IO通道 ,DMA

通道处理机 : 通道处理机虽然不是一台具有完整指令系统的处理机,但可以把它看作是一台能够执行有限输入输出指令、能够被多台外围设备共享的小型DMA专用处理器机。
通道完成一次数据传输的主要过程 :
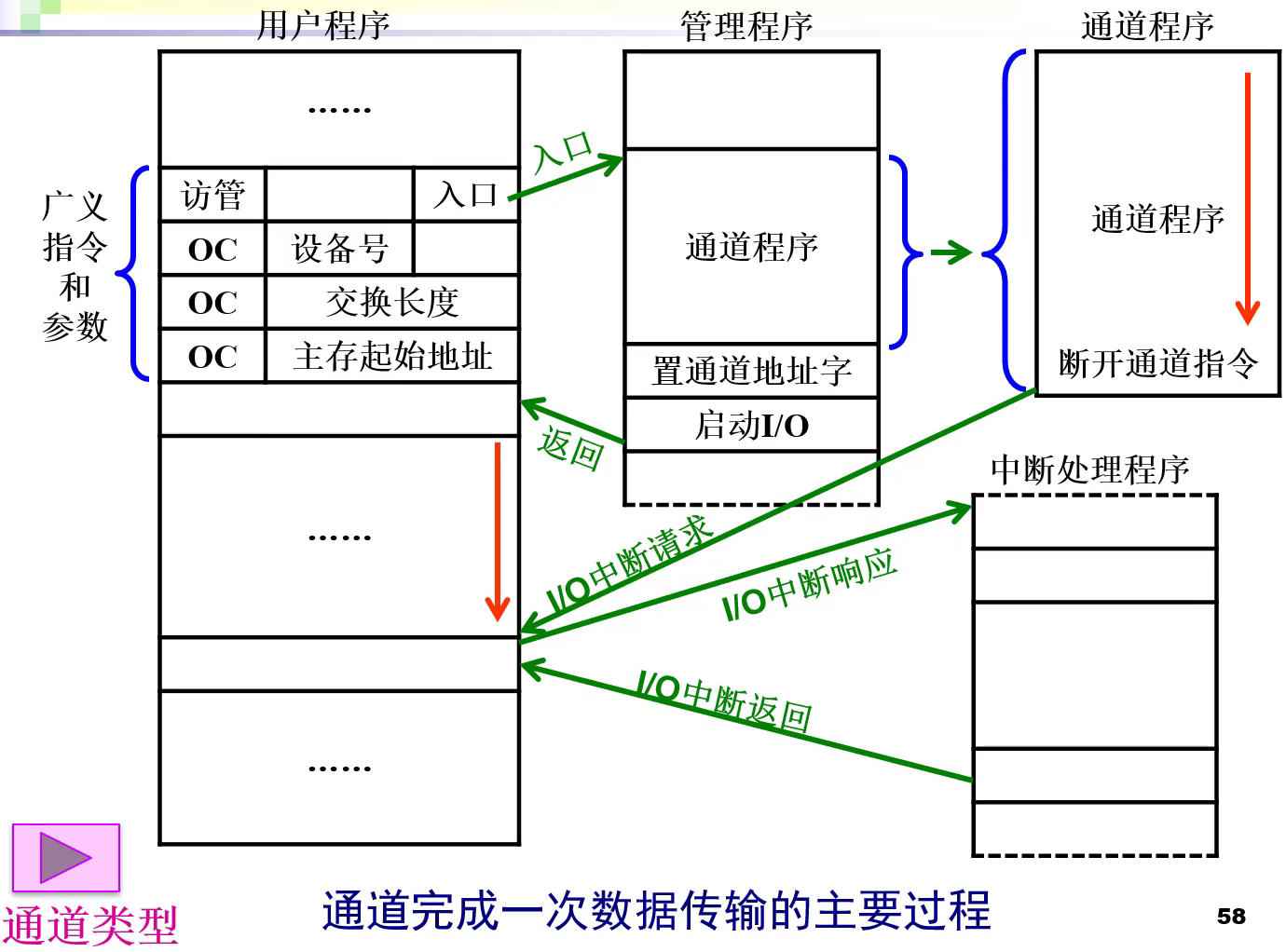
通道的三种类型#
字节多路通道#
- 适用于字符类低速外围设备, 通道的数据宽度为单字节, 以字节交叉方式轮流的为多台外部设备服务. 如 : 光电机
- 选中一个设备后传一个字节, 然后换下一个设备
选择通道#
- 选择通道为优先级高的高速外围设备服务, 如磁盘. 数据传送以成块的方式进行.
- 每个选择通道只有一个以成组方式工作的子通道, 逐个为多台高速外围设备服务
- 选中一个设备后必须把该设备所有数据全传送完
数组多路通道#
- 把字节多路通道和选择通道的特性结合起来
- 连接多台高速外设, 每次为一台高速设备传送一个数据块, 并轮流为多台外围设备服务

计算通道流量#
计算通道实际最大流量#
- 字节多路通道-----各设备字节传送速率之和
- 选择通道和数组多路通道-----各设备字节传送速率的最大值
例题#

极限流量 = 各通道最大值之和
DMA
DMA(Direct Memory Access,直接存储器访问) 是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依赖于 CPU 的大量中断负载。否则,CPU 需要从来源把每一片段的资料复制到暂存器,然后把它们再次写回到新的地方。在这个时间中,CPU 对于其他的工作来说就无法使用。
DMA控制器 : DMAC ( Direct Memory Access Controller )
DMA的传输过程#

