MongoDB分布式集群架构
MongoDB分布式集群架构
1. 主从复制
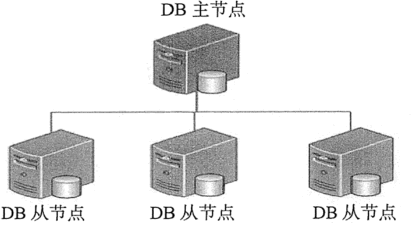
主从复制是 MongoDB 中最简单的数据库同步备份的集群技术,其基本的设置方式是建立一个主节点(Primary)和一个或多个从节点(Secondary)
-
主从复制比单节点的可用性好很多,可用于备份、故障恢复、读扩展等。集群中的主从节点均运行 MongoDB 实例,完成数据的存储、查询与修改操作。
-
主从复制模式的集群只能有一个主节点,提供所有的增、删、改、查服务,从节点不提供任何服务,也可以提供查询服务,减少主节点压力
-
每个从节点要知道主节点的地址,主节点记录在其上的所有操作,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
-
在主从复制的集群中,当主节点出现故障时,只能人工介入,指定新的主节点,从节点不会自动升级为主节点。同时,在这段时间内,该集群架构只能处于只读状态。
搭建MongoDB主从复制集群(一主一从)
新版本的MongoDB已经不再支持主从复制集群,所以以下面的配置,MongoDB无法启动。
MongoDB官方建议使用副本集代替主从复制
| 环境 | 参数 |
|---|---|
| MongoDB版本 | v5.0.3 |
| Master ip | 192.168.5.31 |
| Slave ip | 192.168.5.32 |
-
新建master的配置文件master.conf
事先建好所需的目录并授权
port=27017 dbpath=/data/mongodb/data logpath=/data/mongodb/log/mongod.log pidfilepath=/data/mongodb/log/mongod.pid bind_ip=192.168.5.31 fork=true logappend=true journal=true # 确定本机为master master=true -
新建slave的配置文件slave.conf
port=27017 dbpath=/data/mongodb/data logpath=/data/mongodb/log/mongod.log pidfilepath=/data/mongodb/log/mongod.pid bind_ip=192.168.5.32 fork=true logappend=true journal=true # 确定master的ip和端口 source=192.168.5.31:21017 # 确定本机为从 slave=true -
分别启动MongoDB
# master启动 /usr/local/mongodb/bin/mongod --config /usr/local/mongodb/conf/master.conf # slave启动 /usr/local/mongodb/bin/mongod --config /usr/local/mongodb/conf/slave.conf
2. 副本集
2.1 副本集的介绍
一组MongoDB副本就是一群MongoDB进程,这些进程维护同样的数据集,提供了冗余和高可用,是生产环境部署的基础。
一个MongoDB副本集包括三种节点:主节点、从节点和仲裁节点。
-
主节点负责处理客户端请求,读、写数据, 记录在其上所有操作的oplog
-
从节点定期轮询主节点获取操作日志,实现数据同步。属于异步复制,也因此,可能导致用户在从节点中读取到的数据和主节点不一致。
-
