BUAA-OO 第三单元总结
BUAA-OO 第三单元总结
前言
如果说计算机语言避免了自然语言的二义性,那么JML规格就在方法层面上避免了人的理解的歧义,同时JML又不对具体实现做出限制,因而在JML的规约下编码,正如“戴着镣铐跳舞”。有了这样一个明确的界限,无论是编码还是测试,相当于就有了一个契约。
一、测试数据
(一)以对象为单位
虽然这单元给出了JML规格,但是我们并不能直接利用JML规格来自动生成测试样例以及自动进行评测,因此我没有就每个方法进行单元测试,而是采用了除瞪眼法外最有效的debug方法——对拍。
在准备测试数据时,考虑到这单元的作业中,每条指令都有非常明确的操作对象,因此我选择以对象为单位展开“单元测试”。
具体而言,首先需要将指令按照对象进行分类。如第十一次作业中的EmojiMessage,涉及到的指令有storeEmojiId、addEmojiMessage、sendMessage、sendIndirectMessage、deleteColdEmoji、queryReceivedMessage、querySocialValue、queryPopularity,因此在构造EmojiMessage的测试样例时,在初始化完整个图后,只进行上述指令的测试。
由于采取了以对象为单位的单元测试,因此在数据生成器中,我们可以模拟对象的行为,这样可以使得生成的数据有迹可循(可以根据当前对象状态来决定生成的数据),而不是简单的随机数据。
以对象为单位展开测试,一方面测试数据的针对性比较强,能够高强度地测试某一个对象的具体功能,同时debug时也能精准锁定错误位置;另一方面,相比于传统的单元测试(以每个方法为单元),又能很好地覆盖一个对象所涉及到的一系列方法。
(二)数据质量
这单元引入了异常处理机制,传统的随机生成数据如果不加以控制,只会引发大量的异常,数据的质量并不高。因此,在自测的过程中,随机测试并不是我测试的重点。
为了提高数据的质量,我在构造相应的测试样例前会先做好测试方案,明确测试的对象、测试的指令、测试数据分布特征等,然后在依据方案生成测试样例(提前写好测试方案,在一定的程度上把思考和编写测试数据的过程进行了解耦,也可以提高整个测试思路的清晰程度)。


构造出测试样例后,还要用程序跑一跑看是否达到了预期效果(比如如果deleteColdEmoji的limit调得太大,就会把所有EmojiId都清除),然后修正测试方案再重新生成数据。
同时,对于一些卡性能的指令,我也构造了相应的极端样例,如4000+个person构成一条单链,然后用qbs、sim轰炸。(不得不说,极端样例的针对性还是挺强的,有时候能卡出几十秒的CPU时间)。
(三)JML与测试
当然,虽然采用对拍的测试方法,但是在生成测试数据的过程中还是会考虑JML的相关约束,对一些容易遗漏的地方进行测试(当然,这也是基于自己对JML的理解)。
比如在Exception的针对性测试中,主要对每个方法的exception behavior分支进行相应的测试,而对于Group的测试中,也着重考虑了坑点1111的相关测试样例。
此外,在对拍过程中发现问题时,JML规格就成为了我们评判的黄金标准(虽然可以多人对拍,对比相同数量hhh)
二、架构分析与图模型
(一)架构分析
这单元的架构基本上已经由JML规格给出了,和前两单元一样,主要是层次化架构(特别是本单元第一次作业体现的尤为明显)。
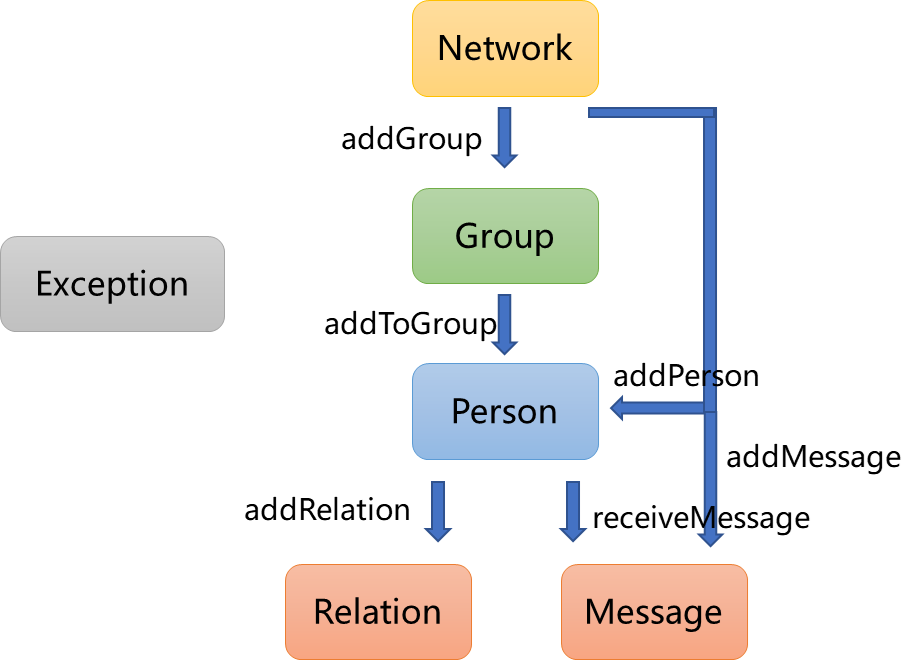
其中,顶层的Network主要负责管理各个元素(就像UML中的UMLModel),包括Person、Group以及Message。Group管理部分Person对象,Person对象则管理着Relation以及收到的Message。而Exception则是相对独立的一部分。(相比于前两单元,这单元的层次结构显得非常平易近人)
