JVM全面分析之String
String的基本特性
- String 在jdk8之前内部定义了final char[] value 用于存储字符串数据。jdk9时改为byte[]。
- 字符串常量池中不会存储相同内容的字符串。
- String 的String Pool是一个固定大小的HashTable,默认值大小长度是1009.如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降。
- 使用-XX:StringTableSize可设置StringTable长度
- jdk6中StringTable是固定的,就是1009长度,所以如果长两次中的字符串过多就会导致效率下降很快。StringTableSize设置没有要求
- 在jdk7中,StringTable的长度默认值是60013,StringTableSize设置没有要求。
- 在jdk8开始,设置StringTable的长度的话,1009是可设置的最小值。
String的内存分配
String的基本操作
- 常量与常量的拼接结果在常量池中,原理是编译期优化
- 常量池中不会存在相同内容的常量。
- 只要其中有一个是变量,结果就在堆中。变量拼接的理由是StringBuilder。
- 如果拼接的结果调用intern()方法,则主动将常量池中还没有的字符串对象放入池中,并返回此对象地址。
public class StringTest1 {
public static void main(String[] args) {
String s1 = "a" + "b" + "c"; // 编译器优化为 ”abc“,在常量池放"abc"
String s2 = "abc"; // "abc"一定是放在字符串常量池中,将此地址赋给s2。此处的"abc"发现在上一行代码中常量池已经存在,就直接使用已有的”abc“.
/*
最终.java编译成.class,再执行.class
String s1 = "abc";
String s2 = "abc";
*/
System.out.println(s1 == s2); // true
System.out.println(s1.equals(s2)); // true
}
}
上述代码的class文件内容为:

从字节码角度看:
public class StringTest2 {
public static void main(String[] args) {
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop"; // 编译器优化为 “javaEEhadoop”
// 如果拼接符号的前后出现了变量,则相当于在堆空间中new String(),具体的内容为拼接的结果:javaEEhadoop
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4); // true
System.out.println(s3 == s5); // false
System.out.println(s3 == s6); // false
System.out.println(s3 == s7); // false
System.out.println(s5 == s6); // false
System.out.println(s5 == s7); // false
System.out.println(s6 == s7); // false
// intern():判断字符串长两次中是否存在javaEEhadoop值,如果存在,则返回常量池中javaEEhadoop的地址;
// 如果字符串常量池中不存在javaEEhadoop,则在常量池中加载一份javaEEhadoop,并返回此对象的地址。
String s8 = s6.intern();
System.out.println(s3 == s8); // true
}
}
通过以下代码我们解析字符串拼接符"+"的底层实现
public void test3() {
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4);
}
底层字节码反编译后的结果为:
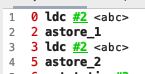
0 ldc #12 <a>
2 astore_1
3 ldc #13 <b>
5 astore_2
6 ldc #14 <ab>
8 astore_3
9 new #5 <java/lang/StringBuilder>
12 dup
13 invokespecial #6 <java/lang/StringBuilder.<init>>
16 aload_1
17 invokevirtual #7 <java/lang/StringBuilder.append>
20 aload_2
21 invokevirtual #7 <java/lang/StringBuilder.append>
24 invokevirtual #8 <java/lang/StringBuilder.toString>
27 astore 4
29 getstatic #9 <java/lang/System.out>
32 aload_3
33 aload 4
35 if_acmpne 42 (+7)
38 iconst_1
39 goto 43 (+4)
42 iconst_0
43 invokevirtual #10 <java/io/PrintStream.println>
46 return
从反编译结果的第9行后面看:s1 + s2 的执行细节为:(变量s是我临时定义的)
- StringBuilder s = new StringBuilder();
- s.append("a");
- s.append("b");
- s.toString() --> 约等于 new String("ab")
补充:在jdk5.0之后使用的是StringBuilder,在jdk5.0之前使用的是Stringbuffer
那设计到字符串变量的拼接都是这样的过程吗?不是的,请继续往下看
public void test4() {
final String s1 = "a";
final String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4); // true
}
从class文件看:

字节码角度看:
0 ldc #12 <a>
2 astore_1
3 ldc #13 <b>
5 astore_2
6 ldc #14 <ab>
8 astore_3
9 ldc #14 <ab>
11 astore 4
13 getstatic #9 <java/lang/System.out>
16 aload_3
17 aload 4
19 if_acmpne 26 (+7)
22 iconst_1
23 goto 27 (+4)
26 iconst_0
27 invokevirtual #10 <java/io/PrintStream.println>
30 return
发现此时没有StringBuilder出现了。而都是用的字符串常量池。
下面是一个练习
public void test5() {
String s1 = "javaEEhadoop";
String s2 = "javaEE";
String s3 = s1 + "hadoop";
System.out.println(s1 == s3); // false
final String s4 = "javaEE";
String s5 = s4 + "hadoop";
System.out.println(s1 == s5); // true
}
下面再进行一次对比:
public static void test6(){
long l1 = System.currentTimeMillis();
String src = "";
for (int i = 0; i < 100000; i++) {
src = src + "a";
}
long l2 = System.currentTimeMillis();
System.out.println(l2-l1); // 8635
}
public static void test7() {
long l1 = System.currentTimeMillis();
StringBuffer src = new StringBuffer();
for (int i = 0; i < 100000; i++) {
src.append("a");
}
long l2 = System.currentTimeMillis();
System.out.println(l2 - l1); // 35
}
两个方法为何差距如此大呢?原因为:
test6方法中每次循环都会创建一个StringBuilder、String类(StringBuilder调用toString方法会创建一个String类)。
总结
- 通过StringBuilder的append()的方式添加字符串的效率要远高于使用String的字符串拼接方式!