可添加一台节点作为“仲裁者”,不维护数据,负责维护节点间的心跳和响应其他副本集成员的请求。
由于副本集出现故障的时候,存活的节点必须大于副本集节点总数的一半,否则无法选举主节点,或者主节点会自动降级为从节点,整个副本集变为只读。因此,增加一个不容易出故障的仲裁节点,可以增加有效选票,降低整个副本集不可用的风险。仲裁节点可多于一个。
副本集与主从复制集群的异同:
- 都有一个主节点和若干个从节点
- 主从节点功能类似
- 主节点发生故障时,副本集可以自动投票,选举新的主节点,并引导其他从节点连接新的主节点。
MongoDB副本集是自带故障转移功能的主从复制
2.2 副本集架构


2.3 搭建MongoDB副本集
| 环境 | 参数 |
|---|---|
| MongoDB版本 | v5.0.3 |
| 主节点 | 192.168.5.31:27017 |
| 从节点 | 192.168.5.32:27017 |
| 仲裁节点 | 192.168.5.33:27017 |
-
新建各节点的配置文件,三台节点的配置文件可以一样
dbpath=/data/mongodb1 logpath=/data/mongodb1/log/mongodb.log logappend=true noprealloc=true port=27017 fork=true # 关键配置,指定副本集的名字 replSet=rs -
分别启动MongoDB
/usr/local/mongodb/bin/mongod --config /usr/local/mongodb/conf/mongod.conf -
登录任意一台主机
/usr/local/mongodb/bin/mongo --host 192.168.5.31 --port 27017 -
初始化副本集
因为还没有指定那台主机是主节点,哪台主机是从节点,所以需要先进行配置。
rs.initiate({"_id":"rs",members:[{"_id":1,"host":"192.168.5.31:27017",priority:100},{"_id":2,"host":"192.168.5.32:27017", priority:99},{"_id":3,"host":"192.168.5.33:27017",arbiterOnly:true}]})-
最外层的_id是副本集的名字,要与配置文件中的一致
-
members是副本集的服务器列表
-
_id 服务器的唯一id
-
host 服务器ip
-
priority 优先级。默认为1,优先级0为被动节点,不能成为活跃节点。优先级不为0则按照有大到小选出活跃节点。
-
arbiterOnly 仲裁节点
初始化好后,优先级最大的192.168.5.31成为了PRIMARY节点,也就是主节点。
-
副本集相关命令
# 查看副本集状态
rs.conf()
# 或者
rs.status()
# 添加副本
rs.add("ip:port")
# 删除节点
rs.remove("ip:port")
# 重新配置副本集(可以通过这种方式直接创建副本集)
config={"_id":"rs",members:[{"_id":1,"host":"192.168.5.31:27017",priority:100},{"_id":2,"host":"192.168.5.32:27017", priority:99},{"_id":3,"host":"192.168.5.33:27017",arbiterOnly:true}]}
rs.initiate(config)
2.4 验证副本集的可用性