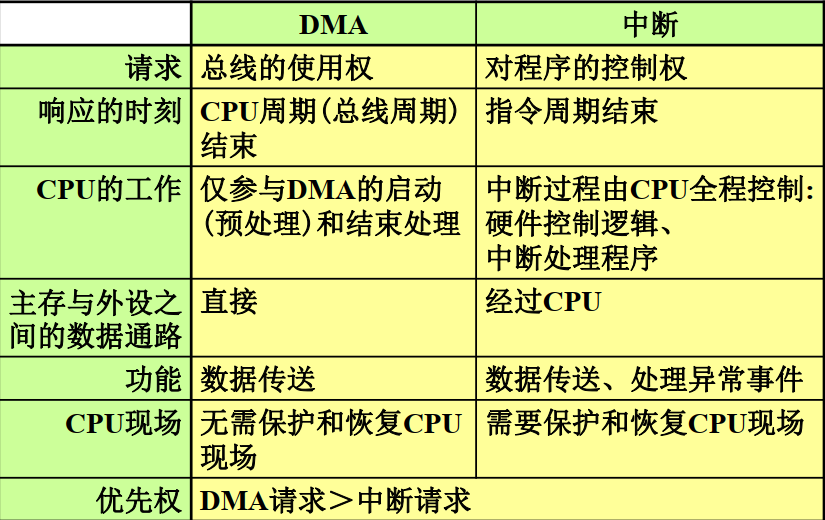
DMA和中断的比较#
- 中断和DMA的响应时间------指令周期结束后响应中断, CPU周期结束后响应DMA

DMA的工作机制#
1. 周期挪用 ( 窃取 ) 方式 --- 现代计算机#
DMA 控制器对主存储器存取数据常采用周期挪用方式, 即是在中央处理器执行程序期间, DMA控制器为存取数据, 强行插入使用主存储器若干周期;
两种情况 :
- 隐藏周期DMA : 窃取总线
- 暂停CPU方式 : 抢总线
特点 :
- 当主存工作速度都高于外设较多时, 可提高主存的利用率, 且对CPU的影响较小
2. 存储器分时方式 --- Motorala 6800系列#
- 原来的一个存取周期分割成两个时间片, 一片分给CPU, 一片分给DMAC
- 无需申请和归还总线
- 需要主存的工作速度提高一倍
- Motorola 6800系列8位CPU
3. 停止CPU方式 --- 早期计算机#
- DMAC : 申请总线 --> 独占总线 --> 释放总线
- 控制简单 ; 主存利用率不高
4. 扩展时钟周期方式#
两道例题#
例题1

例题2

两次传输 ( 中断 ) 的间隔时间 :
每次传输中断服务时间 :
因此, CPU用于该外设I/O时间占整个CPU时间的百分比为 :
两次DMA传输的间隔时间 :
每次DMA预处理时间 :
百分比 :

JAVA NIO知识点总结(3)——通道Channel的原理与获取方法
通道用于数据的传输,缓冲区用于数据的存取。
什么是通道
通道( Channel):由 java.nio.channels 包定义的。 Channel 表示 IO 源与目标打开的连接。Channel 类似于传统的“流”。只不过 Channel本身不能直接访问数据, Channel 只能与Buffer 进行交互。
那么通道与流有什么区别呢?带着这样的问题,我们来看看什么是通道:
之前已经说过,应用程序与磁盘之间的数据写入或者读出,都需要由用户地址空间和内存地址空间之间来回复制数据,内存地址空间中的数据通过操作系统层面的IO接口,完成与磁盘的数据存取。在应用程序调用这些系统IO接口时,由CPU完成一系列调度、任务分配,早先这些IO接口都是由CPU独立负责。所以当发生大规模读写请求时,CPU的占用率很高。
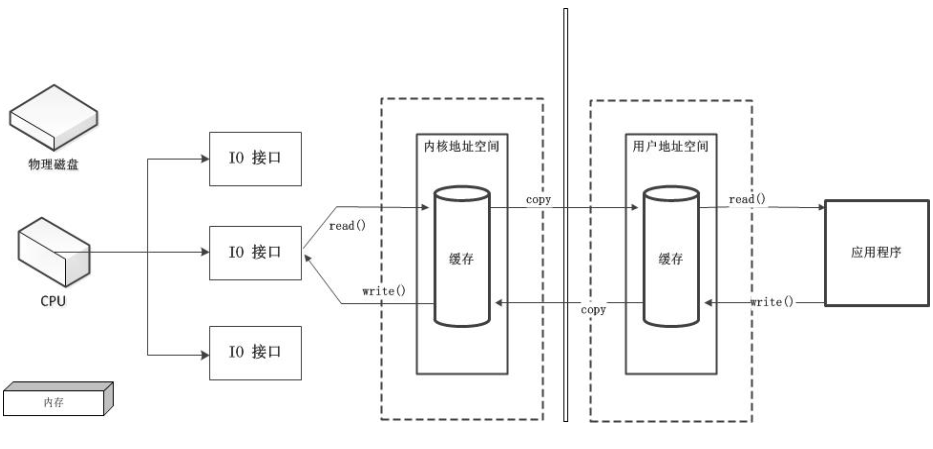
之后,操作系统为了避免CPU完全被各种IO接口调用占用,引入了DMA(直接存储器存储)。当应用程序对操作系统发出一个读写请求时,会由DMA先向CPU申请权限,申请到权限之后,内存地址空间与磁盘之间的IO操作就全由DMA来负责操作。这样,在读写请求的过程中,CPU不需要再参与,CPU去做其他事情。当然,DMA来独立完成数据在磁盘与内存空间中的来去,需要借助于DMA总线。但是当DMA总线过多时,大量的IO操作也会造成总线冲突,即也会影响最终的读写性能。

