
内存映射
man pidstat
pidstat -r
linux操作系统:内核态内存映射
内核态的内存映射机制,主要包含如下几个部分:
- 内核态内存映射函数vmalloc、kmap_atomic是如何工作的
- 内核态页表是放在哪里的,如何工作的?swapper_pg_dir 是怎么回事;
- 出现内核态缺页异常该怎么办?
内核页表
和用户态页表不同,在系统初始化的时候,我们就要创建内核页表了。
我们从内核页表的根swapper_pg_dir开始找线索,在arch/x86/include/asm/pgtable_64.h就能找到它的定义。
extern pud_t level3_kernel_pgt[512];
extern pud_t level3_ident_pgt[512];
extern pmd_t level2_kernel_pgt[512];
extern pmd_t level2_fixmap_pgt[512];
extern pmd_t level2_ident_pgt[512];
extern pte_t level1_fixmap_pgt[512];
extern pgd_t init_top_pgt[];
#define swapper_pg_dir init_top_pgt
swapper_pg_dir指向内核最顶级的目录pgd,同时出现的还有几个页表目录。64 位系统的虚拟地址空间的布局中, XXX_ident_pgt 对应的是直接映射区,XXX_kernel_pgt 对应的是内核代码区,XXX_fixmap_pgt 对应的是固定映射区。
它们是在哪里初始化的呢?在汇编语言的文件里面的 arch\x86\kernel\head_64.S。这段代码比较难看懂,你只要明白它是干什么的就行了。
__INITDATA
NEXT_PAGE(init_top_pgt)
.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.org init_top_pgt + PGD_PAGE_OFFSET*8, 0
.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.org init_top_pgt + PGD_START_KERNEL*8, 0
/* (2^48-(2*1024*1024*1024))/(2^39) = 511 */
.quad level3_kernel_pgt - __START_KERNEL_map + _PAGE_TABLE
NEXT_PAGE(level3_ident_pgt)
.quad level2_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.fill 511, 8, 0
NEXT_PAGE(level2_ident_pgt)
/* Since I easily can, map the first 1G.
* Don't set NX because code runs from these pages.
*/
PMDS(0, __PAGE_KERNEL_IDENT_LARGE_EXEC, PTRS_PER_PMD)
NEXT_PAGE(level3_kernel_pgt)
.fill L3_START_KERNEL,8,0
/* (2^48-(2*1024*1024*1024)-((2^39)*511))/(2^30) = 510 */
.quad level2_kernel_pgt - __START_KERNEL_map + _KERNPG_TABLE
.quad level2_fixmap_pgt - __START_KERNEL_map + _PAGE_TABLE
NEXT_PAGE(level2_kernel_pgt)
/*
* 512 MB kernel mapping. We spend a full page on this pagetable
* anyway.
*
* The kernel code+data+bss must not be bigger than that.
*
* (NOTE: at +512MB starts the module area, see MODULES_VADDR.
* If you want to increase this then increase MODULES_VADDR
* too.)
*/
PMDS(0, __PAGE_KERNEL_LARGE_EXEC,
KERNEL_IMAGE_SIZE/PMD_SIZE)
NEXT_PAGE(level2_fixmap_pgt)
.fill 506,8,0
.quad level1_fixmap_pgt - __START_KERNEL_map + _PAGE_TABLE
/* 8MB reserved for vsyscalls + a 2MB hole = 4 + 1 entries */
.fill 5,8,0
NEXT_PAGE(level1_fixmap_pgt)
.fill 51
内核页表的顶级目录init_top_pgt,定义在__INITDATA里面。这个区域叫做.init区域,里面存放这代码段以及一些初始化了的全局变量。可以看到,页表的跟其实就是全局变量,这就是使得我们初始化的时候,甚至内存管理还没有初始化的时候,很容易就可以定位到。
接下来,定义 init_top_pgt 包含哪些项,这个汇编代码比较难懂了。你可以简单地认为,quad 是声明了一项的内容,org 是跳到了某个位置。
所以,init_top_pgt 有三项,上来先有一项,指向的是 level3_ident_pgt,也即直接映射区页表的三级目录。为什么要减去 __START_KERNEL_map 呢?因为 level3_ident_pgt 是定义在内核代码里的,写代码的时候,写的都是虚拟地址,谁写代码的时候也不知道将来加载的物理地址是多少呀,对不对?
因为 level3_ident_pgt 是在虚拟地址的内核代码段里的,而 __START_KERNEL_map 正是虚拟地址空间的内核代码段的起始地址。这样,level3_ident_pgt 减去 __START_KERNEL_map 才是物理地址。
第一项定义完了以后,接下来我们跳到 PGD_PAGE_OFFSET 的位置,再定义一项。从定义可以看出,这一项就应该是 __PAGE_OFFSET_BASE 对应的。__PAGE_OFFSET_BASE 是虚拟地址空间里面内核的起始地址。第二项也指向 level3_ident_pgt,直接映射区。
PGD_PAGE_OFFSET = pgd_index(__PAGE_OFFSET_BASE)
PGD_START_KERNEL = pgd_index(__START_KERNEL_map)
L3_START_KERNEL = pud_index(__START_KERNEL_map)
第二项定义完了以后,接下来跳到 PGD_START_KERNEL 的位置,再定义一项。从定义可以看出,这一项应该是 __START_KERNEL_map 对应的项,__START_KERNEL_map 是虚拟地址空间里面内核代码段的起始地址。第三项指向 level3_kernel_pgt,内核代码区。
接下来的代码就很类似了,就是初始化个表项,然后指向下一级目录,最终形成下面这张图。
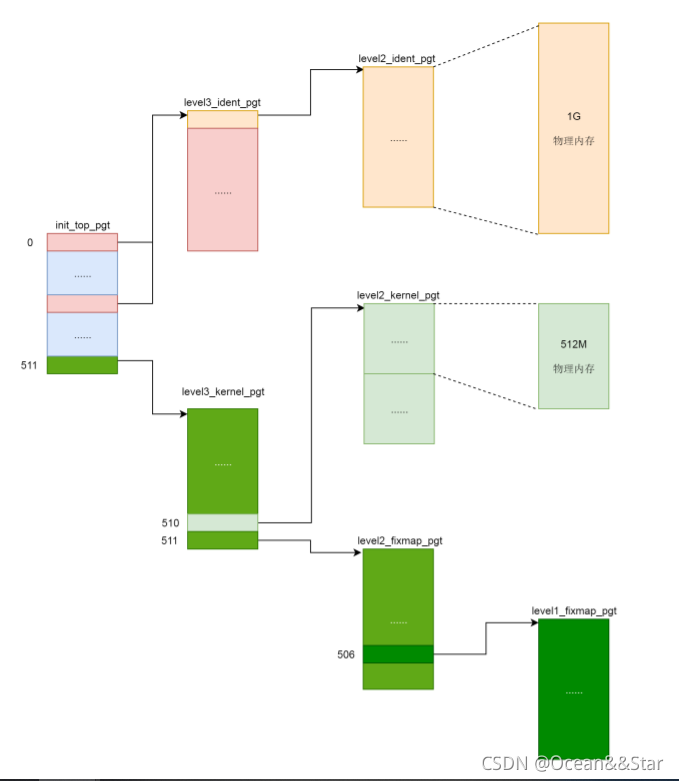
内核页表定义完了,一开始这里面的页表能够覆盖的内存范围比较小。比如,内核代码区512M,直接映射1G。这个时候,其实只要能够映射基本的内核代码和数据结构就可以了。可以看出,里面还空着很多项,可以用与将来映射巨大的内核虚拟地址空,等用到的时候再进行映射。
如果是用户态进程页表,会有 mm_struct 指向进程顶级目录 pgd,对于内核来讲,也定义了一个 mm_struct,指向 swapper_pg_dir。
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};
定义完了内核页表,接下来是初始化内核页表,在系统启动的时候 start_kernel 会调用 setup_arch。
void __init setup_arch(char **cmdline_p)
{
/*
* copy kernel address range established so far and switch
* to the proper swapper page table
*/
clone_pgd_range(swapper_pg_dir + KERNEL_PGD_BOUNDARY,
initial_page_table + KERNEL_PGD_BOUNDARY,
KERNEL_PGD_PTRS);
load_cr3(swapper_pg_dir);
__flush_tlb_all();
......
init_mm.start_code = (unsigned long) _text;
init_mm.end_code = (unsigned long) _etext;
init_mm.end_data = (unsigned long) _edata;
init_mm.brk = _brk_end;
......
init_mem_mapping();
......
}
在 setup_arch 中,load_cr3(swapper_pg_dir)说明内核页表要开始其中了,并且刷新了TLB,初始化init_mm的成员变量,最重要的就是init_mem_mapping。最终它会调用kernel_physical_mapping_init。
/*
* Create page table mapping for the physical memory for specific physical
* addresses. The virtual and physical addresses have to be aligned on PMD level
* down. It returns the last physical address mapped.
*/
unsigned long __meminit
kernel_physical_mapping_init(unsigned long paddr_start,
unsigned long paddr_end,
unsigned long page_size_mask)
{
unsigned long vaddr, vaddr_start, vaddr_end, vaddr_next, paddr_last;
paddr_last = paddr_end;
vaddr = (unsigned long)__va(paddr_start);
vaddr_end = (unsigned long)__va(paddr_end);
vaddr_start = vaddr;
for (; vaddr < vaddr_end; vaddr = vaddr_next) {
pgd_t *pgd = pgd_offset_k(vaddr);
p4d_t *p4d;
vaddr_next = (vaddr & PGDIR_MASK) + PGDIR_SIZE;
if (pgd_val(*pgd)) {
p4d = (p4d_t *)pgd_page_vaddr(*pgd);
paddr_last = phys_p4d_init(p4d, __pa(vaddr),
__pa(vaddr_end),
page_size_mask);
continue;
}
p4d = alloc_low_page();
paddr_last = phys_p4d_init(p4d, __pa(vaddr), __pa(vaddr_end),
page_size_mask);
p4d_populate(&init_mm, p4d_offset(pgd, vaddr), (pud_t *) p4d);
}
__flush_tlb_all();
return paddr_l
在kernel_physical_mapping_init 里,我们先通过__va将物理地址转换为虚拟地址,然后在创建虚拟地址和物理地址的映射页表。
问题是,既然对于内核来讲,我们可以用_va和_pa直接在虚拟地址和物理地址之间直接转来转去,为什么还要建立页表呢?因为这是CPU和内存的硬件的需求,也就是四,CPU在保护模式下访问虚拟地址的时候,就会用CR3这个寄存器,这个寄存器是CPU定义的,作为操作系统,我们是软件,只能按照硬件的要求来。
可以按照咱们将初始化的时候的过程,系统早早就进入了保护模式,到了 setup_arch 里面才 load_cr3,如果使用 cr3 是硬件的要求,那之前是怎么办的呢?如果你仔细去看 arch\x86\kernel\head_64.S,这里面除了初始化内核页表之外,在这之前,还有另一个页表 early_top_pgt。看到关键字 early 了嘛?这个页表就是专门用在真正的内核页表初始化之前,为了遵循硬件的要求而设置的。
vmalloc 和 kmap_atomic 原理
在用户态可以通过malloc函数分配内存,当然malloc在分配比较大的内存的时候,底层调用的是mmap,当然也可以直接通过mmap做内存映射,在内核里面也有响应的函数。
在虚拟地址空间里面,有个vmalloc区域,从VMALLOC_START 开始到 VMALLOC_END,可以用于映射一段物理内存
/**
* vmalloc - allocate virtually contiguous memory
* @size: allocation size
* Allocate enough pages to cover @size from the page level
* allocator and map them into contiguous kernel virtual space.