-
在primary中创建一个集合,并插入一个文档进行测试
rs:PRIMARY> show dbs; admin 0.000GB config 0.000GB local 0.000GB rs:PRIMARY> use test switched to db test rs:PRIMARY> db.blog.insert({"title":"My Blog Post"}) WriteResult({ "nInserted" : 1 }) rs:PRIMARY> db.blog.find(); { "_id" : ObjectId("61922727374d5bc3c6e5f760"), "title" : "My Blog Post" } -
在secondary中进行验证
rs:SECONDARY> use test switched to db test rs:SECONDARY> db.blog.find() Error: error: { "topologyVersion" : { "processId" : ObjectId("619216c63a8215058148b536"), "counter" : NumberLong(4) }, "ok" : 0, "errmsg" : "not master and slaveOk=false", "code" : 13435, "codeName" : "NotPrimaryNoSecondaryOk", "$clusterTime" : { "clusterTime" : Timestamp(1636968456, 1), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId" : NumberLong(0) } }, "operationTime" : Timestamp(1636968456, 1) } rs:SECONDARY> rs.secondaryOk() rs:SECONDARY> db.blog.find() { "_id" : ObjectId("61922727374d5bc3c6e5f760"), "title" : "My Blog Post" }
3. 分片
参考:https://gitee.com/abcd1234567_1/mongo-db/blob/master/分片集群.md
3.1 分片集群介绍
在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据也足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
为什么使用分片集群
使用副本集的话,所有节点保存均为副本全集,单机占用空间大,搜索慢,主节点负载重(数据同步+业务读写),横向扩展效果差(即使增加节点也没啥卵用的意思)
主从缺点
- 中小应用做读写分离,可以缓解一定的并发压力,但是所有的节点都是副本的全集,某个时间点我们得同时给主和从节点加硬盘
- 当数据大了的时候,搜索就变慢了,因为无论主节点去搜索,还是从节点搜索,你都是对整体的数据全集去做搜索.如1w条数据, 无论主从都得在1w条数据里去搜索,搜索效率快不了,如:在一个从节点搜索要5秒,那么其他从节点也是需要5秒时间.这样只会增加服务器成本
- 数据量大对主节点的负担越来越重,一方面是搜索的压力,另一方面主节点数据发生变化后,都需要同步到其他的从节点,从节点越多,主节点的压力就越大
3.2 架构
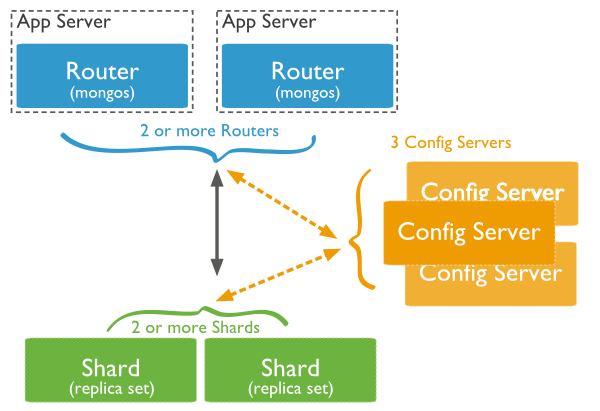