为了避免DMA总线冲突对性能的影响,后来便有了通道的方式。通道,它是一个完全独立的处理器。CPU是中央处理器,通道本身也是一个处理器,专门负责IO操作。既然是处理器,通道有自己的IO命令,与CPU无关。它更适用于大型的IO操作,性能更高。

总结几个要点:
直接存储器DMA有独立总线。
但在大量数据面前,可能会存在总线冲突,还是需要CPU来处理。
通道是一个独立的处理器
DMA方式还是需要向CPU申请DMA总线的。
通道有自己的处理器,适合与大量IO请求的场景,数据传输直接通过通道进行传输,不再需要请求CPU
(本文出自oschina的happyBKs的博文:https://my.oschina.net/happyBKs/blog/1595866)
如何获取通道
获取通道一般有以下两种主要方式:
获取通道的一种方式是对支持通道的对象调用getChannel() 方法。支持通道的类如下:
FileInputStream
FileOutputStream
RandomAccessFile
DatagramSocket
Socket
ServerSocket
获取通道的其他方式是使用 Files 类的静态方法 newByteChannel() 获取字节通道。或者通过通道的静态方法 open() 打开并返回指定通道。
下面我们看一组例子:
我们展示了三种将一个文件通过通道、缓冲区复制出另一个文件的方法:请注意获取通道的方式的不同,以及建立缓冲区方式的不同。
package com.happybks.nio.nio;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.channels.FileChannel.MapMode;
import java.nio.file.OpenOption;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
import org.junit.Test;
/**
*
* 一、通道(Channel):用于源节点与目标节点的连接。
* 在Java NIO中负责缓冲区中数据的传输。
* Channel本身不存储数据,因此需要配合缓冲区进行传输(就像铁路必须配合火车才能完成乘客的运输)
*
* 二、通道的主要实现类
* java.nio.channels.Channel接口:
* |-- FileChannel 用于本地文件数据传输
* |-- SocketChannel 用于网络,TCP
* |-- ServerSocketChannel 用于网络,TCP
* |-- DatagramChannel 用于网络,UDP
*
* 三、获取通道(jdk1.7之后有三种方式)
*
* 1、Java只针对支持通道的类提供了getChannel()方法 本地IO:
* FileInputStream/FileOutputStream
* RandomAccessFile
*
* 网络IO:
* Socket
* ServerSocket
* DatagramSocket
*
* 2、在JDK1.7中的NIO.2提供了针对各个通道提供了静态方法open()
*
* 3、在JDK1.7中的NIO.2的Files工具类的newByteChannel()
*
*
* 四、通道之间的数据传输
* transferForm()
* transferTo()
*
* @author happyBKs
*
*/
public class TestChannel {
/**
* 1、利用通道完成文件复制(非直接缓冲区)
* @throws IOException
*/
@Test
public void test1() throws IOException {
long start=System.currentTimeMillis();
FileInputStream fis = null;
FileOutputStream fos = null;
// 1、获取通道
FileChannel inChannel = null;
FileChannel outChannel = null;
try {
fis = new FileInputStream("D:/Test/NIO/1.jpg");
fos = new FileOutputStream("D:/Test/NIO/2.jpg");
inChannel = fis.getChannel();
outChannel = fos.getChannel();
// 2、分配指定大小的缓冲区
ByteBuffer buf = ByteBuffer.allocate(1024);
// 3、将通道中的数据存入缓冲区
while (inChannel.read(buf) != -1) {
buf.flip();
// 4、将缓冲区中的数据写入通道中
outChannel.write(buf);
buf.clear();// 清空缓冲区
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if (outChannel != null) {
outChannel.close();
}
if (inChannel != null) {
inChannel.close();
}
if (fos != null) {
fos.close();
}
if (fis != null) {
fis.close();
}
long end=System.currentTimeMillis();
System.out.println(end-start);
}
}
//2、使用直接缓冲区完成文件的复制(内存映射文件的方式)
@Test
public void test2() throws IOException{
long start=System.currentTimeMillis();
final Path path=Paths.get("D:/", "Test/","NIO/","1.jpg");
final OpenOption options=StandardOpenOption.READ;
FileChannel inChannel = FileChannel.open(path, options);
//注意:StandardOpenOption的CREATE_NEW代表如果已存在则创建失败;CREATE代表如果已存在则覆盖
//FileChannel outChannel = FileChannel.open(Paths.get("D:/Test/NIO/", "3.jpg"), StandardOpenOption.WRITE, StandardOpenOption.CREATE_NEW);
FileChannel outChannel = FileChannel.open(Paths.get("D:/Test/NIO/", "3.jpg"), StandardOpenOption.WRITE,StandardOpenOption.READ, StandardOpenOption.CREATE_NEW);
//注意:因为下面从通道得到的映射文件缓冲区的映射模式是读写模式,而这个outChannel只有写的打开选项,所以是不够,还要加入读配置。
final MapMode mode=MapMode.READ_ONLY;
final long position=0;
final long size=inChannel.size();
//这种利用通道通过映射文件建立直接缓冲区的方式和用缓冲区allocateDirect(int)的方式,两者的原理是一模一样的!
//只是申请直接缓冲区的方式不同。
MappedByteBuffer inMappedBuf = inChannel.map(mode, position, size);
MappedByteBuffer outMappedBuf = outChannel.map(MapMode.READ_WRITE, 0, inChannel.size());
