OCR图像识别:python+pytesseract+Tesseract-OCR
1.安装pytesseract
pip install pytesseract
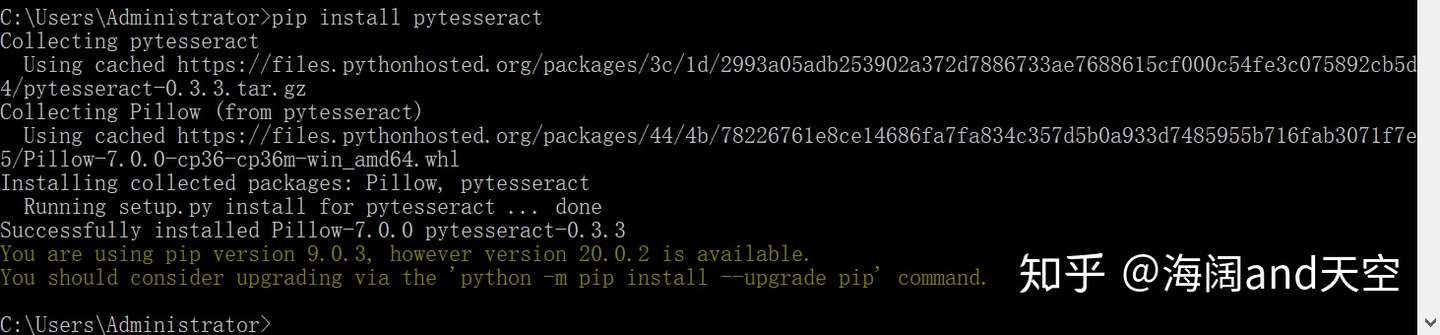
编辑pytesseract.py文件:
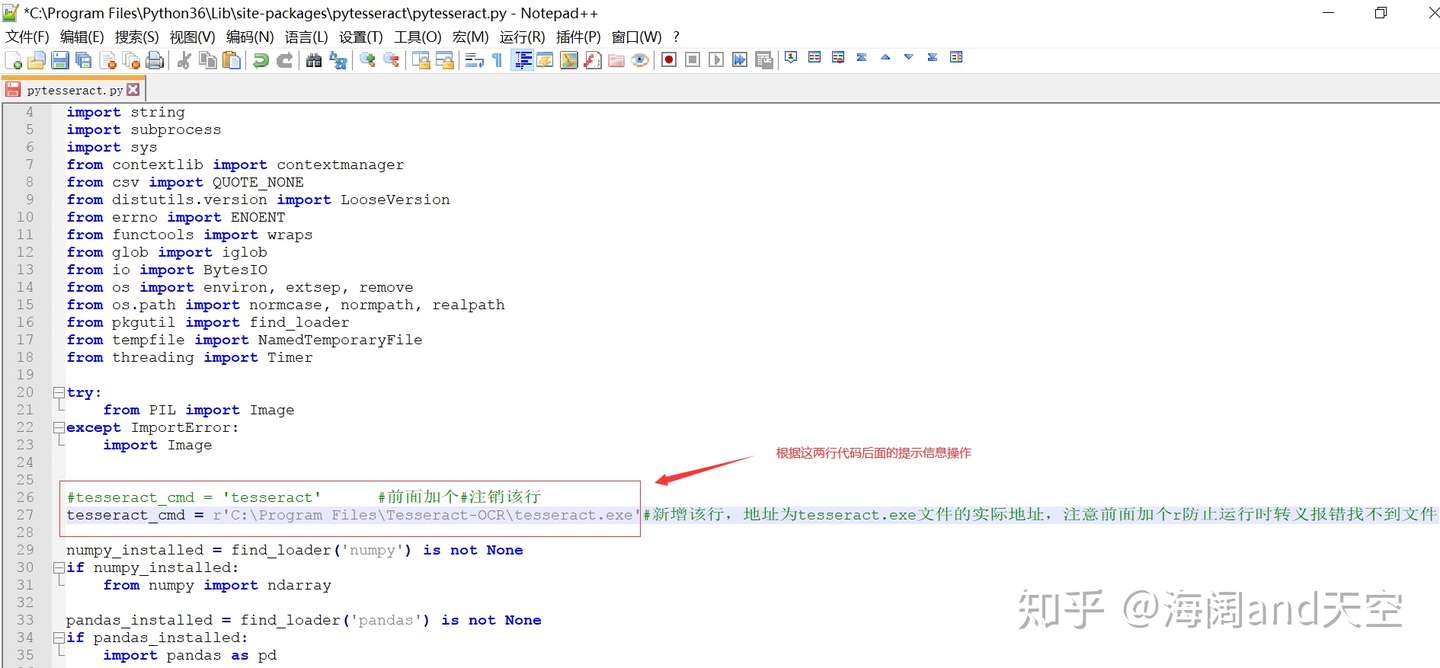
