redis,详解三种集群策略,Redis Lua 脚本
Redis中5种数据结构的使用场景介绍 - SegmentFault 思否
redis:详解三种集群策略_卜可的博客-CSDN博客_redis集群三种方式
redis包含三种集群策略
- 主从复制
- 哨兵
- 集群
主从复制
在主从复制中,数据库分为俩类,主数据库(master)和从数据库(slave)。其中主从复制有如下特点:
- 主数据库可以进行读写操作,当读写操作导致数据变化时会自动将数据同步给从数据库
- 从数据库一般都是只读的,并且接收主数据库同步过来的数据
- 一个master可以拥有多个slave,但是一个slave只能对应一个master
主从复制工作机制
当slave启动后,主动向master发送SYNC命令。master接收到SYNC命令后在后台保存快照(RDB持久化)和缓存保存快照这段时间的命令,然后将保存的快照文件和缓存的命令发送给slave。slave接收到快照文件和命令后加载快照文件和缓存的执行命令。
复制初始化后,master每次接收到的写命令都会同步发送给slave,保证主从数据一致性。
主从配置
redis默认是主数据,所以master无需配置,我们只需要修改slave的配置即可。
设置需要连接的master的ip端口:
slaveof 192.168.0.107 6379
如果master设置了密码。需要配置:
masterauth
连接成功进入命令行后,可以通过以下命令行查看连接该数据库的其他库信息:
info replication
哨兵
哨兵的作用是监控 redis系统的运行状况,他的功能如下:
- 监控主从数据库是否正常运行
- master出现故障时,自动将slave转化为master
- 多哨兵配置的时候,哨兵之间也会自动监控
- 多个哨兵可以监控同一个redis
哨兵工作机制
哨兵进程启动时会读取配置文件的内容,通过sentinel monitor master-name ip port quorum查找到master的ip端口。一个哨兵可以监控多个master数据库,只需要提供多个该配置项即可。
同事配置文件还定义了与监控相关的参数,比如master多长时间无响应即即判定位为下线。
哨兵启动后,会与要监控的master建立俩条连接:
- 一条连接用来订阅master的
_sentinel_:hello频道与获取其他监控该master的哨兵节点信息 - 另一条连接定期向master发送INFO等命令获取master本身的信息
与master建立连接后,哨兵会执行三个操作,这三个操作的发送频率都可以在配置文件中配置:
- 定期向master和slave发送INFO命令
- 定期向master个slave的_sentinel_:hello频道发送自己的信息
- 定期向master、slave和其他哨兵发送PING命令
这三个操作的意义非常重大,发送INFO命令可以获取当前数据库的相关信息从而实现新节点的自动发现。所以说哨兵只需要配置master数据库信息就可以自动发现其slave信息。获取到slave信息后,哨兵也会与slave建立俩条连接执行监控。通过INFO命令,哨兵可以获取主从数据库的最新信息,并进行相应的操作,比如角色变更等。
接下来哨兵向主从数据库的_sentinel_:hello频道发送信息与同样监控这些数据库的哨兵共享自己的信息,发送内容为哨兵的ip端口、运行id、配置版本、master名字、master的ip端口还有master的配置版本。这些信息有以下用处:
- 其他哨兵可以通过该信息判断发送者是否是新发现的哨兵,如果是的话会创建一个到该哨兵的连接用于发送PIN命令。
- 其他哨兵通过该信息可以判断master的版本,如果该版本高于直接记录的版本,将会更新
当实现了自动发现slave和其他哨兵节点后,哨兵就可以通过定期发送PING命令定时监控这些数据库和节点有没有停止服务。发送频率可以配置,但是最长间隔时间为1s,可以通过sentinel down-after-milliseconds mymaster 600设置。
如果被ping的数据库或者节点超时未回复,哨兵任务其主观下线。如果下线的是master,哨兵会向其他哨兵点发送命令询问他们是否也认为该master主观下线,如果达到一定数目(即配置文件中的quorum)投票,哨兵会认为该master已经客观下线,并选举领头的哨兵节点对主从系统发起故障恢复。
如上文所说,哨兵认为master客观下线后,故障恢复的操作需要由选举的领头哨兵执行,选举采用Raft算法:
- 发现master下线的哨兵节点(我们称他为A)向每个哨兵发送命令,要求对方选自己为领头哨兵
- 如果目标哨兵节点没有选过其他人,则会同意选举A为领头哨兵
- 如果有超过一半的哨兵同意选举A为领头,则A当选
- 如果有多个哨兵节点同时参选领头,此时有可能存在一轮投票无竞选者胜出,此时每个参选的节点等待一个随机时间后再次发起参选请求,进行下一轮投票精选,直至选举出领头哨兵
选出领头哨兵后,领头者开始对进行故障恢复,从出现故障的master的从数据库中挑选一个来当选新的master,选择规则如下:
- 所有在线的slave中选择优先级最高的,优先级可以通过
slave-priority配置 - 如果有多个最高优先级的slave,则选取复制偏移量最大(即复制越完整)的当选
- 如果以上条件都一样,选取id最小的slave
挑选出需要继任的slaver后,领头哨兵向该数据库发送命令使其升格为master,然后再向其他slave发送命令接受新的master,最后更新数据。将已经停止的旧的master更新为新的master的从数据库,使其恢复服务后以slave的身份继续运行。
哨兵配置
哨兵配置的配置文件为sentinel.conf,设置主机名称,地址,端口,以及选举票数即恢复时最少需要几个哨兵节点同意。
sentinel monitor mymaster 192.168.0.107 6379 1
只要配置需要监控的master就可以了,哨兵会监控连接该master的slave。
启动哨兵节点:
redis-server sentinel.conf --sentinel &
出现如下内容表示启动成功
[root@buke110 redis]# bin/redis-server etc/sentinel.conf --sentinel &
[1] 3072
[root@buke110 redis]# 3072:X 12 Apr 22:40:02.503 * Increased maximum number of open files to 10032 (it was originally set to 1024).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 2.9.102 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 3072
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
3072:X 12 Apr 22:40:02.554 # Sentinel runid is e510bd95d4deba3261de72272130322b2ba650e7
3072:X 12 Apr 22:40:02.554 # +monitor master mymaster 192.168.0.107 6379 quorum 1
3072:X 12 Apr 22:40:03.516 * +slave slave 192.168.0.108:6379 192.168.0.108 6379 @ mymaster 192.168.0.107 6379
3072:X 12 Apr 22:40:03.516 * +slave slave 192.168.0.109:6379 192.168.0.109 6379 @ mymaster 192.168.0.107 6379
可以在任何一台服务器上查看指定哨兵节点信息:
bin/redis-cli -h 192.168.0.110 -p 26379 info Sentinel
控制台输出哨兵信息:
[root@buke107 redis]# bin/redis-cli -h 192.168.0.110 -p 26379 info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=mymaster,status=ok,address=192.168.0.107:6379,slaves=2,sentinels=1
集群
使用集群,只需要将每个数据库节点的cluster-enable配置打开即可。每个集群中至少需要三个主数据库才能正常运行。
集群配置
安装依赖环境ruby,注意ruby版本必须高于2.2
yum install ruby
yum install rubygems
gem install redis
修改配置文件:
bind 192.168.0.107
配置端口
port 6380
配置快照保存路径
dir /usr/local/redis-cluster/6380/
开启集群
cluster-enabled yes
为节点设置不同的工作目录
cluster-config-file nodes-6380.conf
集群失效时间
cluster-node-timeout 15000
开启集群中的节点:
reids-service …/6380/redis.conf
将节点加入集群中
redis-trib.rb create --replicas 1 192.168.0.107:6380 192.168.0.107:6381 192.168.0.107:6382 192.168.0.107:6383 192.168.0.107:6384 192.168.0.107:6385
中途需要输入yes确定创建集群:
[root@buke107 src]# redis-trib.rb create --replicas 1 192.168.0.107:6380 192.168.0.107:6381 192.168.0.107:6382 192.168.0.107:6383 192.168.0.107:6384 192.168.0.107:6385
>>> Creating cluster
Connecting to node 192.168.0.107:6380: OK
Connecting to node 192.168.0.107:6381: OK
Connecting to node 192.168.0.107:6382: OK
Connecting to node 192.168.0.107:6383: OK
Connecting to node 192.168.0.107:6384: OK
Connecting to node 192.168.0.107:6385: OK
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.0.107:6380
192.168.0.107:6381
192.168.0.107:6382
Adding replica 192.168.0.107:6383 to 192.168.0.107:6380
Adding replica 192.168.0.107:6384 to 192.168.0.107:6381
Adding replica 192.168.0.107:6385 to 192.168.0.107:6382
M: 5cd3ed3a84ead41a765abd3781b98950d452c958 192.168.0.107:6380
slots:0-5460 (5461 slots) master
M: 90b4b326d579f9b5e181e3df95578bceba29b204 192.168.0.107:6381
slots:5461-10922 (5462 slots) master
M: 868456121fa4e6c8e7abe235a88b51d354a944b5 192.168.0.107:6382
slots:10923-16383 (5461 slots) master
S: b8e047aeacb9398c3f58f96d0602efbbea2078e2 192.168.0.107:6383
replicates 5cd3ed3a84ead41a765abd3781b98950d452c958
S: 68cf66359318b26df16ebf95ba0c00d9f6b2c63e 192.168.0.107:6384
replicates 90b4b326d579f9b5e181e3df95578bceba29b204
S: d6d01fd8f1e5b9f8fc0c748e08248a358da3638d 192.168.0.107:6385
replicates 868456121fa4e6c8e7abe235a88b51d354a944b5
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join....