//申请的空间都在物理内存中。
//注意:申请直接缓冲区,仅仅适用于ByteBuffer缓冲区类型,其他缓冲区类型不支持。
//与之前的通过流获得的通道不同,这种通过映射文件的方式是直接把数据通过映射文件放到物理内存中,还需要通道进行传输吗?是不是就不用了吧。我现在只需要直接向直接缓冲区中放就可以了,不需要通道。
//所以与之前相比,获取通道的操作都省去了,直接操作缓冲区即可。
//直接对缓冲区进行数据的读写操作
byte[] dst=new byte[inMappedBuf.limit()];
inMappedBuf.get(dst);
outMappedBuf.put(dst);
inChannel.close();
outChannel.close();
long end=System.currentTimeMillis();
System.out.println(end-start);
}
/**
* 通道之间的数据传输(直接缓冲区)
* @throws IOException
*/
@Test
public void test3() throws IOException{
FileChannel inChannel = FileChannel.open(Paths.get("D:/Test/NIO/", "1.jpg"), StandardOpenOption.READ);
FileChannel outChannel = FileChannel.open(Paths.get("D:/Test/NIO/", "4.jpg"), StandardOpenOption.WRITE,StandardOpenOption.READ, StandardOpenOption.CREATE_NEW);
inChannel.transferTo(0, inChannel.size(), outChannel);
//outChannel.transferFrom(inChannel, 0, inChannel.size());
inChannel.close();
outChannel.close();
}
}
第一种方式其实还是从流中获取通道。缓冲区用的是缓冲区allocate的非直接缓冲区。
第二种是用通道类本身的静态方法打开一个对应类型的通道。缓冲区用的是通过映射文件申请的直接缓冲区。注意内存映射文件MappedByteBuffer本质上与前面介绍的通过缓冲区类的allocateDirect(int)获取直接缓冲区的方式是本质上一样、方式上不同的。且内存映射文件MappedByteBuffer只有ByteBuffer支持,其他六种类型缓冲区不支持。
利用内存映射文件MappedByteBuffer,可以不要通过通道去完成读写,请看例子中,我们从活动获取了内存映射文件之后,直接操作的是两个内存映射文件MappedByteBuffer。
注意内存映射文件MappedByteBuffer和通道的读写模式的权限要匹配,否则会报错。
StandardOpenOption.CREATE_NEW和StandardOpenOption.CREATE的区别:
StandardOpenOption.CREATE_NEW 如果文件存在就创建;如果不存在则报错。你可以理解为二奶小三,就是要破坏别人家庭干掉原配,如果人家是单身狗她反而觉得没挑战。
StandardOpenOption.CREATE 如果文件存在就创建;如果不存在也创建。即不管存不存在,文件都创建,而且新的会覆盖旧的。
第三种方式仍是用通道类本身的静态方法打开一个对应类型的通道。但它完全利用通道完成整个数据传输,代码中没有任何缓冲区。
我们最后来看看实际非直接缓冲区和内存映射文件直接缓冲区,哪种方式的效率高,高多少。
我们将刚才的1.jpg等都换成小电影。别误会:)我找了个《XX动物城》,大约1.5G
但是我今天的实验做得比较失败,不知道是不是windows自身有什么样的缓存策略,还是什么原因,我发现allocateDirect与allocate并有没什么太大性能差别,而且缓冲区大小设置大了,也不能完全断定性能会提高。
@Test
public void test1() throws IOException {
long start=System.currentTimeMillis();
FileInputStream fis = null;
FileOutputStream fos = null;
// 1、获取通道
FileChannel inChannel = null;
FileChannel outChannel = null;
try {
fis = new FileInputStream("D:/Test/NIO/疯狂动物城1.mkv");//("D:/Test/NIO/1.jpg");
fos = new FileOutputStream("D:/Test/NIO/疯狂动物城2.mkv");//("D:/Test/NIO/2.jpg");
inChannel = fis.getChannel();
outChannel = fos.getChannel();
// 2、分配指定大小的缓冲区
ByteBuffer buf = ByteBuffer.allocate(1024);
// 3、将通道中的数据存入缓冲区
while (inChannel.read(buf) != -1) {
buf.flip();
// 4、将缓冲区中的数据写入通道中
outChannel.write(buf);
buf.clear();// 清空缓冲区
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if (outChannel != null) {
outChannel.close();
}
if (inChannel != null) {
inChannel.close();
}
if (fos != null) {
fos.close();
}
if (fis != null) {
fis.close();
}
long end=System.currentTimeMillis();
System.out.println("非直接缓冲区耗时(ms):"+(end-start));
}
}我运行了好几遍:
非直接缓冲区耗时(ms):37795非直接缓冲区耗时(ms):29793非直接缓冲区耗时(ms):26636非直接缓冲区耗时(ms):45328
即使我把非直接缓冲区大小从1024调大10倍到10240,速度好像是快一些,但是还是差不太多
非直接缓冲区耗时(ms):26174非直接缓冲区耗时(ms):20005之后我将allocate方法改为allocateDirect,使用1024大小缓冲区对比实验:发现耗时真的变快了
直接缓冲区耗时(ms):18233
直接缓冲区耗时(ms):17599直接缓冲区耗时(ms):18339我把非直接缓冲区大小从1024调大10倍到10240,速度几乎完全一样,没什么提升
直接缓冲区耗时(ms):17153直接缓冲区耗时(ms):17333
但是诡异的事情发生了:我这个时候再运行第一个非直接缓冲区的例子,居然1024大小的非直接缓冲区也能有18秒左右的时间完成。
非直接缓冲区耗时(ms):18905所以,我看别的资料介绍的一些实验结论今天无法得到证实了,我只把那些经验之谈记下来把:
利用内存映射文件直接缓冲区来通道传输数据 要比 直接缓冲区来的快、性能高;但是内存映射文件直接缓冲区由于是os管理下的内存空间,所以垃圾的回收有时会存在回收问题,现象就是文件已经传输完毕,但是整个程序会有时卡住。但是,今天我的实验结果却完全没有这样的体验,也不能作证这样的观点。如果有哪位这方面了解的多,欢迎分享,尤其是分享code,我想多是一些典型例子。
分散(Scatter)和聚集(Gather)
分散读取( Scattering Reads)是指从 Channel 中读取的数据“分散” 到多个 Buffer 中。
注意:按照缓冲区的顺序,从 Channel 中读取的数据依次将 Buffer 填满。

