浅析 x86 架构中 cache 的组织结构-每个程序员都应该了解的 CPU 高速缓存
cache通常被翻译为高速缓冲存储器(以下简称“高速缓存”),虽然现在cache的含义已经不单单指CPU和主存储器(也就是通常所谓的内存)之间的高速缓存了,但在本文中所谓的cache依旧特指CPU和主存储器之间的高速缓存。
这篇文章诞生的源头是我之前在stackoverflow看到的一个问题:
Why is transposing a matrix of 512×512 much slower than transposing a matrix of 513×513 ?
这个问题虽然国外的大神给出了完美的解释,但是我当时看过之后还是一头雾水。想必对x86架构上的cache没有较深入了解过的童鞋看过之后也是一样的感受吧。于是趁着寒假回家第一天还没有过多外界干扰的时候,我们就来详细的研究下x86架构下cache的组织方式吧。
我们就由这个问题开始讨论吧。这个问题说为什么转置一个512×512的矩阵反倒比513×513的矩阵要慢?(不知道什么是矩阵转置的童鞋补习线性代数去)提问者给出了测试的代码以及执行的时间。
不过我们不知道提问者测试机器的硬件架构,不过我的测试环境就是我这台笔记本了,x86架构,处理器是Intel Core i3-2310M 2.10GHz。顺便啰嗦一句,在linux下,直接用cat命令查看/proc/cpuinfo这个虚拟文件就可以查看到当前CPU的很多信息。
首先,我们将提问者给出的代码修改为C语言版,然后编译运行进行测试。提问者所给出的这段代码有逻辑问题,但是这和我们的讨论主题无关,所以请无视这些细节吧 :),代码如下:
1
|
|
我的机器上得出了如下的测试结果:
Average for a matrix of 513 : 0.003879 s
Average for a matrix of 512 : 0.004570 s
512×512的矩阵转置确实慢于513×513的矩阵,但是有意思的是我并没有提问者那么悬殊的执行结果。不过在编译命令行加上参数 -O2 优化后差异很明显了:
Average for a matrix of 513 : 0.001442 s
Average for a matrix of 512 : 0.005469 s
也就是说512×512的矩阵居然比513×513的矩阵转置平均慢了近4倍!
那么,是什么原因导致这个神奇的结果呢?
- 如果真是cache的缘故,那么cache又是如何影响代码执行的效率呢?
- 如果是因为cache具体的组织方式带来的特殊现象,那cache究竟是怎么组织的呢?
- 除此之外,仅仅是512×512的矩阵转置慢吗?其它的数字又会怎样呢?
- 搞明白了cache的组织方式之后,能给我们平时写代码定义变量有怎样的启示呢?
好了,我们提出的问题足够多了,现在我们来尝试在探索中逐一解答这些问题,并尝试分析一些现代CPU的特性对代码执行造成的影响。
我们从cache的原理说起,cache存在的目的是在高速的CPU和较低速的主存储器之间建立一个数据存储的缓冲地带,通常由SRAM制造,访问速度略慢于CPU的寄存器,但是却高于DRAM制造的主存储器。因为制造成本过高,所以cache的容量一般都很小,一般只有几MB甚至几十到几百KB而已。那你可能会说,这么小的cache怎么可能有大作用。有趣的是还真有大作用,由于程序的局部性原理的存在,小容量的cache在工作时能轻易达到90%以上的读写命中率。局部性原理分为时间局部性和空间局部性,这里不再详述,有兴趣的童鞋请参阅其他资料。
顺便插一句嘴,不光金字塔型的存储器体系结构和制造成本相关,甚至我觉得计算机体系结构很大程度受制于成本等因素的考量。假设主存储器的存储速率能和CPU寄存器比肩的话,cache肯定就会退出历史的舞台了。如果磁盘的读写速度能达到寄存器级别并且随机存取,那恐怕内存也就没有存在的必要的……
言归正传,我们如何查看自己机器上CPU的cache信息呢?/proc/cpuinfo这里是没有的,我们需要使用lscpu命令查看,这条命令在我的机器上得到了如下的输出结果:
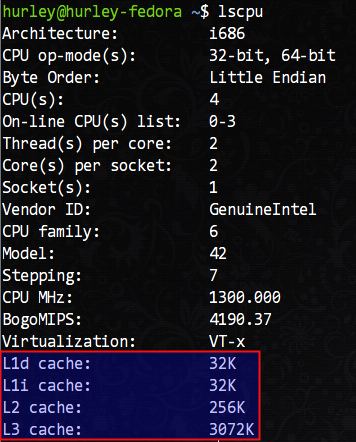
可以看到,我的机器拥有L1d(L1数据cache)和L1i(L1指令cache)各32KB、L2 cache 256KB、L3 cache 3072KB(3MB)。
L1缓存居然分为数据缓存和指令缓存,这不是哈佛架构么?x86不是冯·诺伊曼架构么,怎么会在存储区域区分指令和数据?其实,教科书中讲述的都是完全理想化的模型,在实际的工程中,很难找到这种理想化的设计。就拿操作系统内核而言,尽管所谓的微内核组织结构更好,但是在目前所有知名的操作系统中是找不到完全符合学术意义上的微内核的例子。工程上某些时候就是一种折衷,选择更“接地气”的做法,而不是一味的契合理论模型。
既然cache容量很有限,那么如何组织数据便是重点了。接下来,我们谈谈cache和内存数据的映射方式。一般而言,有所谓的全相联映射,直接相联映射和组相联映射三种方式。
CPU和cache是以字为单位进行数据交换的,而cache却是以行(块)(即Cache Block,或Cache Line)为单位进行数据交换的。在cache中划分若干个字为一行,在内存中划分若干个字为一块,这里的行和块是大小相等的。CPU要获取某内存地址的数据时会先检查该地址所在的块是否在cache中,如果在称之为cache命中,CPU很快就可以读取到所需数据;反之称为cache未命中,此时需要从内存读取数据,同时会将该地址所在的整个内存块复制到cache里存储以备再次使用。
我们依次来看这三种映射方式,首先是全相联映射,这种映射方式很简单,内存中的任意一块都可以放置到cache中的任意一行去。为了便于说明,我们给出以下的简单模型来理解这个设计。
我们假设有一个4行的cache,每行4个字,每个字占4个字节,即64字节的容量。另外还有256字节(16块,每块4字,每字4字节)的一个RAM存储器来和这个cache进行映射。映射结构如图所示:
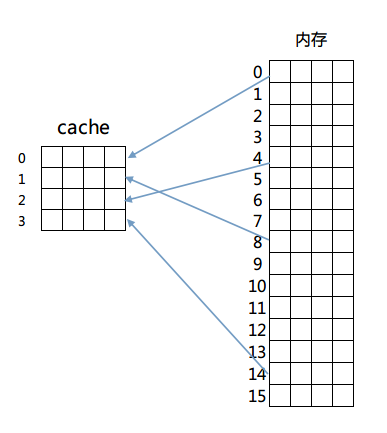
那么如何判断cache是否命中呢?由于内存和cache是多对一的映射,所以必须在cache存储一行数据的同时标示出这些数据在内存中的确切位置。简单的说,在cache每一行中都有一个Index,这个Index记录着该行数据来自内存的哪一块(其实还有若干标志位,包括有效位(valid bit)、脏位(dirty bit)、使用位(use bit)等。这些位在保证正确性、排除冲突、优化性能等方面起着重要作用)。那么在进行一个地址的判断时,采用全相联方式的话,因为任意一行都有可能存在所需数据,所以需要比较每一行的索引值才能确定cache中是否存在所需数据。这样的电路延迟较长,设计困难且复杂性高,所以一般只有在特殊场合,比如cache很小时才会使用。
然后是第二种方法:直接相连映射。这个方法固定了行和块的对应关系,例如内存第0块必须放在cache第0行,第一块必须放在第一行,第二块必须放在第二行……循环放置,即满足公式:
内存块放置行号 = 内存块号 % cache总行数
映射如图所示:
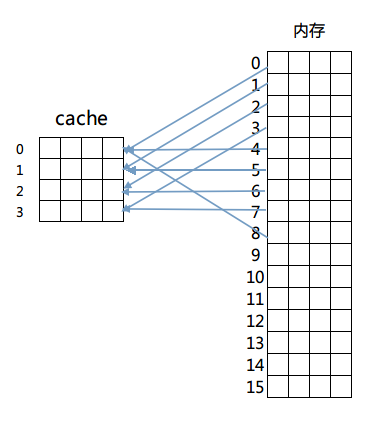
这样做解决了比较起来困难的问题,由于每一块固定到了某一行,只需要计算出目标内存所在的行号进行检查即可判断出cache是否命中。但是这么做的话因为一旦发生冲突就必须换出cache中的指定行,频繁的更换缓存内容造成了大量延迟,而且未能有效利用程序运行期所具有的时间局部性。
综上,最终的解决方案是最后的组相联映射方式(Set Associativity),这个方案结合了以上两种映射方式的优点。具体的方法是先将cache的行进行分组,然后内存块按照组号求模来决定该内存块放置到cache的哪一个组。但是具体放置在组内哪一行都可以,具体由cache替换算法决定。
我们依旧以上面的例子来说明,将cache里的4行分为两组,然后采用内存里的块号对组号求模的方式进行组号判断,即内存0号块第一组里,2号块放置在第二组里,3号块又放置在第一组,以此类推。这么做的话,在组内发生冲突的话,可以选择换出组内一个不经常读写的内存块,从而减少冲突,更好的利用了资源(具体的cache替换策略不在讨论范围内,有兴趣的童鞋请自行研究)。同时因为组内行数不会很多,也避免了电路延迟和设计的复杂性。
x86中cache的组织方式采用的便是组相联映射方式。
上面的阐述可能过于简单,不过大家应该理解了组相联映射方式是怎么回事了。那么我们接下来结合我的机器上具体的cache映射计算方法继续分析。
我们刚说过组相联映射方式的行号可以通过 块号 % 分组个数 的公式来计算,那么直接给出一个内存地址的话如何计算呢?其实内存地址所在的块号就是 内存地址值 / 分块字节数,那么直接由一个内存地址计算出所在cache中的行分组的组号计算公式就是:
内存地址所在cache组号 = (内存地址值 / 分块字节数) % 分组个数
很简单吧?假定一个cache行(内存块)有4个字,我们画出一个32位地址拆分后的样子:

因为字长32的话,每个字有4个字节,所以需要内存地址最低2位时字节偏移,同理每行(块)有4个字,块内偏移也是2位。这里的索引位数取决于cache里的行数,这个图里我画了8位,那就表示cache一共有256个分组(0~255)存在,每个分组有多少行呢?这个随意了,这里的行数是N,cache就是N路组相联映射。具体的判断自然是取tag进行组内逐一匹配测试了,如果不幸没有命中,那就需要按照cache替换算法换出组内的一行了。顺带画出这个地址对应的cache结构图:
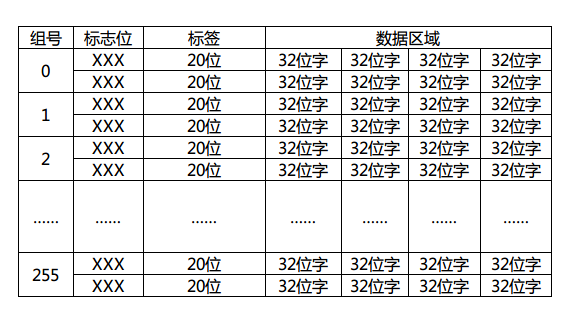
标志位是有效位(valid bit)、脏位(dirty bit)、使用位(use bit)等,用于该cache行的写回算法,替换算法使用。这里简单期间我就画了一个2路组相联映射的例子出来。现在大家应该大致明白cache工作的流程了吧?首先由给出的内存地址计算出所在cache的组号(索引),再由判断电路逐一比较标签(tag)值来判断是否命中,若命中则通过行(块)内偏移返回所在字数据,否则由cache替换算法决定换出某一行(块),同时由内存调出该行(块)数据进行替换。
其实工作的流程就是这样,至于cache写回的策略(写回法,写一次法,全写法)不在本文的讨论范围之内,就不细说了。
有了以上铺垫,我们终于可以来解释那个512×512的矩阵转置问题了。很艰难的铺垫,不是吗?但我们距离胜利越来越近了。
512×512的矩阵,或者用C语言的说法称之为512×512的整型二维数组,在内存中是按顺序存储的。
那么以我的机器为例,在上面的lscpu命令输出的结果中,L1d(一级数据缓存)拥有32KB的容量。但是,有没有更详细的行大小和分组数量的信息?当然有,而且不需要多余的命令。在/sys/devices/system/cpu目录下就可以看到各个CPU核的所有详细信息,当然也包括cache的详细信息,我们主要关注L1d缓存的信息,以核0为例,在/sys/devices/system/cpu/cpu0/cache目录下有index0~index4这四个目录,分别对应L1d,L1i,L2,L3的信息。我们以L1d(index0)为例查看详细参数。
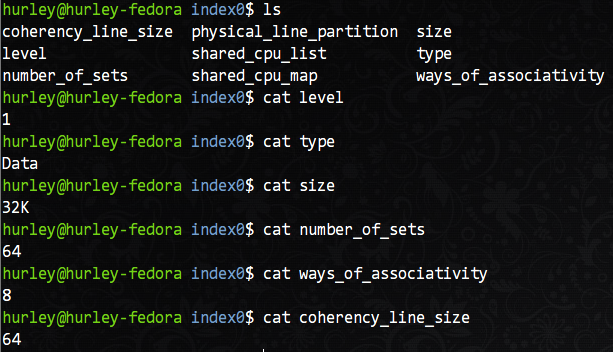
从图中我们可以知道,这是L1数据缓存的相关信息:共有64个组,每组8行,每行16字(64字节),共有32KB的总容量。按照我们之前的分析,相信你很容易就能说出这个机器上L1d缓存的组织方式。没错,就是8路组相联映射。
顺带贴出Intel的官方文档证明我不是在信口开河:

此时32位内存地址的拆分如下:
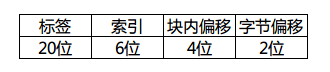
对应的cache图想必也难不倒大家吧?和上边的cache结构不同的就是改变了分组数量、每组行数和每行大小。
我们继续分析转置问题。每个cache行(块)拥有64个字节,正好是16个int变量的大小。一个n阶矩阵的一个行正好填充n / 16个cache行。512阶矩阵的话,每个矩阵的行就填充了32个组中的行,2个矩阵的行就覆盖了64个组。之后的行若要使用,就必然牵扯到cache的替换了。如果此时二维数组的array[0][0]开始从cache第一行开始放置。那么当进入第二重for循环之后,由于内存地址计算出的cache组号相同,导致每一个组中的正在使用的cache行发生了替换,不断发生的组内替换使得cache完全没有发挥出效果,所以造成了512×512的矩阵在转置的时候耗时较大的原因。具体的替换点大家可以自行去计算,另外513×513矩阵大家也可以试着去分析没有过多cache失效的原因。不过这个问题是和CPU架构有关的,所以假如你的机器没有产生同样的效果,不妨自己研究研究自己机器的cache结构。
另外网上针对这个问题也有诸多大牛给出的解释,大家不妨参照着理解吧。别人说过的我就不说了,大家可以参考着分析。
原本想把这篇作为上篇,再去写一个下篇讲述一些编程中要注意的问题。不过偶然间看到了微软大牛Igor Ostrovsky的博文《Gallery of Processor Cache Effects》,瞬间感觉自己不可能写的更好了。所以推荐大家去读这篇文章。如果感觉英文吃力的话,耗子叔这里有@我的上铺叫路遥做的翻译解释《7个示例科普CPU Cache》。
另外,开源中国这里的一篇译文也有参考价值:《每个程序员都应该了解的 CPU 高速缓存》。
One quick request: in a document of this length there are bound to be a few typographical errors remaining. If you find one, and wish to see it corrected, please let us know via mail to lwn@lwn.net rather than by posting a comment. That way we will be sure to incorporate the fix and get it back into Ulrich's copy of the document and other readers will not have to plow through uninteresting comments.]
[编者按:这是Ulrich Drepper写“程序员都该知道存储器”的第二部。那些没有读过第一部 的读者可能希望从这一部开始。这本书写的非常好,并且感谢Ulrich授权我们出版。
一点说明:书籍出版时可能会有一些印刷错误,如果你发现,并且想让它在后续的出版中更正,请将意见发邮件到lwn@lwn.net ,我们一定会更正,并反馈给Ulrich的文档副本,别的读者就不会受到这些困扰。]
CPUs are today much more sophisticated than they were only 25 years ago. In those days, the frequency of the CPU core was at a level equivalent to that of the memory bus. Memory access was only a bit slower than register access. But this changed dramatically in the early 90s, when CPU designers increased the frequency of the CPU core but the frequency of the memory bus and the performance of RAM chips did not increase proportionally. This is not due to the fact that faster RAM could not be built, as explained in the previous section. It is possible but it is not economical. RAM as fast as current CPU cores is orders of magnitude more expensive than any dynamic RAM.
If the choice is between a machine with very little, very fast RAM and a machine with a lot of relatively fast RAM, the second will always win given a working set size which exceeds the small RAM size and the cost of accessing secondary storage media such as hard drives. The problem here is the speed of secondary storage, usually hard disks, which must be used to hold the swapped out part of the working set. Accessing those disks is orders of magnitude slower than even DRAM access.
Fortunately it does not have to be an all-or-nothing decision. A computer can have a small amount of high-speed SRAM in addition to the large amount of DRAM. One possible implementation would be to dedicate a certain area of the address space of the processor as containing the SRAM and the rest the DRAM. The task of the operating system would then be to optimally distribute data to make use of the SRAM. Basically, the SRAM serves in this situation as an extension of the register set of the processor.
如果有两个选项让你选择,一个是速度非常快、但容量很小的内存,一个是速度还算快、但容量很多的内存,如果你的工作集比较大,超过了前一种情况,那么人们总是会选择第二个选项。原因在于辅存(一般为磁盘)的速度。由于工作集超过主存,那么必须用辅存来保存交换出去的那部分数据,而辅存的速度往往要比主存慢上好几个数量级。
好在这问题也并不全然是非甲即乙的选择。在配置大量DRAM的同时,我们还可以配置少量SRAM。将地址空间的某个部分划给SRAM,剩下的部分划给DRAM。一般来说,SRAM可以当作扩展的寄存器来使用。
While this is a possible implementation, it is not viable. Ignoring the problem of mapping the physical resources of such SRAM-backed memory to the virtual address spaces of the processes (which by itself is terribly hard) this approach would require each process to administer in software the allocation of this memory region. The size of the memory region can vary from processor to processor (i.e., processors have different amounts of the expensive SRAM-backed memory). Each module which makes up part of a program will claim its share of the fast memory, which introduces additional costs through synchronization requirements. In short, the gains of having fast memory would be eaten up completely by the overhead of administering the resources.
So, instead of putting the SRAM under the control of the OS or user, it becomes a resource which is transparently used and administered by the processors. In this mode, SRAM is used to make temporary copies of (to cache, in other words) data in main memory which is likely to be used soon by the processor. This is possible because program code and data has temporal and spatial locality. This means that, over short periods of time, there is a good chance that the same code or data gets reused. For code this means that there are most likely loops in the code so that the same code gets executed over and over again (the perfect case for spatial locality). Data accesses are also ideally limited to small regions. Even if the memory used over short time periods is not close together there is a high chance that the same data will be reused before long (temporal locality). For code this means, for instance, that in a loop a function call is made and that function is located elsewhere in the address space. The function may be distant in memory, but calls to that function will be close in time. For data it means that the total amount of memory used at one time (the working set size) is ideally limited but the memory used, as a result of the random access nature of RAM, is not close together. Realizing that locality exists is key to the concept of CPU caches as we use them today.
A simple computation can show how effective caches can theoretically be. Assume access to main memory takes 200 cycles and access to the cache memory take 15 cycles. Then code using 100 data elements 100 times each will spend 2,000,000 cycles on memory operations if there is no cache and only 168,500 cycles if all data can be cached. That is an improvement of 91.5%.
The size of the SRAM used for caches is many times smaller than the main memory. In the author's experience with workstations with CPU caches the cache size has always been around 1/1000th of the size of the main memory (today: 4MB cache and 4GB main memory). This alone does not constitute a problem. If the size of the working set (the set of data currently worked on) is smaller than the cache size it does not matter. But computers do not have large main memories for no reason. The working set is bound to be larger than the cache. This is especially true for systems running multiple processes where the size of the working set is the sum of the sizes of all the individual processes and the kernel.
