
LINUS:为何对象引用计数必须是原子的,利用二级指针删除单向链表
Linus大神又在rant了!这次的吐槽对象是时下很火热的并行技术(parellism),并直截了当地表示并行计算是浪费所有人时间(“The whole “let’s parallelize” thing is a huge waste of everybody’s time.”)。大致意思是说乱序性能快、提高缓存容量、降功耗。当然笔者不打算正面讨论并行的是是非非(过于宏伟的主题),因为Linus在另一则帖子中举了对象引用计数(reference counting)的例子来说明并行的复杂性。
在Linus回复之前有人指出对象需要锁机制的情况下,引用计数的原子性问题:
Since it is being accessed in a multi-threaded way, via multiple access paths, generally it needs its own mutex — otherwise, reference counting would not be required to be atomic and a lock of a higher-level object would suffice.
由于(对象)通过多线程方式及多种获取渠道,一般而言它需要自身维护一个互斥锁——否则引用计数就不要求是原子的,一个更高层次的对象锁足矣。
而Linus不那么认为:
The problem with reference counts is that you often need to take them *before* you take the lock that protects the object data.
引用计数的问题在于你经常需要在对象数据上锁保护之前完成它。
The thing is, you have two different cases:
问题有两种情况:
– object *reference* 对象引用
– object data 对象数据
and they have completely different locking.
它们锁机制是完全不一样的。
Object data locking is generally per-object. Well, unless you don’t have huge scalability issues, in which case you may have some external bigger lock (extreme case: one single global lock).
对象数据保护一般是一个对象拥有一个锁,假设你没有海量扩展性问题,不然你需要一些外部大一点的锁(极端的例子,一个对象一个全局锁)。
But object *referencing* is mostly about finding the object (and removing/freeing it). Is it on a hash chain? Is it in a tree? Linked list? When the reference count goes down to zero, it’s not the object data that you need to protect (the object is not used by anything else, so there’s nothing to protect!), it’s the ways to find the object you need to protect.
但对象引用主要关于对象的寻找(移除或释放),它是否在哈希链,一棵树或者链表上。当对象引用计数降为零,你要保护的不是对象数据,因为对象没有在其它地方使用,你要保护的是对象的寻找操作。
And the lock for the lookup operation cannot be in the object, because – by definition – you don’t know what the object is! You’re trying to look it up, after all.
而且查询操作的锁不可能在对象内部,因为根据定义,你还不知道这是什么对象,你在尝试寻找它。
So generally you have a lock that protects the lookup operation some way, and the reference count needs to be atomic with respect to that lock.
因此一般你要对查询操作上锁,而且引用计数相对那个锁来说是原子的(译者注:查询锁不是引用计数所在的对象所有,不能保护对象引用计数,后面会解释为何引用计数变更时其所在对象不能上锁)。
And yes, that lock may well be sufficient, and now you’re back to non-atomic reference counts. But you usually don’t have just one way to look things up: you might have pointers from other objects (and that pointer is protected by the object locking of the other object), but there may be multiple such objects that point to this (which is why you have a reference count in the first place!)
当然这个锁是充分有效的,现在假设引用计数是非原子的,但你常常不仅仅使用一种方式来查询:你可能拥有其它对象的指针(这个指针又被其它对象的对象锁给保护起来),但同时还会有多个对象指向它(这就是为何你第一时间需要引用计数的理由)。
See what happens? There is no longer one single lock for lookup. Imagine walking a graph of objects, where objects have pointers to each other. Each pointer implies a reference to an object, but as you walk the graph, you have to release the lock from the source object, so you have to take a new reference to the object you are now entering.
看看会发生什么?查询不止存在一个锁保护。你可以想象走过一张对象流程图,其中对象存在指向其它对象的指针,每个指针暗含了一次对象引用,但当你走过这个流程图,你必须释放源对象的锁,而你进入新对象时又必须增加一次引用。
And in order to avoid deadlocks, you can not in the general case take the lock of the new object first – you have to release the lock on the source object, because otherwise (in a complex graph), how do you avoid simple ABBA deadlock?
而且为了避免死锁,你一般不能立即对新对象上锁——你必须释放源对象的锁,否则在一个复杂流程图里,你如何避免ABBA死锁(译者注:假设两个线程,一个是A->B,另一个B->;A,当线程一给A上锁,线程二给B上锁,此时两者谁也无法释放对方的锁)?
So atomic reference counts fix that. They work because when you move from object A to object B, you can do this:
原子引用计数修正了这一点,当你从对象A到对象B,你会这样做:
(a) you have a reference count to A, and you can lock A
对象A增加一次引用计数,并上锁。
(b) once object A is locked, the pointer from A to B is stable, and you know you have a reference to B (because of that pointer from A to B)
对象A一旦上锁,A指向B的指针就是稳定的,于是你知道你引用了对象B。
(c) but you cannot take the object lock for B (ABBA deadlock) while holding the lock on A
但你不能在对象A上锁期间给B上锁(ABBA死锁)。
(d) increment the atomic reference count on B
对象B增加一次原子引用计数。
(e) now you can drop the lock on A (you’re “exiting” A)
现在你可以扔掉对象A的锁(退出对象A)。
(f) your reference count means that B cannot go away from under you despite unlocking A, so now you can lock B.
对象B的原子引用计数意味着即使给A解锁期间,B也不会失联,现在你可以给B上锁。
See? Atomic reference counts make this kind of situation possible. Yes, you want to avoid the overhead if at all possible (for example, maybe you have a strict ordering of objects, so you know you can walk from A to B, and never walk from B to A, so there is no ABBA deadlock, and you can just lock B while still holding the lock on A).
看见了吗?原子引用计数使这种情况成为可能。是的,你想尽一切办法避免这种代价,比如,你也许把对象写成严格顺序的,这样你可以从A到B,绝不会从B到A,如此就不存在ABBA死锁了,你也就可以在A上锁期间给B上锁了。
But if you don’t have some kind of forced ordering, and if you have multiple ways to reach an object (and again – why have reference counts in the first place if that isn’t true!) then atomic reference counts really are the simple and sane answer.
但如果你无法做到这种强迫序列,如果你有多种方式接触一个对象(再一次强调,这是第一时间使用引用计数的理由),这样,原子引用计数就是简单又理智的答案。
If you think atomic refcounts are unnecessary, that’s a big flag that you don’t actually understand the complexities of locking.
如果你认为原子引用计数是不必要的,这就大大说明你实际上不了解锁机制的复杂性。
Trust me, concurrency is hard. There’s a reason all the examples of “look how easy it is to parallelize things” tend to use simple arrays and don’t ever have allocations or freeing of the objects.
相信我,并发设计是困难的。所有关于“并行化如此容易”的理由都倾向于使用简单数组操作做例子,甚至不包含对象的分配和释放。
People who think that the future is highly parallel are invariably completely unaware of just how hard concurrency really is. They’ve seen Linpack, they’ve seen all those wonderful examples of sorting an array in parallel, they’ve seen all these things that have absolutely no actual real complexity – and often very limited real usefulness.
那些认为未来是高度并行化的人一成不变地完全没有意识到并发设计是多么困难。他们只见过Linpack,他们只见过并行技术中关于数组排序的一切精妙例子,他们只见过一切绝不算真正复杂的事物——对真正的用处经常是非常有限的。
(译者注:当然,我无意借大神之口把技术宗教化。实际上Linus又在另一篇帖子中综合了对并行的评价。)
Oh, I agree. My example was the simple case. The really complex cases are much worse.
哦,我同意。我的例子还算简单,真正复杂的用例更糟糕。
I seriously don’t believe that the future is parallel. People who think you can solve it with compilers or programming languages (or better programmers) are so far out to lunch that it’s not even funny.
我严重不相信未来是并行的。有人认为你可以通过编译器,编程语言或者更好的程序员来解决问题,他们目前都是神志不清,没意识到这一点都不有趣。
Parallelism works well in simplified cases with fairly clear interfaces and models. You find parallelism in servers with independent queries, in HPC, in kernels, in databases. And even there, people work really hard to make it work at all, and tend to expressly limit their models to be more amenable to it (eg databases do some things much better than others, so DB admins make sure that they lay out their data in order to cater to the limitations).
并行计算可以在简化的用例以及具备清晰的接口和模型上正常工作。你发现并行在服务器上独立查询里,在高性能计算(High-performance computing)里,在内核里,在数据库里。即使如此,人们还得花很大力气才能使它工作,并且还要明确限制他们的模型来尽更多义务(例如数据库要想做得更好,数据库管理员得确保数据得到合理安排来迎合局限性)。
Of course, other programming models can work. Neural networks are inherently very parallel indeed. And you don’t need smarter programmers to program them either..
当然,其它编程模型倒能派上用场,神经网络(neural networking)天生就是非常并行化的,你不需要更聪明的程序员为之写代码。
参考资料
- Real World Technologies:Linus常去“灌水”的一个论坛,讨论未来机器架构(看名字就知道Linus技术偏好,及其之前对虚拟化技术(virtualization)的吐槽)
- 多线程程序中操作的原子性:解释为什么i++不是原子操作
- Concurrency Is Not Parallelism:Go语言之父Rob Pike幻灯片解释“并发”与“并行”概念上的区别
由于它是通过多线程方式访问的,通过多个访问路径,
> 通常它需要它的自己的互斥锁——否则,引用计数不需要
> 是原子的,并且更高级别对象的锁就足够
了 引用计数的问题是你经常需要*在*之前*你获取保护对象的锁对象数据。
问题是,您有两种不同的情况:
- 对象 *引用*
- 对象数据
,它们具有完全不同的锁定。
对象数据锁定通常是针对每个对象的。好吧,除非你没有巨大的可扩展性问题,在这种情况下你可能有一些外部更大的锁(极端情况:一个全局锁)。
但是对象*引用*主要是关于找到对象(并删除/释放它)。它在哈希链上吗?是在一棵树上吗?链表?当引用计数下降到零时,您需要保护的不是对象数据(该对象没有被其他任何东西使用,所以没有什么需要保护的!),而是找到您需要保护的对象的方法。
并且查找操作的锁不能在对象中,因为——根据定义——你不知道对象是什么!毕竟,您正在尝试查找它。
所以通常你有一个以某种方式保护查找操作的锁,并且引用计数需要相对于该锁是原子的。
是的,那个锁可能就足够了,现在你又回到了非原子引用计数。但是您通常只有一种查找方式:您可能有来自其他对象的指针(并且该指针受其他对象的对象锁定保护),但可能有多个这样的对象指向 this (这就是为什么你首先有一个引用计数!)。
走着瞧吧?不再有一个用于查找的锁。想象一下在对象图上行走,其中对象之间有相互的指针。每个指针都隐含着一个对象的引用,但是当你走图时,你必须从源对象释放锁,所以你必须对你现在输入的对象进行一个新的引用。
并且为了避免死锁,在一般情况下,您不能先获取新对象的锁 - 您必须释放源对象上的锁,否则(在复杂图中),您如何避免简单的 ABBA 死锁?
