李宏毅机器学习组队学习打卡活动day05---网络设计的技巧
写在前面
报名了一个组队学习,这次学习网络设计的技巧,对应的是李宏毅老师深度学习视频的P5-p9。
参考视频:https://www.bilibili.com/video/av59538266
参考笔记:https://github.com/datawhalechina/leeml-notes
局部最小值和鞍点
在梯度下降的时候,优化有些时候会失败,即出现了梯度为零的点,但是梯度为零的点,不只有对应local minima(局部最小值),也有可能对应鞍点(saddle point)
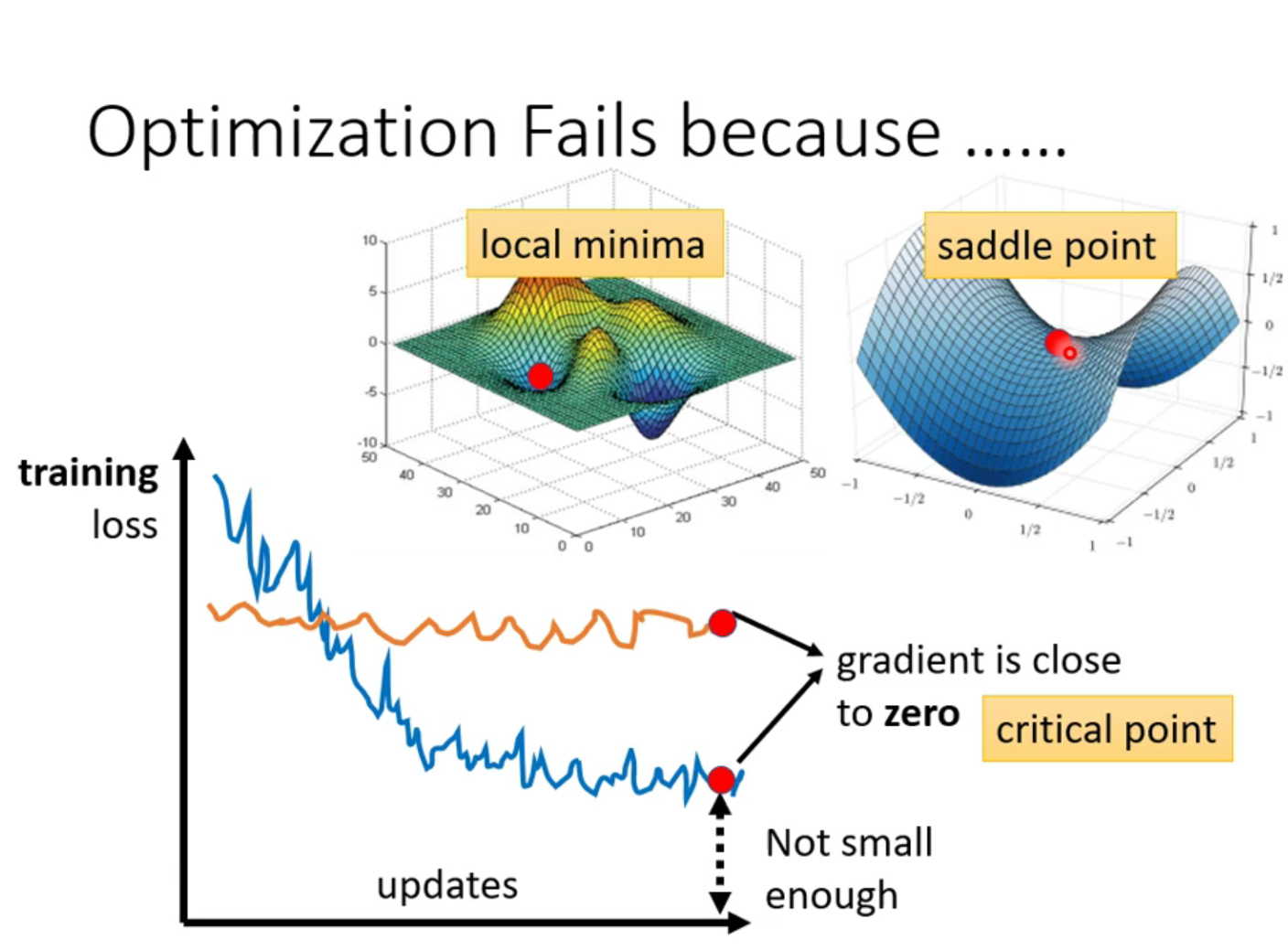
那么怎么判断是saddle point还是local minimal?