>>> Performing Cluster Check (using node 192.168.0.107:6380)
M: 5cd3ed3a84ead41a765abd3781b98950d452c958 192.168.0.107:6380
slots:0-5460 (5461 slots) master
M: 90b4b326d579f9b5e181e3df95578bceba29b204 192.168.0.107:6381
slots:5461-10922 (5462 slots) master
M: 868456121fa4e6c8e7abe235a88b51d354a944b5 192.168.0.107:6382
slots:10923-16383 (5461 slots) master
M: b8e047aeacb9398c3f58f96d0602efbbea2078e2 192.168.0.107:6383
slots: (0 slots) master
replicates 5cd3ed3a84ead41a765abd3781b98950d452c958
M: 68cf66359318b26df16ebf95ba0c00d9f6b2c63e 192.168.0.107:6384
slots: (0 slots) master
replicates 90b4b326d579f9b5e181e3df95578bceba29b204
M: d6d01fd8f1e5b9f8fc0c748e08248a358da3638d 192.168.0.107:6385
slots: (0 slots) master
replicates 868456121fa4e6c8e7abe235a88b51d354a944b5
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
进入任何一个集群中的节点:
redis-cli -c -h 192.168.0.107 -p 6381
查看集群中的节点:
[root@buke107 src]# redis-cli -c -h 192.168.0.107 -p 6381
192.168.0.107:6381> cluster nodes
868456121fa4e6c8e7abe235a88b51d354a944b5 192.168.0.107:6382 master - 0 1523609792598 3 connected 10923-16383
d6d01fd8f1e5b9f8fc0c748e08248a358da3638d 192.168.0.107:6385 slave 868456121fa4e6c8e7abe235a88b51d354a944b5 0 1523609795616 6 connected
5cd3ed3a84ead41a765abd3781b98950d452c958 192.168.0.107:6380 master - 0 1523609794610 1 connected 0-5460
b8e047aeacb9398c3f58f96d0602efbbea2078e2 192.168.0.107:6383 slave 5cd3ed3a84ead41a765abd3781b98950d452c958 0 1523609797629 1 connected
68cf66359318b26df16ebf95ba0c00d9f6b2c63e 192.168.0.107:6384 slave 90b4b326d579f9b5e181e3df95578bceba29b204 0 1523609796622 5 connected
90b4b326d579f9b5e181e3df95578bceba29b204 192.168.0.107:6381 myself,master - 0 0 2 connected 5461-10922
如上图所示,已经建立起三主三从的集群。
增加集群节点
cluster meet ip port
Redis Lua 脚本 - SegmentFault 思否
Lua 简介
Lua语言提供了如下几种数据类型:booleans(布尔)、numbers(数值)、strings(字符串)、tables(表格)。
下面是一些 Lua 的示例,里面注释部分会讲解相关的作用:
--
--
-- 拿客
-- 网站:www.coderknock.com
-- QQ群:213732117
-- 三产 创建于 2017年06月15日 12:04:54。
-- 描述:
--
--
local strings website = "coderknock.com"
print(website)
local tables testArray = { website, "sanchan", true, 2, 3.1415926 }
-- 遍历 testArray
print("======== testArray =======")
for i = 1, #testArray
do
print(testArray[i])
end
-- 另一种遍历方式
print("======== in testArray =======")
for index, value in ipairs(testArray)
do
-- 这种方式拼接 boolean 是会报错
print("index ---->"..index)
-- 这种组合大量数据时效率高
print(value)
end
--while 循环
print("======== while =======")
local int sum = 0
local int i = 0
while i <= 100
do
sum = sum +i
i = i + 1
end
--输出结果为5050
print(sum)
--if else
print("======== if else =======")
for i = 1, #testArray
do
if testArray[i] == "sanchan"
then
print("true")
break
else
print(testArray[i])
end
end
-- 哈希
local tables user_1 = { age = 28, name = "tome" }
--user_1 age is 28
print("======== hash =======")
print(user_1["name"].." age is " .. user_1["age"])
print("======== in hash =======")
for key, value in pairs(user_1)
do
print(key .. ":".. value)
end
print("======== function =======")
function funcName(str)
-- 代码逻辑
print(str)
return "new"..str
end
print(funcName("123"))Redis 中执行 Lua 脚本
Lua脚本功能为Redis开发和运维人员带来如下三个好处:
-
Lua脚本在Redis中是原子执行的,执行过程中间不会插入其他命令。
-
Lua脚本可以帮助开发和运维人员创造出自己定制的命令,并可以将这些命令常驻在Redis内存中,实现复用的效果。
-
Lua脚本可以将多条命令一次性打包,有效地减少网络开销。
EVAL
自2.6.0可用。
时间复杂度:EVAL 和 EVALSHA 可以在 O(1) 复杂度内找到要被执行的脚本,其余的复杂度取决于执行的脚本本身。
语法:EVAL script numkeys key [key ...] arg [arg ...]