所以原子引用计数解决了这个问题。它们起作用是因为当您从对象 A 移动到对象 B 时,您可以这样做:
(a) 您有对 A 的引用计数,并且您可以锁定 A
(b) 一旦对象 A 被锁定,从 A 到 B 的指针是稳定的,并且您知道您有对 B 的引用(因为从 A 到 B 的指针)
(c) 但是您不能为 B 获取对象锁( ABBA 死锁)同时保持 A 上的锁
(d)增加 B 上的原子引用计数
(e)现在你可以取消 A 上的锁(你“退出”A)
(f)你的引用计数意味着 B 不能去尽管解锁了 A,但仍然远离你,所以现在你可以锁定 B。
看到了吗?原子引用计数使这种情况成为可能。是的,您希望尽可能避免开销(例如,也许您对对象有严格的排序,因此您知道可以从 A 走到 B,而永远不会从 B 走到 A,因此没有 ABBA 死锁,并且您可以在仍然保持对 A 的锁定的同时锁定 B)。
但是,如果您没有某种强制排序,并且如果您有多种方法可以访问一个对象(再说一次 - 如果这不是真的,为什么首先要使用引用计数!)那么原子引用计数确实是简单而理智的答案。
如果您认为原子引用计数是不必要的,那么这是一个很大的标志,表明您实际上并不了解锁定的复杂性。
相信我,并发很难。所有“看看并行化事物是多么容易”的例子都倾向于使用简单的数组并且从来没有分配或释放对象是有原因的。
认为未来高度并行的人总是完全不知道并发到底有多难。他们见过 Linpack,他们见过所有那些并行排序数组的绝妙例子,他们见过所有这些完全没有实际复杂性的东西——而且通常非常有限的实际用途。
Linus:利用二级指针删除单向链表 | 酷 壳 - CoolShell
感谢网友full_of_bull投递此文(注:此文最初发表在这个这里,我对原文后半段修改了许多,并加入了插图)
Linus大婶在slashdot上回答一些编程爱好者的提问,其中一个人问他什么样的代码是他所喜好的,大婶表述了自己一些观点之后,举了一个指针的例子,解释了什么才是core low-level coding。
下面是Linus的教学原文及翻译——
“At the opposite end of the spectrum, I actually wish more people understood the really core low-level kind of coding. Not big, complex stuff like the lockless name lookup, but simply good use of pointers-to-pointers etc. For example, I’ve seen too many people who delete a singly-linked list entry by keeping track of the “prev” entry, and then to delete the entry, doing something like。(在这段话的最后,我实际上希望更多的人了解什么是真正的核心底层代码。这并不像无锁文件名查询(注:可能是git源码里的设计)那样庞大、复杂,只是仅仅像诸如使用二级指针那样简单的技术。例如,我见过很多人在删除一个单项链表的时候,维护了一个”prev”表项指针,然后删除当前表项,就像这样)”
and whenever I see code like that, I just go “This person doesn’t understand pointers”. And it’s sadly quite common.(当我看到这样的代码时,我就会想“这个人不了解指针”。令人难过的是这太常见了。)
People who understand pointers just use a “pointer to the entry pointer”, and initialize that with the address of the list_head. And then as they traverse the list, they can remove the entry without using any conditionals, by just doing a “*pp = entry->next”. (了解指针的人会使用链表头的地址来初始化一个“指向节点指针的指针”。当遍历链表的时候,可以不用任何条件判断(注:指prev是否为链表头)就能移除某个节点,只要写)
So there’s lots of pride in doing the small details right. It may not be big and important code, but I do like seeing code where people really thought about the details, and clearly also were thinking about the compiler being able to generate efficient code (rather than hoping that the compiler is so smart that it can make efficient code *despite* the state of the original source code). (纠正细节是令人自豪的事。也许这段代码并非庞大和重要,但我喜欢看那些注重代码细节的人写的代码,也就是清楚地了解如何才能编译出有效代码(而不是寄望于聪明的编译器来产生有效代码,即使是那些原始的汇编代码))。
Linus举了一个单向链表的例子,但给出的代码太短了,一般的人很难搞明白这两个代码后面的含义。正好,有个编程爱好者阅读了这段话,并给出了一个比较完整的代码。他的话我就不翻译了,下面给出代码说明。
如果我们需要写一个remove_if(link*, rm_cond_func*)的函数,也就是传入一个单向链表,和一个自定义的是否删除的函数,然后返回处理后的链接。
这个代码不难,基本上所有的教科书都会提供下面的代码示例,而这种写法也是大公司的面试题标准模板:
这里remove_fn由调用查提供的一个是否删除当前实体结点的函数指针,其会判断删除条件是否成立。这段代码维护了两个节点指针prev和curr,标准的教科书写法——删除当前结点时,需要一个previous的指针,并且还要这里还需要做一个边界条件的判断——curr是否为链表头。于是,要删除一个节点(不是表头),只要将前一个节点的next指向当前节点的next指向的对象,即下一个节点(即:prev->next = curr->next),然后释放当前节点。
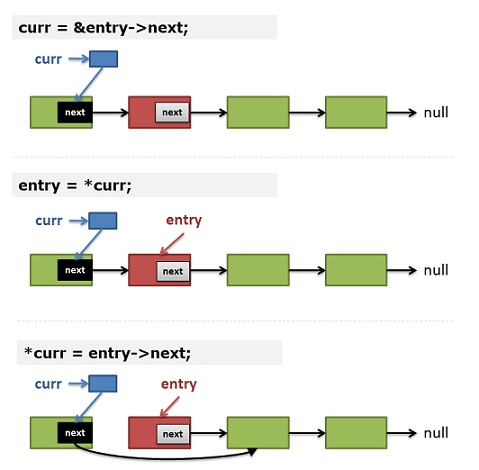
但在Linus看来,这是不懂指针的人的做法。那么,什么是core low-level coding呢?那就是有效地利用二级指针,将其作为管理和操作链表的首要选项。代码如下:
同上一段代码有何改进呢?我们看到:不需要prev指针了,也不需要再去判断是否为链表头了,但是,curr变成了一个指向指针的指针。这正是这段程序的精妙之处。(注意,我所highlight的那三行代码)
让我们来人肉跑一下这个代码,对于——
- 删除节点是表头的情况,输入参数中传入head的二级指针,在for循环里将其初始化curr,然后entry就是*head(*curr),我们马上删除它,那么第8行就等效于*head = (*head)->next,就是删除表头的实现。
- 删除节点不是表头的情况,对于上面的代码,我们可以看到——
1)(第12行)如果不删除当前结点 —— curr保存的是当前结点next指针的地址。
2)(第5行) entry 保存了 *curr —— 这意味着在下一次循环:entry就是prev->next指针所指向的内存。
3)(第8行)删除结点:*curr = entry->next; —— 于是:prev->next 指向了 entry -> next;
是不是很巧妙?我们可以只用一个二级指针来操作链表,对所有节点都一样。
如果你对上面的代码和描述理解上有困难的话,你可以看看下图的示意:
几周前,Linus Torvalds在slashdot上回答了一些问题。他所有的回答都很好读,但有一个特别引起了我的注意。当被要求描述他最喜欢的内核黑客时,Torvalds抱怨他现在很少看代码 - 除非是为了整理别人的混乱。然后他停下来承认他为内核极其狡猾的文件名查找缓存感到自豪,然后继续抱怨无能。
在光谱的另一端,我实际上希望更多的人了解真正核心的低级编码。不是像无锁名称查找这样的大而复杂的东西,而只是很好地利用了指针到指针等。例如,我见过太多人通过跟踪条目来删除单个链接列表条目,然后删除该条目,做类似的事情
previf (prev) prev->next = entry->next; else list_head = entry->next;每当我看到这样的代码时,我就会说"这个人不理解指针"。可悲的是,这很常见。
理解指针的人只使用"指向入口指针的指针",并使用list_head的地址对其进行初始化。然后,当他们遍历列表时,他们可以通过执行.
*pp = entry->next
好吧,我以为我理解了指针,但是,可悲的是,如果被要求实现列表删除功能,我也会跟踪以前的列表节点。下面是代码的草图:
typedef struct node
{
struct node * next;
....
} node;
typedef bool (* remove_fn)(node const * v);
// Remove all nodes from the supplied list for which the
// supplied remove function returns true.
// Returns the new head of the list.
node * remove_if(node * head, remove_fn rm)
{
for (node * prev = NULL, * curr = head; curr != NULL; )
{
node * const next = curr->next;
if (rm(curr))
{
if (prev)
prev->next = next;
else
head = next;
free(curr);
}
else
prev = curr;
curr = next;
}
return head;
}
链表是一个简单但格式完美的结构,它只不过是每个节点的指针和一个哨兵值,但是修改此类列表的代码可能很微妙。难怪链表出现在这么多面试问题中!
上面显示的实现中的微妙之处是处理从列表顶部删除的任何节点所需的条件。
现在让我们来看看Linus Torvalds想到的实现。在本例中,我们将指针传递到列表头,并使用指向下一个指针的指针完成列表遍历和修改。
void remove_if(node ** head, remove_fn rm)
{
for (node** curr = head; *curr; )
{
node * entry = *curr;
if (rm(entry))
{
*curr = entry->next;
free(entry);
}
else
curr = &entry->next;
}
}
好多了!关键见解是,链表中的链接是指针,因此指向指针的指针是修改此类列表的主要候选项。
§
改进的版本是两星编程的一个例子:双倍的星号表示两个级别的间接。第三颗星会太多了。remove_if()
Three Star Programmer (c2.com)
面向 C 程序员的评级系统。你的指针越间接(即变量前面的"*"越多),你的声誉就越高。无星C程序员几乎不存在,因为几乎所有非平凡的程序都需要使用指针。大多数是一星级程序员。在旧时代(嗯,我很年轻,所以至少对我来说,这些时代看起来像旧时代),人们偶尔会发现一个由三星级程序员完成的代码,并敬畏地颤抖。 有些人甚至声称他们已经看到了涉及函数指针的三星代码,在多个间接级别上。对我来说,听起来就像UFO一样真实。 需要明确的是:被称为三星程序员通常不是恭维。
无星编程再次成为时尚,因为C++和
