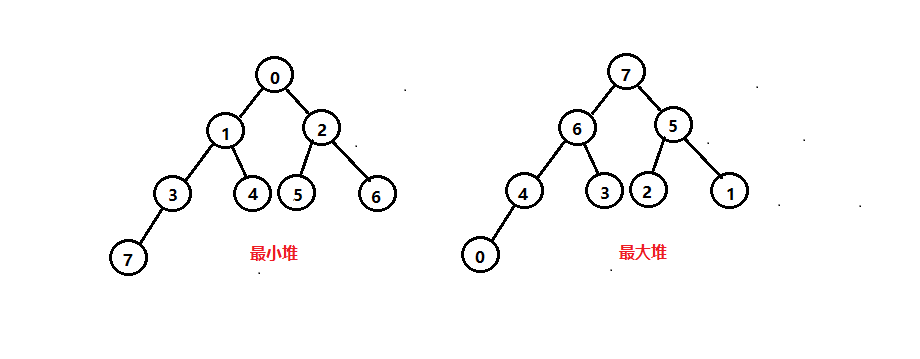
解决方案堆定义堆(英语:heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。
堆总是满足下列性质:
1. 堆中某个节点的值总是不大于或不小于其父节点的值
2. 堆总是一棵完全二叉树(完全二叉树要求,除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列)
对于每个节点的值都大于等于子树中每个节点值的堆,我们叫作“大顶堆”。对于每个节点的值都小于等于子树中每个节点值的堆,我们叫作“小顶堆”。
堆实现
完全二叉树比较适合用数组来存储(链表也可以实现)。为什么这么说呢?用数组来存储完全二叉树是非常节省存储空间的。因为我们不需要存储左右子节点的指针,单纯地通过数组的下标,就可以找到一个节点的左右子节点和父节点。
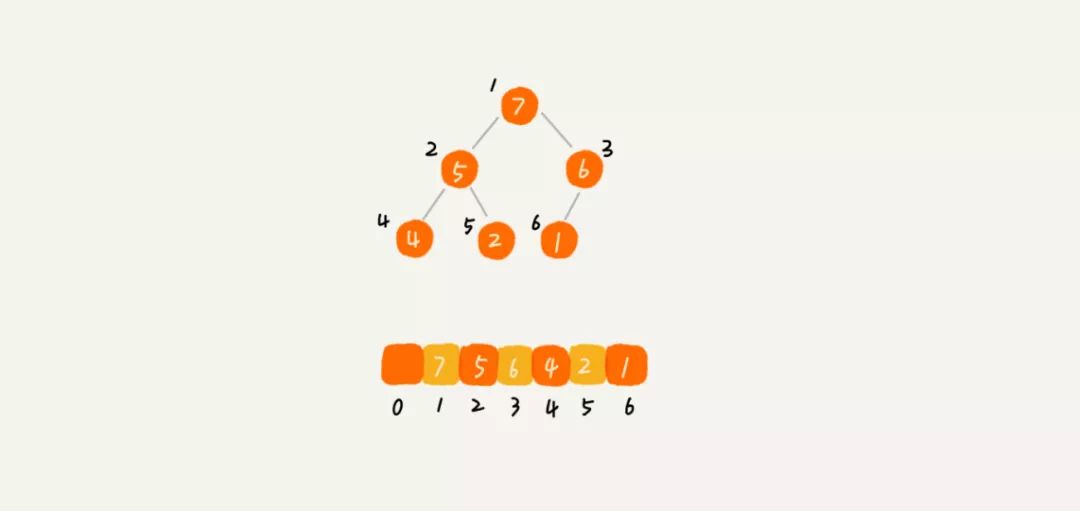
经过上图可以发现,数组位置0为空,虽然浪费了一个存储空间,但是当计算元素在数组位置的时候确非常方便:数组下标为X的元素的左子树的下标为2x,右子树的下标为2x+1。
其实实现一个堆非常简单,就是顺着元素所在的路径,向上或者向下对比然后交换位置
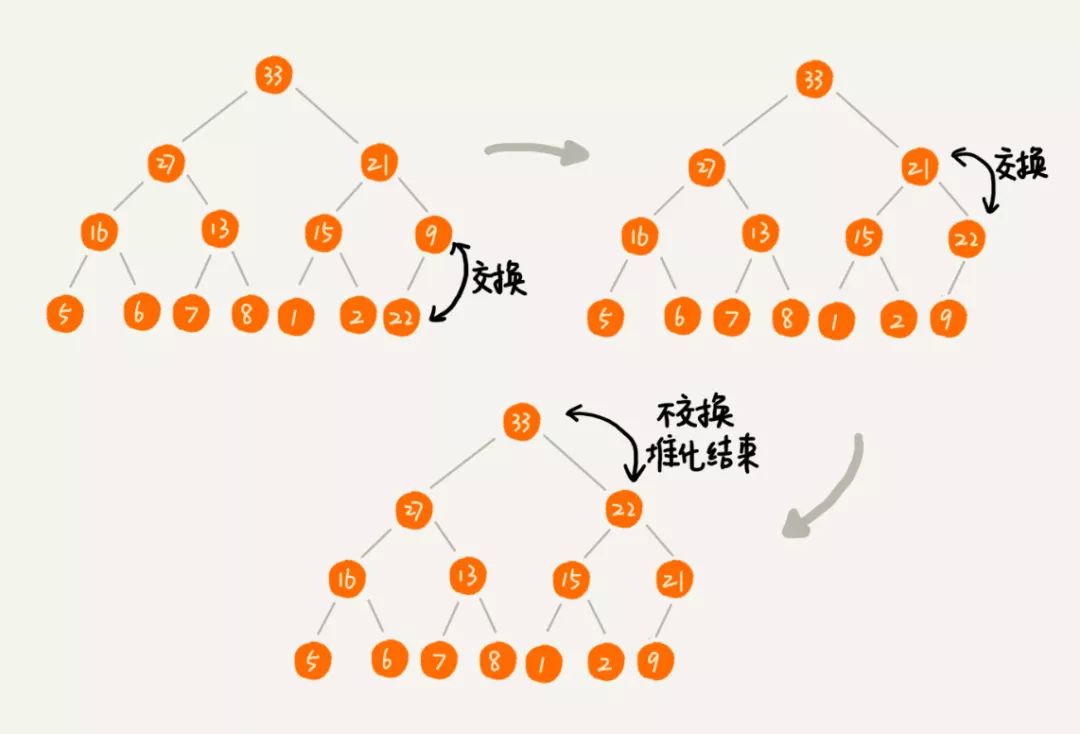
1. 添加元素
添加元素的时候我们习惯采用自下而上的调整方式来调整堆,我们在数组的最后一个空闲位置插入新元素,按照堆的下标上标原则查找到父元素对比,如果小于父元素的值(大顶堆),则互相交换。如图:
2. 删除最大(最小元素)
对于大顶堆,堆顶的元素就是最大元素。删除该元素之后,我们需要把第二大元素提到堆顶位置。依次类推,直到把路径上的所有元素都调整完毕。
扩展阅读
1. 小顶堆的顶部元素其实就是整个堆最小的元素,大顶堆顶部元素是整个堆的最大元素。这也是堆排序的最大优点,取最小元素或者最大元素时间复杂度为O(1)
2. 删除元素的时候我们要注意一点,如果采用自顶向下交换元素的方式,在很多情况下造成堆严重的不平衡(左右子树深度相差较大)的情况,为了防止类似情况,我们可以把最后一个元素提到堆顶,然后调整的策略,因为最后一个元素总是在最后一级,不会造成左右子树相差很大的情况。
3. 对于有重复元素的堆,一种解决方法是认为是谁先谁大,后进入堆的元素小于先进入堆的元素,这样在查找的时候一定要查彻底才行。另外一种方式是在堆的每个元素中存储一个链表,用来存放相同的元素,原理类似于散列表。不过这样在删除这个元素的时候需要特殊处理一下。
4. 删除堆顶数据和往堆中插入数据的时间复杂度都是 O(logn)。
5. 不断调整堆的过程其实就是排序过程,在某些场景下,我们可以利用堆来实现排序。
asp.net core 模拟代码以下代码经过少许修改甚至不修改的情况下可直接在生产环境应用
小顶堆实现代码
/// <summary>
/// 小顶堆,T类型需要实现 IComparable 接口
/// </summary>
class MinHeap<T> where T : IComparable
{
private T[] container; // 存放堆元素的容器
private int capacity; // 堆的容量,最大可以放多少个元素
private int count; // 堆中已经存储的数据个数
public MinHeap(int _capacity)
{
container = new T[_capacity + 1];
capacity = _capacity;
count = 0;
}
//插入一个元素
public bool AddItem(T item)
{
if (count >= capacity)
{
return false;
}
++count;
container[count] = item;
int i = count;
while (i / 2 > 0 && container[i].CompareTo(container[i / 2]) < 0)
{
// 自下往上堆化,交换 i 和i/2 元素
T temp = container[i];
container[i] = container[i / 2];