说明:
从 Redis 2.6.0 版本开始,通过内置的 Lua 解释器,可以使用 EVAL 命令对 Lua 脚本进行求值。
script 参数是一段 Lua 5.1 脚本程序,它会被运行在 Redis 服务器上下文中,这段脚本不必(也不应该)定义为一个 Lua 函数。
numkeys 参数用于指定键名参数的个数。
键名参数 key [key ...] 从 EVAL 的第三个参数开始算起,表示在脚本中所用到的那些 Redis 键(key),这些键名参数可以在 Lua 中通过全局变量 KEYS 数组,用 1 为起始所有的形式访问( KEYS[1] , KEYS[2] ,以此类推)。
在命令的最后是那些不是键名参数的附加参数 arg [arg ...] ,可以在 Lua 中通过全局变量 ARGV 数组访问,访问的形式和 KEYS 变量类似( ARGV[1] 、 ARGV[2] ,诸如此类)。
上面这几段长长的说明可以用一个简单的例子来概括:
coderknock>EVAL 'return "return String KEYS1: "..KEYS[1].." KEYS2: ".." "..KEYS[2].." ARGV1: "..ARGV[1].." ARGV2: "..ARGV[2]' 3 KEYS1Str KEYS2Str KEYS3Str ARGV1Str ARGV2Str ARGV3Str ARGV4Str
"return String KEYS1: KEYS1Str KEYS2: KEYS2Str ARGV1: ARGV1Str ARGV2: ARGV2Str"在 Lua 脚本中,可以使用两个不同函数来执行 Redis 命令,它们分别是:
-
redis.call() -
redis.pcall()
这两个函数的唯一区别在于它们使用不同的方式处理执行命令所产生的错误,在后面的『错误处理』部分会讲到这一点。
redis.call() 和 redis.pcall() 两个函数的参数可以是任何格式良好(well formed)的 Redis 命令:
# 最后的 0 代表的是没有 keys 是必须的
127.0.0.1:6379> EVAL "return redis.call('SET','testLuaSet','luaSetValue')" 0
OK
127.0.0.1:6379> GET testLuaSet
"luaSetValue"
127.0.0.1:6379> EVAL "return redis.call('GET','testLuaSet')" 0
"luaSetValue"上面的脚本虽然完成了功能,但是 key 部分应该由 Redis 传入而不是在 Lua 脚本中直接写入,我们改进一下:
127.0.0.1:6379> EVAL "return redis.call('SET',KEYS[1],ARGV[1])" 1 evalShell shellTest
OK
127.0.0.1:6379> GET evalShell
"shellTest"下面我们再次改进运行多 key 插入,这里使用 Python :
import redis
r = redis.StrictRedis(host='127.0.0.1', password='admin123', port=6379, db=0)
luaScript = """
for i = 1, #KEYS
do
redis.call('SET', KEYS[i], ARGV[i])
end
return #KEYS
"""
luaSet = r.register_script(luaScript)
luaSet(keys=["pyLuaKey1", "pyLuaKey2", "pyLuaKey3"], args=["pyLuaKeyArg1", "pyLuaKeyArg2", "pyLuaKeyArg3"])
# r.eval(luaScript,)
# 下面会报错 因为 ARGV 会数组越界
# luaSet(keys=["key1", "key2", "key3"], args=["arg1"])我们在终端中验证一下是否插入成功:
127.0.0.1:6379> GET pyLuaKey1
"pyLuaKeyArg1"
127.0.0.1:6379> GET pyLuaKey2
"pyLuaKeyArg2"
127.0.0.1:6379> GET pyLuaKey3
"pyLuaKeyArg3"要求使用正确的形式来传递键(key)是有原因的,因为不仅仅是 EVAL 这个命令,所有的 Redis 命令,在执行之前都会被分析,籍此来确定命令会对哪些键进行操作。
因此,对于 EVAL 命令来说,必须使用正确的形式来传递键,才能确保分析工作正确地执行。除此之外,使用正确的形式来传递键还有很多其他好处,它的一个特别重要的用途就是确保 Redis 集群可以将你的请求发送到正确的集群节点。(对 Redis 集群的工作还在进行当中,但是脚本功能被设计成可以与集群功能保持兼容。)不过,这条规矩并不是强制性的,从而使得用户有机会滥用(abuse) Redis 单实例配置(single instance configuration),代价是这样写出的脚本不能被 Redis 集群所兼容。
在 Lua 数据类型和 Redis 数据类型之间转换
当 Lua 通过 call() 或 pcall() 函数执行 Redis 命令的时候,命令的返回值会被转换成 Lua 数据结构。同样地,当 Lua 脚本在 Redis 内置的解释器里运行时,Lua 脚本的返回值也会被转换成 Redis 协议(protocol),然后由 EVAL 将值返回给客户端。
数据类型之间的转换遵循这样一个设计原则:如果将一个 Redis 值转换成 Lua 值,之后再将转换所得的 Lua 值转换回 Redis 值,那么这个转换所得的 Redis 值应该和最初时的 Redis 值一样。
换句话说, Lua 类型和 Redis 类型之间存在着一一对应的转换关系。
以下列出的是详细的转换规则:
从 Redis 转换到 Lua :
-
Redis 整数转换成 Lua numbers
-
Redis bulk 回复转换成 Lua strings
-
Redis 多条 bulk 回复转换成 Lua tables,tables 内可能有其他别的 Redis 数据类型
-
Redis 状态回复转换成 Lua tables, tables 内的
ok域包含了状态信息 -
Redis 错误回复转换成 Lua tables ,tables 内的
err域包含了错误信息 -
Redis 的 Nil 回复和 Nil 多条回复转换成 Lua 的 booleans
false
从 Lua 转换到 Redis:
-
Lua numbers 转换成 Redis 整数
-
Lua strings 换成 Redis bulk 回复
-
Lua tables (array) 转换成 Redis 多条 bulk 回复
-
一个带单个
ok域的 Lua tables,转换成 Redis 状态回复 -
一个带单个
err域的 Lua tables ,转换成 Redis 错误回复 -
Lua 的 booleans
false转换成 Redis 的 Nil bulk 回复
从 Lua 转换到 Redis 有一条额外的规则,这条规则没有和它对应的从 Redis 转换到 Lua 的规则:
-
Lua booleans
true转换成 Redis 整数回复中的1
以下是几个类型转换的例子:
# Lua strings 换成 Redis bulk 回复
127.0.0.1:6379> EVAL "return redis.call('GET','evalShell')" 0
"shellTest"
# 错误的情况
127.0.0.1:6379> EVAL "return redis.call('SADD','evalShell','a')" 0
(error) ERR Error running script (call to f_e17faafbc130014cebb229b71e0148b1f8f52389): @user_script:1: WRONGTYPE Operation against a key holding the wrong kind of value
# redis 中与 lua 各种类型转换
127.0.0.1:6379> EVAL "return {1,3.1415,'luaStrings',true,false}" 0
1) (integer) 1
2) (integer) 3
3) "luaStrings"
4) (integer) 1
5) (nil)脚本的原子性
Redis 使用单个 Lua 解释器去运行所有脚本,并且, Redis 也保证脚本会以原子性(atomic)的方式执行:当某个脚本正在运行的时候,不会有其他脚本或 Redis 命令被执行。这和使用 MULTI / EXEC 包围的事务很类似。在其他别的客户端看来,脚本的效果(effect)要么是不可见的(not visible),要么就是已完成的(already completed)。
另一方面,这也意味着,执行一个运行缓慢的脚本并不是一个好主意。写一个跑得很快很顺溜的脚本并不难,因为脚本的运行开销(overhead)非常少,但是当你不得不使用一些跑得比较慢的脚本时,请小心,因为当这些蜗牛脚本在慢吞吞地运行的时候,其他客户端会因为服务器正忙而无法执行命令。
错误处理
前面的命令介绍部分说过, redis.call() 和 redis.pcall() 的唯一区别在于它们对错误处理的不同。
当 redis.call() 在执行命令的过程中发生错误时,脚本会停止执行,并返回一个脚本错误,错误的输出信息会说明错误造成的原因:
127.0.0.1:6379> EVAL "return redis.call('SADD','evalShell','a')" 0
(error) ERR Error running script (call to f_e17faafbc130014cebb229b71e0148b1f8f52389): @user_script:1: WRONGTYPE Operation against a key holding the wrong kind of value和 redis.call() 不同, redis.pcall() 出错时并不引发(raise)错误,而是返回一个带 err 域的 Lua 表(table),用于表示错误(这样与命令行客户端直接操作返回相同):
127.0.0.1:6379> EVAL "return redis.pcall('SADD','evalShell','a')" 0
(error) WRONGTYPE Operation against a key holding the wrong kind of valueHelper 函数返回Redis类型
从Lua返回Redis类型有两个 Helper 函数。
-
redis.error_reply(error_string)返回错误回复。此函数只返回一个字段表,其中err字段设置为指定的字符串。 -
redis.status_reply(status_string)返回状态回复。此函数只返回一个字段表,其中ok字段设置为指定的字符串。
使用 Helper 函数或直接以指定的格式返回表之间没有区别,因此以下两种形式是等效的:
return {err="My Error"}
return redis.error_reply("My Error")脚本缓存
Redis 保证所有被运行过的脚本都会被永久保存在脚本缓存当中,这意味着,当 EVAL 命令在一个 Redis 实例上成功执行某个脚本之后,随后针对这个脚本的所有 EVALSHA 命令都会成功执行。
刷新脚本缓存的唯一办法是显式地调用 SCRIPT FLUSH 命令,这个命令会清空运行过的所有脚本的缓存。通常只有在云计算环境中,Redis 实例被改作其他客户或者别的应用程序的实例时,才会执行这个命令。
缓存可以长时间储存而不产生内存问题的原因是,它们的体积非常小,而且数量也非常少,即使脚本在概念上类似于实现一个新命令,即使在一个大规模的程序里有成百上千的脚本,即使这些脚本会经常修改,即便如此,储存这些脚本的内存仍然是微不足道的。
事实上,用户会发现 Redis 不移除缓存中的脚本实际上是一个好主意。比如说,对于一个和 Redis 保持持久化链接(persistent connection)的程序来说,它可以确信,执行过一次的脚本会一直保留在内存当中,因此它可以在 pipline 中使用 EVALSHA 命令而不必担心因为找不到所需的脚本而产生错误(稍候我们会看到在 pipline 中执行脚本的相关问题)。
SCRIPT 命令
Redis 提供了以下几个 SCRIPT 命令,用于对脚本子系统(scripting subsystem)进行控制:
SCRIPT LOAD
自2.6.0可用。
时间复杂度:O(N) ,
N为脚本的长度(以字节为单位)。
语法:SCRIPT LOAD script
说明:
清除所有 Lua 脚本缓存。
返回值:
给定 script 的 SHA1 校验和
SCRIPT DEBUG
自3.2.0可用。
时间复杂度:O(1)。
语法:SCRIPT DEBUG YES|SYNC|NO
说明:
Redis包括一个完整的 Lua 调试器,代号 LDB,可用于使编写复杂脚本的任务更简单。在调试模式下,Redis 充当远程调试服务器,客户端 redis-cli 可以逐步执行脚本,设置断点,检查变量等 。
应避免施工生产机器进行调试!