利用泰勒公式进行判断,如果是Critical point(一阶导数为零),那么第二项就为零,那我们只需要判断二阶微分的情况。

如果Hessian矩阵H的特征值全大于零,那么它就是Local minima; 如果特征值全小于零,那么它就是Local maxima; 如果特征值有大于零,又有小于零,那么这个点就是Saddle point
如果点卡在saddle point,那么沿着特征值为负的特征向量走。
例如:这个矩阵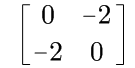 ,算得一个特征值为-2,特征向量为[1;1],只需沿着特征向量方向走就可以解决。
,算得一个特征值为-2,特征向量为[1;1],只需沿着特征向量方向走就可以解决。
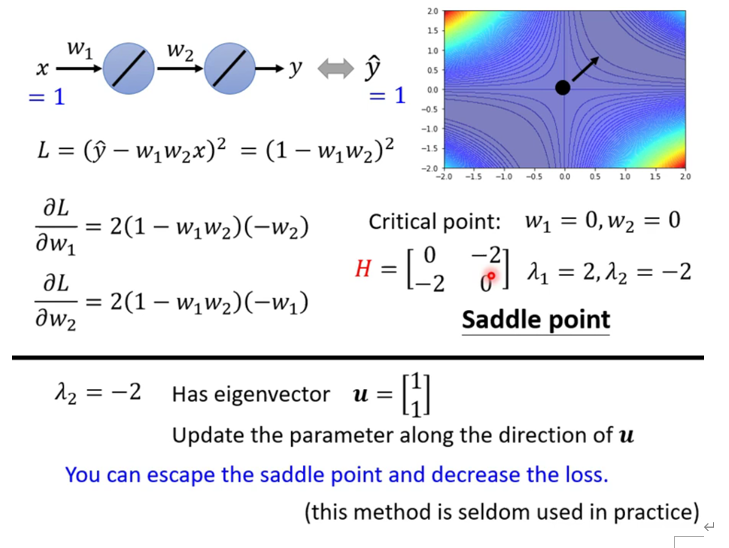
但是这个计算量太大,实际操作中不会这样用。
batch(批次) 和 momentum(动量)
batch