container[i / 2] = temp;
i = i / 2;
}
return true;
}
//获取最小的元素
public T GetMinItem()
{
if (count == 0)
{
return default(T);
}
T result = container[1];
return result;
}
//删除最小的元素,即堆顶元素
public bool DeteleMinItem()
{
if (count == 0)
{
return false;
}
container[1] = container[count];
container[count] = default(T);
--count;
UpdateHeap(container, count, 1);
return true;
}
//从某个节点开始从上向下 堆化
private void UpdateHeap(T[] a, int n, int i)
{
while (true)
{
int maxPos = i;
//遍历左右子树,确定那个是最小的元素
if (i * 2 <= n && a[i].CompareTo(a[i * 2]) > 0)
{
maxPos = i * 2;
}
if (i * 2 + 1 <= n && a[maxPos].CompareTo(a[i * 2 + 1]) > 0)
{
maxPos = i * 2 + 1;
}
if (maxPos == i)
{
break;
}
T temp = container[i];
container[i] = container[maxPos];
container[maxPos] = temp;
i = maxPos;
}
}
}//因为需要不停的从log文件读取内容,所以需要一个和log文件保持连接的包装
class LogInfoIndex : IComparable
{
//标志内容来自于哪个文件
public int FileIndex { get; set; }
//具体的日志文件内容
public LogInfo Data { get; set; }
public int CompareTo(object obj)
{
var tempInfo = obj as LogInfoIndex;
if (this.Data.Index > tempInfo.Data.Index)
{
return 1;
}
else if (this.Data.Index < tempInfo.Data.Index)
{
return -1;
}
return 0;
}
}
class LogInfo
{
//用int来模拟datetime 类型,因为用int 看的最直观
public int Index { get; set; }
public string UserName { get; set; }
} static void WriteFile()
{
int fileCount = 0;
while (fileCount < 10)
{
string filePath = $@"D:\log\{fileCount}.txt";
int index = 0;
while (index < 100000)
{
LogInfo info = new LogInfo() { Index = index, UserName = Guid.NewGuid().ToString() };
File.AppendAllText(filePath, JsonConvert.SerializeObject(info)+ "\r\n");
index++;
}
fileCount++;
}
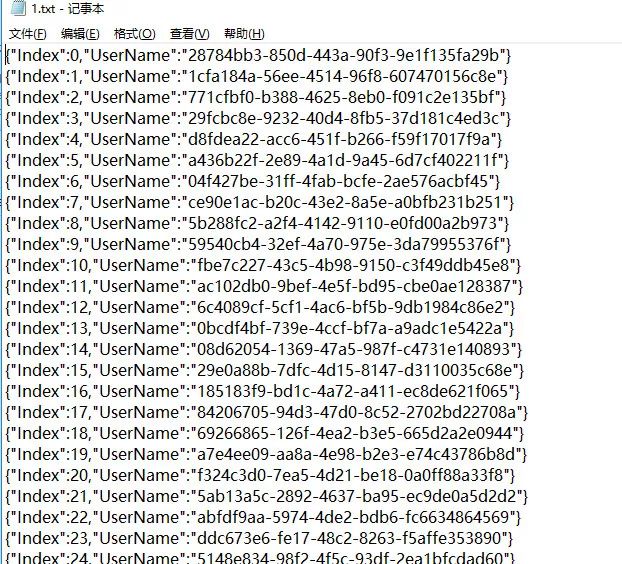
}文件内容如下:
测试程序
static void Main(string[] args)
{
int heapItemCount = 10;
int startIndex = 0;
StreamReader[] allReader = new StreamReader[10];
MinHeap<LogInfoIndex> container = new MinHeap<LogInfoIndex>(heapItemCount);
//首先每个文件读取一条信息