(二)图模型构建
在本单元中,我的图模型构建主要是在上述层次化结构下展开的。
图中的每个顶点,由Network直接管理,而对于顶点之间的边Relation,则由相应的顶点Person管理,以类似邻接链表的方式来存储图结构,这样可以比较好地处理稀疏图的情况(这也符合本单元社交网络的实际情况)。
此外,为了处理一系列与连通相关的问题,我还引入了Block类来表示各个连通分量,Block类主要管理该连通分量中的顶点Person和边Relation,这样Block类就可以很方便地获取该连通分量中的基本信息了。我在Block类中实现了merge、getShortestPath等方法,实现了连通分量的合并以及连通分量中计算最短路径,把这些与连通分量相关的图的算法与其他部分解耦。
(三)维护策略
对于顶层Network(单例模式),由于其管理的Person和Group具有唯一的id,因此使用HashMap来进行存储,可以迅速地在全局内根据相应id找到对应的对象实例。同理,对于Group所管理的Person也通过HashMap来进行存储以实现快速查找。
而对于顶点Person所管理的边Relation,采用以另一顶点的id为键,边权重为值的HashMap进行存储,以实现图内两个顶点之间边的快速查找。为了使顶点Person能够迅速查找所在的连通分量Block以及Group,我在Person类内部分别维护了一个Block和Group的变量。
对于连通分量Block所管理的顶点Person和边Relation,Person通过HashMap存储,Relation则采用TreeSet来存储(便于Prim算法每次取出权重最小的边)
总而言之,针对具有独特id的Person、Group、Message等对象的管理,都通过HashMap来实现快速查找,而对于一些需要进行排序的对象,则用TreeSet或PriorityQueue进行管理(但是需要注意的是,在某个对象放入可排序容器中后,该对象与排序相关的属性就不能再改变了,因为改变后容器中的顺序并不会发生改变,除非拿出来再放回去)。
对于其他一些变量,如value、age,则主要通过在加入和删除对象时进行相应的修改,如Group中在加入和删除Person时维护age相关属性和value相关属性,此外,在addRelation时需要注意Group也要维护value相关的属性。
Java丰富的容器类型为图模型的构建和存储提供了极大的便利。
三、性能相关
本单元与性能相关的主要是四条指令:qgav、qbs、qlc、sim。
本单元作业中未出现性能问题,但是这四条指令的相关优化方法还是比较值得讨论的,其中的一些算法也拓展了自己的视野,在此做个记录。
(一)qgav
qgav的方差主要通过Group类内部维护ageSum和ageSqSum(平方和),通过以下公式得到(啊哈,这是概统留下的宝贵知识)
(ageSqSum - 2 * ageAve * ageSum + ageAve * ageAve * length) / length
其中,length为Group中Person的人数。计算过程中需要注意精度问题(因为整除并不服从分配律),这也是上式中括号里的length不能直接和外面length相除的原因。
为了确保优化的正确性,可以分别写一个标准算法(即JML给出的算法)和优化算法,两种算法进行对拍,比较是否完全一致。
(二)qbs
qbs的优化主要通过并查集(Block)来实现。
