中国GDP影响因素的数据分析
 分析我国GDP的影响因素,选取其中常见的变量作为自变量,以我国GDP作为因变量,采用多种机器学习模型,通过自动化学习和建模,评估并确定对GDP增长影响主要因素。
通过这种方法,可以更准确地理解各因素对GDP的贡献度,为经济决策提供科学依据,从而促进我国经济的稳定增长
分析我国GDP的影响因素,选取其中常见的变量作为自变量,以我国GDP作为因变量,采用多种机器学习模型,通过自动化学习和建模,评估并确定对GDP增长影响主要因素。
通过这种方法,可以更准确地理解各因素对GDP的贡献度,为经济决策提供科学依据,从而促进我国经济的稳定增长
01 丨 背景及问题描述
国内生产总值GDP是国民经济核算的核心指标,也是衡量一个国家或地区经济状况和发展水平的重要指标。一个国家或地区的经济究竟处于增长或衰退阶段,能够从GDP的变化中体现出来。
实现经济(GDP)增长是我国宏观经济政策的目标之一,研究影响经济(GDP)增长的因素对促进我国经济快速发展有着十分重要的意义。
在计量经济学里面的研究,围绕着影响GDP的因素的研究有很多,包括但不限于人口,固定资产投资,消费,净出口,税收,广义M2货币,物价指数CPI等。
分析上述经济因素间的关系进行可视化分析,并利用这些因素作为自变量,以我国GDP作为因变量,采用3种机器学习模型,通过自动化学习和建模,评估并确定对GDP增长影响主要因素。
通过这种方法,可以更准确地理解各因素对GDP的贡献度,为经济决策提供科学依据,从而促进我国经济的稳定增长。
02 丨 数据分析
- 导入数据分析常用包
#导入数据分析常用包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
import statsmodels.formula.api as smf
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 支持中文
plt.rcParams['axes.unicode_minus'] = False #负号- 读取数据
# 读取数据,并将year列作为索引列
datafile = 'sample4.xlsx'
data=pd.read_excel(datafile, index_col='year')
#查看数据前三行
data.head(3)
# 查看数据信息(其中 year 列为索引列)
print(data.shape) # 数据大小
data.info()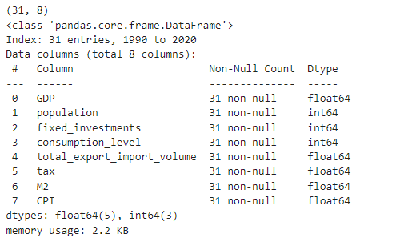
数据共有 31 行,由 9 列(其中 year 列为索引列)组成,每列代表的含义如下:
- year:年份
- GDP:国内生产总值
- population:人口
- fixed_investments:固定资产投资
- consumption_level:消费水平
- total_export_import_volume:净出口
- tax:税收 M2:广义货币供应量
- CPI:物价指数
选取 其中 year 列为索引列,GDP 作为问题的解以及模型的输出,其余7个属性作为模型的输入。
03 丨 数据预处理
观察数据情况:绘制箱线图
#绘制箱线图
columns = data.columns.tolist() # 列表头
fig = plt.figure(figsize=(12,4), dpi=128)
dis_cols = 4
dis_rows = len(columns) // dis_cols + (0 if len(columns) % dis_cols == 0 else 1)
for i in range(len(columns)):
plt.subplot(dis_rows, dis_cols, i + 1)
sns.boxplot(data=data[columns[i]], orient="v",width=0.5)
plt.ylabel(columns[i], fontsize=12)
plt.tight_layout()
plt.show()
箱线图的组成:通常包括箱子(boxes)、须线(whiskers)、横线(caps)、中位线(medians)和异常值点(fliers)。
1. boxes:一个包含箱子(矩形部分,代表数据的上下四分位数)的 Line2D 对象的列表。
2. whiskers:一个包含须线(从箱子延伸出去的线段,通常表示到最大/最小值或内四分位数一定范围内的点)的 Line2D 对象的列表。
3. caps:一个包含横线(在须线末端的小横杠,用来标识须线的结束)的 Line2D 对象的列表。
4. medians:一个包含中位线(在箱子内部的中位数标记)的 Line2D 对象的列表。
5. fliers:一个包含异常值点(在箱线图之外的单独标记的点)的 Line2D 对象的列表。
如何分析:
1. 观察箱体位置和大小:箱体的位置和大小提供了关于数据分布的中心位置和离散程度的信息。
2. 比较中位数和四分位数:中位数提供数据集中心位置的度量,不受极端值的影响,四分位数提供了数据分布的更详细视图,显示了数据的四分之一和四分之三的位置。
3. 分析须线和异常值: 须线的长度表示了数据的最大和最小观测值(除去异常值)与箱体的距离。 如果须线较长且有异常值存在,说明有一部分数据远离主体数据范围,可能是由数据录入错误、测量误差或真实的极端值造成。
分析发现,CPI列出现两个异常值点
观察数据情况:删除全0列、删除20%以上为的0的列、删除取值唯一的列
# 删除全0列
data = data.drop(columns=[col for col in data.columns if (data[col] == 0).all()])
# 删除20%以上为0的列
threshold = 0.2
zero_counts = data.isin([0]).sum() # 返回一个Series,其中包含了DataFrame中每列0值的计数
cols_to_drop = zero_counts[zero_counts / len(data) > threshold].index
data = data.drop(columns=cols_to_drop)
# 删除取值唯一的列
data = data.drop(columns=[col for col in data.columns if data[col].nunique() == 1])观察数据情况:观察缺失值
#观察缺失值
import missingno as msno
