


区块链|肖臻《区块链技术与应用》公开课之以太坊篇
以太坊的帐户
account-based ledger:基于帐户的模型,系统会显示每个以太坊帐户的余额,类似于生活中的银行账户。这样的帐户设计天然地组织了 double spending attack(双花攻击),但是会遇到 replay attack(重放攻击)
replay attack(重放攻击):A 向 B 转账,转账完成后,B 又将这笔交易提交一次,节点会认为这是一笔新交易,又进行了广播
解决 replay attack 的方法:在交易中增加一个 nonce,用来记录这是转账方发送的第几次交易,在交易完成后,nonce 加一。这样节点在收到交易后,会先验证一下交易中的 nonce 值是否刚好比转账方当前的 nonce 值大 1,如果是则代表该交易不是 replay attack
以太坊分为以下两类帐户:
externally owned account(外部账户):也称普通帐户,用户通过私钥掌握该帐户,包含 balance(账户余额)和 nonce(发送交易数)
smart contract account(合约帐户):无法主动发起交易,同样包含 balance 和 nonce(用于记录被调用次数),除此之外还包含 code(合约代码)和 storage(存储,包含相关状态以及每个变量的取值)
以太坊中的状态树
以太坊地址有 160 个字节,一般表示成 40 个十六进制的数
状态树:包含了以太坊所有的地址帐户信息
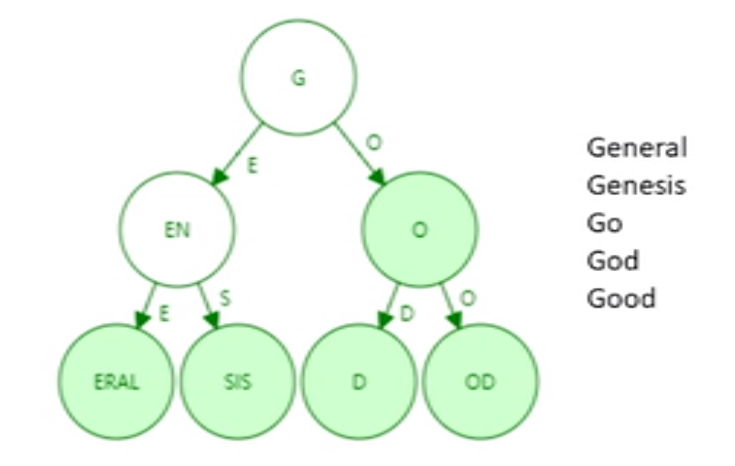
上图为 Patricia Tree 结构
以太坊使用的是 Modified MPT(Merkle Patricia Tree)结构,其中 MPT 是指在 Patricia Tree 的基础上将所有普通指针转换为哈希指针
MPT 的优点:
1. 只要根哈希不变,即证明整个树都没有被篡改
2. 证明某帐户有多少钱
3. 证明某帐户不存在
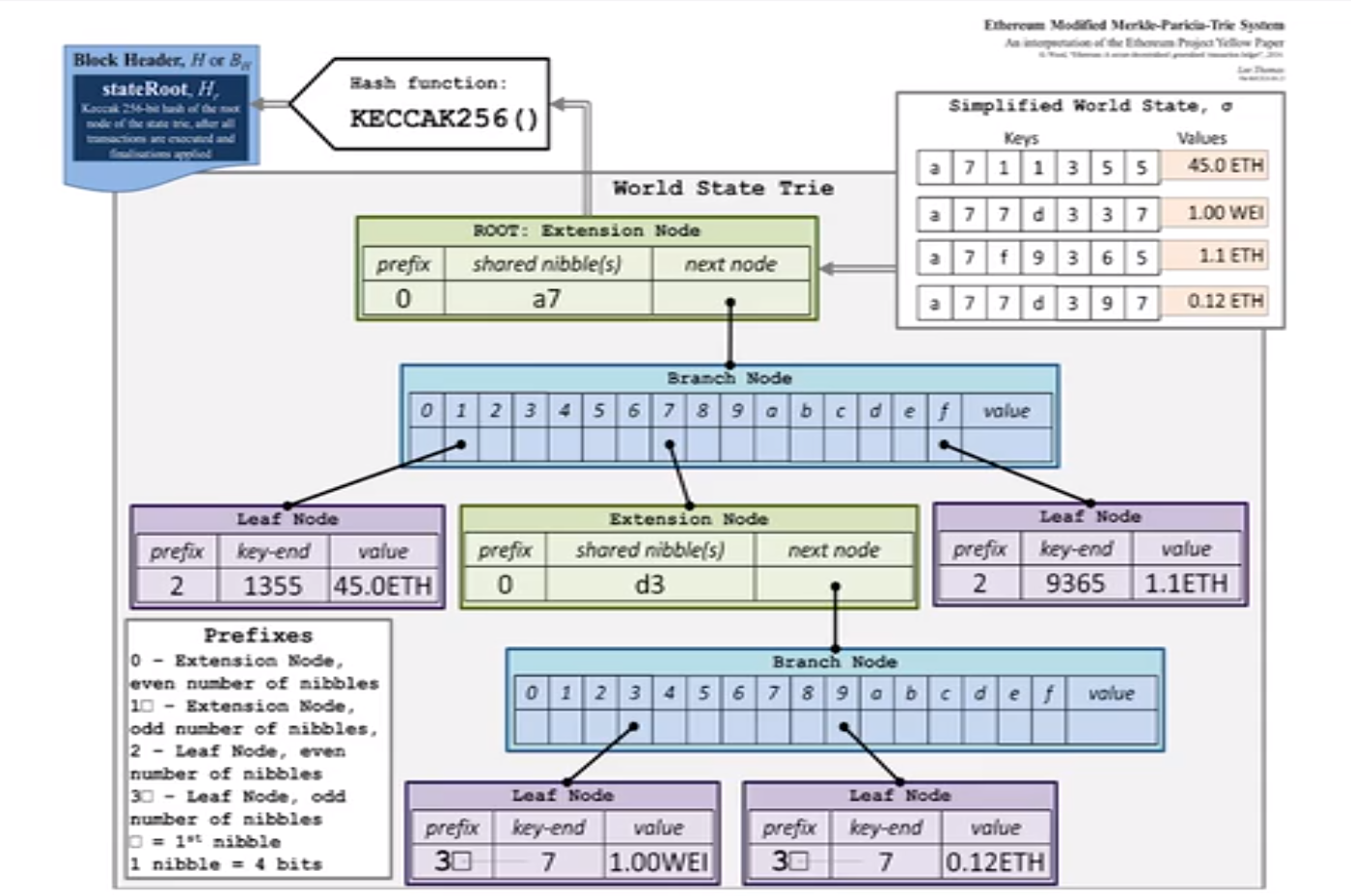
上图为以太坊 Modified MPT 状态树结构
以合约帐户为例,当帐户信息发生改变,会新建一个分支用来记录发生改变的信息,其中未发生变化的信息会指向上一个分支中对应的信息,下图中的 Nonce、Balance 和 Storage 中第 3 个分支的第 3 层发生了改变,而 Code 未发生改变,因而 Code 指向上一个分支中的 Code,Storage 第 1、2 分支以及第 3 分支的第 1、2 层也指向上一个分支中对应的分支。在合约账户中,可以将 Storage 也视为一个 MPT。

以合约帐户为例,展示账户信息修改后的 MPT
Q:为什么要保留原来的帐户信息?