*
* For tight control over page level allocator and protection flags
* use __vmalloc() instead.
*/
void *vmalloc(unsigned long size)
{
return __vmalloc_node_flags(size, NUMA_NO_NODE,
GFP_KERNEL);
}
static void *__vmalloc_node(unsigned long size, unsigned long align,
gfp_t gfp_mask, pgprot_t prot,
int node, const void *caller)
{
return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END,
gfp_mask, prot, 0, node, caller);
}
我们再来看内核的临时映射函数 kmap_atomic 的实现。从下面的代码我们可以看出,如果是 32 位有高端地址的,就需要调用 set_pte 通过内核页表进行临时映射;如果是 64 位没有高端地址的,就调用 page_address,里面会调用 lowmem_page_address。其实低端内存的映射,会直接使用 __va 进行临时映射。
void *kmap_atomic_prot(struct page *page, pgprot_t prot)
{
......
if (!PageHighMem(page))
return page_address(page);
......
vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
set_pte(kmap_pte-idx, mk_pte(page, prot));
......
return (void *)vaddr;
}
void *kmap_atomic(struct page *page)
{
return kmap_atomic_prot(page, kmap_prot);
}
static __always_inline void *lowmem_page_address(const struct page *page)
{
return page_to_virt(page);
}
#define page_to_virt(x) __va(PFN_PHYS(page_to_pfn(x)
内核态缺页异常
可以看出,kmap_atomic和vmalloc不同。kmap_atomic发现,没有页表的时候,就直接创建页表进行映射了。而vmalloc没有,它只分配了内核的虚拟地址。所以,访问它的时候,会产生缺页异常。
内核态的缺页异常还是会调用 do_page_fault,然后走vmalloc_fault。这个函数并不复杂,主要用于关联内核页表项。
/*
* 32-bit:
*
* Handle a fault on the vmalloc or module mapping area
*/
static noinline int vmalloc_fault(unsigned long address)
{
unsigned long pgd_paddr;
pmd_t *pmd_k;
pte_t *pte_k;
/* Make sure we are in vmalloc area: */
if (!(address >= VMALLOC_START && address < VMALLOC_END))
return -1;
/*
* Synchronize this task's top level page-table
* with the 'reference' page table.
*
* Do _not_ use "current" here. We might be inside
* an interrupt in the middle of a task switch..
*/
pgd_paddr = read_cr3_pa();
pmd_k = vmalloc_sync_one(__va(pgd_paddr), address);
if (!pmd_k)
return -1;
pte_k = pte_offset_kernel(pmd_k, address);
if (!pte_present(*pte_k))
return -1;
return 0
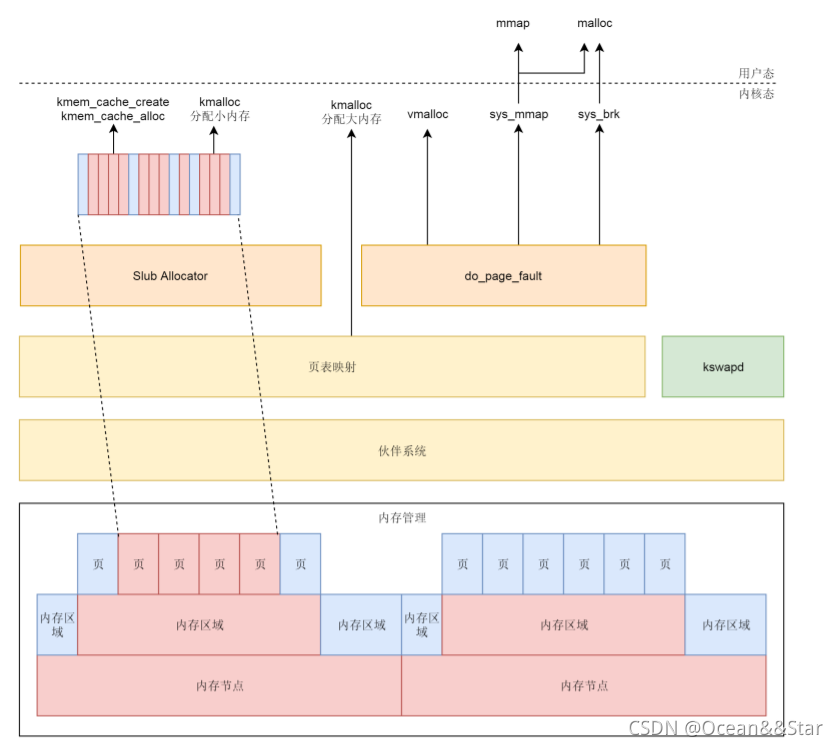
总结
整个内存管理的体系:
- 物理内存根据NUMA架构分节点,每个节点里面再分区域。每个区域里面再分页
- 物理页面通过伙伴系统进行分配。分配的物理页面要变成虚拟地址让上次可以访问,kswapd可以根据物理页面的使用情况对页面进行换入换出
- 对于内存的分配需求,可能是来自内核态,也可能是来自用户态
- 对于内核态,kmalloc 在分配大内存的时候,以及 vmalloc 分配不连续物理页的时候,直接使用伙伴系统,分配后转换为虚拟地址,访问的时候需要通过内核页表进行映射。
- 对于 kmem_cache 以及 kmalloc 分配小内存,则使用 slub 分配器,将伙伴系统分配出来的大块内存切成一小块一小块进行分配。
- kmem_cache 和 kmalloc 的部分不会被换出,因为用这两个函数分配的内存多用于保持内核关键的数据结构。内核态中 vmalloc 分配的部分会被换出,因而当访问的时候,发现不在,就会调用 do_page_fault。
- 对于用户态的内存分配,或者直接调用 mmap 系统调用分配,或者调用 malloc。调用 malloc 的时候,如果分配小的内存,就用 sys_brk 系统调用;如果分配大的内存,还是用 sys_mmap 系统调用。正常情况下,用户态的内存都是可以换出的,因而一旦发现内存中不存在,就会调用 do_page_fault。
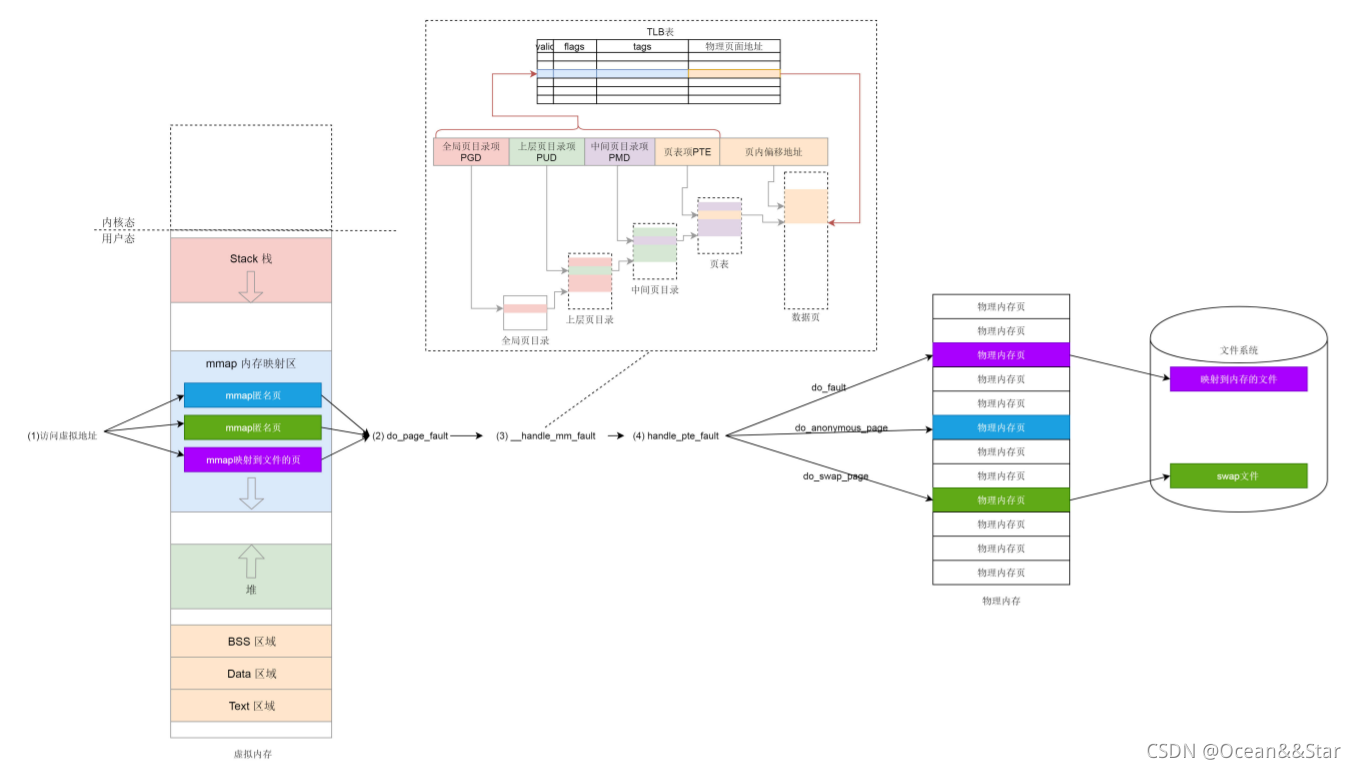
linux操作系统:用户态内存映射
前面几节,我们知道了虚拟内存空间是如何组织的,也看了物理页面如何管理的。限制我们需要一些数据结构,将二者管理起来
mmap原理
每一个进程都有一个列表vm_area_struct,指向虚拟地址空间的不同的内存块,这个编码的名字叫做mmap
struct mm_struct {
struct vm_area_struct *mmap; /* list of VMAs */
......
}
struct vm_area_struct {
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree.