while(startIndex< heapItemCount)
{
string filePath = $@"D:\log\{startIndex}.txt";
System.IO.StreamReader reader = new System.IO.StreamReader(filePath);
allReader[startIndex] = reader;
string content= reader.ReadLine();
var contentObj = JsonConvert.DeserializeObject<LogInfo>(content);
LogInfoIndex item = new LogInfoIndex() { FileIndex= startIndex , Data= contentObj };
container.AddItem(item);
startIndex++;
}
//然后开始循环出堆,入堆
while (true)
{
var heapFirstItem = container.GetMinItem();
if (heapFirstItem == null)
{
break;
}
container.DeteleMinItem();
File.AppendAllText($@"D:\log\total.txt", JsonConvert.SerializeObject(heapFirstItem.Data) + "\r\n");
var nextContent = allReader[heapFirstItem.FileIndex].ReadLine();
if (string.IsNullOrWhiteSpace( nextContent))
{
//如果其中一个文件已经读取完毕 则跳过
continue;
}
var contentObj = JsonConvert.DeserializeObject<LogInfo>(nextContent);
LogInfoIndex item = new LogInfoIndex() { FileIndex = heapFirstItem.FileIndex, Data = contentObj };
container.AddItem(item);
}
//释放StreamReader
foreach (var reader in allReader)
{
reader.Dispose();
}
Console.WriteLine("完成");
Console.Read();
}
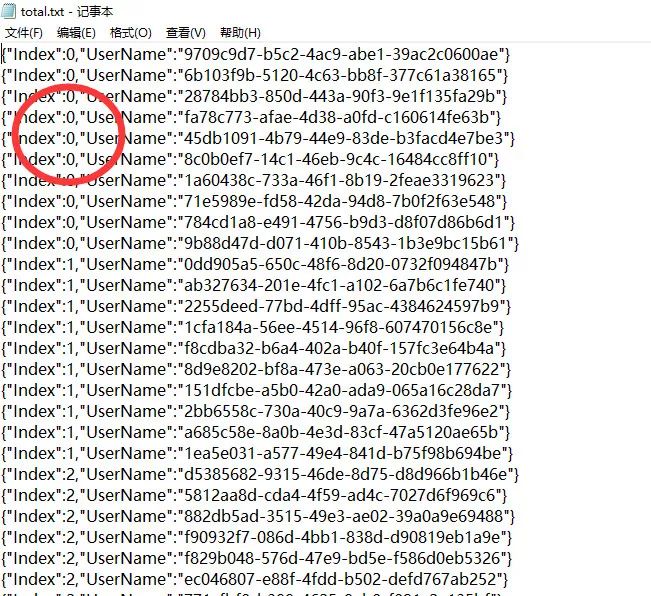
最终排序结果如下图:
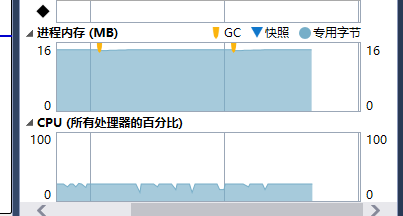
机器使用cpu内存完全没有达到所有排序文件的总大小:
程序员修仙之路--把用户访问记录优化到极致
菜菜呀,前几天做的用户空间,用户反映有时候比较慢呀
还记得菜菜不久之前设计的用户空间吗?没看过的同学请进传送门=》设计高性能访客记录系统
还记得遗留的什么问题吗?菜菜来重复一下,在用户访问记录的缓存中怎么来判断是否有当前用户的记录呢?链表虽然是我们这个业务场景最主要的数据结构,但并不是当前这个问题最好的解决方案,所以我们需要一种能快速访问元素的数据结构来解决这个问题?那就是今天我们要谈一谈的 散列表
散列表
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表
散列表其实可以约等于我们常说的Key-Value形式。散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。为什么要用数组呢?因为数组按照下标来访问元素的时间复杂度为O(1),不明白的同学可以参考菜菜以前的关于数组的文章。既然要按照数组的下标来访问元素,必然也必须考虑怎么样才能把Key转化为下标。这就是接下来要谈一谈的散列函数。
散列函数散列函数通俗来讲就是把一个Key转化为数组下标的黑盒。散列函数在散列表中起着非常关键的作用。散列函数,顾名思义,它是一个函数。我们可以把它定义成hash(key),其中 key 表示元素的键值,hash(key) 的值表示经过散列函数计算得到的散列值。
那一个散列函数有哪些要求呢?