模板。这里的目的是完全避免间接,内联所有内容,并在编译时对其进行全部评估。没有那些"动态"的废话。-戴夫哈里斯我认为,它走得太远了。我一直在尝试招募C++程序员。在十几次采访中,除了一次之外,所有人都无法处理简单的指针操作(反转整数数组)。唯一的例外很挣扎,但最终还是成功了。我知道C++不像C那样需要指针,但我发现令人担忧的是,这些人声称C++能力,并且显然可以找到C++编程的工作。-- PaulHudson See FreshmansFirstLanguage. 请参阅TheDumbingDownOfProgramming和SkewedBellCurve In Smalltalk: anArray reverse。在 C++ Standard Library: aList.reverse(); 当然(实际上,当然不是,因为那还不存在)。但这不是重点。我不想知道他们是否可以反转数组。我想知道他们是否了解C++和指针如何工作到足以实现诸如"在原地反转整数"之类的东西。--保罗·哈德森原谅我在这里插嘴,但这不是重点吗? 我希望我的团队中的开发人员能够思考他们想要完成的工作。我们中的一个人误解了这个页面的讽刺意味。我发现自己(在马萨诸塞州剑桥市)被一群C++(现在是Java)的"开发人员"所包围,他们对展示他们对"C++和指针的工作原理"了解多少的前景垂涎三尺 - 并且他们没有最模糊的想法,为什么有人会想要反转数组,更不用说了。 在一个完美的世界里,我希望不必做出选择:我希望每个经验丰富的专业人士都知道如何完成这样的壮举。但是,如果我必须选择,我会在任何一天使用抽象器。我所面对的失败和缺点几乎总是源于对需要解决的问题的困惑。指针表达式几乎总是按照开发人员的预期精确工作。--TomStambaugh我不认为这是重点,不,我理解ThreeStarProgrammer造成的问题。但是,那些无法成为OneStar程序员的人也是有问题的。 记得我当时是在描述一次采访。我我同意,如果他们发现自己在编写程序并需要反转数组,我宁愿他们使用库函数而不是自己编写。 但在我们的情况下,我们需要能够在与此类似的级别编写代码的程序员 - 反转数组只是面试中讨论的一个例子。 我不想要那些只知道如何摆弄比特的程序员,但不知道为什么。我不希望程序员只能处理连接以前编写的功能,但在需要时无法进入低级内容。 我可能也会选择好的抽象器。但我也没有很多好的抽象器出现。我对我所见的人的技能水平感到非常失望。 根据我从这些面试(以及前世的类似面试)中获得的经验,指针表达式并不完全按照开发人员的意图工作(我在面试中继续询问候选人如何满足自己,他们制作的代码是有效的。生成的大多数代码在边界情况下都失败了,无论如何,他们都不知道如何测试它。在生成代码时,他们也不会考虑边界情况之类的事情。令人沮丧)。-保罗哈德森嗯。我们似乎对能够同时做到这两点的程序员有着共同的愿望。在组建团队时,我试图找到并雇用PragmaticProgrammer,他们可能会达到我们每个人寻求的平衡。我的经验是,这更像是一种态度,而不是一种特定的技能。 我发现教一个天真的抽象器如何编程比教一个天真的程序员如何抽象要容易得多。我可以(并且已经)帮助一个10岁的孩子学习如何取消引用指针。我甚至无法帮助(非常)非常有成就的程序员(任何年龄)学会发现一个好的抽象的"啊哈"感觉。我的经验是,自称的ThreeStarProgrammer是最难达到的。 我所知道的ThreeStarProgrammer对我的团队和他们生成的代码造成了毁灭性的打击。根据我的经验,他们似乎带来的态度是"我比你聪明,比你更强硬,我将在我的代码中证明这一点。看*这个*!并弹出一些难以理解的象形文字混乱。我引用C++参考手册作为规范示例。根据我的经验,这种态度是如此具有破坏性,以至于它完全压倒了他们的技术专长带来的任何优势。 相反,与我共事过的更谦逊的工匠团队的工作效率也大大提高。我很高兴听到"我并不是一个伟大的程序员,我是历史专业的 - 但让我向你展示我们在上一个项目中将访客和策略结合起来的方式,我真的很喜欢它是如何出来的"......在我的白板上流淌着优雅,简洁的美丽作品。我回应谦卑,从"我"到"我们"的转变,以及对抽象本身的明显欣赏。是的,这些人很难找到:这就是为什么我坚持付给他们高薪,并在遇到他们时雇用他们,无论我是否有开放要求。 虽然我很欣赏发出此代码所需的特殊技能,但我发现它作为反例最有用。我想雇用的开发人员是那些看着它并说"哎呀!它可能会起作用,但为什么在地球上会有人这样写呢!我希望那些品味和对抽象的渴望迫使他们抱怨这样的代码的开发人员。-汤姆·斯坦博好吧,我想我们在这里非常同意。我最近合作过的最好的程序员之一(对组织有用)是人力资源部门的转换者,符合您描述的模式。因此,我们希望那些可以成为ThreeStarProgrammer的人,但具有良好的品味和判断力,不想成为。-- PaulHudson Yup,這對我來說是這樣的。 -- TomStambaugh 這就像一個優秀飛行員的定義:一個利用他/她優越的判斷力來避免他/她需要他/她優越技能的情況的人。 -- StefanVorkoetter作為對這場辯論的一個小貢獻,我試圖巧妙地實施就地反轉,並碰巧產生了至少三個錯誤的版本, 由于使用"!="而不是"<"(不要问),所有在边界情况上都失败了。我唯一的救赎借口是,我甚至在考虑设计测试之前就抓住了所有这些代码...... -- JoostMeerten我们如何区分简洁的惯用语代码和难以理解的代码?我们写作的专业水平如何?我试图避免使用GuruOnlyCode,但我自己有时确实偏离了这条线(即使我不是大师)。这就像将艺术与色情区分开来一样,很难定义,但当我看到它时我就知道了。 *微笑* - TomStambaugh
已经有一段时间了,但我曾经做过一个程序,在某一点上至少有4个级别的间接性。 这个节目是一个屏幕抓取工具。屏幕数据作为一系列字节从服务器发送,原作者只是将其转储到内存缓冲区中。然后,他会继续走过它的一部分,将它的片段投射到他在给定点想要的特定类型中。 缓冲区是一个结构化 blob,某些数据被偏移到其他部分(它是字段索引)。反过来,字段数据与数据的其他部分有偏移量,以处理字符串文本、格式化代码等内容。 为了获得屏幕标题(这只是屏幕数据中的一个特殊字段),原作者设法在单个语句中进行了四到五个指针取消引用,包括转换和偏移调整。该语句分布在四到五行中,行有80个字符(并且没有缩进...随着缩进,它增长到大约8行)。 尽管如此,这比另一部分更容易,他在另一部分将数据片段视为数组。当然,每个引用都对数组使用不同的数据类型,因此大小也不同。在这里,我试图遵循程序正在做什么,给定缓冲区的打印输出和大量荧光笔......(他的一个循环中有一个FencePostError,导致格式数据被错误地读取)。- RobertWatkins
ThreeStarProgrammers概念的一个问题是,该术语仅在C / C++的上下文中才有意义,其中*是指针取消引用运算符。在其他具有显式指针 frobbing 的语言中,用适当的词素替换 * 很简单 - 例如,您可以在 Pascal 中使用ThreeCircumflexProgrammers。 ThreeCaratProgrammers怎么样? 显然,遵循Algol-68(所有语言之母),并将这样的程序员称为ref ref程序员NickKeighley。 但是其他语言呢,那里没有(明确的)取消引用的指针呢?我们应该如何辱骂其他语言(LispLanguage,SmalltalkLanguage,PythonLanguage,JavaLanguage,PerlLanguage等)的程序员,他们太聪明了, 对自己有利? :)有人有什么好的建议吗? 好吧,有人可能会争辩说,任何使用LispLanguage编程的人对于他们自己的利益来说都已经太聪明了。;-)
另外,嵌套#if,#else,#endif呢?这些可能比指针取消引用更难,特别是考虑到跨平台,跨编译器,甚至跨语言问题。
我倾向于将整个线程称为PriestlyProgrammers,或者如何编写只有启动者才能理解的神秘代码,并且他们只能在隔周的星期二理解。有利于工作保障,对维护相当差。-雷施耐德德德夫!零!抓住那个支持我们关系的异教徒...工艺品!
前几天,我有一个类似于三星时刻的东西,在Python语言中。出于某种原因,我最终需要一个函数,该函数采用返回谓词的函数,并返回一个将返回新谓词的新函数,即原始谓词的补语。这在当时似乎是一个优雅的解决方案... --有人 使用HigherOrderFunction没有错 --MontanaRowe
问:你怎么称呼一个知道在哪里可以找到ThreeStarProgrammer的人? 答:三个十字路口。 问:您怎么称呼一家需要或使用ThreeStarProgrammer的公司? 答:三延迟
这里的潜在问题可能是在需要时不制作新对象。如果有人使用三个级别的间接寻址,他们可能应该使用一些合适的方法创建某种容器类。然后将三星构造转换为命名对象类型,并带有一些命名方法供您使用。一个很大的改进。 三星程序员看不到一个新对象如何提供帮助,而三星的发生是因为其他一些类现在做得太多了。 请记住,这是C程序员的评级方案。没有类请注意,C中的编码类是标准的CeeIdiom
已经有一段时间了,请原谅我的语法错误。下面是不需要对空列表进行特殊处理或匹配列表末尾的列表插入的代码。
A HumbleProgrammer
: It's easy to define. It's only pornography if I don't like it. It's PropellerBeanie code if you enjoyed writing it too much.
struct foo { struct foo *next; int thedata; };
struct foo *thehead = NULL;
insert(struct foo *bar) {
foo **ptr = &thehead;
while(*ptr && performSomeComparisonCheck(*ptr, bar)) {
ptr = &(*ptr)->next;
}
bar->next = *ptr;
- ptr = 酒吧;
}
这是丑陋的代码,好吧。一个全局变量来保存数组,以及一个完全不必要的间接级别,只是为了避免对列表末尾的测试(尽管 performSomeComparisonCheck() 是做什么的?但是,仍然只有两颗星。不过,这是一项英勇的努力。你在微信工作吗?--某人 如果你可以在变量之前用*查找和替换变量,之后找不到没有*的变量,那么你根本不需要那个*。*ptr是您关心的数据;你从不使用 ptr,所以用 ptr 替换所有 *ptr(一次且仅一次),你会得到你想要的代码。-MontanaRowe这是我的代码(自从我看这个页面以来已经有一段时间了)。全局变量只是 - 哎呀 - 你必须在你写例子的地方有一个变量。performSomeComparisonCheck 返回一个布尔值,用于确定我们要在前面插入哪个元素。这是元句法 - 你希望函数将指针指向函数吗?这是C大约1986年,记住,不是C++。关于删除所有*ptr的评论是完全错误的 - 我希望看到他尝试。至于代码很丑陋,我更喜欢它。这并不比在LispLanguage中通过递归进行循环更困难或更不卷积。-保罗·默里:我在两点上错了。首先,我的指针语句仅适用于您的指针与您指向的事物相同的类型时。第二,前提条件没有得到满足。我说,"你永远不要使用ptr",这是错误的:ptr = &(*ptr)->next;第三,我的措辞本身并不是"错误的",它真的很令人困惑。--MontanaRowe上述陈述是错误的,因为它完全忽略了使用C中的指针通过引用传递参数的事实,该指针不支持直接引用,如C++因此函数:void func(int *n) {
*n = 10;
}
- 可以替换为 n 的 n 对于在函数调用方中保留 n 的编辑值仍然是必需的
我一直在做一些需要阅读python解释器源代码的工作。它在几个领域使用三星。我认为它被用作指针数组的第一个元素的指针,指向动态分配的对象。抽象是怎么回事?无论如何,讽刺是美丽的:具有最佳语法的语言之一就是用这种废话实现的......哈哈 AJB
当您需要使用有序索引指向字符串的指针数组时,三星代码自然会出现(因为我们要求数组中的位置,而不是字符串本身)。这些字符串的类型为 char const *。数据块的类型为 char const *const *const [02]。索引块的类型为 char const *const *const [02]。(最里面的间接寻址不算数,因为字符串类型可以变成倾斜的;但是,最外层的数组弥补了这一缺陷。
通过明智地使用typedef,可以很容易地避免三星编程:我宁愿使用三星编程,也不愿使用过多的typedef。特别是指针的类型化。呸。- wrl
我在生产代码中看到(虽然不是我自己写的)配置结构的四颗星(在nginx中)。这超出了我目前的理解,为什么它使用四颗星,但我确实在某个时候理解了它的用途。 来源
:nginx/src/core/ngx_cycle.h(最早在0.1.11和1.5.9版)可能是一个程序员Stereotype参见:ThreeStarPerl,ThreeStarAssembler,ThreeStarJava,ThreeStarSwap,YouMightBeaThreeStarProgrammer和ThreeStarProgrammerExamples
Linux PID 1 和 Systemd | 酷 壳 - CoolShell
要说清 Systemd,得先从Linux操作系统的启动说起。Linux 操作系统的启动首先从 BIOS 开始,然后由 Boot Loader 载入内核,并初始化内核。内核初始化的最后一步就是启动 init 进程。这个进程是系统的第一个进程,PID 为 1,又叫超级进程,也叫根进程。它负责产生其他所有用户进程。所有的进程都会被挂在这个进程下,如果这个进程退出了,那么所有的进程都被 kill 。如果一个子进程的父进程退了,那么这个子进程会被挂到 PID 1 下面。(注:PID 0 是内核的一部分,主要用于内进换页,参看:Process identifier)
SysV Init
PID 1 这个进程非常特殊,其主要就任务是把整个操作系统带入可操作的状态。比如:启动 UI – Shell 以便进行人机交互,或者进入 X 图形窗口。传统上,PID 1 和传统的 Unix System V 相兼容的,所以也叫 sysvinit,这是使用得最悠久的 init 实现。Unix System V 于1983年 release。
在 sysvint 下,有好几个运行模式,又叫 runlevel。比如:常见的 3 级别指定启动到多用户的字符命令行界面,5 级别指定启起到图形界面,0 表示关机,6 表示重启。其配置在 /etc/inittab 文件中。
与此配套的还有 /etc/init.d/ 和 /etc/rc[X].d,前者存放各种进程的启停脚本(需要按照规范支持 start,stop子命令),后者的 X 表示不同的 runlevel 下相应的后台进程服务,如:/etc/rc3.d 是 runlevel=3 的。 里面的文件主要是 link 到 /etc/init.d/ 里的启停脚本。其中也有一定的命名规范:S 或 K 打头的,后面跟一个数字,然后再跟一个自定义的名字,如:S01rsyslog,S02ssh。S 表示启动,K表示停止,数字表示执行的顺序。
UpStart