并查集是这样一个顶点的集合,集合中的顶点都是互相连通的,连通的顶点都在同一个并查集中。因此,在qbs查询连通分量的数量时,只需要查询并查集的数量即可。这里简单的对并查集的算法进行介绍。
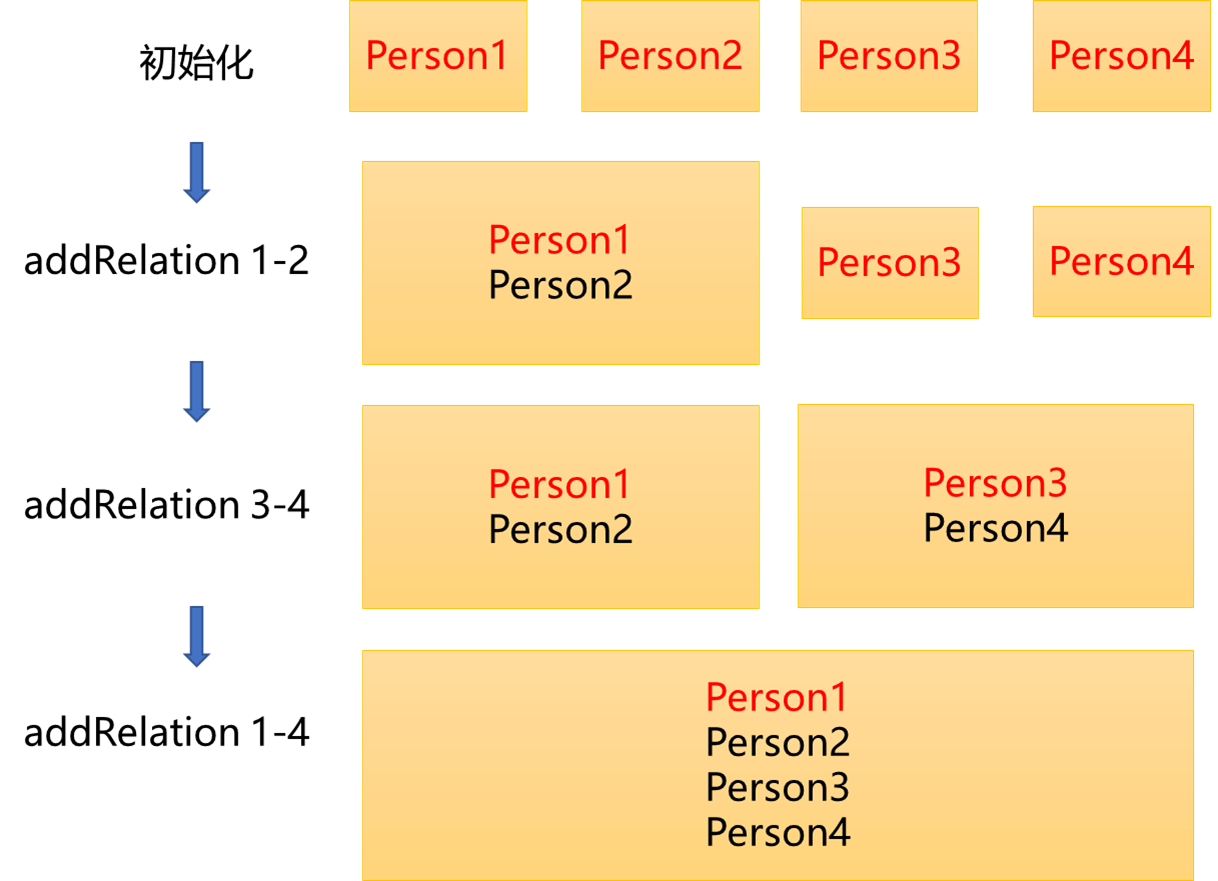
我们可以把每个并查集看成江湖的一个门派,每个门派都有一个boss(图中用红字标出),根据这个boss我们可以唯一确定一个门派(也就是在本单元中,我们可以用boss的id来表示Block的id)。
一开始,每个人都在自己的门派中当boss。
然后,当我们开始添加关系时,可以看做门派间的吞并(merge)。具体步骤如下:
-
Person1和Person2添加关系
-
如果Person1和Person2原来所在Block相同,则结束,否则继续下一步
-
比较两Block大小,规定小的为次Block,大的为主Block
-
次Block向主Block合并:将次Block中所有Person加入主Block
-
将次Block中所有Person所维护的Block变量(表示该Person所在Block)指向主Block
-
删除次Block
这样,我们就完成了一次合并。
(三)qlc
qlc指令主要查询最小生成树。最小生成树可以通过Kruskal算法来实现,即每次选取一条权重最短的边,如果加入后不会形成圈,那么就加入,否则丢弃。
Kruskal算法的关键就在于取出最小的边且其两端的顶点处于不同的连通分量。由于已经使用并查集来表示连通分量,因此只需要判断这条边的两个顶点在加入这条边前是否属于同一个Block,如果是,那么加入这条边后一定会形成圈,故丢弃,否则加入并合并两个Block。
(四)sim
sim指令主要查询最短路径,采用Dijkstra算法。其中,可以使用优先队列PriorityQueue进行堆优化(PriorityQueue保证每次取出的元素都是最小或最大的,其内部通过小顶堆排序)。
具体实现主要参考了讨论区中助教的帖子:
-
初始化:起始点s的距离为0,其他为无穷;访问数组全部为0表示未访问。把s扔到优先队列中。
-
从优先队列中取出最小距离的一点u,如果u已经被访问了,则不做任何操作。否则进行3
-
取出u的距离du,对于所有与u邻接的边e,设权重为w,e的另一顶点为v,v的距离为dv,如果v已经访问过,则跳过;否则访问v,同时若du+w<dv,则更新dv,并把v扔到优先队列中
-
重复2、3直至优先队列为空
四、Network扩展
假设出现了Advertiser、Producer、Customer、Person,那么产品从生产到销售的流程可以表示如下。
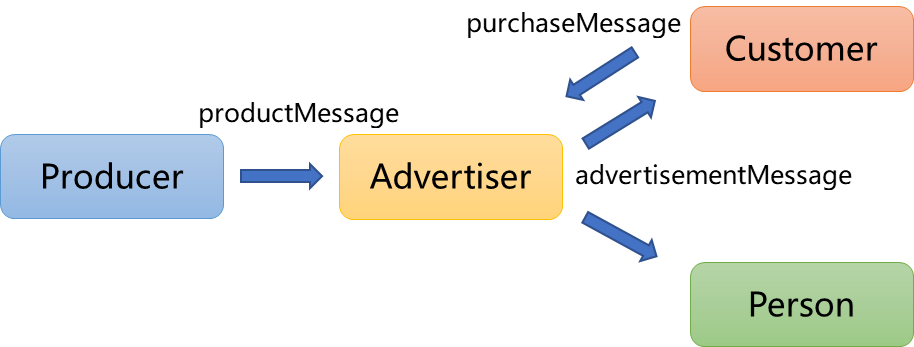
即Producer通过发送ProductMessage告知Advertiser所生成的待销售产品,Advertiser向Customer和Person发送AdvertisementMessage向Customer和Person推送产品广告,Customer根据自身兴趣向Advertiser发送PurchaseMessage购买产品。
为了查询销量和销售路径,添加接口Product,并在Network中添加成员。
/*@ public instance model non_null Product[] products;
@*/
(一)sendMessage 发送消息
sendMessage接口需要扩展上述三类新的Message的发送。主要有以下功能。
-
发送ProductMessage会使得Network中的products中新增该product,并使对应Advertiser的能够销售该product(containsProduct)
-