*/
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
其实内存映射不仅仅是物理内存和虚拟内存之间的映射,还包含将文件中的内容映射到虚拟内存空间。这个时候,访问内存空间就能够访问到文件里面的数据。而仅有物理内存和虚拟内存的映射,是一种特殊情况。
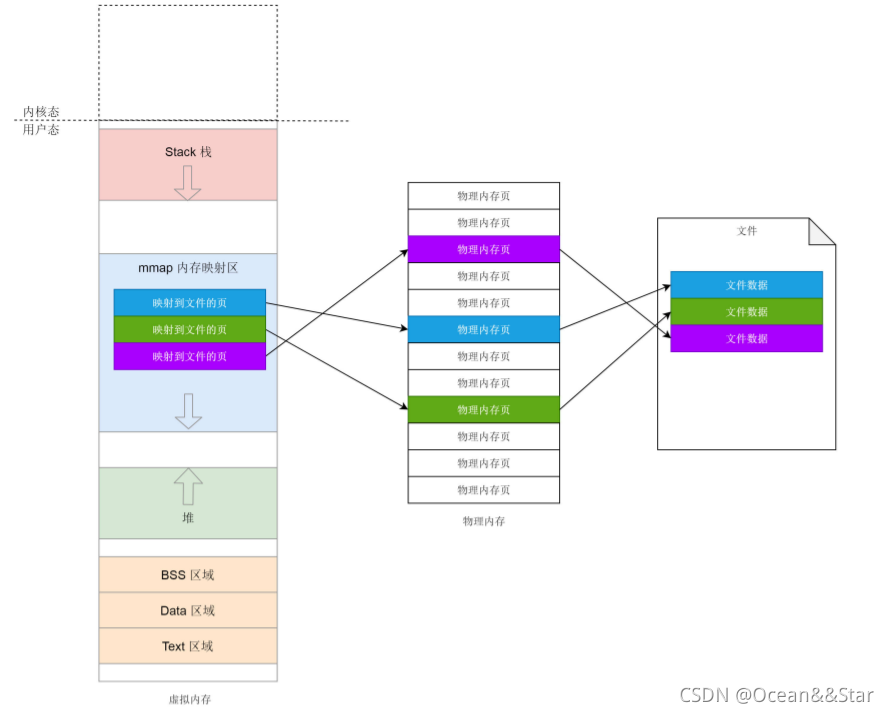
- 如果我们要申请小块堆内存,就用brk。
- 如果我们要申请大块堆内存,就用mmap。这里的mmap就是映射内存空间到物理内存
- 如果一个进程想映射一个文件到自己的虚拟内存空间,也有用mmap系统调用。这个时候mmap是映射内存空间到物理内存再到文件。
mmap系统调用做了什么?
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off)
{
......
error = sys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT);
......
}
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
struct file *file = NULL;
......
file = fget(fd);
......
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
return retval;
}
如果要映射到文件,fd就会传过来一个文件描述符,并且mmap_pgoff里面通过fget函数,根据文件描述符好的struct file。struct file表示打开的一个文件。
接下来的调用链是vm_mmap_pgoff->do_mmap_pgoff->do_mmap。这里面主要干了两件事情:
- 调用get_unmapped_area 找到一个没有映射的区域
- 调用mmap_region映射这个区域
我们来看看get_unmapped_area 函数
unsigned long
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
{
unsigned long (*get_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
......
get_area = current->mm->get_unmapped_area;
if (file) {
if (file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
}
......
}
- 这里面如果是匿名映射,则调用mm_struct 里面的get_unmapped_area 函数。这个函数其实是arch_get_unmapped_area。它会调用find_vma_prev,在表示虚拟内存区域的vm_area_struct 红黑树上找到相应的位置。之所以叫做prev,是说这个时候虚拟内存区域还没有建立,找到前一个vm_area_struct
- 如果不是匿名映射,而是映射到一个文件,这样在Linux里面,每个打开的文件都有一个struct file结构,里面有一个file_operations,用来表示和这个文件相关的操作。如果是我们熟知的ext4文件系统,调用的是 thp_get_unmapped_area。如果我们仔细看这个函数,最终还是调用 mm_struct 里面的 get_unmapped_area 函数。殊途同归。
const struct file_operations ext4_file_operations = {
......
.mmap = ext4_file_mmap
.get_unmapped_area = thp_get_unmapped_area,
};
unsigned long __thp_get_unmapped_area(struct file *filp, unsigned long len,
loff_t off, unsigned long flags, unsigned long size)
{
unsigned long addr;
loff_t off_end = off + len;
loff_t off_align = round_up(off, size);
unsigned long len_pad;
len_pad = len + size;
......
addr = current->mm->get_unmapped_area(filp, 0, len_pad,
off >> PAGE_SHIFT, flags);
addr += (off - addr) & (size - 1);
return addr;
}
我们再来看mmap_region,看它如何映射这个虚拟内存区域:
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
struct rb_node **rb_link, *rb_parent;
/*
* Can we just expand an old mapping?
*/
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
INIT_LIST_HEAD(&vma->anon_vma_chain);
if (file) {
vma->vm_file = get_file(file);
error = call_mmap(file, vma);
addr = vma->vm_start;
vm_flags = vma->vm_flags;
}
......
vma_link(mm, vma, prev, rb_link, rb_parent);
return addr;
.....
- 还记得我们刚找到了虚拟内存区域的前一个vm_area_struct,我们首先要看,是否能够基于它进程扩展,也就是调用vma_merge,和前一个vm_area_struct合并到一起。
- 如果不能,就需要调用kmem_cache_zalloc,在Slub里面创建一个新的vm_area_struct对象,设置起始和结束位置,将它加入队列。
- 如果是映射到文件,则设置vm_flie为目标文件,调用call_mmap。其实就是调用file_operatiions的mmap函数。对于ext4文件系统,调用的是ext4_file_mmap。从政函数的参数可以看出,这一刻文件和内存开始发生关系了。这里我们将vm_area_struct 的内存操作设置为文件系统操作,也就是说,读写内存就是读写文件系统
static inline int call_mmap(struct file *file, struct vm_area_struct *vma)
{
return file->f_op->mmap(file, vma);
}
static int ext4_file_mmap(struct file *file, struct vm_area_struct *vma)
{
......
vma->vm_ops = &ext4_file_vm_ops;
......
}
- 我们再回到mmap_region函数。最终,vma_link函数将新创建的vm_area_struct挂在了mm_struct里面的红黑树上
这个时候,从内存到文件的映射关系,至少要在逻辑层面上建立起来。那从文件到内存的映射关系呢?vma_link还做了另外一件事情,就是__vma_link_file。这个东西要用户建立这层映射关系。
对于打开的文件,会有一个结构 struct file 来表示。它有个成员指向 struct address_space 结构,这里面有棵变量名为 i_mmap 的红黑树,vm_area_struct 就挂在这棵树上。
struct address_space {
struct inode *host; /* owner: inode, block_device */
......
struct rb_root i_mmap; /* tree of private and shared mappings */
......
const struct address_space_operations *a_ops; /* methods */
......
}
static void __vma_link_file(struct vm_area_struct *vma)
{
struct file *file;
file = vma->vm_file;
if (file) {
struct address_space *mapping = file->f_mapping;
vma_interval_tree_insert(vma, &mapping->i_mmap);
}
到这里,内存映射的内容就要告一段落了。可是现在还没有和物理内存发生任何关系,还是在虚拟内存里面折腾啊?
对的,因为到目前为止,我们还没有开始真正的访问内存。这个时候,内存管理并不直接分配物理内存,因为物理内存相对于虚拟地址空间太宝贵了,只有等到真正用的那一刻才会开始分配
用户态缺页异常
一旦开始访问虚拟内存的某个地址,如果发现,并没有对应的物理页,就会触发缺页中断,调用do_page_fault
dotraplinkage void notrace
do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
unsigned long address = read_cr2(); /* Get the faulting address */
......
__do_page_fault(regs, error_code, address);
......
}
/*
* This routine handles page faults. It determines the address,
* and the problem, and then passes it off to one of the appropriate
* routines.
*/
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address)
{
struct vm_area_struct *vma;
struct task_struct *tsk;
struct mm_struct *mm;
tsk = current;
mm = tsk->mm;
if (unlikely(fault_in_kernel_space(address))) {
if (vmalloc_fault(address) >= 0)
return;
}
......
vma = find_vma(mm, address);
......
fault = handle_mm_fault(vma, address, flags);
......
- 在__do_page_fault里面,先要判断缺页中断是否发生在内核。
- 如果发生在内核则调用vmalloc_fault,在内核里面,vmalloc区域需要内核页表映射到物理页
- 如果发生在用户空间里面,找到你访问的那个地址所在的区域vm_area_struct,然后调用handle_mm_fault来映射这个区域
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
int ret;
pgd = pgd_offset(mm, address);
p4d = p4d_alloc(mm, pgd, address);
......
vmf.pud = pud_alloc(mm, p4d, address);
......
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
......
return handle_pte_fault(&vmf);
}
到这里,我们看到了熟悉的PGD、P4G、PUD、PMD、PTE,这就是页表中四级页表的概念(因为暂且不考虑五级页表,我们暂时忽略 P4G。)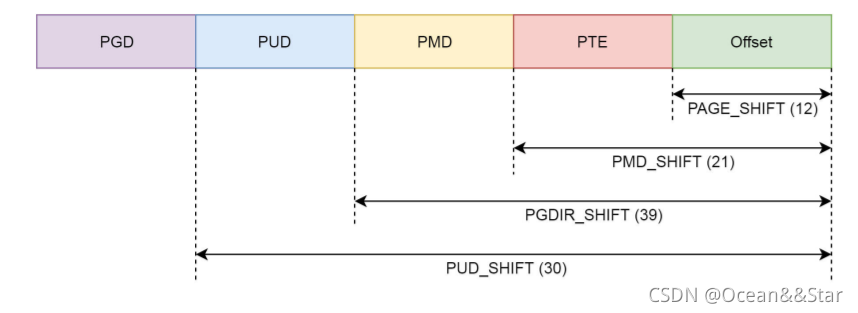
pgd_t 用于全局页目录项,pud_t 用于上层页目录项,pmd_t 用于中间页目录项,pte_t 用于直接页表项。
每个进程都有独立的地址空间,为了这个进程独立完成映射,每个进程都有独立的进程页表,这个页表的最顶层的pgd存放在task_struct中的mm_struct的pgd变量里面。
在一个进程新创建的时候,会调用fork,对于内存的部分会调用copy_mm,里面调用dup_mm
/*
* Allocate a new mm structure and copy contents from the
* mm structure of the passed in task structure.
