后端开发实践系列——领域驱动设计(DDD)编码实践
Martin Fowler在《企业应用架构模式》一书中写道:
I found this(business logic) a curious term because there are few things that are less logical than business logic.
初略翻译过来可以理解为:业务逻辑是很没有逻辑的逻辑。
的确,很多时候软件的业务逻辑是无法通过推理而得到的,有时甚至是被臆想出来的。这样的结果使得原本已经很复杂的业务变得更加复杂而难以理解。而在具体编码实现时,除了应付业务上的复杂性,技术上的复杂性也不能忽略,比如我们要讲究技术上的分层,要遵循软件开发的基本原则,又比如要考虑到性能和安全等等。
在很多项目中,技术复杂度与业务复杂度相互交错纠缠不清,这种火上浇油的做法成为不少软件项目无法继续往下演进的原因。然而,在合理的设计下,技术和业务是可以分离开来或者至少它们之间的耦合度是可以降低的。在不同的软件建模方法中,领域驱动设计(Domain Driven Design,DDD)尝试通过其自有的原则与套路来解决软件的复杂性问题,它将研发者的目光首先聚焦在业务本身上,使技术架构和代码实现成为软件建模过程中的“副产品”。
DDD总览
DDD分为战略设计和战术设计。在战略设计中,我们讲求的是子域和限界上下文(Bounded Context,BC)的划分,以及各个限界上下文之间的上下游关系。当前如此火热的“在微服务中使用DDD”这个命题,究其最初的逻辑无外乎是“DDD中的限界上下文可以用于指导微服务中的服务划分”。事实上,限界上下文依然是软件模块化的一种体现,与我们一直以来追求的模块化原则的驱动力是相同的,即通过一定的手段使软件系统在人的大脑中更加有条理地呈现,让作为“目的”的人能够更简单地了解进而掌控软件系统。
如果说战略设计更偏向于软件架构,那么战术设计便更偏向于编码实现。DDD战术设计的目的是使得业务能够从技术中分离并突显出来,让代码直接表达业务的本身,其中包含了聚合根、应用服务、资源库、工厂等概念。虽然DDD不一定通过面向对象(OO)来实现,但是通常情况下在实践DDD时我们采用的是OO编程范式,行业中甚至有种说法是“DDD是OO进阶”,意思是面向对象中的基本原则(比如SOLID)在DDD中依然成立。本文主要讲解DDD的战术设计。
本文以一个简单的电商订单系统为例,通过以下方式可以获取源代码:

实现业务的3种常见方式
在讲解DDD之前,让我们先来看一下实现业务代码的几种常见方式,在示例项目中有个“修改Order中Product的数量”的业务需求如下:
可以修改Order中Product的数量,但前提是Order处于未支付状态,Product数量变更后Order的总价(totalPrice)应该随之更新。
1. 基于“Service + 贫血模型”的实现
这种方式当前被很多软件项目所采用,主要的特点是:存在一个贫血的“领域对象”,业务逻辑通过一个Service类实现,然后通过setter方法更新领域对象,最后通过DAO(多数情况下可能使用诸如Hibernate之类的ORM框架)保存到数据库中。实现一个OrderService类如下:
@Transactional
public void changeProductCount(String id, ChangeProductCountCommand command) {
Order order = DAO.findById(id);
if (order.getStatus() == PAID) {
throw new OrderCannotBeModifiedException(id);
}
OrderItem orderItem = order.getOrderItem(command.getProductId());
orderItem.setCount(command.getCount());
order.setTotalPrice(calculateTotalPrice(order));
DAO.saveOrUpdate(order);
}
这种方式依然是一种面向过程的编程范式,违背了最基本的OO原则。另外的问题在于职责划分模糊不清,使本应该内聚在Order中的业务逻辑泄露到了其他地方(OrderService),导致Order成为一个只是充当数据容器的贫血模型(Anemic Model),而非真正意义上的领域模型。在项目持续演进的过程中,这些业务逻辑会分散在不同的Service类中,最终的结果是代码变得越来越难以理解进而逐渐丧失扩展能力。
2. 基于事务脚本的实现
在上一种实现方式中,我们会发现领域对象(Order)存在的唯一目的其实是为了让ORM这样的工具能够一次性地持久化,在不使用ORM的情况下,领域对象甚至都没有必要存在。于是,此时的代码实现便退化成了事务脚本(Transaction Script),也就是直接将Service类中计算出的结果直接保存到数据库(或者有时都没有Service类,直接通过SQL实现业务逻辑):
@Transactional
public void changeProductCount(String id, ChangeProductCountCommand command) {
OrderStatus orderStatus = DAO.getOrderStatus(id);
if (orderStatus == PAID) {
throw new OrderCannotBeModifiedException(id);
}
DAO.updateProductCount(id, command.getProductId(), command.getCount());
DAO.updateTotalPrice(id);
}
可以看到,DAO中多出了很多方法,此时的DAO不再只是对持久化的封装,而是也会包含业务逻辑。
另外,DAO.updateTotalPrice(id)方法的实现中将直接调用SQL来实现Order总价的更新。与“Service+贫血模型”方式相似,事务脚本也存在业务逻辑分散的问题。
事实上,事务脚本并不是一种全然的反模式,在系统足够简单的情况下完全可以采用。但是:一方面“简单”这个度其实并不容易把握;另一方面软件系统通常会在不断的演进中加入更多的功能,使得原本简单的代码逐渐变得复杂。因此,事务脚本在实际的应用中使用得并不多。
3. 基于领域对象的实现
在这种方式中,核心的业务逻辑被内聚在行为饱满的领域对象(Order)中,实现Order类如下:
public void changeProductCount(ProductId productId, int count) {
if (this.status == PAID) {
throw new OrderCannotBeModifiedException(this.id);
}
OrderItem orderItem = retrieveItem(productId);
orderItem.updateCount(count);
}
然后在Controller或者Service中,调用Order.changeProductCount()
@PostMapping("/order/{id}/products")