LDB可以以两种模式之一启用:异步或同步。在异步模式下,服务器创建一个不阻塞的分支调试会话,并且在会话完成后,数据的所有更改都将回滚,因此可以使用相同的初始状态重新启动调试。同步调试模式在调试会话处于活动状态时阻塞服务器,并且数据集在结束后会保留所有更改。
-
YES。启用Lua脚本的非阻塞异步调试(更改将被丢弃)。 -
SYNC。启用阻止Lua脚本的同步调试(保存对数据的更改)。
-
NO。禁用脚本调试模式。
返回值:
总是返回 OK
示例:
该功能是新出功能,使用频率不是很高,在之后我会单独录个视频来进行演示(请关注我的博客 www.coderknock.com,或关注本文后续更新)。
SCRIPT FLUSH
自2.6.0可用。
时间复杂度:O(N) ,
N为缓存中脚本的数量。
语法:SCRIPT FLUSH
说明:
清除所有 Lua 脚本缓存。
返回值:
总是返回 OK
SCRIPT EXISTS
自2.6.0可用。
时间复杂度:O(N) ,
N为给定的 SHA1 校验和的数量。
语法:SCRIPT EXISTS sha1 [sha1 ...]
说明:
给定一个或多个脚本的 SHA1 校验和,返回一个包含 0 和 1 的列表,表示校验和所指定的脚本是否已经被保存在缓存当中。
返回值:
一个列表,包含 0 和 1 ,前者表示脚本不存在于缓存,后者表示脚本已经在缓存里面了。
列表中的元素和给定的 SHA1 校验和保持对应关系,比如列表的第三个元素的值就表示第三个 SHA1 校验和所指定的脚本在缓存中的状态。
SCRIPT KILL
自2.6.0可用。
时间复杂度:O(1)。
语法:SCRIPT KILL
说明:
杀死当前正在运行的 Lua 脚本,当且仅当这个脚本没有执行过任何写操作时,这个命令才生效。
这个命令主要用于终止运行时间过长的脚本,比如一个因为 BUG 而发生无限 loop 的脚本,诸如此类。
SCRIPT KILL 执行之后,当前正在运行的脚本会被杀死,执行这个脚本的客户端会从 EVAL 命令的阻塞当中退出,并收到一个错误作为返回值。
另一方面,假如当前正在运行的脚本已经执行过写操作,那么即使执行 SCRIPT KILL ,也无法将它杀死,因为这是违反 Lua 脚本的原子性执行原则的。在这种情况下,唯一可行的办法是使用 SHUTDOWN NOSAVE 命令,通过停止整个 Redis 进程来停止脚本的运行,并防止不完整(half-written)的信息被写入数据库中。
返回值:
执行成功返回 OK ,否则返回一个错误。
SCRIPT 相关示例:
# 加载一个脚本到缓存
127.0.0.1:6379> SCRIPT LOAD "return redis.call('SET',KEYS[1],ARGV[1])"
"cf63a54c34e159e75e5a3fe4794bb2ea636ee005"
# EVALSHA 在后面会讲解,这里就是调用一个脚本缓冲
127.0.0.1:6379> EVALSHA cf63a54c34e159e75e5a3fe4794bb2ea636ee005 1 ttestScript evalSHATest
OK
127.0.0.1:6379> GET ttestScript
"evalSHATest"
127.0.0.1:6379> SCRIPT EXISTS cf63a54c34e159e75e5a3fe4794bb2ea636ee005
1) (integer) 1
# 这里有三个 SHA 第一第三是随便输入的,检测是否存在脚本缓存
127.0.0.1:6379> SCRIPT EXISTS nonsha cf63a54c34e159e75e5a3fe4794bb2ea636ee005 abc
1) (integer) 0
2) (integer) 1
3) (integer) 0
# 清空脚本缓存
127.0.0.1:6379> SCRIPT FLUSH
OK
# 清除脚本缓存后再次执行就找不到该脚本了
127.0.0.1:6379> SCRIPT EXISTS cf63a54c34e159e75e5a3fe4794bb2ea636ee005
1) (integer) 0
# 没有脚本在执行时
127.0.0.1:6379> SCRIPT KILL
(error) ERR No scripts in execution right now.我们创建一个 lua 脚本,该脚本存在 E:/LuaProject/src/Sleep.lua :
--
--
-- 拿客
-- 网站:www.coderknock.com
-- QQ群:213732117
-- 三产 创建于 2017年06月16日 15:47:30。
-- 描述:
--
--
for i = 1, 1000000
do
print(i)--就是循环打印这样可以模拟长时间的脚本执行
end
return "ok"使用 redis-cli --eval 调用:
C:\Users\zylia>redis-cli -a admin123 --eval E:/LuaProject/src/Sleep.lua此时服务端开始输出,当前客户端被阻塞:
1
2
3
...