注意务必确保地址正确,保存后关闭。
2.安装Pillow
pip install Pillow

3.下载并安装Tesseract-OCR
下载地址:https://digi.bib.uni-mannheim.de/tesseract/
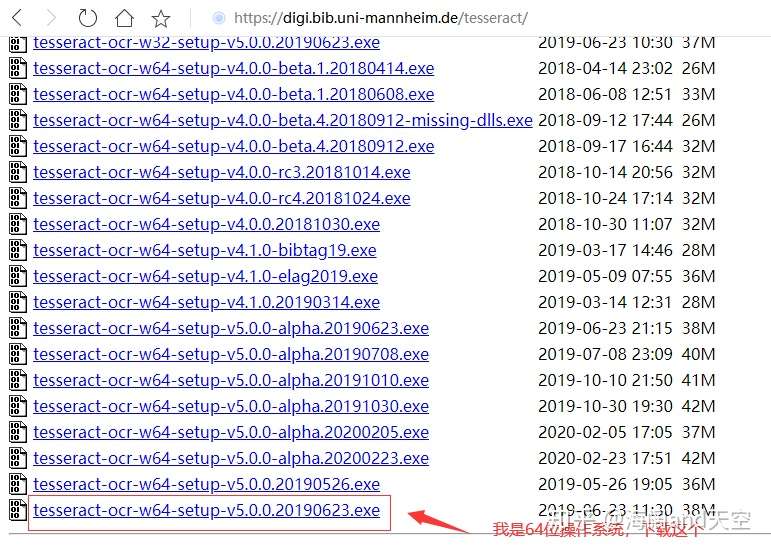
开始安装下载的包:
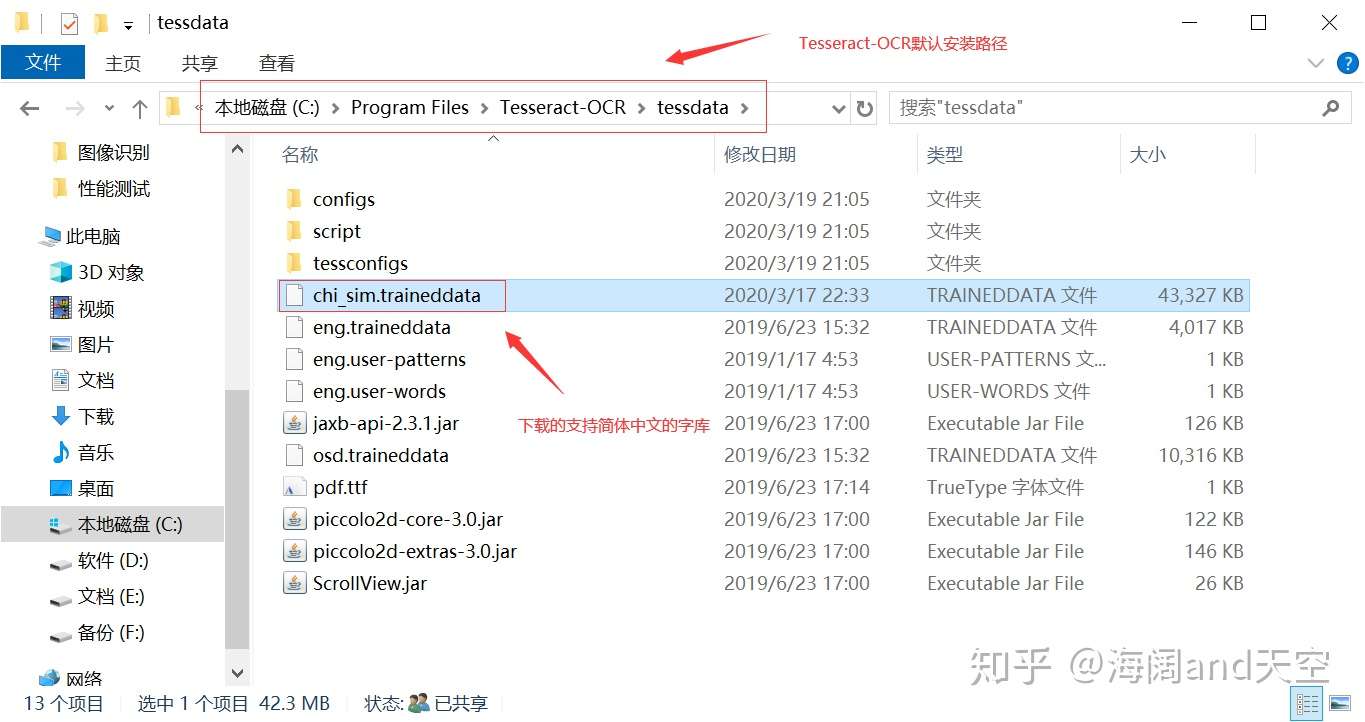