public void changeProductCount(@PathVariable(name = "id") String id, @RequestBody @Valid ChangeProductCountCommand command) {
Order order = DAO.byId(orderId(id));
order.changeProductCount(ProductId.productId(command.getProductId()), command.getCount());
order.updateTotalPrice();
DAO.saveOrUpdate(order);
}
可以看到,所有业务(“检查Order状态”、“修改Product数量”以及“更新Order总价”)都被包含在了Order对象中,这些正是Order应该具有的职责。(不过示例代码中有个地方明显违背了内聚性原则,下文会讲到,作为悬念读者可以先行尝试着找一找)
事实上,这种方式与本文要讲的DDD战术模式已经很相近了,只是DDD抽象出了更多的概念与原则。
基于业务的分包
在本系列的上一篇:Spring Boot项目模板文章中,其实我已经讲到了基于业务的分包,结合DDD的场景,这里再简要讨论一下。所谓基于业务分包即通过软件所实现的业务功能进行模块化划分,而不是从技术的角度划分(比如首先划分出service和infrastruture等包)。在DDD的战略设计中,我们关注于从一个宏观的视角俯视整个软件系统,然后通过一定的原则对系统进行子域和限界上下文的划分。在战术实践中,我们也通过类似的提纲挈领的方法进行整体的代码结构的规划,所采用的原则依然逃离不了“内聚性”和“职责分离”等基本原则。此时,首先映入眼帘的便是软件的分包。
在DDD中,聚合根(下文会讲到)是主要业务逻辑的承载体,也是“内聚性”原则的典型代表,因此通常的做法便是基于聚合根进行顶层包的划分。在示例电商项目中,有两个聚合根对象Order和Product,分别创建order包和product包,然后在各自的顶层包下再根据代码结构的复杂程度划分子包,比如对于product包:
└── product
├── CreateProductCommand.java
├── Product.java
├── ProductApplicationService.java
├── ProductController.java
├── ProductId.java
├── ProductNotFoundException.java
├── ProductRepository.java
└── representation
├── ProductRepresentationService.java
└── ProductSummaryRepresentation.java
可以看到,ProductRepository和ProductController等多数类都直接放在了product包下,而没有单独分包;但是展现类ProductSummaryRepresentation却做了单独分包。这里的原则是:在所有类已经被内聚在了product包下的情况下,如果代码结构足够的简单,那么没有必要再次进行子包的划分,ProductRepository和ProductController便是这种情况;而如果多个类需要做再次的内聚,那么需要另行分包,比如通过REST API接口返回Product数据时,代码中涉及到了两个对象ProductRepresentationService和ProductSummaryRepresentation,这两个对象是紧密关联的,因此将他们放在representation子包下。而对于更加复杂的Order,分包如下:
├── order
│ ├── OrderApplicationService.java
│ ├── OrderController.java
│ ├── OrderPaymentProxy.java
│ ├── OrderPaymentService.java
│ ├── OrderRepository.java
│ ├── command
│ │ ├── ChangeAddressDetailCommand.java
│ │ ├── CreateOrderCommand.java
│ │ ├── OrderItemCommand.java
│ │ ├── PayOrderCommand.java
│ │ └── UpdateProductCountCommand.java
│ ├── exception
│ │ ├── OrderCannotBeModifiedException.java
│ │ ├── OrderNotFoundException.java
│ │ ├── PaidPriceNotSameWithOrderPriceException.java
│ │ └── ProductNotInOrderException.java
│ ├── model
│ │ ├── Order.java
│ │ ├── OrderFactory.java
│ │ ├── OrderId.java
│ │ ├── OrderIdGenerator.java
│ │ ├── OrderItem.java
│ │ └── OrderStatus.java
│ └── representation
│ ├── OrderItemRepresentation.java
│ ├── OrderRepresentation.java
│ └── OrderRepresentationService.java
可以看到,我们专门创建了一个model包用于放置所有与Order聚合根相关的领域对象;另外,基于同类型相聚原则,创建command包和exception包分别用于放置请求类和异常类。
领域模型的门面——应用服务
UML中有用例(Use Case)的概念,表示的是软件向外提供业务功能的基本逻辑单元。在DDD中,由于业务被提到了第一优先级,那么自然地我们希望对业务的处理能够显现出来,为了达到这样的目的,DDD专门提供了一个名为应用服务(ApplicationService)的抽象层。ApplicationService采用了门面模式,作为领域模型向外提供业务功能的总出入口,就像酒店的前台处理客户的不同需求一样。

在编码实现业务功能时,通常用2种工作流程:
-
自底向上:先设计数据模型,比如关系型数据库的表结构,再实现业务逻辑。我在与不同的程序员结对编程的时候,总会是听到这么一句话:“让我先把数据库表的字段设计出来吧”。这种方式将关注点优先放在了技术性的数据模型上,而不是代表业务的领域模型,是DDD之反。
-
自顶向下:拿到一个业务需求,先与客户方确定好请求数据格式,再实现Controller和ApplicationService,然后实现领域模型(此时的领域模型通常已经被识别出来),最后实现持久化。
在DDD实践中,自然应该采用自顶向下的实现方式。ApplicationService的实现遵循一个很简单的原则,即一个业务用例对应ApplicationService上的一个业务方法。比如,对于上文提到的“修改Order中Product的数量”业务需求实现如下:
实现OrderApplicationService:
@Transactional
public void changeProductCount(String id, ChangeProductCountCommand command) {