聚集写入( Gathering Writes)是指将多个 Buffer 中的数据“聚集”到 Channel。
注意:按照缓冲区的顺序,写入 position 和 limit 之间的数据到 Channel 。

*
* 五、分散(Scatter)与聚集(Gather)
* 分散读取(Scattering Reads):将通道中的数据分散到多个缓冲区中
* 聚集写入(Gathering Writes):将多个缓冲区中的数据聚集到通道中
*
*
* @author happyBKs
*
*/ //分散与聚集
@Test
public void test4() throws IOException{
RandomAccessFile raf1=new RandomAccessFile("D:/Test/NIO/t1.txt", "rw");
//1、获取通道
FileChannel channel1 = raf1.getChannel();
//2、分配指定大小的缓冲区
ByteBuffer buf1=ByteBuffer.allocate(100);
ByteBuffer buf2=ByteBuffer.allocate(1024);
//3、分散读取
ByteBuffer[] bufs={buf1,buf2};
channel1.read(bufs);
for(ByteBuffer byteBuffer:bufs){
byteBuffer.flip();
}
System.out.println(new String(bufs[0].array(),0,bufs[0].limit()));
System.out.println("-----------------------------------------");
System.out.println(new String(bufs[1].array(),0,bufs[1].limit()));
//4、聚集写入
RandomAccessFile raf2=new RandomAccessFile("D:/Test/NIO/t2.txt", "rw");
FileChannel channel2 = raf2.getChannel();
channel2.write(bufs);
channel2.close();
raf2.close();
channel1.close();
raf1.close();
}
程序运行的结果为:
控制台输出:
直接与非直接缓冲区的要点
字节缓冲区要么是直接的,要么是非直�
-----------------------------------------
�的。如果为直接字节缓冲区,则 Java 虚拟机会尽最大努力直接在此缓冲区上执行本机 I/O 操作。也就是说,在每次调用操作系统基础的一个本机 I/O 操作之前(或之后),虚拟机都会尽量避免将缓冲区的内容复制到中间缓冲区中(或从中间缓冲区中复制内容)。
直接字节缓冲区可以通过调用此类的 allocateDirect() 工厂方法来创建。此方法返回的缓冲区进行分配和取消分配所需成本通常高于非直接缓冲区。直接缓冲区的内容可以驻留在常规的垃圾回收堆之外,因此,它们对应用程序的内存需求量造成的影响可能并不明显。所以,建议将直接缓冲区主要分配给那些易受基础系统的本机 I/O 操作影响的大型、持久的缓冲区。一般情况下,最好仅在 直接缓冲区能在程序性能方面带来明显好处时 分配它们。
直接字节缓冲区还可以通过 FileChannel 的 map() 方法 将文件区域
文件生成:

注意这里生成的文件比原先的小,是因为我申请的两个缓冲区的大小之和比t1.txt中的内容字节数少,代码中我只分散读取了一次,所以写入的也只有t1.txt开头的那100+1024=1124字节的内容。


最后对通道常用方法的总结:
| 方 法 | 描 述 |
| int read(ByteBuffer dst) | 从 Channel 中读取数据到 ByteBuffer |
| long read(ByteBuffer[] dsts) | 将 Channel 中的数据“分散”到 ByteBuffer[] |
| int write(ByteBuffer src) | 将 ByteBuffer 中的数据写入到 Channel |
| long write(ByteBuffer[] srcs) | 将 ByteBuffer[] 中的数据“聚集”到 Channel |
| long position() | 返回此通道的文件位置 |
| FileChannel position(long p) | 设置此通道的文件位置 |
| long size() | 返回此通道的文件的当前大小 |
| FileChannel truncate(long s) | 将此通道的文件截取为给定大小 |
| void force(boolean metaData) | 强制将所有对此通道的文件更新写入到存储设备中 |
IO通道
本文原创,转载需标明原处。
通道,主要负责传输数据,相当于流,但流只能是输入或输出类型中的其一,而通道则可以兼并二者。
通道的基类是:Channel
- boolean isOpen()
- void close()
通道有同步方式和异步方式。
- 同步方式:亲力亲为,不交给他人来做。
- 异步方式:需要等待的事情,交给他人来做。做完之后,可以自己接着做,也可以由他人继续接着做。
通道有阻塞方式与非阻塞方式。
- 阻塞方式:在做这件事时,可能需要等待,也可能不需要等待。
- 非阻塞方式:在做这件事之前,确保不需要等待。换句话说,确保不需要等待的时候,我才来做。例如,银行人多的时候,我就直接离开,没人的时候,我就进入。
同步方式的输入输出通道

上图表示出,同步方式的输入输出通道的数据流通。这些通道的基类主要是ReadableByteChannel,WritableByteChannel。
- ReadableByteChannel和WritableByteChannel,操作一个ByteBuffer进行读写字节数据。
- ScatteringByteChannel和GatheringByteChannel分别是ReadableByteChannel,WritableByteChannel强化版,不仅可以操作一个ByteBuffer,还可以操作一组ByteBuffer。
- FileChannel提供了更为快捷的操作,直接操作ReadableByteChannel和WritableByteChannel进行读写。
- ByteChannel仅仅只是ReadableByteChannel和WritableByteChannel的组合,因此自然也是那些同时继承了ReadableByteChannel和WritableByteChannel的Channel的基类。
- SeekableByteChannel(FileChannel是该类的唯一实现类),其表示不仅可以输入输出,还可以定位操作点,获取容量(文件大小)和缩减容量(文件大小)。
异步方式的输入输出通道