发送AdvertisementMessage会使得对应Person收到信息中增加该AdvetisementMessage
-
发送PurchaseMessage会使得Customer的money减少,同时Customer拥有的该类product数加1,该种类product的销量增加1,对应Producer的money增加(假设Advertiser心地善良,免费宣传)
/*@ public normal_behavior
@ requires containsMessage(id) && getMessage(id).getType() == 0 &&
@ getMessage(id).getPerson1().isLinked(getMessage(id).getPerson2()) &&
@ getMessage(id).getPerson1() != getMessage(id).getPerson2();
@ assignable messages, products;
@ ensures (\old(getMessage(id)) instanceof ProductMessage) ==>
@ (\exists int i; 0 <= i < products.length; products[i] == \old(getMessage(id)).getProduct() &&
@ products[i].containsAdvertiser(\old(getMessage(id)).getPerson2().getId()) &&
@ \old(getMessage(id)).getPerson2().containsProduct(products[i].getId()));
@ ensures (\old(getMessage(id)) instance of AdvertisementMessage) ==>
@ (\old(getMessage(id).getPerson2().containsAdvertisement(id)));
@ ensures (\old(getMessage(id)) instance of PurchaseMessage) ==>
@ \old(getMessage(id)).getPerson1().money == \old(getMessage(id).getPerson1().money) -
@ \old(getMessage(id)).getProduct().getCost() &&
@ \old(getMessage(id)).getProduct().getProducer().money ==
@ \old(getMessage(id).getProduct().getProducer().money) + \old(getMessage(id)).getProduct().getCost() &&
@ \old(getMessage(id)).getPerson1().productNum(\old(getMessage(id).getProduct().getId())) ==
@ \old(getMessage(id).getPerson1().productNum(\old(getMessage(id).getProduct().getId())) + 1 &&
@ (exists int i; 0 <= i < \old(products.length); products[i] == \old(getMessage(id)).getProduct &&
@ \old(products[i]).getSalesVolume() == \old(products[i].getSalesVolume()) + 1);