Order order = orderRepository.byId(orderId(id));
order.changeProductCount(ProductId.productId(command.getProductId()), command.getCount());
orderRepository.save(order);
}
OrderController调用OrderApplicationService:
@PostMapping("/{id}/products")
public void changeProductCount(@PathVariable(name = "id") String id, @RequestBody @Valid ChangeProductCountCommand command) {
orderApplicationService.changeProductCount(id, command);
}
此时,
order.changeProductCount()和orderRepository.save()都没有必要实现,但是由OrderController和OrderApplicationService所构成的业务处理的架子已经搭建好了。
可以看到,“修改Order中Product的数量”用例中的
OrderApplicationService.changeProductCount()方法实现中只有不多的3行代码,然而,如此简单的ApplicationService却存在很多讲究。
ApplicationService需要遵循以下原则:
-
业务方法与业务用例一一对应:前面已经讲到,不再赘述。
-
业务方法与事务一一对应:也即每一个业务方法均构成了独立的事务边界,在本例中,
OrderApplicationService.changeProductCount()
方法标记有Spring的@Transactional注解,表示整个方法被封装到了一个事务中。
-
本身不应该包含业务逻辑:业务逻辑应该放在领域模型中实现,更准确的说是放在聚合根中实现,在本例中,
order.changeProductCount()方法才是真正实现业务逻辑的地方,而ApplicationService只是作为代理调用order.changeProductCount()方法,因此,ApplicationService应该是很薄的一层。 -
与UI或通信协议无关:ApplicationService的定位并不是整个软件系统的门面,而是领域模型的门面,这意味着ApplicationService不应该处理诸如UI交互或者通信协议之类的技术细节。在本例中,Controller作为ApplicationService的调用者负责处理通信协议(HTTP)以及与客户端的直接交互。这种处理方式使得ApplicationService具有普适性,也即无论最终的调用方是HTTP的客户端,还是RPC的客户端,甚至一个Main函数,最终都统一通过ApplicationService才能访问到领域模型。
-
接受原始数据类型:ApplicationService作为领域模型的调用方,领域模型的实现细节对其来说应该是个黑盒子,因此ApplicationService不应该引用领域模型中的对象。此外,ApplicationService接受的请求对象中的数据仅仅用于描述本次业务请求本身,在能够满足业务需求的条件下应该尽量的简单。因此,ApplicationService通常处理一些比较原始的数据类型。在本例中,
OrderApplicationService所接受的Order ID是Java原始的String类型,在调用领域模型中的Repository时,才被封装为OrderId对象。
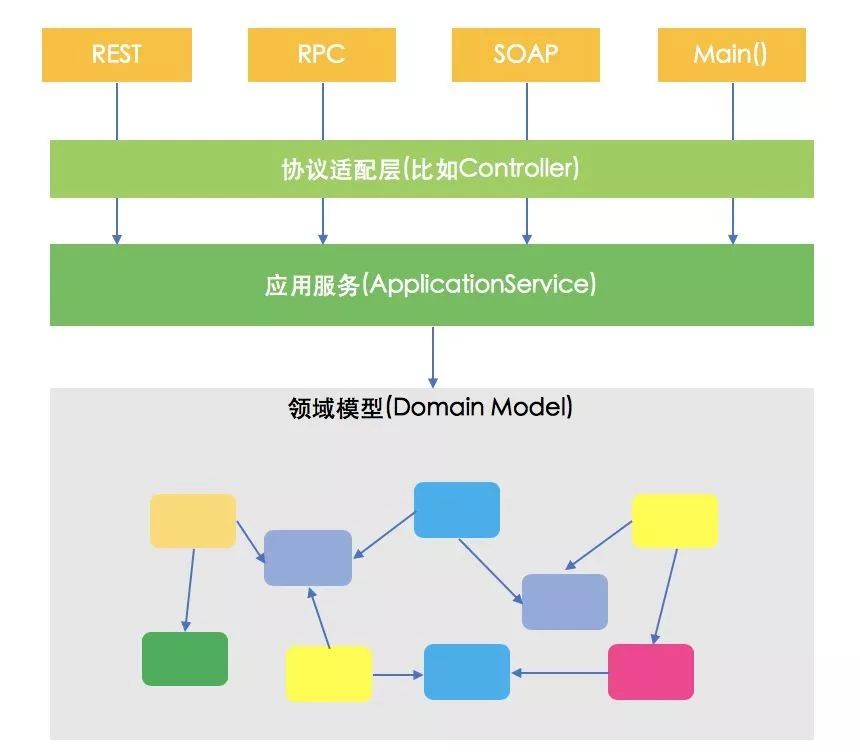
(应用服务(ApplicationService)是领域模型的门面)
业务的载体——聚合根
接地气一点地讲,聚合根(Aggreate Root, AR)就是软件模型中那些最重要的以名词形式存在的领域对象,比如本文示例项目中的Order和Product。又比如,对于一个会员管理系统,会员(Member)便是一个聚合根;对于报销系统,报销单(Expense)便是一个聚合根;对于保险系统,保单(Policy)便是一个聚合根。聚合根是主要的业务逻辑载体,DDD中所有的战术实现都围绕着聚合根展开。
然而,并不是说领域模型中的所有名词都可以建模为聚合根。所谓“聚合”,顾名思义,即需要将领域中高度内聚的概念放到一起组成一个整体。至于哪些概念才能聚到一起,需要我们对业务本身有很深刻的认识,这也是为什么DDD强调开发团队需要和领域专家一起工作的原因。近年来流行起来的事件风暴建模活动,究其本意也是通过罗列出领域中发生的所有事件可以让我们全面的了解领域中的业务,进而识别出聚合根。
对于“更新Order中Product数量”用例,聚合根Order的实现如下:
public void changeProductCount(ProductId productId, int count) {
if (this.status == PAID) {
throw new OrderCannotBeModifiedException(this.id);
}
OrderItem orderItem = retrieveItem(productId);
orderItem.updateCount(count);
this.totalPrice = calculateTotalPrice();
}
private BigDecimal calculateTotalPrice() {
return items.stream()
.map(OrderItem::totalPrice)
.reduce(ZERO, BigDecimal::add);
}
private OrderItem retrieveItem(ProductId productId) {
return items.stream()
.filter(item -> item.getProductId().equals(productId))
.findFirst()
.orElseThrow(() -> new ProductNotInOrderException(productId, id));
}
在本例中,Order中的品项(orderItems)和总价(totalPrice)是密切相关的,orderItems的变化会直接导致totalPrice的变化,因此,这二者自然应该内聚在Order下。此外,totalPrice的变化是orderItems变化的必然结果,这种因果关系是业务驱动出来的,为了保证这种“必然”,我们需要在Order.changeProductCount()方法中同时实现“因”和“果”,也即聚合根应该保证业务上的一致性。在DDD中,业务上的一致性被称为不变条件(Invariants)。
还记得上文中提到的“违背内聚性的悬念”吗?当时调用Order上的业务方式如下:
.....
order.changeProductCount(ProductId.productId(command.getProductId()), command.getCount());
order.updateTotalPrice();
.....
