
[转]如何判断一个文本文件内容的编码格式 UTF-8 ? ANSI(GBK)
转自:http://blog.csdn.net/jiangqin115/article/details/42684017
UTF-8编码的文本文档,有的带有BOM (Byte Order Mark, 字节序标志),即0xEF, 0xBB, 0xBF,有的没有。Windows下的txt文本编辑器在保存UTF-8格式的文本文档时会自动添加BOM到文件头。在判断这类文档时,可以根据文档的前3个字节来进行判断。然而BOM不是必需的,而且也不是推荐的。对不希望UTF-8文档带有BOM的程序会带来兼容性问题,例如Java编译器在编译带有BOM的UTF-8源文件时就会出错。而且BOM去掉了UTF-8一个期望的特性,即是在文本全部是ASCII字符时UTF-8是和ASCII一致的,即UTF-8向下兼容ASCII。
在具体判断时,如果文档不带有BOM,就无法根据BOM做出判断,而且IsTextUnicode API也无法对UTF-8编码的Unicode字符串做出判断。那在编程判断时就要根据UTF-8字符编码的规律进行判断了。
UTF-8是一种多字节编码的字符集,表示一个Unicode字符时,它可以是1个至多个字节,在表示上有规律:
1字节:0xxxxxxx
2字节:110xxxxx 10xxxxxx
3字节:1110xxxx 10xxxxxx 10xxxxxx
4字节:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
这样就可以根据上面的特征对字符串进行遍历来判断一个字符串是不是UTF-8编码了。应该指出的是UTF-8字符串的各个字节的取值有一定的范围,并不是所有的值都是有效的UTF-8字符,但是一般的应用的情况下这样的判断在对足够长的字符串及是比较精确了,而且实现也比较简单。具体的字节取值范围可以参见"Unicode Explained"一书中的6.4.3。另外BOM本身也符合3字节UTF-8字符编码规律,所以本方法对带BOM的UTF-8字符串也是有效的。
1. 判断文本是否UTF编码
在下面程序中对最大3字节长的UTF-8字符进行了判断,在实际情况下,几乎所有能用到的UTF-8字符最长就是3个字节
bool IsUTF8(const void* pBuffer, long size) { bool IsUTF8 = true; unsigned char* start = (unsigned char*)pBuffer; unsigned char* end = (unsigned char*)pBuffer + size; while (start < end) { if (*start < 0x80) // (10000000): 值小于0x80的为ASCII字符 { start++; } else if (*start < (0xC0)) // (11000000): 值介于0x80与0xC0之间的为无效UTF-8字符 { IsUTF8 = false; break; } else if (*start < (0xE0)) // (11100000): 此范围内为2字节UTF-8字符 { if (start >= end - 1) { break; } if ((start[1] & (0xC0)) != 0x80) { IsUTF8 = false; break; } start += 2; } else if (*start < (0xF0)) // (11110000): 此范围内为3字节UTF-8字符 { if (start >= end - 2) { break; } if ((start[1] & (0xC0)) != 0x80 || (start[2] & (0xC0)) != 0x80) { IsUTF8 = false; break; } start += 3; } else { IsUTF8 = false; break; } } return IsUTF8; }
2. 判断文件是否UTF-8编码:
bool CConvertCharset::IsUTF8File(const char* pFileName) { FILE *f = NULL; fopen_s(&f, pFileName, "rb"); if (NULL == f) { return false; } fseek(f, 0, SEEK_END); long lSize = ftell(f); fseek(f, 0, SEEK_SET); //或rewind(f); char *pBuff = new char[lSize + 1]; memset(pBuff, 0, lSize + 1); fread(pBuff, lSize, 1, f); fclose(f); bool bIsUTF8 = IsUTF8Text(pBuff, lSize); delete []pBuff; pBuff = NULL; return bIsUTF8; }
UTF-8 到底是什么意思?unicode编码简介
在电脑上处理文字的时候,你可能经常接触到一个名词,叫UTF-8.