1. 散列函数计算得到的值是一个非负整数值。
2. 如果 key1 = key2,那hash(key1) == hash(key2)
3. 如果 key1 ≠ key2,那hash(key1) ≠ hash(key2)
简单说一下以上三点,第一点:因为散列值其实就是数组的下标,所以必须是非负整数(>=0),第二点:同一个key计算的散列值必须相同。重点说一下第三点,其实第三点只是理论上的,我们想象着不同的Key得到的散列值应该不同,但是事实上,这一点很难做到。我们可以反证一下,如果这个公式成立,我计算无限个Key的散列值,那散列表底层的数组必须做到无限大才行。像业界比较著名的MD5、SHA等哈希算法,也无法完全避免这样的冲突。当然如果底层的数组越小,这种冲突的几率就越大。所以一个完美的散列函数其实是不存在的,即便存在,付出的时间成本,人力成本可能超乎想象。
散列冲突既然再好的散列函数都无法避免散列冲突,那我们就必须寻找其他途径来解决这个问题。
1. 寻址
如果遇到冲突的时候怎么办呢?方法之一是在冲突的位置开始找数组中空余的空间,找到空余的空间然后插入。就像你去商店买东西,发现东西卖光了,怎么办呢?找下一家有东西卖的商家买呗。不管采用哪种探测方法,当散列表中空闲位置不多的时候,散列冲突的概率就会大大提高。为了尽可能保证散列表的操作效率,一般情况下,我们会尽可能保证散列表中有一定比例的空闲槽位。我们用装载因子(load factor)来表示空位的多少。
散列表的装载因子 = 填入表中的元素个数 / 散列表的长度
装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降. 假设散列函数为 f=(key%1000),如下图所示

2. 链地址法(拉链法)
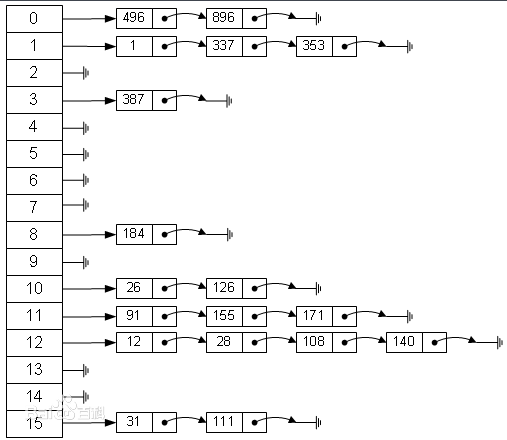
拉链法属于一种最常用的解决散列值冲突的方式。基本思想是数组的每个元素指向一个链表,当散列值冲突的时候,在链表的末尾增加新元素。查找的时候同理,根据散列值定位到数组位置之后,然后沿着链表查找元素。如果散列函数设计的非常糟糕的话,相同的散列值非常多的话,散列表元素的查找会退化成链表查找,时间复杂度退化成O(n)
3. 再散列法
这种方式本质上是计算多次散列值,那就必然需要多个散列函数,在产生冲突时再使用另一个散列函数计算散列值,直到冲突不再发生,这种方法不易产生“聚集”,但增加了计算时间。
4. 建立一个公共溢出区
至于这种方案网络上介绍的比较少,一般应用的也比较少。可以这样理解:散列值冲突的元素放到另外的容器中,当然容器的选择有可能是数组,有可能是链表甚至队列都可以。但是无论是什么,想要保证散列表的优点还是需要慎重考虑这个容器的选择。
扩展阅读
1. 这里需要在强调一次,散列表底层依赖的是数组按照下标访问的特性(时间复杂度为O(1)),而且一般散列表为了避免大量冲突都有装载因子的定义,这就涉及到了数组扩容的特性:需要为新数组开辟空间,并且需要把元素copy到新数组。如果我们知道数据的存储量或者数据的大概存储量,在初始化散列表的时候,可以尽量一次性分配足够大的空间。避免之后的数组扩容弊端。事实证明,在内存比较紧张的时候,优先考虑这种一次性分配的方案也要比其他方案好的多。
2. 散列表的寻址方案中,有一种特殊情况:如果我寻找到数组的末尾仍然无空闲位置,怎么办呢?这让我想到了循环链表,数组也一样,可以组装一个循环数组。末尾如果无空位,就可以继续在数组首位继续搜索。
3. 关于散列表元素的删除,我觉得有必要说一说。首先基于拉链方式的散列表由于元素在链表中,所有删除一个元素的时间复杂度和链表是一样的,后续的查找也没有任何问题。但是寻址方式的散列表就不同了,我们假设一下把位置N元素删除,那N之后相同散列值的元素就搜索不出来了,因为N位置已经是空位置了。散列表的搜索方式决定了空位置之后的元素就断片了....这也是为什么基于拉链方式的散列表更常用的原因之一吧。
4. 在工业级的散列函数中,元素的散列值做到尽量平均分布是其中的要求之一,这不仅仅是为了空间的充分利用,也是为了防止大量的hashCode落在同一个位置,设想在拉链方式的极端情况下,查找一个元素的时间复杂度退化成在链表中查找元素的时间复杂度O(n),这就导致了散列表最大特性的丢失。
5. 拉链方式实现的链表中,其实我更倾向于使用双向链表,这样在删除一个元素的时候,双向链表的优势可以同时发挥出来,这样可以把散列表删除元素的时间复杂度降低为O(1)。
6. 在散列表中,由于元素的位置是散列函数来决定的,所有遍历一个散列表的时候,元素的顺序并非是添加元素先后的顺序,这一点需要我们在具体业务应用中要注意。
Net Core c# 代码
有几个地方菜菜需要在强调一下:
1. 在当前项目中用的分布式框架为基于Actor模型的Orleans,所以我每个用户的访问记录不必担心多线程问题。
2. 我没用使用hashtable这个数据容器,是因为hashtable太容易发生装箱拆箱的问题。
3. 使用双向链表是因为查找到了当前元素,相当于也查找到了上个元素和下个元素,当前元素的删除操作时间复杂度可以为O(1)
class UserViewInfo
{
//用户ID
public int UserId { get; set; }
//访问时间,utc时间戳
public int Time { get; set; }
//用户姓名
public string UserName { get; set; }
}
class UserSpace
{
//缓存的最大数量
const int CacheLimit = 1000;
//这里用双向链表来缓存用户空间的访问记录
LinkedList<UserViewInfo> cacheUserViewInfo = new LinkedList<UserViewInfo>();
//这里用哈希表的变种Dictionary来存储访问记录,实现快速访问,同时设置容量大于缓存的数量限制,减小哈希冲突