Unix 和 Linux 在 sysvint 运作多年后,大约到了2006年的时候,Linux内核进入2.6时代,Linux有了很多更新。并且,Linux开始进入桌面系统,而桌面系统和服务器系统不一样的是,桌面系统面临频繁重启,而且,用户会非常频繁的使用硬件的热插拔技术。于是,这些新的场景,让 sysvint 受到了很多挑战。
比如,打印机需要CUPS等服务进程,但是如果用户没有打机印,启动这个服务完全是一种浪费,而如果不启动,如果要用打印机了,就无法使用,因为sysvint 没有自动检测的机制,它只能一次性启动所有的服务。另外,还有网络盘挂载的问题。在 /etc/fstab 中,负责硬盘挂载,有时候还有网络硬盘(NFS 或 iSCSI)在其中,但是在桌面机上,有很可能开机的时候是没有网络的, 于是网络硬盘都不可以访问,也无法挂载,这会极大的影响启动速度。sysvinit 采用 netdev 的方式来解决这个问题,也就是说,需要用户自己在 /etc/fstab 中给相应的硬盘配置上 netdev 属性,于是 sysvint 启动时不会挂载它,只有在网络可用后,由专门的 netfs 服务进程来挂载。这种管理方式比较难以管理,也很容易让人掉坑。
所以,Ubuntu 开发人员在评估了当时几个可选的 init 系统后,决定重新设计这个系统,于是,这就是我们后面看到的 upstart 。 upstart 基于事件驱动的机制,把之前的完全串行的同步启动服务的方式改成了由事件驱动的异步的方式。比如:如果有U盘插入,udev 得到通知,upstart 感知到这个事件后触发相应的服务程序,比如挂载文件系统等等。因为使用一个事件驱动的玩法,所以,启动操作系统时,很多不必要的服务可以不用启动,而是等待通知,lazy 启动。而且事件驱动的好处是,可以并行启动服务,他们之间的依赖关系,由相应的事件通知完成。
upstart 有着很不错的设计,其中最重要的两个概念是 Job 和 Event。
Job 有一般的Job,也有service的Job,并且,upstart 管理了整个 Job 的生命周期,比如:Waiting, Starting, pre-Start, Spawned, post-Start, Running, pre-Stop, Stopping, Killed, post-Stop等等,并维护着这个生命周期的状态机。
Event 分成三类,signal, method 和 hooks。signal 就是异步消息,method 是同步阻塞的。hooks 也是同步的,但介于前面两者之间,发出hook事件的进程必须等到事件完成,但不检查是否成功。
但是,upstart 的事件非常复杂,也非常纷乱,各种各样的事件(事件没有归好类)导致有点凌乱。不过因为整个事件驱动的设计比之前的 sysvinit 来说好太多,所以,也深得欢迎。
Systemd
直到2010的有一天,一个在 RedHat工作的工程师 Lennart Poettering 和 Kay Sievers ,开始引入了一个新的 init 系统—— systemd。这是一个非常非常有野心的项目,这个项目几乎改变了所有的东西,systemd 不但想取代已有的 init 系统,而且还想干更多的东西。
Lennart 同意 upstart 干的不错,代码质量很好,基于事件的设计也很好。但是他觉得 upstart 也有问题,其中最大的问题还是不够快,虽然 upstart 用事件可以达到一定的启动并行度,但是,本质上来说,这些事件还是会让启动过程串行在一起。 如:NetworkManager 在等 D-Bus 的启动事件,而 D-Bus 在等 syslog 的启动事件。
Lennart 认为,实现上来说,upstart 其实是在管理一个逻辑上的服务依赖树,但是这个服务依赖树在表现形式上比较简单,你只需要配置——“启动 B好了就启动A”或是“停止了A后就停止B”这样的规则。但是,Lennart 说,这种简单其实是有害的(this simplification is actually detrimental)。他认为,
- 从一个系统管理的角度出来,他一开始会设定好整个系统启动的服务依赖树,但是这个系统管理员要人肉的把这个本来就非常干净的服务依整树给翻译成计算机看的懂的 Event/Action 形式,而且 Event/Action 这种配置方式是运行时的,所以,你需要运行起来才知道是什么样的。
- Event逻辑从头到脚到处都是,这个事件扩大了运维的复杂度,还不如之前的
sysvint。 也就是说,当用户配置了 “启动D-Bus后请启动NetworkManager”, 这个upstart可以干,但是反过来,如果,用户启动NetworkManager,我们应该先去启动他的前置依赖D-Bus,然而你还要配置相应的反向 Event。本来,我只需要配置一条依赖的,结果现在我要配置很多很多情况下的Event。
- 最后,
upstart里的 Event 的并不标准,很混乱,没有良好的定义。比如:既有,进程启动,运行,停止的事件,也有USB设备插入、可用、拔出的事件,还有文件系统设备being mounted、 mounted 和 umounted 的事件,还有AC电源线连接和断开的事件。你会发现,这进程启停的、USB的、文件系统的、电源线的事件,看上去长得很像, 但是没有被标准化抽像出来掉,因为绝大多数的事件都是三元组:start, condition, stop 。这种概念设计模型并没有在upstart中出现。因为upstart被设计为单一的事件,而忽略了逻辑依赖。
当然,如果 systemd 只是解决 upstart 的问题,他就改造 upstart 就好了,但是 Lennart 的野心不只是想干个这样的事,他想干的更多。
首先,systemd 清醒的认识到了 init 进程的首要目标是要让用户快速的进入可以操作OS的环境,所以,这个速度一定要快,越快越好,所以,systemd 的设计理念就是两条:
- To start less.
- And to start more in parallel.
也就是说,按需启动,能不启动就不启动,如果要启动,能并行启动就并行启动,包括你们之间有依赖,我也并行启动。按需启动还好理解,那么,有依赖关系的并行启动,它是怎么做到的?这里,systemd 借鉴了 MacOS 的 Launchd 的玩法(在Youtube上有一个分享——Launchd: One Program to Rule them All,在苹果的开源网站上也有相关的设计文档——About Daemons and Services)
要解决这些依赖性,systemd 需要解决好三种底层依赖—— Socket, D-Bus ,文件系统。
- Socket依赖。如果服务C依赖于服务S的socket,那么就要先启动S,然后再启动C,因为如果C启动时找不到S的Socket,那么C就会失败。
systemd可以帮你在S还没有启动好的时候,建立一个socket,用来接收所有的C的请求和数据,并缓存之,一旦S全部启动完成,把systemd替换好的这个缓存的数据和Socket描述符替换过去。
- D-Bus依赖。
D-Bus全称 Desktop Bus,是一个用来在进程间通信的服务。除了用于用户态进程和内核态进程通信,也用于用户态的进程之前。现在,很多的现在的服务进程都用D-Bus而不是Socket来通信。比如:NetworkManager就是通过D-Bus和其它服务进程通讯的,也就是说,如果一个进程需要知道网络的状态,那么就必需要通过D-Bus通信。D-Bus支持 “Bus Activation”的特性。也就是说,A要通过D-Bus服务和B通讯,但是B没有启动,那么D-Bus可以把B起来,在B启动的过程中,D-Bus帮你缓存数据。systemd可以帮你利用好这个特性来并行启动 A 和 B。
- 文件系统依赖。系统启动过程中,文件系统相关的活动是最耗时的,比如挂载文件系统,对文件系统进行磁盘检查(fsck),磁盘配额检查等都是非常耗时的操作。在等待这些工作完成的同时,系统处于空闲状态。那些想使用文件系统的服务似乎必须等待文件系统初始化完成才可以启动。
systemd参考了autofs的设计思路,使得依赖文件系统的服务和文件系统本身初始化两者可以并发工作。autofs可以监测到某个文件系统挂载点真正被访问到的时候才触发挂载操作,这是通过内核automounter模块的支持而实现的。比如一个open()系统调用作用在某个文件系统上的时候,而这个文件系统尚未执行挂载,此时open()调用被内核挂起等待,等到挂载完成后,控制权返回给open()系统调用,并正常打开文件。这个过程和autofs是相似的。
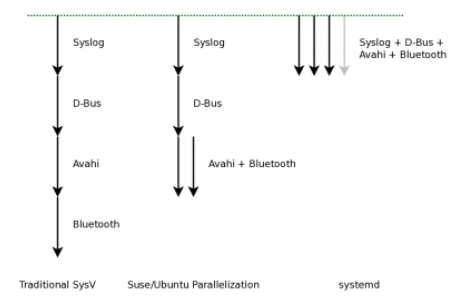
下图来自 Lennart 的演讲里的一页PPT,展示了不同 init 系统的启动。
除此之外,systemd 还在启动时管理好了一些下面的事。
用C语言取代传统的脚本式的启动。前面说过,sysvint 用 /etc/rcX.d 下的各种脚本启动。然而这些脚本中需要使用 awk, sed, grep, find, xargs 等等这些操作系统的命令,这些命令需要生成进程,生成进程的开销很大,关键是生成完这些进程后,这个进程就干了点屁大的事就退了。换句话说就是,我操作系统干了那么多事为你拉个进程起来,结果你就把个字串转成小写就退了,把我操作系统当什么了?
在正常的一个 sysvinit 的脚本里,可能会有成百上千个这样的命令。所以,慢死。因此,systemd 全面用 C 语言全部取代了。一般来说,sysvinit 下,操作系统启动完成后,用 echo $$ 可以看到,pid 被分配到了上千的样子,而 systemd 的系统只是上百。
另外,systemd 是真正一个可以管住服务进程的——可以跟踪上服务进程所fork/exec出来的所有进程。
- 我们知道, 传统 Unix/Linux 的 Daemon 服务进程的最佳实践基本上是这个样子的 (具体过程可参看这篇文章“SysV Daemon”)——
- 进程启动时,关闭所有的打开的文件描述符(除了标准描述符0,1,2),然后重置所有的信号处理。
- 调用
fork()创建子进程,在子进程中setsid(),然后父进程退出(为了后台执行) - 在子进程中,再调用一次
fork(),创建孙子进程,确定没有交互终端。然后子进程退出。 - 在孙子进程中,把标准输入标准输出标准错误都连到
/dev/null上,还要创建 pid 文件,日志文件,处理相关信号 …… - 最后才是真正开始提供服务。
- 在上面的这个过程中,服务进程除了两次
fork外还会fork出很多很多的子进程(比如说一些Web服务进程,会根据用户的请求链接来fork子进程),这个进程树是相当难以管理的,因为,一旦父进程退出来了,子进程就会被挂到 PID 1下,所以,基本上来说,你无法通过服务进程自已给定的一个pid文件来找到所有的相关进程(这个对开发者的要求太高了),所以,在传统的方式下用脚本启停服务是相当相当的 Buggy 的,因为无法做对所有的服务生出来的子子孙孙做到监控。
- 为了解决这个问题,
upstart通过变态的strace来跟踪进程中的fork()和exec()或exit()等相关的系统调用。这种方法相当笨拙。systemd使用了一个非常有意思的玩法来 tracking 服务进程生出来的所有进程,那就是用cgroup(我在 Docker 的基础技术“cgroup篇”中讲过这个东西)。cgroup主要是用来管理进程组资源配额的事,所以,无论服务如何启动新的子进程,所有的这些相关进程都会同属于一个cgroup,所以,systemd只需要简单的去遍历一下相应的cgroup的那个虚文件系统目录下的文件,就可以正确的找到所有的相关进程,并将他们一一停止。
另外,systemd 简化了整个 daemon 开发的过程:
- 不需要两次
fork(),只需要实现服务本身的主逻辑就可以了。 - 不需要
setsid(),systemd会帮你干 - 不需要维护
pid文件,systemd会帮处理。 - 不需要管理日志文件或是使用
syslog,或是处理HUP的日志reload信号。把日志打到stderr上,systemd帮你管理。 - 处理
SIGTERM信号,这个信号就是正确退出当前服务,不要做其他的事。 - ……
除此之外,systemd 还能——
- 自动检测启动的服务间有没有环形依赖。
- 内建 autofs 自动挂载管理功能。
- 日志服务。
systemd改造了传统的 syslog 的问题,采用二进制格式保存日志,日志索引更快。 - 快照和恢复。对当前的系统运行的服务集合做快照,并可以恢复。
- ……
还有好多好多,他接管很多很多东西,于是就让很多人不爽了,因为他在干了很多本不属于 PID 1 的事。
Systemd 争论和八卦
于是 systemd 这个东西成了可能是有史以来口水战最多的一个开源软件了。systemd 饱受各种争议,最大的争议就是他破坏了 Unix 的设计哲学(相关的哲学可以读一下《Unix编程艺术》),干了一个大而全而且相当复杂的东西。当然,Lennart 并不同意这样的说法,他后来又写一篇blog “The Biggest Myths”来解释 systemd 并不是这样的,大家可以前往一读。
这个争议大到什么样子呢?2014 年,Debian Linux 因为想准备使用 systemd 来作为标准的 init 守护进程来替换 sysvinit 。而围绕这个事的争论达到了空前的热度,争论中充满着仇恨,systemd 的支持者和反对者都在互相辱骂,导致当时 Debian 阵营开始分裂。还有人给 Lennart 发了死亡威胁的邮件,用比特币雇凶买杀手,扬言要取他的性命,在Youbute上传了侮辱他的歌曲,在IRC和各种社交渠道上给他发下流和侮辱性的消息。这已经不是争议了,而是一种不折不扣的仇恨!