我们先用一个简单的计算来展示一下高速缓存的效率。假设,访问主存需要200个周期,而访问高速缓存需要15个周期。如果使用100个数据元素100次,那么在没有高速缓存的情况下,需要2000000个周期,而在有高速缓存、而且所有数据都已被缓存的情况下,只需要168500个周期。节约了91.5%的时间。
用作高速缓存的SRAM容量比主存小得多。以我的经验来说,高速缓存的大小一般是主存的千分之一左右(目前一般是4GB主存、4MB缓存)。这一点本身并不是什么问题。只是,计算机一般都会有比较大的主存,因此工作集的大小总是会大于缓存。特别是那些运行多进程的系统,它的工作集大小是所有进程加上内核的总和。
What is needed to deal with the limited size of the cache is a set of good strategies to determine what should be cached at any given time. Since not all data of the working set is used at exactly the same time we can use techniques to temporarily replace some data in the cache with other data. And maybe this can be done before the data is actually needed. This prefetching would remove some of the costs of accessing main memory since it happens asynchronously with respect to the execution of the program. All these techniques and more can be used to make the cache appear bigger than it actually is. We will discuss them in Section 3.3. Once all these techniques are exploited it is up to the programmer to help the processor. How this can be done will be discussed in Section 6.
3.1 CPU Caches in the Big Picture
Before diving into technical details of the implementation of CPU caches some readers might find it useful to first see in some more details how caches fit into the “big picture” of a modern computer system.
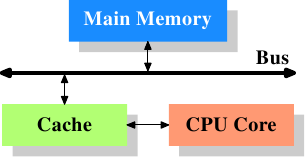
Figure 3.1: Minimum Cache Configuration
Figure 3.1 shows the minimum cache configuration. It corresponds to the architecture which could be found in early systems which deployed CPU caches. The CPU core is no longer directly connected to the main memory. {In even earlier systems the cache was attached to the system bus just like the CPU and the main memory. This was more a hack than a real solution.} All loads and stores have to go through the cache. The connection between the CPU core and the cache is a special, fast connection. In a simplified representation, the main memory and the cache are connected to the system bus which can also be used for communication with other components of the system. We introduced the system bus as “FSB” which is the name in use today; see Section 2.2. In this section we ignore the Northbridge; it is assumed to be present to facilitate the communication of the CPU(s) with the main memory.
3.1 高速缓存的位置
在深入介绍高速缓存的技术细节之前,有必要说明一下它在现代计算机系统中所处的位置。
图3.1: 最简单的高速缓存配置图
图3.1展示了最简单的高速缓存配置。早期的一些系统就是类似的架构。在这种架构中,CPU核心不再直连到主存。{在一些更早的系统中,高速缓存像CPU与主存一样连到系统总线上。那种做法更像是一种hack,而不是真正的解决方案。}数据的读取和存储都经过高速缓存。CPU核心与高速缓存之间是一条特殊的快速通道。在简化的表示法中,主存与高速缓存都连到系统总线上,这条总线同时还用于与其它组件通信。我们管这条总线叫“FSB”——就是现在称呼它的术语,参见第2.2节。在这一节里,我们将忽略北桥。
Even though computers for the last several decades have used the von Neumann architecture, experience has shown that it is of advantage to separate the caches used for code and for data. Intel has used separate code and data caches since 1993 and never looked back. The memory regions needed for code and data are pretty much independent of each other, which is why independent caches work better. In recent years another advantage emerged: the instruction decoding step for the most common processors is slow; caching decoded instructions can speed up the execution, especially when the pipeline is empty due to incorrectly predicted or impossible-to-predict branches.
Soon after the introduction of the cache, the system got more complicated. The speed difference between the cache and the main memory increased again, to a point that another level of cache was added, bigger and slower than the first-level cache. Only increasing the size of the first-level cache was not an option for economical reasons. Today, there are even machines with three levels of cache in regular use. A system with such a processor looks like Figure 3.2. With the increase on the number of cores in a single CPU the number of cache levels might increase in the future even more.
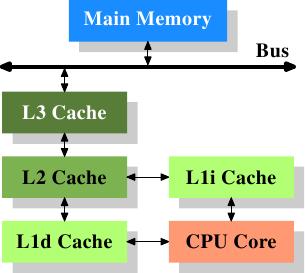
Figure 3.2: Processor with Level 3 Cache
Figure 3.2 shows three levels of cache and introduces the nomenclature we will use in the remainder of the document. L1d is the level 1 data cache, L1i the level 1 instruction cache, etc. Note that this is a schematic; the data flow in reality need not pass through any of the higher-level caches on the way from the core to the main memory. CPU designers have a lot of freedom designing the interfaces of the caches. For programmers these design choices are invisible.
在高速缓存出现后不久,系统变得更加复杂。高速缓存与主存之间的速度差异进一步拉大,直到加入了另一级缓存。新加入的这一级缓存比第一级缓存更大,但是更慢。由于加大一级缓存的做法从经济上考虑是行不通的,所以有了二级缓存,甚至现在的有些系统拥有三级缓存,如图3.2所示。随着单个CPU中核数的增加,未来甚至可能会出现更多层级的缓存。
图3.2: 三级缓存的处理器
图3.2展示了三级缓存,并介绍了本文将使用的一些术语。L1d是一级数据缓存,L1i是一级指令缓存,等等。请注意,这只是示意图,真正的数据流并不需要流经上级缓存。CPU的设计者们在设计高速缓存的接口时拥有很大的自由。而程序员是看不到这些设计选项的。
In addition we have processors which have multiple cores and each core can have multiple “threads”. The difference between a core and a thread is that separate cores have separate copies of (almost {Early multi-core processors even had separate 2nd level caches and no 3rd level cache.}) all the hardware resources. The cores can run completely independently unless they are using the same resources—e.g., the connections to the outside—at the same time. Threads, on the other hand, share almost all of the processor's resources. Intel's implementation of threads has only separate registers for the threads and even that is limited, some registers are shared. The complete picture for a modern CPU therefore looks like Figure 3.3.
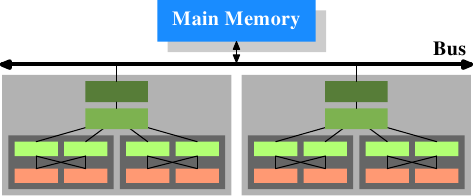
Figure 3.3: Multi processor, multi-core, multi-thread
In this figure we have two processors, each with two cores, each of which has two threads. The threads share the Level 1 caches. The cores (shaded in the darker gray) have individual Level 1 caches. All cores of the CPU share the higher-level caches. The two processors (the two big boxes shaded in the lighter gray) of course do not share any caches. All this will be important, especially when we are discussing the cache effects on multi-process and multi-thread applications.
另外,我们有多核CPU,每个核心可以有多个“线程”。核心与线程的不同之处在于,核心拥有独立的硬件资源({早期的多核CPU甚至有独立的二级缓存。})。在不同时使用相同资源(比如,通往外界的连接)的情况下,核心可以完全独立地运行。而线程只是共享资源。Intel的线程只有独立的寄存器,而且还有限制——不是所有寄存器都独立,有些是共享的。综上,现代CPU的结构就像图3.3所示。
图3.3 多处理器、多核心、多线程
在上图中,有两个处理器,每个处理器有两个核心,每个核心有两个线程。线程们共享一级缓存。核心(以深灰色表示)有独立的一级缓存,同时共享二级缓存。处理器(淡灰色)之间不共享任何缓存。这些信息很重要,特别是在讨论多进程和多线程情况下缓存的影响时尤为重要。
3.2 Cache Operation at High Level
To understand the costs and savings of using a cache we have to combine the knowledge about the machine architecture and RAM technology from Section 2 with the structure of caches described in the previous section.
By default all data read or written by the CPU cores is stored in the cache. There are memory regions which cannot be cached but this is something only the OS implementers have to be concerned about; it is not visible to the application programmer. There are also instructions which allow the programmer to deliberately bypass certain caches. This will be discussed in Section 6.
3.2 高级的缓存操作
了解成本和节约使用缓存,我们必须结合在第二节中讲到的关于计算机体系结构和RAM技术,以及前一节讲到的缓存描述来探讨。
默认情况下,CPU核心所有的数据的读或写都存储在缓存中。当然,也有内存区域不能被缓存的,但是这种情况只发生在操作系统的实现者对数据考虑的前提下;对程序实现者来说,这是不可见的。这也说明,程序设计者可以故意绕过某些缓存,不过这将是第六节中讨论的内容了。
If the CPU needs a data word the caches are searched first. Obviously, the cache cannot contain the content of the entire main memory (otherwise we would need no cache), but since all memory addresses are cacheable, each cache entry is tagged using the address of the data word in the main memory. This way a request to read or write to an address can search the caches for a matching tag. The address in this context can be either the virtual or physical address, varying based on the cache implementation.
Since the tag requires space in addition to the actual memory, it is inefficient to chose a word as the granularity of the cache. For a 32-bit word on an x86 machine the tag itself might need 32 bits or more. Furthermore, since spatial locality is one of the principles on which caches are based, it would be bad to not take this into account. Since neighboring memory is likely to be used together it should also be loaded into the cache together. Remember also what we learned in Section 2.2.1: RAM modules are much more effective if they can transport many data words in a row without a new CAS or even RAS signal. So the entries stored in the caches are not single words but, instead, “lines” of several contiguous words. In early caches these lines were 32 bytes long; now the norm is 64 bytes. If the memory bus is 64 bits wide this means 8 transfers per cache line. DDR supports this transport mode efficiently.
如果CPU需要访问某个字(word),先检索缓存。很显然,缓存不可能容纳主存所有内容(否则还需要主存干嘛)。系统用字的内存地址来对缓存条目进行标记。如果需要读写某个地址的字,那么根据标签来检索缓存即可。这里用到的地址可以是虚拟地址,也可以是物理地址,取决于缓存的具体实现。
标签是需要额外空间的,用字作为缓存的粒度显然毫无效率。比如,在x86机器上,32位字的标签可能需要32位,甚至更长。另一方面,由于空间局部性的存在,与当前地址相邻的地址有很大可能会被一起访问。再回忆下2.2.1节——内存模块在传输位于同一行上的多份数据时,由于不需要发送新CAS信号,甚至不需要发送RAS信号,因此可以实现很高的效率。基于以上的原因,缓存条目并不存储单个字,而是存储若干连续字组成的“线”。在早期的缓存中,线长是32字节,现在一般是64字节。对于64位宽的内存总线,每条线需要8次传输。而DDR对于这种传输模式的支持更为高效。
When memory content is needed by the processor the entire cache line is loaded into the L1d. The memory address for each cache line is computed by masking the address value according to the cache line size. For a 64 byte cache line this means the low 6 bits are zeroed. The discarded bits are used as the offset into the cache line. The remaining bits are in some cases used to locate the line in the cache and as the tag. In practice an address value is split into three parts. For a 32-bit address it might look as follows:

With a cache line size of 2O the low O bits are used as the offset into the cache line. The next S bits select the “cache set”. We will go into more detail soon on why sets, and not single slots, are used for cache lines. For now it is sufficient to understand there are 2S sets of cache lines. This leaves the top 32 - S - O = T bits which form the tag. These T bits are the value associated with each cache line to distinguish all the aliases {All cache lines with the same S part of the address are known by the same alias.} which are cached in the same cache set. The S bits used to address the cache set do not have to be stored since they are the same for all cache lines in the same set.
当处理器需要内存中的某块数据时,整条缓存线被装入L1d。缓存线的地址通过对内存地址进行掩码操作生成。对于64字节的缓存线,是将低6位置0。这些被丢弃的位作为线内偏移量。其它的位作为标签,并用于在缓存内定位。在实践中,我们将地址分为三个部分。32位地址的情况如下:
如果缓存线长度为2O,那么地址的低O位用作线内偏移量。上面的S位选择“缓存集”。后面我们会说明使用缓存集的原因。现在只需要明白一共有2S个缓存集就够了。剩下的32 - S - O = T位组成标签。它们用来区分别名相同的各条线{有相同S部分的缓存线被称为有相同的别名。}用于定位缓存集的S部分不需要存储,因为属于同一缓存集的所有线的S部分都是相同的。
When an instruction modifies memory the processor still has to load a cache line first because no instruction modifies an entire cache line at once (exception to the rule: write-combining as explained in Section 6.1). The content of the cache line before the write operation therefore has to be loaded. It is not possible for a cache to hold partial cache lines. A cache line which has been written to and which has not been written back to main memory is said to be “dirty”. Once it is written the dirty flag is cleared.
To be able to load new data in a cache it is almost always first necessary to make room in the cache. An eviction from L1d pushes the cache line down into L2 (which uses the same cache line size). This of course means room has to be made in L2. This in turn might push the content into L3 and ultimately into main memory. Each eviction is progressively more expensive. What is described here is the model for an exclusive cache as is preferred by modern AMD and VIA processors. Intel implements inclusive caches {This generalization is not completely correct. A few caches are exclusive and some inclusive caches have exclusive cache properties.} where each cache line in L1d is also present in L2. Therefore evicting from L1d is much faster. With enough L2 cache the disadvantage of wasting memory for content held in two places is minimal and it pays off when evicting. A possible advantage of an exclusive cache is that loading a new cache line only has to touch the L1d and not the L2, which could be faster.
当某条指令修改内存时,仍然要先装入缓存线,因为任何指令都不可能同时修改整条线(只有一个例外——第6.1节中将会介绍的写合并(write-combine))。因此需要在写操作前先把缓存线装载进来。如果缓存线被写入,但还没有写回主存,那就是所谓的“脏了”。脏了的线一旦写回主存,脏标记即被清除。
为了装入新数据,基本上总是要先在缓存中清理出位置。L1d将内容逐出L1d,推入L2(线长相同)。当然,L2也需要清理位置。于是L2将内容推入L3,最后L3将它推入主存。这种逐出操作一级比一级昂贵。这里所说的是现代AMD和VIA处理器所采用的独占型缓存(exclusive cache)。而Intel采用的是包容型缓存(inclusive cache),{并不完全正确,Intel有些缓存是独占型的,还有一些缓存具有独占型缓存的特点。}L1d的每条线同时存在于L2里。对这种缓存,逐出操作就很快了。如果有足够L2,对于相同内容存在不同地方造成内存浪费的缺点可以降到最低,而且在逐出时非常有利。而独占型缓存在装载新数据时只需要操作L1d,不需要碰L2,因此会比较快。
The CPUs are allowed to manage the caches as they like as long as the memory model defined for the processor architecture is not changed. It is, for instance, perfectly fine for a processor to take advantage of little or no memory bus activity and proactively write dirty cache lines back to main memory. The wide variety of cache architectures among the processors for the x86 and x86-64, between manufacturers and even within the models of the same manufacturer, are testament to the power of the memory model abstraction.
In symmetric multi-processor (SMP) systems the caches of the CPUs cannot work independently from each other. All processors are supposed to see the same memory content at all times. The maintenance of this uniform view of memory is called “cache coherency”. If a processor were to look simply at its own caches and main memory it would not see the content of dirty cache lines in other processors. Providing direct access to the caches of one processor from another processor would be terribly expensive and a huge bottleneck. Instead, processors detect when another processor wants to read or write to a certain cache line.
处理器体系结构中定义的作为存储器的模型只要还没有改变,那就允许多CPU按照自己的方式来管理高速缓存。这表示,例如,设计优良的处理器,利用很少或根本没有内存总线活动,并主动写回主内存脏高速缓存行。这种高速缓存架构在如x86和x86-64各种各样的处理器间存在。制造商之间,即使在同一制造商生产的产品中,证明了的内存模型抽象的力量。
在对称多处理器(SMP)架构的系统中,CPU的高速缓存不能独立的工作。在任何时候,所有的处理器都应该拥有相同的内存内容。保证这样的统一的内存视图被称为“高速缓存一致性”。如果在其自己的高速缓存和主内存间,处理器设计简单,它将不会看到在其他处理器上的脏高速缓存行的内容。从一个处理器直接访问另一个处理器的高速缓存这种模型设计代价将是非常昂贵的,它是一个相当大的瓶颈。相反,当另一个处理器要读取或写入到高速缓存线上时,处理器会去检测。
If a write access is detected and the processor has a clean copy of the cache line in its cache, this cache line is marked invalid. Future references will require the cache line to be reloaded. Note that a read access on another CPU does not necessitate an invalidation, multiple clean copies can very well be kept around.
More sophisticated cache implementations allow another possibility to happen. If the cache line which another processor wants to read from or write to is currently marked dirty in the first processor's cache a different course of action is needed. In this case the main memory is out-of-date and the requesting processor must, instead, get the cache line content from the first processor. Through snooping, the first processor notices this situation and automatically sends the requesting processor the data. This action bypasses main memory, though in some implementations the memory controller is supposed to notice this direct transfer and store the updated cache line content in main memory. If the access is for writing the first processor then invalidates its copy of the local cache line.
如果CPU检测到一个写访问,而且该CPU的cache中已经缓存了一个cache line的原始副本,那么这个cache line将被标记为无效的cache line。接下来在引用这个cache line之前,需要重新加载该cache line。需要注意的是读访问并不会导致cache line被标记为无效的。
更精确的cache实现需要考虑到其他更多的可能性,比如第二个CPU在读或者写他的cache line时,发现该cache line在第一个CPU的cache中被标记为脏数据了,此时我们就需要做进一步的处理。在这种情况下,主存储器已经失效,第二个CPU需要读取第一个CPU的cache line。通过测试,我们知道在这种情况下第一个CPU会将自己的cache line数据自动发送给第二个CPU。这种操作是绕过主存储器的,但是有时候存储控制器是可以直接将第一个CPU中的cache line数据存储到主存储器中。对第一个CPU的cache的写访问会导致本地cache line的所有拷贝被标记为无效。
Over time a number of cache coherency protocols have been developed. The most important is MESI, which we will introduce in Section 3.3.4. The outcome of all this can be summarized in a few simple rules:
- A dirty cache line is not present in any other processor's cache.
- Clean copies of the same cache line can reside in arbitrarily many caches.
If these rules can be maintained, processors can use their caches efficiently even in multi-processor systems. All the processors need to do is to monitor each others' write accesses and compare the addresses with those in their local caches. In the next section we will go into a few more details about the implementation and especially the costs.
- 一个脏缓存线不存在于任何其他处理器的缓存之中。
- 同一缓存线中的干净拷贝可以驻留在任意多个其他缓存之中。
Finally, we should at least give an impression of the costs associated with cache hits and misses. These are the numbers Intel lists for a Pentium M:
To Where Cycles Register <= 1 L1d ~3 L2 ~14 Main Memory ~240
These are the actual access times measured in CPU cycles. It is interesting to note that for the on-die L2 cache a large part (probably even the majority) of the access time is caused by wire delays. This is a physical limitation which can only get worse with increasing cache sizes. Only process shrinking (for instance, going from 60nm for Merom to 45nm for Penryn in Intel's lineup) can improve those numbers.
最后,我们至少应该关注高速缓存命中或未命中带来的消耗。下面是英特尔奔腾 M 的数据:
| To Where | Cycles |
|---|---|
| Register | <= 1 |
| L1d | ~3 |
| L2 | ~14 |
| Main Memory | ~240 |
这是在CPU周期中的实际访问时间。有趣的是,对于L2高速缓存的访问时间很大一部分(甚至是大部分)是由线路的延迟引起的。这是一个限制,增加高速缓存的大小变得更糟。只有当减小时(例如,从60纳米的Merom到45纳米Penryn处理器),可以提高这些数据。
The numbers in the table look high but, fortunately, the entire cost does not have to be paid for each occurrence of the cache load and miss. Some parts of the cost can be hidden. Today's processors all use internal pipelines of different lengths where the instructions are decoded and prepared for execution. Part of the preparation is loading values from memory (or cache) if they are transferred to a register. If the memory load operation can be started early enough in the pipeline, it may happen in parallel with other operations and the entire cost of the load might be hidden. This is often possible for L1d; for some processors with long pipelines for L2 as well.
There are many obstacles to starting the memory read early. It might be as simple as not having sufficient resources for the memory access or it might be that the final address of the load becomes available late as the result of another instruction. In these cases the load costs cannot be hidden (completely).
提早启动内存的读取有许多障碍。它可能只是简单的不具有足够资源供内存访问,或者地址从另一个指令获取,然后加载的最终地址才变得可用。在这种情况下,加载成本是不能隐藏的(完全的)。
For write operations the CPU does not necessarily have to wait until the value is safely stored in memory. As long as the execution of the following instructions appears to have the same effect as if the value were stored in memory there is nothing which prevents the CPU from taking shortcuts. It can start executing the next instruction early. With the help of shadow registers which can hold values no longer available in a regular register it is even possible to change the value which is to be stored in the incomplete write operation.
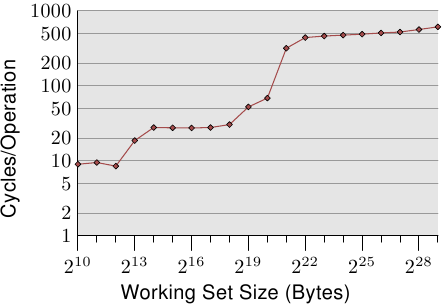
Figure 3.4: Access Times for Random Writes
For an illustration of the effects of cache behavior see Figure 3.4. We will talk about the program which generated the data later; it is a simple simulation of a program which accesses a configurable amount of memory repeatedly in a random fashion. Each data item has a fixed size. The number of elements depends on the selected working set size. The Y–axis shows the average number of CPU cycles it takes to process one element; note that the scale for the Y–axis is logarithmic. The same applies in all the diagrams of this kind to the X–axis. The size of the working set is always shown in powers of two.