Dictionary<int, UserViewInfo> dicUserView = new Dictionary<int, UserViewInfo>(1250);
//添加用户的访问记录
public void AddUserView(UserViewInfo uv)
{
//首先查找缓存列表中是否存在,利用hashtable来实现快速查找
if (dicUserView.TryGetValue(uv.UserId, out UserViewInfo currentUserView))
{
//如果存在,则把该用户访问记录从缓存当前位置移除,添加到头位置
cacheUserViewInfo.Remove(currentUserView);
cacheUserViewInfo.AddFirst(currentUserView);
}
else
{
//如果不存在,则添加到缓存头部 并添加到哈希表中
cacheUserViewInfo.AddFirst(uv);
dicUserView.Add(uv.UserId, uv);
}
//这里每次都判断一下缓存是否超过限制
if (cacheUserViewInfo.Count > CacheLimit)
{
//移除缓存最后一个元素,并从hashtable中删除,理论上来说,dictionary的内部会两个指针指向首元素和尾元素,所以查找这两个元素的时间复杂度为O(1)
var lastItem = cacheUserViewInfo.Last.Value;
dicUserView.Remove(lastItem.UserId);
cacheUserViewInfo.RemoveLast();
}
}
}
程序员修仙之路--设计一个实用的线程
菜菜呀,我最近研究技术呢,发现线上一个任务程序线程数有点多呀
◆◆原因排查◆◆
经过一个多小时的代码排查终于查明了线上程序线程数过多的原因:这是一个接收mq消息的一个服务,程序大体思路是这样的,监听的线程每次收到一条消息,就启动一个线程去执行,每次启动的线程都是新的。说到这里,咱们就谈一谈这个程序有哪些弊端呢:
1. 每次收到一条消息都创建一个新的线程,要知道线程的资源对于系统来说是很昂贵的,消息处理完成还要销毁这个线程。
2. 这个程序用到的线程数量是没有限制的。当线程到达一定数量,程序反而因线程在cpu切换开销的原因处理效率降低。无论的你的服务器cpu是多少核心,这个现象都有发生的可能。
◆◆解决问题◆◆
线程多的问题该怎么解决呢,增加cpu核心数?治标不治本。对于开发者而言,最为常用也最为有效的是线程池化,也就是说线程池。
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。 例如,线程数一般取cpu数量+2比较合适,线程数过多会导致额外的线程切换开销。
线程池其中一项很重要的技术点就是任务的队列,队列虽然属于一种基础的数据结构,但是发挥了举足轻重的作用。
◆◆队列◆◆
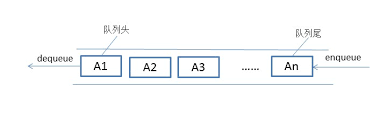
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
队列是一种采用的FIFO(first in first out)方式的线性表,也就是经常说的先进先出策略。
实现
数组
队列可以用数组Q[1…m]来存储,数组的上界m即是队列所容许的最大容量。在队列的运算中需设两个指针:head,队头指针,指向实际队头元素+1的位置;tail,队尾指针,指向实际队尾元素位置。一般情况下,两个指针的初值设为0,这时队列为空,没有元素。以下为一个简单的实例(生产环境需要优化):
public class QueueArray<T>
{
//队列元素的数组容器
T[] container = null;
int IndexHeader, IndexTail;
public QueueArray(int size)
{
container = new T[size];
IndexHeader = 0;
IndexTail = 0;
}
public void Enqueue(T item)
{
//入队的元素放在头指针的指向位置,然后头指针前移
container[IndexHeader] = item;
IndexHeader++;
}
public T Dequeue()
{
//出队:把尾元素指针指向的元素取出并清空(不清空也可以)对应的位置,尾指针前移
T item = container[IndexTail];
container[IndexTail] = default(T);
IndexTail++;
return item;
}
}
链表
队列采用的FIFO(first in first out),新元素总是被插入到链表的尾部,而读取的时候总是从链表的头部开始读取。每次读取一个元素,释放一个元素。所谓的动态创建,动态释放。因而也不存在溢出等问题。由于链表由元素连接而成,遍历也方便。以下是一个实例仅供参考:
public class QueueLinkList<T>
{
LinkedList<T> contianer = null;
public QueueLinkList()
{
contianer = new LinkedList<T>();
}
public void Enqueue(T item)
{
//入队的元素其实就是加入到队尾
contianer.AddLast(item);
}
public T Dequeue()
{
//出队:取链表第一个元素,然后把这个元素删除
T item = contianer.First.Value;
contianer.RemoveFirst();
return item;
}
}
队列的扩展阅读