*/
static struct mm_struct *dup_mm(struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm = current->mm;
mm = allocate_mm();
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk, mm->user_ns))
goto fail_nomem;
err = dup_mmap(mm, oldmm);
return mm;
}
在这里,除了创建一个新的mm_struct,并且通过memcpy将它和父进程的弄成一模一样之外,我们还需要调用mm_init进行初始化。接下来,mm_init调用mm_alloc_pgd,分配全局页目录页,赋值给mm_struct的pdg成员变量
static inline int mm_alloc_pgd(struct mm_struct *mm)
{
mm->pgd = pgd_alloc(mm);
return 0;
}
pgd_alloc里面除了分配PDG之外,还做了很重要的一个事情,就是调用pgd_ctor。
static void pgd_ctor(struct mm_struct *mm, pgd_t *pgd)
{
/* If the pgd points to a shared pagetable level (either the
ptes in non-PAE, or shared PMD in PAE), then just copy the
references from swapper_pg_dir. */
if (CONFIG_PGTABLE_LEVELS == 2 ||
(CONFIG_PGTABLE_LEVELS == 3 && SHARED_KERNEL_PMD) ||
CONFIG_PGTABLE_LEVELS >= 4) {
clone_pgd_range(pgd + KERNEL_PGD_BOUNDARY,
swapper_pg_dir + KERNEL_PGD_BOUNDARY,
KERNEL_PGD_PTRS);
}
......
}
pgd_ctor 干了什么事情呢?我们注意看里面的注释,它拷贝了对于swapper_pg_dir的引用,swapper_pg_dir 是内核页表的最顶级的全局页目录。
一个进程的虚拟地址空间包含用户态和内核态两部分。为了从虚拟地址空间映射到物理页面,页表也分为用户地址空间的页表和内核页表,这就和上面的vmalloc有关系了。在内核里面,映射靠内核页表,这里内核页表会拷贝一份到进程的页表。
至此,一个进程fork完毕之后,有了内核页表,有了自己顶级的pgd,但是对于用户地址空间来讲,还完全没有映射过。这需要等待这个进程在某个CPU上运行,并且对内存访问的那一刻了。
当这个进程被调用到某个CPU上运行的时候,要调用context_switch进行上下文切换,对于内存方面的切换会调用switch_mm_irqs_off,这里面会调用load_new_mm_cr3。
cr3是CPU的一个寄存器,它会指向当前进程的顶级pgd。如果CPU的指令要访问进程的虚拟内存,它就会自动从cr3里面得到pgd在物理内存的地址,然后根据里面的页表解析虚拟内存的地址为物理内存,从而访问真正的物理内存上的数据。
这里要注意两点。
- 第一点,cr3里面存放当前进程的顶级pgd,这个是硬件的要求。cr3里面需要存放pgd在物理内存的地址,不能是虚拟地址。因而load_new_mm_cr3里面会使用__pa,将mm_struct里面的成员变量pdg(mm_struct 里面存的都是虚拟地址)变为物理地址,才能加载到cr3里面去
- 第二点:
- 用户进程在运行的过程中,访问虚拟内存中的数据,会被cr3里面指向的页表转换为物理地址后,才在物理内存中访问数据,这个过程都是在用户态进程的,地址转换的过程无需进入内核态
- 只有访问虚拟内存的时候,发现没有映射物理内存,页表也没有创建过,才触发缺页异常。进入内核调用do_page_fault,一直调用到__handle_mm_fault,这才有了上面解析到这个函数的时候,我们看到的地面。既然原来没有创建过页表,那只好补上这一课。于是,__handle_mm_fault 调用 pud_alloc 和 pmd_alloc,来创建相应的页目录项,最后调用 handle_pte_fault 来创建页表项。
绕了一大圈,终于将页表整个机制的各个部分串了起来。但是咱们的故事还没讲完,物理的内存还没找到。我们还得接着分析 handle_pte_fault 的实现。
static int handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
......
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
......
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
......
}
这里面总的来说分了三种情况。
如果 PTE,也就是页表项,从来没有出现过,那就是新映射的页。如果是匿名页,就是第一种情况,应该映射到一个物理内存页,在这里调用的是 do_anonymous_page。如果是映射到文件,调用的就是 do_fault,这是第二种情况。如果PTE原来出现过,说明原来页面在物理内存中,后来换出到硬盘了,现在应该换回来,调用的是do_swap_page
我们来看第一种情况,do_anonymous_page。
- 对于匿名页的元素,我们需要先通弄过pte_alloc分配一个页表项
- 然后通过alloc_zeroed_user_highpage_movable 分配一个页。之后它会调用alloc_pages_vma,并最终调用__alloc_pages_nodemask,这个函数就是伙伴系统的核心函数,专门用来分配物理页面的。
- do_anonymous_page接下来调用mk_pte,将页表项指向新分配的物理页,set_pte_at会将页表项塞到页表里面
static int do_anonymous_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mem_cgroup *memcg;
struct page *page;
int ret = 0;
pte_t entry;
......
if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
return VM_FAULT_OOM;
......
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
......
entry = mk_pte(page, vma->vm_page_prot);
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
......
}
第二种情况映射到文件do_fault,最终我们会调用__do_fault。
static int __do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
int ret;
......
ret = vma->vm_ops->fault(vmf);
......
return ret;
}
- 这里调用了 struct vm_operations_struct vm_ops 的 fault 函数。还记得咱们上面用 mmap 映射文件的时候,对于 ext4 文件系统,vm_ops 指向了 ext4_file_vm_ops,也就是调用了 ext4_filemap_fault。
static const struct vm_operations_struct ext4_file_vm_ops = {
.fault = ext4_filemap_fault,
.map_pages = filemap_map_pages,
.page_mkwrite = ext4_page_mkwrite,
};
int ext4_filemap_fault(struct vm_fault *vmf)
{
struct inode *inode = file_inode(vmf->vma->vm_file);
......
err = filemap_fault(vmf);
......
return err;
}
- ext4_filemap_fault中,vm_file就是我们当时mmap的时候映射的那个文件,然后我们需要调用filemap_fault:
- 对于文件映射来说,一般这个文件会在物理内存里面有页表作为它的缓存,find_get_page就是找那个页
- 如果找到了,就调用do_async_mmap_readahead,预读一些数据到内存里面
- 如果没有,就调到no_cached_page
int filemap_fault(struct vm_fault *vmf)
{
int error;
struct file *file = vmf->vma->vm_file;
struct address_space *mapping = file->f_mapping;
struct inode *inode = mapping->host;
pgoff_t offset = vmf->pgoff;
struct page *page;
int ret = 0;
......
page = find_get_page(mapping, offset);
if (likely(page) && !(vmf->flags & FAULT_FLAG_TRIED)) {
do_async_mmap_readahead(vmf->vma, ra, file, page, offset);
} else if (!page) {
goto no_cached_page;
}
......
vmf->page = page;
return ret | VM_FAULT_LOCKED;
no_cached_page:
error = page_cache_read(file, offset, vmf->gfp_mask);
......
}
- 如果没有物理内存的缓存页,我们就调用page_cache_read。在这里显示分配一个缓存页,将这一页加到lru表里面,然后在address_space 中调用address_space_operations 的 readpage 函数,将文件内容读到内存中。
static int page_cache_read(struct file *file, pgoff_t offset, gfp_t gfp_mask)
{
struct address_space *mapping = file->f_mapping;
struct page *page;
......
page = __page_cache_alloc(gfp_mask|__GFP_COLD);
......
ret = add_to_page_cache_lru(page, mapping, offset, gfp_mask & GFP_KERNEL);
......
ret = mapping->a_ops->readpage(file, page);
......
}
- struct address_space_operations 对于 ext4 文件系统的定义如下所示。这么说来,上面的 readpage 调用的其实是 ext4_readpage。最后会调用 ext4_read_inline_page,这里面有部分逻辑和内存映射有关
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.readpages = ext4_readpages,
......
};
static int ext4_read_inline_page(struct inode *inode, struct page *page)
{
void *kaddr;
......
kaddr = kmap_atomic(page);
ret = ext4_read_inline_data(inode, kaddr, len, &iloc);
flush_dcache_page(page);
kunmap_atomic(kaddr);
......
}
- 在ext4_read_inline_page函数里面,我们需要先调用kmap_atomic,将物理内存映射到内核的虚拟地址空间,得到内核中的地址kaddr。
- kmap_atomic是用来做临时内核映射的。本来把物理内存映射到用户虚拟地址空间,不需要在内核里面映射一把。但是,现在因为要从文件里面读取数据并写入这个物理页面,又不能使用物理地址,我们只能使用虚拟地址,这就需要在内核里面临时映射一把。
- 临时映射后,ext4_read_inline_data 读取文件到这个虚拟地址。读取完毕后,我们取消这个临时映射 kunmap_atomic 就行了
接下来看第三种情况,do_swap_page
- 物理内存如果长时间不用,就要换出到硬盘,也就是swap。但是现在这部分数据又要访问了,我们还得想办法再次读到内存中来
int do_swap_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct page *page, *swapcache;
struct mem_cgroup *memcg;
swp_entry_t entry;
pte_t pte;
......
entry = pte_to_swp_entry(vmf->orig_pte);
......
page = lookup_swap_cache(entry);
if (!page) {
page = swapin_readahead(entry, GFP_HIGHUSER_MOVABLE, vma,
vmf->address);
......
}
......
swapcache = page;
......
pte = mk_pte(page, vma->vm_page_prot);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, pte);
vmf->orig_pte = pte;
......
swap_free(entry);
......
}
- do_swap_page 函数会先查找swap文件有没有缓存页。
- 如果没有,就调用swapin_readahead,将swap文件读到内存中来,形成内存页,并通过mk_pte生成页表项。set_pte_at将页表项插入页表
- swap_free将swap文件清理,因为重新加载会内存了,不需要swap文件了
swapin_readahead 会最终调用 swap_readpage,在这里,我们看到了熟悉的 readpage 函数,也就是说读取普通文件和读取 swap 文件,过程是一样的,同样需要用 kmap_atomic 做临时映射。
int swap_readpage(struct page *page, bool do_poll)
{
struct bio *bio;
int ret = 0;
struct swap_info_struct *sis = page_swap_info(page);
blk_qc_t qc;
struct block_device *bdev;
......
if (sis->flags & SWP_FILE) {
struct file *swap_file = sis->swap_file;
struct address_space *mapping = swap_file->f_mapping;
ret = mapping->a_ops->readpage(swap_file, page);
return ret;
}
......