我们可以用Batch的思想来优化,可以将样本划分,对每一个小样本进行梯度下降。
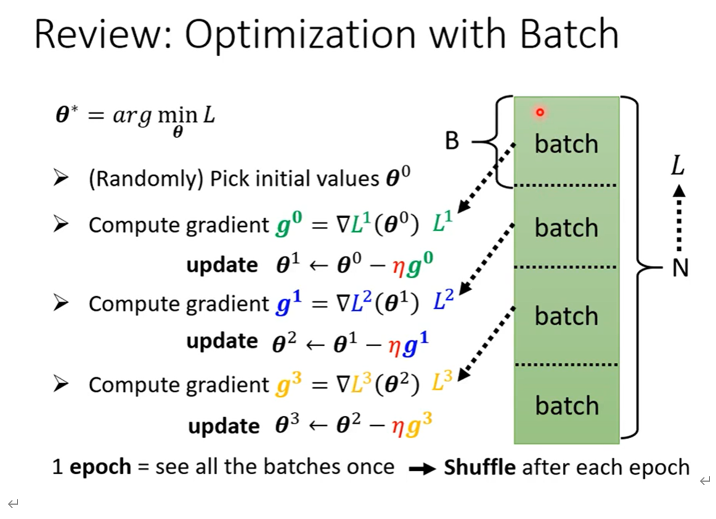
Small Batch v.s. Large Batch

利用GPU的平行计算,可以看出一次中batch size为100和batch size为1的计算时间差不多
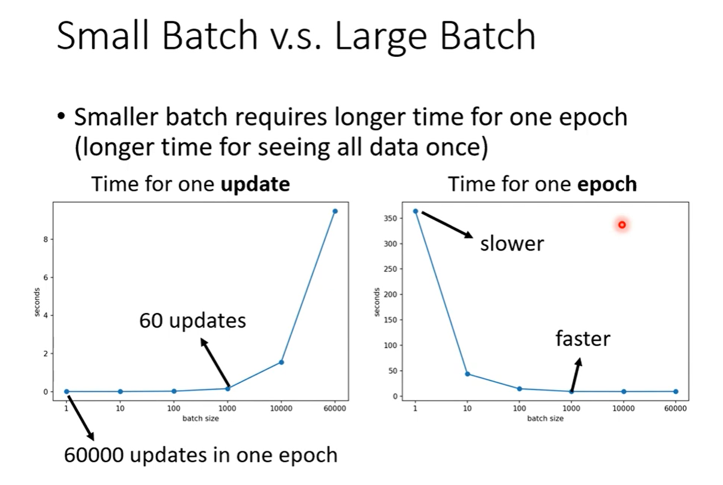
总体上来看,Smaller batch需要更多的时间。
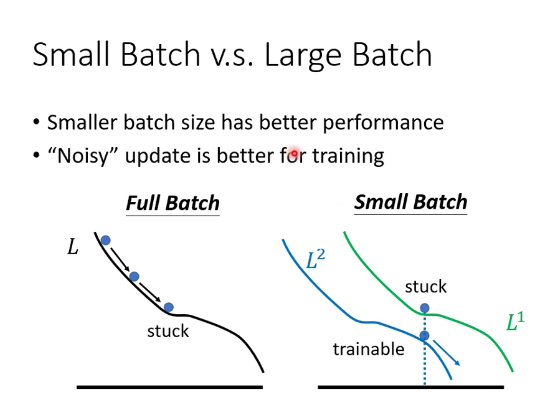
Small batch 会有更好的运行效果。

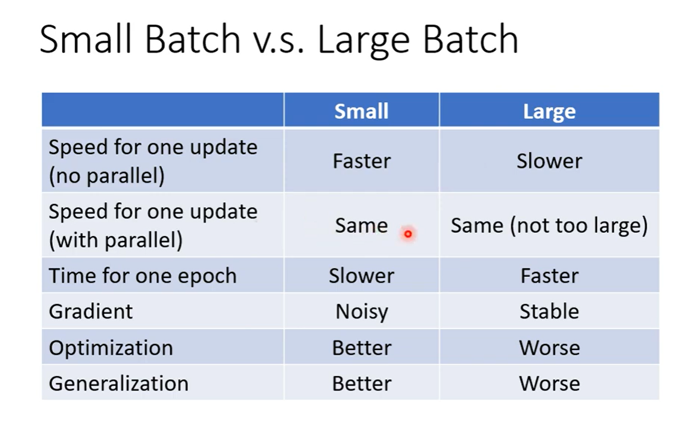
总结
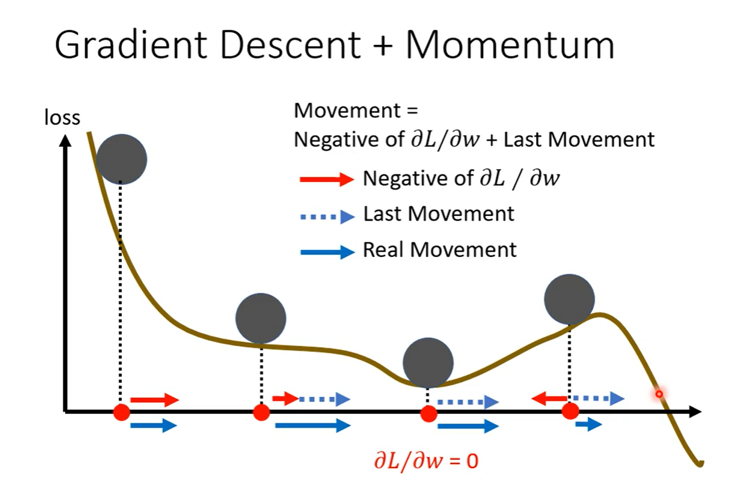
Moment
Moment通常会保持上一次的梯度下降趋势,即上一次的梯度下降趋势会对本次的梯度下降有影响。