1. 队列通过数组来实现的话有什么问题吗?是的。首先基于数组不可变本质的因素(具体可参考菜菜之前的文章),当一个队列的元素把数组沾满的时候,数组扩容是有性能问题的,数组的扩容过程不只是开辟新空间分配内存那么简单,还要有数组元素的copy过程,更可怕的是会给GC造成极大的压力。如果数组比较小可能影响比较小,但是当一个数组比较大的时候,比如占用500M内存的一个数组,数据copy其实会造成比较大的性能损失。
2. 队列通过数组来实现,随着头指针和尾指针的位置移动,尾指针最终会指向第一个元素的位置,也就是说没有元素可以出队了,其实要解决这个问题有两种方式,其一:在出队或者入队的过程中不断的移动所有元素的位置,避免上边所说的极端情况发生;其二:可以把数组的首尾元素连接起来,使其成为一个环状,也就是经常说的循环队列。
3. 队列在一些特殊场景下其实还有一些变种,比如说循环队列,阻塞队列,并发队列等,有兴趣的同学可以去研究一下,这里不在展开讨论。这里说到阻塞队列就多说一句,其实用阻塞队列可以实现一个最基本的生产者消费者模式。
4. 当队列用链表方式实现的时候,由于链表的首尾操作时间复杂度都是O(1),而且没有空间大小的限制,所以一般的队列用链表实现更简单
5. 当队列中无元素可出队或者没有空间可入队的时候,是阻塞当前的操作还是返回错误信息,取决于在座各位队列的设计者了。
◆◆简单实用的线程池◆◆
Net Core C# 版本
//线程池
public class ThreadPool
{
bool PoolEnable = false; //线程池是否可用
List<Thread> ThreadContainer = null; //线程的容器
ConcurrentQueue<ActionData> JobContainer = null; //任务的容器
public ThreadPool(int threadNumber)
{
PoolEnable = true;
ThreadContainer = new List<Thread>(threadNumber);
JobContainer = new ConcurrentQueue<ActionData>();
for (int i = 0; i < threadNumber; i++)
{
var t = new Thread(RunJob);
ThreadContainer.Add(t);
t.Start();
}
}
//向线程池添加一个任务
public void AddTask(Action<object> job,object obj, Action<Exception> errorCallBack=null)
{
if (JobContainer != null)
{
JobContainer.Enqueue(new ActionData { Job = job, Data = obj , ErrorCallBack= errorCallBack });
}
}
//终止线程池
public void FinalPool()
{
PoolEnable = false;
JobContainer = null;
if (ThreadContainer != null)
{
foreach (var t in ThreadContainer)
{
//强制线程退出并不好,会有异常
//t.Abort();
t.Join();
}
ThreadContainer = null;
}
}
private void RunJob()
{
while (true&& JobContainer!=null&& PoolEnable)
{
//任务列表取任务
ActionData job=null;
JobContainer?.TryDequeue(out job);
if (job == null)
{
//如果没有任务则休眠
Thread.Sleep(10);
continue;
}
try
{
//执行任务
job.Job.Invoke(job.Data);
}
catch(Exception error)
{
//异常回调
job?.ErrorCallBack(error);
}
}
}
}
public class ActionData
{
//执行任务的参数
public object Data { get; set; }
//执行的任务
public Action<object> Job { get; set; }
//发生异常时候的回调方法
public Action<Exception> ErrorCallBack { get; set; }
}
使用方法
ThreadPool pool = new ThreadPool(100);
for (int i = 0; i < 5000; i++)
{
pool.AddTask((obj) =>
{
Console.WriteLine($"{obj}__{System.Threading.Thread.CurrentThread.ManagedThreadId}");
}, i, (e) =>
{
Console.WriteLine(e.Message);
});
}
pool.FinalPool();
Console.Read();程序员修神之路--问世间异步为何物?
异步是怎么回事呢,能讲讲不?
◆异步定义◆◆
关于异步的定义,网上有很多不同的形式,但是归根结底中心思想是不变的。无论是在http请求调用的层面,还是在cpu内核态和用户态传输数据的层面,异步这个行为针对的是调用方:
一个可以无需等待被调用方的返回值就让操作继续进行的方法
在多数程序员的概念中一般是指线程处理的层面:
异步是计算机多线程的异步处理。与同步处理相对,异步处理不用阻塞当前线程来等待处理完成,而是允许后续操作,直至其它线程将处理完成,并回调通知此线程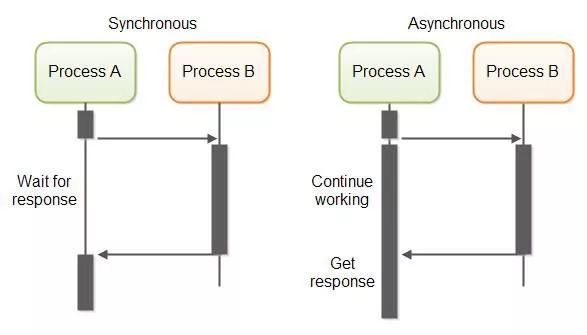
可以这样通俗的理解,异步主要解决的问题是不阻塞调用方,用方这里可以是http请求的发起者,也可以是一个线程。