msno.matrix(data)观察数据情况:处理异常值,标记为0
# 对CPI列进行异常值处理
# 计算四分位数和IQR
q1 = data['CPI'].quantile(0.25)
q3 = data['CPI'].quantile(0.75)
iqr = q3 - q1
low_bound = q1 - 1.5 * iqr
up_bound = q3 + 1.5 * iqr
# 找出异常值并将其置为0
outliers = data[(data['CPI'] < low_bound) | (data['CPI'] > up_bound)]['CPI'].tolist()
print(outliers)
data.loc[(data['CPI'] < low_bound) | (data['CPI'] > up_bound), 'CPI'] = 0[112.5, 117.1] 说明在CPI列中存在两个异常值:112.5 和 117.1,并将这两个异常值标记为0
观察数据情况:处理异常值,用平均值填充(两个相邻数据都是0,不适合向前或者向后填充,浮点数众数填充不太适合,所以使用平均值进行填充)
# 须将0转化为缺失值,再计算平均值
# 将 0 替换为 np.nan
data_nan = data.replace(0, np.nan)
# 用平均值填充缺失值
data = data_nan.fillna(data_nan.mean())
print(data['CPI'])观察数据情况:显示热力图,进行相关性分析
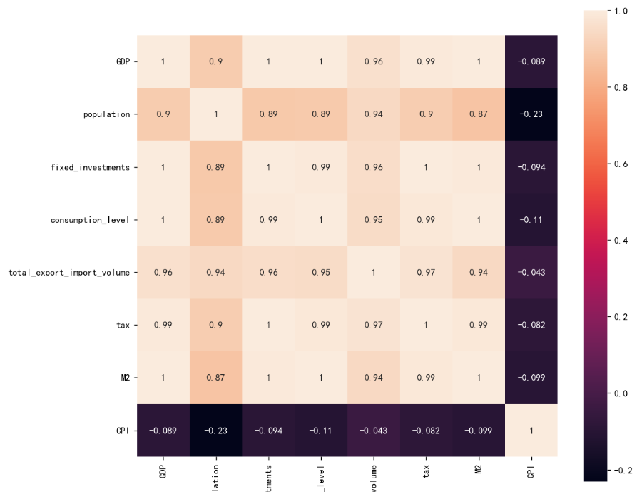
约定 相关系数 > 0.4 的特征作为模型的输入
04 丨 数据建模
- 将样本划分为训练集和测试集(80%作为训练集、20%作为测试集)
#划分训练集和测试集,查看他们的形状
from sklearn.model_selection import train_test_split
# 取出 X 和 y
X = data.iloc[:,1:]
y = data.iloc[:,0]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
print(X_train.shape,X_test.shape,y_train.shape,y_test.shape)
print(y_test)- 数据标准化(将特征转换到相同的尺度上来,避免量级对数据分析的影响)
#数据标准化 0-1规范化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_s = scaler.transform(X_train)
X_test_s = scaler.transform(X_test)
print('训练数据形状:')
print(X_train_s.shape,y_train.shape)
print('测试数据形状:')
print(X_test_s.shape,y_test.shape)# 拟合归一化器
scaler.fit(y_test.values.reshape(-1, 1)) # 使用.values将其转换为numpy数组,并reshape
scaler.fit(y_train.values.reshape(-1, 1))
# 归一化y
y_test_normalized = scaler.transform(y_test.values.reshape(-1, 1))
y_train_normalized = scaler.transform(y_train.values.reshape(-1, 1))
# 将归一化后的数据转换回Series
y_test_normalized_series = pd.Series(y_test_normalized.flatten())
y_train_normalized_series = pd.Series(y_train_normalized.flatten())选取何种模型?分析每个变量随 year 变化趋势
#每个变量随时间的变化趋势
columns = data.columns.tolist()
fig = plt.figure(figsize=(12,4), dpi=128)
dis_cols = 4
dis_rows = len(columns) // dis_cols + (0 if len(columns) % dis_cols == 0 else 1)
for i in range(len(columns)):
plt.subplot(dis_rows,dis_cols, i + 1)
sns.lineplot(data=data[columns[i]],lw=1)
plt.ylabel(columns[i], fontsize=12)
plt.tight_layout()
plt.show()
然后绘制两两变量之间的散点图
sns.pairplot(data[columns],diag_kind='kde')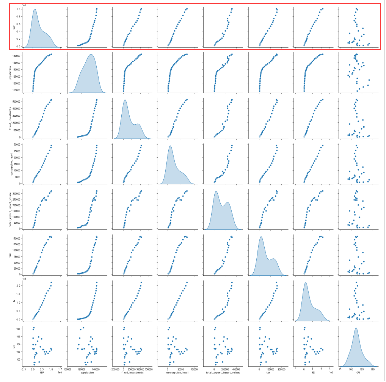

模型的输出GDP,与其他特征(除CPI外)呈明显的线性关系
建立线性回归模型,通过MSE和R2两个评价指标进行评价
# 使用线性回归模型
from sklearn.linear_model import LinearRegression
# 创建线性回归模型
model2 = LinearRegression()
# 训练模型
model2.fit(X_train_s, y_train_normalized_series)
# 使用模型预测测试集
y_pred = model2.predict(X_test_s)
# 计算mse
mse = mean_squared_error(y_test_normalized_series, y_pred)
print(f'Mean Squared Error: {mse}')
# 计算R平方值
r2 = model2.score(X_test_s, y_test_normalized_series) # 使用模型的.score方法
r2_manual = r2_score(y_test_normalized_series, y_pred) # 使用sklearn.metrics的r2_score方法
print(f'R2: {r2_manual}')通过训练模型,使用模型预测,对比预测值和真实值的关系,输出 MSE 和 R2:
Mean Squared Error: 0.00048310181658096685