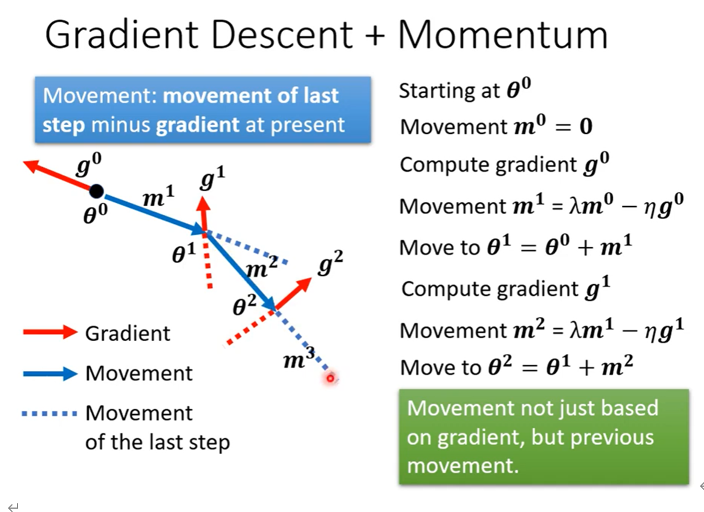
自动调节学习速率
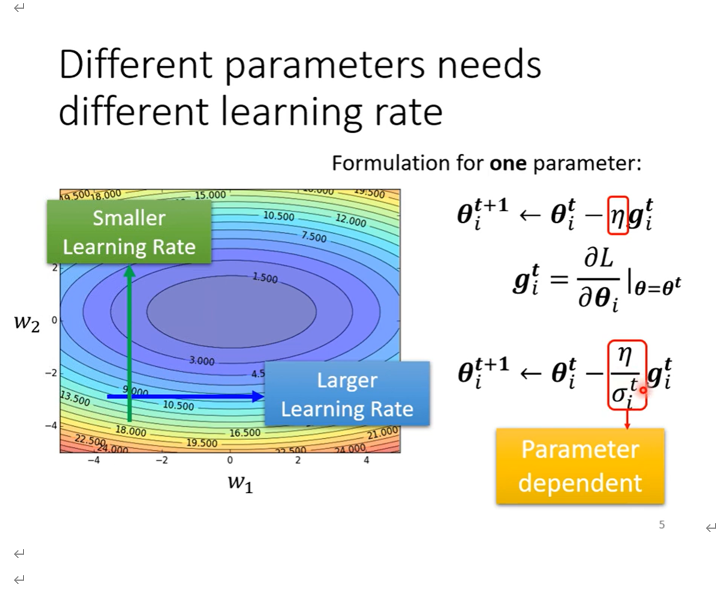
RMSProp
RMSProp 迭代方式:

Adam
Adam:RMSProp + Momentum

Suammary

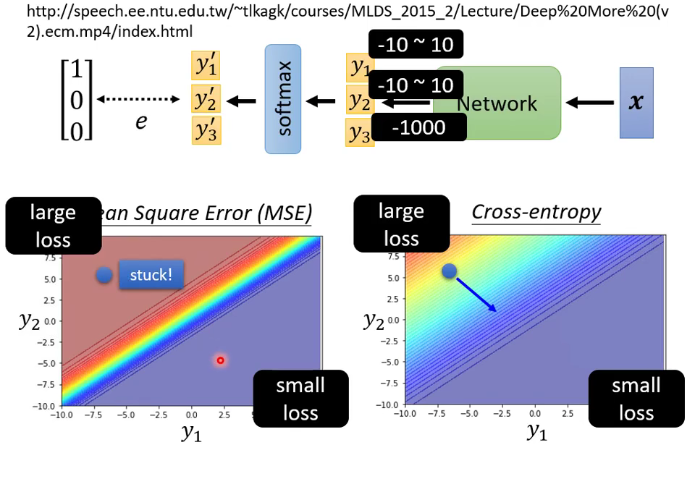
Loss 也会产生影响
Cross-entropy比 Mean Square Error更常用于分类。
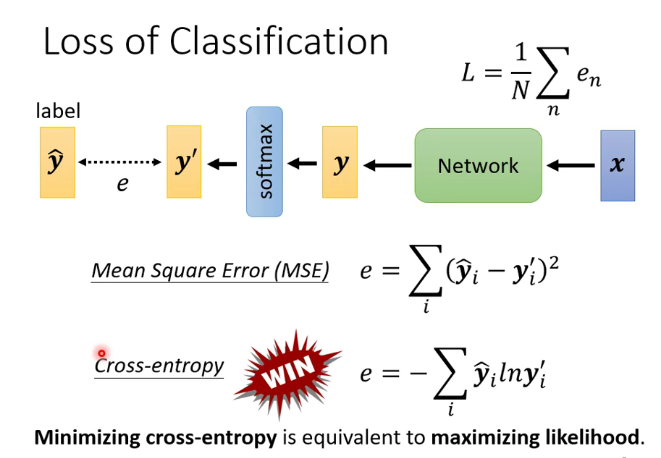
例子:
批次标准化(Batch Normalization)
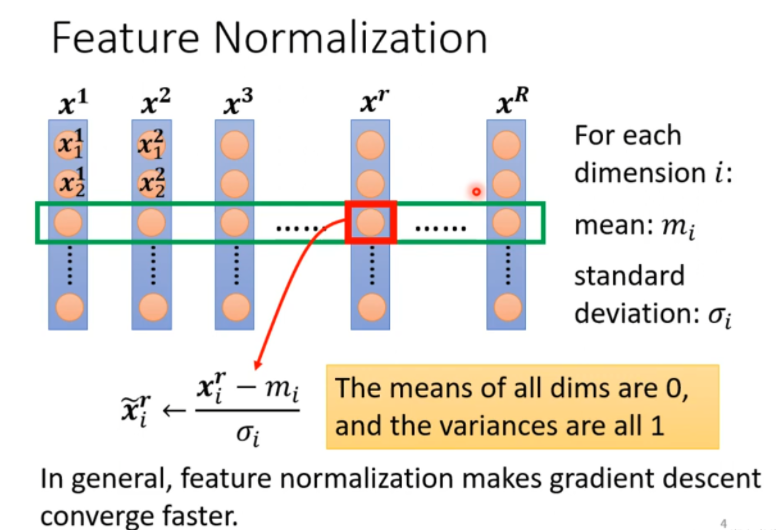
Feature Normalization
Feature Normalization的作用是 让\(x_i\)的范围设定相同
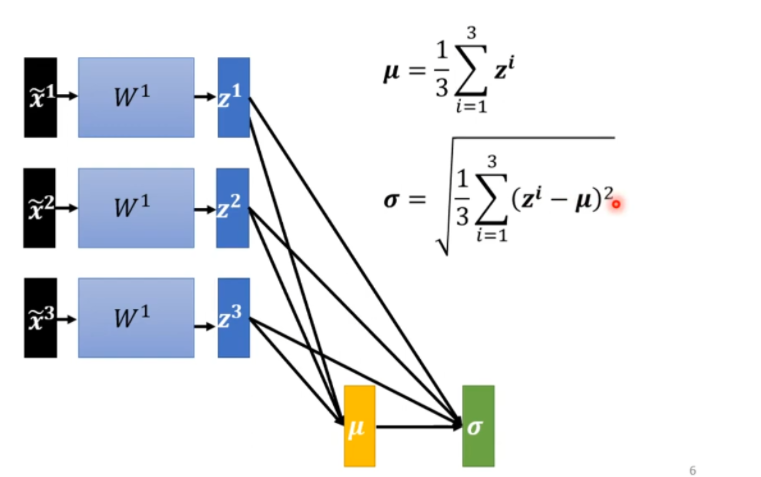