23456我们再启动一个客户端:
C:\Users\zylia>redis-cli -a admin123
# 杀掉还在执行的那个脚本
127.0.0.1:6379> SCRIPT KILL
OK
(0.84s)此时刚才我们执行脚本的客户端(就是被阻塞的那个)会抛出异常:
(error) ERR Error running script (call to f_d5ee0fe7467b0e19fe3fb0a0388d522bf26d95d8): @user_script:13: Script killed by user with SCRIPT KILL...服务端也会停止打印:
524991
524992
524993
524994
524995
524996
524997
524998
[1904] 16 Jun 15:55:24.178 # Lua script killed by user with SCRIPT KILL.带宽和 EVALSHA
EVAL 命令要求你在每次执行脚本的时候都发送一次脚本主体(script body)。Redis 有一个内部的缓存机制,因此它不会每次都重新编译脚本,不过在很多场合,付出无谓的带宽来传送脚本主体并不是最佳选择。
为了减少带宽的消耗, Redis 实现了 EVALSHA 命令,它的作用和 EVAL 一样,都用于对脚本求值,但它接受的第一个参数不是脚本,而是脚本的 SHA1 校验和(sum)。
EVALSHA 命令的表现如下:
-
如果服务器还记得给定的 SHA1 校验和所指定的脚本,那么执行这个脚本
-
如果服务器不记得给定的 SHA1 校验和所指定的脚本,那么它返回一个特殊的错误,提醒用户使用 EVAL 代替
EVALSHA
我将之前的脚本存储到缓存中使用 EVALSHA 调用:
127.0.0.1:6379> SCRIPT LOAD "return redis.call('GET','evalShell')"
"c870035beb27b1c404c19624c50b5e451ecf1623"
127.0.0.1:6379> EVALSHA c870035beb27b1c404c19624c50b5e451ecf1623 0
"shellTest"
127.0.0.1:6379> evalsha 6b1bf486c81ceb7edf3c093f4c48582e38c0e791 0
(nil)
127.0.0.1:6379> evalsha ffffffffffffffffffffffffffffffffffffffff 0
(error) NOSCRIPT No matching script. Please use EVAL.
# 在 EVAL 错误的情况中 call to f_e17faafbc130014cebb229b71e0148b1f8f52389
# e17faafbc130014cebb229b71e0148b1f8f52389 就是该命令的 SHA1 值
127.0.0.1:6379> EVAL "return redis.call('SADD','evalShell','a')" 0
(error) ERR Error running script (call to f_e17faafbc130014cebb229b71e0148b1f8f52389): @user_script:1: WRONGTYPE Operation against a key holding the wrong kind of value纯函数脚本
在编写脚本方面,一个重要的要求就是,脚本应该被写成纯函数(pure function)。
也就是说,脚本应该具有以下属性:
对于同样的数据集输入,给定相同的参数,脚本执行的 Redis 写命令总是相同的。脚本执行的操作不能依赖于任何隐藏(非显式)数据,不能依赖于脚本在执行过程中、或脚本在不同执行时期之间可能变更的状态,并且它也不能依赖于任何来自 I/O 设备的外部输入。
使用系统时间(system time),调用像 RANDOMKEY 那样的随机命令,或者使用 Lua 的随机数生成器,类似以上的这些操作,都会造成脚本的求值无法每次都得出同样的结果。
为了确保脚本符合上面所说的属性, Redis 做了以下工作:
Lua 没有访问系统时间或者其他内部状态的命令
-
Redis 会返回一个错误,阻止这样的脚本运行: 这些脚本在执行随机命令之后(比如
RANDOMKEY、SRANDMEMBER或TIME等),还会执行可以修改数据集的 Redis 命令。如果脚本只是执行只读操作,那么就没有这一限制。注意,随机命令并不一定就指那些带RAND字眼的命令,任何带有非确定性的命令都会被认为是随机命令,比如TIME命令就是这方面的一个很好的例子。 -
每当从 Lua 脚本中调用那些返回无序元素的命令时,执行命令所得的数据在返回给 Lua 之前会先执行一个静默(slient)的字典序排序(lexicographical sorting)。举个例子,因为 Redis 的 Set 保存的是无序的元素,所以在 Redis 命令行客户端中直接执行
SMEMBERS,返回的元素是无序的,但是,假如在脚本中执行redis.call("smembers", KEYS[1]),那么返回的总是排过序的元素。 -
对 Lua 的伪随机数生成函数
math.random和math.randomseed进行修改,使得每次在运行新脚本的时候,总是拥有同样的 seed 值。这意味着,每次运行脚本时,只要不使用math.randomseed,那么math.random产生的随机数序列总是相同的。
当 Redis 执行 Lua 脚本时会对脚本进行检查,要执行的 lua 脚本:
function fun()
-- 业务逻辑
end执行是报错,因为 Redis 不允许脚本中存在 function:
C:\Users\zylia>redis-cli -a admin123 --eval E:/LuaProject/src/Sleep.lua
(error) ERR Error running script (call to f_36ebb6a8391764938e347056b2de7a33626c029b): @enable_strict_lua:8: user_script:11: Script attempted to create global variable 'fun'要执行的 lua 脚本:
for i = 1, 100
do
os.execute("ping -n " .. tonumber(2) .. " localhost > NUL")
print(i)
end
return "ok"执行是报错,因为 Redis 不允许脚本使用 os 等一部分全局变量:
C:\Users\zylia>redis-cli -a admin123 --eval E:/LuaProject/src/Sleep.lua
(error) ERR Error running script (call to f_bb4268eafae9d9bcd8a2571f067abf5ab46be3d0): @enable_strict_lua:15: user_script:13: Script attempted to access unexisting global variable 'os'全局变量保护
为了防止不必要的数据泄漏进 Lua 环境, Redis 脚本不允许创建全局变量。如果一个脚本需要在多次执行之间维持某种状态,它应该使用 Redis key 来进行状态保存。
企图在脚本中访问一个全局变量(不论这个变量是否存在)将引起脚本停止, EVAL 命令会返回一个错误:
127.0.0.1:6379> EVAL "website='coderknock.com'" 0
(error) ERR Error running script (call to f_ad03e14e835e9880720cd43db8062256c089cd79): @enable_strict_lua:8: user_script:1: Script attempted to create global variable 'website'Lua 的 debug 工具,或者其他设施,比如打印(alter)用于实现全局保护的 meta table ,都可以用于实现全局变量保护。
实现全局变量保护并不难,不过有时候还是会不小心而为之。一旦用户在脚本中混入了 Lua 全局状态,那么 AOF 持久化和复制(replication)都会无法保证,所以,请不要使用全局变量。
避免引入全局变量的一个诀窍是:将脚本中用到的所有变量都使用 local 关键字定义为局部变量。
库
Redis 内置的 Lua 解释器加载了以下 Lua 库:
-
base -
table -
string -
math -
debug -
cjson -
cmsgpack
其中 cjson 库可以让 Lua 以非常快的速度处理 JSON 数据,除此之外,其他别的都是 Lua 的标准库。
每个 Redis 实例都保证会加载上面列举的库,从而确保每个 Redis 脚本的运行环境都是相同的。
下面我们演示一下 cjson 的使用,Lua 脚本如下
--
--
-- 拿客
-- 网站:www.coderknock.com
-- QQ群:213732117
-- 三产 创建于 2017年06月16日 15:47:30。
-- 描述:
--
--
local json = cjson
local str = '["testWebsit", "testQQ", "sanchan"]' -- json格式的字符串
local j = json.decode(str) -- 解码为表
for i = 1, #j
do
print(i.." --> "..j[i])
end
str = '{"WebSite": "coderknock.com", "QQGroup": 213732117}'
j = json.decode(str)
j['Auth'] = 'sachan'
local new_str = json.encode(j)
return new_str执行过程如下,上面的命令窗口是我们的客户端,下面是 Redis:

可以看到,客户端输出了一个序列号 json ,服务端打印出来我们解码的 json。
使用脚本散发 Redis 日志
在 Lua 脚本中,可以通过调用 redis.log 函数来写 Redis 日志(log):
redis.log(loglevel, message)
其中, message 参数是一个字符串,而 loglevel 参数可以是以下任意一个值:
redis.LOG_DEBUG
redis.LOG_VERBOSE
redis.LOG_NOTICE
redis.LOG_WARNING
上面的这些等级(level)和标准 Redis 日志的等级相对应。
对于脚本散发(emit)的日志,只有那些和当前 Redis 实例所设置的日志等级相同或更高级的日志才会被散发。
以下是一个日志示例:
redis.log(redis.LOG_WARNING, "Something is wrong with this script.")