对于写操作,CPU并不需要等待数据被安全地放入内存。只要指令具有类似的效果,就没有什么东西可以阻止CPU走捷径了。它可以早早地执行下一条指令,甚至可以在影子寄存器(shadow register)的帮助下,更改这个写操作将要存储的数据。
图3.4: 随机写操作的访问时间
图3.4展示了缓存的效果。关于产生图中数据的程序,我们会在稍后讨论。这里大致说下,这个程序是连续随机地访问某块大小可配的内存区域。每个数据项的大小是固定的。数据项的多少取决于选择的工作集大小。Y轴表示处理每个元素平均需要多少个CPU周期,注意它是对数刻度。X轴也是同样,工作集的大小都以2的n次方表示。
The graph shows three distinct plateaus. This is not surprising: the specific processor has L1d and L2 caches, but no L3. With some experience we can deduce that the L1d is 213 bytes in size and that the L2 is 220 bytes in size. If the entire working set fits into the L1d the cycles per operation on each element is below 10. Once the L1d size is exceeded the processor has to load data from L2 and the average time springs up to around 28. Once the L2 is not sufficient anymore the times jump to 480 cycles and more. This is when many or most operations have to load data from main memory. And worse: since data is being modified dirty cache lines have to be written back, too.
This graph should give sufficient motivation to look into coding improvements which help improve cache usage. We are not talking about a few measly percent here; we are talking about orders-of-magnitude improvements which are sometimes possible. In Section 6 we will discuss techniques which allow writing more efficient code. The next section goes into more details of CPU cache designs. The knowledge is good to have but not necessary for the rest of the paper. So this section could be skipped.
图中有三个比较明显的不同阶段。很正常,这个处理器有L1d和L2,没有L3。根据经验可以推测出,L1d有213字节,而L2有220字节。因为,如果整个工作集都可以放入L1d,那么只需不到10个周期就可以完成操作。如果工作集超过L1d,处理器不得不从L2获取数据,于是时间飘升到28个周期左右。如果工作集更大,超过了L2,那么时间进一步暴涨到480个周期以上。这时候,许多操作将不得不从主存中获取数据。更糟糕的是,如果修改了数据,还需要将这些脏了的缓存线写回内存。
看了这个图,大家应该会有足够的动力去检查代码、改进缓存的利用方式了吧?这里的性能改善可不只是微不足道的几个百分点,而是几个数量级呀。在第6节中,我们将介绍一些编写高效代码的技巧。而下一节将进一步深入缓存的设计。虽然精彩,但并不是必修课,大家可以选择性地跳过。
3.3 CPU Cache Implementation Details
Cache implementers have the problem that each cell in the huge main memory potentially has to be cached. If the working set of a program is large enough this means there are many main memory locations which fight for each place in the cache. Previously it was noted that a ratio of 1-to-1000 for cache versus main memory size is not uncommon.
3.3.1 Associativity
It would be possible to implement a cache where each cache line can hold a copy of any memory location. This is called a fully associative cache. To access a cache line the processor core would have to compare the tags of each and every cache line with the tag for the requested address. The tag would be comprised of the entire part of the address which is not the offset into the cache line (that means, S in the figure on Section 3.2 is zero).
3.3 CPU缓存实现的细节
缓存的实现者们都要面对一个问题——主存中每一个单元都可能需被缓存。如果程序的工作集很大,就会有许多内存位置为了缓存而打架。前面我们曾经提过缓存与主存的容量比,1:1000也十分常见。
3.3.1 关联性
我们可以让缓存的每条线能存放任何内存地址的数据。这就是所谓的全关联缓存(fully associative cache)。对于这种缓存,处理器为了访问某条线,将不得不检索所有线的标签。而标签则包含了整个地址,而不仅仅只是线内偏移量(也就意味着,图3.2中的S为0)。
There are caches which are implemented like this but, by looking at the numbers for an L2 in use today, will show that this is impractical. Given a 4MB cache with 64B cache lines the cache would have 65,536 entries. To achieve adequate performance the cache logic would have to be able to pick from all these entries the one matching a given tag in just a few cycles. The effort to implement this would be enormous.

Figure 3.5: Fully Associative Cache Schematics
For each cache line a comparator is needed to compare the large tag (note, S is zero). The letter next to each connection indicates the width in bits. If none is given it is a single bit line. Each comparator has to compare two T-bit-wide values. Then, based on the result, the appropriate cache line content is selected and made available. This requires merging as many sets of O data lines as there are cache buckets. The number of transistors needed to implement a single comparator is large especially since it must work very fast. No iterative comparator is usable. The only way to save on the number of comparators is to reduce the number of them by iteratively comparing the tags. This is not suitable for the same reason that iterative comparators are not: it takes too long.
高速缓存有类似这样的实现,但是,看看在今天使用的L2的数目,表明这是不切实际的。给定4MB的高速缓存和64B的高速缓存段,高速缓存将有65,536个项。为了达到足够的性能,缓存逻辑必须能够在短短的几个时钟周期内,从所有这些项中,挑一个匹配给定的标签。实现这一点的工作将是巨大的。
Figure 3.5: 全关联高速缓存原理图
对于每个高速缓存行,比较器是需要比较大标签(注意,S是零)。每个连接旁边的字母表示位的宽度。如果没有给出,它是一个单比特线。每个比较器都要比较两个T-位宽的值。然后,基于该结果,适当的高速缓存行的内容被选中,并使其可用。这需要合并多套O数据线,因为他们是缓存桶(译注:这里类似把O输出接入多选器,所以需要合并)。实现仅仅一个比较器,需要晶体管的数量就非常大,特别是因为它必须非常快。没有迭代比较器是可用的。节省比较器的数目的唯一途径是通过反复比较标签,以减少它们的数目。这是不适合的,出于同样的原因,迭代比较器不可用:它的时间太长。
Fully associative caches are practical for small caches (for instance, the TLB caches on some Intel processors are fully associative) but those caches are small, really small. We are talking about a few dozen entries at most.
For L1i, L1d, and higher level caches a different approach is needed. What can be done is to restrict the search. In the most extreme restriction each tag maps to exactly one cache entry. The computation is simple: given the 4MB/64B cache with 65,536 entries we can directly address each entry by using bits 6 to 21 of the address (16 bits). The low 6 bits are the index into the cache line.
对于L1i,L1d和更高级别的缓存,需要采用不同的方法。可以做的就是是限制搜索。最极端的限制是,每个标签映射到一个明确的缓存条目。计算很简单:给定的4MB/64B缓存有65536项,我们可以使用地址的bit6到bit21(16位)来直接寻址高速缓存的每一个项。地址的低6位作为高速缓存段的索引。
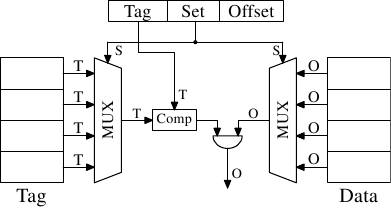
Figure 3.6: Direct-Mapped Cache Schematics
Such a direct-mapped cache is fast and relatively easy to implement as can be seen in Figure 3.6. It requires exactly one comparator, one multiplexer (two in this diagram where tag and data are separated, but this is not a hard requirement on the design), and some logic to select only valid cache line content. The comparator is complex due to the speed requirements but there is only one of them now; as a result more effort can be spent on making it fast. The real complexity in this approach lies in the multiplexers. The number of transistors in a simple multiplexer grows with O(log N), where N is the number of cache lines. This is tolerable but might get slow, in which case speed can be increased by spending more real estate on transistors in the multiplexers to parallelize some of the work and to increase the speed. The total number of transistors can grow slowly with a growing cache size which makes this solution very attractive. But it has a drawback: it only works well if the addresses used by the program are evenly distributed with respect to the bits used for the direct mapping. If they are not, and this is usually the case, some cache entries are heavily used and therefore repeatedly evicted while others are hardly used at all or remain empty.
Figure 3.6: Direct-Mapped Cache Schematics
在图3.6中可以看出,这种直接映射的高速缓存,速度快,比较容易实现。它只是需要一个比较器,一个多路复用器(在这个图中有两个,标记和数据是分离的,但是对于设计这不是一个硬性要求),和一些逻辑来选择只是有效的高速缓存行的内容。由于速度的要求,比较器是复杂的,但是现在只需要一个,结果是可以花更多的精力,让其变得快速。这种方法的复杂性在于在多路复用器。一个简单的多路转换器中的晶体管的数量增速是O(log N)的,其中N是高速缓存段的数目。这是可以容忍的,但可能会很慢,在某种情况下,速度可提升,通过增加多路复用器晶体管数量,来并行化的一些工作和自身增速。晶体管的总数只是随着快速增长的高速缓存缓慢的增加,这使得这种解决方案非常有吸引力。但它有一个缺点:只有用于直接映射地址的相关的地址位均匀分布,程序才能很好工作。如果分布的不均匀,而且这是常态,一些缓存项频繁的使用,并因此多次被换出,而另一些则几乎不被使用或一直是空的。
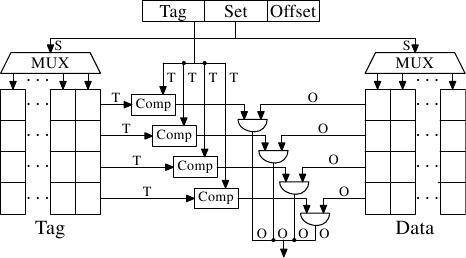
Figure 3.7: Set-Associative Cache Schematics
This problem can be solved by making the cache set associative. A set-associative cache combines the features of the full associative and direct-mapped caches to largely avoid the weaknesses of those designs. Figure 3.7 shows the design of a set-associative cache. The tag and data storage are divided into sets which are selected by the address. This is similar to the direct-mapped cache. But instead of only having one element for each set value in the cache a small number of values is cached for the same set value. The tags for all the set members are compared in parallel, which is similar to the functioning of the fully associative cache.
Figure 3.7: 组关联高速缓存原理图
可以通过使高速缓存的组关联来解决此问题。组关联结合高速缓存的全关联和直接映射高速缓存特点,在很大程度上避免那些设计的弱点。图3.7显示了一个组关联高速缓存的设计。标签和数据存储分成不同的组并可以通过地址选择。这类似直接映射高速缓存。但是,小数目的值可以在同一个高速缓存组缓存,而不是一个缓存组只有一个元素,用于在高速缓存中的每个设定值是相同的一组值的缓存。所有组的成员的标签可以并行比较,这类似全关联缓存的功能。
The result is a cache which is not easily defeated by unfortunate or deliberate selection of addresses with the same set numbers and at the same time the size of the cache is not limited by the number of comparators which can be implemented in parallel. If the cache grows it is (in this figure) only the number of columns which increases, not the number of rows. The number of rows only increases if the associativity of the cache is increased. Today processors are using associativity levels of up to 16 for L2 caches or higher. L1 caches usually get by with 8.
| L2 Cache Size | Associativity | |||||||
|---|---|---|---|---|---|---|---|---|
| Direct | 2 | 4 | 8 | |||||
| CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | |
| 512k | 27,794,595 | 20,422,527 | 25,222,611 | 18,303,581 | 24,096,510 | 17,356,121 | 23,666,929 | 17,029,334 |
| 1M | 19,007,315 | 13,903,854 | 16,566,738 | 12,127,174 | 15,537,500 | 11,436,705 | 15,162,895 | 11,233,896 |
| 2M | 12,230,962 | 8,801,403 | 9,081,881 | 6,491,011 | 7,878,601 | 5,675,181 | 7,391,389 | 5,382,064 |
| 4M | 7,749,986 | 5,427,836 | 4,736,187 | 3,159,507 | 3,788,122 | 2,418,898 | 3,430,713 | 2,125,103 |
| 8M | 4,731,904 | 3,209,693 | 2,690,498 | 1,602,957 | 2,207,655 | 1,228,190 | 2,111,075 | 1,155,847 |
| 16M | 2,620,587 | 1,528,592 | 1,958,293 | 1,089,580 | 1,704,878 | 883,530 | 1,671,541 | 862,324 |
Table 3.1: Effects of Cache Size, Associativity, and Line Size
Given our 4MB/64B cache and 8-way set associativity the cache we are left with has 8,192 sets and only 13 bits of the tag are used in addressing the cache set. To determine which (if any) of the entries in the cache set contains the addressed cache line 8 tags have to be compared. That is feasible to do in very short time. With an experiment we can see that this makes sense.
其结果是高速缓存,不容易被不幸或故意选择同属同一组编号的地址所击败,同时高速缓存的大小并不限于由比较器的数目,可以以并行的方式实现。如果高速缓存增长,只(在该图中)增加列的数目,而不增加行数。只有高速缓存之间的关联性增加,行数才会增加。今天,处理器的L2高速缓存或更高的高速缓存,使用的关联性高达16。 L1高速缓存通常使用8。
| L2 Cache Size | Associativity | |||||||
|---|---|---|---|---|---|---|---|---|
| Direct | 2 | 4 | 8 | |||||
| CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | |
| 512k | 27,794,595 | 20,422,527 | 25,222,611 | 18,303,581 | 24,096,510 | 17,356,121 | 23,666,929 | 17,029,334 |
| 1M | 19,007,315 | 13,903,854 | 16,566,738 | 12,127,174 | 15,537,500 | 11,436,705 | 15,162,895 | 11,233,896 |
| 2M | 12,230,962 | 8,801,403 | 9,081,881 | 6,491,011 | 7,878,601 | 5,675,181 | 7,391,389 | 5,382,064 |
| 4M | 7,749,986 | 5,427,836 | 4,736,187 | 3,159,507 | 3,788,122 | 2,418,898 | 3,430,713 | 2,125,103 |
| 8M | 4,731,904 | 3,209,693 | 2,690,498 | 1,602,957 | 2,207,655 | 1,228,190 | 2,111,075 | 1,155,847 |
| 16M | 2,620,587 | 1,528,592 | 1,958,293 | 1,089,580 | 1,704,878 | 883,530 | 1,671,541 | 862,324 |
Table 3.1: 高速缓存大小,关联行,段大小的影响
给定我们4MB/64B高速缓存,8路组关联,相关的缓存留给我们的有8192组,只用标签的13位,就可以寻址缓集。要确定哪些(如果有的话)的缓存组设置中的条目包含寻址的高速缓存行,8个标签都要进行比较。在很短的时间内做出来是可行的。通过一个实验,我们可以看到,这是有意义的。
Table 3.1 shows the number of L2 cache misses for a program (gcc in this case, the most important benchmark of them all, according to the Linux kernel people) for changing cache size, cache line size, and associativity set size. In Section 7.2 we will introduce the tool to simulate the caches as required for this test.
Just in case this is not yet obvious, the relationship of all these values is that the cache size is
cache line size × associativity × number of sets
The addresses are mapped into the cache by using
O = log 2 cache line size
S = log 2 number of sets
in the way the figure in Section 3.2 shows.
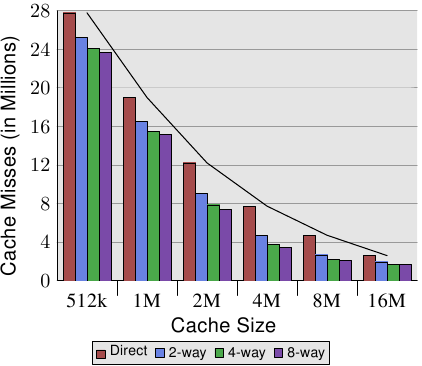
Figure 3.8: Cache Size vs Associativity (CL=32)
Figure 3.8 makes the data of the table more comprehensible. It shows the data for a fixed cache line size of 32 bytes. Looking at the numbers for a given cache size we can see that associativity can indeed help to reduce the number of cache misses significantly. For an 8MB cache going from direct mapping to 2-way set associative cache saves almost 44% of the cache misses. The processor can keep more of the working set in the cache with a set associative cache compared with a direct mapped cache.
表3.1显示一个程序在改变缓存大小,缓存段大小和关联集大小,L2高速缓存的缓存失效数量(根据Linux内核相关的方面人的说法,GCC在这种情况下,是他们所有中最重要的标尺)。在7.2节中,我们将介绍工具来模拟此测试要求的高速缓存。
万一这还不是很明显,所有这些值之间的关系是高速缓存的大小为:
cache line size × associativity × number of sets
地址被映射到高速缓存使用
O = log 2 cache line size
S = log 2 number of sets
在第3.2节中的图显示的方式。
Figure 3.8: 缓存段大小 vs 关联行 (CL=32)
图3.8表中的数据更易于理解。它显示一个固定的32个字节大小的高速缓存行的数据。对于一个给定的高速缓存大小,我们可以看出,关联性,的确可以帮助明显减少高速缓存未命中的数量。对于8MB的缓存,从直接映射到2路组相联,可以减少近44%的高速缓存未命中。组相联高速缓存和直接映射缓存相比,该处理器可以把更多的工作集保持在缓存中。
In the literature one can occasionally read that introducing associativity has the same effect as doubling cache size. This is true in some extreme cases as can be seen in the jump from the 4MB to the 8MB cache. But it certainly is not true for further doubling of the associativity. As we can see in the data, the successive gains are much smaller. We should not completely discount the effects, though. In the example program the peak memory use is 5.6M. So with a 8MB cache there are unlikely to be many (more than two) uses for the same cache set. With a larger working set the savings can be higher as we can see from the larger benefits of associativity for the smaller cache sizes.
In general, increasing the associativity of a cache above 8 seems to have little effects for a single-thread workload. With the introduction of multi-core processors which use a shared L2 the situation changes. Now you basically have two programs hitting on the same cache which causes the associativity in practice to be halved (or quartered for quad-core processors). So it can be expected that, with increasing numbers of cores, the associativity of the shared caches should grow. Once this is not possible anymore (16-way set associativity is already hard) processor designers have to start using shared L3 caches and beyond, while L2 caches are potentially shared by a subset of the cores.
在文献中,偶尔可以读到,引入关联性,和加倍高速缓存的大小具有相同的效果。在从4M缓存跃升到8MB缓存的极端的情况下,这是正确的。关联性再提高一倍那就肯定不正确啦。正如我们所看到的数据,后面的收益要小得多。我们不应该完全低估它的效果,虽然。在示例程序中的内存使用的峰值是5.6M。因此,具有8MB缓存不太可能有很多(两个以上)使用相同的高速缓存的组。从较小的缓存的关联性的巨大收益可以看出,较大工作集可以节省更多。
在一般情况下,增加8以上的高速缓存之间的关联性似乎对只有一个单线程工作量影响不大。随着介绍一个使用共享L2的多核处理器,形势发生了变化。现在你基本上有两个程序命中相同的缓存, 实际上导致高速缓存减半(对于四核处理器是1/4)。因此,可以预期,随着核的数目的增加,共享高速缓存的相关性也应增长。一旦这种方法不再可行(16 路组关联性已经很难)处理器设计者不得不开始使用共享的三级高速缓存和更高级别的,而L2高速缓存只被核的一个子集共享。
Another effect we can study in Figure 3.8 is how the increase in cache size helps with performance. This data cannot be interpreted without knowing about the working set size. Obviously, a cache as large as the main memory would lead to better results than a smaller cache, so there is in general no limit to the largest cache size with measurable benefits.
As already mentioned above, the size of the working set at its peak is 5.6M. This does not give us any absolute number of the maximum beneficial cache size but it allows us to estimate the number. The problem is that not all the memory used is contiguous and, therefore, we have, even with a 16M cache and a 5.6M working set, conflicts (see the benefit of the 2-way set associative 16MB cache over the direct mapped version). But it is a safe bet that with the same workload the benefits of a 32MB cache would be negligible. But who says the working set has to stay the same? Workloads are growing over time and so should the cache size. When buying machines, and one has to choose the cache size one is willing to pay for, it is worthwhile to measure the working set size. Why this is important can be seen in the figures on Figure 3.10.
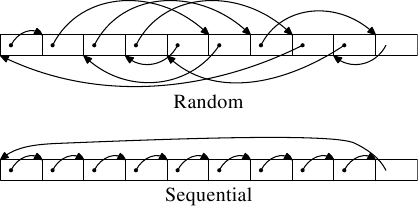
Figure 3.9: Test Memory Layouts
Two types of tests are run. In the first test the elements are processed sequentially. The test program follows the pointernbut the array elements are chained so that they are traversed in the order in which they are found in memory. This can be seen in the lower part of Figure 3.9. There is one back reference from the last element. In the second test (upper part of the figure) the array elements are traversed in a random order. In both cases the array elements form a circular single-linked list.