MongoDB分片集群有如下组件:
-
Shard Server
将库拆分,根据片键将数据拆分存储。
其基本思想:将集合分块,分散到若干片中,每个片只负责总数据的一部分,最终通过均衡器保证各分片数据量均衡。
-
Config Server
用于保存集群和分片的元数据,在集群启动最开始时建立,保存各个分片包含数据的信息。
分片集群的核心
-
Route Server
集群请求入口,本质上是个请求分发中心,将对应请求转发到对应shard分片服务器上,常规会配置多个mongos路由服务器,确保高可用。
Route Server 本身不保存数据,启动时从 Config Server 加载集群信息到缓存中,并将客户端的请求路由给每个 Shard Server,在各 Shard Server 返回结果后进行聚合并返回客户端。
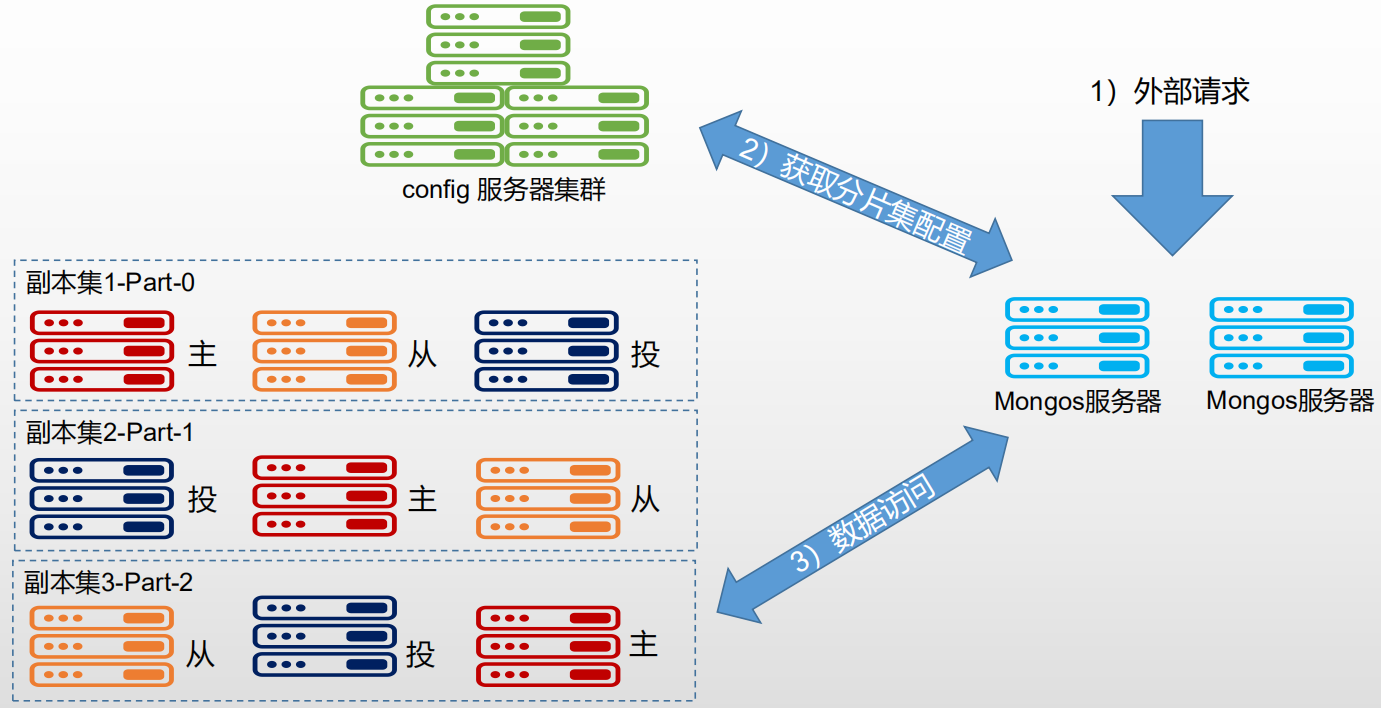
3.3 分片原理
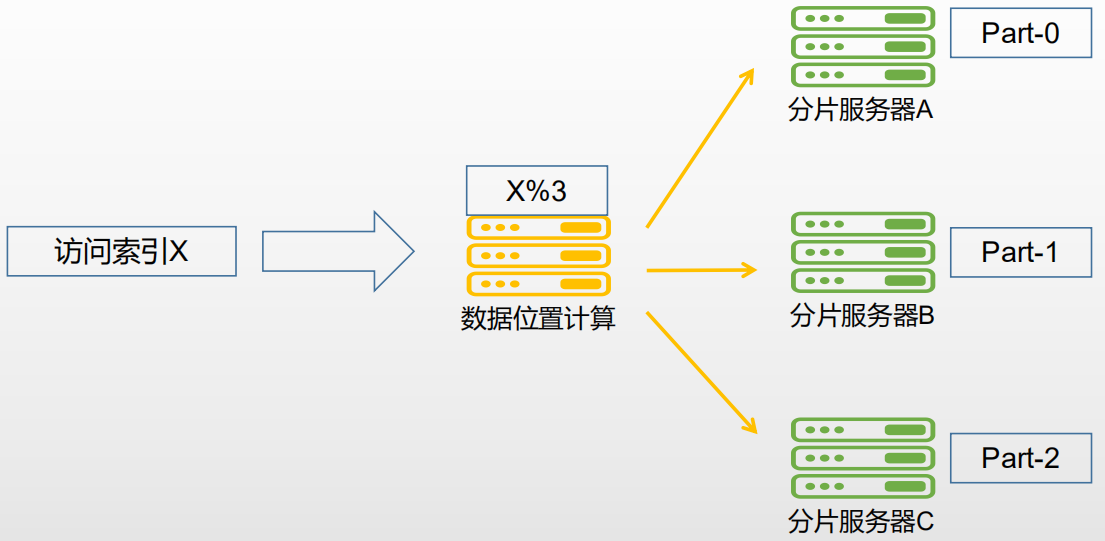
分片服务器上分别存储整个集群数据的一部分,所有分片服务器都能承担读写的压力,如果给三台分片都加入副本集,三台节点宕机都能有副本集能顶上
3.4 搭建MongoDB分片集
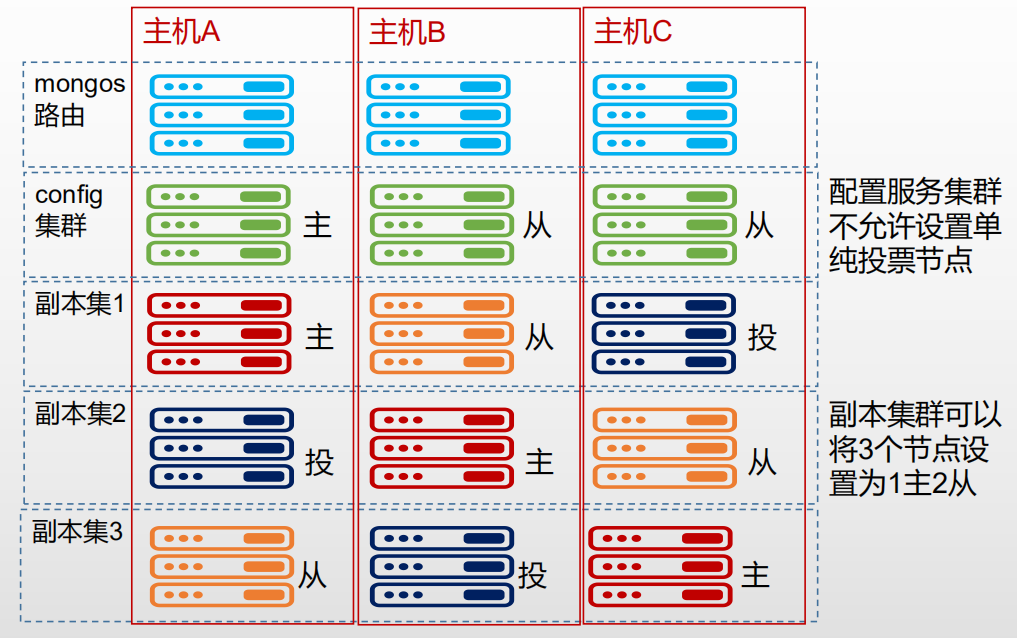
| 环境 | 参数 |
|---|---|
| MongoDB | v5.0.3 |
| 主机A IP | 192.168.5.31 |
| 主机B IP | 192.168.5.32 |
| 主机C IP | 192.168.5.33 |
- 主机规划

-
搭建Config集群
没有特别说明则以下步骤三台服务器都要做
-
创建相应目录
mkdir /data/mongodb/{data,log} -p mkdir /data/mongodb/data/confsvr -
创建配置文件
cd /usr/local/mongodb/ mkdir conf && cd conf cat > confsvr.conf << EOF dbpath=/data/mongodb/data/confsvr logpath=/data/mongodb/log/confsvr.log pidfilepath=/data/mongodb/confsvr.pid directoryperdb=true logappend=true replSet=confset bind_ip=0.0.0.0 port=27400 oplogSize=10000 fork=true configsvr=true EOF -
启动
/usr/local/mongodb/bin/mongod --config /usr/local/mongodb/conf/confsvr.conf -
初始化config服务副本集(任意一台主机执行)
# 进入主节点 /usr/local/mongodb/bin/mongo 192.168.5.31:27400 # 初始化副本集 rs.initiate({"_id":"confset",members:[{"_id":1,"host":"192.168.5.31:27400"},{"_id":2,"host":"192.168.5.32:27400"},{"_id":3,"host":"192.168.5.33:27400"}]})
-
-
搭建Shard集群
如果没有特别指明则以下步骤三台服务器都要做
-
创建相关文件夹
mkdir -p /data/mongodb/data/shard{1..3} -
创建配置文件