@*/
public void sendMessage(int id) throws
RelationNotFoundException, MessageIdNotFoundException, PersonIdNotFoundException;
(二)querySalesVolume 查询销量
/*@ public normal_behavior
@ requires containsProduct(id);
@ ensures (\exists int i; 0 <= i < products.length; products[i].getId() == id &&
@ \result == products[i].getSalesVolume());
@ also
@ public exceptional_behavior
@ signals (ProductIdNotFoundException e) !containsProduct(id);
@*/
public int querySalesVolume(int id) throws ProductIdNotFoundException;
(三)querySalesPath 查询销售路径
查询能够销售该Id的product的Advertiser的Id。
/*@ public normal_behavior
@ requires containsProduct(id);
@ ensures (\forall int i; 0<= i < \result.length; containsPerson(\result[i]) &&
@ getPerson(\result[i]) instanceof Advertiser && getPerson(\result[i]).containsProduct(id)) &&
@ (\forall int i; 0 <= i < people.length; (people[i] instance of Advertiser &&
people[i].containsProduct(id)) ==> (\exists int j; 0 <= j <= \result.length;
\result[j].getId() == people[i].getId()));
@ also
@ public exceptional_behavior
@ signals (ProductIdNotFoundException e) !containsProduct(id);
@*/
public List<Integer> querySalesPath(int id) throws ProductIdNotFoundException;
(预测一波明年的Unit3是市场销售网络)
五、心得体会
(一)关于JML
JML规格给我最直观的体会就是严谨。JML规格对每个方法都做成了准确而完备的限制和说明,这就使得无论是编程者还是其他代码阅读者,或者是测试人员,对于某个方法乃至整个类、设计都能有一个无异议的共识。凡是符合JML规格的都是正确的,不符合JML规格的都是错误的,因此,JML规格就成为了整个开发过程的黄金标准。
这种极其严格的形式化规约,让我想起了从自然语言到机器语言的过渡。正是人类从自然语言过渡到严谨、无二义性的机器语言,才催生了计算机的出现和发展,把人类历史推向一个全新的时代。试想如果未来这种形式化规约能够和机器语言建立起真正的联系,那么机器是不是就可以根据JML规格来自动判断一个方法、一个设计是否正确?是否就可以真正实现根据JML规格的自动测试?