你会不会觉得一丝疑惑,这到底是什么东西?
用一句话说明的话,UTF-8是一种编码格式,一个字节包含8个比特。
等会,什么是编码,什么又是比特?为什么要用这个东西?
那我们从基础说起,简单的介绍一下基本概念:
编码
我们都知道人有人的语言,计算机有计算机的语言,就是机器语言,所谓的二进制,0和1,1代表有一个信号,0表示没有信号。那怎么把人的语言翻译成机器语言呢,就需要一个字典,字典就是ASCII,如下图,左边是这个行为就是编码,左边是机器可以识别的ASCII码,右面是代表的字符,比如 00100001 代表 "!", 从左到右转换就是解码 (decode),从右到左就是编码 (encode)。
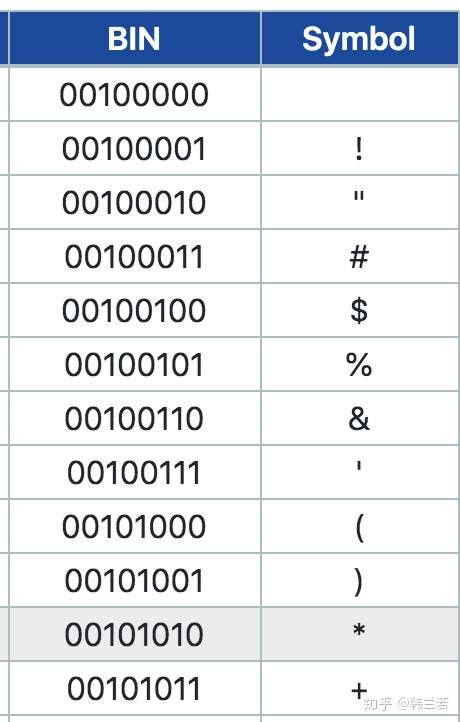
因为ASIIC码有8位数,每位是一个比特 (bit),8位就是一个字节 (byte)。除了第一位是0, 其他7位都可以有0 或者 1 两个选择,所以ASCII 一共可以表示 2^7 ,也就是128个字符。包括a-z 大小写,0-9 数字 和一些标点符号等。其中真正可读的只有95 个字符,其他的都是一些控制符,比如NUL,代表NULL。
对于英语来说, ASCII 包括所有的字母了,但是对于其他的语言来说,比如汉语,当然95个字符远远不够。有人说ASCII的第一位只能是0很浪费,如果也可以是1 的话, 就会多128个组合,一共256个。然而这样也不够。所以我们有:
多字节编码
上述编码是单字节编码, 也就是只有8个比特。如果想匹配多于256个字符的语言,一个字节显然不够,用两个字节的话,16比特,可以编码65536个字符,BIG-5就是一个双字节编码方式,它包括大多数中文繁体字,GB18030 则包括繁体和简体。比如:
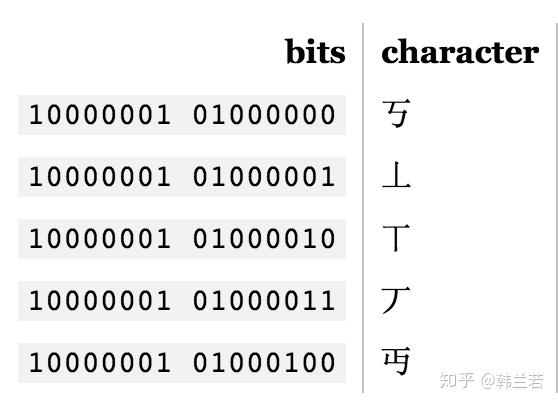
这样每种语言可能都有他们的编码体系,用着不同的字节,对于人和机器来说,这样都很容易混乱。所以我们有:
统一编码 Unicode
像上文说的,对于一些语言单字节编码不够,所以采用双字节,双字节也不够的时候可以采用三字节,甚至四字节,字节是不是越多越好呢?并不是,因为字节用的越多,那些用单字节就能表示的字符会增加很多个0, 浪费很多容量。比如 A 可能就是00000000 00000000 00000000 01000001, 这样就没有必要了。
如果一个人想写不同的语言,那他最好使用Unicode。 Unicode 用多少个字节呢?
0个。
因为Unicode其实不是一种编码, 而是定义了一个表, 表中为世界上每种语言中的每个字符设定了统一并且唯一的码位 (code point),以满足跨语言、跨平台进行文本转换的要求。在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。如下图。
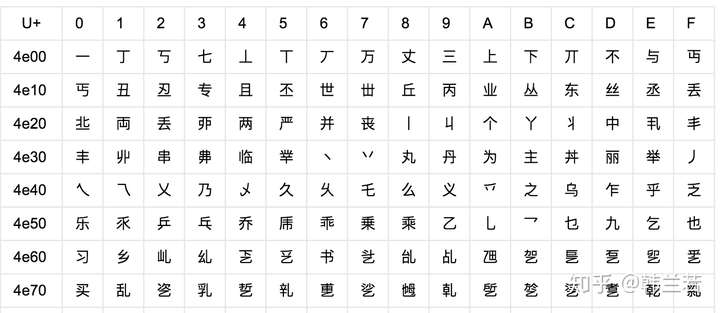
比如一个人想写一篇文章,包括英语和日语,单字节编码可以表示英语,但是显然不能满足他写日语,因为他需要3个字节才能表示一个『あ』,也就是11100011 10000001 10000010。 他可以用双字节编码,这样他只需要一个双字节,也就是00110000 01000010。所以他可以选择语言最高所需要的编码,也就是UTF-16. 如果他只需要写英语, 那UTF-8就可以。

UTF-8
UTF-8的特点是对不同范围的字符使用不同长度的编码。

上表表示如何从一个从Unicode 转化到UTF-8 , 对于前0x7F的字符,UTF-8编码和ASCII码是一一对应的。如果一个字符在000800-00FFFF 之间,那转化到UTF-8 需要用三字节模板,使用16个码位,每个x 就是一个码位。
比如『汉』这个字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001。
当然如果用16位更节约空间。对于中文而言,Unicode 16编码里面已经包含了GB18030里面的所有汉字(27484个字)。
Unicode的好处
如果一个语言支持Unicode, 说明它本身一个字符就是单字节,比如英语:
>>> string_e = 'hello'
>>> string_e[0]
'h'每个字符都是一个8位的字符串。所以在Python 里用字符串的截取功能[], 就会给我们第一个字节,同时也是一个字符 h。
如果是汉语,在UTF-8 中三个字节才能代表一个字符。如果我们同样使用截取[]:
>>> string = '汉字'
>>> string[0]
'\xe6'只会给我们返回一个「汉」这个字的第一个字节, 也就是11100110, 但是「汉」需要用11100110 10111100 10100010 才能表示。那我们要怎么才能截取汉字的第一个字符呢?
>>> string_u = string.decode('UTF-8')
>>> string_u[0]
u'\u6c49'
>>> print(string_u[0].encode('UTF-8'))
汉将「汉字」解码到Unicode, 这时再截取第一个字符就是一个 u 开头的Unicode了,再用UTF-8 编码, 返回的就是「汉」 这个字符了。
在进行汉字文本分析时可能会有更多应用,本文先讲到这里。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号