为了实现“更新Order中Product数量”业务功能,这里先后调用了Order上的两个public方法changeProductCount()和updateTotalPrice()。虽然这种做法也能正确地实现业务逻辑,但是它将保证业务一致性的职责交给了Order的调用方(上文中的Controller)而不是Order自身,此时调用方需要确保在调用了changeProductCount()之后必须调用updateTotalPrice()方法,这一方面是Order中业务逻辑的泄露,另一方面调用方并不承担这样的职责,而Order才最应该承担这样的职责。
对内聚性的追求会自然地延伸出聚合根的边界。在DDD的战略设计中,我们已经通过限界上下文的划分将一个大的软件系统拆分为了不同的“模块”,在这样的前提下,再在某个限界上下文中来讨论内聚性将比在大泥球系统中讨论变得简单得多。
对聚合根的设计需要提防上帝对象(God Object),也即用一个大而全的领域对象来实现所有的业务功能。上帝对象的背后存在着一种表面上看似合理的逻辑:既然要内聚,那么让我们把所有相关的东西都聚到一起吧,比如用一个Product类来应付所有的业务场景,包括订单、物流、发票等等。这种机械的方式看似内聚,实则恰恰是内聚性的反面。要解决这样的问题依然需要求助于限界上下文,不同限界上下文使用各自的通用语言(Ubiquitous Language),通用语言要求一个业务概念不应该有二义性,在这样的原则下,不同的限界上下文可能都有自己的Product类,虽然名字相同,却体现着不同的业务。
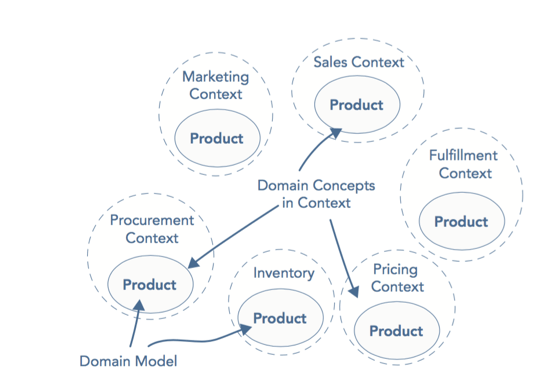
(不同的限界上下文中都有各自的Product,有些Product是聚合根,有些不是)
除了内聚性和一致性,聚合根还有以下特征:
-
聚合根的实现应该与框架无关:既然DDD讲求业务复杂度和技术复杂度的分离,那么作为业务主要载体的聚合根应该尽量少地引用技术框架级别的设施,最好是POJO。试想一下,如果你的项目哪天需要从Spring迁移到Play,而你可以自信地给老板说,直接将核心Java代码拷贝过去即可,这将是一种多么美妙的体验。又或者说,很多时候技术框架会有“大步”的升级,这种升级会导致框架中API的变化并且不再支持向后兼容,此时如果我们的领域模与框架无关,那么便可做到在框架升级的过程中幸免于难。
-
聚合根之间的引用通过ID完成:在聚合根边界设计合理的情况下,一次业务用例只会更新一个聚合根,此时你在该聚合根中去引用另外聚合根的整体有什么好处呢?在本文示例中,一个
Order下的OrderItem引用了ProductId,而不是整个Product。 -
聚合根内部的所有变更都必须通过聚合根完成:为了保证聚合根的一致性,同时避免聚合根内部逻辑向外泄露,客户方只能将整个聚合根作为统一调用入口。
-
如果一个事务需要更新多个聚合根,首先思考一下自己的聚合根边界处理是否出了问题,因为在设计合理的情况下通常不会出现一个事务更新多个聚合根的场景。如果这种情况的确是业务所需,那么考虑引入消息机制和事件驱动架构,保证一个事务只更新一个聚合根,然后通过消息机制异步更新其他聚合根。
-
聚合根不应该引用基础设施。
-
外界不应该持有聚合根内部的数据结构。
-
尽量使用小聚合。
实体 vs 值对象
软件模型中存在实体对象(Entity)和值对象(Value Object)之说,这种划分方式事实上并不是DDD的专属,但是在DDD中我们非常强调这两者之间的区别。
实体对象表示的是具有一定生命周期并且拥有全局唯一标识(ID)的对象,比如本文中的Order和Product,而值对象表示用于起描述性作用的,没有唯一标识的对象,比如Address对象。
聚合根一定是实体对象,但是并不是所有实体对象都是聚合根,同时聚合根还可以拥有其他子实体对象。聚合根的ID在整个软件系统中全局唯一,而其下的子实体对象的ID只需在单个聚合根下唯一即可。在本文示例项目中,OrderItem是聚合根Order下的子实体对象:
public class OrderItem {
private ProductId productId;
private int count;
private BigDecimal itemPrice;
}
可以看到,虽然OrderItem使用了ProductID作为ID,但是此时我们并没有享受ProductID的全局唯一性,事实上多个Order可以包含相同ProductID的OrderItem,也即多个订单可以包含相同的产品。
区分实体和值对象的一个很重要的原则便是根据相等性来判断,实体对象的相等性是通过ID来完成的,对于两个实体,如果他们的所有属性均相同,但是ID不同,那么他们依然两个不同的实体,就像一对长得一模一样的双胞胎,他们依然是两个不同的自然人。对于值对象来说,相等性的判断是通过属性字段来完成的。比如,订单下的送货地址Address对象便是一个典型的值对象:
public class Address {
private String province;
private String city;
private String detail;
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Address address = (Address) o;
return province.equals(address.province) &&
city.equals(address.city) &&
detail.equals(address.detail);
}
@Override
public int hashCode() {
return Objects.hash(province, city, detail);
}
}
在Address的equals()方法中,通过判断Address所包含的所有属性(province,city,detail)来决定两个Address的相等性。
值对象还有一个特点是不变的(Immutable),也就说一个值对象一旦被创建出来了便不能对其进行变更,如果要变更,必须重新创建一个新的值对象整体替换原有的。比如,示例项目有一个业务需求:
在订单未支付的情况下,可以修改订单送货地址的详细地址(detail)