}
通过上面复杂的过程,用户态缺页异常处理完毕了。物理内存中有了页面,页表也建立好了映射。接下来,用户程序在虚拟内存空间里面,可以通过虚拟地址顺利经过页表映射的访问物理页面上的数据了。
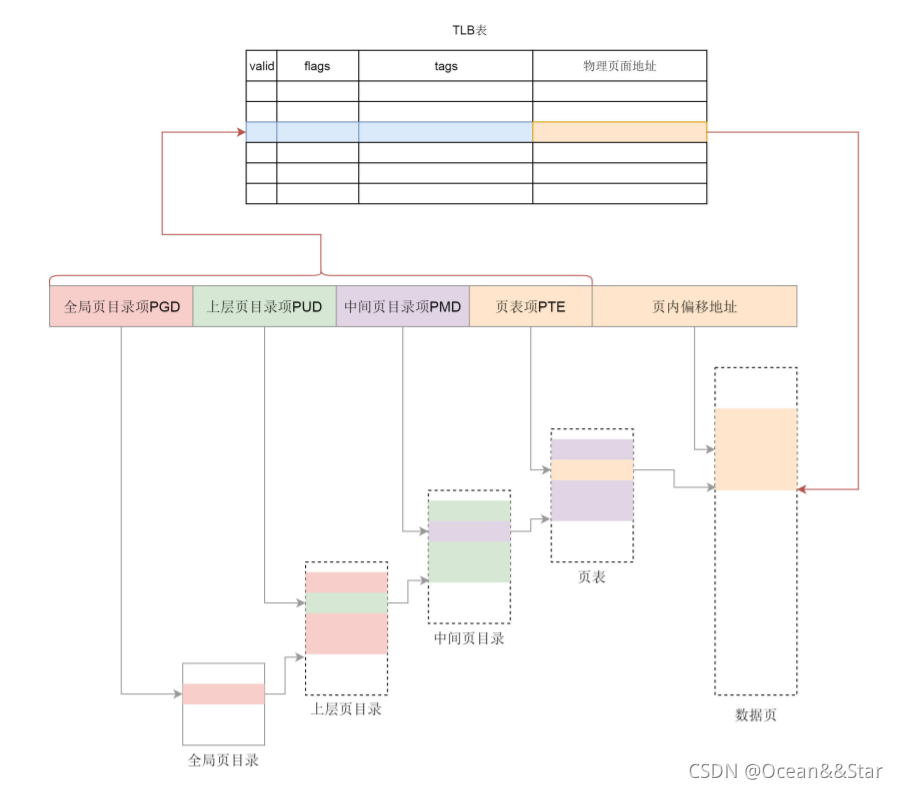
页表一般都很大,只能存放在内存中。操作系统每次访问内存都要折腾两步,先通过查询页表得到物理地址,然后访问该物理地址读取指令、数据。
为了提高映射速度,我们引入了TLB(Translation Lookaside Buffer),即快表,专门用来做地址映射的硬件设备。它不再内存中,可存储的数据比较少,但是比内存要快。所以,我们可以现象,TLB就是页表的cache,其中存储了当前最可能被访问的页表项,其内容就是页表中的一个副本。
有了 TLB 之后,地址映射的过程就像图中画的。我们先查块表,块表中有映射关系,然后直接转换为物理地址。如果在 TLB 查不到映射关系时,才会到内存中查询页表。
总结
用户态的内存映射机制包含下面几个部分:
- 用户态内存映射函数mmap,可以做匿名映射和文件映射
- 用户态的页表结构,存储位置在mm_struct中
- 在用户态访问没有映射的内存会引发缺页异常,分配物理页表、补齐页表。如果是匿名映射则分配物理内存;如果是swap,则将swap文件读入;如果是文件映射,则将文件读入。,
linux操作系统:物理内存管理
物理内存管理:会议室管理员如何分配会议室
物理内存的组织方式
最经典的内存使用方式:CPU是通过总线去访问内存的
平坦内存模型(最经典的模型):
- 内存是由连续的一页一页的块组成的。我们可以从0开始对物理页进程编号,这样每个物理页都会有个页号。
- 由于物理地址是连续的,页也是连续的,每个页大小也是一样的。因此对于任何一个地址,只要直接除一下每页的大小,很容易直接算出在哪一页。每个页有一个结构struct page表示,这个结构也是放在一个数组里面,这样根据页号,很容易通过下标找到相应的struct page结构。
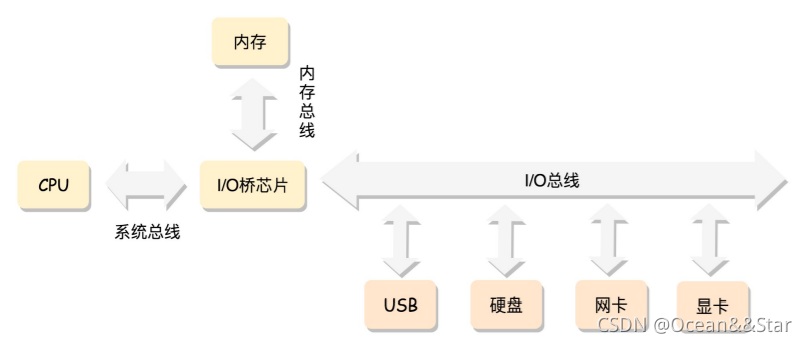
- 在这种模式下,CPU也会有多个,在总线的一侧
- 所有的内存条组成一大块内存,在总线的另一侧,所有的CPU访问内存都要过总线,而且距离是一样的,这种模式叫做SMP(Symmetric multiprocessing),即对称多处理器。
- 当然,缺点是,总线会成为瓶颈,因为数据都要走它
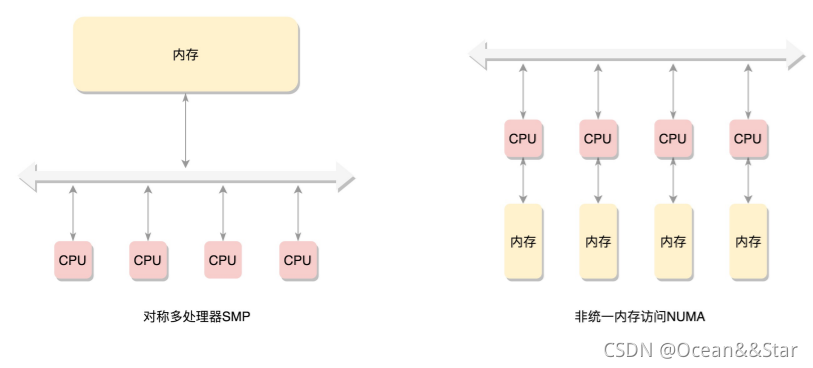
为了提高性能和可扩展性,后来有了一种更高级的模式,NUMA(Non-uniform memory access),非一致性内存访问:
- 在这种模式下,内存不是一整块。
- 每个CPU都有自己的本地内存,CPU访问本地内存不用过总线,因而速度快很多,每个CPU核内存在一起,称为一个NUMA节点
- 但是,在本地内存不足的情况下,每个CPU都可以去另外的NUMA节点申请内存,这个时候访问延时就会比较长。
- 这样,内存被分成了多个节点,每个节点再被分成一个一个的页面。由于页需要全局唯一定位,页还是需要有全局唯一的页号的。但是由于物理内存不是连起来的了,页号也就不再连续了。于是内存模型就变成了非连续内存模型,管理起来就复杂一些。
这里需要指出的是,NUMA往往是非连续内存模型。而非连续内存模型不一定就是NUMA,有时候一大片内存的情况下,也会有物理内存地址不连续的情况。
由来内存技术牛了,可以支持热插播了。这个时候,不连续成为常态,于是就有了稀疏内存模型
节点
我们主要解析当前的主流场景,NUMA方式。我们首先要能够表示NUMA节点的概念,于是就有了typedef struct pglist_data pg_data_t:
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
struct page *node_mem_map;
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page range, including holes */
int node_id;
......
} pg_data_t;
-
每一个节点都有自己的ID:node_id
-
node_mem_map :这个节点的struct page数组,用于描述这个节点里面的所有的页
-
node_start_pfn:这个节点的起始页号
-
node_present_pages:真正可用的物理页面的数目;node_spanned_pages:这个节点中包含不连续的物理内存地址的页面数
- 比如,64M物理内存隔着一个4M的空洞,然后是另外的64M物理内存。这样换算成页面数目就是,16K个页面隔着1K个页面,然后是另外16K个页面。
- 这种情况下,node_spanned_pages 就是33K 个页面,node_present_pages 就是 32K 个页面
-
每个节点分成一个个区域
zone,放在数组node_zones里面。这个数组的大小为MAX_NR_ZONES。 -
nr_zones表示当前节点的区域数量
-
node_zonelists是备用节点和它的内存区域的情况。前面讲NUMA的时候,我们讲了CPU访问内存,本节点速度最快,但是如果本节点内存不够就需要去其他节点进行分配。毕竟,就算在备用节点里面选择,慢了点也比没有强。
既然,内存被分成了多个节点,那么pglist_data 应该放在一个数组里面。每个节点一项,如下:
struct pglist_data *node_data[MAX_NUMNODES] __read_mostly;
区域
到这里,我们把内存分成了节点,把节点分成了区域。
区域的类型(什么是区域)?
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
__MAX_NR_ZONES
};
- ZONE_DMA是指可用于作DMA(Direct Memory Access,直接内存存取)的内存。DMA是这样一种机制:要把外设的数据读入内存或者把内存的数据传送到外设,原来都要通过CPU控制完成,但是这会占用CPU,影响CPU处理其他事情,所以有了DMA模式。CPU只需要DMA控制器下达指令,让DMA控制器来处理数据的传送,数据传送完毕再把信息反馈给CPU,这样就可以解放CPU。
- 对于64位的系统,有两个DMA区域。除了上面说的 ZONE_DMA,还有 ZONE_DMA32。
- ZONE_NORMAL是直接映射区,就是这里提到的,从物理内存到虚拟内存的内核区域,通过加上一个常量直接映射
- ZONE_HIGHMEM是高端内存区,就是这里提到的,对于32位系统来说超过896M的地方,对于64位没必要有的一段区域
- ZONE_MOVABLE是可移动区域,通过将物理内存划分为可移动分配区域和不可移动分配区域来避免内存碎片。
注意,上面对区域的划分都是针对物理内存的
一个区域里面是如何组织的
表示区域的数据结构zone如下:
- zone_start_pfn:表示属于这个zone的第一个页
- 从注释中可以看到,
spanned_pages = zone_end_pfn - zone_start_pfn,也就是spanned_pages 指的是不管中间有没有物理内存空洞,反正就是最后的页号减去其实的页号 - present_pages = spanned_pages - absent_pages(pages in holes),也即 present_pages是这个zone在物理内存中真实存在的所有page数目
- managed_pages = present_pages - reserved_pages,也即 managed_pages是这个zone被伙伴系统管理的所有page数目
- per_cpu_pageset 用于区分冷热页。什么是冷热页呢?为了让CPU快速访问段描述符,在CPU里面有段描述符缓存。CPU访问这个缓存的速度比内存快得多。同样对于页面来讲,也是这样的。如果一个页被加载到CPU高速缓存里面,这就是一个热页(hot page),CPU读起来速度会快很多,如果没有就是冷页(Cold Page)。由于每个 CPU 都有自己的高速缓存,因而 per_cpu_pageset 也是每个 CPU 一个。
struct zone {
......