从图3.8中,我们还可以研究缓存大小对性能的影响。这一数据需要了解工作集的大小才能进行解读。很显然,与主存相同的缓存比小缓存能产生更好的结果,因此,缓存通常是越大越好。
上文已经说过,示例中最大的工作集为5.6M。它并没有给出最佳缓存大小值,但我们可以估算出来。问题主要在于内存的使用并不连续,因此,即使是16M的缓存,在处理5.6M的工作集时也会出现冲突(参见2路集合关联式16MB缓存vs直接映射式缓存的优点)。不管怎样,我们可以有把握地说,在同样5.6M的负载下,缓存从16MB升到32MB基本已没有多少提高的余地。但是,工作集是会变的。如果工作集不断增大,缓存也需要随之增大。在购买计算机时,如果需要选择缓存大小,一定要先衡量工作集的大小。原因可以参见图3.10。
图3.9: 测试的内存分布情况
我们执行两项测试。第一项测试是按顺序地访问所有元素。测试程序循着指针n进行访问,而所有元素是链接在一起的,从而使它们的被访问顺序与在内存中排布的顺序一致,如图3.9的下半部分所示,末尾的元素有一个指向首元素的引用。而第二项测试(见图3.9的上半部分)则是按随机顺序访问所有元素。在上述两个测试中,所有元素都构成一个单向循环链表。
3.3.2 Measurements of Cache Effects
All the figures are created by measuring a program which can simulate working sets of arbitrary size, read and write access, and sequential or random access. We have already seen some results in Figure 3.4. The program creates an array corresponding to the working set size of elements of this type:
struct l {
struct l *n;
long int pad[NPAD];
};
All entries are chained in a circular list using thenelement, either in sequential or random order. Advancing from one entry to the next always uses the pointer, even if the elements are laid out sequentially. Thepadelement is the payload and it can grow arbitrarily large. In some tests the data is modified, in others the program only performs read operations.
In the performance measurements we are talking about working set sizes. The working set is made up of an array ofstruct lelements. A working set of 2N bytes contains
2 N/sizeof(struct l)
elements. Obviouslysizeof(struct l)depends on the value ofNPAD. For 32-bit systems,NPAD=7 means the size of each array element is 32 bytes, for 64-bit systems the size is 64 bytes.
3.3.2 Cache的性能测试
用于测试程序的数据可以模拟一个任意大小的工作集:包括读、写访问,随机、连续访问。在图3.4中我们可以看到,程序为工作集创建了一个与其大小和元素类型相同的数组:
struct l {
struct l *n;
long int pad[NPAD];
};
n字段将所有节点随机得或者顺序的加入到环形链表中,用指针从当前节点进入到下一个节点。pad字段用来存储数据,其可以是任意大小。在一些测试程序中,pad字段是可以修改的, 在其他程序中,pad字段只可以进行读操作。
在性能测试中,我们谈到工作集大小的问题,工作集使用结构体l定义的元素表示的。2N 字节的工作集包含
2 N/sizeof(struct l)
个元素. 显然sizeof(struct l) 的值取决于NPAD的大小。在32位系统上,NPAD=7意味着数组的每个元素的大小为32字节,在64位系统上,NPAD=7意味着数组的每个元素的大小为64字节。
Single Threaded Sequential Access
The simplest case is a simple walk over all the entries in the list. The list elements are laid out sequentially, densely packed. Whether the order of processing is forward or backward does not matter, the processor can deal with both directions equally well. What we measure here—and in all the following tests—is how long it takes to handle a single list element. The time unit is a processor cycle. Figure 3.10 shows the result. Unless otherwise specified, all measurements are made on a Pentium 4 machine in 64-bit mode which means the structurelwithNPAD=0is eight bytes in size.
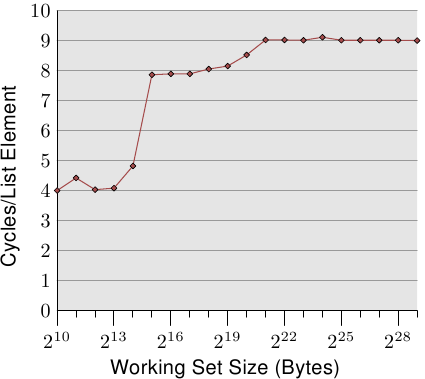
Figure 3.10: Sequential Read Access, NPAD=0
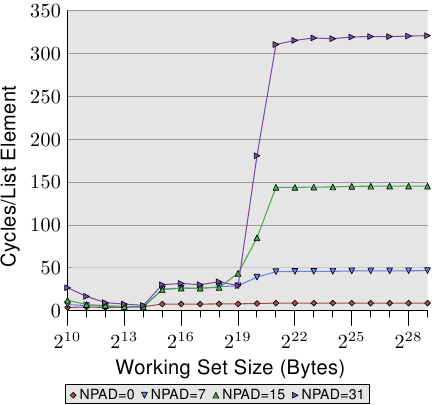
Figure 3.11: Sequential Read for Several Sizes
单线程顺序访问
最简单的情况就是遍历链表中顺序存储的节点。无论是从前向后处理,还是从后向前,对于处理器来说没有什么区别。下面的测试中,我们需要得到处理链表中一个元素所需要的时间,以CPU时钟周期最为计时单元。图3.10显示了测试结构。除非有特殊说明, 所有的测试都是在Pentium 4 64-bit 平台上进行的,因此结构体l中NPAD=0,大小为8字节。
图 3.10: 顺序读访问, NPAD=0
图 3.11: 顺序读多个字节
- Up to a working set size of 214 bytes.
- From 215 bytes to 220 bytes.
- From 221 bytes and up.
These steps can be easily explained: the processor has a 16kB L1d and 1MB L2. We do not see sharp edges in the transition from one level to the other because the caches are used by other parts of the system as well and so the cache is not exclusively available for the program data. Specifically the L2 cache is a unified cache and also used for the instructions (NB: Intel uses inclusive caches).
一开始的两个测试数据收到了噪音的污染。由于它们的工作负荷太小,无法过滤掉系统内其它进程对它们的影响。我们可以认为它们都是4个周期以内的。这样一来,整个图可以划分为比较明显的三个部分:
- 工作集小于214字节的。
- 工作集从215字节到220字节的。
- 工作集大于221字节的。
这样的结果很容易解释——是因为处理器有16KB的L1d和1MB的L2。而在这三个部分之间,并没有非常锐利的边缘,这是因为系统的其它部分也在使用缓存,我们的测试程序并不能独占缓存的使用。尤其是L2,它是统一式的缓存,处理器的指令也会使用它(注: Intel使用的是包容式缓存)。
What is perhaps not quite expected are the actual times for the different working set sizes. The times for the L1d hits are expected: load times after an L1d hit are around 4 cycles on the P4. But what about the L2 accesses? Once the L1d is not sufficient to hold the data one might expect it would take 14 cycles or more per element since this is the access time for the L2. But the results show that only about 9 cycles are required. This discrepancy can be explained by the advanced logic in the processors. In anticipation of using consecutive memory regions, the processor prefetches the next cache line. This means that when the next line is actually used it is already halfway loaded. The delay required to wait for the next cache line to be loaded is therefore much less than the L2 access time.
The effect of prefetching is even more visible once the working set size grows beyond the L2 size. Before we said that a main memory access takes 200+ cycles. Only with effective prefetching is it possible for the processor to keep the access times as low as 9 cycles. As we can see from the difference between 200 and 9, this works out nicely.
We can observe the processor while prefetching, at least indirectly. In Figure 3.11 we see the times for the same working set sizes but this time we see the graphs for different sizes of the structurel. This means we have fewer but larger elements in the list. The different sizes have the effect that the distance between thenelements in the (still consecutive) list grows. In the four cases of the graph the distance is 0, 56, 120, and 248 bytes respectively.
在工作集超过L2的大小之后,预取的效果更明显了。前面我们说过,主存的访问需要耗时200个周期以上。但在预取的帮助下,实际耗时保持在9个周期左右。200 vs 9,效果非常不错。
我们可以观察到预取的行为,至少可以间接地观察到。图3.11中有4条线,它们表示处理不同大小结构时的耗时情况。随着结构的变大,元素间的距离变大了。图中4条线对应的元素距离分别是0、56、120和248字节。
At the bottom we can see the line from the previous graph, but this time it appears more or less as a flat line. The times for the other cases are simply so much worse. We can see in this graph, too, the three different levels and we see the large errors in the tests with the small working set sizes (ignore them again). The lines more or less all match each other as long as only the L1d is involved. There is no prefetching necessary so all element sizes just hit the L1d for each access.
For the L2 cache hits we see that the three new lines all pretty much match each other but that they are at a higher level (about 28). This is the level of the access time for the L2. This means prefetching from L2 into L1d is basically disabled. Even withNPAD=7 we need a new cache line for each iteration of the loop; forNPAD=0, instead, the loop has to iterate eight times before the next cache line is needed. The prefetch logic cannot load a new cache line every cycle. Therefore we see a stall to load from L2 in every iteration.
图中最下面的这一条线来自前一个图,但在这里更像是一条直线。其它三条线的耗时情况比较差。图中这些线也有比较明显的三个阶段,同时,在小工作集的情况下也有比较大的错误(请再次忽略这些错误)。在只使用L1d的阶段,这些线条基本重合。因为这时候还不需要预取,只需要访问L1d就行。
在L2阶段,三条新加的线基本重合,而且耗时比老的那条线高很多,大约在28个周期左右,差不多就是L2的访问时间。这表明,从L2到L1d的预取并没有生效。这是因为,对于最下面的线(NPAD=0),由于结构小,8次循环后才需要访问一条新缓存线,而上面三条线对应的结构比较大,拿相对最小的NPAD=7来说,光是一次循环就需要访问一条新线,更不用说更大的NPAD=15和31了。而预取逻辑是无法在每个周期装载新线的,因此每次循环都需要从L2读取,我们看到的就是从L2读取的时延。
It gets even more interesting once the working set size exceeds the L2 capacity. Now all four lines vary widely. The different element sizes play obviously a big role in the difference in performance. The processor should recognize the size of the strides and not fetch unnecessary cache lines forNPAD=15 and 31 since the element size is smaller than the prefetch window (see Section 6.3.1). Where the element size is hampering the prefetching efforts is a result of a limitation of hardware prefetching: it cannot cross page boundaries. We are reducing the effectiveness of the hardware scheduler by 50% for each size increase. If the hardware prefetcher were allowed to cross page boundaries and the next page is not resident or valid the OS would have to get involved in locating the page. That means the program would experience a page fault it did not initiate itself. This is completely unacceptable since the processor does not know whether a page is not present or does not exist. In the latter case the OS would have to abort the process. In any case, given that, forNPAD=7 and higher, we need one cache line per list element the hardware prefetcher cannot do much. There simply is no time to load the data from memory since all the processor does is read one word and then load the next element.
Another big reason for the slowdown are the misses of the TLB cache. This is a cache where the results of the translation of a virtual address to a physical address are stored, as is explained in more detail in Section 4. The TLB cache is quite small since it has to be extremely fast. If more pages are accessed repeatedly than the TLB cache has entries for the translation from virtual to physical address has to be constantly repeated. This is a very costly operation. With larger element sizes the cost of a TLB lookup is amortized over fewer elements. That means the total number of TLB entries which have to be computed per list element is higher.
To observe the TLB effects we can run a different test. For one measurement we lay out the elements sequentially as usual. We useNPAD=7 for elements which occupy one entire cache line. For the second measurement we place each list element on a separate page. The rest of each page is left untouched and we do not count it in the total for the working set size. {Yes, this is a bit inconsistent because in the other tests we count the unused part of the struct in the element size and we could defineNPADso that each element fills a page. In that case the working set sizes would be very different. This is not the point of this test, though, and since prefetching is ineffective anyway this makes little difference.} The consequence is that, for the first measurement, each list iteration requires a new cache line and, for every 64 elements, a new page. For the second measurement each iteration requires loading a new cache line which is on a new page.
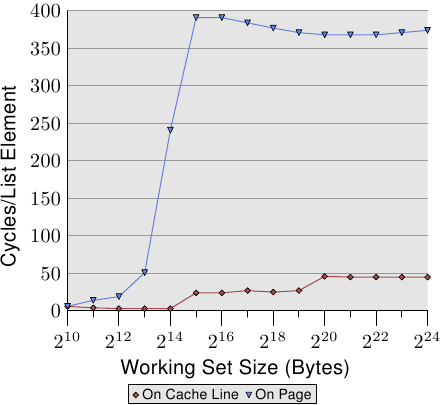
Figure 3.12: TLB Influence for Sequential Read
为了观察TLB的性能,我们可以进行另两项测试。第一项:我们还是顺序存储列表中的元素,使NPAD=7,让每个元素占满整个cache line,第二项:我们将列表的每个元素存储在一个单独的页上,忽略每个页没有使用的部分以用来计算工作集的大小。(这样做可能不太一致,因为在前面的测试中,我计算了结构体中每个元素没有使用的部分,从而用来定义NPAD的大小,因此每个元素占满了整个页,这样以来工作集的大小将会有所不同。但是这不是这项测试的重点,预取的低效率多少使其有点不同)。结果表明,第一项测试中,每次列表的迭代都需要一个新的cache line,而且每64个元素就需要一个新的页。第二项测试中,每次迭代都会在一个新的页中加载一个新的cache line。
图 3.12: TLB 对顺序读的影响
As can be seen the number of cycles it takes to compute the physical address and store it in the TLB is very high. The graph in Figure 3.12 shows the extreme case, but it should now be clear that a significant factor in the slowdown for largerNPADvalues is the reduced efficiency of the TLB cache. Since the physical address has to be computed before a cache line can be read for either L2 or main memory the address translation penalties are additive to the memory access times. This in part explains why the total cost per list element forNPAD=31 is higher than the theoretical access time for the RAM.
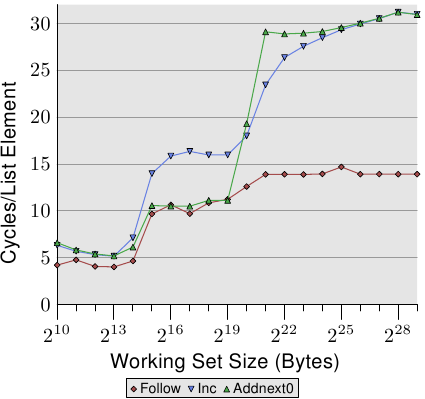
Figure 3.13: Sequential Read and Write, NPAD=1
We can glimpse a few more details of the prefetch implementation by looking at the data of test runs where the list elements are modified. Figure 3.13 shows three lines. The element width is in all cases 16 bytes. The first line is the now familiar list walk which serves as a baseline. The second line, labeled “Inc”, simply increments thepad[0]member of the current element before going on to the next. The third line, labeled “Addnext0”, takes thepad[0]list element of the next element and adds it to thepad[0]member of the current list element.
可以看出,计算物理地址并把它存储在TLB中所花费的周期数量级是非常高的。图3.12的表格显示了一个极端的例子,但从中可以清楚的得到:TLB缓存效率降低的一个重要因素是大型NPAD值的减缓。由于物理地址必须在缓存行能被L2或主存读取之前计算出来,地址转换这个不利因素就增加了内存访问时间。这一点部分解释了为什么NPAD等于31时每个列表元素的总花费比理论上的RAM访问时间要高。
图3.13 NPAD等于1时的顺序读和写
通过查看链表元素被修改时测试数据的运行情况,我们可以窥见一些更详细的预取实现细节。图3.13显示了三条曲线。所有情况下元素宽度都为16个字节。第一条曲线“Follow”是熟悉的链表走线在这里作为基线。第二条曲线,标记为“Inc”,仅仅在当前元素进入下一个前给其增加thepad[0]成员。第三条曲线,标记为"Addnext0", 取出下一个元素的thepad[0]链表元素并把它添加为当前链表元素的thepad[0]成员。
The naïve assumption would be that the “Addnext0” test runs slower because it has more work to do. Before advancing to the next list element a value from that element has to be loaded. This is why it is surprising to see that this test actually runs, for some working set sizes, faster than the “Inc” test. The explanation for this is that the load from the next list element is basically a forced prefetch. Whenever the program advances to the next list element we know for sure that element is already in the L1d cache. As a result we see that the “Addnext0” performs as well as the simple “Follow” test as long as the working set size fits into the L2 cache.
The “Addnext0” test runs out of L2 faster than the “Inc” test, though. It needs more data loaded from main memory. This is why the “Addnext0” test reaches the 28 cycles level for a working set size of 221 bytes. The 28 cycles level is twice as high as the 14 cycles level the “Follow” test reaches. This is easy to explain, too. Since the other two tests modify memory an L2 cache eviction to make room for new cache lines cannot simply discard the data. Instead it has to be written to memory. This means the available bandwidth on the FSB is cut in half, hence doubling the time it takes to transfer the data from main memory to L2.
在没运行时,大家可能会以为"Addnext0"更慢,因为它要做的事情更多——在没进到下个元素之前就需要装载它的值。但实际的运行结果令人惊讶——在某些小工作集下,"Addnext0"比"Inc"更快。这是为什么呢?原因在于,系统一般会对下一个元素进行强制性预取。当程序前进到下个元素时,这个元素其实早已被预取在L1d里。因此,只要工作集比L2小,"Addnext0"的性能基本就能与"Follow"测试媲美。
但是,"Addnext0"比"Inc"更快离开L2,这是因为它需要从主存装载更多的数据。而在工作集达到2 21字节时,"Addnext0"的耗时达到了28个周期,是同期"Follow"14周期的两倍。这个两倍也很好解释。"Addnext0"和"Inc"涉及对内存的修改,因此L2的逐出操作不能简单地把数据一扔了事,而必须将它们写入内存。因此FSB的可用带宽变成了一半,传输等量数据的耗时也就变成了原来的两倍。
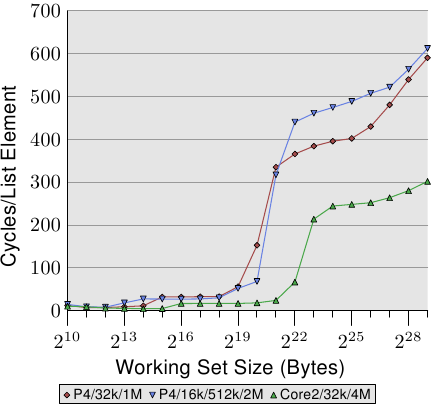
Figure 3.14: Advantage of Larger L2/L3 Caches
One last aspect of the sequential, efficient cache handling is the size of the cache. This should be obvious but it still should be pointed out. Figure 3.14 shows the timing for the Increment benchmark with 128-byte elements (NPAD=15 on 64-bit machines). This time we see the measurement from three different machines. The first two machines are P4s, the last one a Core2 processor. The first two differentiate themselves by having different cache sizes. The first processor has a 32k L1d and an 1M L2. The second one has 16k L1d, 512k L2, and 2M L3. The Core2 processor has 32k L1d and 4M L2.
图3.14: 更大L2/L3缓存的优势
决定顺序式缓存处理性能的另一个重要因素是缓存容量。虽然这一点比较明显,但还是值得一说。图3.14展示了128字节长元素的测试结果(64位机,NPAD=15)。这次我们比较三台不同计算机的曲线,两台P4,一台Core 2。两台P4的区别是缓存容量不同,一台是32k的L1d和1M的L2,一台是16K的L1d、512k的L2和2M的L3。Core 2那台则是32k的L1d和4M的L2。
The interesting part of the graph is not necessarily how well the Core2 processor performs relative to the other two (although it is impressive). The main point of interest here is the region where the working set size is too large for the respective last level cache and the main memory gets heavily involved.
| Set Size | Sequential | Random | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| L2 Hit | L2 Miss | #Iter | Ratio Miss/Hit | L2 Accesses Per Iter | L2 Hit | L2 Miss | #Iter | Ratio Miss/Hit | L2 Accesses Per Iter | |
| 220 | 88,636 | 843 | 16,384 | 0.94% | 5.5 | 30,462 | 4721 | 1,024 | 13.42% | 34.4 |
| 221 | 88,105 | 1,584 | 8,192 | 1.77% | 10.9 | 21,817 | 15,151 | 512 | 40.98% | 72.2 |
| 222 | 88,106 | 1,600 | 4,096 | 1.78% | 21.9 | 22,258 | 22,285 | 256 | 50.03% | 174.0 |
| 223 | 88,104 | 1,614 | 2,048 | 1.80% | 43.8 | 27,521 | 26,274 | 128 | 48.84% | 420.3 |
| 224 | 88,114 | 1,655 | 1,024 | 1.84% | 87.7 | 33,166 | 29,115 | 64 | 46.75% | 973.1 |
| 225 | 88,112 | 1,730 | 512 | 1.93% | 175.5 | 39,858 | 32,360 | 32 | 44.81% | 2,256.8 |
| 226 | 88,112 | 1,906 | 256 | 2.12% | 351.6 | 48,539 | 38,151 | 16 | 44.01% | 5,418.1 |
| 227 | 88,114 | 2,244 | 128 | 2.48% | 705.9 | 62,423 | 52,049 | 8 | 45.47% | 14,309.0 |
| 228 | 88,120 | 2,939 | 64 | 3.23% | 1,422.8 | 81,906 | 87,167 | 4 | 51.56% | 42,268.3 |
| 229 | 88,137 | 4,318 | 32 | 4.67% | 2,889.2 | 119,079 | 163,398 | 2 | 57.84% | 141,238.5 |
Table 3.2: L2 Hits and Misses for Sequential and Random Walks, NPAD=0
As expected, the larger the last level cache is the longer the curve stays at the low level corresponding to the L2 access costs. The important part to notice is the performance advantage this provides. The second processor (which is slightly older) can perform the work on the working set of 220 bytes twice as fast as the first processor. All thanks to the increased last level cache size. The Core2 processor with its 4M L2 performs even better.