上图表示出,异步方式的输入输出通道的数据流通。
异步方式的具体通道类有两个,分别是AsynchronousSocketChannel和AsynchronousFileChannel。
输入输出通道
整合所有输入输出的通道,可以有五种源头类型的通道:文件,网络,管道,输入流,输出流。

可使用非阻塞方式的通道(以下简称可非阻塞通道)
这类通道的基类是SelectableChannel,默认是阻塞,通过方法configBlocking(boolean)设置是否阻塞,方法isBlocking()查看是否阻塞。

上图表示出具体的可非阻塞通道类,以及表示出非阻塞方式所使用到的各组件之间的关系图。
具体怎么使用,可以参考其它相关的文章,最重要还是记得一点,非阻塞的概念就是确保这件事情不需要等待的时候才去做。怎么确保,selector的select()系列方法,这些方法会阻塞,阻塞到它检测到那些事情不需要等待了,就会让我去做。
需要注意的是,在使用非阻塞方式的方法时,必须先使用configBlocking(false),设置为非阻塞。
异步方式的通道
异步的概念,就是把需要等待的事情,委托给他人来做,做完的时候,可以选择自己接着做,也可以继续由受委托的人接着做。
那么异步有两种结果,一种是自己接着做,一种是他人接着做。
自己接着做的方式,操作方法的返回值是一个Future对象,使用这个对象可以检测完成进度。
- boolean isDone():测试是否完成。
- boolean isCanceled():测试异步运行是否被中止。
- boolean cannel(boolean):中止异步运行,并返回是否中止成功。
- V get()/get(long, TimeUnit):有些操作需要获取运行的返回值,如读取时,需要知道读取的字节数。但如果异步运行未完成或未中止,就会进入阻塞。
他人接着做的方式,操作参数里需要传入一个CompletionHandler对象,这个对象的方法将由异步线程来调用。
- void completed(V result, A attachment):完成时异步运行的方法。
- void failed(Throwable exc, A attachment):失败时异步运行的方法。
异步方式的通道基类是AsynchronousChannel,但这个类仅仅只是一个身份类,并没有提供任何操作方法。它的子类有:
- AsynchronousFileChannel
- AsynchronousByteChannel:这是一个接口,表示不仅具有异步方式,同时是输入输出字节类型的通道。但唯一的实现类为AsynchronousSocketChannel。
- AsynchronousServerSocketChannel
- AsynchronousSocketChannel
其它通道
- NetworkChannel:网络通道,用于网络的通道。
- InterruptibleChannel:表示线程被中止时,可以中断输入输出的通道。
通道的建立
一般使用静态方法open建立,其它方式的建立,如下图:

待续更新……
1 阻塞IO
传统的 IO 流都是阻塞式的。也就是说,当一个线程调用 accept(),read() 或 write()时,该线程被阻塞,直到有一些数据被读取或写入,该线程在此期间不能执行其他任务。
阻塞accept()
当没有客户端连接时,用户进程会一直阻塞。
阻塞IO读取
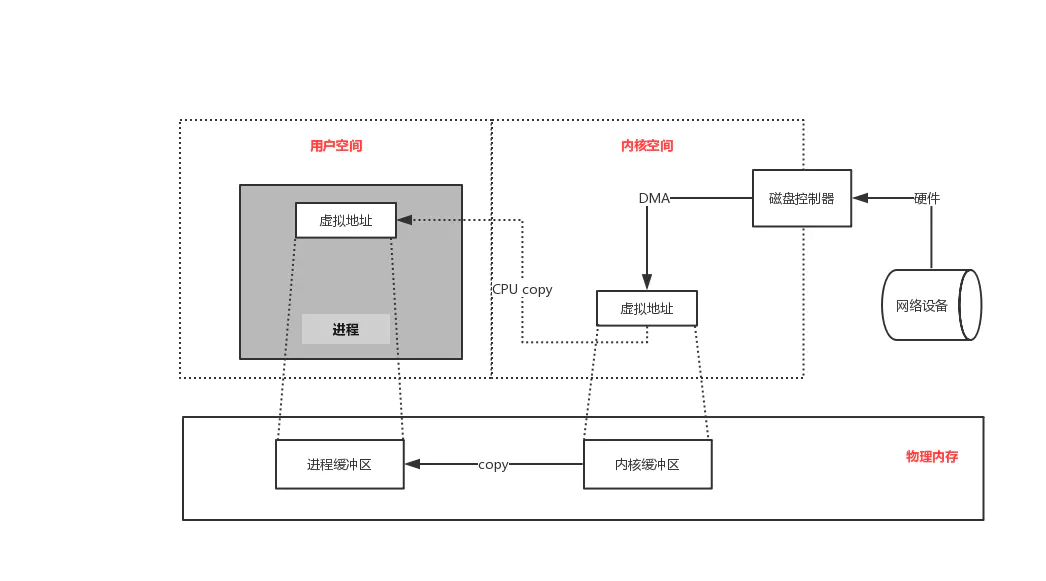
对于一次IO读取,数据会先从网络设备缓冲区被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的缓冲区,最后返回。
如果在网络设备缓冲区中没有发现数据会导致应用程序进程阻塞等待。
阻塞IO写入

