

Datawhale组队学习——计算之魂第一章学习笔记
第1章 毫厘千里之差——大O概念
1.1 算法的规范化和量化度量
要点:
体系结构,软件从计算机科学中分离出来。
思考题1.1世界上还有什么产品类似于计算机,是软硬件分离的?( 难度系数1颗星
理解分析:软硬件分离,何为软件?何为硬件?我的理解是:在物理世界以实际存在的物质组成的且不随时间发生明显的物理性质变化的为硬件,能够随时间、随不同场景去协调硬件使之发挥某些功能完成相应任务的系统为软件。
答案:类似计算机的软硬件分离的产品有很多:电视,手机,智能手表等智能设备。
思考:再发散一下思维,人,算不算呢?虽然把人视作产品过于荒谬,但从我的角度来看,构成人的生物组织可以视为硬件,而大脑里的意识和“灵魂”等不能用具体物理粒子描述的存在,则可以视为软件。
既然人可以算作此类,那其他动植物呢?很有意思。
1.2 大数和数量级的概念
节选:
高德纳的思想主要包括以下三个部分。
1.在比较算法的快慢时,只需要考虑数据量特别大,大到近乎无穷大时的情况。为什么要比大数的情况,而不比小数的情况呢?因为计算机的发明就是为了处理大量数据的,而且数据越处理越多。比如我和同学们做砸的那个对账功能,就是没有考虑数据量会剧增。
2.决定算法快慢的因素虽然可能有很多,但是所有的因素都可以被分为两类:第一类是不随数据量变化的因素,第二类是随数据量变化的因素。
比如说有两种算法:第一种的运算次数是3N2,其中N是处理的数据量;第二种则是100NlogN[2]。前面的那个3也好,这里的100也罢,都是常数,和N的大小显然没有关系,处理10个、100个、1亿个数,都是如此。但是后面和N有关的部分则不同,当N很大时,N2要比NlogN大得多。在处理几千,甚至几万个数字的时候,这两种算法差异不明显,但是高德纳认为,我们衡量算法好坏时,只需要考虑N近乎无穷大的情况。为什么这么考虑问题呢?因为计算机的任务是处理远远超出我们想象的规模的数据量,而我们的认知其实很难想象那样规模的数据有多少。
要点:
复杂度、数量级、大O的概念。
思考题1.2 如果一个程序只运行一次,在编写它的时候,你是采用最直观但是效率较低的算法,还是依然寻找复杂度最优的算法?(难度系数2颗星)
理解分析:只运行一次,意味着不需要考虑维护等后期开销,只考虑这次运行的效率。但题目并没有告知数据量的大小。当数据量小时,这时候只运行一次,用效率低且直观的算法并没有很大问题,但当数据量大时,这时候我们如果采用效率低且直观的算法,即使只运行一次,依然可能给我们带来困扰。这时候,我们就需要寻找复杂度最优的算法。
答案:根据数据量选择,数据量大寻找复杂度最优,数据量小则二者均可,若数据量未知,则尽可能采用复杂度低的算法,先实现,后改进。
1.3 怎样寻找最好的算法
要点
分治算法、递归、少做无用功、逆向思维、复杂度巨大的差异。
节选
例题1.3 总和最大区间问题
给定一个实数序列,设计一个最有效的算法,找到一个总和最大的区间。
比如在下面的序列中:
1.5, −12.3, 3.2, −5.5, 23.2, 3.2, −1.4, −12.2, 34.2, 5.4, −7.8, 1.1, −4.9
总和最大的区间是从第5个数(23.2)到第10个数(5.4)。
思考题1.3
Q1.将例题1.3的线性复杂度算法写成伪代码。(难度系数2颗星)
Q2.在一个数组中寻找一个区间,使得区间内的数字之和等于某个事先给定的数字。(AB、FB、LK等公司的面试。(难度系数3颗星))
Q3.在一个二维矩阵中,寻找一个矩形的区域,使其中的数字之和达到最大值。(例题1.3的变种,硅谷公司真实的面试题。(难度系数4颗星))
Q1伪代码(复杂O(N))
int maxSubseqSum(int A[], intN)
{
int thisSum, maxSum;
int i;
thisSum = maxSum = 0;
for(i = 0; i < N; i++){