于是,Lennart 在 Google Plus 上发了贴子,批评整个 Linux 开源社区和 Linus 本人。他大意说,
这个社区太病态了,全是 ass holes,你们不停用各种手段在各种地方用不同的语言和方式来侮辱和漫骂我。我还是一个年轻人,我从来没有经历过这样的场面,但是今天我已经对这种场面很熟悉了。我有时候说话可能不准确,但是我不会像他样那样说出那样的话,我也没有被这些事影响,因为我脸皮够厚,所以,为什么我可以在如何大的反对声面前让
systemd成功,但是,你们 Linux 社区太可怕了。你们里面的有精神病的人太多了。另外,对于Linus Torvalds,你是这个社区的 Role Model,但可惜你是一个 Bad Role Model,你在社区里的刻薄和侮辱性的言行,基本从一定程度上鼓励了其它人跟你一样,当然,并不只是你一个人的问题,而是在你周围聚集了一群和你一样的这样干的人。送你一句话—— A fish rots from the head down !一条鱼是从头往下腐烂的……
这篇契文很长,喜欢八卦的同学可以前往一读。感受一下 Lennart 当时的心态(我觉得能算上是非常平稳了)。
Linus也在被一媒体问起 systemd 这个事来(参看“Torvalds says he has no strong opinions on systemd”),Linus在采访里说,
我对
systemd和 Lennart 的贴子没有什么强烈的想法。虽然,传统的 Unix 设计哲学—— “Do one thing and Do it well”,很不错,而且我们大多数人也实践了这么多年,但是这并不代表所有的真实世界。在历史上,也不只有systemd这么干过。但是,我个人还是 old-fashioned 的人,至少我喜欢文本式的日志,而不是二进制的日志。但是systemd没有必要一定要有这样的品味。哦,我说细节了……
今天,systemd 占据了几乎所有的主流的 Linux 发行版的默认配置,包括:Arch Linux、CentOS、CoreOS、Debian、Fedora、Megeia、OpenSUSE、RHEL、SUSE企业版和 Ubuntu。而且,对于 CentOS, CoreOS, Fedora, RHEL, SUSE这些发行版来说,不能没有 systemd。(Ubuntu 还有一个不错的wiki – Systemd for Upstart Users 阐述了如何在两者间切换)
其它
还记得在《缓存更新的套路》一文中,我说过,如果你要做好架构,首先你得把计算机体系结构以及很多老古董的基础技术吃透了。因为里面会有很多可以借鉴和相通的东西。那么,你是否从这篇文章里看到了一些有分布式架构相似的东西?
比如:从 sysvinit 到 upstart 再到 systemd,像不像是服务治理?Linux系统下的这些服务进程,是不是很像分布式架构中的微服务?还有那个D-Bus,是不是很像SOA里的ESB?而 init 系统是不是很像一个控制系统?甚至像一个服务编排(Service Orchestration)系统?
分布式系统中的服务之间也有很多依赖,所以,在启动一个架构的时候,如果我们可以做到像 systemd 那样并行启动的话,那么是不是就像是一个微服务的玩法了?
嗯,你会发现,技术上的很多东西是相通的,也是互相有对方的影子,所以,其实技术并不多。关键是我们学在了表面还是看到了本质。
echo $$ 返回登录shell的PID
echo $? 返回上一个命令的状态,0表示没有错误,其它任何值表明有错误
echo $# 返回传递到脚本的参数个数
echo $* 以一个单字符串显示所有向脚本传递的参数,与位置变量不同,此选项参数可超过9个
echo $! 返回后台运行的最后一个进程的进程ID号
echo $@ 返回传递到脚本的参数个数,但是使用时加引号,并在引号中返回每个参数
echo $- 显示shell使用的当前选项
参照:https://zhidao.baidu.com/question/1964506273683875500.html
Linux 创造者 Linus Torvalds 以其对许多技术事物的强烈见解而闻名。但是当谈到 systemd(在 Linux 世界引起相当程度的焦虑的 init 系统)时,Torvalds 是中立的。
Torvalds 在接受 iTWire 采访时说:“谈到 systemd,你可能会期望我有很多丰富多彩的意见,但我没有。” “我个人并不介意 systemd,事实上我的主要台式机和笔记本电脑都运行它。
在提到他与systemd 的主要开发人员之一Kay Sievers 的争吵时,Torvalds 补充道:“现在,我与一些开发人员相处不来,并认为他们对错误和兼容性有点过于傲慢,但我也非常不喜欢 systemd 的想法。”
Torvalds 还以他通常直截了当的严肃方式回答了许多其他问题,包括技术问题和一般问题。编辑后的成绩单如下。感谢我的 UNIX 大师Peter Giorgilli,他提出了一些问题。
Linus Torvalds:所以我认为现在 UNIX 的许多“原始理想”更多是一种思维方式问题,而不是必然反映情况的现实。
理解传统的 UNIX“做一件事并做好”模型仍然有价值,在该模型中,许多工作流可以作为一个简单工具的管道来完成,每个工具都增加了自己的价值,但让我们面对现实,这并不是复杂系统的真正工作方式,以及这与主要应用程序的工作方式或设计方式无关。这是一个有用的简化,它在*某些*级别仍然是正确的,但我认为它也很明显它并没有真正描述大部分现实。
不过,它可能会描述一些特定的案例,而且我确实认为它是一个有用的教学工具。人们显然仍然使用 UNIX 可能与之相关的那些传统的进程和文件描述符管道,但是在很多情况下,您拥有大型复杂的统一系统。
而且 systemd 绝不是打破旧的 UNIX 遗产的部分。图形应用程序很少以这种方式工作(在像“LyX”这样的东西中肯定有_echoes_,但我认为这是例外而不是规则),然后显然有 GNU emacs 的传统反例,它实际上不是关于“简单的 UNIX 模型”,而是一个全新的大型基础设施。像systemd。
现在,我仍然很老式,我喜欢我的文本日志文件,而不是二进制文件,所以我认为有时 systemd 不一定有最好的品味,但是嘿,细节..
您之前是否见过类似的情况——从 1991 年您第一次将 Linux 供下载时——一种新的做事方式的引入引起了如此多的痛苦和极端的反应?
哦,以前有过激烈的战斗。想想 emacs 与 vi 的战争。或者,更接近于 systemd,整个“SysV init”与“BSD init”的差异肯定最终成为人们“热烈讨论”的事情。或者想想桌面比较。
我不太确定 systemd 争吵与那些争吵有何不同。这是技术性的,但不可否认,systemd 开发人员也非常擅长在纯粹的个人层面上疏远人们。这并不是什么特别新鲜的事情_要么_:80 年代末和 90 年代初 GPL 和 BSD 许可阵营之间的(非常)激烈的战争几乎肯定更多是关于所涉及的人以及他们如何激怒人们而不是必然深入了解其他差异(显然存在,但仍然存在)。
如果有人争辩说 systemd 造成了一个单点故障,导致系统在出现故障时无法启动,您会怎么说?它本身集中了许多服务,如果一个服务失败,那么该系统几乎毫无用处。
我认为人们正在寻找借口。我的意思是,如果这是不使用某个软件的原因,那么您也不应该使用内核。
当然,内核是特殊的,内核工程师只是更好的人。每个人都知道这一点。因此,也许将其他更平凡的项目与内核这样崇高的项目进行比较是不公平的。但是看看像 glibc 等缓慢的项目——当他们搞砸时,每个人也会受到伤害。所以我不知道。
我提出这个问题是因为我看到有人呼吁在服务器上迁移到 BSD,而不是 Linux。我以前从未见过这种程度的极端行为——但后来我自 1998 年以来一直在使用 Linux。
所以我不得不承认,我通常不会试图跟随这样的风暴,但我也认为正在发生变化的一件事是,你拥有这种强烈的民粹主义恐慌文化,我认为人们可能把它看得太重了。显然不仅仅是在科技媒体上(我相信你可以像我一样指出大量声称做同样事情的严肃世界新闻网站),但科技界当然也有很多“意见” "和相关的膨化。
在 BSD 阵营里有一个经典的术语:“自行车棚绘画”,这很大程度上是关于随机的人们觉得他们有能力讨论表面问题,因为每个人都觉得他们可以对颜色选择发表意见. 因此,肤浅的问题会引起更多噪音。然后,当涉及到实际困难而深入的技术决策时,人们(有时)会意识到他们只是了解得不够多,他们不会给出同样的口头时间。
您是否阅读过 Lennart Poettering 撰写的有关将 Btrfs 文件系统作为默认文件系统组织发行版的新文档?如果是这样,你怎么看?
我完全不确定这是否一定是正确的处理方式,但实际上我很高兴人们朝着这个方向努力。对于第三方应用程序来说,当前的打包模型肯定是不可行的,即使对于由 Linux 发行版作为核心发行版的一部分分发的项目,我也不相信它有那么好。
您如何使用 Btrfs 实现这一点的确切细节是否正确?我真的一点儿都不知道。这是一个复杂的问题,它不会通过一些激进的新事物在一夜之间解决,而且我对改变一切并声称它解决问题的花哨的新模型持怀疑态度(也许新颖性和复杂性以及花哨的细节只会让它变得困难说它_不_有现有系统存在的问题,所以这被视为问题不再存在的论点——不是因为它们真的消失了,而是因为它们太难争论了,因为发生了太多变化)。
但我认为这是一个非常值得研究的问题。
在使用 Git 近十年之后,这些年来添加的任何功能是否让您感到惊讶?
嗯,真的没有那么多核心变化。这是非常可识别的同一件事,只是抛光并做得更好。大多数真正的核心概念完全没有改变。
不,令人惊讶的是它最终变得如此受欢迎。人们抱怨它使用起来有多么困难,更重要的是,当涉及到分发时,人们真的从根本上没有“理解”它,而当涉及到 git 所做的一些根本不同的其他事情时(但要好得多)。就像 git 重命名的整个方式一样,“git blame”如何跟踪某些代码的历史,甚至跨越代码移动,不仅是基于“文件”,而且是在文件之间。
这些是不久前人们非常积极地争论的事情。“旧模型”(实际上是各种伪装的 CVS)仍然对事情应该如何运作的心态产生巨大影响。
然后 github 出现了,很多随机项目开始使用 git(ruby 社区似乎从网络上随机引入了很多人使用 git),然后突然之间,真的,这一切都从“离谱”变成了“公认”。不,不是普遍,但新模型似乎真的切换到人们“得到它”的地方,并且仍然有关于随机事物的抱怨,但他们肯定变得更加沉默。
我想这并不是真的突然,这更像是一个获得足够临界质量的问题,你会发现人们互相解释发生了什么,但对我来说_感觉_突然。Git 从一个相当小众的用途(内核、其他一些真正的核心项目)到更广泛的受众,现在它几乎是任何开源项目的默认 SCM(源代码管理系统),而且很多非 OSS 的也是如此。现在几乎所有的开发环境都有 git 插件(通常是原生支持)。
您在孩子就读的学校接受 IT 教育是什么体验?