详情:
* StringBuilder的append()的方式:自始至终只创建一个StringBuilder的对象。而使用String的字符串拼接方式:创建多个StringBuilder和String的对象。
* 使用String的字符串拼接方式:内存中由于创建了较多的StringBuilder和String的对象,内存占用更大;如果内存不够将频繁出现GC。
字符串拼接操作
intern()的使用
首先看看String源码中intern()方法:
public native String intern();
发现其实native类型
如果不是用双引号声明的String对象,可以使用String提供的intern方法:intern方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中。
- 比如:String myInfo = new String("hello world").intern();
也就是说,如果在任意字符串上调用String.intern方法,那么其返回结果所指向的哪个类实例,必须和直接以常量形式出现的字符串实例完全相同。因此,下列表达式的值必定是true:
("a" + "b" +"c").intern() == "abc"
通俗来讲,Interned String就是确保字符串在内存里只有一份拷贝,这样可以节约内存空间,加快字符串操作任务的执行速度。注意,这个值会被存在字符串内部池(String intern Pool)
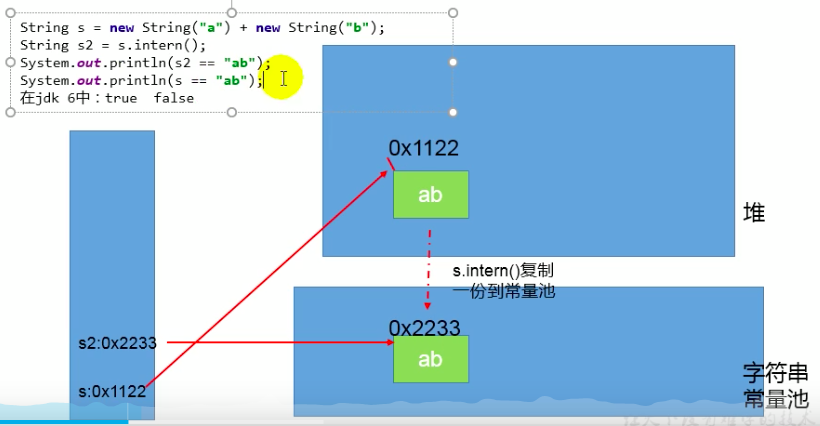
题目一:new String("ab")会创建几个对象?
public class StringTest3 {
public static void main(String[] args) {
String s1 = new String("ab");
}
}
其字节码内容如下:
0 new #2 <java/lang/String>
3 dup
4 ldc #3 <ab>
6 invokespecial #4 <java/lang/String.<init>>
9 astore_1
10 return
可见其创造了两个对象:字符串常量池中一个:存放”ab“;堆空间中一个:String。
题目而:new String("a") + new String("b")呢?
