
关于数据库优化2——关于表的连接顺序,和where子句的前后顺序,是否会影响到sql的执行效率问题
有好多时候,我们常听别人说大表在前,小表在后,包括现在好多百度出来的靠前的答案都有说数据库是从右到左加载的,所以from语句最后关联的那张表会先被处理。如果三表交叉,就选择交叉表来作为基础表。等等一些结论,但是这些真的正确么?我就回家做了一个小的验证,来看一看到底是怎么一回事。(博主作实验用的是Oracle,但是不代表只是Oracle是这样的原理,现在大部分的关系型数据库都是一样的)
首先我们来执行一下以下的sql语句,来看一下执行计划。看一看到底是怎么样的。
1 drop table tab_big; --删除原有big表 2 drop table tab_small; 3 create table tab_big as select * from dba_objects where rownum<=30000; --创建表,并且插入记录 4 create table tab_small as select * from dba_objects where rownum<=10; 5 set autotrace traceonly --开启执行计划和统计信息 6 set linesize 1000 7 set timing on 8 select count(*) from tab_big,tab_small; 9 select count(*) from tab_small,tab_big;
OK,完事后咱们来看一看,到底表的顺序到底是否会影响到数据库的执行效率,我们来看一下”select count(*) from tab_big,tab_small“和”select count(*) from tab_small,tab_big“的执行计划(图1为大表在前,小表在后。图2为小表在前)
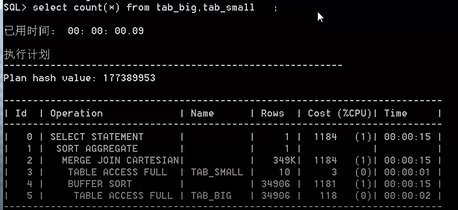

执行完后。我们惊奇的发现,居然他们耗费的资源和时间基本是一模一样的,所以说这个表的顺序会影响sql的执行效率是一个不对的结论,但是大部分网上评论和博客都是这么写的,真的是恶意谣言么?那咱们看一下下面这两条sql的执行效率。
然后我们执行下,下面的这两条sql。
1 select /*+rule*/ count(*) from tab_big,tab_small;--/*+rule*/基于规则执行 2 select /*+rule*/ count(*) from tab_small,tab_big;
接下来我们看一下这两条sql的执行计划。(图1为第一条sql大表在前,小表在后,图2为第二条sql,小表在前)

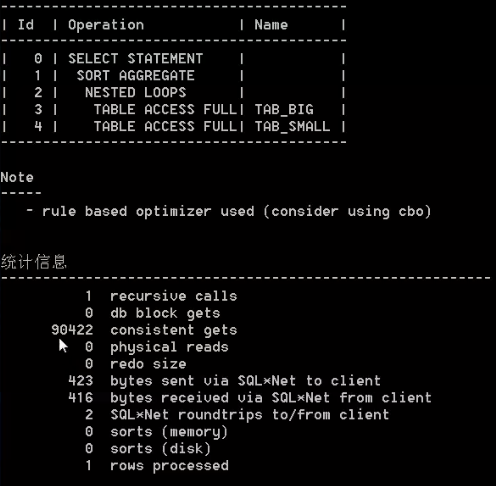
这个时候我们有惊奇的发现,这个就应了网上大部分的答案,说明他们说的也是有道理的。这其中是什么原因呢?根据我在翻阅各种资料和查阅官网后得知:原来早些的数据库版本是基于规则去处理的sql,也就是加上我们的/*+rule*/这个之后。但是现在我们的数据库都是基于代价的,所以也就不存在了表的顺序会影响sql的效率了。那我们的where其实也是一样的道理,也不会因为顺序去影响sql的效率。(where的结论博主也经过了执行验证,但是同理表连接,所以就不贴出来代码了)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号