thisSum += A[i];
if(thisSum > maxSum)
maxSum = thisSum;
else if(this < 0)
thisSum = 0;
}
return maxSum;
}
1.4 关于排序的讨论
要点
归并排序、堆排序、快速排序、递归、分治、平均时间复杂度、最坏时间复杂度、就地特征、排序的稳定性。
节选
1.今天常用的排序算法有三种,它们分别是归并排序(Merge Sort)、快速排序(Quick Sort)和堆排序(Heap Sort)。这三种算法的共同特点是平均时间复杂度均为O(NlogN)。
2.1.今天人们对排序算法的改进大多是结合几种排序算法的思想,形成混合排序算法(Hybrid Sorting Algorithm),比如将快速排序和堆排序结合起来的内省排序(Introspective Sort,简称Introsort),它成为如今大多数标准函数库(STL)中的排序函数使用的算法。
2.2.蒂姆排序(Timsort)将两种排序算法的特点相结合(插入排序节省内存、归并排序节省时间),最坏时间复杂度控制在O(NlogN)量级,同时还能够保证排序稳定性这样一举三得的混合排序算法。蒂姆排序最初是在Python程序语言中实现的,今天它依然是这种程序语言默认的排序算法,比如今天Java和安卓(Android)操作系统内部,使用的就是这种排序算法。
2.3.蒂姆排序可以被看成是以块(它在算法中被称为run)为单位的归并排序
2.4.蒂姆排序采用了跳跃式预测的方法,具体看链接:https://github.com/python/cpython/blob/master/Objects/listsort.txt
2.5 TimSort,整合了插入排序的简单直观和归并排序效率高的特点。
思考题
Q1.赛跑问题(GS)。
假定有25名短跑选手比赛争夺前三名,赛场上有五条赛道,一次可以有五名选手同时比赛。比赛并不计时,只看相应的名次。假设选手的发挥是稳定的,也就是说如果约翰比张三跑得快,张三比凯利跑得快,约翰一定比凯利跑得快。最少需要几次比赛才能决出前三名?(在第6章给出了这一问题的解答。(难度系数3颗星))
先说答案,最少比7次。
第一步:分5组,所有人都比完一次。这个时候,每组各有5个排名,所有小组的第一名再比一次,此时将这五组的成绩按小组第一从高到低把小组排个序,以方便后面的数据操作,第一步共比了6次。
第二步:第一组比完,第一名已经出来了,接下来寻找第二名和第三名。具体做法是,将成绩第一的小组里面的第二名和第三名抽出,将成绩第二的小组里面的第一名和第二名抽出,将成绩第三的小组里面的第一名抽出,这五个人比一次,取第二名和第三名作为总排名的第二名和第三名。
分析如下:
图示:
图中,红色为第一步决出的第一名,毋庸置疑的第一名,比完第一步之后,我们首先能考虑到的是淘汰绿色部分的选手,进一步分析不难发现,B3、C2、C3也将被淘汰,因为B3不可能快过B1和B2,所以无缘第二步的比赛,同理,C2、C3也不可能快过B1和C1,因此也无缘第二步的比赛。
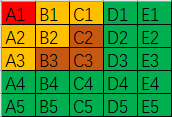
Q2.区间排序。
如果有N个区间[l1,r1],[l2,r2],…,[lN,rN],只要满足下面的条件我们就说这些区间是有序的:存在xi∈[li,ri],其中i=1,2,…,N。
比如,[1, 4]、[2, 3]和[1.5, 2.5]是有序的,因为我们可以从这三个区间中选择1.1、2.1和2.2三个数。同时[2, 3]、[1, 4]和[1.5, 2.5]也是有序的,因为我们可以选择2.1、2.2和2.4。但是[1, 2]、[2.7, 3.5]和[1.5, 2.5]不是有序的。
对于任意一组区间,如何将它们进行排序?(难度系数3颗星)
没看懂,待解决。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本