执行上面的函数会在服务器端产生这样的信息:
[32343] 22 Mar 15:21:39 # Something is wrong with this script.
沙箱(sandbox)和最大执行时间
脚本应该仅仅用于传递参数和对 Redis 数据进行处理,它不应该尝试去访问外部系统(比如文件系统),或者执行任何系统调用。
除此之外,脚本还有一个最大执行时间限制,它的默认值是 5 秒钟,一般正常运作的脚本通常可以在几分之几毫秒之内完成,花不了那么多时间,这个限制主要是为了防止因编程错误而造成的无限循环而设置的。
最大执行时间的长短由 lua-time-limit 选项来控制(以毫秒为单位),可以通过编辑 redis.conf 文件或者使用 CONFIG GET 和 CONFIG SET 命令来修改它。
当一个脚本达到最大执行时间的时候,它并不会自动被 Redis 结束,因为 Redis 必须保证脚本执行的原子性,而中途停止脚本的运行意味着可能会留下未处理完的数据在数据集(data set)里面。
因此,当脚本运行的时间超过最大执行时间后,以下动作会被执行:
-
Redis 记录一个脚本正在超时运行
-
Redis 开始重新接受其他客户端的命令请求,但是只有 SCRIPT KILL 和 SHUTDOWN NOSAVE 两个命令会被处理,对于其他命令请求, Redis 服务器只是简单地返回 BUSY 错误。
-
可以使用 SCRIPT KILL 命令将一个仅执行只读命令的脚本杀死,因为只读命令并不修改数据,因此杀死这个脚本并不破坏数据的完整性
-
如果脚本已经执行过写命令,那么唯一允许执行的操作就是 SHUTDOWN NOSAVE ,它通过停止服务器来阻止当前数据集写入磁盘
pipeline上下文(context)中的 EVALSHA
在 pipeline 请求的上下文中使用 EVALSHA 命令时,要特别小心,因为在 pipeline 中,必须保证命令的执行顺序。
一旦在 pipeline 中因为 EVALSHA 命令而发生 NOSCRIPT 错误,那么这个 pipeline 就再也没有办法重新执行了,否则的话,命令的执行顺序就会被打乱。
为了防止出现以上所说的问题,客户端库实现应该实施以下的其中一项措施:
-
总是在 pipeline 中使用 EVAL 命令
-
检查 pipeline 中要用到的所有命令,找到其中的 EVAL 命令,并使用 SCRIPT EXISTS 命令检查要用到的脚本是不是全都已经保存在缓存里面了。如果所需的全部脚本都可以在缓存里找到,那么就可以放心地将所有 EVAL 命令改成 EVALSHA 命令,否则的话,就要在pipeline 的顶端(top)将缺少的脚本用 SCRIPT LOAD 命令加上去。
Redis三种集群方式概述 - 每天进步一点点! - ITeye博客
Redis有三种集群方式
主从复制,哨兵模式和Redis-Cluster集群。
1.1、主从复制
1.1.1、主从复制原理
1. 从服务器连接主服务器,发送SYNC(同步)命令;
2. 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3. 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4. 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
5. 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6. 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;(从服务器初始化完成)
7. 主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令(从服务器初始化完成后的操作)
1.1.2、主从复制优缺点:
优点:
支持主从复制,主机会自动将数据同步到从机,可以进行读写分离
为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成
Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。
Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。
Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据
缺点:
Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
1.2、哨兵模式
1.2.1、哨兵模式原理:
当主服务器中断服务后,可以将一个从服务器升级为主服务器,以便继续提供服务,但是这个过程需要人工手动来操作。 为此,Redis 2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。
哨兵的作用就是监控Redis系统的运行状况。它的功能包括以下两个。
(1)监控主服务器和从服务器是否正常运行。
(2)主服务器出现故障时自动将从服务器转换为主服务器。
1.2.2、哨兵的工作方式:
a. 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
b. 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)
c. 如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态
d. 当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)
e. 在一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
f. 当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
g. 若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
1.2.3、哨兵模式的优缺点
优点:
哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
主从可以自动切换,系统更健壮,可用性更高。
缺点:
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
1.3、Redis-Cluster集群
1.3.1、原理
redis的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台redis服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上存储不同的内容。
1.3.2、Redis-Cluster采用无中心结构,它的特点如下
1. 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
2. 节点的fail是通过集群中超过半数的节点检测失效时才生效。
3. 客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
1.3.3、工作方式:
在redis的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是cluster,可以理解为是一个集群管理的插件。当我们的存取的key到达的时候,redis会根据crc16的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
为了保证高可用,redis-cluster集群引入了主从模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点。当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点A1都宕机了,那么该集群就无法再提供服务了。
理解Redis的内存回收机制和过期淘汰策略 - 掘金 (juejin.cn)
之前看到过一道面试题:Redis的过期策略都有哪些?内存淘汰机制都有哪些?手写一下LRU代码实现?笔者结合在工作上遇到的问题学习分析,希望看完这篇文章能对大家有所帮助。
从一次不可描述的故障说起
问题描述:一个依赖于定时器任务的生成的接口列表数据,时而有,时而没有。
怀疑是Redis过期删除策略
排查过程长,因为手动执行定时器,set数据没有报错,但是set数据之后不生效。
set没报错,但是set完再查的情况下没数据,开始怀疑Redis的过期删除策略(准确来说应该是Redis的内存回收机制中的数据淘汰策略触发内存上限淘汰数据。),导致新加入Redis的数据都被丢弃了。最终发现故障的原因是因为配置错了,导致数据写错地方,并不是Redis的内存回收机制引起。
通过这次故障后思考总结,如果下一次遇到类似的问题,在怀疑Redis的内存回收之后,如何有效地证明它的正确性?如何快速证明猜测的正确与否?以及什么情况下怀疑内存回收才是合理的呢?下一次如果再次遇到类似问题,就能够更快更准地定位问题的原因。另外,Redis的内存回收机制原理也需要掌握,明白是什么,为什么。
花了点时间查阅资料研究Redis的内存回收机制,并阅读了内存回收的实现代码,通过代码结合理论,给大家分享一下Redis的内存回收机制。
为什么需要内存回收?