Considering Deep Learning
在深度学习中有多层,上一层的输出就是下一层的输入,如果对上一层的input进行处理,但是在下一层中运算导致数据之间也相差很大,同样地,也应该进行处理。
但是,当改变\(z^i\)的值的时候,会影响\(\mu\)和\(\sigma\),\(z^{(i+1)}\)的值也会发生改变,每一个计算都会改变,导致整个网络中中间结果特别多,所以我们要考虑分批处理,也就是Batch Normalization

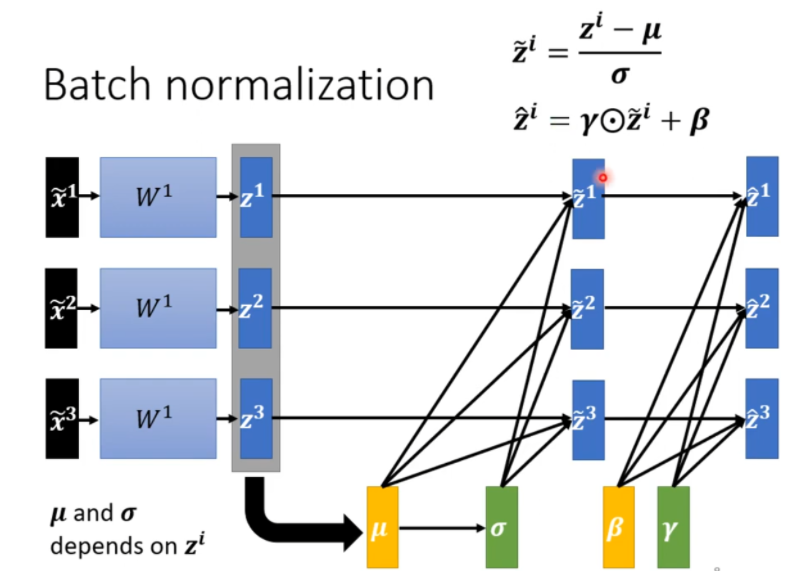
在求得之后,再将\(\gamma\)乘上\(\tilde{z}^i\)再加上\(\beta\)。而\(\beta\)和\(\gamma\)是单独训练出来的,为了防止\(\tilde{z}^i\)平均数为0,会给神经网络带来负面影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号