由于Address是Order聚合根中的一个对象,对Address的更改只能通过Order完成,在Order中实现changeAddressDetail()方法:
public void changeAddressDetail(String detail) {
if (this.status == PAID) {
throw new OrderCannotBeModifiedException(this.id);
}
this.address = this.address.changeDetailTo(detail);
}
可以看到,通过调用address.changeDetailTo()方法,我们获取到了一个全新的Address对象,然后将新的Address对象整体赋值给address属性。此时Address.changeDetailTo()的实现如下:
public Address changeDetailTo(String detail) {
return new Address(this.province, this.city, detail);
}
这里的changeDetailTo()方法使用了新的详细地址detail和未发生变更的province、city重新创建出了一个Address对象。
值对象的不变性使得程序的逻辑变得更加简单,你不用去维护复杂的状态信息,需要的时候创建,不要的时候直接扔掉即可,使得值对象就像程序中的过客一样。在DDD建模中,一种受推崇的做法便是将业务概念尽量建模为值对象。
对于OrderItem来说,由于我们的业务需要对OrderItem的数量进行修改,也即拥有生命周期的意味,因此本文将OrderItem建模为了实体对象。但是,如果没有这样的业务需求,那么将OrderItem建模为值对象应该更合适一些。
另外,需要指明的是,实体和值对象的划分并不是一成不变的,而应该根据所处的限界上下文来界定,相同一个业务名词,在一个限界上下文中可能是实体,在另外的限界上下文中可能是值对象。比如,订单Order在采购上下文中应该建模为一个实体,但是在物流上下文中便可建模为一个值对象。
聚合根的家——资源库
通俗点讲,资源库(Repository)就是用来持久化聚合根的。从技术上讲,Repository和DAO所扮演的角色相似,不过DAO的设计初衷只是对数据库的一层很薄的封装,而Repository是更偏向于领域模型。另外,在所有的领域对象中,只有聚合根才“配得上”拥有Repository,而DAO没有这种约束。
实现Order的资源库OrderRepository如下:
public void save(Order order) {
String sql = "INSERT INTO ORDERS (ID, JSON_CONTENT) VALUES (:id, :json) " +
"ON DUPLICATE KEY UPDATE JSON_CONTENT=:json;";
Map<String, String> paramMap = of("id", order.getId().toString(), "json", objectMapper.writeValueAsString(order));
jdbcTemplate.update(sql, paramMap);
}
public Order byId(OrderId id) {
try {
String sql = "SELECT JSON_CONTENT FROM ORDERS WHERE ID=:id;";
return jdbcTemplate.queryForObject(sql, of("id", id.toString()), mapper());
} catch (EmptyResultDataAccessException e) {
throw new OrderNotFoundException(id);
}
}
在OrderRepository中,我们只定义了save()和byId()方法,分别用于保存/更新聚合根和通过ID获取聚合根。这两个方法是Repository中最常见的方法,有的DDD实践者甚至认为一个纯粹的Repository只应该包含这两个方法。
读到这里,你可能会有些疑问:为什么OrderRepository中没有更新和查询等方法?事实上,Repository所扮演的角色只是向领域模型提供聚合根而已,就像一个聚合根的“容器”一样,这个“容器”本身并不关心客户端对聚合根的操作到底是新增还是更新,你给一个聚合根对象,Repository只是负责将其状态从计算机的内存同步到持久化机制中,从这个角度讲,Repository只需要一个类似save()的方法便可完成同步操作。当然,这个是从概念的出发点得出的设计结果,在技术层面,新增和更新还是需要区别对待,比如SQL语句有insert和update之分,只是我们将这样的技术细节隐藏在了save()方法中,客户方并无需知道这些细节。在本例中,我们通过MySQL的ON DUPLICATE KEY UPDATE特性同时处理对数据库的新增和更新操作。当然,我们也可以通过编程判断聚合根在数据库中是否已经存在,如果存在则update,否则insert。另外,诸如Hibernate这样的持久化框架自动提供saveOrUpate()方法可以直接用于对聚合根的持久化。
对于查询功能来说,在Repository中实现查询本无不合理之处,然而项目的演进可能导致Repository中充斥着大量的查询代码“喧宾夺主”似的掩盖了Repository原本的目的。事实上,DDD中读操作和写操作是两种很不一样的过程,笔者的建议是尽量将此二者分开实现,由此查询功能将从Repository中分离出去,在下文中我将详细讲到。
在本例中,我们在技术实现上使用到了Spring的JdbcTemplate和JSON格式持久化Order聚合根,其实Repository并不与某种持久化机制绑定,一个被抽象出来的Repository向外暴露的功能“接口”始终是向领域模型提供聚合根对象,就像“聚合根的家”一样。
好了,至此让我们来做个回顾,上文中我们以“更新Order中的Product数量”业务需求为例,讲到了应用服务、聚合根和资源库,对该业务需求的处理流程体现了DDD处理业务需求的最常见最典型的形式:
应用服务作为总体协调者,先通过资源库获取到聚合根,然后调用聚合根中的业务方法,最后再次调用资源库保存聚合根。
流程示意图如下:
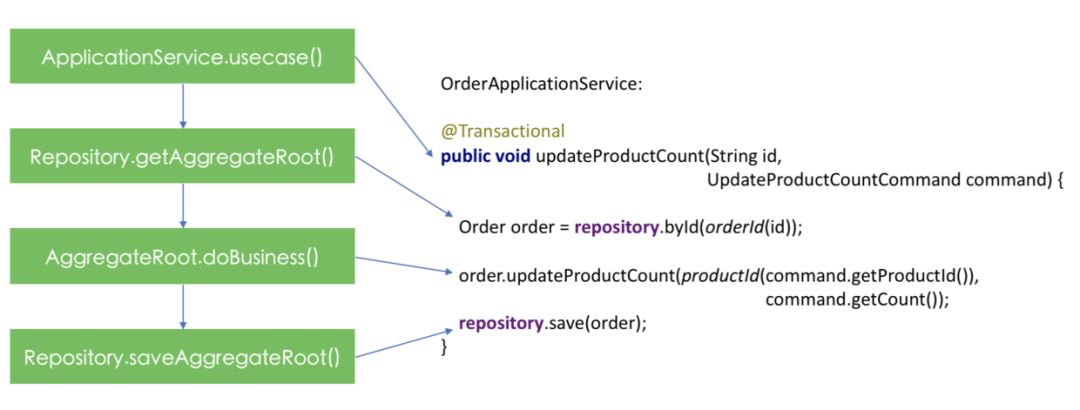
(DDD处理业务流程的典型流程)
创生之柱——工厂
稍微提炼一下,我们便知道软件里面的写操作要么是修改既有数据,要么是新建数据。对于前者,DDD给出的答案已经在上文中讲到,接下来我们讲讲在DDD中如何新建聚合根。
创建聚合根通常通过设计模式中的工厂(Factory)模式完成,这一方面可以享受到工厂模式本身的好处,另一方面,DDD中的Factory还具有将“聚合根的创建逻辑”显现出来的效果。

(创生之柱——恒星诞生的地方,距地球约6500光年,由哈勃太空望远镜于1995年拍摄)
聚合根的创建过程可简单可复杂,有时可能直接调用构造函数即可,而有时却存在一个复杂的构造流程,比如需要调用其他系统获取数据等。通常来讲,Factory有两种实现方式:
-
直接在聚合根中实现Factory方法,常用于简单的创建过程
-
独立的Factory类,用于有一定复杂度的创建过程,或者创建逻辑不适合放在聚合根上
让我们先演示一下简单的Factory方法,在示例订单系统中,有个业务用例是“创建Product”:
创建Product,属性包括名称(name),描述(description)和单价(price),ProductId为UUID
在Product类中实现工厂方法create():
public static Product create(String name, String description, BigDecimal price) {
return new Product(name, description, price);
}
private Product(String name, String description, BigDecimal price) {
this.id = ProductId.newProductId();
this.name = name;
this.description = description;
this.price = price;
this.createdAt = Instant.now();
}
这里,Product中的create()方法并不包含创建逻辑,而是将创建过程直接代理给了Product的构造函数。你可能觉得这个create()方法有些多此一举,然而这种做法的初衷依然是:我们希望将聚合根的创建逻辑突显出来。构造函数本身是一个非常技术的东西,任何地方只要涉及到在计算机内存中新建对象都需要使用构造函数,无论创建的初始原因是业务需要,还是从数据库加载,亦或是从JSON数据反序列化。因此程序中往往存在多个构造函数用于不同的场景,而为了将业务上的创建与技术上的创建区别开来,我们引入了create()方法用于表示业务上的创建过程。
“创建Product”所设计到的Factory的确简单,让我们再来看看另外一个例子:“创建Order”:
创建Order,包含用户选择的Product及其数量,OrderId必须调用第三方的OrderIdGenerator获取
这里的OrderIdGenerator是具有服务性质的对象(即下文中的领域服务),在DDD中,聚合根通常不会引用其他服务类。另外,调用OrderIdGenerator生成ID应该是一个业务细节,如前文所讲,这种细节不应该放在ApplicationService中。此时,可以通过Factory类来完成Order的创建:
@Component
public class OrderFactory {
private final OrderIdGenerator idGenerator;
public OrderFactory(OrderIdGenerator idGenerator) {
this.idGenerator = idGenerator;
}
public Order create(List<OrderItem> items, Address address) {
OrderId orderId = idGenerator.generate();
return Order.create(orderId, items, address);
}
}
必要的妥协——领域服务
前面我们提到,聚合根是业务逻辑的主要载体,也就是说业务逻辑的实现代码应该尽量地放在聚合根或者聚合根的边界之内。但有时,有些业务逻辑并不适合于放在聚合根上,比如前文的OrderIdGenerator便是如此,在这种“迫不得已”的情况下,我们引入领域服务(Domain Service)。还是先来看一个列子,对于Order的支付有以下业务用例:
通过支付网关OrderPaymentService完成Order的支付。
在OrderApplicationService中,直接调用领域服务OrderPaymentService:
@Transactional
public void pay(String id, PayOrderCommand command) {
Order order = orderRepository.byId(orderId(id));
orderPaymentService.pay(order, command.getPaidPrice());
orderRepository.save(order);
}
然后实现OrderPaymentService:
public void pay(Order order, BigDecimal paidPrice) {
order.pay(paidPrice);
paymentProxy.pay(order.getId(), paidPrice);
}
这里的PaymentProxy与OrderIdGenerator相似,并不适合于放在Order中。可以看到,在OrderApplicationService中,我们并没有直接调用Order中的业务方法,而是先调用OrderPaymentService.pay(),然后在OrderPaymentService.pay()中完成调用支付网关PaymentProxy.pay()这样的业务细节。