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
unsigned long zone_start_pfn;
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
*/
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
......
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
......
} ____cacheline_internodealigned_in_
页
页是组成物理内存的基本单位,其数据结构是struct page。这是一个特别复杂的结构,里面有很多union,union结构是在C语言中被用于同一块内存根据情况保存不同类型数据的一种方式。这里之所以用了union,是因为一个物理页面使用模式有很多种
(1)第一种模式,要用就用一整页。这一整页的内存
- 或者直接和虚拟地址空间建立映射关系,我们把这种叫做匿名页(anonymous page)
- 或者用于关联一个文件,然后再和虚拟地址空间建立映射关系,这样的文件,我们称为内存映射文件(Memory-mapped File)
如果这一页是这种使用模式,则会使用union中的如下变量:
- struct address_space *mapping 就是用于内存映射,如果是匿名页,最低位为1;如果是映射文件,最低位为0
- pgoff_t index 是在映射区的偏移量
- atomic_t _mapcount,每个进程都有自己的页表,这里值有多少页表向项指向了这个页
- struct list_head lru 表示这一页应该在一个链表上,比如这个页面被换出,就在换出页的链表中
- compound 相关的变量用于复合页(Compound Page),就是将物理上连续的两个或者多个页看成一个独立的大页。
(2)第二种模式,仅需分配小块内存。
- 有时候,我们不需要一下子分配这么多的内存,比如分配一个task_struct结构,只需要分配小块的内存,去存储这个进程描述结构的对象。
- 为了满足对这种小内存块的需要,linux系统采用了一种被称为
slab allocator的技术,用于分配称为slab的一小块内存。它的基本原理是从内存管理模块申请一整块页,然后划分成多个小块的存储池,用复杂的队列来维护这些小块的状态(状态包括:被分配了、分放回池子、应该被回收)。 - 也正是因为 slab allocator 对于队列的维护过于复杂,后来就有了一种不使用队列的分配器
slub allocator,后面我们会解析这个分配器。但是你会发现,它里面还是用了很多 slab 的字眼,因为它保留了 slab 的用户接口,可以看成 slab allocator 的另一种实现。 - 还有一种小块内存的分配器叫做
slob,非常简单,主要使用在小型的嵌入式系统。 - 如果某一页是用于分隔成一小块一小块的内存进行分配的使用模式,则会使用union中的以下变量:
- s_mem 是已经分配了正在使用的 slab 的第一个对象;
- freelist 是池子中的空闲对象;
- rcu_head 是需要释放的列表
struct page {
unsigned long flags;
union {
struct address_space *mapping;
void *s_mem; /* slab first object */
atomic_t compound_mapcount; /* first tail page */
};
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* sl[aou]b first free object */
};
union {
unsigned counters;
struct {
union {
atomic_t _mapcount;
unsigned int active; /* SLAB */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
int units; /* SLOB */
};
atomic_t _refcount;
};
};
union {
struct list_head lru; /* Pageout list */
struct dev_pagemap *pgmap;
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
};
struct rcu_head rcu_head;
struct {
unsigned long compound_head; /* If bit zero is set */
unsigned int compound_dtor;
unsigned int compound_order;
};
};
union {
unsigned long private;
struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
};
......
}
页的分配
上面我们讲了物理内存的组织,从节点到区域到页到小块。接下来,我们来看物理内存的分配。
对于要分配比较大的内存,比如到分配页级别的,可以使用伙伴系统(buddy system):
- linux中内存管理的“页”大小为4KB。把所有的空闲页分组为11个页块链表,每个块链表分别包含很多个大小的页块,有1、2、4、8、16、32、128、256、512和1024个连续页的页块。最大可以申请1024个连续页,对应4MB大小的连续内存。每个页块的第一个页的物理地址是该页块大小的整数倍。
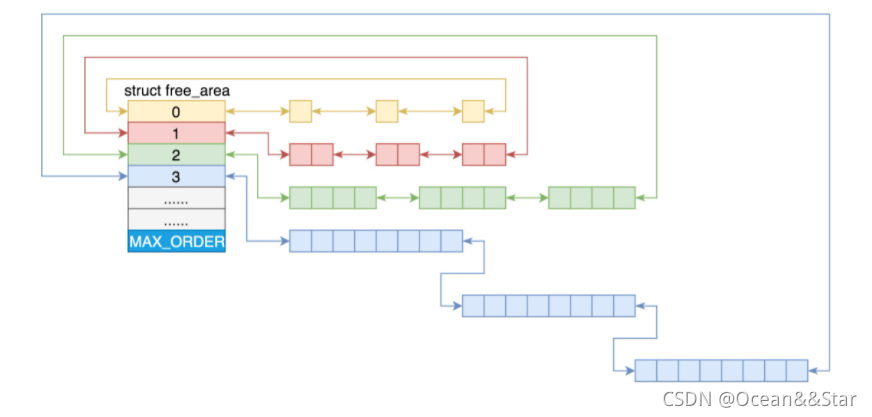
- 第 i 个页块链表中,页块中页的数目为 2^i
- 在struct zone里面有如下定义:
struct free_area free_area[MAX_ORDER];
- MAX_ORDER 就是指数。
#define MAX_ORDER 11
- 当向内存请求分配( 2 ( i − 1 ) , 2 i ] (2^{(i-1)}, 2^i](2(i−1),2i]数目的页块时,按照2^i页块请求处理。如果对应的页块链表中没有空闲页块时,那我们就到更大的页块链表中去找。当分配的页块中有多余的页时,伙伴系统会根据多余的页块大小插入到对应的空闲页块链表中
- 比如,要请求一个128个页的页块时,先检查128个页的页块链表是否有空闲块。如果没有,则查256个页的页块链表;如果有空闲块的话,则将256个页的页块分成两份,一份使用,一份插入到128个页的页块链表中。如果还是没有,就查512个页的页块链表;如果有的话,就分裂为128、128、256三个页块,一个128的使用,剩余两个插入到对应页块链表(伙伴系统的意思就是劫富济贫)
上面这个过程,我们可以在分配页的函数alloc_pages中看到:
static inline struct page *
alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
/**
* alloc_pages_current - Allocate pages.
*
* @gfp:
* %GFP_USER user allocation,
* %GFP_KERNEL kernel allocation,
* %GFP_HIGHMEM highmem allocation,
* %GFP_FS don't call back into a file system.
* %GFP_ATOMIC don't sleep.
* @order: Power of two of allocation size in pages. 0 is a single page.
*
* Allocate a page from the kernel page pool. When not in
* interrupt context and apply the current process NUMA policy.
* Returns NULL when no page can be allocated.
*/
struct page *alloc_pages_current(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;
struct page *page;
......
page = __alloc_pages_nodemask(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
......
return page;
}
alloc_pages 会调用 alloc_pages_current,这里面的注释比较容易看懂了,gfp表示希望在哪个区域中分配这个内存:
GFP_USER:用于分配一个页映射到用户进程的虚拟地址空间,并且希望直接被内核或者硬件访问,主要用于一个用户进程希望通过内存映射的方式,访问某些硬件的缓存,比如显卡缓存GFP_KERNEL:用于内核中分配页,主要分配ZONE_NORAML区域,也就是直接映射区GFP_HIGHMEM:主要分配高端区域的内存
另一个参数 order,就是表示分配 2 的 order 次方个页。
接下来调用__alloc_pages_nodemask。这是伙伴系统的核心方法。它会调用get_page_from_freelist。这里面的逻辑就是在一个循环中先看当前节点的zone。如果找不到空闲页,则再看备用节点的zone
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
......
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx, ac->nodemask) {
struct page *page;
......
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
......
}
每一个zone,都有伙伴系统维护的各种大小的队列,rmqueue就是找到合适大小的那个队列,把页面取下来。
接下来的调用链是 rmqueue->__rmqueue->__rmqueue_smallest。在这里,我们能清楚看到伙伴系统的逻辑。
static inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
page = list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
if (!page)
continue;
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
- 从当前的order,也就是指数开始,在伙伴系统的free_area找2^order大小的页块
- 如果链表的第一个不为空,就找到了
- 如果为空,就到更大的order的页块链表里面去找。
- 找到之后,除了将页块从链表中取下来,我们还要把多余的部分放在其他页块链表里面。expand就是干这个事情的
- area–就是伙伴系统那个表里面的前一项
- 前一项里面的页块大小是当前项的页块大小除以 2,size 右移一位也就是除以 2
- list_add 就是加到链表上
- nr_free++ 就是计数加 1。
static inline void expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area,
int migratetype)
{
unsigned long size = 1 << high;
while (high > low) {
area--;
high--;
size >>= 1;
......
list_add(&page[size].lru, &area->free_list[migratetype]);
area->nr_free++;
set_page_order(&page[size], high);
}
}
小内存的分配
如果遇到小的对象,会使用slub分配器进行分配。接下来将分析其原理。
在创建进程的时候,会调用dup_task_struct,它想要试图复制一个task_struct对象,需要先调用alloc_task_struct node,分配一个task_struct对象。
从下面代码可以看出,它调用了kmem_cache_alloc_node函数,在task_struct的缓存区域task_struct_cahcep分配了一块内存
static struct kmem_cache *task_struct_cachep;
task_struct_cachep = kmem_cache_create("task_struct",
arch_task_struct_size, align,
SLAB_PANIC|SLAB_NOTRACK|SLAB_ACCOUNT, NULL);
static inline struct task_struct *alloc_task_struct_node(int node)
{
return kmem_cache_alloc_node(task_struct_cachep, GFP_KERNEL, node);
}
static inline void free_task_struct(struct task_struct *tsk)
{
kmem_cache_free(task_struct_cachep, tsk);
}
- 在系统初始化的时候,task_struct_cachep会被kmem_cache_create函数创建。这个函数是专门用于分配task_struct对象的缓存。这个缓冲区的名字叫做task_struct。缓冲区中每一块的大小正好等于task_struct的大小,也就是arch_task_struct_size
- 有了这个缓冲区,每次创建task_struct的时候,我们不用到内存里面去分配,先在缓存里面看有没有直接可用的,这就是
kmem_cache_alloc_node的作用 - 当一个进程结束,task_struct也不用直接被销毁,而是放回缓冲中,这就是kmem_cache_free的作用。这样,新进程创建的时候,我们就可以直接用现成的缓存中的task_struct了
那么缓冲区struct kmem_cache 是什么样子的呢?
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retriving partial slabs etc */
unsigned long flags;
unsigned long min_partial;
int size; /* The size of an object including meta data */
int object_size; /* The size of an object without meta data */
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
int cpu_partial; /* Number of per cpu partial objects to keep around */
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
......