老实说,我的孩子除了作为用户之外,似乎从来没有真正对计算机感兴趣,所以虽然他们肯定不是 Luddites,但我对 IT 教育也没有任何感觉。有趣的是,他们在学校的笔记本电脑上使用 Linux 真的不是问题。OpenOffice 和各种 webby 的东西都很好用,我担心会出现一些会导致大问题的情况。到目前为止什么都没有,尽管我确信他们有自己的问题。
我们当地的学校甚至在我们搬到这里之前就使用了 Linux 和 OpenOffice(不仅如此,但仍然如此),所以这可能是其中的一部分。
继此之后,您对学校如何教授信息技术,或者更广泛地说信息技术在教育中的地位有什么看法?(例如,在课堂上使用平板电脑等设备。)
我不是平板电脑的忠实粉丝,除了作为纯消费设备。不要误会我的意思,我自己使用平板电脑,每天使用它只是在不在电脑前(连同我的手机)阅读电子邮件,但如果我想*创造*某些东西,我想要一个键盘。我认为这在教育中也是如此。当然,其中很大一部分是“消费”,并且能够展示动画而不是静态图片当然可以成为任何电子媒体都比传统书籍更强大的教学工具,但帕特里夏只是想要一本书_as_一本书,而不是在 Kindle 上,因为她想做突出显示和便签等。当然,你也可以在电子媒体上做到这一点,但不一定更好。当你真正*创造*某些东西时,我只是怀疑笔记本电脑会好得多。
最后,我不认为教育的真正问题在于 IT 或缺乏 IT。我强烈认为,一个真正能教书的好老师(不仅仅是为了考试,而且必须满足一些随意的基准,这似乎很常见)才是最重要的*如此*。甚至除了老师,我们为孩子寻找的其中一件事不仅仅是找到一所好学校,而是搬到一个我们的同龄人(以及孩子们的同龄人)欣赏教育的地方。
它?不特别。它可以帮助,它可以伤害。我认为这是一个有趣且有益的就业领域,我很高兴它的薪水很高。我喜欢 IT,但它不是主要的东西(好吧,除非你是一家科技公司,你的第一项工作就是做 IT 部分)。我可能是一个巨大的计算机书呆子,但即便如此,我也不认为教育应该与计算机有关。不是作为一门学科,也不是作为课堂资源。
您如何看待像 OLPC 所要求的那样在学校里为孩子们提供笔记本电脑?它对教育有帮助还是阻碍?
我认为 OLPC 与其说是“广泛使用”,不如说是“早年”。就像在贫困地区一样,无论*年龄如何,都无法使用计算机。
而我实际上非常相信“访问”这个东西。我进入计算机的原因主要是我的祖父,他在 80 年代初让我访问计算机,当时大多数我这个年龄的孩子肯定没有这种访问权限. 你可以找到很多计算机人的类似故事:许多人很早就开始工作,因为他们有父母或学校,或者可以玩设备和学习的东西。
由于这个原因,我认为 Raspberry PI 也是一个伟大的项目,正是因为它可以让人们进行修补。而且我真的认为在很多方面“修补匠”比“使用”更重要。学习*使用*计算机的人当然也学到了一些重要的东西,但我认为学习*修补*技术的孩子实际上学到了更深入、更重要的东西。
但我真的不认为“修补课程”在学校环境中有意义。我真的认为你不可能给“修补”打分,我不认为你可以在不破坏它的价值的情况下把它变成一些有组织的东西。我认为你想提供资源并使之成为可能,但几乎就这样了。
因此,请以任何方式支持修补:在学校图书馆提供互联网和计算机以访问它,并让孩子们搜索除小猫视频或色情片之外的其他内容。鼓励更轻松的修修补补环境:编程俱乐部、机器人技术、3D 打印等等。让孩子们制作一个气象气球并在太空中途拍照。像鼓励足球或其他什么一样鼓励“极客”的事情。
如果孩子们有兴趣,网上有可供他们学习的资源。向他们展示那些,让他们成为。不是每个人都会感兴趣,我认为你不能在不破坏修补的情况下强迫它。
你认为你今天比 10 年前更好的程序员了吗?
嗯,十年前我确实比今天做了很多*更多*的编程,所以我不得不说“不”。当我做更多的编程时,我显然是一个更有效率的程序员。
我仍然不会称自己为“经理”——我当然没有堕落到那个程度,我也不做季度预算等——但与此同时,我也不再是真正的程序员了。“技术带头人”。您需要了解编程才能判断哪些有效,哪些无效,但与实际编写代码相比,我写了更多“如何以这种方式解决问题”之类的电子邮件。
您是否发现年龄越大编程越困难?
是和否。并不是说编程本身更难,但尤其是作为一个顶级维护者,我不能像你真正需要做的那样专注于一个特定的领域,以便能够真正解决棘手的问题。我只是不再那么专业了,而且我真的负担不起进入“区域”并在一两个星期(或一个月。或其他)中只处理一个非常特殊的问题。编程是关于细节的,并且让它们正确,你真的需要坐下来,非常熟悉一个特定的问题。
不要误会我的意思,我不完全确定我还想再做一些。我已经完成了设备驱动程序编程,在你面前有一个规格表真的很有趣,只是尝试让一些随机的非常具体的硬件工作。没有什么比它更能让硬件栩栩如生的了。但与此同时,我*已经*完成了,我已经完成了,而且我很确定,如果我的生活中再也不需要编写另一个设备驱动程序,我也会很高兴。因为这真的是一件非常注重细节的事情,你必须真正进入这个你不关心其他任何事情的地方。
所以我很高兴成为技术负责人。我的一部分错过了这样一个事实,即我真的没有时间或可能再深入研究一件小事。但我更喜欢“概述”。
我认为我仍然喜欢做我所做的事情的原因之一是我今天所做的与我 10 年前所做的不同,而这反过来又与我 20 年前所做的大不相同。整个项目都有连续性的历史,但与此同时,事情肯定已经发生了变化。
你喜欢管理如此庞大的一群经常笨拙的人,还是有比公众目睹的更多的头发撕裂?
我确实喜欢它,而且我实际上认为,与公众目击者相比,撕掉头发的次数要少得多。
人们看到风暴的故事和声音的争论。您正在为 systemd 撰写一篇文章,但我可以向您指出许多关于我诅咒他人的文章,如果您在外面,那么这些可能是您唯一看到的有关该过程的文章。因为它们又是吹毛求疵、评论文章、飞扬的东西。很少有人写关于某个随机领域的深入而有趣的技术讨论,而这样做的人(如 LWN 等)不会在社交媒体上传播_除非_他们然后写了一篇关于每个人都可以发表意见的其他内容的文章。
作为一个大项目的技术负责人是否有压力?是的,它可以,而且并不总是很有趣。但是*大多数*时间事情实际上运作良好,大多数时候我真的很喜欢所有与我一起工作的人,而且大多数时候它只是很有趣。偶尔的突发事件也不一定非常糟糕。我不了解你,但我个人对“持续的低级摩擦”比偶尔发生的人们真正互相称呼对方的大喊大叫更有压力。
如果您重新开始编写类 UNIX 内核,您还会使用“C”编程语言吗?
绝对地。这是绝对没有改变的一件事。
假设你遵循了“斯诺登”的启示——关于美国国家安全局进行的大规模监视的报告范围,有什么特别让你感到惊讶的吗?
不是真的监视,不。政客们被误导的愤怒(即对斯诺登的愤怒,而不是因为他暴露的事情)我想也不应该令人惊讶,但它仍然是。伤心。尤其是(加利福尼亚州参议员黛安娜)范斯坦的虚伪,尤其是在整个间谍传奇中,简直令人作呕。
自从我们首次提议将systemd 包含在发行版中以来,它已在许多论坛、邮件列表和会议中频繁讨论。在这些讨论中,人们经常会听到一些关于 systemd 的神话,一遍又一遍地重复,但肯定不会通过不断的重复获得任何真理。让我们花点时间来揭穿其中的一些:
-
误解:systemd 是单体的。
如果您在启用所有配置选项的情况下构建 systemd,您将构建 69 个单独的二进制文件。这些二进制文件都服务于不同的任务,并且出于多种原因被巧妙地分开。例如,我们在设计 systemd 时考虑到了安全性,因此大多数守护进程以最低权限运行(例如使用内核功能)并且只负责非常特定的任务,以最大限度地减少它们的安全面和影响。此外,systemd 比任何先前的解决方案都更能并行启动。这种并行化是通过并行运行更多进程来实现的。因此,将 systemd 很好地拆分为许多二进制文件以及进程是至关重要的。事实上,许多这些二进制文件[1]被很好地分离出来,以至于它们在 systemd 之外也非常有用。
一个包含 69 个单独二进制文件的包很难被称为 单片的。然而,与之前的解决方案不同的是,我们在单个 tarball 中提供更多组件,并在具有统一发布周期的单个存储库中将它们上游维护。
-
误解:systemd 是关于速度的。
是的,systemd 很快(有人在大约 900 毫秒内完成了一个相当完整的用户空间启动,有人吗?),但这主要只是做正确事情的副作用。事实上,我们从未真正坐下来优化 systemd 的最后一点性能。相反,我们实际上经常故意选择稍慢的代码路径,以保持代码更具可读性。这并不意味着速度对我们来说无关紧要,但是将 systemd 降低到它的速度肯定是一种误解,因为这肯定不在我们目标列表的首位。
-
误解:systemd 的快速启动与服务器无关。
这完全不是真的。许多管理员实际上热衷于减少维护窗口期间的停机时间。在高可用性设置中,如果出现故障的机器能够非常快地恢复,那就太好了。在具有大量 VM 或容器的云设置中,缓慢启动的价格会随着实例数量的增加而倍增。在数百个虚拟机或容器的非常缓慢的启动上花费几分钟的 CPU 和 IO 会大大降低系统的密度,见鬼,它甚至会花费你更多的能量。慢靴在经济上可能相当昂贵。然后,容器的快速启动允许您实现诸如套接字激活容器之类的逻辑,从而使您能够大幅增加云系统的密度。
当然,在许多服务器设置中,启动确实无关紧要,但 systemd 应该涵盖整个范围。是的,我知道通常是服务器固件在启动时花费最多的时间,而操作系统无论如何都比这快,但是,systemd 仍然应该涵盖整个范围(见上文...... ),不,并非所有服务器都有如此糟糕的固件,当然也不是虚拟机和容器,它们也是一种服务器。[2]
-
误解:systemd 与 shell 脚本不兼容。
这完全是假的。我们只是不将它们用于启动过程,因为我们相信它们不是用于该特定目的的最佳工具,但这并不意味着 systemd 与它们不兼容。您可以轻松地将 shell 脚本作为 systemd 服务运行,哎呀,您可以将用任何语言编写的脚本作为 systemd 服务运行,systemd 丝毫不在意可执行文件中的内容。此外,我们大量使用 shell 脚本用于我们自己的目的,用于安装、构建、测试 systemd。您可以在早期启动过程中粘贴脚本,将它们用于正常服务,您可以在最晚关闭时运行它们,几乎没有限制。
-
误解:systemd 很难。
这也完全是无稽之谈。systemd 平台实际上比传统的 Linux 简单得多,因为它将系统对象及其依赖项统一为 systemd 单元。配置文件语言很简单,多余的配置文件我们去掉了。我们为系统的大部分配置提供统一的工具。该系统比传统的 Linux 系统要少得多。我们还有非常全面的文档(所有链接都来自主页)关于 systemd 的几乎所有细节,这不仅涵盖了管理/面向用户的界面,还涵盖了开发人员 API。
systemd 肯定有一个学习曲线。什么都行。但是,我们愿意相信对于大多数人来说,理解 systemd 实际上比基于 Shell 的引导更简单。惊讶我们这么说?嗯,事实证明,Shell 不是一门漂亮的语言,它的语法既神秘又复杂。systemd 单元文件更容易理解,它们不公开编程语言,但本质上简单且具有声明性。话虽如此,如果您对 shell 有经验,那么是的,采用 systemd 需要一些学习。
为了让学习更容易,我们努力提供与以前解决方案的最大兼容性。但不仅如此,在许多发行版中,您会发现一些传统工具现在甚至会告诉您——在执行您要求的操作时——您可以如何使用较新的工具以一种可能更好的方式来完成它.