图中最有趣的地方,并不是Core 2如何大胜两台P4,而是工作集开始增长到连末级缓存也放不下、需要主存热情参与之后的部分。
| Set Size | Sequential | Random | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| L2 Hit | L2 Miss | #Iter | Ratio Miss/Hit | L2 Accesses Per Iter | L2 Hit | L2 Miss | #Iter | Ratio Miss/Hit | L2 Accesses Per Iter | |
| 220 | 88,636 | 843 | 16,384 | 0.94% | 5.5 | 30,462 | 4721 | 1,024 | 13.42% | 34.4 |
| 221 | 88,105 | 1,584 | 8,192 | 1.77% | 10.9 | 21,817 | 15,151 | 512 | 40.98% | 72.2 |
| 222 | 88,106 | 1,600 | 4,096 | 1.78% | 21.9 | 22,258 | 22,285 | 256 | 50.03% | 174.0 |
| 223 | 88,104 | 1,614 | 2,048 | 1.80% | 43.8 | 27,521 | 26,274 | 128 | 48.84% | 420.3 |
| 224 | 88,114 | 1,655 | 1,024 | 1.84% | 87.7 | 33,166 | 29,115 | 64 | 46.75% | 973.1 |
| 225 | 88,112 | 1,730 | 512 | 1.93% | 175.5 | 39,858 | 32,360 | 32 | 44.81% | 2,256.8 |
| 226 | 88,112 | 1,906 | 256 | 2.12% | 351.6 | 48,539 | 38,151 | 16 | 44.01% | 5,418.1 |
| 227 | 88,114 | 2,244 | 128 | 2.48% | 705.9 | 62,423 | 52,049 | 8 | 45.47% | 14,309.0 |
| 228 | 88,120 | 2,939 | 64 | 3.23% | 1,422.8 | 81,906 | 87,167 | 4 | 51.56% | 42,268.3 |
| 229 | 88,137 | 4,318 | 32 | 4.67% | 2,889.2 | 119,079 | 163,398 | 2 | 57.84% | 141,238.5 |
表3.2: 顺序访问与随机访问时L2命中与未命中的情况,NPAD=0
与我们预计的相似,最末级缓存越大,曲线停留在L2访问耗时区的时间越长。在220字节的工作集时,第二台P4(更老一些)比第一台P4要快上一倍,这要完全归功于更大的末级缓存。而Core 2拜它巨大的4M L2所赐,表现更为卓越。
For a random workload this might not mean that much. But if the workload can be tailored to the size of the last level cache the program performance can be increased quite dramatically. This is why it sometimes is worthwhile to spend the extra money for a processor with a larger cache.
Single Threaded Random Access Measurements
We have seen that the processor is able to hide most of the main memory and even L2 access latency by prefetching cache lines into L2 and L1d. This can work well only when the memory access is predictable, though.
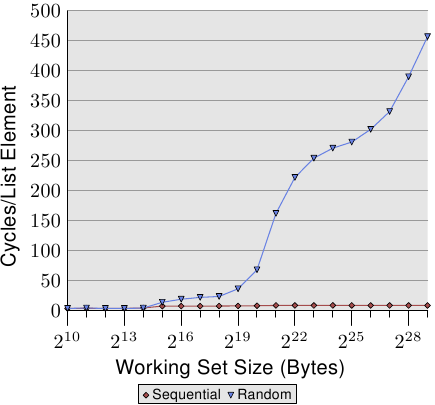
Figure 3.15: Sequential vs Random Read, NPAD=0
If the access is unpredictable or random the situation is quite different. Figure 3.15 compares the per-list-element times for the sequential access (same as in Figure 3.10) with the times when the list elements are randomly distributed in the working set. The order is determined by the linked list which is randomized. There is no way for the processor to reliably prefetch data. This can only work by chance if elements which are used shortly after one another are also close to each other in memory.
对于随机的工作负荷而言,可能没有这么惊人的效果,但是,如果我们能将工作负荷进行一些裁剪,让它匹配末级缓存的容量,就完全可以得到非常大的性能提升。也是由于这个原因,有时候我们需要多花一些钱,买一个拥有更大缓存的处理器。
单线程随机访问模式的测量
前面我们已经看到,处理器能够利用L1d到L2之间的预取消除访问主存、甚至是访问L2的时延。
图3.15: 顺序读取vs随机读取,NPAD=0
但是,如果换成随机访问或者不可预测的访问,情况就大不相同了。图3.15比较了顺序读取与随机读取的耗时情况。
换成随机之后,处理器无法再有效地预取数据,只有少数情况下靠运气刚好碰到先后访问的两个元素挨在一起的情形。
There are two important points to note in Figure 3.15. First, the large number is cycles needed for growing working set sizes. The machine makes it possible to access the main memory in 200-300 cycles but here we reach 450 cycles and more. We have seen this phenomenon before (compare Figure 3.11). The automatic prefetching is actually working to a disadvantage here.
The second interesting point is that the curve is not flattening at various plateaus as it has been for the sequential access cases. The curve keeps on rising. To explain this we can measure the L2 access of the program for the various working set sizes. The result can be seen in Figure 3.16 and Table 3.2.
图3.15中有两个需要关注的地方。首先,在大的工作集下需要非常多的周期。这台机器访问主存的时间大约为200-300个周期,但图中的耗时甚至超过了450个周期。我们前面已经观察到过类似现象(对比图3.11)。这说明,处理器的自动预取在这里起到了反效果。
其次,代表随机访问的曲线在各个阶段不像顺序访问那样保持平坦,而是不断攀升。为了解释这个问题,我们测量了程序在不同工作集下对L2的访问情况。结果如图3.16和表3.2。
The figure shows that, when the working set size is larger than the L2 size, the cache miss ratio (L2 misses / L2 access) starts to grow. The curve has a similar form to the one in Figure 3.15: it rises quickly, declines slightly, and starts to rise again. There is a strong correlation with the cycles per list element graph. The L2 miss rate will grow until it eventually reaches close to 100%. Given a large enough working set (and RAM) the probability that any of the randomly picked cache lines is in L2 or is in the process of being loaded can be reduced arbitrarily.
The increasing cache miss rate alone explains some of the costs. But there is another factor. Looking at Table 3.2 we can see in the L2/#Iter columns that the total number of L2 uses per iteration of the program is growing. Each working set is twice as large as the one before. So, without caching we would expect double the main memory accesses. With caches and (almost) perfect predictability we see the modest increase in the L2 use shown in the data for sequential access. The increase is due to the increase of the working set size and nothing else.
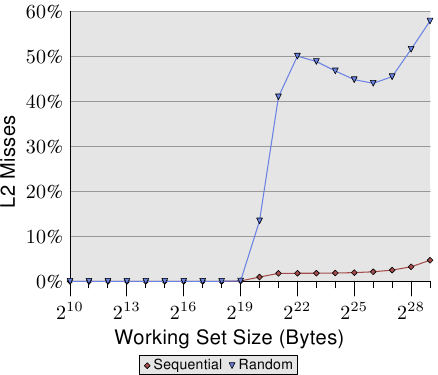
Figure 3.16: L2d Miss Ratio
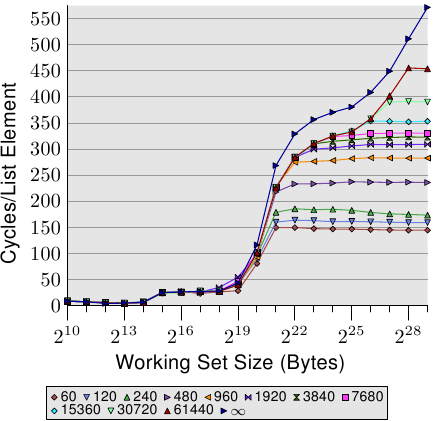
Figure 3.17: Page-Wise Randomization, NPAD=7
从图中可以看出,当工作集大小超过L2时,未命中率(L2未命中次数/L2访问次数)开始上升。整条曲线的走向与图3.15有些相似: 先急速爬升,随后缓缓下滑,最后再度爬升。它与耗时图有紧密的关联。L2未命中率会一直爬升到100%为止。只要工作集足够大(并且内存也足够大),就可以将缓存线位于L2内或处于装载过程中的可能性降到非常低。
缓存未命中率的攀升已经可以解释一部分的开销。除此以外,还有一个因素。观察表3.2的L2/#Iter列,可以看到每个循环对L2的使用次数在增长。由于工作集每次为上一次的两倍,如果没有缓存的话,内存的访问次数也将是上一次的两倍。在按顺序访问时,由于缓存的帮助及完美的预见性,对L2使用的增长比较平缓,完全取决于工作集的增长速度。
图3.16: L2d未命中率
图3.17: 页意义上(Page-Wise)的随机化,NPAD=7
The element size forNPAD=7 is 64 bytes, which corresponds to the cache line size. Due to the randomized order of the list elements it is unlikely that the hardware prefetcher has any effect, most certainly not for more than a handful of elements. This means the L2 cache miss rate does not differ significantly from the randomization of the entire list in one block. The performance of the test with increasing block size approaches asymptotically the curve for the one-block randomization. This means the performance of this latter test case is significantly influenced by the TLB misses. If the TLB misses can be lowered the performance increases significantly (in one test we will see later up to 38%).
3.3.3 Write Behavior
Before we start looking at the cache behavior when multiple execution contexts (threads or processes) use the same memory we have to explore a detail of cache implementations. Caches are supposed to be coherent and this coherency is supposed to be completely transparent for the userlevel code. Kernel code is a different story; it occasionally requires cache flushes.
This specifically means that, if a cache line is modified, the result for the system after this point in time is the same as if there were no cache at all and the main memory location itself had been modified. This can be implemented in two ways or policies:
- write-through cache implementation;
- write-back cache implementation.
3.3.3 写入时的行为
在我们开始研究多个线程或进程同时使用相同内存之前,先来看一下缓存实现的一些细节。我们要求缓存是一致的,而且这种一致性必须对用户级代码完全透明。而内核代码则有所不同,它有时候需要对缓存进行转储(flush)。
这意味着,如果对缓存线进行了修改,那么在这个时间点之后,系统的结果应该是与没有缓存的情况下是相同的,即主存的对应位置也已经被修改的状态。这种要求可以通过两种方式或策略实现:
- 写通(write-through)
- 写回(write-back)
The write-back policy is more sophisticated. Here the processor does not immediately write the modified cache line back to main memory. Instead, the cache line is only marked as dirty. When the cache line is dropped from the cache at some point in the future the dirty bit will instruct the processor to write the data back at that time instead of just discarding the content.
写通比较简单。当修改缓存线时,处理器立即将它写入主存。这样可以保证主存与缓存的内容永远保持一致。当缓存线被替代时,只需要简单地将它丢弃即可。这种策略很简单,但是速度比较慢。如果某个程序反复修改一个本地变量,可能导致FSB上产生大量数据流,而不管这个变量是不是有人在用,或者是不是短期变量。
写回比较复杂。当修改缓存线时,处理器不再马上将它写入主存,而是打上已弄脏(dirty)的标记。当以后某个时间点缓存线被丢弃时,这个已弄脏标记会通知处理器把数据写回到主存中,而不是简单地扔掉。
Write-back caches have the chance to be significantly better performing, which is why most memory in a system with a decent processor is cached this way. The processor can even take advantage of free capacity on the FSB to store the content of a cache line before the line has to be evacuated. This allows the dirty bit to be cleared and the processor can just drop the cache line when the room in the cache is needed.
But there is a significant problem with the write-back implementation. When more than one processor (or core or hyper-thread) is available and accessing the same memory it must still be assured that both processors see the same memory content at all times. If a cache line is dirty on one processor (i.e., it has not been written back yet) and a second processor tries to read the same memory location, the read operation cannot just go out to the main memory. Instead the content of the first processor's cache line is needed. In the next section we will see how this is currently implemented.
写回有时候会有非常不错的性能,因此较好的系统大多采用这种方式。采用写回时,处理器们甚至可以利用FSB的空闲容量来存储缓存线。这样一来,当需要缓存空间时,处理器只需清除脏标记,丢弃缓存线即可。
但写回也有一个很大的问题。当有多个处理器(或核心、超线程)访问同一块内存时,必须确保它们在任何时候看到的都是相同的内容。如果缓存线在其中一个处理器上弄脏了(修改了,但还没写回主存),而第二个处理器刚好要读取同一个内存地址,那么这个读操作不能去读主存,而需要读第一个处理器的缓存线。在下一节中,我们将研究如何实现这种需求。
Before we get to this there are two more cache policies to mention:
- write-combining; and
- uncacheable.
Both these policies are used for special regions of the address space which are not backed by real RAM. The kernel sets up these policies for the address ranges (on x86 processors using the Memory Type Range Registers, MTRRs) and the rest happens automatically. The MTRRs are also usable to select between write-through and write-back policies.
Write-combining is a limited caching optimization more often used for RAM on devices such as graphics cards. Since the transfer costs to the devices are much higher than the local RAM access it is even more important to avoid doing too many transfers. Transferring an entire cache line just because a word in the line has been written is wasteful if the next operation modifies the next word. One can easily imagine that this is a common occurrence, the memory for horizontal neighboring pixels on a screen are in most cases neighbors, too. As the name suggests, write-combining combines multiple write accesses before the cache line is written out. In ideal cases the entire cache line is modified word by word and, only after the last word is written, the cache line is written to the device. This can speed up access to RAM on devices significantly.
在此之前,还有其它两种缓存策略需要提一下:
- 写入合并
- 不可缓存
这两种策略用于真实内存不支持的特殊地址区,内核为地址区设置这些策略(x86处理器利用内存类型范围寄存器MTRR),余下的部分自动进行。MTRR还可用于写通和写回策略的选择。
写入合并是一种有限的缓存优化策略,更多地用于显卡等设备之上的内存。由于设备的传输开销比本地内存要高的多,因此避免进行过多的传输显得尤为重要。如果仅仅因为修改了缓存线上的一个字,就传输整条线,而下个操作刚好是修改线上的下一个字,那么这次传输就过于浪费了。而这恰恰对于显卡来说是比较常见的情形——屏幕上水平邻接的像素往往在内存中也是靠在一起的。顾名思义,写入合并是在写出缓存线前,先将多个写入访问合并起来。在理想的情况下,缓存线被逐字逐字地修改,只有当写入最后一个字时,才将整条线写入内存,从而极大地加速内存的访问。
Finally there is uncacheable memory. This usually means the memory location is not backed by RAM at all. It might be a special address which is hardcoded to have some functionality outside the CPU. For commodity hardware this most often is the case for memory mapped address ranges which translate to accesses to cards and devices attached to a bus (PCIe etc). On embedded boards one sometimes finds such a memory address which can be used to turn an LED on and off. Caching such an address would obviously be a bad idea. LEDs in this context are used for debugging or status reports and one wants to see this as soon as possible. The memory on PCIe cards can change without the CPU's interaction, so this memory should not be cached.
3.3.4 Multi-Processor Support
In the previous section we have already pointed out the problem we have when multiple processors come into play. Even multi-core processors have the problem for those cache levels which are not shared (at least the L1d).
It is completely impractical to provide direct access from one processor to the cache of another processor. The connection is simply not fast enough, for a start. The practical alternative is to transfer the cache content over to the other processor in case it is needed. Note that this also applies to caches which are not shared on the same processor.
3.3.4 多处理器支持
在上节中我们已经指出当多处理器开始发挥作用的时候所遇到的问题。甚至对于那些不共享的高速级别的缓存(至少在L1d级别)的多核处理器也有问题。
直接提供从一个处理器到另一处理器的高速访问,这是完全不切实际的。从一开始,连接速度根本就不够快。实际的选择是,在其需要的情况下,转移到其他处理器。需要注意的是,这同样应用在相同处理器上无需共享的高速缓存。
The question now is when does this cache line transfer have to happen? This question is pretty easy to answer: when one processor needs a cache line which is dirty in another processor's cache for reading or writing. But how can a processor determine whether a cache line is dirty in another processor's cache? Assuming it is just because a cache line is loaded by another processor would be suboptimal (at best). Usually the majority of memory accesses are read accesses and the resulting cache lines are not dirty. Processor operations on cache lines are frequent (of course, why else would we have this paper?) which means broadcasting information about changed cache lines after each write access would be impractical.
What developed over the years is the MESI cache coherency protocol (Modified, Exclusive, Shared, Invalid). The protocol is named after the four states a cache line can be in when using the MESI protocol:
- Modified: The local processor has modified the cache line. This also implies it is the only copy in any cache.
- Exclusive: The cache line is not modified but known to not be loaded into any other processor's cache.
- Shared: The cache line is not modified and might exist in another processor's cache.
- Invalid: The cache line is invalid, i.e., unused.
This protocol developed over the years from simpler versions which were less complicated but also less efficient. With these four states it is possible to efficiently implement write-back caches while also supporting concurrent use of read-only data on different processors.
多年来,人们开发除了MESI缓存一致性协议(MESI=Modified, Exclusive, Shared, Invalid,变更的、独占的、共享的、无效的)。协议的名称来自协议中缓存线可以进入的四种状态:
- 变更的: 本地处理器修改了缓存线。同时暗示,它是所有缓存中唯一的拷贝。
- 独占的: 缓存线没有被修改,而且没有被装入其它处理器缓存。
- 共享的: 缓存线没有被修改,但可能已被装入其它处理器缓存。
- 无效的: 缓存线无效,即,未被使用。
MESI协议开发了很多年,最初的版本比较简单,但是效率也比较差。现在的版本通过以上4个状态可以有效地实现写回式缓存,同时支持不同处理器对只读数据的并发访问。
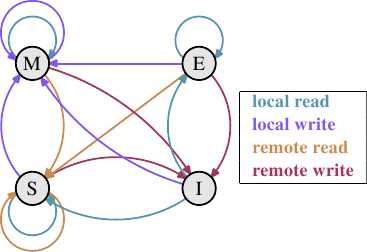
Figure 3.18: MESI Protocol Transitions
The state changes are accomplished without too much effort by the processors listening, or snooping, on the other processors' work. Certain operations a processor performs are announced on external pins and thus make the processor's cache handling visible to the outside. The address of the cache line in question is visible on the address bus. In the following description of the states and their transitions (shown in Figure 3.18) we will point out when the bus is involved.
Initially all cache lines are empty and hence also Invalid. If data is loaded into the cache for writing the cache changes to Modified. If the data is loaded for reading the new state depends on whether another processor has the cache line loaded as well. If this is the case then the new state is Shared, otherwise Exclusive.
图3.18: MESI协议的状态跃迁图
在协议中,通过处理器监听其它处理器的活动,不需太多努力即可实现状态变更。处理器将操作发布在外部引脚上,使外部可以了解到处理过程。目标的缓存线地址则可以在地址总线上看到。在下文讲述状态时,我们将介绍总线参与的时机。
一开始,所有缓存线都是空的,缓存为无效(Invalid)状态。当有数据装进缓存供写入时,缓存变为变更(Modified)状态。如果有数据装进缓存供读取,那么新状态取决于其它处理器是否已经状态了同一条缓存线。如果是,那么新状态变成共享(Shared)状态,否则变成独占(Exclusive)状态。
If a Modified cache line is read from or written to on the local processor, the instruction can use the current cache content and the state does not change. If a second processor wants to read from the cache line the first processor has to send the content of its cache to the second processor and then it can change the state to Shared. The data sent to the second processor is also received and processed by the memory controller which stores the content in memory. If this did not happen the cache line could not be marked as Shared. If the second processor wants to write to the cache line the first processor sends the cache line content and marks the cache line locally as Invalid. This is the infamous “Request For Ownership” (RFO) operation. Performing this operation in the last level cache, just like the I→M transition is comparatively expensive. For write-through caches we also have to add the time it takes to write the new cache line content to the next higher-level cache or the main memory, further increasing the cost.
If a cache line is in the Shared state and the local processor reads from it no state change is necessary and the read request can be fulfilled from the cache. If the cache line is locally written to the cache line can be used as well but the state changes to Modified. It also requires that all other possible copies of the cache line in other processors are marked as Invalid. Therefore the write operation has to be announced to the other processors via an RFO message. If the cache line is requested for reading by a second processor nothing has to happen. The main memory contains the current data and the local state is already Shared. In case a second processor wants to write to the cache line (RFO) the cache line is simply marked Invalid. No bus operation is needed.
The Exclusive state is mostly identical to the Shared state with one crucial difference: a local write operation does not have to be announced on the bus. The local cache copy is known to be the only one. This can be a huge advantage so the processor will try to keep as many cache lines as possible in the Exclusive state instead of the Shared state. The latter is the fallback in case the information is not available at that moment. The Exclusive state can also be left out completely without causing functional problems. It is only the performance that will suffer since the E→M transition is much faster than the S→M transition.