但是,如果真的要实现上述设想,我想还有很长的路要走。
一方面,JML规格并不限制具体实现,那么对于各种各样的实现形式(这是一个无限大的空间),如何实现从JML规格到具体实现的映射?也许可以先过渡到这样一个阶段,由人预先指定好从JML规格中各个元素到实际实现的映射,然后由机器在该指定好的映射下自动根据JML进行计算和模拟,以判断正确性。在这样一个阶段后,再寻求JML规格脱离人预先指定的映射,由机器自动完成JML规格和实际实现的匹配,再进行计算模拟。为了实现这种机器匹配,可能需要额外加入形式化规约(如规定各个成员的命名等)。
另一方面,即使机器能够实现JML规格到具体实现的自动匹配,但是JML规格的效率依然是一个大问题。以本单元中的queryLeastConnection为例,自然语言可以很简洁的描述为”寻找最小生成树“,而要理解JML规格的描述,需要一步步按照规格来推演、去画图,然后去寻找规律,看这个方法讲的到底是什么。我对于助教能够完整准确地把这个方法的JML规格写出来感到由衷佩服,因为如果让我写最小生成树的JML规格,我毫无头绪。我想,这正是JML规格的严谨性带来的不可避免的弊端——繁琐。此外,阅读JML规格以保证完全理解正确也需要较多的时间。这种严谨和繁琐之间的trade off是需要谨慎考量的。
emm一时想到吴际老师说的关于JML的形式化验证,就扯多了。。当然,以上只是我在经过本单元学习后对JML规格一个微浅的认识,可能如今或未来不久就有技术能够解决上述问题了也未可知。
除了上述内容,这单元JML形式化规约还是给我带来了一些启发,比如未来在编写程序时,可以先对某些功能写出类似JML形式化的规约(不考虑具体实现,当然也不必像JML这么严谨),然后在该规约下进行编程,最后根据规约进行测试。这就类似于将思考设计的过程和具体的实现过程解耦(这是我从计组到OS到OO总结出的血泪经验hhh),同时把这个过程以一种具象化的形式呈现出来。
(二)关于测试
果然,测试是每次单元总结都避不开的,因为必须承认,自己对测试的认识还不够全面,测试水平也还有很大的提高空间,因此每单元中对于测试都会有新的收获(或许这也是一件好事)。
这单元我关于测试的体会主要有两个:以对象为单位开展测试和如何提高数据质量。
以对象为单位开展测试,主要是因为我们是基于面向对象的方法进行开发,整个设计依赖的就是对象本身和对象间的协作。因此,以对象为单位来对各个对象涉及到的功能展开测试,我想这是一个比较高效且完备的方法。(当然,构造测试样例时不如随机数据那么爽~)
第二是数据的质量决定了测试的强度,因此在测试中必须着重提高数据的质量而非数量。在这单元中,我尝试了新的测试方法:
-
编写测试方案
-
根据测试方案构造测试样例
-
运行测试样例,检查预期效果
-
修改测试方案,重新测试
经过以上流程,测试数据的质量相比于随机数据能够得到比较大的提升,也正是这些数据帮我实现了最后一次互测中的5刀(随机数据并没有发现出互测中别人的bug)
未来的学习过程中,我会继续尝试并不断完善上述测试流程,尽量形成一套成熟而完备的测试思路(比如检查测试样例的覆盖性等等)。
六、special chapter
首先,真诚感谢助教们的辛勤付出!无论是作业还是实验的JML规格,都是肉眼可见的繁琐和复杂。(虽然我们根据规格写代码真的很爽~)
其次,感谢对拍的小伙伴们,每次和小伙伴对拍全部相同都特别有安全感hhh(以及不用写正确性判断程序的快乐!)。
最后,告别每周日的快乐互测,最后一次hack了5个人,算是为互测画上了完美的句号~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号