但此处需要明确的是:异步与多线程与并行不是同一个概念。
◆◆CPU密集型操作◆◆
我听有的同学说,异步解决的是IO密集型的操作,菜菜觉得是不准确的。异步同样可以解决CPU密集型操作,只不过场景有限而已。有一个前提:利用异步解决CPU密集型操作要求当前运行环境支持多线程才行,比如javascript这个语言,本质上它的运行环境是单线程的,所以对于CPU密集型操作,javascript会显得力不从心。
异步解决CPU密集操作一般情况下发生在同进程中,为什么这么说呢,如果发生在不同机器或者不同进程在很多情况下已经属于IO密集型的范围了。这里顺便提醒一下:IO操作可不单单是指磁盘的操作,所有有输入/输出(Input/Output)操作的都可以泛称为IO。
举个栗子吧:
在一个带有UI的软件上点击一个按钮,UI线程会发生操作行为,假如UI线程在执行过程中有一个计算比较耗时的操作(你可以想象成计算1--999999999的和),UI线程在同步操作的情况下会一直等待计算结果,在计算完毕之后才会继续执行剩余操作,在等待的这个过程中,呈现给用户的情况就是UI卡住了,俗称假死了,带给用户的体验是非常不好的。这种情况下,我们可以新启动一个线程去执行这个耗时的操作,当执行完毕,利用某种通知机制来通知原来线程,以便原来线程继续自己的操作。
启动新线程执行CPU密集型操作利用的其实就是多线程的优势,如果是单核CPU,其实这种优势并不明显
◆◆IO密集型操作◆◆
异步的优势在IO密集型操作中表现的淋漓尽致,无论是读取一个文件还是发起一个网络请求,菜菜的建议是尽量使用异步。这里首先普及一个小知识:其实每个外设设备都有自己的处理器,比如磁盘,所以每个外设设备都可以处理自己相应的请求操作。但是处理外设设备信息的速度和cpu的执行速度来比较有着天壤之别。

上图展示了不同的 IO 操作所占用的 CPU 时钟周期,在计算机中,CPU 的运算速度最快,以其的运算速度为基准,时钟周期为1。其次是一级缓存、二级缓存和内存,硬盘和网络最慢,它们所花费的时钟周期和内存所花费的时钟周期差距在五位数以上,更不用提跟 CPU 和一级缓存、二级缓存的差距了。
由于速度的差距,所以几乎所有的IO操作都推荐使用异步。比如当读取磁盘一个文件的时候,同步状态下当前线程在等待读取的结果,这个线程闲置的时间几乎可以用蛋疼来形容。所以现代的几乎所有的知名第三方的操作都是异步操作,尤其以Redis,Nodejs 为代表的单线程运行环境令人刮目相看。
现在是微服务盛行的时代,UI往往一个简单的按钮操作,其实在后台程序可能调用了几个甚至更多的微服务接口(关于微服务这里不展开),如果程序是同步操作的话,那响应时间是这些服务接口响应时间的和,但是如果采用的是异步操作,调用方可以在瞬间把调用服务接口的操作发送出去,线程可以继续执行下边代码或者等待所有的服务接口返回值也可以。最差的情况下,接口的响应时间为最慢的那个服务接口响应时间,这有点类似于木桶效应。
◆◆异步的回调◆◆
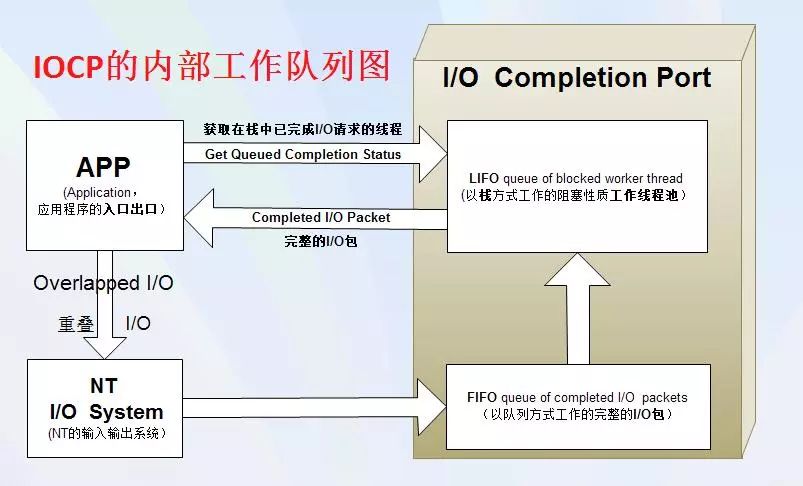
通过以上介绍,我们一定要记住一个知识点:异步需要回调机制。异步操作之所以能在执行结果完成之后继续执行下面程序完全归功于回调,这也是所有异步场景的核心所在,前到js的异步回调,后到cpu内核空间copy数据到用户空间完成通知 等等异步场景,回调无处不在。说道回调大部分语言都是注册一个回调函数,比如js会把回调的方法注册到执行的队列,c#会把回调注册到IOCP。这里延伸一下,在很多系统里,很多IO网络模型其实是属于同步范畴的,比如多路复用技术,真正异步非阻塞的推荐windows下的IOCP。
现在很多现代语言都支持更优秀的回调方式,比如js和c# 现在都支持async 和await方式来进行异步操作。
据说windows下的IOCP才是真正的异步非阻塞模型,求留言区验证!
◆◆异步的特点◆◆
优势
1异步操作无须额外的线程负担,使用回调的方式进行后续处理,在设计良好的情况下,处理函数可以不必使用共享变量(即使无法完全不用,最起码可以减少 共享变量的数量),减少了死锁的可能。2线程数量的减少,减少了线程上下文在cpu切换的开销。
3微服务环境(调用多个服务接口的情况下)加快了上层接口的响应时间,意味着增加了上层接口的吞吐量
劣势
1异步操作传统的做法都是通过回调函数来实现,与同步的思维有些差异,而且难以调试2如果当前环境有操作顺序的要求,异步操作为了保证执行的顺序需要做额外的工作3由于多数情况下异步的回调过程中的执行线程并非原来的线程,所以在捕获异常,上下文传递等方面需要做特殊处理,特别是不同线程共享代码或共享数据时容易出问题。写在最后1在并发量较小的情况下,阻塞式 IO和异步IO的差距可能不是那么明显,但随着并发量的增加,异步IO的优势将会越来越大,吞吐率和性能上的差距也会越来越明显。
2在压力比较小的情况下,一般异步请求的响应时间大于同步请求的响应时间,因为异步的回调也是需要时间的3在大并发的情况下,采用异步调用的程序所用线程数要远远小于同步调用程序所用的线程数,cpu使用率也一样(因为避免了太多线程上下文切换的成本)
为了系统性能,不要让任何设备停下来休息
程序员修神之路--提高网站的吞吐量
百科
吞吐量是指对网络、设备、端口、虚电路或其他设施,单位时间内成功地传送数据的数量(以比特、字节、分组等测量)。
以上的定义比较宽泛,定义到网站或者接口的吞吐量是这样的:吞吐量是指系统在单位时间内处理请求的数量。这里有一个注意点就是单位时间内,对于网站的吞吐量这个单位时间一般定义为1秒,也就是说网站在一秒之内能处理多少http(https/tcp)请求。与吞吐量对应的衡量网站性能的还有响应时间、并发数、QPS每秒查询率。
响应时间是一个系统最重要的指标之一,它的数值大小直接反应了系统的快慢。响应时间是指执行一个请求从开始到最后收到响应数据所花费的总体时间。