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
......
struct kmem_cache_node *node[MAX_NUMNODES];
};
- 在struct kmem_cache里面,有个变量struct list_head list,这个结构我们已经看到很多次了。我们可以想象一下,对于操作系统来讲,要创建和管理的缓存绝对不止task_struct,还有mm_struct、fs_struct等,因此,所有的缓存最后都会放在一个链表里面,也就是LIST_HEAD(slab_caches)
- 对于缓存来讲,其实就是分配了连续几页的大内存块,然后根据缓存对象的对象,切成小内存块
- 所以,我们这里有三个kmem_cache_order_objects 类型的变量。这里面的 order,就是 2 的 order 次方个页面的大内存块,objects 就是能够存放的缓存对象的数量。
看不懂了orz
最终,我们将大内存块切分成小内存块,样子就像下面这样。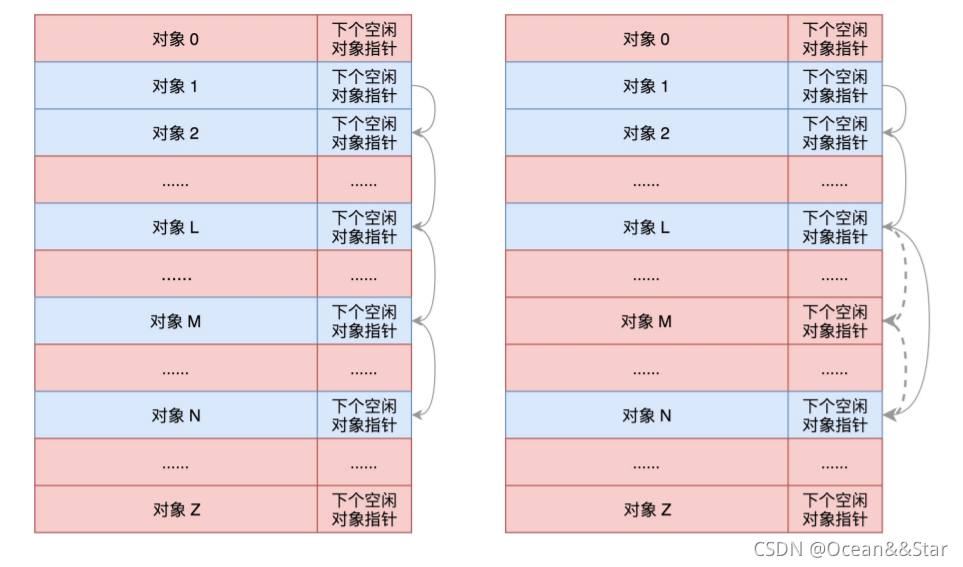
- 每一项的结构都是缓存对象后面跟一个下一个空闲对象的指针,这样非常方便将所有的空闲对象连成一个链。(相当于用数组实现一个可以随机插入和删除的链表)
- 所以,这里面就有三个变量:size是包含这个指针的大小,object_size是纯对象的大小,offset就是把下一个空闲对象的指针存放在这一项里的偏移量
那这些缓存对象哪些被分配了,哪些在空着,什么情况下整个大内存都被分配完了,需要向伙伴系统申请几个页形成新的大内存块?这些信息该由谁来维护呢?
- 接下来就是最重要的两个成员变量出场的时候了。kmem_cache_cpu 和kmem_cache_node,它们都是每个节点上有一个,一模一样
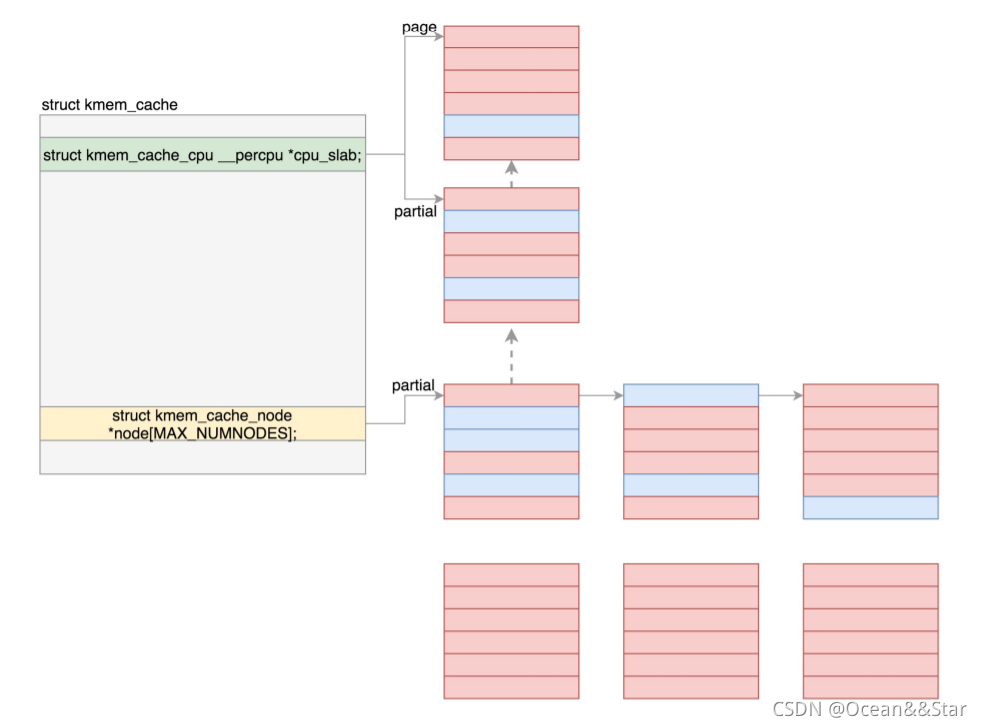
- 在分配缓存块的时候,要分两种路径,fast path和slow path,也就是快速通道和普通通道。
- 其中kmem_cache_cpu 就是快速通道,kmem_cache_node 是普通通道。
- 每次分配的时候,要先从kmem_cache_cpu 进行分配,如果kmem_cache_cpu 里面没有空闲的块,才去kmem_cache_node 中进行分配;如果还是没有空闲的块,才去伙伴系统分配新的页。
我们来看一下,kmem_cache_cpu 里面是如何存放缓存块的。
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial; /* Partially allocated frozen slabs */
#endif
......
};
- page指向大内存块的第一个页,缓存块就是从里面分配的
- freelist指向大内存块里面第一个空闲的项。如上面所说,这一项会有指针指向下一个空闲的项,最终所有空闲的项会形成一个链表
- partial指向的也是大内存块的第一个页,之所以叫做partial(部分),就是因为它里面部分被分配出去了,部分是空的。这是一个备用列表,当page满了,就会从这里找
我们再来看 kmem_cache_node 的定义。
struct kmem_cache_node {
spinlock_t list_lock;
......
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
......
#endif
};
- 这里的partial,是一个链表。这个链表里存放的是部分空闲的大内存块。这是kmem_cache_cpu 里面的partial的备用列表,如果那里没有,就到这里来找。
下面我们就来看看这个分配过程。kmem_cache_alloc_node 会调用 slab_alloc_node。你还是先重点看这里面的注释,这里面说的就是快速通道和普通通道的概念。
/*
* Inlined fastpath so that allocation functions (kmalloc, kmem_cache_alloc)
* have the fastpath folded into their functions. So no function call
* overhead for requests that can be satisfied on the fastpath.
*
* The fastpath works by first checking if the lockless freelist can be used.
* If not then __slab_alloc is called for slow processing.
*
* Otherwise we can simply pick the next object from the lockless free list.
*/
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
......
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
......
object = c->freelist;
page = c->page;
if (unlikely(!object || !node_match(page, node))) {
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
}
......
return object;
}
快速通道很简单,取出cpu_slab也就是kmem_cache_cpu 的freelist,这就是第一个空闲的项,可以直接返回了。如果没有空闲的了,就进入普通通道,调用__slab_alloc
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *freelist;
struct page *page;
......
redo:
......
/* must check again c->freelist in case of cpu migration or IRQ */
freelist = c->freelist;
if (freelist)
goto load_freelist;
freelist = get_freelist(s, page);
if (!freelist) {
c->page = NULL;
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
load_freelist:
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);
return freelist;
new_slab:
if (slub_percpu_partial(c)) {
page = c->page = slub_percpu_partial(c);
slub_set_percpu_partial(c, page);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;
}
freelist = new_slab_objects(s, gfpflags, node, &c);
......
return freeli
在这里,我们首先再次尝试一下 kmem_cache_cpu 的 freelist。为什么呢?万一当前进程被中断,等回来的时候,别人已经释放了一些缓存,说不定又有空间了呢。如果找到了,就跳到 load_freelist,在这里将 freelist 指向下一个空闲项,返回就可以了。
如果 freelist 还是没有,则跳到 new_slab 里面去。这里面我们先去 kmem_cache_cpu 的 partial 里面看。如果 partial 不是空的,那就将 kmem_cache_cpu 的 page,也就是快速通道的那一大块内存,替换为 partial 里面的大块内存。然后 redo,重新试下。这次应该就可以成功了。
如果真的还不行,那就要到 new_slab_objects 了。
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
int node, struct kmem_cache_cpu **pc)
{
void *freelist;
struct kmem_cache_cpu *c = *pc;
struct page *page;
freelist = get_partial(s, flags, node, c);
if (freelist)
return freelist;
page = new_slab(s, flags, node);
if (page) {
c = raw_cpu_ptr(s->cpu_slab);
if (c->page)
flush_slab(s, c);
freelist = page->freelist;
page->freelist = NULL;
stat(s, ALLOC_SLAB);
c->page = page;
*pc = c;
} else
freelist = NULL;
return freelis
在这里面,get_partial 会根据 node id,找到相应的 kmem_cache_node,然后调用 get_partial_node,开始在这个节点进行分配。
/*
* Try to allocate a partial slab from a specific node.
*/
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,
struct kmem_cache_cpu *c, gfp_t flags)
{
struct page *page, *page2;
void *object = NULL;
int available = 0;
int objects;
......
list_for_each_entry_safe(page, page2, &n->partial, lru) {
void *t;
t = acquire_slab(s, n, page, object == NULL, &objects);
if (!t)
break;
available += objects;
if (!object) {
c->page = page;
stat(s, ALLOC_FROM_PARTIAL);
object = t;
} else {
put_cpu_partial(s, page, 0);
stat(s, CPU_PARTIAL_NODE);
}
if (!kmem_cache_has_cpu_partial(s)
|| available > slub_cpu_partial(s) / 2)
break;
}
......
return object;
acquire_slab 会从 kmem_cache_node 的 partial 链表中拿下一大块内存来,并且将 freelist,也就是第一块空闲的缓存块,赋值给 t。并且当第一轮循环的时候,将 kmem_cache_cpu 的 page 指向取下来的这一大块内存,返回的 object 就是这块内存里面的第一个缓存块 t。如果 kmem_cache_cpu 也有一个 partial,就会进行第二轮,再次取下一大块内存来,这次调用 put_cpu_partial,放到 kmem_cache_cpu 的 partial 里面。
如果 kmem_cache_node 里面也没有空闲的内存,这就说明原来分配的页里面都放满了,就要回到 new_slab_objects 函数,里面 new_slab 函数会调用 allocate_slab。
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{
struct page *page;
struct kmem_cache_order_objects oo = s->oo;
gfp_t alloc_gfp;
void *start, *p;
int idx, order;
bool shuffle;
flags &= gfp_allowed_mask;
......