4.下载简体字识别包并放置到Tesseract-OCR安装目录下的的tessdata目录下
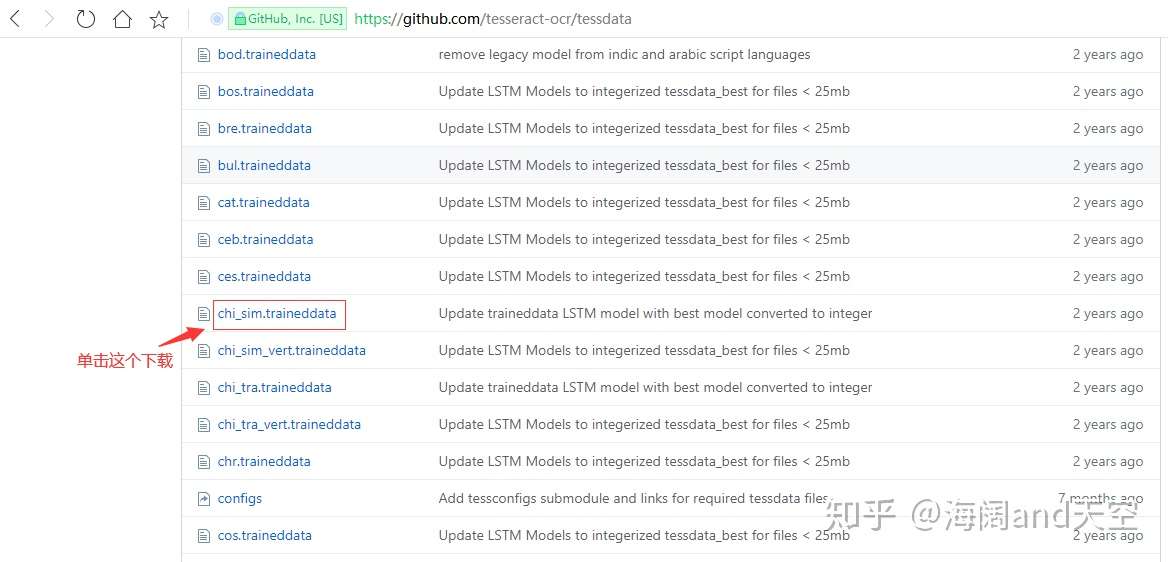
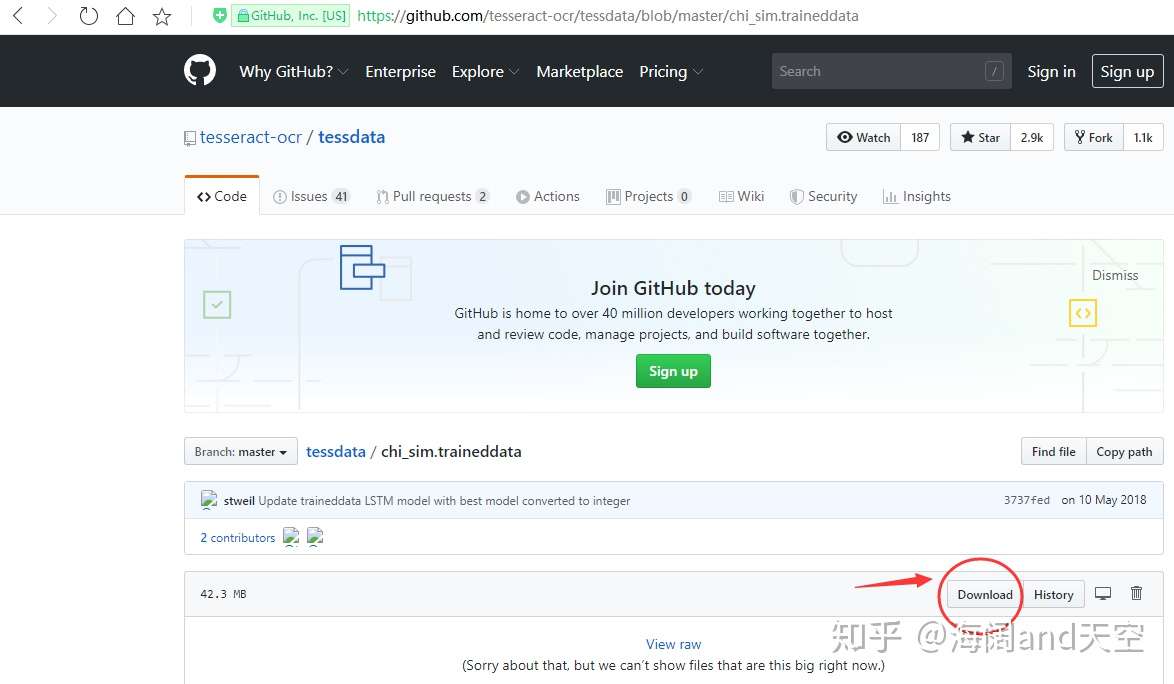
将下载的文件放入Tesseract-OCR安装目录下的的tessdata目录下:
5.代码示例
先来几张图片看下识别效果:
 1.png
1.png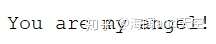 2.png
2.png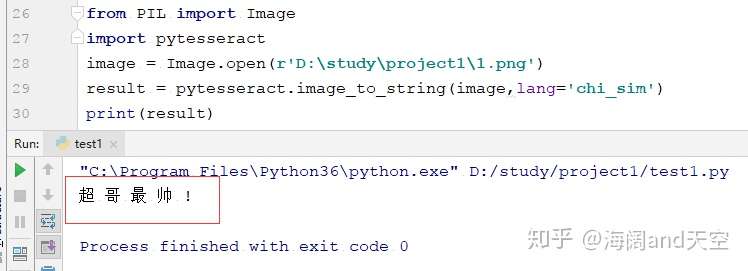
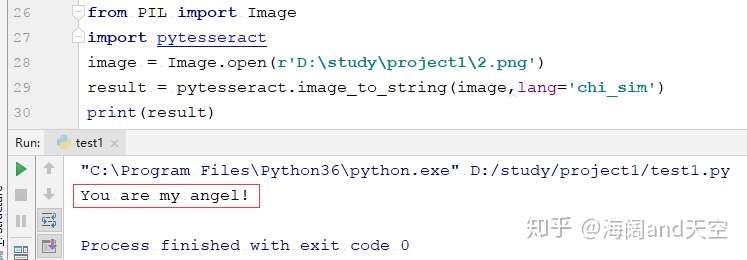
贴上源码,大家就不用费劲儿敲了哈!