并发数是指系统同时能处理的请求数量,这个也是反应了系统的负载能力。
每秒查询率(QPS)是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
我们以高速收费站为例子也许更直观一些,吞吐量就是一天之内通过的车辆数,响应时间就是车速,并发数就是高速上同时奔跑的汽车数。由此可见其实以上几个指标是有内在联系的。比如:响应时间缩短,在一定程度上可以提高吞吐量。
其实以上几个指标主要反映了两个概念:
1. 系统在单位时间之内能做多少事情
2. 系统做一件事情需要的时间
提高吞吐量以下场景都是在假设程序不发生异常的情况下服务器(进程)级别
服务器级别增加网站吞吐量也是诸多措施中最容易并且是效果最好的,如果一个网站能通过增加少量的服务器来提高吞吐量,菜菜觉得是应该优先采用的。毕竟一台服务器的费用相比较一个程序员费用来说要低的多。但是有一个前提,就是你的服务器是系统的瓶颈,网站系统之后的其他系统并非瓶颈。如果你的系统的瓶颈在DB或者其他服务,盲目的增加服务器并不能解决你的问题。
通过增加服务器来解决你的网站瓶颈,意味着你的网站需要做负载均衡,如果没有运维相关人员,你可能还得需要研究负载均衡的方案,比如LVS,Nginx,F5等。我曾经面试过很多入道不久的同学,就提高吞吐量问题,如果没有回答上用负载均衡方案的基本都pass了,不要说别的,这个方案就是一个基础,就好比学习一个语言,你连最基本的语法都不会,我凭什么让你通过。有喷的同学可以留言哦
其实现在很多静态文件采用CDN,本质上也可以认为是增加服务器的策略
线程级别
当一个请求到达服务器并且正确的被服务器接收之后,最终执行这个请求的载体是一个线程。当一个线程被cpu载入执行其指令的时候,在同步的状态下,当前线程会阻塞在那里等待cpu结果,如果cpu执行的是比较慢的IO操作,线程会一直被阻塞闲置很长时间,这里的很长是对比cpu的速度而言,如果你想有一个直观的速度对比,可以去查看菜菜以前的文章:
当一个新的请求到来的时候,如果没有新的线程去领取这个任务并执行,要么会发生异常,要么创建新的线程。线程是一种很稀缺的资源,不可能无限制的创建。这种情况下我们就要把线程这种资源充分利用起来,不要让线程停下来。这也是程序推荐采用异步的原因,试想,一个线程不停的在工作,遇到比较慢的IO不会去等待结果,而是接着处理下一个请求,当IO的结果返回来得到通知的时候,线程再去取IO结果,岂不是能在相同时间内处理更多的请求。
程序异步化(非阻塞)会明显提高系统的吞吐量,但是响应时间可能会稍微变大
还有一点,尽量减少线程上下文在cpu的切换,因为线程上线文切换的成本也是比较大的,在线程切换的时候,cpu需要把当前线程的上下文信息记录下来用以下次调用的时候使用,然后把新线程的上下文信息载入然后执行。这个过程相对于cpu的执行速度而言,要慢很多。
不要拿Golang反驳以上观点,golang的协程虽然是用户级别比线程更小的载体,但是最终和Cpu进行交互的还是线程。
Cpu级别
在讲cpu级别之前,如果有一定的网络模型的基础,也许会好一些。这里大体阐述一下,现代操作系统都采用虚拟寻址的方式,它的寻址空间(虚拟存储空间)为4G(2的32次方)。操作系统将虚拟空间分为两类:内核空间和用户空间。内核空间独立于用户空间,有访问受保护的内存空间、IO设备的权限(所有的用户空间共享)。用户空间就是我们的应用程序运行的空间,其实用户空间并没有操作各种IO设备的权限,像我们平时读取一个文件,本质上是委托内核空间去执行读取指令的,内核空间读取到数据之后再把数据复制到程序运行的空间,最后应用程序再把数据返回调用方。
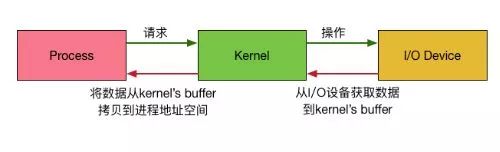
通过上图大体可以看出,内核会为每个I/O设备维护一个buffer(同一个文件描述符读和写的buffer不同),应用程序发出一个IO操作的指令其实通过了内核空间和用户空间两个部分,并且发生了数据的复制操作。这个过程其实主要包含两个步骤:
1. 用户进程发出操作指令并等待数据
2. 内核把数据返回给用户进程(buffer的复制操作)
根据这两个操作的不同表现,所以IO模型有了同步阻塞,同步非阻塞,异步阻塞,异步非阻塞的概念,但是这里并非此文的重点,所以不在展开详细介绍。
利用cpu提高系统吞吐量主要目标是提高单位时间内cpu运行的指令数,避免cpu做一些无用功:
cpu负责把buffer的数据copy到应用程序空间,应用程序再把数据返回给调用方,假如这个过程发生的是一次Socket操作,应用程序在得到IO返回数据之后,还需要网卡把数据返回给client端,这个过程又需要把刚刚得到的buffer数据再次通过内核发送至网卡,通过网络传送出去。由此可见cpu把buffer数据copy到应用程序空间这个过程完全没有必要,在内核空间完全可以把buffer数据直接传输至网卡,这也是零拷贝技术要解决的问题。具体的零拷贝技术在这里不再展开。
不要让任何设备停下来,不要让任何设备做无用功
通过增加cpu的个数来增加吞吐量网络传输级别
至于网络传输级别,由于协议大部分是Tcp/ip,所以在协议传输方面优化的手段比较少,但是应用程序级别协议可以选择压缩率更好的,比如采用grpc会比单纯的http协议要好很多,http2 要比http 1.1要好很多。另外一方面网卡尽量加大传输速率,比如千兆网卡要比百兆网卡速度更快。由于网络传输比较偏底层,所以人工干预的切入点会少很多。
最后总结
大部分程序员都是工作在应用层,针对应用级别代码能提高吞吐量的建议:
1加大应用的进程数,增加并发数,特别在进程数是瓶颈的情况下2优化线程调用,尽量池化。
3应用的代码异步化,特别是异步非阻塞式编程对于提高吞吐量效果特别明显
4充分利用多核cpu优势,实现并行编程。
5减少每个调用的响应时间,缩短调用链。例如通过加索引的方式来减少访问一次数据库的时间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号