

数据库设计——三范式
关系型数据库是现在广泛应用的数据库类型,对关系型数据库的设计就是对数据进行组织化和结构化的过程。对于小规模的数据库我们处理起来还是比较轻松地,但是随着数据库规模的扩大我们将发现用户操控数据库的SQL语句将变得笨拙、复杂。更糟糕的是很有可能导致数据不完整,不准确。所以我们有必要将数据设计的更加符合规范。
在实际开发中最为常见的设计范式有三个:
1.第一范式
即表的列的具有原子性,不可再分解,即列的信息,不能分解, 只有数据库是关系型数据库(mysql/oracle/db2/informix/sysbase/sql server),就自动的满足1NF;
换句话说:能分就分,分到不能分为止!
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。
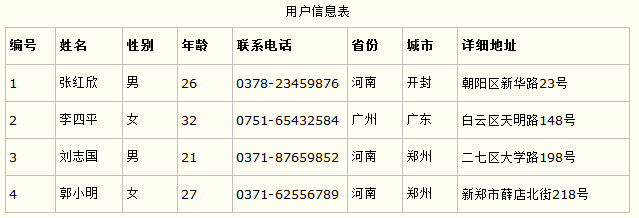
上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的时候就非常方便,也提高了数据库的性能。
2.第二范式(确保表中的每列都和主键相关)
在满足第一范式的基础上,数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖(部分函数依赖指的是存在组合关键字中的某些字段决定非关键字段的情况),也即所有非关键字段都完全依赖于任意一组候选关键字。(另外,所有单关键字的数据库表都符合第二范式,因为不可能存在组合关键字。)
即:第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
1、 尽可能的使用单关键字吧!
2、 每个表只表述一种信息,别傻乎乎的把所有信息都放到一个表里!
表中的记录是唯一的, 就满足2NF, 通常我们设计一个主键来实现
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
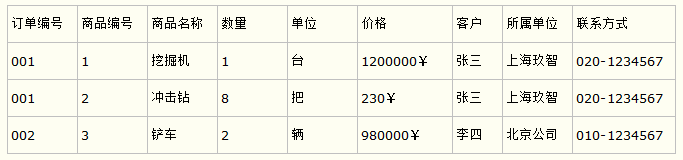
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。
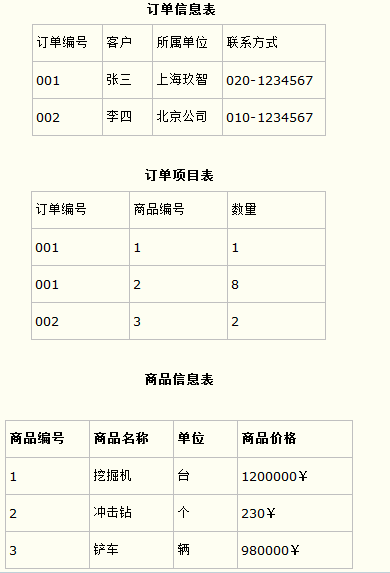
这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
3.第三范式(确保每列都和主键列直接相关,而不是间接相关)
在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。所谓传递函数依赖,指的是如果存在"A → B → C"的决定关系,则C传递函数依赖于A。也就是说表中的字段和主键直接对应不依靠其他的中间字段。
即:第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
说白了:决定某字段值的必须是主键!
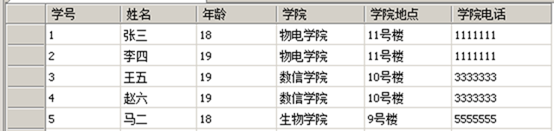
可以看出表中的学院地点依赖于学院,学院依赖于学号,学院电话同理。所以这不符合第三范式,这样的结果同样会造成下述不良后果:
(1) 数据冗余:同一个“学院”由n个学生,“学院地点”和“学院电话”就重复n-1次。
(2) 更新异常:若调整了某学院的地点,数据表中所有有关行的“学院地点”值都要更新,否则会出现同一学院但是地点却不同的情况。
(3) 插入异常:假设要增加一个新学院,暂时还没有人报考。这样,由于还没有“学号”关键字,相关数据将无法记录入数据库。
(4) 删除异常:假设一批学生已经毕业,这些学生信息记录就应该从数据库表中删除。但是,与此同时,学院、学院地点和学院电话信息也被删除了。很显然,这也会导致插入异常。
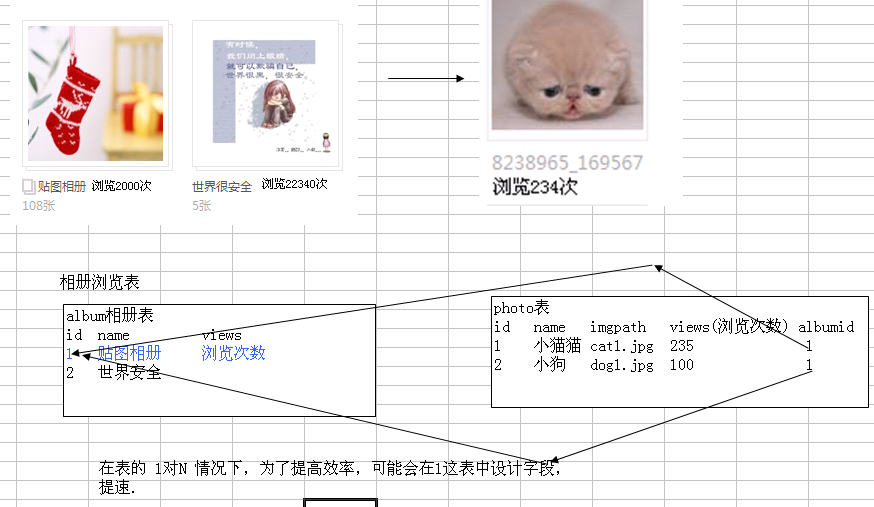
反3NF : 但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。
案例:
reference:
http://www.cnblogs.com/linjiqin/archive/2012/04/01/2428695.html
http://blog.csdn.net/beijiguangyong/article/details/6249807
传智播客Mysql优化教程