到此,再来反观在通常的实践中我们编写的Service类,事实上这些Servcie类将DDD中的ApplicationService和DomainService糅合在了一起,比如在”基于Service + 贫血模型”的实现“小节中的OrderService便是如此。在DDD中,ApplicationService和DomainService是两个很不一样的概念,前者是必须有的DDD组件,而后者只是一种妥协的结果,因此程序中的DomainService应该越少越好。
Command对象
通常来说,DDD中的写操作并不需要向客户端返回数据,在某些情况下(比如新建聚合根)可以返回一个聚合根的ID,这意味着ApplicationService或者聚合根中的写操作方法通常返回void即可。比如,对于OrderApplicationService,各个方法签名如下:
public OrderId createOrder(CreateOrderCommand command) ;
public void changeProductCount(String id, ChangeProductCountCommand command) ;
public void pay(String id, PayOrderCommand command) ;
public void changeAddressDetail(String id, String detail) ;
可以看到,在多数情况下我们使用了后缀为Command的对象传给ApplicationService,比如CreateOrderCommand和ChangeProductCountCommand。Command即命令的意思,也即写操作表示的是外部向领域模型发起的一次命令操作。事实上,从技术上讲,Command对象只是一种类型的DTO对象,它封装了客户端发过来的请求数据。在Controller中所接收的所有写操作都需要通过Command进行包装,在Command比较简单(比如只有1-2个字段)的情况下Controller可以将Command解开之后,将其中的数据直接传递给ApplicationService,比如changeAddressDetail()便是如此;而在Command中数据字段比较多时,可以直接将Command对象传递给ApplicationService。当然,这并不是DDD中需要严格遵循的一个原则,比如无论Command的简繁程度,统一将所有Command从Controller传递给ApplicationService,也不存在太大的问题,更多的只是一个编码习惯上的选择。不过有一点需要强调,即前文提到的“ApplicationService需要接受原始数据类型而不是领域模型中的对象”,在这里意味着Command对象中也应该包含原始的数据类型。
统一使用Command对象还有个好处是,我们通过查找所有后缀为Command的对象,便可以概览性地了解软件系统向外提供的业务功能。
阶段性小结一下,以上我们主要围绕着软件的“写操作”在DDD中的实现进行讨论,并且讲到了3种场景,分别是:
-
通过聚合根完成业务请求
-
通过Factory完成聚合根的创建
-
通过DomainService完成业务请求
以上3种场景大致上涵盖了DDD完成业务写操作的基本方面,总结下来3句话:创建聚合根通过Factory完成;业务逻辑优先在聚合根边界内完成;聚合根中不合适放置的业务逻辑才考虑放到DomainService中。
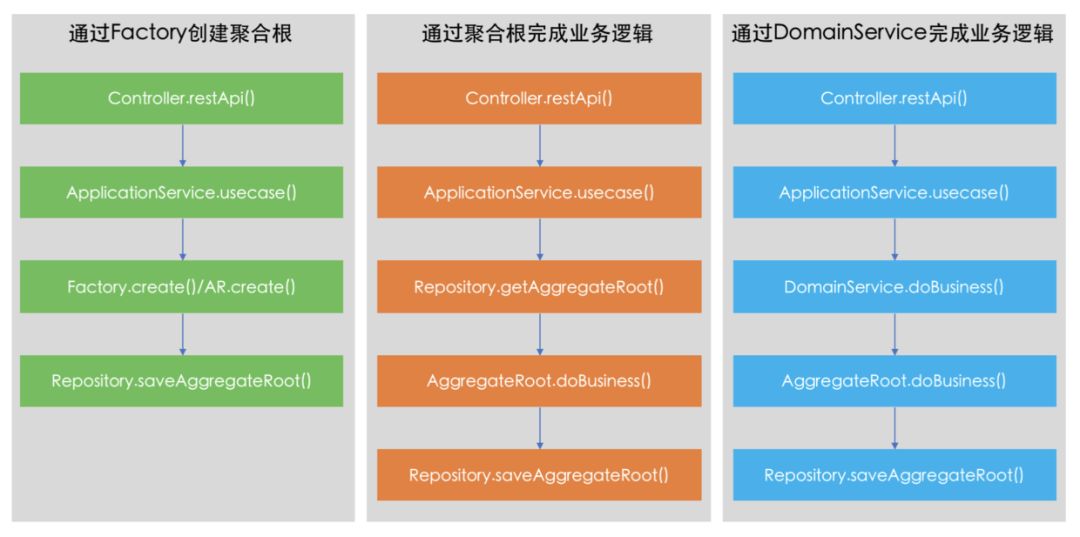
(DDD实现软件"写操作"的3种场景)
DDD中的读操作
软件中的读模型和写模型是很不一样的,我们通常所讲的业务逻辑更多的时候是在写操作过程中需要关注的东西,而读操作更多关注的是如何向客户方返回恰当的数据展现。
在DDD的写操作中,我们需要严格地按照“应用服务 -> 聚合根 -> 资源库”的结构进行编码,而在读操作中,采用与写操作相同的结构有时不但得不到好处,反而使整个过程变得冗繁。这里介绍3种读操作的方式:
-
基于领域模型的读操作
-
基于数据模型的读操作
-
CQRS
首先,无论哪种读操作方式,都需要遵循一个原则:领域模型中的对象不能直接返回给客户端,因为这样领域模型的内部便暴露给了外界,而对领域模型的修改将直接影响到客户端。因此,在DDD中我们通常为读操作专门创建相应的模型用于数据展现。在写操作中,我们通过Command后缀进行请求数据的统一,在读操作中,我们通过Representation后缀进行展现数据的统一,这里的Representation也即REST中的“R”。
基于领域模型的读操作
这种方式将读模型和写模型糅合到一起,先通过资源库获取到领域模型,然后将其转换为Representation对象,这也是当前被大量使用的方式,比如对于“获取Order详情的接口”,OrderApplicationService实现如下:
@Transactional(readOnly = true)
public OrderRepresentation byId(String id) {
Order order = orderRepository.byId(orderId(id));
return orderRepresentationService.toRepresentation(order);
}
我们先通过orderRepository.byId()获取到Order聚合根对象,然后调用
orderRepresentationService.toRepresentation()将Order转换为展现对象OrderRepresentation,
OrderRepresentationService.toRepresentation()实现如下:
public OrderRepresentation toRepresentation(Order order) {
List<OrderItemRepresentation> itemRepresentations = order.getItems().stream()