对于一次IO写入,数据会先应用程序的缓冲区被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到网络设备缓冲区,最后返回。
在网络阻塞严重的时候,由于网络设备的缓冲区数据无法发送到网络中,会一直堆积直到没有足够的内存来进行写操作,从而导致应用程序进程阻塞等待。
2 阻塞IO 单线程
@Test
public void test_server() throws Exception {
/** 创建服务器套接字通道 ServerSocketChannel **/
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
/** 绑定监听 InetSocketAddress **/
serverSocketChannel.bind(new InetSocketAddress("localhost", 8888));
/** 设置为阻塞IO模型 **/
serverSocketChannel.configureBlocking(true);
while (true){
System.out.println("阻塞等待客户端连接" );
SocketChannel socketChannel = serverSocketChannel.accept();
System.out.println("客户端连接成功");
ByteBuffer readbuf = ByteBuffer.allocate(100);
System.out.println("阻塞等待客户端请求数据" );
/**
* 等待 网络设备 --copy-->操作系统内核缓冲区
* 等待 操作系统内核缓冲区 --copy --> 用户内存
* 此函数一共经历2次拷贝等待
* **/
socketChannel.read(readbuf);
System.out.println("读取客户端请求数据成功" );
System.out.println(new String(readbuf.array()));
}
}
@Test
public void test_readcanunblock_client() throws Exception {
SocketChannel socketChannel = SocketChannel.open();
socketChannel.configureBlocking(true);
System.out.println("阻塞服务端端响应连接" );
socketChannel.connect(new InetSocketAddress("localhost", 8888));
System.out.println("连接服务端成功" );
/** 等待一段事件向客户端后向服务请求数据 **/
TimeUnit.SECONDS.sleep(30);
socketChannel.write(ByteBuffer.wrap("hello server".getBytes()));
}
由于整个接收请求和处理请求都是在同一个线程里,按照当前示例同时只能处理一个连接请求。如果某个请求很慢会导致其他请求阻塞。