from PIL import Image
import pytesseract
image = Image.open(r'D:\study\project1\2.png')#打开图片
result = pytesseract.image_to_string(image,lang='chi_sim')#使用简体中文字库识别图片并返回结果
print(result)#打印识别的图片内容
最后的说明:本方法对于识别一些简单纯净的中文、数字、字母和标点符号的效果还是不错的,如果是经过处理的图片,比如验证码等图片的识别,需要借助jTessBoxEditor训练字库才能提高识别的准确率哦,有待下篇放送哈,敬请期待!!!

https://zhuanlan.zhihu.com/p/113961004
Python3使用 pytesseract 进行图片识别
一、安装Tesseract-OCR软件
参考我的前一篇文章:Windows安装Tesseract-OCR 4.00并配置环境变量
二、Python中使用
需要使用 pytesseract 库,官方使用说明请看:https://pypi.python.org/pypi/pytesseract
1. 安装依赖
1 pip install pytesseract 2 pip install pillow
2. 编写代码
准备识别下面这个验证码:

代码如下:

1 import pytesseract
2 from PIL import Image
3
4 image = Image.open("code.png")
5 code = pytesseract.image_to_string(image)
6 print(code)
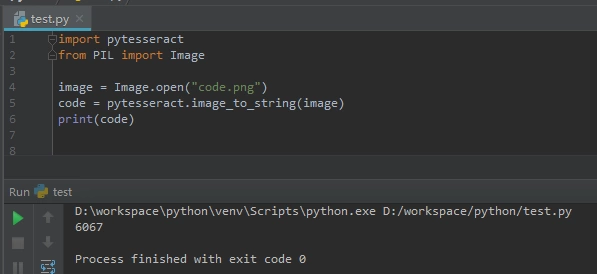
结果为6067,识别成功。
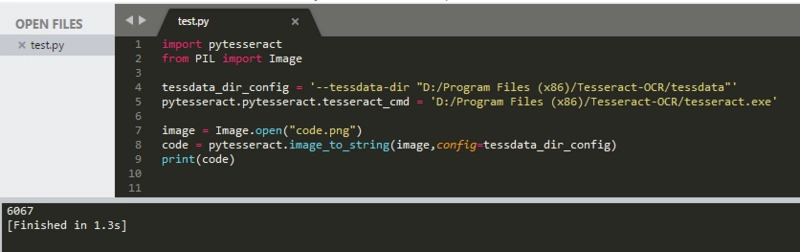
3. 如果出现错误,一般是系统变量设置的问题:
解决办法一:根据安装Tesseract软件的步骤配置环境变量,设置好即可。
解决方法二:在代码中添加相关变量参数:
1 import pytesseract
2 from PIL import Image
3
4 pytesseract.pytesseract.tesseract_cmd = 'D:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
5 tessdata_dir_config = '--tessdata-dir "D:/Program Files (x86)/Tesseract-OCR/tessdata"'
6
7 image = Image.open("code.png")
8 code = pytesseract.image_to_string(image, config=tessdata_dir_config)
9 print(code)
--------------------------------------------------------------------------------------------------------------------
talk is cheap , show me the code.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号