From this description of the state transitions it should be clear where the costs specific to multi-processor operations are. Yes, filling caches is still expensive but now we also have to look out for RFO messages. Whenever such a message has to be sent things are going to be slow.
Exclusive状态与Shared状态很像,只有一个不同之处: 在Exclusive状态时,本地写入操作不需要在总线上声明,因为本地的缓存是系统中唯一的拷贝。这是一个巨大的优势,所以处理器会尽量将缓存线保留在Exclusive状态,而不是Shared状态。只有在信息不可用时,才退而求其次选择shared。放弃Exclusive不会引起任何功能缺失,但会导致性能下降,因为E→M要远远快于S→M。
从以上的说明中应该已经可以看出,在多处理器环境下,哪一步的代价比较大了。填充缓存的代价当然还是很高,但我们还需要留意RFO消息。一旦涉及RFO,操作就快不起来了。
There are two situations when RFO messages are necessary:
- A thread is migrated from one processor to another and all the cache lines have to be moved over to the new processor once.
- A cache line is truly needed in two different processors. {At a smaller level the same is true for two cores on the same processor. The costs are just a bit smaller. The RFO message is likely to be sent many times.}
In multi-thread or multi-process programs there is always some need for synchronization; this synchronization is implemented using memory. So there are some valid RFO messages. They still have to be kept as infrequent as possible. There are other sources of RFO messages, though. In Section 6 we will explain these scenarios. The Cache coherency protocol messages must be distributed among the processors of the system. A MESI transition cannot happen until it is clear that all the processors in the system have had a chance to reply to the message. That means that the longest possible time a reply can take determines the speed of the coherency protocol. {Which is why we see nowadays, for instance, AMD Opteron systems with three sockets. Each processor is exactly one hop away given that the processors only have three hyperlinks and one is needed for the Southbridge connection.} Collisions on the bus are possible, latency can be high in NUMA systems, and of course sheer traffic volume can slow things down. All good reasons to focus on avoiding unnecessary traffic.
RFO在两种情况下是必需的:
- 线程从一个处理器迁移到另一个处理器,需要将所有缓存线移到新处理器。
- 某条缓存线确实需要被两个处理器使用。{对于同一处理器的两个核心,也有同样的情况,只是代价稍低。RFO消息可能会被发送多次。}
多线程或多进程的程序总是需要同步,而这种同步依赖内存来实现。因此,有些RFO消息是合理的,但仍然需要尽量降低发送频率。除此以外,还有其它来源的RFO。在第6节中,我们将解释这些场景。缓存一致性协议的消息必须发给系统中所有处理器。只有当协议确定已经给过所有处理器响应机会之后,才能进行状态跃迁。也就是说,协议的速度取决于最长响应时间。{这也是现在能看到三插槽AMD Opteron系统的原因。这类系统只有三个超级链路(hyperlink),其中一个连接南桥,每个处理器之间都只有一跳的距离。}总线上可能会发生冲突,NUMA系统的延时很大,突发的流量会拖慢通信。这些都是让我们避免无谓流量的充足理由。
There is one more problem related to having more than one processor in play. The effects are highly machine specific but in principle the problem always exists: the FSB is a shared resource. In most machines all processors are connected via one single bus to the memory controller (see Figure 2.1). If a single processor can saturate the bus (as is usually the case) then two or four processors sharing the same bus will restrict the bandwidth available to each processor even more.
Even if each processor has its own bus to the memory controller as in Figure 2.2 there is still the bus to the memory modules. Usually this is one bus but, even in the extended model in Figure 2.2, concurrent accesses to the same memory module will limit the bandwidth.
The same is true with the AMD model where each processor can have local memory. Yes, all processors can concurrently access their local memory quickly. But multi-thread and multi-process programs--at least from time to time--have to access the same memory regions to synchronize.
此外,关于多处理器还有一个问题。虽然它的影响与具体机器密切相关,但根源是唯一的——FSB是共享的。在大多数情况下,所有处理器通过唯一的总线连接到内存控制器(参见图2.1)。如果一个处理器就能占满总线(十分常见),那么共享总线的两个或四个处理器显然只会得到更有限的带宽。
即使每个处理器有自己连接内存控制器的总线,如图2.2,但还需要通往内存模块的总线。一般情况下,这种总线只有一条。退一步说,即使像图2.2那样不止一条,对同一个内存模块的并发访问也会限制它的带宽。
对于每个处理器拥有本地内存的AMD模型来说,也是同样的问题。的确,所有处理器可以非常快速地同时访问它们自己的内存。但是,多线程呢?多进程呢?它们仍然需要通过访问同一块内存来进行同步。
Concurrency is severely limited by the finite bandwidth available for the implementation of the necessary synchronization. Programs need to be carefully designed to minimize accesses from different processors and cores to the same memory locations. The following measurements will show this and the other cache effects related to multi-threaded code.
Multi Threaded Measurements
To ensure that the gravity of the problems introduced by concurrently using the same cache lines on different processors is understood, we will look here at some more performance graphs for the same program we used before. This time, though, more than one thread is running at the same time. What is measured is the fastest runtime of any of the threads. This means the time for a complete run when all threads are done is even higher. The machine used has four processors; the tests use up to four threads. All processors share one bus to the memory controller and there is only one bus to the memory modules.
对同步来说,有限的带宽严重地制约着并发度。程序需要更加谨慎的设计,将不同处理器访问同一块内存的机会降到最低。以下的测试展示了这一点,还展示了与多线程代码相关的其它效果。
多线程测量
为了帮助大家理解问题的严重性,我们来看一些曲线图,主角也是前文的那个程序。只不过这一次,我们运行多个线程,并测量这些线程中最快那个的运行时间。也就是说,等它们全部运行完是需要更长时间的。我们用的机器有4个处理器,而测试是做多跑4个线程。所有处理器共享同一条通往内存控制器的总线,另外,通往内存模块的总线也只有一条。
Figure 3.19: Sequential Read Access, Multiple Threads
Figure 3.19 shows the performance for sequential read-only access for 128 bytes entries (NPAD=15 on 64-bit machines). For the curve for one thread we can expect a curve similar to Figure 3.11. The measurements are for a different machine so the actual numbers vary.
The important part in this figure is of course the behavior when running multiple threads. Note that no memory is modified and no attempts are made to keep the threads in sync when walking the linked list. Even though no RFO messages are necessary and all the cache lines can be shared, we see up to an 18% performance decrease for the fastest thread when two threads are used and up to 34% when four threads are used. Since no cache lines have to be transported between the processors this slowdown is solely caused by one or both of the two bottlenecks: the shared bus from the processor to the memory controller and bus from the memory controller to the memory modules. Once the working set size is larger than the L3 cache in this machine all three threads will be prefetching new list elements. Even with two threads the available bandwidth is not sufficient to scale linearly (i.e., have no penalty from running multiple threads).
图3.19: 顺序读操作,多线程
图3.19展示了顺序读访问时的性能,元素为128字节长(64位计算机,NPAD=15)。对于单线程的曲线,我们预计是与图3.11相似,只不过是换了一台机器,所以实际的数字会有些小差别。
更重要的部分当然是多线程的环节。由于是只读,不会去修改内存,不会尝试同步。但即使不需要RFO,而且所有缓存线都可共享,性能仍然分别下降了18%(双线程)和34%(四线程)。由于不需要在处理器之间传输缓存,因此这里的性能下降完全由以下两个瓶颈之一或同时引起: 一是从处理器到内存控制器的共享总线,二是从内存控制器到内存模块的共享总线。当工作集超过L3后,三种情况下都要预取新元素,而即使是双线程,可用的带宽也无法满足线性扩展(无惩罚)。
When we modify memory things get even uglier. Figure 3.20 shows the results for the sequential Increment test.
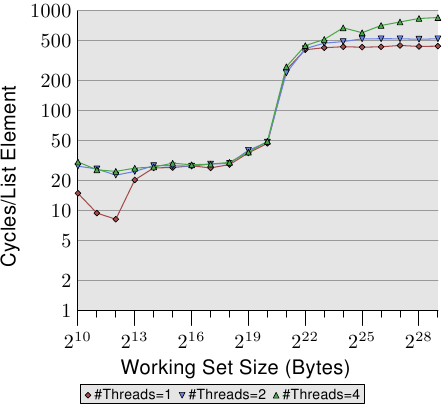
Figure 3.20: Sequential Increment, Multiple Threads
This graph is using a logarithmic scale for the Y axis. So, do not be fooled by the apparently small differences. We still have about a 18% penalty for running two threads and now an amazing 93% penalty for running four threads. This means the prefetch traffic together with the write-back traffic is pretty much saturating the bus when four threads are used.
We use the logarithmic scale to show the results for the L1d range. What can be seen is that, as soon as more than one thread is running, the L1d is basically ineffective. The single-thread access times exceed 20 cycles only when the L1d is not sufficient to hold the working set. When multiple threads are running, those access times are hit immediately, even with the smallest working set sizes.
当加入修改之后,场面更加难看了。图3.20展示了顺序递增测试的结果。
图3.20: 顺序递增,多线程
图中Y轴采用的是对数刻度,不要被看起来很小的差值欺骗了。现在,双线程的性能惩罚仍然是18%,但四线程的惩罚飙升到了93%!原因在于,采用四线程时,预取的流量与写回的流量加在一起,占满了整个总线。
我们用对数刻度来展示L1d范围的结果。可以发现,当超过一个线程后,L1d就无力了。单线程时,仅当工作集超过L1d时访问时间才会超过20个周期,而多线程时,即使在很小的工作集情况下,访问时间也达到了那个水平。
One aspect of the problem is not shown here. It is hard to measure with this specific test program. Even though the test modifies memory and we therefore must expect RFO messages we do not see higher costs for the L2 range when more than one thread is used. The program would have to use a large amount of memory and all threads must access the same memory in parallel. This is hard to achieve without a lot of synchronization which would then dominate the execution time.
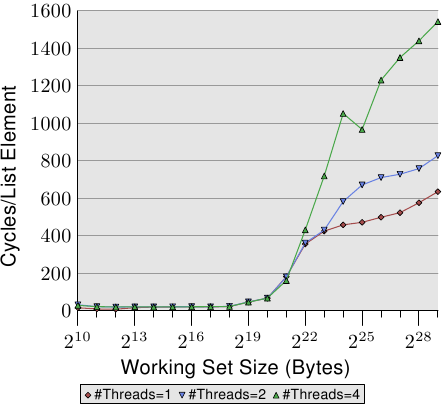
Figure 3.21: Random Addnextlast, Multiple Threads
Finally in Figure 3.21 we have the numbers for the Addnextlast test with random access of memory. This figure is provided mainly to show to the appallingly high numbers. It now take around 1,500 cycles to process a single list element in the extreme case. The use of more threads is even more questionable. We can summarize the efficiency of multiple thread use in a table.
#Threads Seq Read Seq Inc Rand Add 2 1.69 1.69 1.54 4 2.98 2.07 1.65 Table 3.3: Efficiency for Multiple Threads
The table shows the efficiency for the multi-thread run with the largest working set size in the three figures on Figure 3.21. The number shows the best possible speed-up the test program incurs for the largest working set size by using two or four threads. For two threads the theoretical limits for the speed-up are 2 and, for four threads, 4. The numbers for two threads are not that bad. But for four threads the numbers for the last test show that it is almost not worth it to scale beyond two threads. The additional benefit is minuscule. We can see this more easily if we represent the data in Figure 3.21 a bit differently.
这里并没有揭示问题的另一方面,主要是用这个程序很难进行测量。问题是这样的,我们的测试程序修改了内存,所以本应看到RFO的影响,但在结果中,我们并没有在L2阶段看到更大的开销。原因在于,要看到RFO的影响,程序必须使用大量内存,而且所有线程必须同时访问同一块内存。如果没有大量的同步,这是很难实现的,而如果加入同步,则会占满执行时间。
图3.21: 随机的Addnextlast,多线程
最后,在图3.21中,我们展示了随机访问的Addnextlast测试的结果。这里主要是为了让大家感受一下这些巨大到爆的数字。极端情况下,甚至用了1500个周期才处理完一个元素。如果加入更多线程,真是不可想象哪。我们把多线程的效能总结了一下:
表3.3: 多线程的效能
#Threads Seq Read Seq Inc Rand Add 2 1.69 1.69 1.54 4 2.98 2.07 1.65
这个表展示了图3.21中多线程运行大工作集时的效能。表中的数字表示测试程序在使用多线程处理大工作集时可能达到的最大加速因子。双线程和四线程的理论最大加速因子分别是2和4。从表中数据来看,双线程的结果还能接受,但四线程的结果表明,扩展到双线程以上是没有什么意义的,带来的收益可以忽略不计。只要我们把图3.21换个方式呈现,就可以很容易看清这一点。
Figure 3.22: Speed-Up Through Parallelism
The curves in Figure 3.22 show the speed-up factors, i.e., relative performance compared to the code executed by a single thread. We have to ignore the smallest sizes, the measurements are not accurate enough. For the range of the L2 and L3 cache we can see that we indeed achieve almost linear acceleration. We almost reach factors of 2 and 4 respectively. But as soon as the L3 cache is not sufficient to hold the working set the numbers crash. They crash to the point that the speed-up of two and four threads is identical (see the fourth column in Table 3.3). This is one of the reasons why one can hardly find motherboard with sockets for more than four CPUs all using the same memory controller. Machines with more processors have to be built differently (see Section 5).
图3.22: 通过并行化实现的加速因子
图3.22中的曲线展示了加速因子,即多线程相对于单线程所能获取的性能加成值。测量值的精确度有限,因此我们需要忽略比较小的那些数字。可以看到,在L2与L3范围内,多线程基本可以做到线性加速,双线程和四线程分别达到了2和4的加速因子。但是,一旦工作集的大小超出L3,曲线就崩塌了,双线程和四线程降到了基本相同的数值(参见表3.3中第4列)。也是部分由于这个原因,我们很少看到4CPU以上的主板共享同一个内存控制器。如果需要配置更多处理器,我们只能选择其它的实现方式(参见第5节)。
These numbers are not universal. In some cases even working sets which fit into the last level cache will not allow linear speed-ups. In fact, this is the norm since threads are usually not as decoupled as is the case in this test program. On the other hand it is possible to work with large working sets and still take advantage of more than two threads. Doing this requires thought, though. We will talk about some approaches in Section 6.
Special Case: Hyper-Threads
Hyper-Threads (sometimes called Symmetric Multi-Threading, SMT) are implemented by the CPU and are a special case since the individual threads cannot really run concurrently. They all share almost all the processing resources except for the register set. Individual cores and CPUs still work in parallel but the threads implemented on each core are limited by this restriction. In theory there can be many threads per core but, so far, Intel's CPUs at most have two threads per core. The CPU is responsible for time-multiplexing the threads. This alone would not make much sense, though. The real advantage is that the CPU can schedule another hyper-thread when the currently running hyper-thread is delayed. In most cases this is a delay caused by memory accesses.
可惜,上图中的数据并不是普遍情况。在某些情况下,即使工作集能够放入末级缓存,也无法实现线性加速。实际上,这反而是正常的,因为普通的线程都有一定的耦合关系,不会像我们的测试程序这样完全独立。而反过来说,即使是很大的工作集,即使是两个以上的线程,也是可以通过并行化受益的,但是需要程序员的聪明才智。我们会在第6节进行一些介绍。
特例: 超线程
由CPU实现的超线程(有时又叫对称多线程,SMT)是一种比较特殊的情况,每个线程并不能真正并发地运行。它们共享着除寄存器外的绝大多数处理资源。每个核心和CPU仍然是并行工作的,但核心上的线程则受到这个限制。理论上,每个核心可以有大量线程,不过到目前为止,Intel的CPU最多只有两个线程。CPU负责对各线程进行时分复用,但这种复用本身并没有多少厉害。它真正的优势在于,CPU可以在当前运行的超线程发生延迟时,调度另一个线程。这种延迟一般由内存访问引起。
If two threads are running on one hyper-threaded core the program is only more efficient than the single-threaded code if the combined runtime of both threads is lower than the runtime of the single-threaded code. This is possible by overlapping the wait times for different memory accesses which usually would happen sequentially. A simple calculation shows the minimum requirement on the cache hit rate to achieve a certain speed-up.
The execution time for a program can be approximated with a simple model with only one level of cache as follows (see [htimpact]):
T exe = N[(1-F mem)T proc + F mem(G hitT cache + (1-G hit)T miss)]
The meaning of the variables is as follows:
N = Number of instructions. Fmem = Fraction of N that access memory. Ghit = Fraction of loads that hit the cache. Tproc = Number of cycles per instruction. Tcache = Number of cycles for cache hit. Tmiss = Number of cycles for cache miss. Texe = Execution time for program.
如果两个线程运行在一个超线程核心上,那么只有当两个线程合起来的运行时间少于单线程运行时间时,效率才会比较高。我们可以将通常先后发生的内存访问叠合在一起,以实现这个目标。有一个简单的计算公式,可以帮助我们计算如果需要某个加速因子,最少需要多少的缓存命中率。
程序的执行时间可以通过一个只有一级缓存的简单模型来进行估算(参见[htimpact]):
T exe = N[(1-F mem )T proc + F mem (G hit T cache + (1-G hit )T miss )]
各变量的含义如下:
N = 指令数 Fmem = N中访问内存的比例 Ghit = 命中缓存的比例 Tproc = 每条指令所用的周期数 Tcache = 缓存命中所用的周期数 Tmiss = 缓冲未命中所用的周期数 Texe = 程序的执行时间
Figure 3.23: Minimum Cache Hit Rate For Speed-Up
The X–axis represents the cache hit rate Ghit of the single-thread code. The Y–axis shows the required cache hit rate for the multi-threaded code. This value can never be higher than the single-threaded hit rate since, otherwise, the single-threaded code would use that improved code, too. For single-threaded hit rates below 55% the program can in all cases benefit from using threads. The CPU is more or less idle enough due to cache misses to enable running a second hyper-thread.
为了让任何判读使用双线程,两个线程之中任一线程的执行时间最多为单线程指令的一半。两者都有一个唯一的变量缓存命中数。 如果我们要解决最小缓存命中率相等的问题需要使我们获得的线程的执行率不少于50%或更多,如图 3.23.
图 3.23: 最小缓存命中率-加速
X轴表示单线程指令的缓存命中率Ghit,Y轴表示多线程指令所需的缓存命中率。这个值永远不能高于单线程命中率,否则,单线程指令也会使用改良的指令。为了使单线程的命中率在低于55%的所有情况下优于使用多线程,cup要或多或少的足够空闲因为缓存丢失会运行另外一个超线程。
The green area is the target. If the slowdown for the thread is less than 50% and the workload of each thread is halved the combined runtime might be less than the single-thread runtime. For the modeled system here (numbers for a P4 with hyper-threads were used) a program with a hit rate of 60% for the single-threaded code requires a hit rate of at least 10% for the dual-threaded program. That is usually doable. But if the single-threaded code has a hit rate of 95% then the multi-threaded code needs a hit rate of at least 80%. That is harder. Especially, and this is the problem with hyper-threads, because now the effective cache size (L1d here, in practice also L2 and so on) available to each hyper-thread is cut in half. Both hyper-threads use the same cache to load their data. If the working set of the two threads is non-overlapping the original 95% hit rate could also be cut in half and is therefore much lower than the required 80%.
Hyper-Threads are therefore only useful in a limited range of situations. The cache hit rate of the single-threaded code must be low enough that given the equations above and reduced cache size the new hit rate still meets the goal. Then and only then can it make any sense at all to use hyper-threads. Whether the result is faster in practice depends on whether the processor is sufficiently able to overlap the wait times in one thread with execution times in the other threads. The overhead of parallelizing the code must be added to the new total runtime and this additional cost often cannot be neglected.
In Section 6.3.4 we will see a technique where threads collaborate closely and the tight coupling through the common cache is actually an advantage. This technique can be applicable to many situations if only the programmers are willing to put in the time and energy to extend their code.
因此,超线程只在某些情况下才比较有用。单线程代码的缓存命中率必须低到一定程度,从而使缓存容量变小时新的命中率仍能满足要求。只有在这种情况下,超线程才是有意义的。在实践中,采用超线程能否获得更快的结果,取决于处理器能否有效地将每个进程的等待时间与其它进程的执行时间重叠在一起。并行化也需要一定的开销,需要加到总的运行时间里,这个开销往往是不能忽略的。
在6.3.4节中,我们会介绍一种技术,它将多个线程通过公用缓存紧密地耦合起来。这种技术适用于许多场合,前提是程序员们乐意花费时间和精力扩展自己的代码。
What should be clear is that if the two hyper-threads execute completely different code (i.e., the two threads are treated like separate processors by the OS to execute separate processes) the cache size is indeed cut in half which means a significant increase in cache misses. Such OS scheduling practices are questionable unless the caches are sufficiently large. Unless the workload for the machine consists of processes which, through their design, can indeed benefit from hyper-threads it might be best to turn off hyper-threads in the computer's BIOS. {Another reason to keep hyper-threads enabled is debugging. SMT is astonishingly good at finding some sets of problems in parallel code.}
3.3.5 Other Details
So far we talked about the address as consisting of three parts, tag, set index, and cache line offset. But what address is actually used? All relevant processors today provide virtual address spaces to processes, which means that there are two different kinds of addresses: virtual and physical.