R2: 0.9996875580691639
建立随机森林模型
# 使用训练集来训练随机森林回归模型
#随机森林
from sklearn.ensemble import RandomForestRegressor
model1 = RandomForestRegressor(n_estimators=5000, max_features=int(X.shape[1] / 3), random_state=0)
model1.fit(X_train_s, y_train_normalized_series)from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
# 使用模型预测测试集
y_pred = model1.predict(X_test_s)
# 计算mse
mse = mean_squared_error(y_test_normalized_series, y_pred)
print(f'Mean Squared Error: {mse}')
# 计算R平方值
r2 = model1.score(X_test_s, y_test_normalized_series) # 使用模型的.score方法
r2_manual = r2_score(y_test_normalized_series, y_pred) # 使用sklearn.metrics的r2_score方法
print(f'R2: {r2}')通过训练模型,使用模型预测,对比预测值和真实值的关系,输出 MSE 和 R2:
Mean Squared Error: 0.0061440299975638315
R2: 0.996026401620388
随机森林超参数优化,使用网格搜索来优化超参数
#利用K折交叉验证搜索最优超参数
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.datasets import make_regression
# 定义随机森林回归模型
rf = RandomForestRegressor(random_state=42)
# 定义要优化的超参数范围
param_grid = {
'n_estimators': [100, 200, 300], # 决策树的数量
'max_depth': [None, 10, 20, 30], # 决策树的最大深度
'min_samples_split': [2, 5, 10], # 分割内部节点所需的最小样本数
'min_samples_leaf': [1, 2, 4], # 叶节点所需的最小样本数
'max_features': ['auto', 'sqrt', 'log2'] # 寻找最佳分割时要考虑的特征数量
}# 使用网格搜索来优化超参数
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2)
grid_search.fit(X_train_s, y_train_normalized_series)
# 输出最佳参数和得分
print("Best parameters found: ", grid_search.best_params_)
print("Best cross-validation score: ", grid_search.best_score_)
# 使用最佳参数在测试集上评估模型
best_rf = grid_search.best_estimator_
test_score = best_rf.score(X_test_s, y_test_normalized_series)
print("Test set score: ", test_score)Fitting 5 folds for each of 324 candidates, totalling 1620 fits
Best parameters found: {'max_depth': None, 'max_features': 'auto', 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 200}
Best cross-validation score: 0.9555303184422325
Test set score: 0.9960774334121186
查看每个特征值对输出结果的重要性
print(model1.feature_importances_)
sorted_index = model1.feature_importances_.argsort()
plt.barh(range(X.shape[1]), model1.feature_importances_[sorted_index])
plt.yticks(np.arange(X.shape[1]),X.columns[sorted_index],fontsize=14)
plt.xlabel('X Importance',fontsize=12)
plt.ylabel('covariate X',fontsize=12)
plt.title('Importance Ranking Plot of Covariate ',fontsize=15)
plt.tight_layout()
对GDP的影响因素重要性依次为:税收 > 消费 > M2 > 人口 > 固定资产投资 > 净出口 > CPI
建立支持向量机模型
from sklearn.svm import SVR # 确保导入 SVR
# 创建支持向量回归模型
model3 = SVR()
# 拟合模型
model3.fit(X_train_s, y_train_normalized_series)
# 测试数据
y_pred = model3.predict(X_test_s)
# 评估模型
mse = mean_squared_error(y_test_normalized_series, y_pred)
r2 = r2_score(y_test_normalized_series, y_pred)
print("MSE:", mse)
print("R2:", r2)通过训练模型,使用模型预测,对比预测值和真实值的关系,输出 MSE 和 R2:
Mean Squared Error: 0.01599042289036876
R2: 0.9896583319886665

END💯

 浙公网安备 33010602011771号
浙公网安备 33010602011771号