A:1. 是为了保证在以太坊产生分叉时,最短链的区块回滚账户信息
2. 是因为以太坊的智能合约执行后,无法通过执行后的结果推出执行前的帐户信息,因而需要保留原来的账户信息以便回看
以太坊中的交易树和收据树
除状态树外,以太坊还有交易树和收据树
交易树:每次发布一个区块时,区块里的交易会组成一棵区块树,也是一棵 Merkle Tree,和比特币是类似的
收据树:每个交易执行完之后会生成一个收据,记录该交易的相关信息,交易树和收据树上的节点是一一对应的。以太坊智能合约执行过程比较复杂,通过收据树有利于快速查询执行的结果
GHOST 协议
因为以太坊出快速度较快,导致临时性分叉的出现变得十分常见。对于那些没有成为最长链的区块,GHOST 协议将其命名为 uncle block(叔父区块)。在后续的区块中可以包含 uncle block,且至多包含两个,被包含的 uncle block 可以得到 7/8 的出块奖励,包含 uncle block 的区块每包含一个 uncle block 可以额外 1/32 的出块奖励
uncle block(叔父区块):与当前区块在 7 代以内有相同的祖先区块,超过 7 代的 uncle block 即使被包含在新区块中,也得不到出块奖励,且每增加一代,uncle block 的奖励(uncle reward)减少 1/8,最少为 2/8
包含在新区块中的 uncle block 的交易是不会被执行的,因此新区块在发布前也无需检验 uncle block 中的交易是否合法,因为 uncle block 中的交易可能和主链上的交易重复
只有分叉后的第一个区块称为 uncle block,在这个分叉之后的不算,因为如果都算 uncle block,那么将大大降低分叉攻击的成本
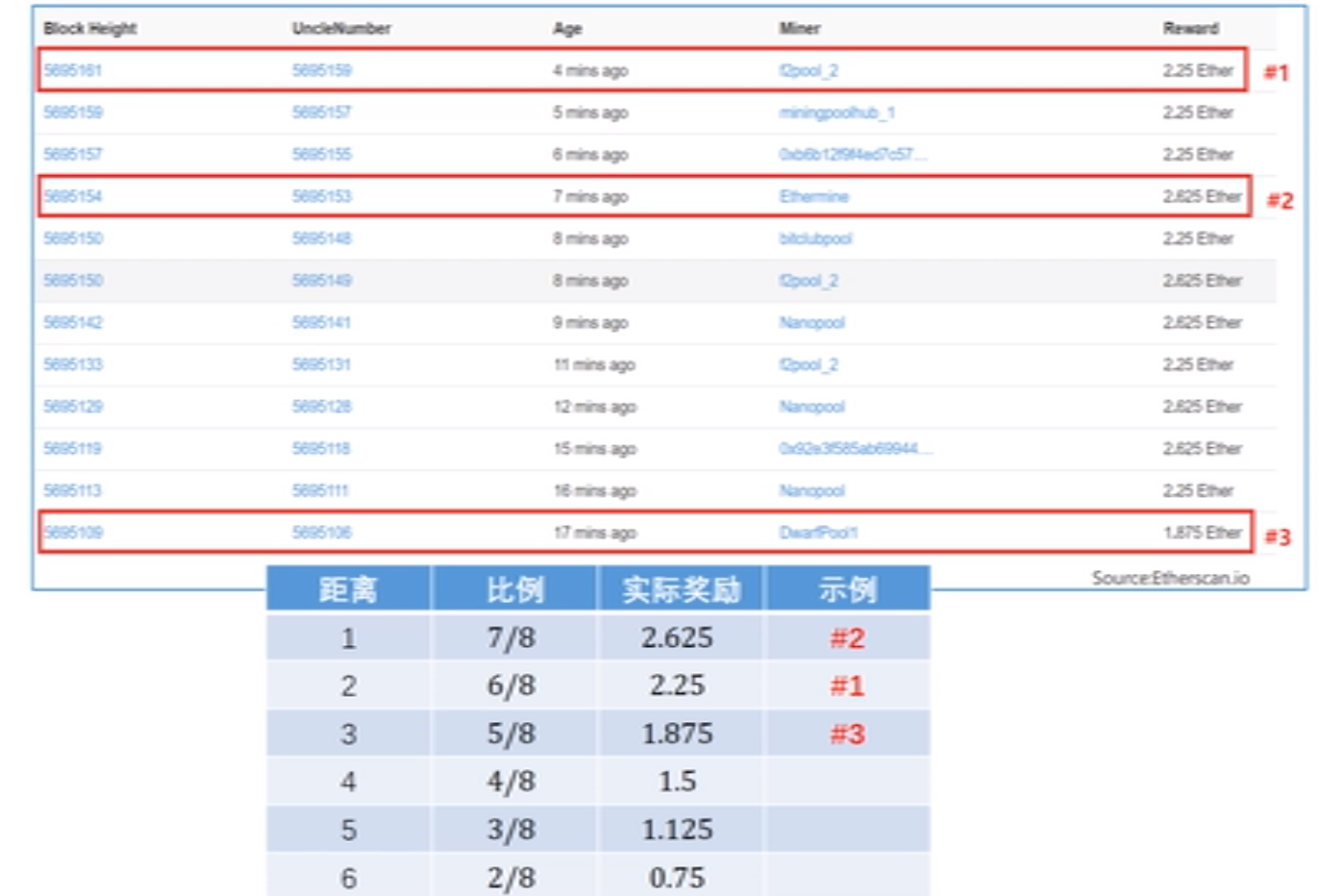
上图为 uncle block 的真实奖励(此时出块奖励为 3 ETH)
以太坊的挖矿算法
以太坊使用 2 个数据集,分别为:大小为 16M 的 cache 和大小为 1G 的 DAG,且数据集会不断增大,其中轻节点只需要保存 cache,而矿工需要保存 DAG
一、cache
通过 seed 计算 cache:对 seed 求哈希得到第一个元素,对第一个元素求哈希得到第二个元素,然后按照该规则依次生成后续的元素,即 cache 中元素按序生成,每个元素产生时与上一个元素相关。
每隔 30000 个块会重新生成 seed(新的 seed 由原来的 seed 取哈希值得),并且利用新的 seed 生成新的 cache。
cache 的初始大小为 16M,每隔 30000 个块重新生成时增大初始大小的 1/128 —— 128K。
二、dataset(DAG)
1. 先通过 cache 中的第 i% cache_size 个元素生成初始的 mix,因为两个不同的 dataset 元素可能对应同一个 cache 中的元素,为了保证每个初始 mix 都不同,i 也参与了哈希计算