阻塞IO 多线程
使用多线程技术将请求操作交给子线程完成,可以让多个请求同时处理。
@Test
public void test_server2() throws Exception {
/** 创建服务器套接字通道 ServerSocketChannel **/
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
/** 绑定监听 InetSocketAddress **/
serverSocketChannel.bind(new InetSocketAddress("localhost", 8888));
/** 设置为阻塞IO模型 **/
serverSocketChannel.configureBlocking(true);
while (true){
System.out.println("阻塞等待客户端连接" );
SocketChannel socketChannel = serverSocketChannel.accept();
System.out.println("收到客户端");
new BeginThread(socketChannel).start();
}
}
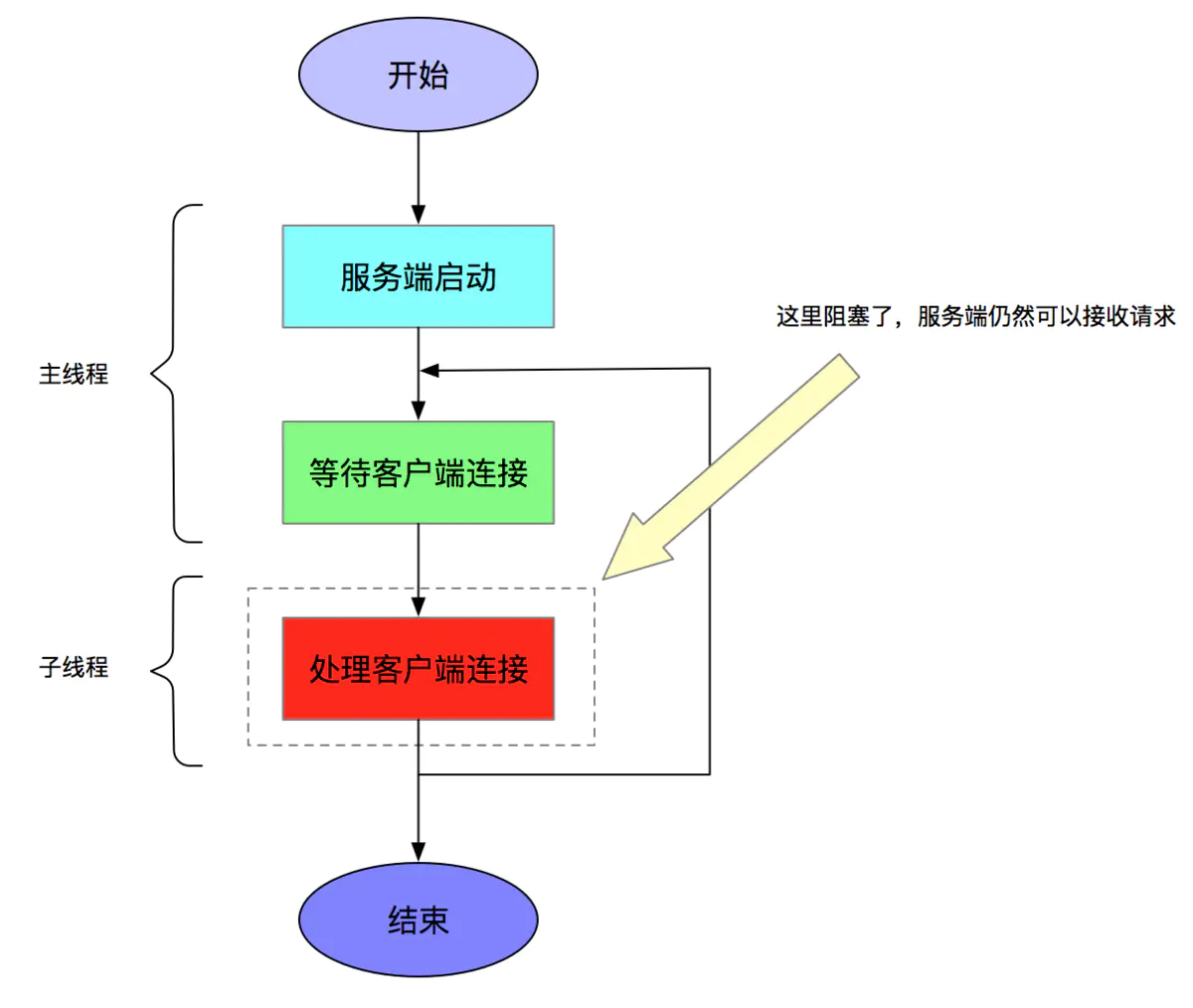
这种方式每次一个新的连接,都会启动一个线程。如果存在1百万个连接,那么需要创建1百万个线程,JVM会对限制进程线程的数量,如果超过这时会抛出异常。即使设置支持1百万个线程,那么按照一个连接最少64k内存来算,64k*1000000 约 61G,也足以让OOM将进程杀死
阻塞IO 线程池
为了解决同步阻塞IO面临一个链路需要一个线程处理的问题。后端通过一个线程池来处理多个客户端的请求。通过线程池可以灵活的调配线程池资源,设置线程的最大值,防止由于海量并发请求导致线程耗尽。
@Test
public void test_server3() throws Exception {
/** 创建服务器套接字通道 ServerSocketChannel **/
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
/** 绑定监听 InetSocketAddress **/
serverSocketChannel.bind(new InetSocketAddress("localhost", 8888));
/** 设置为阻塞IO模型 **/
serverSocketChannel.configureBlocking(true);
while (true){
System.out.println("阻塞等待客户端连接" );
SocketChannel socketChannel = serverSocketChannel.accept();
System.out.println("收到客户端");
ExecutorService executorService = Executors.newFixedThreadPool(10);
executorService.execute(new BeginThread(socketChannel));
}
}
阻塞IO 线程池弊端
使用线程池是为管控进程内的线程资源。当遇到海量的请求时,线程池内部的工作线程数量N,一定远远小于请求任务数量M。当线程池内阻塞队列中任务满时只能阻塞新请求或拒绝新请求。这就需要我们能快速处理请求。然而阻塞IO 发起read() 或 write()时,该线程都是同步阻塞的。阻塞时间取决于对方IO线程的处理速度和网络IO的传输速度。相当于我们应用程序需要依赖对方处理速度,导致我们应用程序的可靠性降低。
案例
如果我们应用程序在和一个故障节点通信。
-
1 阻塞IO读取故障节点的数据,由于读取输入流是阻塞的。因此同步阻塞时间又平时的10S变成60S
-
2 假如大量线程池内工作线程都在读取这个故障节点数据,那么由于线程池内工作线程处理缓慢,导致新的请求处理不过来,被放入阻塞队列中。
-
3 由于阻塞队列容量有限。当超过限制时只能阻塞或拒绝新的请求。
2 非阻塞IO
Java NIO 是非阻塞模式的。当一个线程调用 accept(),read() 或 write()时,该线程不会被阻塞,会直接返回。
非阻塞accept()
相对于阻塞IO,非阻塞会直接返回。当不存在客户端连接时serverSocketChannel.accept()会返回一个NULL。来告知应用程序没有客户端连接。
非阻塞IO读取
相对于阻塞IO读取,非阻塞如果在网络设备缓冲区中没有发现数据不会阻塞而会直接返回。我们可以通过判断返回读取数据大小。来判断网络设备缓冲区中是否存在数据读取。
非阻塞IO写入
相对于阻塞IO写入,在网络阻塞严重的时候,由于网络设备的缓冲区数据无法发送到网络中,会一直堆积直到没有足够的内存来进行写操作,这时并不会阻塞当前线程而是写入失败返回。我们可以通过判断返回写入数据大小。判断是否写入成功。
/**
* 非阻塞 IO
*/
@Test
public void test_UnBlock_server() throws Exception {
/** 创建服务器套接字通道 ServerSocketChannel **/
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
/** 绑定监听 InetSocketAddress **/
serverSocketChannel.bind(new InetSocketAddress("localhost", 8888));
/** 设置为非阻塞IO模式 **/
serverSocketChannel.configureBlocking(false);
boolean is_Run = true;
while (is_Run) {
/** 非阻塞IO模式,accept()会立刻返回,如果请求没有到达返回null **/
SocketChannel socketChannel = serverSocketChannel.accept();
/** 判断请求是否到达 **/
if (Optional.ofNullable(socketChannel).isPresent()) {
boolean is_Read = true;
while (is_Run) {
/** 设置为非阻塞IO模式 **/
socketChannel.configureBlocking(false);
ByteBuffer byteBuffer = ByteBuffer.allocate(100);
/** 非阻塞IO模式,read()会立刻返回,,如果请求没有数据到达返回0 **/
int read = socketChannel.read(byteBuffer);
if (read > 0) {
System.out.println(new String(byteBuffer.array()));
break;
} else {
System.out.println("客户端请求数据未到达");
TimeUnit.SECONDS.sleep(1);
}
}
} else {
System.out.println("客户端请求连接未到达");
TimeUnit.SECONDS.sleep(2);
}
}
}
@Test
public void test_UnBlock_client() throws Exception {
SocketChannel socketChannel = SocketChannel.open();
/** 设置为非阻塞IO模式 **/
socketChannel.configureBlocking(false);
/** 非阻塞IO模式,accept()会立刻返回 **/
socketChannel.connect(new InetSocketAddress("localhost", 8888));
/** 等待客户端连接成功 **/
while (!socketChannel.finishConnect()){
}
/** 等待一段事件向客户端后向服务请求数据 **/
TimeUnit.SECONDS.sleep(5);
socketChannel.write(ByteBuffer.wrap("hello server".getBytes()));
System.out.println("数据已发送");
while (true) {
TimeUnit.SECONDS.