无论如何,要点可能是 systemd 可能像这样的系统一样简单,并且我们努力使其易于学习。但是,是的,如果您了解 sysvinit,那么采用 systemd 需要一些学习,但坦率地说,如果您掌握了 sysvinit,那么 systemd 对您来说应该很容易。
-
误解:systemd 不是模块化的。
根本不是真的。在编译时,您有许多 配置开关来选择要构建的内容和不构建的内容。而我们的文件,你如何在选择的更多详细信息,你需要什么,超越我们的配置开关。
这种模块化与 Linux 内核的完全不同,在 Linux 内核中,您可以在编译时单独选择许多功能。如果内核对您来说足够模块化,那么 systemd 也应该非常接近。
-
误解:systemd 仅适用于台式机。
这当然不是真的。使用 systemd,我们尝试覆盖与 Linux 本身几乎相同的范围。虽然我们关心桌面使用,但我们也关心服务器使用和嵌入式使用的方式几乎相同。您可以打赌,如果 Red Hat 不是管理服务器上的服务的最佳选择,那么它不会成为 RHEL7 的核心部分。
许多公司的人都在使用 systemd。汽车制造商将其组装到汽车中,Red Hat 将其用于服务器操作系统,而 GNOME 则使用其许多界面来改进桌面。你可以在玩具、太空望远镜和风力涡轮机中找到它。
我最近研究的大多数功能可能主要与服务器相关,例如容器支持、资源管理或安全功能。我们已经很好地涵盖了桌面系统,并且有许多公司在为嵌入式系统开发,有些甚至提供咨询服务。
-
误解:systemd 是由于 NIH 综合症而创建的。
这不是真的。在我们开始研究 systemd 之前,我们一直在推动 Canonical 的 Upstart 被广泛采用(Fedora/RHEL 也使用了一段时间)。然而,我们最终得出的结论是,它的设计在其核心本质上存在缺陷(至少在我们看来:最根本的是,它将依赖管理留给管理员/开发人员,而不是在代码中解决这个难题),如果有什么核心错误你最好更换它,而不是修复它。但这并不是唯一的原因,其他因素也起作用,例如许可/贡献协议。NIH 不是原因之一,但... [3]
-
误解:systemd 是一个 freedesktop.org 项目。
好吧,systemd 肯定托管在 fdo,但 freedesktop.org 只不过是代码和文档的存储库。几乎任何编码人员都可以在那里请求一个存储库并将他的东西转储到那里(只要它与免费系统的基础设施有些相关)。没有阴谋集团,没有“标准化”计划,没有项目审查,什么都没有。它只是一个很好的、免费的、可靠的地方来拥有你的存储库。在这方面,它有点像 SourceForge、github、kernel.org,只是不是商业性的,也没有过多的要求,因此是保存我们东西的好地方。
所以是的,我们在 fdo 托管我们的东西,但是这个神话的隐含假设是有一群人会面然后就未来的自由系统的样子达成一致,这完全是假的。
-
误解:systemd 不是 UNIX。
这当然有一定的道理。systemd 的源代码不包含源自原始 UNIX 的一行代码。然而,我们从 UNIX 中获得灵感,因此 systemd 中有大量的 UNIX。例如,UNIX 的“一切都是文件”的想法反映在 systemd 中所有服务都在运行时在内核文件系统cgroupfs 中公开。然后,UNIX 的原始特性之一是基于内置终端支持的多座支持。然而,如今文本终端几乎不是您与计算机交互的最先进技术。通过 systemd,我们带来了原生的多席位 支持回来,但这次完全支持当今的硬件,涵盖图形、鼠标、音频、网络摄像头等,以及所有全自动、热插拔功能且无需配置。事实上,将 systemd 设计为一套集成工具,每个工具都有各自的用途,但当一起使用时,它不仅仅是各部分的总和,这几乎是 UNIX 哲学的核心。然后,我们项目的处理方式(即在单个 git 存储库中维护大部分核心操作系统)更接近 BSD 模型(这是一个真正的 UNIX,与 Linux 不同)的处事方式(其中大部分核心操作系统位于保存在一个 CVS/SVN 存储库中),而不是 Linux 上的东西。
归根结底,UNIX 对每个人来说都是不同的。对于我们 systemd 维护者来说,这是我们从中获得灵感的东西。对于其他人来说,它是一种宗教,就像其他世界宗教一样,对它有不同的解读和理解。有些人根据特定的代码遗产来定义 UNIX,有些人将其视为一组想法,有些人将其视为一组命令或 API,甚至其他人将其视为行为定义。当然,要让所有这些人都开心是不可能的。
最终,某个东西是否是 UNIX 的问题并不重要。技术上的优秀并不是 UNIX 独有的。对我们来说,UNIX 是一个主要的影响因素(见鬼,最大的一个),但我们也有其他影响。因此,在某些领域 systemd 将非常 UNIXy,而在其他领域则少一些。
-
误解:systemd 很复杂。
这当然有一定的道理。现代计算机是复杂的野兽,因此在其上运行的操作系统也必须很复杂。但是,systemd 肯定不会比相同组件的先前实现更复杂。相反,它更简单,冗余更少(见上文)。此外,基于 systemd 构建一个简单的操作系统将比传统的 Linux 包含更少的包。更少的包可以更轻松地构建您的系统,摆脱相互依赖关系以及所涉及的每个组件的许多不同行为。
-
误解:systemd 很臃肿。
好吧,臃肿当然有很多不同的定义。但在大多数定义中,systemd 可能与膨胀相反。由于 systemd 组件共享一个公共代码库,它们倾向于为公共代码路径共享更多代码。这是一个例子:在传统的 Linux 设置中,sysvinit、start-stop-daemon、inetd、cron、dbus,都实现了一个方案,在某个希望干净的环境中使用各种配置选项执行进程。在 systemd 上,所有这些的代码路径、配置解析以及实际执行都是共享的。这意味着更少的代码、更少的错误、更少的内存和缓存压力,因此是一件非常好的事情。作为一个副作用,你实际上获得了更多的功能......
如上所述,systemd 也非常模块化。您可以在构建时选择需要和不需要的组件。因此,人们可以专门选择他们想要的“膨胀”级别。
在构建 systemd 时,它只需要三个依赖项:glibc、libcap 和 dbus。而已。它可以使用更多的依赖项,但这些完全是可选的。
所以,是的,无论你怎么看,它都不 臃肿。
-
误区:systemd 只支持 Linux 对 BSD 不利。
完全错误。BSD 人员对 systemd 几乎不感兴趣。如果 systemd 是可移植的,这不会改变什么,他们仍然不会采用它。世界上的其他 Unix 也是如此。Solaris 有 SMF,BSD 有他们自己的“rc”系统,并且他们总是将它与 Linux 分开维护。init 系统非常接近整个操作系统的核心。因此,这些其他操作系统通过其核心用户空间来定义自己。假设如果我们只是让它可移植,他们就会采用我们的核心用户空间,这是完全没有任何基础的。
-
神话:systemd 仅支持 Linux,因此 Debian 不可能将其作为默认设置。
Debian 在其发行版中支持非 Linux 内核。systemd 不会在这些上运行。不过,这是一个问题吗,这是否会阻碍他们采用系统作为默认设置?并不真地。将 Debian 移植到这些其他内核的人们愿意投入时间进行大量移植工作,他们建立了测试和构建系统,并为他们的目标修补和构建了许多软件包。与此相比,为打包服务维护 systemd 单元文件和经典 init 脚本的工作量可以忽略不计,尤其是因为这些脚本通常已经存在。
-
神话:如果 systemd 的维护者愿意,它可以移植到其他内核。
那明显是错的。将 systemd 移植到其他内核是不可行的。我们只是使用了太多 Linux 特定的接口。对于少数人可能会在其他内核上找到替代品,一些人可能想要关闭某些功能,但对于大多数人来说,这也不是真的可能。这是一个很小的、非常不全面的列表:cgroups、fanotify、umount2()、/proc/self/mountinfo(包括通知)、/dev/ swaps(相同)、udev、netlink、/sys的结构、/proc/$PID /comm, /proc/$PID/cmdline, /proc/$PID/loginuid, /proc/$PID/stat, /proc/$PID/session, /proc/$PID/exe, /proc/$PID/fd一样,tmpfs,devtmpfs, 能力,各种命名空间,各种使用prctl()秒,无数的 读写控制,在安装()系统调用及其语义,selinux,审计,inotify,statfs,O_DIRECTORY,O_NOATIME,/proc/$PID/root,waitid(),SCM_CREDENTIALS,SCM_RIGHTS,mkostemp(),/dev/input,...
不,如果您查看此列表并挑选出少数您可以在其他内核上想到明显对应项的地方,然后再考虑一下,并查看您没有挑选的其他内核,以及替换它们的复杂性。
-
误解:systemd 无缘无故不可移植。
废话!我们使用 Linux 特定的功能是因为我们需要它来实现我们想要的。Linux 具有 UNIX/POSIX 所没有的众多功能,我们希望为用户提供这些功能。这些功能非常有用,但前提是它们实际上以友好的方式向用户公开,这就是我们对 systemd 所做的。
-
误解:systemd 使用二进制配置文件。
不知道是谁想出了这个疯狂的神话,但这绝对不是真的。systemd 几乎完全通过简单的文本文件进行配置。您还可以使用内核命令行和环境变量更改一些设置。它的配置中没有任何二进制文件(甚至没有 XML)。只是简单、简单、易于阅读的文本文件。
-
误区:systemd 是一个功能蠕变。
好吧,systemd 肯定涵盖了它过去的更多领域。它不再只是一个 init 系统,而是构建操作系统的基本用户空间构建块,但我们仔细确保大多数功能都是可选的。您可以在编译时关闭很多功能,甚至在运行时关闭更多功能。因此,您可以自由选择所需的功能爬行量。
-
误解:systemd 强迫你做某事。
systemd 不是黑手党。它是自由软件,您可以随心所欲地使用它,这包括不使用它。这几乎与“强迫”相反。
-
误解:systemd 使运行 syslog 变得不可能。
不是真的,我们在引入日志时仔细确保所有数据也传递给任何正在运行的 syslog 守护进程。事实上,如果有什么变化,那么只有那个 syslog 现在获得比以前更完整的数据,因为我们现在涵盖早期启动内容以及任何系统服务的 STDOUT/STDERR。
-
误解:systemd 不兼容。
我们非常努力地提供与 sysvinit 的最佳兼容性。事实上,绝大多数 init 脚本应该可以在 systemd 上正常工作,未经修改。然而,实际上确实存在一些不兼容性,但我们尝试记录这些并解释如何处理它们。最终,实际上不是 sysvinit 本身的每个系统都会与它有一定的不兼容,因为它不会共享相同的代码路径。
我们的目标是确保各种分布之间的差异保持在最低限度。这意味着单元文件通常可以在与您编写的不同发行版上正常工作,这与经典的 init 脚本相比有了很大的改进,这些脚本很难以在多个 Linux 发行版上运行的方式编写,因为它们之间存在许多不兼容性.