2. 随后循环 256 次,每次根据当前的 mix 值求的下一个要访问的 cache 元素的下表,用这个 cache 元素和 mix 求得新的 mix 值。由于初始的 mix 值都不同,所以访问 cache 的序列也都是不同的
3. 最终返回 mix 的哈希值,得到第 i 个 dataset 中的元素
4. 多次调用这个函数,就可以得到完整的 dataset
当前以太坊挖矿通常使用 GPU
以太坊难度调整算法
一、基础



二、难度炸弹
Q:为什么设置难度炸弹?
A:设置难度炸弹的原因是要降低迁移到 PoS 协议时发生 fork 的风险;到时候挖矿难度非常大,所以矿工有意愿迁移到 PoS 协议。但是因为低估了 PoS 协议的开发难度,需要延长大概一年半的时间,而此时难度炸弹的威力已经显现,导致挖矿难度越来越大,所以在计算难度炸弹时将真正的区块号减去三百万,以此降低挖矿难度。

智能合约
一、基本概念
智能合约是运行在区块链上的一段代码,代码的逻辑定义了合约的内容。
智能合约的账户保存了合约当前的运行状态
· balance:当前余额
· nonce:交易次数
· code:合约代码
· storage:存储,数据结构是一棵 MPT
Solidity 是智能合约最常用的语言,语法上与 JavaScript 很接近。
二、智能合约的创建和运行
1. 智能合约的代码写完后,要编译成 bytecode
2. 创建合约:外部账户发起一个转账交易到 0x0 的地址
· 转账的金额是 0,但是要支付汽油费
· 合约的代码放在 data 域里
3. 智能合约运行在 EVM(Ethereum Virtual Machine)上
4. 以太坊是一个交易驱动的状态机
· 调用智能合约的交易发布到区块链上后,每个矿工都会执行这个交易,从当前状态确定性地转移到下一个状态
三、汽油费
1. 智能合约是个 Turing-complete Programming Model(图灵完备)
2. 执行合约中的指令要收取汽油费,由发起交易的人来支付
3. EVM 中不同指令消耗的汽油费是不一样的
四、错误处理
1. 智能合约中不存在自定义的 try-catch 结构
2. 一旦遇到异常,除特殊情况外,本次执行操作全部回滚
3. 如果遇到汽油费不足的情况,会将本次执行操作全不回滚,但已经用掉的汽油费不退回
五、嵌套调用
1. 智能合约的执行具有原子性:执行过程中出现错误,会导致回滚
2. 嵌套调用是指一个合约调用另一个合约中的函数
3. 嵌套调用是否会触发连锁式的回滚?
· 如果被调用的合约执行过程中发生异常,会不会导致发起调用的这个合约也跟着一起回滚?
· 有些调用方法会引起连锁式的回滚,有些则不会
4. 一个合约直接向一个合约账户里转账,没有指明调用哪个函数,仍然会引起嵌套调用