public class StringTest3 {
public static void main(String[] args) {
String s = new String("a") + new String("b");
}
}
字节码内容如下:
0 new #2 <java/lang/StringBuilder>
3 dup
4 invokespecial #3 <java/lang/StringBuilder.<init>>
7 new #4 <java/lang/String>
10 dup
11 ldc #5 <a>
13 invokespecial #6 <java/lang/String.<init>>
16 invokevirtual #7 <java/lang/StringBuilder.append>
19 new #4 <java/lang/String>
22 dup
23 ldc #8 <b>
25 invokespecial #6 <java/lang/String.<init>>
28 invokevirtual #7 <java/lang/StringBuilder.append>
31 invokevirtual #9 <java/lang/StringBuilder.toString>
34 astore_1
35 return
解析:
- 对象1:new StringBuilder()
- 对象2 :new String("a")
- 对象3:常量池中的"a"
- 对象4:new String("b")
- 对象5:常量池中的”b“
深入剖析:StringBuilder的toString():
6. 对象6:new String("ab");强调一下:toString()的调用,在字符串常量池中,没有生成”ab“。不信你看字节码
题目三:
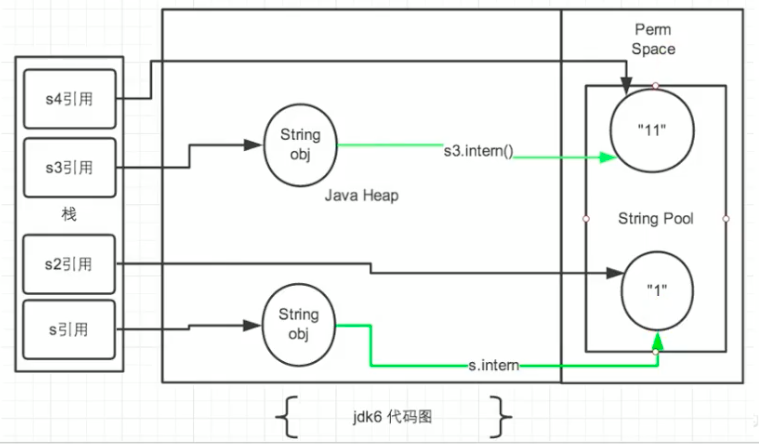
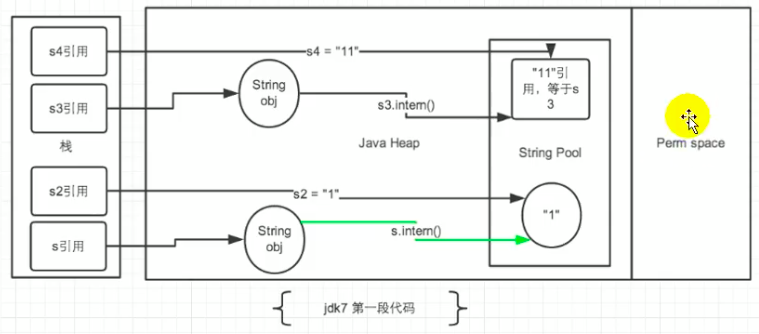
public class StringTest3 {
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1"); // s3变量记录的地址为:new String("11").但是常量池中没有”11“
// 执行完上一行代码以后,字符串常量池中,是否有”11“呢? 答案:不存在!!!
s3.intern(); // 在字符串常量池中生成”11“。如何理解:jdk6: 创建了一个新的对象”11“,也就有新的地址。
// jdk7: 此时常量中并没有创建”11“,而是创建一个指向堆空间中new String("11")的地址
String s4 = "11"; // s4变量记录的地址:使用的是上一行代码执行时,在常量池中生成的”11“的地址。
System.out.println(s3 == s4);
}
}
- 在jdk1.6中的结果为 false 、 false
- 在jdk1.7中的结果为 false 、 true
上题变形
public class StringTest6 {
public static void main(String[] args) {
String s3 = new String("1") + new String("1"); // new String("11")
// 执行完上一行代码,字符串常量池中,是否存在"11"呢?答案:不存在!!!
String s4 = "11";
String s5 = s3.intern();
System.out.println(s3 == s4); // false
System.out.println(s5 == s4); // true
}
}
总结String的intern()的使用:
-
jdk6中,将这个字符串对象尝试放入串池中。
* 如果串池中有,则并不会放入。返回已有的串池中的对象的地址
* 如果没有,会把此对象复制一份,放入串池,并返回串池中的对象地址。 -
jdk7起,将这个字符串对象尝试放入串池。
* 如果串池中有,则并不会放入。返回已有的串池中的对象的地址。
* 如果没有,则会把把对象的引用地址复制一份,放入串池,并返回串池中的引用地址。
intern()使用:练习1
jdk6:
jdk7:

变形
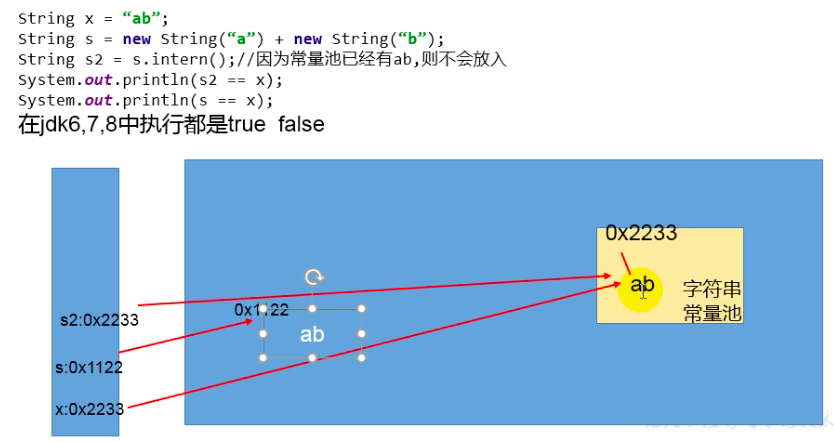
intern()使用:练习2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号