-
误解:systemd 不可编写脚本,因为它使用 D-Bus。
不对。systemd 提供的几乎每个 D-Bus 接口也可以在命令行工具中使用,例如在systemctl、 loginctl、 timedatectl、 hostnamectl、 localectl 等中。您可以从 shell 脚本轻松调用这些工具,它们通过易于使用的命令从命令行打开几乎整个 API。
也就是说,D-Bus 实际上绑定了世界上几乎所有已知的脚本语言。即使在 shell 中,您也可以使用dbus-send 或gdbus调用任意 D-Bus 方法。如果有的话,由于 D-Bus 在各种脚本语言中的良好支持,这提高了脚本能力。
-
误解:systemd 要求您使用一些神秘的配置工具,而不是允许您直接编辑配置文件。
根本不是真的。我们提供了一些配置工具,使用它们可以获得一些额外的功能(例如,所有设置的命令行完成!),但根本不需要使用它们。如果您愿意,您可以随时直接编辑有问题的文件,这是完全支持的。当然,有时您需要在编辑配置后显式重新加载某些守护程序的配置,但这对于大多数 UNIX 服务来说几乎是正确的。
-
误解:systemd 不稳定且有问题。
当然不是根据我们的数据。很长一段时间以来,我们一直在密切监视 Fedora 错误跟踪器(和其他一些)。对于操作系统的这样一个核心组件来说,错误的数量非常少,特别是如果您不考虑我们为项目跟踪的众多 RFE 错误。我们很好地将 systemd 排除在发行版的阻止程序错误列表之外。我们有一个相对较快的开发周期,主要是增量更改以保持高质量和稳定性。
-
误解:systemd 不可调试。
错误的。有些人试图暗示 shell 是一个很好的调试器。嗯,这不是真的。在 systemd 中,我们为您提供了实际的调试功能。例如:交互式调试、详细跟踪、屏蔽任何
热点上 高跟鞋 的的 以前的故事,这里是 现在 的 第十八 批 的 我 正在进行的 一系列 关于 systemd 为 管理员:
管理资源
现代计算的一个重要方面是资源管理:如果您在一台机器上运行多个程序,您希望将可用资源分配给它们以执行特定策略。这对于稀缺资源是主要限制因素的小型嵌入式或移动系统尤为重要,但同样适用于资源充足但单个节点上的程序/服务/容器数量急剧增加的大型安装,例如云设置更高。
传统上,在 Linux 上只有一个策略是真正可用的:所有进程获得大致相同的 CPU 时间或 IO 带宽,通过进程nice值进行一些调整。这种方法非常简单,并且在很长一段时间内都很好地涵盖了 Linux 的各种用途。然而,它有缺点:并非所有进程都应该是偶数,并且涉及大量进程的服务(想想:Apache 有很多 CGI 工人)这种方式会比很少的服务获得更多的资源(想想:syslog)。
在考虑 systemd 的服务管理时,我们很快意识到资源管理必须是它的核心功能。在现代世界中——无论是服务器还是嵌入式——控制各种服务的 CPU、内存和 IO 资源不能事后考虑,而必须作为一流的服务设置内置。并且它必须是针对每个服务的,而不是像传统的 nice 值或POSIX 资源限制那样针对每个进程。
在这个故事中,我想阐明您可以采取哪些措施来对 systemd 服务实施资源策略。以一种或另一种方式进行的资源管理已经在 systemd 中可用一段时间了,所以现在是我们向更广泛的受众介绍它的时候了。
在之前的一篇博文中,我强调了 Linux Control Croups (cgroups) 作为标记的分层分组机制与 Linux cgroups 作为资源控制子系统之间的区别。systemd 需要前者,后者是可选的。现在我们可以利用这个可选的后半部分来管理每个服务的资源。(在这一点上,在继续阅读之前先阅读cgroups可能是个好主意,至少要对它们是什么以及它们完成什么有一个基本的了解。即使认为下面的解释将是非常高级的,但这一切都使如果你稍微了解一下背景,就会更有意义。)
用于资源管理的主要 Linux cgroup 控制器是cpu、 memory 和blkio。要使用这些,它们需要在内核中启用,许多发行版(包括 Fedora)都这样做。systemd 公开了几个高级服务设置来使用这些控制器,而无需了解过多的内核细节。
管理 CPU
作为一个很好的默认设置,如果在内核中启用了cpu控制器,systemd 将在启动时为每个服务创建一个 cgroup。没有任何进一步的配置,这已经有一个很好的效果:在 systemd 系统上,每个系统服务都将获得相等数量的 CPU,无论它包含多少个进程。或者换句话说:在您的 Web 服务器上,MySQL 将获得与 Apache 大致相同数量的 CPU,即使后者包含 1000 个 CGI 脚本进程,但前者仅包含几个工作任务。(此行为可以被关闭,参见DefaultControllers = 在/etc/systemd/system.conf。)
除了此默认设置之外,还可以使用CPUShares= 设置显式配置服务获取的 CPU 份额。默认值是 1024,如果你增加这个数字,你会比未改变的 1024 分配更多的 CPU 给服务,如果你减少它,更少。
让我们更详细地看看我们如何利用它。假设我们要分配 Apache 1500 CPU 份额而不是默认的 1024。为此,让我们在/etc/systemd/system/httpd.service 中为 Apache 创建一个新的管理员服务文件,覆盖供应商在/usr/ 中提供的服务文件lib/systemd/system/httpd.service,但让我们更改CPUShares=参数:
.include /usr/lib/systemd/system/httpd.service [服务] CPU份额=1500
第一行将拉入供应商服务文件。现在,让我们重新加载 systemd 的配置并重新启动 Apache,以便考虑新的服务文件:
systemctl 守护进程重新加载 systemctl restart httpd.service
是的,就是这样,你完成了!
(请注意,在单元文件中设置CPUShares=将导致特定服务在cpu层次结构中获得自己的 cgroup ,即使cpu未包含在 DefaultControllers= 中。)
分析资源使用情况
当然,在没有真正了解问题服务的资源使用情况的情况下更改资源分配就像盲目飞行。为了帮助您了解所有服务的资源使用情况,我们创建了工具systemd-cgtop,它将枚举系统的所有 cgroup,确定它们的资源使用情况(CPU、内存和 IO)并以类似top的方式呈现它们。基于 systemd 服务在 cgroups 中管理的事实,此工具因此可以向您展示 top 向您展示的流程的服务。
不幸的是,默认情况下cgtop只能为您绘制每个服务的 CPU 使用率图表,IO 和内存仅作为整个机器的总数进行跟踪。原因很简单,默认情况下blkio和 内存控制器层次结构中没有每个服务的 cgroup,但这正是我们确定资源使用情况所需要的。为所有服务获取这些数据的最佳方法是简单地将内存和blkio 控制器添加到system.conf 中前面提到的DefaultControllers=设置中。
管理内存
为了强制限制内存 systemd为服务提供 MemoryLimit=和MemorySoftLimit=设置,总结其所有进程的内存。这些设置采用内存大小(以字节为单位),即服务的总内存限制。此设置理解 Kilobyte、Megabyte、Gigabyte、Terabyte(以 1024 为基数)的常用 K、M、G、T 后缀。
.include /usr/lib/systemd/system/httpd.service [服务] 内存限制=1G
(类似于 CPUShares=以上设置此选项将导致服务在内存cgroup 层次结构中获得自己的 cgroup 。)
管理块 IO
要控制块 IO,可以使用多种设置。首先, 可以使用BlockIOWeight= 为特定服务分配 IO权重。在行为上,权重概念与CPU 资源控制的份额概念没有什么不同(见上文)。但是,默认权重为 1000,有效范围为 10 到 1000:
.include /usr/lib/systemd/system/httpd.service [服务] 块IO权重=500
或者,可以指定每个设备的权重:
.include /usr/lib/systemd/system/httpd.service [服务] BlockIOWeight=/dev/disk/by-id/ata-SAMSUNG_MMCRE28G8MXP-0VBL1_DC06K01009SE009B5252 750
您还可以指定文件系统中的任何路径,而不是指定实际的设备节点:
.include /usr/lib/systemd/system/httpd.service [服务] BlockIOWeight=/home/lennart 750
如果指定的路径不指向设备节点,systemd 将确定块设备/home/lennart已打开,并为其分配带宽权重。
您甚至可以同时添加每个设备和普通线,这将为设备设置每个设备的权重,并将其他值设置为其他所有设备的默认值。
或者,可以使用BlockIOReadBandwidth=和BlockIOWriteBandwidth= 设置来控制显式带宽限制 。这些设置采用一对设备节点和带宽速率(以每秒字节数为单位)或文件路径和带宽速率:
.include /usr/lib/systemd/system/httpd.service [服务] BlockIOReadBandwith=/var/log 5M
这将支持/var/log的块设备上的最大读取带宽设置 为 5Mb/s。
(类似于 CPUShares=和MemoryLimit=使用这三个设置中的任何一个都会导致服务在blkio层次结构中获得自己的 cgroup 。)
管理其他资源参数
上述选项仅涵盖各种 Linux 控制组控制器公开的可用控件的一小部分。我们选择了这些并为它们添加了高级选项,因为我们假设这些与大多数人最相关,并且他们确实需要一个可以正确处理单元并解析块设备名称的漂亮界面。
在许多情况下,上面解释的选项可能不足以满足您的用例,但低级内核 cgroup 设置可能会有所帮助。很容易从 systemd 单元文件中使用这些选项,而无需对它们进行高级设置。例如,有时设置服务的swappiness可能很有用。内核通过memory.swappiness cgroup 属性使其可控,但 systemd 并未将其公开为高级选项。尽管如此,您仍然可以使用低级ControlGroupAttribute=设置来使用它 :
.include /usr/lib/systemd/system/httpd.service [服务] ControlGroupAttribute=memory.swappiness 70
(与其他情况类似,这也会导致将服务添加到内存层次结构中。)
稍后我们可能会为各种 cgroup 属性添加更多高级控件。事实上,如果您经常使用它并认为它值得更多关注,请联系我们。然后我们会考虑为它添加一个高级选项。(更好的是:向我们发送补丁!)
免责声明:请注意,使用各种资源控制器确实会对系统产生运行时影响。实施资源限制是有代价的。如果您确实使用它们,某些操作确实会变慢。尤其是内存控制器(曾经有过?)以牺牲性能为代价的坏名声。
有关所有这些的更多详细信息,请查看上述单元设置以及cpu、 内存 和blkio 控制器的文档。
这就是现在。当然,这个博客故事只关注每个服务的资源设置。最重要的是,您还可以设置更传统的、众所周知的每个进程的资源设置,然后这些设置将被各种子进程继承,但始终只对每个进程强制执行。更具体地说,是 IOSchedulingClass=、IOSchedulingPriority=、 CPUSchedulingPolicy=、CPUSchedulingPriority=、 CPUAffinity=、LimitCPU=和相关的。这些不使用 cgroup 控制器并且具有低得多的性能成本。我们可能会在以后的文章中更详细地介绍这些内容。
面向管理员的 systemd,第十八部分http://0pointer.de/blog/projects/resources.html
面向管理员的 systemd,第 XII 部分http://0pointer.de/blog/projects/security.html
最棒、最少广告的 Fedora 17 功能http://0pointer.de/blog/projects/multi-seat.html
不兼容https://www.freedesktop.org/wiki/Software/systemd/Incompatibilities/
系统控制https://www.freedesktop.org/software/systemd/man/systemctl.html
登录https://www.freedesktop.org/software/systemd/man/loginctl.html
时间控制https://www.freedesktop.org/software/systemd/man/timedatectl.html
主机名https://www.freedesktop.org/software/systemd/man/hostnamectl.html
本地化https://www.freedesktop.org/software/systemd/man/localectl.html
dbus-send https://dbus.freedesktop.org/doc/dbus-send.1.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号