.map(orderItem -> new OrderItemRepresentation(orderItem.getProductId().toString(),
orderItem.getCount(),
orderItem.getItemPrice()))
.collect(Collectors.toList());
return new OrderRepresentation(order.getId().toString(),
itemRepresentations,
order.getTotalPrice(),
order.getStatus(),
order.getCreatedAt());
}
这种方式的优点是非常直接明了,也不用创建新的数据读取机制,直接使用Repository读取数据即可。然而缺点也很明显:一是读操作完全束缚于聚合根的边界划分,比如,如果客户端需要同时获取Order及其所包含的Product,那么我们需要同时将Order聚合根和Product聚合根加载到内存再做转换操作,这种方式既繁琐又低效;二是在读操作中,通常需要基于不同的查询条件返回数据,比如通过Order的日期进行查询或者通过Product的名称进行查询等,这样导致的结果是Repository上处理了太多的查询逻辑,变得越来越复杂,也逐渐偏离了Repository本应该承担的职责。
基于数据模型的读操作
这种方式绕开了资源库和聚合,直接从数据库中读取客户端所需要的数据,此时写操作和读操作共享的只是数据库。比如,对于“获取Product列表”接口,通过一个专门的ProductRepresentationService直接从数据库中读取数据:
@Transactional(readOnly = true)
public PagedResource<ProductSummaryRepresentation> listProducts(int pageIndex, int pageSize) {
MapSqlParameterSource parameters = new MapSqlParameterSource();
parameters.addValue("limit", pageSize);
parameters.addValue("offset", (pageIndex - 1) * pageSize);
List<ProductSummaryRepresentation> products = jdbcTemplate.query(SELECT_SQL, parameters,
(rs, rowNum) -> new ProductSummaryRepresentation(rs.getString("ID"),
rs.getString("NAME"),
rs.getBigDecimal("PRICE")));
int total = jdbcTemplate.queryForObject(COUNT_SQL, newHashMap(), Integer.class);
return PagedResource.of(total, pageIndex, products);
}
然后在Controller中直接返回:
@GetMapping
public PagedResource<ProductSummaryRepresentation> pagedProducts(@RequestParam(required = false, defaultValue = "1") int pageIndex,
@RequestParam(required = false, defaultValue = "10") int pageSize) {
return productRepresentationService.listProducts(pageIndex, pageSize);
}
可以看到,真个过程并没有使用到ProductRepository和Product,而是将SQL获取到的数据直接新建为ProductSummaryRepresentation对象。
这种方式的优点是读操作的过程不用囿于领域模型,而是基于读操作本身的需求直接获取需要的数据即可,一方面简化了整个流程,另一方面大大提升了性能。但是,由于读操作和写操作共享了数据库,而此时的数据库主要是对应于聚合根的结构创建的,因此读操作依然会受到写操作的数据模型的牵制。不过这种方式是一种很好的折中,微软也提倡过这种方式,更多细节请参考微软官网。
CQRS
CQRS(Command Query Responsibility Segregation),即命令查询职责分离,这里的命令可以理解为写操作,而查询可以理解为读操作。与“基于数据模型的读操作”不同的是,在CQRS中写操作和读操作使用了不同的数据库,数据从写模型数据库同步到读模型数据库,通常通过领域事件的形式同步变更信息。
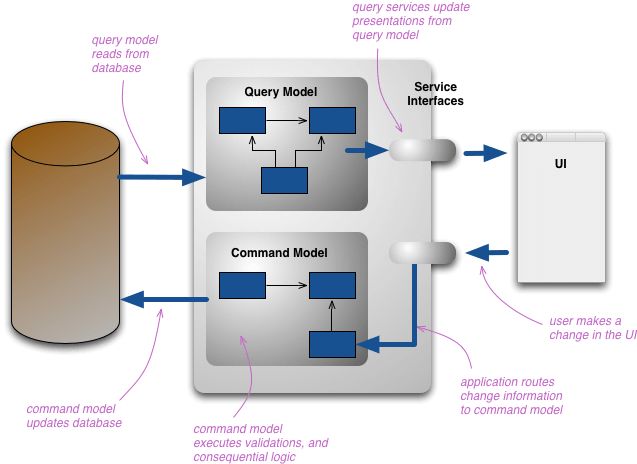
(CQRS架构)
这样一来,读操作便可以根据自身所需独立设计数据结构,而不用受写模型数据结构的牵制。CQRS本身是一个很大的话题,已经超出了本文的范围,读者可以自行研究。
到此,DDD中的读操作可以大致分为3种实现方式:
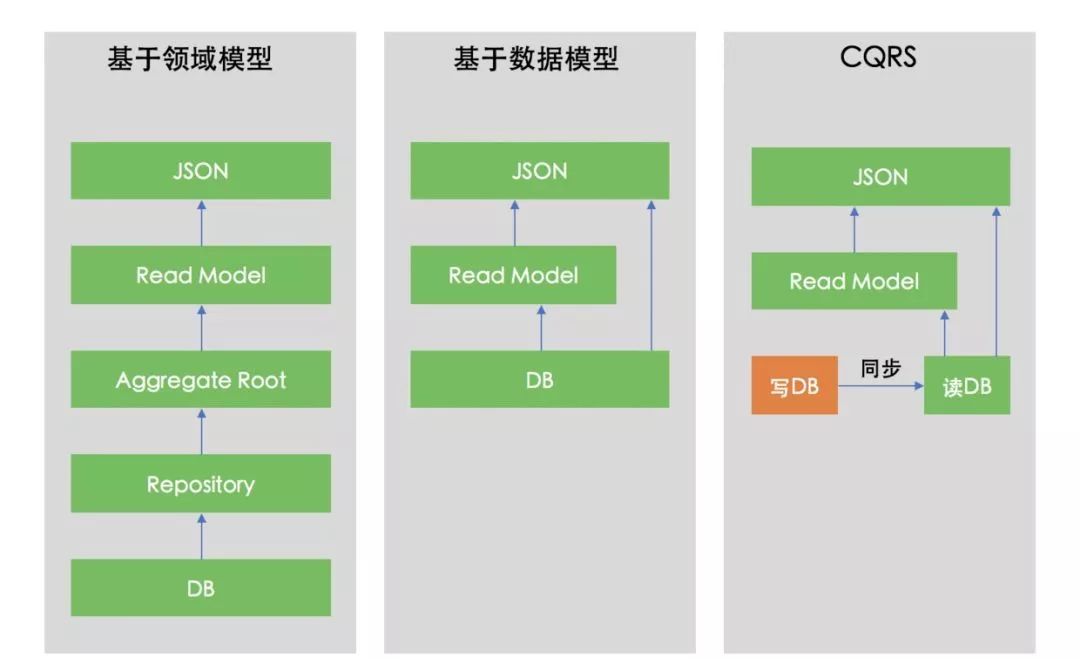
(DDD读操作的3种实现方式)
总结
本文主要介绍了DDD中的应用服务、聚合、资源库和工厂等概念以及与它们相关的编码实践,然后着重讲到了软件的读写操作在DDD中的实现方式,其中写操作的3种场景为:
-
通过聚合根完成业务请求,这是DDD完成业务请求的典型方式
-
通过Factory完成聚合根的创建,用于创建聚合根
-
通过DomainService完成业务请求,当业务放在聚合根中不合适时才考虑放在DomainService中
对于读操作,同样给出了3种方式:
-
基于领域模型的读操作(读写操作糅合在了一起,不推荐)
-
基于数据模型的读操作(绕过聚合根和资源库,直接返回数据,推荐)
-
CQRS(读写操作分别使用不同的数据库)
以上“3读3写”基本上涵盖了程序员完成业务功能的日常开发之所需,原来DDD就这么简单,不是吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号