Cache
一.What is Cache
1. Cache是一个CPU缓存,位于CPU与内存之间的临时存储器,它的容量比内存小但读写速度快。
2. Cache可以分为ICac和DCache

二.What is it used for?
1.CPU做一次乘法运算只需要几个周期,而做一次内存访问可能需要上百个周期,可见cpu计算速度比内存访问速度快很多。
2.Cache解决了CPU运算速度和和内存读写速度不一致的问题(利用程序的时间局部性和空间局部性)。
三.How it works?
1.如何把内存数据放到Cache
假设我们主存中有32个块而我们的 Cache 一共有8个Cache 行( 一个 Cache 行放一行数据)。现在要把主存中的块 12 放到 Cache 里,应该怎么放呢?我们有三种方式。
全相连:可以放在Cache的任何位置;允许主存中每一字块映射到Cache中的任何一块位置上。通常采用昂贵的“按内容寻址”的相联存储器来完成。
直接映射:主存数据只能装入Cache中的唯一位置。若这个位置已有内容,则产生块冲突,原来的块将无条件地被替换出去。
组相连:将Cache空间分成大小相同的组,主存的一个数据块可以装入到一组内的任何一个位置(组内采取全相联映射)。例如2路组相连,一共有4组,所以可以放在0,1位置中的一个。
优缺点比较
全相连:优点石命中率高;缺点是每一次请求数据同Cache中的地址进行比较需要相当的时间,速度较慢。
直接映射:直接映像Cache优于全相联Cache,能进行快速查找,其缺点是当主存储器的组之间做频繁调用时,Cache控制器必须做多次转换。
组相连:组数越大,比较电路就越大,但Cache利用率更高,Cache miss发生的概率小。组相连数目越小,Cache经常发生替换,容易Cache-miss,但是比较电路比较小。
直接映射和全相连是Cache组相连的两种极端情况,
2.数据如何查询
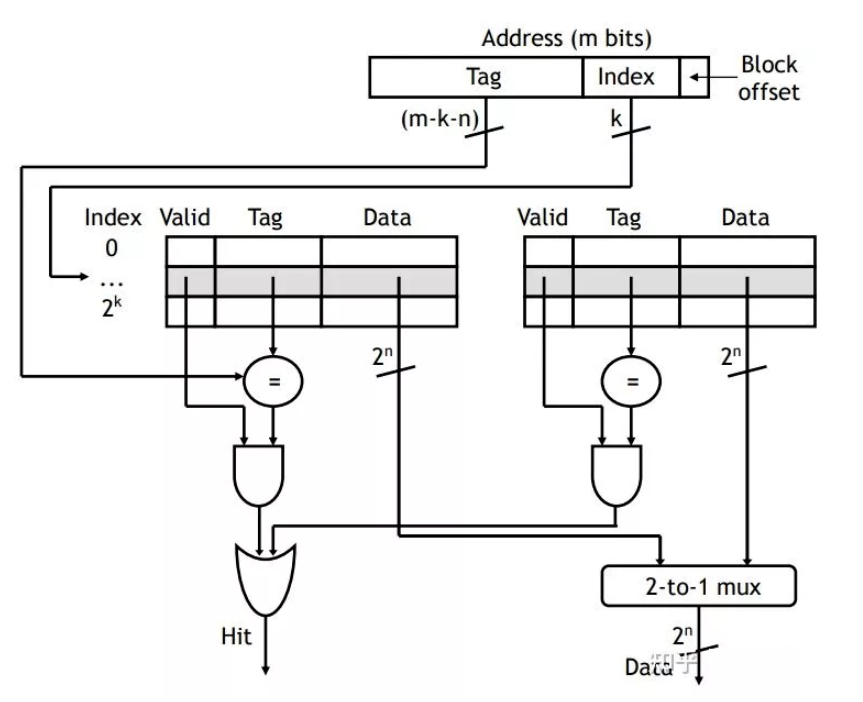
主存和Cache之间的数据交换单位都是以块为单位。由于采用了组相连,则还有几个bit(index)表的是存储到了哪个组。

这里index表示组,tag表示块,所以先比较index,再比较tag,若相等,则cache-hit。
3.数据如何被替换
随机:如果发生Cache miss里随机替换掉一块。(一般不采用)
LRU:(Least recently used). 最近使用的块最后替换。
FIFO) :先进先出。

4.发生写操作,Cache如何处理
通写:直接把数据写回Cache的同时写回主存。极其影响写速度.
回写:先把数据写回Cache, 然后当Cache的数据被替换时再写回主存。
通写队列:通写与回写的结合。先写回一个队列,然后慢慢往主存储写。如果多次写同一个数据,直接写这个队列。避免频繁写主存。
三.what's the problem with Cache?.