The problem with virtual addresses is that they are not unique. A virtual address can, over time, refer to different physical memory addresses. The same address in different process also likely refers to different physical addresses. So it is always better to use the physical memory address, right?
3.3.5 其它细节
我们已经介绍了地址的组成,即标签、集合索引和偏移三个部分。那么,实际会用到什么样的地址呢?目前,处理器一般都向进程提供虚拟地址空间,意味着我们有两种不同的地址: 虚拟地址和物理地址。
虚拟地址有个问题——并不唯一。随着时间的变化,虚拟地址可以变化,指向不同的物理地址。同一个地址在不同的进程里也可以表示不同的物理地址。那么,是不是用物理地址会比较好呢?
The problem here is that instructions use virtual addresses and these have to be translated with the help of the Memory Management Unit (MMU) into physical addresses. This is a non-trivial operation. In the pipeline to execute an instruction the physical address might only be available at a later stage. This means that the cache logic has to be very quick in determining whether the memory location is cached. If virtual addresses could be used the cache lookup can happen much earlier in the pipeline and in case of a cache hit the memory content can be made available. The result is that more of the memory access costs could be hidden by the pipeline.
Processor designers are currently using virtual address tagging for the first level caches. These caches are rather small and can be cleared without too much pain. At least partial clearing the cache is necessary if the page table tree of a process changes. It might be possible to avoid a complete flush if the processor has an instruction which specifies the virtual address range which has changed. Given the low latency of L1i and L1d caches (~3 cycles) using virtual addresses is almost mandatory.
For larger caches including L2, L3, ... caches physical address tagging is needed. These caches have a higher latency and the virtual→physical address translation can finish in time. Because these caches are larger (i.e., a lot of information is lost when they are flushed) and refilling them takes a long time due to the main memory access latency, flushing them often would be costly.
处理器的设计人员们现在使用虚拟地址来标记第一级缓存。这些缓存很小,很容易被清空。在进程页表树发生变更的情况下,至少是需要清空部分缓存的。如果处理器拥有指定变更地址范围的指令,那么可以避免缓存的完全刷新。由于一级缓存L1i及L1d的时延都很小(~3周期),基本上必须使用虚拟地址。
对于更大的缓存,包括L2和L3等,则需要以物理地址作为标签。因为这些缓存的时延比较大,虚拟到物理地址的映射可以在允许的时间里完成,而且由于主存时延的存在,重新填充这些缓存会消耗比较长的时间,刷新的代价比较昂贵。
It should, in general, not be necessary to know about the details of the address handling in those caches. They cannot be changed and all the factors which would influence the performance are normally something which should be avoided or is associated with high cost. Overflowing the cache capacity is bad and all caches run into problems early if the majority of the used cache lines fall into the same set. The latter can be avoided with virtually addressed caches but is impossible for user-level processes to avoid for caches addressed using physical addresses. The only detail one might want to keep in mind is to not map the same physical memory location to two or more virtual addresses in the same process, if at all possible.
Another detail of the caches which is rather uninteresting to programmers is the cache replacement strategy. Most caches evict the Least Recently Used (LRU) element first. This is always a good default strategy. With larger associativity (and associativity might indeed grow further in the coming years due to the addition of more cores) maintaining the LRU list becomes more and more expensive and we might see different strategies adopted.
As for the cache replacement there is not much a programmer can do. If the cache is using physical address tags there is no way to find out how the virtual addresses correlate with the cache sets. It might be that cache lines in all logical pages are mapped to the same cache sets, leaving much of the cache unused. If anything, it is the job of the OS to arrange that this does not happen too often.
另一个细节对程序员们来说比较乏味,那就是缓存的替换策略。大多数缓存会优先逐出最近最少使用(Least Recently Used,LRU)的元素。这往往是一个效果比较好的策略。在关联性很大的情况下(随着以后核心数的增加,关联性势必会变得越来越大),维护LRU列表变得越来越昂贵,于是我们开始看到其它的一些策略。
在缓存的替换策略方面,程序员可以做的事情不多。如果缓存使用物理地址作为标签,我们是无法找出虚拟地址与缓存集之间关联的。有可能会出现这样的情形: 所有逻辑页中的缓存线都映射到同一个缓存集,而其它大部分缓存却空闲着。即使有这种情况,也只能依靠OS进行合理安排,避免频繁出现。
With the advent of virtualization things get even more complicated. Now not even the OS has control over the assignment of physical memory. The Virtual Machine Monitor (VMM, aka hypervisor) is responsible for the physical memory assignment.
The best a programmer can do is to a) use logical memory pages completely and b) use page sizes as large as meaningful to diversify the physical addresses as much as possible. Larger page sizes have other benefits, too, but this is another topic (see Section 4).
虚拟化的出现使得这一切变得更加复杂。现在不仅操作系统可以控制物理内存的分配。虚拟机监视器(VMM,也称为 hypervisor)也负责分配内存。
对程序员来说,最好 a) 完全使用逻辑内存页面 b) 在有意义的情况下,使用尽可能大的页面大小来分散物理地址。更大的页面大小也有其他好处,不过这是另一个话题(见第4节)。
3.4 Instruction Cache
Not just the data used by the processor is cached; the instructions executed by the processor are also cached. However, this cache is much less problematic than the data cache. There are several reasons:
- The quantity of code which is executed depends on the size of the code that is needed. The size of the code in general depends on the complexity of the problem. The complexity of the problem is fixed.
- While the program's data handling is designed by the programmer the program's instructions are usually generated by a compiler. The compiler writers know about the rules for good code generation.
- Program flow is much more predictable than data access patterns. Today's CPUs are very good at detecting patterns. This helps with prefetching.
- Code always has quite good spatial and temporal locality
There are a few rules programmers should follow but these mainly consist of rules on how to use the tools. We will discuss them in Section 6. Here we talk only about the technical details of the instruction cache.
3.4 指令缓存
其实,不光处理器使用的数据被缓存,它们执行的指令也是被缓存的。只不过,指令缓存的问题相对来说要少得多,因为:
- 执行的代码量取决于代码大小。而代码大小通常取决于问题复杂度。问题复杂度则是固定的。
- 程序的数据处理逻辑是程序员设计的,而程序的指令却是编译器生成的。编译器的作者知道如何生成优良的代码。
- 程序的流向比数据访问模式更容易预测。现如今的CPU很擅长模式检测,对预取很有利。
- 代码永远都有良好的时间局部性和空间局部性。
有一些准则是需要程序员们遵守的,但大都是关于如何使用工具的,我们会在第6节介绍它们。而在这里我们只介绍一下指令缓存的技术细节。
Ever since the core clock of CPUs increased dramatically and the difference in speed between cache (even first level cache) and core grew, CPUs have been pipelined. That means the execution of an instruction happens in stages. First an instruction is decoded, then the parameters are prepared, and finally it is executed. Such a pipeline can be quite long (> 20 stages for Intel's Netburst architecture). A long pipeline means that if the pipeline stalls (i.e., the instruction flow through it is interrupted) it takes a while to get up to speed again. Pipeline stalls happen, for instance, if the location of the next instruction cannot be correctly predicted or if it takes too long to load the next instruction (e.g., when it has to be read from memory).
As a result CPU designers spend a lot of time and chip real estate on branch prediction so that pipeline stalls happen as infrequently as possible.
On CISC processors the decoding stage can also take some time. The x86 and x86-64 processors are especially affected. In recent years these processors therefore do not cache the raw byte sequence of the instructions in L1i but instead they cache the decoded instructions. L1i in this case is called the “trace cache”. Trace caching allows the processor to skip over the first steps of the pipeline in case of a cache hit which is especially good if the pipeline stalled.
为了解决这个问题,CPU的设计人员们在分支预测上投入大量时间和芯片资产(chip real estate),以降低管线延误的出现频率。
在CISC处理器上,指令的解码阶段也需要一些时间。x86及x86-64处理器尤为严重。近年来,这些处理器不再将指令的原始字节序列存入L1i,而是缓存解码后的版本。这样的L1i被叫做“追踪缓存(trace cache)”。追踪缓存可以在命中的情况下让处理器跳过管线最初的几个阶段,在管线发生延误时尤其有用。
As said before, the caches from L2 on are unified caches which contain both code and data. Obviously here the code is cached in the byte sequence form and not decoded.
To achieve the best performance there are only a few rules related to the instruction cache:
- Generate code which is as small as possible. There are exceptions when software pipelining for the sake of using pipelines requires creating more code or where the overhead of using small code is too high.
- Whenever possible, help the processor to make good prefetching decisions. This can be done through code layout or with explicit prefetching.
These rules are usually enforced by the code generation of a compiler. There are a few things the programmer can do and we will talk about them in Section 6.
前面说过,L2以上的缓存是统一缓存,既保存代码,也保存数据。显然,这里保存的代码是原始字节序列,而不是解码后的形式。
在提高性能方面,与指令缓存相关的只有很少的几条准则:
- 生成尽量少的代码。也有一些例外,如出于管线化的目的需要更多的代码,或使用小代码会带来过高的额外开销。
- 尽量帮助处理器作出良好的预取决策,可以通过代码布局或显式预取来实现。
这些准则一般会由编译器的代码生成阶段强制执行。至于程序员可以参与的部分,我们会在第6节介绍。
3.4.1 Self Modifying Code
In early computer days memory was a premium. People went to great lengths to reduce the size of the program to make more room for program data. One trick frequently deployed was to change the program itself over time. Such Self Modifying Code (SMC) is occasionally still found, these days mostly for performance reasons or in security exploits.
SMC should in general be avoided. Though it is generally executed correctly there are boundary cases in which it is not and it creates performance problems if not done correctly. Obviously, code which is changed cannot be kept in the trace cache which contains the decoded instructions. But even if the trace cache is not used because the code has not been executed at all (or for some time) the processor might have problems. If an upcoming instruction is changed while it already entered the pipeline the processor has to throw away a lot of work and start all over again. There are even situations where most of the state of the processor has to be tossed away.
3.4.1 自修改的代码
在计算机的早期岁月里,内存十分昂贵。人们想尽千方百计,只为了尽量压缩程序容量,给数据多留一些空间。其中,有一种方法是修改程序自身,称为自修改代码(SMC)。现在,有时候我们还能看到它,一般是出于提高性能的目的,也有的是为了攻击安全漏洞。
一般情况下,应该避免SMC。虽然一般情况下没有问题,但有时会由于执行错误而出现性能问题。显然,发生改变的代码是无法放入追踪缓存(追踪缓存放的是解码后的指令)的。即使没有使用追踪缓存(代码还没被执行或有段时间没执行),处理器也可能会遇到问题。如果某个进入管线的指令发生了变化,处理器只能扔掉目前的成果,重新开始。在某些情况下,甚至需要丢弃处理器的大部分状态。
Finally, since the processor assumes - for simplicity reasons and because it is true in 99.9999999% of all cases - that the code pages are immutable, the L1i implementation does not use the MESI protocol but instead a simplified SI protocol. This means if modifications are detected a lot of pessimistic assumptions have to be made.
It is highly advised to avoid SMC whenever possible. Memory is not such a scarce resource anymore. It is better to write separate functions instead of modifying one function according to specific needs. Maybe one day SMC support can be made optional and we can detect exploit code trying to modify code this way. If SMC absolutely has to be used, the write operations should bypass the cache as to not create problems with data in L1d needed in L1i. See Section 6.1 for more information on these instructions.
最后,由于处理器认为代码页是不可修改的(这是出于简单化的考虑,而且在99.9999999%情况下确实是正确的),L1i用到并不是MESI协议,而是一种简化后的SI协议。这样一来,如果万一检测到修改的情况,就需要作出大量悲观的假设。
因此,对于SMC,强烈建议能不用就不用。现在内存已经不再是一种那么稀缺的资源了。最好是写多个函数,而不要根据需要把一个函数改来改去。也许有一天可以把SMC变成可选项,我们就能通过这种方式检测入侵代码。如果一定要用SMC,应该让写操作越过缓存,以免由于L1i需要L1d里的数据而产生问题。更多细节,请参见6.1节。
Normally on Linux it is easy to recognize programs which contain SMC. All program code is write-protected when built with the regular toolchain. The programmer has to perform significant magic at link time to create an executable where the code pages are writable. When this happens, modern Intel x86 and x86-64 processors have dedicated performance counters which count uses of self-modifying code. With the help of these counters it is quite easily possible to recognize programs with SMC even if the program will succeed due to relaxed permissions.
3.5 Cache Miss Factors
We have already seen that when memory accesses miss the caches, the costs skyrocket. Sometimes this is not avoidable and it is important to understand the actual costs and what can be done to mitigate the problem.
在Linux上,判断程序是否包含SMC是很容易的。利用正常工具链(toolchain)构建的程序代码都是写保护(write-protected)的。程序员需要在链接时施展某些关键的魔术才能生成可写的代码页。现代的Intel x86和x86-64处理器都有统计SMC使用情况的专用计数器。通过这些计数器,我们可以很容易判断程序是否包含SMC,即使它被准许运行。
3.5 缓存未命中的因素
我们已经看过内存访问没有命中缓存时,那陡然猛涨的高昂代价。但是有时候,这种情况又是无法避免的,因此我们需要对真正的代价有所认识,并学习如何缓解这种局面。
3.5.1 Cache and Memory Bandwidth
To get a better understanding of the capabilities of the processors we measure the bandwidth available in optimal circumstances. This measurement is especially interesting since different processor versions vary widely. This is why this section is filled with the data of several different machines. The program to measure performance uses the SSE instructions of the x86 and x86-64 processors to load or store 16 bytes at once. The working set is increased from 1kB to 512MB just as in our other tests and it is measured how many bytes per cycle can be loaded or stored.
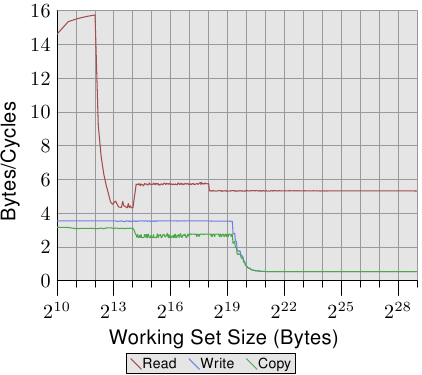
Figure 3.24: Pentium 4 Bandwidth
Figure 3.24 shows the performance on a 64-bit Intel Netburst processor. For working set sizes which fit into L1d the processor is able to read the full 16 bytes per cycle, i.e., one load instruction is performed per cycle (themovapsinstruction moves 16 bytes at once). The test does not do anything with the read data, we test only the read instructions themselves. As soon as the L1d is not sufficient anymore the performance goes down dramatically to less than 6 bytes per cycle. The step at 218 bytes is due to the exhaustion of the DTLB cache which means additional work for each new page. Since the reading is sequential prefetching can predict the accesses perfectly and the FSB can stream the memory content at about 5.3 bytes per cycle for all sizes of the working set. The prefetched data is not propagated into L1d, though. These are of course numbers which will never be achievable in a real program. Think of them as practical limits.
3.5.1 缓存与内存带宽
为了更好地理解处理器的能力,我们测量了各种理想环境下能够达到的带宽值。由于不同处理器的版本差别很大,所以这个测试比较有趣,也因为如此,这一节都快被测试数据灌满了。我们使用了x86和x86-64处理器的SSE指令来装载和存储数据,每次16字节。工作集则与其它测试一样,从1kB增加到512MB,测量的具体对象是每个周期所处理的字节数。
图3.24: P4的带宽
图3.24展示了一颗64位Intel Netburst处理器的性能图表。当工作集能够完全放入L1d时,处理器的每个周期可以读取完整的16字节数据,即每个周期执行一条装载指令(moveaps指令,每次移动16字节的数据)。测试程序并不对数据进行任何处理,只是测试读取指令本身。当工作集增大,无法再完全放入L1d时,性能开始急剧下降,跌至每周期6字节。在218工作集处出现的台阶是由于DTLB缓存耗尽,因此需要对每个新页施加额外处理。由于这里的读取是按顺序的,预取机制可以完美地工作,而FSB能以5.3字节/周期的速度传输内容。但预取的数据并不进入L1d。当然,真实世界的程序永远无法达到以上的数字,但我们可以将它们看作一系列实际上的极限值。
What is more astonishing than the read performance is the write and copy performance. The write performance, even for small working set sizes, does not ever rise above 4 bytes per cycle. This indicates that, in these Netburst processors, Intel elected to use a Write-Through mode for L1d where the performance is obviously limited by the L2 speed. This also means that the performance of the copy test, which copies from one memory region into a second, non-overlapping memory region, is not significantly worse. The necessary read operations are so much faster and can partially overlap with the write operations. The most noteworthy detail of the write and copy measurements is the low performance once the L2 cache is not sufficient anymore. The performance drops to 0.5 bytes per cycle! That means write operations are by a factor of ten slower than the read operations. This means optimizing those operations is even more important for the performance of the program.
In Figure 3.25 we see the results on the same processor but with two threads running, one pinned to each of the two hyper-threads of the processor.
The graph is shown at the same scale as the previous one to illustrate the differences and the curves are a bit jittery simply because of the problem of measuring two concurrent threads. The results are as expected. Since the hyper-threads share all the resources except the registers each thread has only half the cache and bandwidth available. That means even though each thread has to wait a lot and could award the other thread with execution time this does not make any difference since the other thread also has to wait for the memory. This truly shows the worst possible use of hyper-threads.
Figure 3.25: P4 Bandwidth with 2 Hyper-Threads
再来看图3.25,它来自同一颗处理器,只是运行双线程,每个线程分别运行在处理器的一个超线程上。
图3.25: P4开启两个超线程时的带宽表现
图3.25采用了与图3.24相同的刻度,以方便比较两者的差异。图3.25中的曲线抖动更多,是由于采用双线程的缘故。结果正如我们预期,由于超线程共享着几乎所有资源(仅除寄存器外),所以每个超线程只能得到一半的缓存和带宽。所以,即使每个线程都要花上许多时间等待内存,从而把执行时间让给另一个线程,也是无济于事——因为另一个线程也同样需要等待。这里恰恰展示了使用超线程时可能出现的最坏情况。
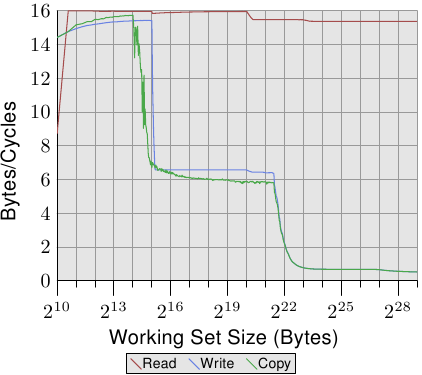
Figure 3.26: Core 2 Bandwidth
Compared to Figures 3.24 and 3.25 the results in Figures 3.26 and 3.27 look quite different for an Intel Core 2 processor. This is a dual-core processor with shared L2 which is four times as big as the L2 on the P4 machine. This only explains the delayed drop-off of the write and copy performance, though.
There are much bigger differences. The read performance throughout the working set range hovers around the optimal 16 bytes per cycle. The drop-off in the read performance after 220 bytes is again due to the working set being too big for the DTLB. Achieving these high numbers means the processor is not only able to prefetch the data and transport the data in time. It also means the data is prefetched into L1d.
图3.26: Core 2的带宽表现
再来看Core 2处理器的情况。看看图3.26和图3.27,再对比下P4的图3.24和3.25,可以看出不小的差异。Core 2是一颗双核处理器,有着共享的L2,容量是P4 L2的4倍。但更大的L2只能解释写操作的性能下降出现较晚的现象。
当然还有更大的不同。可以看到,读操作的性能在整个工作集范围内一直稳定在16字节/周期左右,在220处的下降同样是由于DTLB的耗尽引起。能够达到这么高的数字,不但表明处理器能够预取数据,并且按时完成传输,而且还意味着,预取的数据是被装入L1d的。
The write and copy performance is dramatically different, too. The processor does not have a Write-Through policy; written data is stored in L1d and only evicted when necessary. This allows for write speeds close to the optimal 16 bytes per cycle. Once L1d is not sufficient anymore the performance drops significantly. As with the Netburst processor, the write performance is significantly lower. Due to the high read performance the difference is even higher here. In fact, when even the L2 is not sufficient anymore the speed difference increases to a factor of 20! This does not mean the Core 2 processors perform poorly. To the contrary, their performance is always better than the Netburst core's.

Figure 3.27: Core 2 Bandwidth with 2 Threads
In Figure 3.27, the test runs two threads, one on each of the two cores of the Core 2 processor. Both threads access the same memory, not necessarily perfectly in sync, though. The results for the read performance are not different from the single-threaded case. A few more jitters are visible which is to be expected in any multi-threaded test case.