cd /usr/local/mongodb/conf/ cat > shard1.conf << EOF dbpath=/data/mongodb/data/shard1 logpath=/data/mongodb/log/shard1.log pidfilepath=/data/mongodb/shard1.pid directoryperdb=true logappend=true replSet=rs1 bind_ip=0.0.0.0 port=27101 oplogSize=10000 fork=true shardsvr=true EOF cat > shard2.conf << EOF dbpath=/data/mongodb/data/shard2 logpath=/data/mongodb/log/shard2.log pidfilepath=/data/mongodb/shard2.pid directoryperdb=true logappend=true replSet=rs2 bind_ip=0.0.0.0 port=27102 oplogSize=10000 fork=true shardsvr=true EOF cat > shard3.conf << EOF dbpath=/data/mongodb/data/shard3 logpath=/data/mongodb/log/shard3.log pidfilepath=/data/mongodb/shard3.pid directoryperdb=true logappend=true replSet=rs3 bind_ip=0.0.0.0 port=27103 oplogSize=10000 fork=true shardsvr=true EOF -
启动集群
/usr/local/mongodb/bin/mongod --config /usr/local/mongodb/conf/shard1.conf /usr/local/mongodb/bin/mongod --config /usr/local/mongodb/conf/shard2.conf /usr/local/mongodb/bin/mongod --config /usr/local/mongodb/conf/shard3.conf -
初始化分片数据副本集(任意一台主机执行)
# 初始化shard1 /usr/local/mongodb/bin/mongo 192.168.5.31:27101 rs.initiate({"_id":"rs1",members:[{"_id":1,"host":"192.168.5.31:27101"},{"_id":2,"host":"192.168.5.32:27101", arbiterOnly:true},{"_id":3,"host":"192.168.5.33:27101"}]}) # 初始化shard2 /usr/local/mongodb/bin/mongo 192.168.5.32:27102 rs.initiate({"_id":"rs2",members:[{"_id":1,"host":"192.168.5.31:27102"},{"_id":2,"host":"192.168.5.32:27102"},{"_id":3,"host":"192.168.5.33:27102", arbiterOnly:true}]}) # 初始化shard3 /usr/local/mongodb/bin/mongo 192.168.5.33:27103 rs.initiate({"_id":"rs3",members:[{"_id":1,"host":"192.168.5.31:27103", arbiterOnly:true},{"_id":2,"host":"192.168.5.32:27103"},{"_id":3,"host":"192.168.5.33:27103"}]})
-