存在"Cache-miss"的问题
CPU从存储器提取数据时,会从一级cache到最后一级cache中依次寻找。若找到数据,就称为"Cache-hit",否则称为"Cache-miss"。
存在"Cache一致性"的问题
CPU的访问Cache数据与DDR的数据没有同步,从而造成执行错误。
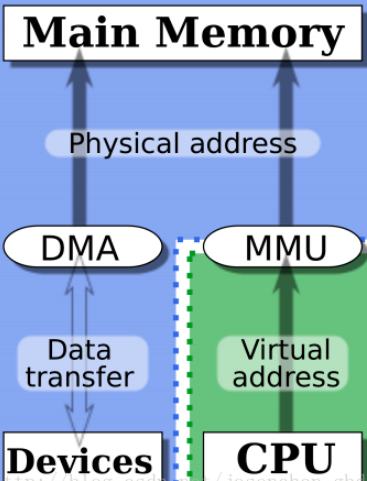
例1:CPU要访问DDR中的一块数据,那么这块数据会放在Cache中,之后DMA控制器直接将外设的数据放在DDR中,更新了刚刚的那一块CPU要访问的数据,此时CPU要获取数据进行处理,还是拿着Cache中未更新的数据(没有立马反映到DDR中)。
问题出在,经过DMA操作,cache缓存对应的内存数据已经被修改了,而CPU本身不知道(DMA传输是不通过CPU的),它仍然认为cache中的数据就是内存中的数据,以后访问Cache映射的内存时,它仍然使用旧的Cache数据。这样就发生Cache与内存的数据“不一致性”错误。

例2:多核系统中假如core0读了主存储的数据,并写回了数据。core1也读了主从的数据。但是这个时候core1并不知道数据已经被改动了,也就是说core1里 Cache中的数据过时了,会产生错误。
例3,网卡发包的时候,CPU将数据写到cache,同时网卡的DMA从内存里去读数据,由于没有同步,就发送了错误的数据。
五.怎么解决缓存一致性问题
1.DMA一致性问题
DMA如果使用cache,那么一定要考虑cache的一致性。
1.禁止DMA目标地址范围内的cache功能: 但是这样就会牺牲性能。
2.一致性DMA映射
3.流式DMA映射。
(注意:一致性DMA映射、流式DMA映射。可以根据DMA缓冲区期望保留的的时间长短来决策)
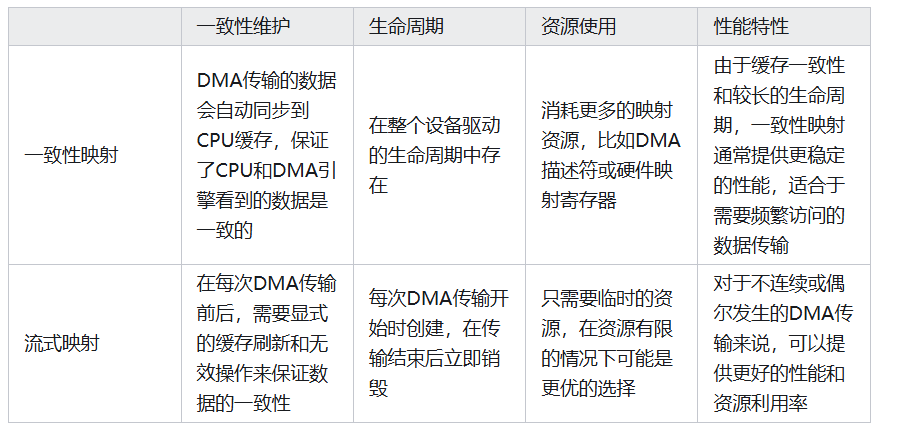
一致性DMA映射:一致性DMA映射申请的缓存区能够使用cache,并且保持cache一致性。一致性映射具有很长的生命周期,在这段时间内占用的映射寄存器,即使不使用也不会释放。生命周期为该驱动的生命周期。一致性DMA可以认为是“同步的”,就是DMA和CPU之间看到的物理内存是一致的;当CPU和DMA需要频繁的操作一块内存区域的时候,一致性DMA映射就比较合适。
点击查看代码
/*
return :函数的返回值时缓冲区的内核虚拟地址,可以被驱动程序使用。
dma_handle: 相关的总线地址则保存在中。
*/
void *dma_alloc_coherent(struct device *dev,size_t size, dma_addr_t *dma_handle,int flag);前两个参数是device结构和所需缓冲区的大小。
流式DMA映射:**驱动程序生命周期很短,禁用cache。一些硬件对流式映射有优化。建立流式DMA映射,需要告诉内核数据的流动方向。
点击查看代码
``` sync_single_for_cpu //一致性接口。 dma_map_single(dev, addr, size, direction); dma_unmap_single(dev, dma_handle, size, direction); dma_map_single dma_unmap_single做的就是这个事情,它会根据数据的方向来判断该是clean cache还是invalid cache。 ```2.总结
总的来说,在需要高性能和缓存一致性的实时数据处理系统中,一致性映射可能是更好的选择。而在资源受限或数据传输模式较为动态的场景下,流式映射可能更加合适
3.举例
1.imx6ull-frambuffer中的DMA
dma_alloc_writecombine 函数属于非一致性DMA映射方式。这种方式分配的内存区域不使用cache/dma_alloc_writecombine 分配的内存区域会禁止缓存(cacheable),这意味着 CPU 的写入操作会直接写入内存,而不是缓存,从而确保 DMA 能够读取到最新的数据。这种方式称为写入合并(write-combine)或写入直通(write-through)。
点击查看代码
/*
return : 内存的虚拟起始地址,在内核要用此地址来操作所分配的内存
dev : 可以平台初始化里指定,主要是用到dma_mask之类参数,可参考framebuffer
size : 实际分配大小,传入dma_map_size即可
handle : 返回的内存物理地址,dma就可以用。
*/
void *dma_alloc_writecombine(struct device *dev, size_t size,
dma_addr_t *handle, gfp_t gfp)
{
struct page *page;
dma_addr_t phys;
page = __dma_alloc(dev, size, handle, gfp);
if (!page)
return NULL;
phys = page_to_phys(page);
*handle = phys;
/* Now, map the page into P3 with write-combining turned on */
return __ioremap(phys, size, _PAGE_BUFFER);
}
static int mxsfb_map_videomem(struct fb_info *fbi)
{
if (fbi->fix.smem_len < fbi->var.yres_virtual * fbi->fix.line_length)