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page)) {
oo = s->min;
alloc_gfp = flags;
/*
* Allocation may have failed due to fragmentation.
* Try a lower order alloc if possible
*/
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page))
goto out;
stat(s, ORDER_FALLBACK);
}
......
return page;
}
在这里,我们看到了 alloc_slab_page 分配页面。分配的时候,要按 kmem_cache_order_objects 里面的 order 来。如果第一次分配不成功,说明内存已经很紧张了,那就换成 min 版本的 kmem_cache_order_objects。
页面换出
另一个物理内存管理必须要处理的事情就是,页面换出:
- 每个进程都有自己的虚拟地址空间,无论是32位还是64位,虚拟地址空间都比较大,物理内存不可能有这么多的空间放得下。所以,一般情况下,页面只有在被使用的时候,才会放在物理内存中
- 如果过了一段时间不被使用,即便用户进程并没有释放它,物理内存也有责任做一定的干预。比如,将这些物理内存中的页面换出到硬盘上去;将空出的物理内存,交给活跃的进程去使用
什么情况下会触发页面换出呢?
- 可以想象,最常见的情况就是,分配内存的时候,发现没有地方了,就试图回收一下。比如,咱们解析申请一个页面的时候,会调用 get_page_from_freelist,接下来的调用链为 get_page_from_freelist->node_reclaim->__node_reclaim->shrink_node,通过这个调用链可以看出,页面换出也是以内存节点为单位的。
- 另外一种情况是,作为内存管理系统应该主动去做的,而不能等真的出了事情再做,这就是内核线程
kswapd。这个内核线程,在系统初始化的时候就被创建。这样它会进入一个无限循环,直到系统停止。在这个循环中,如果内存使用没有那么紧张,拿它就可以放心sleep;如果内存紧张了,就要去检查一下内存,看看是否需要换出一些内存页。这里的调用链是 balance_pgdat->kswapd_shrink_node->shrink_node,是以内存节点为单位的,最后也是调用 shrink_node。
/*
* The background pageout daemon, started as a kernel thread
* from the init process.
*
* This basically trickles out pages so that we have _some_
* free memory available even if there is no other activity
* that frees anything up. This is needed for things like routing
* etc, where we otherwise might have all activity going on in
* asynchronous contexts that cannot page things out.
*
* If there are applications that are active memory-allocators
* (most normal use), this basically shouldn't matter.
*/
static int kswapd(void *p)
{
unsigned int alloc_order, reclaim_order;
unsigned int classzone_idx = MAX_NR_ZONES - 1;
pg_data_t *pgdat = (pg_data_t*)p;
struct task_struct *tsk = current;
for ( ; ; ) {
......
kswapd_try_to_sleep(pgdat, alloc_order, reclaim_order,
classzone_idx);
......
reclaim_order = balance_pgdat(pgdat, alloc_order, classzone_idx);
......
}
}
`
shrink_node 会调用 shrink_node_memcg。这里面有一个循环处理页面的列表,看这个函数的注释,其实和上面我们想表达的内存换出是一样的。
/*
* This is a basic per-node page freer. Used by both kswapd and direct reclaim.
*/
static void shrink_node_memcg(struct pglist_data *pgdat, struct mem_cgroup *memcg,
struct scan_control *sc, unsigned long *lru_pages)
{
......
unsigned long nr[NR_LRU_LISTS];
enum lru_list lru;
......
while (nr[LRU_INACTIVE_ANON] || nr[LRU_ACTIVE_FILE] ||
nr[LRU_INACTIVE_FILE]) {
unsigned long nr_anon, nr_file, percentage;
unsigned long nr_scanned;
for_each_evictable_lru(lru) {
if (nr[lru]) {
nr_to_scan = min(nr[lru], SWAP_CLUSTER_MAX);
nr[lru] -= nr_to_scan;
nr_reclaimed += shrink_list(lru, nr_to_scan,
lruvec, memcg, sc);
}
}
......
}
......
这里面有个lru列表,从下面的定义,我们可以想象,所有的页面都被挂载LRU列表中,LRU就是 Least Recent Use,也就是最近最少使用。也就是说,这个列表里面会按照活跃程度进行排序,这样就很容易把不怎么用的内存页拿出来做处理。
内存页一共分两类,一类是匿名页,和虚拟地址进行管理;一类是内存映射,不但和虚拟地址空间管理,还和文件管理管理。
它的每一类都有两个列表,一共是active,一共是inactive。active就是比较活跃的,inactive就是不怎么活跃的。这里面的页会变化,过一段时间,活跃的可能变成不活跃的,不活跃的可能变成活跃的。如果要换出内存,那就是从不活跃列表中找出最不活跃的,换出到硬盘上
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE,
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
LRU_UNEVICTABLE,
NR_LRU_LISTS
};
#define for_each_evictable_lru(lru) for (lru = 0; lru <= LRU_ACTIVE_FILE; lru++)
static unsigned long shrink_list(enum lru_list lru, unsigned long nr_to_scan,
struct lruvec *lruvec, struct mem_cgroup *memcg,
struct scan_control *sc)
{
if (is_active_lru(lru)) {
if (inactive_list_is_low(lruvec, is_file_lru(lru),
memcg, sc, true))
shrink_active_list(nr_to_scan, lruvec, sc, lru);
return 0;
}
return shrink_inactive_list(nr_to_scan, lruvec, sc, lru);
从上面的代码可以看出,shrink_list 会先缩减活跃页面列表,再压缩不活跃的页面列表。对于不活跃列表的缩减,shrink_inactive_list 就需要对页面进行回收;对于匿名页来讲,需要分片swap,将内存页写入文件系统;对于内存映射关联了文件的,我们需要将在内存中对于文件的修改写回到文件中
小结
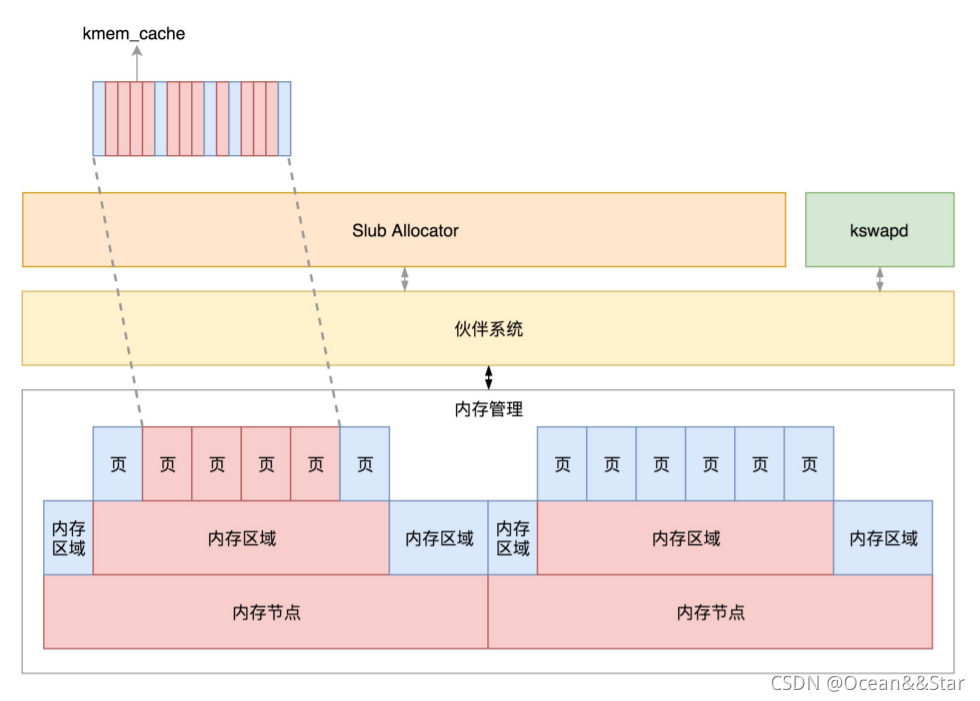
物理内存的组织形式如下图:
- 如果有多个CPU,就有多个节点。每个节点用struct pglist_data表示,放在一个数组里面
- 每个节点分为多个区域,每个区域用struct zone表示,也放在一个数组里面
- 每个区域分为多个页。为了方便分配,空闲页放在struct free_area 里面,使用伙伴系统进行管理和分配,每一页用struct page表示
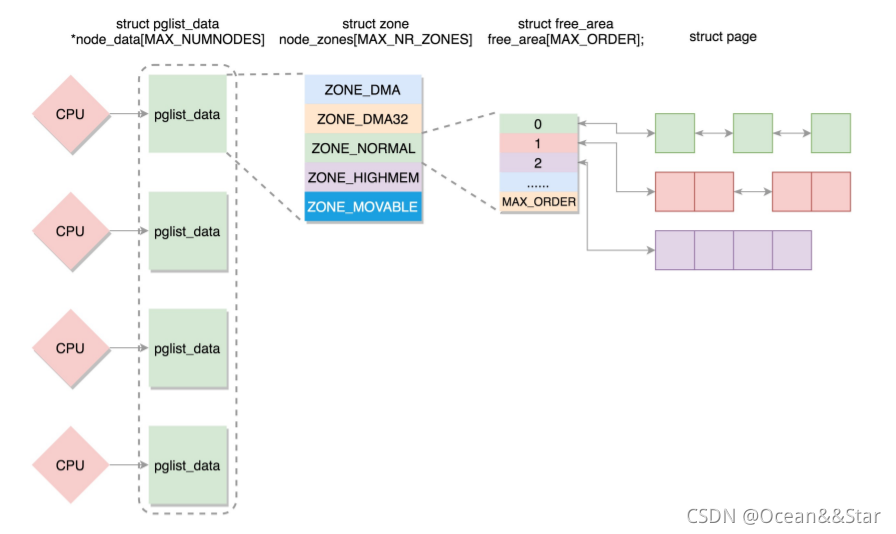
对于物理内存,从下到上的关系以及分配模式如下:
- 物理内存分NUMA节点,分布进行管理
- 每个NUMA节点分成多个内存区域
- 每个内存区域分成多个物理页面
- 伙伴系统将多个连续的页面作为一个大的内存块分配给上层
- kswapd负责物理页面的换入换出
- Slub Allocator 将从伙伴系统申请的大内存块切成小块,分配给其他系统

 浙公网安备 33010602011771号
浙公网安备 33010602011771号