-
1、在Redis中,set指令可以指定key的过期时间,当过期时间到达以后,key就失效了;
-
2、Redis是基于内存操作的,所有的数据都是保存在内存中,一台机器的内存是有限且很宝贵的。
基于以上两点,为了保证Redis能继续提供可靠的服务,Redis需要一种机制清理掉不常用的、无效的、多余的数据,失效后的数据需要及时清理,这就需要内存回收了。
Redis的内存回收机制
Redis的内存回收主要分为过期删除策略和内存淘汰策略两部分。
过期删除策略
删除达到过期时间的key。
1、定时删除
对于每一个设置了过期时间的key都会创建一个定时器,一旦到达过期时间就立即删除。该策略可以立即清除过期的数据,对内存较友好,但是缺点是占用了大量的CPU资源去处理过期的数据,会影响Redis的吞吐量和响应时间。
2、惰性删除
当访问一个key时,才判断该key是否过期,过期则删除。该策略能最大限度地节省CPU资源,但是对内存却十分不友好。有一种极端的情况是可能出现大量的过期key没有被再次访问,因此不会被清除,导致占用了大量的内存。
在计算机科学中,懒惰删除(英文:lazy deletion)指的是从一个散列表(也称哈希表)中删除元素的一种方法。在这个方法中,删除仅仅是指标记一个元素被删除,而不是整个清除它。被删除的位点在插入时被当作空元素,在搜索之时被当作已占据。
3、定期删除
每隔一段时间,扫描Redis中过期key字典,并清除部分过期的key。该策略是前两者的一个折中方案,还可以通过调整定时扫描的时间间隔和每次扫描的限定耗时,在不同情况下使得CPU和内存资源达到最优的平衡效果。
在Redis中,同时使用了定期删除和惰性删除。
过期删除策略原理
为了大家听起来不会觉得疑惑,在正式介绍过期删除策略原理之前,先给大家介绍一点可能会用到的相关Redis基础知识。
redisDb结构体定义
我们知道,Redis是一个键值对数据库,对于每一个redis数据库,redis使用一个redisDb的结构体来保存,它的结构如下:
typedef struct redisDb {
dict *dict; /* 数据库的键空间,保存数据库中的所有键值对 */
dict *expires; /* 保存所有过期的键 */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* 数据库ID字段,代表不同的数据库 */
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;
复制代码从结构定义中我们可以发现,对于每一个Redis数据库,都会使用一个字典的数据结构来保存每一个键值对,dict的结构图如下:
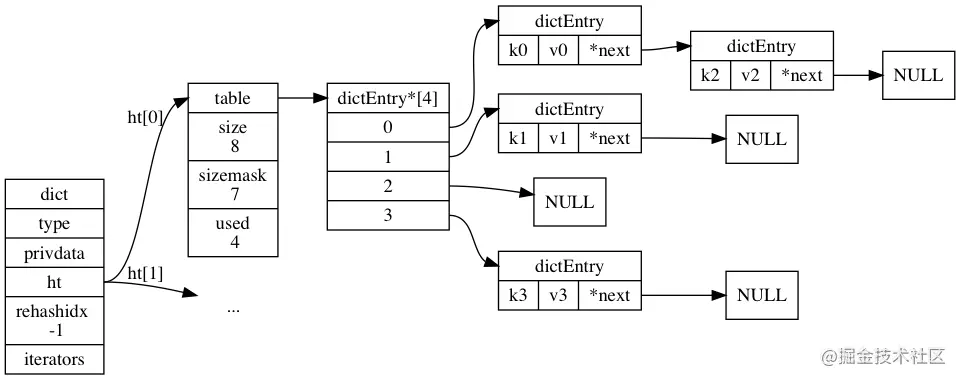
以上就是过期策略实现时用到比较核心的数据结构。程序=数据结构+算法,介绍完数据结构以后,接下来继续看看处理的算法是怎样的。
expires属性
redisDb定义的第二个属性是expires,它的类型也是字典,Redis会把所有过期的键值对加入到expires,之后再通过定期删除来清理expires里面的值。加入expires的场景有:
1、set指定过期时间expire
如果设置key的时候指定了过期时间,Redis会将这个key直接加入到expires字典中,并将超时时间设置到该字典元素。
2、调用expire命令
显式指定某个key的过期时间
3、恢复或修改数据
从Redis持久化文件中恢复文件或者修改key,如果数据中的key已经设置了过期时间,就将这个key加入到expires字典中
以上这些操作都会将过期的key保存到expires。redis会定期从expires字典中清理过期的key。
Redis清理过期key的时机
1、Redis在启动的时候,会注册两种事件,一种是时间事件,另一种是文件事件。(可参考启动Redis的时候,Redis做了什么)时间事件主要是Redis处理后台操作的一类事件,比如客户端超时、删除过期key;文件事件是处理请求。
在时间事件中,redis注册的回调函数是serverCron,在定时任务回调函数中,通过调用databasesCron清理部分过期key。(这是定期删除的实现。)
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData)
{
…
/* Handle background operations on Redis databases. */
databasesCron();
...
}
复制代码2、每次访问key的时候,都会调用expireIfNeeded函数判断key是否过期,如果是,清理key。(这是惰性删除的实现。)
robj *lookupKeyRead(redisDb *db, robj *key) {
robj *val;
expireIfNeeded(db,key);
val = lookupKey(db,key);
...
return val;
}
复制代码3、每次事件循环执行时,主动清理部分过期key。(这也是惰性删除的实现。)
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
}
void beforeSleep(struct aeEventLoop *eventLoop) {
...
/* Run a fast expire cycle (the called function will return
- ASAP if a fast cycle is not needed). */
if (server.active_expire_enabled && server.masterhost == NULL)
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST);
...
}
复制代码过期策略的实现
我们知道,Redis是以单线程运行的,在清理key是不能占用过多的时间和CPU,需要在尽量不影响正常的服务情况下,进行过期key的清理。过期清理的算法如下:
1、server.hz配置了serverCron任务的执行周期,默认是10,即CPU空闲时每秒执行十次。
2、每次清理过期key的时间不能超过CPU时间的25%:timelimit = 1000000*ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC/server.hz/100;
比如,如果hz=1,一次清理的最大时间为250ms,hz=10,一次清理的最大时间为25ms。
3、如果是快速清理模式(在beforeSleep函数调用),则一次清理的最大时间是1ms。
4、依次遍历所有的DB。
5、从db的过期列表中随机取20个key,判断是否过期,如果过期,则清理。
6、如果有5个以上的key过期,则重复步骤5,否则继续处理下一个db
7、在清理过程中,如果达到CPU的25%时间,退出清理过程。
复制代码从实现的算法中可以看出,这只是基于概率的简单算法,且是随机的抽取,因此是无法删除所有的过期key,通过调高hz参数可以提升清理的频率,过期key可以更及时的被删除,但hz太高会增加CPU时间的消耗。
删除key
Redis4.0以前,删除指令是del,del会直接释放对象的内存,大部分情况下,这个指令非常快,没有任何延迟的感觉。但是,如果删除的key是一个非常大的对象,比如一个包含了千万元素的hash,那么删除操作就会导致单线程卡顿,Redis的响应就慢了。为了解决这个问题,在Redis4.0版本引入了unlink指令,能对删除操作进行“懒”处理,将删除操作丢给后台线程,由后台线程来异步回收内存。
实际上,在判断key需要过期之后,真正删除key的过程是先广播expire事件到从库和AOF文件中,然后在根据redis的配置决定立即删除还是异步删除。
如果是立即删除,Redis会立即释放key和value占用的内存空间,否则,Redis会在另一个bio线程中释放需要延迟删除的空间。
小结
总的来说,Redis的过期删除策略是在启动时注册了serverCron函数,每一个时间时钟周期,都会抽取expires字典中的部分key进行清理,从而实现定期删除。另外,Redis会在访问key时判断key是否过期,如果过期了,就删除,以及每一次Redis访问事件到来时,beforeSleep都会调用activeExpireCycle函数,在1ms时间内主动清理部分key,这是惰性删除的实现。
Redis结合了定期删除和惰性删除,基本上能很好的处理过期数据的清理,但是实际上还是有点问题的,如果过期key较多,定期删除漏掉了一部分,而且也没有及时去查,即没有走惰性删除,那么就会有大量的过期key堆积在内存中,导致redis内存耗尽,当内存耗尽之后,有新的key到来会发生什么事呢?是直接抛弃还是其他措施呢?有什么办法可以接受更多的key?
内存淘汰策略
Redis的内存淘汰策略,是指内存达到maxmemory极限时,使用某种算法来决定清理掉哪些数据,以保证新数据的存入。
Redis的内存淘汰机制
- noeviction: 当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间(
server.db[i].dict)中,移除最近最少使用的 key(这个是最常用的)。 - allkeys-random:当内存不足以容纳新写入数据时,在键空间(
server.db[i].dict)中,随机移除某个 key。 - volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间(
server.db[i].expires)中,移除最近最少使用的 key。 - volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间(
server.db[i].expires)中,随机移除某个 key。 - volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间(
server.db[i].expires)中,有更早过期时间的 key 优先移除。
在配置文件中,通过maxmemory-policy可以配置要使用哪一个淘汰机制。
什么时候会进行淘汰?
Redis会在每一次处理命令的时候(processCommand函数调用freeMemoryIfNeeded)判断当前redis是否达到了内存的最大限制,如果达到限制,则使用对应的算法去处理需要删除的key。伪代码如下:
int processCommand(client *c)
{
...
if (server.maxmemory) {
int retval = freeMemoryIfNeeded();
}
...