fbi->fix.smem_len = fbi->var.yres_virtual *
fbi->fix.line_length;
fbi->screen_base = dma_alloc_writecombine(fbi->device,
fbi->fix.smem_len,
(dma_addr_t *)&fbi->fix.smem_start,
GFP_DMA | GFP_KERNEL);
if (fbi->screen_base == 0) {
dev_err(fbi->device, "Unable to allocate framebuffer memory\n");
fbi->fix.smem_len = 0;
fbi->fix.smem_start = 0;
return -EBUSY;
}
dev_dbg(fbi->device, "allocated fb @ paddr=0x%08X, size=%d.\n",
(uint32_t) fbi->fix.smem_start, fbi->fix.smem_len);
fbi->screen_size = fbi->fix.smem_len;
/* Clear the screen */
memset((char *)fbi->screen_base, 0, fbi->fix.smem_len);
return 0;
}
2.imx6ull串口使用的DMA(imx.c)
采用流式DMA映射
点击查看代码
static int imx_uart_dma_init(struct imx_port *sport)
{
struct dma_slave_config slave_config = {};
struct device *dev = sport->port.dev;
int ret, i;
/* Prepare for RX : */
sport->dma_chan_rx = dma_request_slave_channel(dev, "rx");
if (!sport->dma_chan_rx) {
dev_dbg(dev, "cannot get the DMA channel.\n");
ret = -EINVAL;
goto err;
}
slave_config.direction = DMA_DEV_TO_MEM;
slave_config.src_addr = sport->port.mapbase + URXD0;
slave_config.src_addr_width = DMA_SLAVE_BUSWIDTH_1_BYTE;
slave_config.src_maxburst = RXTL_UART;
ret = dmaengine_slave_config(sport->dma_chan_rx, &slave_config);
if (ret) {
dev_err(dev, "error in RX dma configuration.\n");
goto err;
}
//here is important
sport->rx_buf.buf = dma_alloc_coherent(NULL, IMX_RXBD_NUM * RX_BUF_SIZE,
&sport->rx_buf.dmaaddr, GFP_KERNEL);
if (!sport->rx_buf.buf) {
dev_err(dev, "cannot alloc DMA buffer.\n");
ret = -ENOMEM;
goto err;
}
...
}
3.网卡的DMA-buffer也是采用流式映射。
五.怎么改善cache-miss问题
1.Code adjacency(把相关代码放在一起)
把相关代码放在一起有两个涵义,一是相关的源文件要放在一起;二是相关的函数在object文件 里面,也应该是相邻的。这样,在可执行文件被加载到内存里面的时候,函数的位置也是相邻的。 相邻的函数,冲突的几率比较小。而且相关的函数放在一起,也符合模块化编程的要求:那就是 高内聚,低耦合。
2.Data prefetch (数据预取)
符合空间局部性。
3.Early computation(提前计算)
有些变量,需要计算一次,多次使用的时候。最好是提前计算一下,保存结果,以后再引用,避免每次都重新计算一次。能使用常数的地方,尽量使用常数,加减乘除都会消耗CPU的指令,不可不查。
4.局部变量
如果每次都要在栈上分配一个1K大小的变量,这个代价是不是太大了哪?如果这个变量还需要初始化(因 为值是随机的),那是不是更浪费了。全局变量好的一点是不需要反复的重建,销毁;而局部变量就有这个坏处所以避免在栈上使用数组等变量。
5.Per-cpu data structure
Per-cpu data structure 在多核,多CPU或者多线程编程里面一个通用的技巧。使用Per-cpu data structure的目的是避免共享变量的锁,使得每个CPU可以独立访问数据而与其他CPU无关。在多核编程里面,局部变量反而更有好处。
6.减少函数调用的层次
函数越多,有用的事情做的就越少(函数的入栈,出栈等)。所以要减少函数的调用层次。但是不应该 破坏程序的美观和可读性。个人认为好程序的首要标准就是美观和可读性。不好看的程序读起来影响心 情。所以需要权衡利弊,不能一个程序就一个函数。
7.Reduce duplicated code(减少冗余代码)
代码里面的冗余代码和死代码(dead code)很多。减少冗余代码就是减小浪费。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号