-
配置mongos服务
如果没有特别指明则以下步骤三台服务器都要做
-
编辑配置文件
cd /usr/local/mongodb/conf cat > mongossvr.conf << EOF logpath=/data/mongodb/log/mongossvr.log pidfilepath=/data/mongodb/mongossvr.pid logappend=true bind_ip=0.0.0.0 port=20000 fork=true configdb=confset/192.168.5.31:27400,192.168.5.32:27400,192.168.5.33:27400 EOF -
启动mongos
注意:是mongos不是mongod
注意:要顺利启动mongos,需要保证config集群的副本集没有问题
/usr/local/mongodb/bin/mongos --config /usr/local/mongodb/conf/mongossvr.conf
-
-
mongos加入分片集群(任意一台主机操作)
# 连接到mongos /usr/local/mongodb/bin/mongo 192.168.5.31:20000 # 切换到admin数据库 use admin # 通过此命令与数据服务建立关系 db.runCommand({addshard:'rs1/192.168.5.31:27101,192.168.5.32:27101,192.168.5.33:27101'}) db.runCommand({addshard:'rs2/192.168.5.31:27102,192.168.5.32:27102,192.168.5.33:27102'}) db.runCommand({addshard:'rs3/192.168.5.31:27103,192.168.5.32:27103,192.168.5.33:27103'}) # 要声明哪一个数据库通过分片集来存储的,哪一个表通过分片集来存储的 # 开启分片数据库,数据表,指定分片索引field # 将test声明为分片数据库 db.runCommand({ enablesharding: 'test' }) # 自动建表,test数据库下的col_Student表,key:指定分片索引的字段 db.runCommand({ shardcollection: 'test.col_Student',key: {name:1} }) db.runCommand({ shardcollection: 'test.col_Score',key: {_id:"hashed"} }) #去db.collection.find的时候就会通过是hashed还是升序或降序的方式去判断在哪一个分片,通过相应的分片对你的搜索提供服务.同理对你的写入提供服务 #按照name进行升序排列 name:1 #按照name进行降序排列 name:-1 #按照hash排列 name:"hashed" #查看 show dbs use test show collections

 浙公网安备 33010602011771号
浙公网安备 33010602011771号