}
复制代码LRU实现原理
在淘汰key时,Redis默认最常用的是LRU算法(Latest Recently Used)。Redis通过在每一个redisObject保存lru属性来保存key最近的访问时间,在实现LRU算法时直接读取key的lru属性。
具体实现时,Redis遍历每一个db,从每一个db中随机抽取一批样本key,默认是3个key,再从这3个key中,删除最近最少使用的key。实现伪代码如下:
keys = getSomeKeys(dict, sample)
key = findSmallestIdle(keys)
remove(key)
复制代码3这个数字是配置文件中的maxmeory-samples字段,也是可以可以设置采样的大小,如果设置为10,那么效果会更好,不过也会耗费更多的CPU资源。
以上就是Redis内存回收机制的原理介绍,了解了上面的原理介绍后,回到一开始的问题,在怀疑Redis内存回收机制的时候能不能及时判断故障是不是因为Redis的内存回收机制导致的呢?
回到问题原点
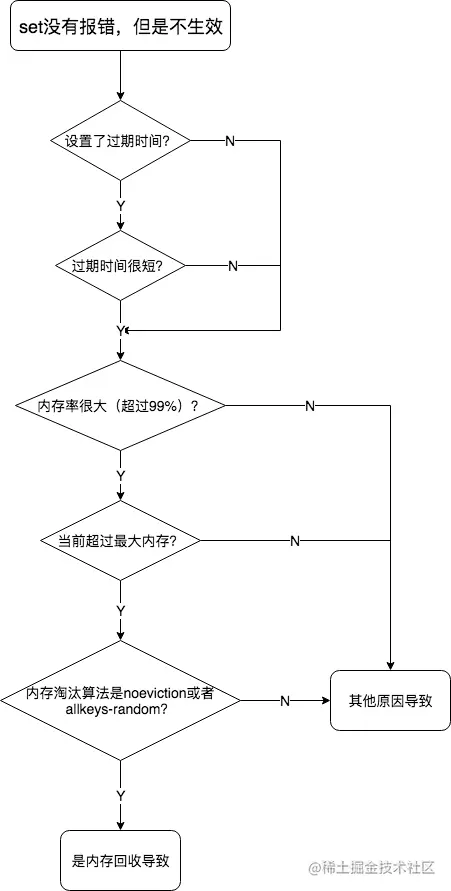
如何证明故障是不是由内存回收机制引起的?
根据前面分析的内容,如果set没有报错,但是不生效,只有两种情况:
- 1、设置的过期时间过短,比如,1s?
- 2、内存超过了最大限制,且设置的是noeviction或者allkeys-random。
因此,在遇到这种情况,首先看set的时候是否加了过期时间,且过期时间是否合理,如果过期时间较短,那么应该检查一下设计是否合理。
如果过期时间没问题,那就需要查看Redis的内存使用率,查看Redis的配置文件或者在Redis中使用info命令查看Redis的状态,maxmemory属性查看最大内存值。如果是0,则没有限制,此时是通过total_system_memory限制,对比used_memory与Redis最大内存,查看内存使用率。
如果当前的内存使用率较大,那么就需要查看是否有配置最大内存,如果有且内存超了,那么就可以初步判定是内存回收机制导致key设置不成功,还需要查看内存淘汰算法是否noeviction或者allkeys-random,如果是,则可以确认是redis的内存回收机制导致。如果内存没有超,或者内存淘汰算法不是上面的两者,则还需要看看key是否已经过期,通过ttl查看key的存活时间。如果运行了程序,set没有报错,则ttl应该马上更新,否则说明set失败,如果set失败了那么就应该查看操作的程序代码是否正确了。
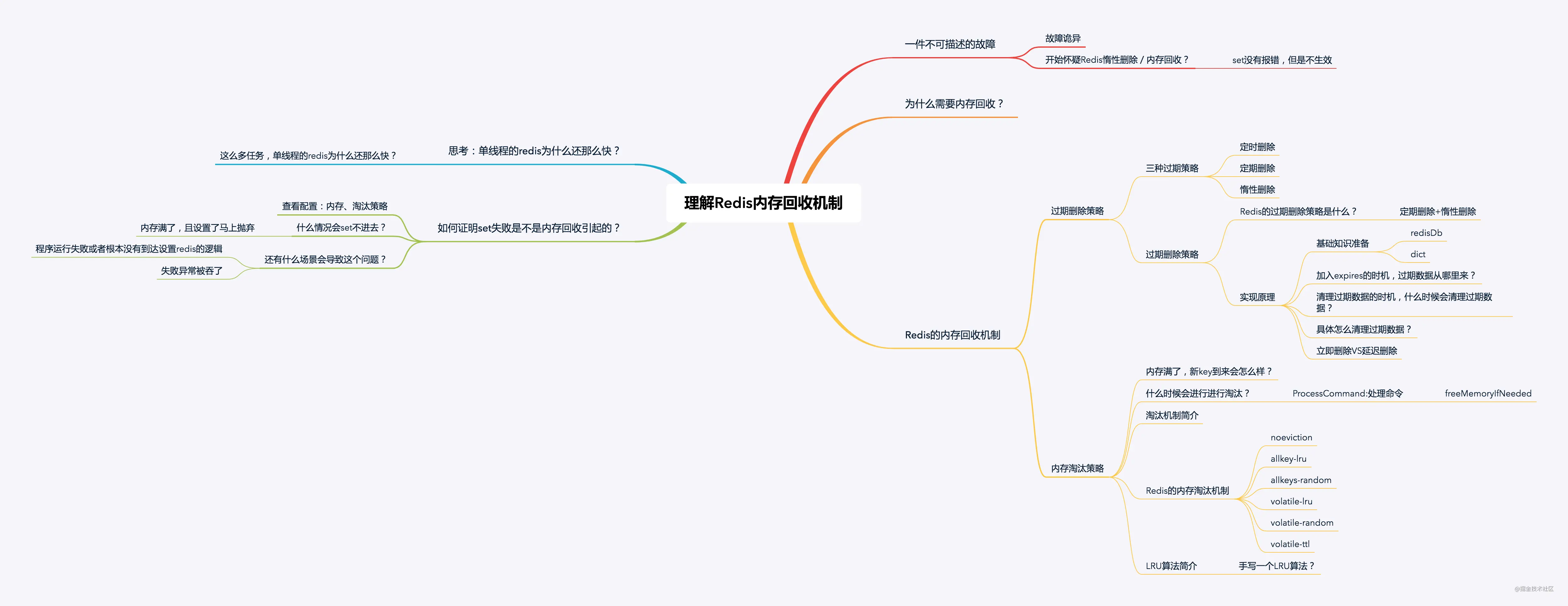
总结
Redis对于内存的回收有两种方式,一种是过期key的回收,另一种是超过redis的最大内存后的内存释放。
对于第一种情况,Redis会在:
1、每一次访问的时候判断key的过期时间是否到达,如果到达,就删除key
2、redis启动时会创建一个定时事件,会定期清理部分过期的key,默认是每秒执行十次检查,每次过期key清理的时间不超过CPU时间的25%,即若hz=1,则一次清理时间最大为250ms,若hz=10,则一次清理时间最大为25ms。
对于第二种情况,redis会在每次处理redis命令的时候判断当前redis是否达到了内存的最大限制,如果达到限制,则使用对应的算法去处理需要删除的key。
看完这篇文章后,你能回答文章开头的面试题了吗?
思考
留下一道思考题,我们知道,Redis是单线程的,单线程的redis还包含了这么多的任务每一次处理命令的线程都包含:处理命令、清理过期key、处理内存回收这些任务,为什么还能这么快?里面做了什么优化?后续再探索这个问题,敬请关注。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号