写/复制操作的性能与P4相比,也有很大差异。处理器没有采用写通策略,写入的数据留在L1d中,只在必要时才逐出。这使得写操作的速度可以逼近16字节/周期。一旦工作集超过L1d,性能即飞速下降。由于Core 2读操作的性能非常好,所以两者的差值显得特别大。当工作集超过L2时,两者的差值甚至超过20倍!但这并不表示Core 2的性能不好,相反,Core 2永远都比Netburst强。
图3.27: Core 2运行双线程时的带宽表现
在图3.27中,启动双线程,各自运行在Core 2的一个核心上。它们访问相同的内存,但不需要完美同步。从结果上看,读操作的性能与单线程并无区别,只是多了一些多线程情况下常见的抖动。
The interesting point is the write and copy performance for working set sizes which would fit into L1d. As can be seen in the figure, the performance is the same as if the data had to be read from the main memory. Both threads compete for the same memory location and RFO messages for the cache lines have to be sent. The problematic point is that these requests are not handled at the speed of the L2 cache, even though both cores share the cache. Once the L1d cache is not sufficient anymore modified entries are flushed from each core's L1d into the shared L2. At that point the performance increases significantly since now the L1d misses are satisfied by the L2 cache and RFO messages are only needed when the data has not yet been flushed. This is why we see a 50% reduction in speed for these sizes of the working set. The asymptotic behavior is as expected: since both cores share the same FSB each core gets half the FSB bandwidth which means for large working sets each thread's performance is about half that of the single threaded case.
Because there are significant differences between the processor versions of one vendor it is certainly worthwhile looking at the performance of other vendors' processors, too. Figure 3.28 shows the performance of an AMD family 10h Opteron processor. This processor has 64kB L1d, 512kB L2, and 2MB of L3. The L3 cache is shared between all cores of the processor. The results of the performance test can be seen in Figure 3.28.

Figure 3.28: AMD Family 10h Opteron Bandwidth
The first detail one notices about the numbers is that the processor is capable of handling two instructions per cycle if the L1d cache is sufficient. The read performance exceeds 32 bytes per cycle and even the write performance is, with 18.7 bytes per cycle, high. The read curve flattens quickly, though, and is, with 2.3 bytes per cycle, pretty low. The processor for this test does not prefetch any data, at least not efficiently.
由于同一个厂商的不同处理器之间都存在着巨大差异,我们没有理由不去研究一下其它厂商处理器的性能。图3.28展示了AMD家族10h Opteron处理器的性能。这颗处理器有64kB的L1d、512kB的L2和2MB的L3,其中L3缓存由所有核心所共享。
图3.28: AMD家族10h Opteron的带宽表现
大家首先应该会注意到,在L1d缓存足够的情况下,这个处理器每个周期能处理两条指令。读操作的性能超过了32字节/周期,写操作也达到了18.7字节/周期。但是,不久,读操作的曲线就急速下降,跌到2.3字节/周期,非常差。处理器在这个测试中并没有预取数据,或者说,没有有效地预取数据。
The write curve on the other hand performs according to the sizes of the various caches. The peak performance is achieved for the full size of the L1d, going down to 6 bytes per cycle for L2, to 2.8 bytes per cycle for L3, and finally .5 bytes per cycle if not even L3 can hold all the data. The performance for the L1d cache exceeds that of the (older) Core 2 processor, the L2 access is equally fast (with the Core 2 having a larger cache), and the L3 and main memory access is slower.
The copy performance cannot be better than either the read or write performance. This is why we see the curve initially dominated by the read performance and later by the write performance.
另一方面,写操作的曲线随几级缓存的容量而流转。在L1d阶段达到最高性能,随后在L2阶段下降到6字节/周期,在L3阶段进一步下降到2.8字节/周期,最后,在工作集超过L3后,降到0.5字节/周期。它在L1d阶段超过了Core 2,在L2阶段基本相当(Core 2的L2更大一些),在L3及主存阶段比Core 2慢。
复制的性能既无法超越读操作的性能,也无法超越写操作的性能。因此,它的曲线先是被读性能压制,随后又被写性能压制。
The multi-thread performance of the Opteron processor is shown in Figure 3.29.
The read performance is largely unaffected. Each thread's L1d and L2 works as before and the L3 cache is in this case not prefetched very well either. The two threads do not unduly stress the L3 for their purpose. The big problem in this test is the write performance. All data the threads share has to go through the L3 cache. This sharing seems to be quite inefficient since even if the L3 cache size is sufficient to hold the entire working set the cost is significantly higher than an L3 access. Comparing this graph with Figure 3.27 we see that the two threads of the Core 2 processor operate at the speed of the shared L2 cache for the appropriate range of working set sizes. This level of performance is achieved for the Opteron processor only for a very small range of the working set sizes and even here it approaches only the speed of the L3 which is slower than the Core 2's L2.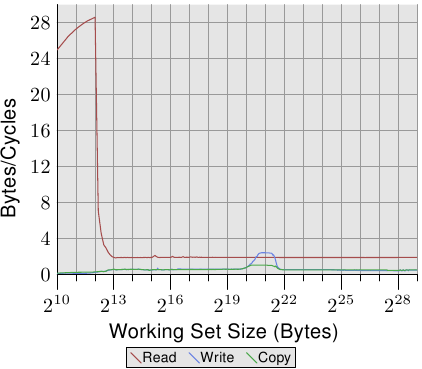
Figure 3.29: AMD Fam 10h Bandwidth with 2 Threads
图3.29显示的是Opteron处理器在多线程时的性能表现。
图3.29: AMD Fam 10h在双线程时的带宽表现
读操作的性能没有受到很大的影响。每个线程的L1d和L2表现与单线程下相仿,L3的预取也依然表现不佳。两个线程并没有过渡争抢L3。问题比较大的是写操作的性能。两个线程共享的所有数据都需要经过L3,而这种共享看起来却效率很差。即使是在L3足够容纳整个工作集的情况下,所需要的开销仍然远高于L3的访问时间。再来看图3.27,可以发现,在一定的工作集范围内,Core 2处理器能以共享的L2缓存的速度进行处理。而Opteron处理器只能在很小的一个范围内实现相似的性能,而且,它仅仅只能达到L3的速度,无法与Core 2的L2相比。
3.5.2 Critical Word Load
Memory is transferred from the main memory into the caches in blocks which are smaller than the cache line size. Today 64 bits are transferred at once and the cache line size is 64 or 128 bytes. This means 8 or 16 transfers per cache line are needed.
The DRAM chips can transfer those 64-bit blocks in burst mode. This can fill the cache line without any further commands from the memory controller and the possibly associated delays. If the processor prefetches cache lines this is probably the best way to operate.
3.5.2 关键字加载
内存以比缓存线还小的块从主存储器向缓存传送。如今64位可一次性传送,缓存线的大小为64或128比特。这意味着每个缓存线需要8或16次传送。
DRAM芯片可以以触发模式传送这些64位的块。这使得不需要内存控制器的进一步指令和可能伴随的延迟,就可以将缓存线充满。如果处理器预取了缓存,这有可能是最好的操作方式。
If a program's cache access of the data or instruction caches misses (that means, it is a compulsory cache miss, because the data is used for the first time, or a capacity cache miss, because the limited cache size requires eviction of the cache line) the situation is different. The word inside the cache line which is required for the program to continue might not be the first word in the cache line. Even in burst mode and with double data rate transfer the individual 64-bit blocks arrive at noticeably different times. Each block arrives 4 CPU cycles or more later than the previous one. If the word the program needs to continue is the eighth of the cache line, the program has to wait an additional 30 cycles or more after the first word arrives.
Things do not necessarily have to be like this. The memory controller is free to request the words of the cache line in a different order. The processor can communicate which word the program is waiting on, the critical word, and the memory controller can request this word first. Once the word arrives the program can continue while the rest of the cache line arrives and the cache is not yet in a consistent state. This technique is called Critical Word First & Early Restart.
如果程序在访问数据或指令缓存时没有命中(这可能是强制性未命中或容量性未命中,前者是由于数据第一次被使用,后者是由于容量限制而将缓存线逐出),情况就不一样了。程序需要的并不总是缓存线中的第一个字,而数据块的到达是有先后顺序的,即使是在突发模式和双倍传输率下,也会有明显的时间差,一半在4个CPU周期以上。举例来说,如果程序需要缓存线中的第8个字,那么在首字抵达后它还需要额外等待30个周期以上。
当然,这样的等待并不是必需的。事实上,内存控制器可以按不同顺序去请求缓存线中的字。当处理器告诉它,程序需要缓存中具体某个字,即「关键字(critical word)」时,内存控制器就会先请求这个字。一旦请求的字抵达,虽然缓存线的剩余部分还在传输中,缓存的状态还没有达成一致,但程序已经可以继续运行。这种技术叫做关键字优先及较早重启(Critical Word First & Early Restart)。
Processors nowadays implement this technique but there are situations when that is not possible. If the processor prefetches data the critical word is not known. Should the processor request the cache line during the time the prefetch operation is in flight it will have to wait until the critical word arrives without being able to influence the order.
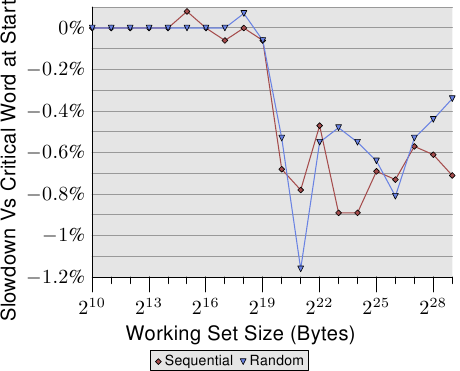
Figure 3.30: Critical Word at End of Cache Line
Even with these optimizations in place the position of the critical word on a cache line matters. Figure 3.30 shows the Follow test for sequential and random access. Shown is the slowdown of running the test with the pointer which is chased in the first word versus the case when the pointer is in the last word. The element size is 64 bytes, corresponding the cache line size. The numbers are quite noisy but it can be seen that, as soon as the L2 is not sufficient to hold the working set size, the performance of the case where the critical word is at the end is about 0.7% slower. The sequential access appears to be affected a bit more. This would be consistent with the aforementioned problem when prefetching the next cache line.
现在的处理器都已经实现了这一技术,但有时无法运用。比如,预取操作的时候,并不知道哪个是关键字。如果在预取的中途请求某条缓存线,处理器只能等待,并不能更改请求的顺序。
图3.30: 关键字位于缓存线尾时的表现
在关键字优先技术生效的情况下,关键字的位置也会影响结果。图3.30展示了下一个测试的结果,图中表示的是关键字分别在线首和线尾时的性能对比情况。元素大小为64字节,等于缓存线的长度。图中的噪声比较多,但仍然可以看出,当工作集超过L2后,关键字处于线尾情况下的性能要比线首情况下低0.7%左右。而顺序访问时受到的影响更大一些。这与我们前面提到的预取下条线时可能遇到的问题是相符的。
3.5.3 Cache Placement
Where the caches are placed in relationship to the hyper-threads, cores, and processors is not under control of the programmer. But programmers can determine where the threads are executed and then it becomes important how the caches relate to the used CPUs.
Here we will not go into details of when to select what cores to run the threads. We will only describe architecture details which the programmer has to take into account when setting the affinity of the threads.
3.5.3 缓存设定
缓存放置的位置与超线程,内核和处理器之间的关系,不在程序员的控制范围之内。但是程序员可以决定线程执行的位置,接着高速缓存与使用的CPU的关系将变得非常重要。
这里我们将不会深入(探讨)什么时候选择什么样的内核以运行线程的细节。我们仅仅描述了在设置关联线程的时候,程序员需要考虑的系统结构的细节。
Hyper-threads, by definition share everything but the register set. This includes the L1 caches. There is not much more to say here. The fun starts with the individual cores of a processor. Each core has at least its own L1 caches. Aside from this there are today not many details in common:
- Early multi-core processors had separate L2 caches and no higher caches.
- Later Intel models had shared L2 caches for dual-core processors. For quad-core processors we have to deal with separate L2 caches for each pair of two cores. There are no higher level caches.
- AMD's family 10h processors have separate L2 caches and a unified L3 cache.
超线程,通过定义,共享除去寄存器集以外的所有数据。包括 L1 缓存。这里没有什么可以多说的。多核处理器的独立核心带来了一些乐趣。每个核心都至少拥有自己的 L1 缓存。除此之外,下面列出了一些不同的特性:
- 早期多核心处理器有独立的 L2 缓存且没有更高层级的缓存。
- 之后英特尔的双核心处理器模型拥有共享的L2 缓存。对四核处理器,则分对拥有独立的L2 缓存,且没有更高层级的缓存。
- AMD 家族的 10h 处理器有独立的 L2 缓存以及一个统一的L3 缓存。
Completely sharing all caches beside L1 as Intel's dual-core processors do can have a big advantage. If the working set of the threads working on the two cores overlaps significantly the total available cache memory is increased and working sets can be bigger without performance degradation. If the working sets do not overlap Intel's Advanced Smart Cache management is supposed to prevent any one core from monopolizing the entire cache.
关于各种处理器模型的优点,已经在它们各自的宣传手册里写得够多了。在每个核心的工作集互不重叠的情况下,独立的L2拥有一定的优势,单线程的程序可以表现优良。考虑到目前实际环境中仍然存在大量类似的情况,这种方法的表现并不会太差。不过,不管怎样,我们总会遇到工作集重叠的情况。如果每个缓存都保存着某些通用运行库的常用部分,那么很显然是一种浪费。
如果像Intel的双核处理器那样,共享除L1外的所有缓存,则会有一个很大的优点。如果两个核心的工作集重叠的部分较多,那么综合起来的可用缓存容量会变大,从而允许容纳更大的工作集而不导致性能的下降。如果两者的工作集并不重叠,那么则是由Intel的高级智能缓存管理(Advanced Smart Cache management)发挥功用,防止其中一个核心垄断整个缓存。
If both cores use about half the cache for their respective working sets there is some friction, though. The cache constantly has to weigh the two cores' cache use and the evictions performed as part of this rebalancing might be chosen poorly. To see the problems we look at the results of yet another test program.
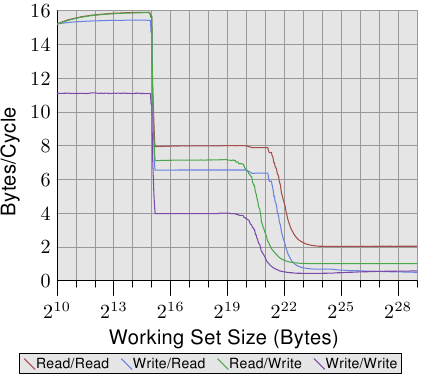
Figure 3.31: Bandwidth with two Processes
The test program has one process constantly reading or writing, using SSE instructions, a 2MB block of memory. 2MB was chosen because this is half the size of the L2 cache of this Core 2 processor. The process is pinned to one core while a second process is pinned to the other core. This second process reads and writes a memory region of variable size. The graph shows the number of bytes per cycle which are read or written. Four different graphs are shown, one for each combination of the processes reading and writing. The read/write graph is for the background process, which always uses a 2MB working set to write, and the measured process with variable working set to read.
即使每个核心只使用一半的缓存,也会有一些摩擦。缓存需要不断衡量每个核心的用量,在进行逐出操作时可能会作出一些比较差的决定。我们来看另一个测试程序的结果。
图3.31: 两个进程的带宽表现
这次,测试程序两个进程,第一个进程不断用SSE指令读/写2MB的内存数据块,选择2MB,是因为它正好是Core 2处理器L2缓存的一半,第二个进程则是读/写大小变化的内存区域,我们把这两个进程分别固定在处理器的两个核心上。图中显示的是每个周期读/写的字节数,共有4条曲线,分别表示不同的读写搭配情况。例如,标记为读/写(read/write)的曲线代表的是后台进程进行写操作(固定2MB工作集),而被测量进程进行读操作(工作集从小到大)。
The interesting part of the graph is the part between 220 and 223 bytes. If the L2 cache of the two cores were completely separate we could expect that the performance of all four tests would drop between 221 and 222 bytes, that means, once the L2 cache is exhausted. As we can see in Figure 3.31 this is not the case. For the cases where the background process is writing this is most visible. The performance starts to deteriorate before the working set size reaches 1MB. The two processes do not share memory and therefore the processes do not cause RFO messages to be generated. These are pure cache eviction problems. The smart cache handling has its problems with the effect that the experienced cache size per core is closer to 1MB than the 2MB per core which are available. One can only hope that, if caches shared between cores remain a feature of upcoming processors, the algorithm used for the smart cache handling will be fixed.
Having a quad-core processor with two L2 caches was just a stop-gap solution before higher-level caches could be introduced. This design provides no significant performance advantage over separate sockets and dual-core processors. The two cores communicate via the same bus which is, at the outside, visible as the FSB. There is no special fast-track data exchange.
The future of cache design for multi-core processors will lie in more layers. AMD's 10h family of processors make the start. Whether we will continue to see lower level caches be shared by a subset of the cores of a processor remains to be seen. The extra levels of cache are necessary since the high-speed and frequently used caches cannot be shared among many cores. The performance would be impacted. It would also require very large caches with high associativity. Both numbers, the cache size and the associativity, must scale with the number of cores sharing the cache. Using a large L3 cache and reasonably-sized L2 caches is a reasonable trade-off. The L3 cache is slower but it is ideally not as frequently used as the L2 cache.
For programmers all these different designs mean complexity when making scheduling decisions. One has to know the workloads and the details of the machine architecture to achieve the best performance. Fortunately we have support to determine the machine architecture. The interfaces will be introduced in later sections.
推出拥有双L2缓存的4核处理器仅仅只是一种临时措施,是开发更高级缓存之前的替代方案。与独立插槽及双核处理器相比,这种设计并没有带来多少性能提升。两个核心是通过同一条总线(被外界看作FSB)进行通信,并没有什么特别快的数据交换通道。
未来,针对多核处理器的缓存将会包含更多层次。AMD的10h家族是一个开始,至于会不会有更低级共享缓存的出现,还需要我们拭目以待。我们有必要引入更多级别的缓存,因为频繁使用的高速缓存不可能被许多核心共用,否则会对性能造成很大的影响。我们也需要更大的高关联性缓存,它们的数量、容量和关联性都应该随着共享核心数的增长而增长。巨大的L3和适度的L2应该是一种比较合理的选择。L3虽然速度较慢,但也较少使用。
对于程序员来说,不同的缓存设计就意味着调度决策时的复杂性。为了达到最高的性能,我们必须掌握工作负载的情况,必须了解机器架构的细节。好在我们在判断机器架构时还是有一些支援力量的,我们会在后面的章节介绍这些接口。
3.5.4 FSB Influence
The FSB plays a central role in the performance of the machine. Cache content can only be stored and loaded as quickly as the connection to the memory allows. We can show how much so by running a program on two machines which only differ in the speed of their memory modules. Figure 3.32 shows the results of the Addnext0 test (adding the content of the next elementspad[0]element to the ownpad[0]element) forNPAD=7 on a 64-bit machine. Both machines have Intel Core 2 processors, the first uses 667MHz DDR2 modules, the second 800MHz modules (a 20% increase).
Figure 3.32: Influence of FSB Speed
The numbers show that, when the FSB is really stressed for large working set sizes, we indeed see a large benefit. The maximum performance increase measured in this test is 18.2%, close to the theoretical maximum. What this shows is that a faster FSB indeed can pay off big time. It is not critical when the working set fits into the caches (and these processors have a 4MB L2). It must be kept in mind that we are measuring one program here. The working set of a system comprises the memory needed by all concurrently running processes. This way it is easily possible to exceed 4MB memory or more with much smaller programs.
3.5.4 FSB的影响
FSB在性能中扮演了核心角色。缓存数据的存取速度受制于内存通道的速度。我们做一个测试,在两台机器上分别跑同一个程序,这两台机器除了内存模块的速度有所差异,其它完全相同。图3.32展示了Addnext0测试(将下一个元素的pad[0]加到当前元素的pad[0]上)在这两台机器上的结果(NPAD=7,64位机器)。两台机器都采用Core 2处理器,一台使用667MHz的DDR2内存,另一台使用800MHz的DDR2内存(比前一台增长20%)。
图3.32: FSB速度的影响
图上的数字表明,当工作集大到对FSB造成压力的程度时,高速FSB确实会带来巨大的优势。在我们的测试中,性能的提升达到了18.5%,接近理论上的极限。而当工作集比较小,可以完全纳入缓存时,FSB的作用并不大。当然,这里我们只测试了一个程序的情况,在实际环境中,系统往往运行多个进程,工作集是很容易超过缓存容量的。
Today some of Intel's processors support FSB speeds up to 1,333MHz which would mean another 60% increase. The future is going to see even higher speeds. If speed is important and the working set sizes are larger, fast RAM and high FSB speeds are certainly worth the money. One has to be careful, though, since even though the processor might support higher FSB speeds the motherboard/Northbridge might not. It is critical to check the specifications.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号