软件系统设计方案-知乎爬虫
0 概述
这篇文章主要是针对一个对于知乎的数据进行爬取的爬虫程序,将进行软件系统的分析和设计,阐述使用的设计模式、软件架构风格与策略,并采用视图来描述软件系统的模型。进行数据库和核心数据结构的设计分析,最终形成软件系统概念原型。
项目简介:这是一个关于爬取知乎网数据的小程序,可以根据具体需求爬取当天的热榜数据,每一个热榜数据包括名称、时间、热度,每一个具体的回答包括用户名、回答、时间、点赞数、评论等相关信息。主要目的是获取数据。在获取数据的过程中,经历了数据清洗等过程。
1 项目的设计方案
首先先确定项目的架构风格和设计模式。
对于架构风格来说:典型的有管道-过滤器分割、批处理风格、黑板风格、资料库风格、层架构风格、发布订阅风格,以及现在流行的以网络为中心的样式风格等。
对于设计模式来说:典型的有工厂方法模式,单例模式,责任链模式,代理模式,外观模式等等。
1.1 架构风格
我们需要确定软件使用的架构风格,首先分析项目的需求,很简单,获取数据->数据清洗->存储信息,每一步都是紧接着上一步进行。考虑到成熟的软件架构风格:数据流风格:数据流样式的特征是将系统视为对连续输入数据的一系列转换,因此,我们可以选择管道-过滤器风格。
考虑到管道过滤器风格的优点:
- 易于添加和删除组件(有助于扩展)
- 允许并发/并行执行(有助于性能)
这正是符合我们设计的软件需要的风格

爬取到的数据必须先经过数据清洗验证才能存储起来,不能将数据直接跳过验证步骤,只有当前一步处理完,后一步处理才能开始。数据传输在步与步之间作为一个整体。
1.2 设计模式
设计模式是软件设计中常见问题的典型解决方案。 每个模式就像一张蓝图, 你可以通过对其进行定制来解决代码中的特定设计问题。
我们的程序主要是注重于行为,我们查看设计模式里的行为模式,我们可以发现,责任链模式与我们的软件具有深度的共同点,进一步的
责任链模式是一种行为设计模式, 允许你将请求沿着处理者链进行发送。 收到请求后, 每个处理者均可对请求进行处理, 或将其传递给链上的下个处理者。责任链会将特定行为转换为被称作处理者的独立对象。 在上述示例中, 每个检查步骤都可被抽取为仅有单个方法的类, 并执行检查操作。 请求及其数据则会被作为参数传递给该方法。
我们给出大致的UML类图
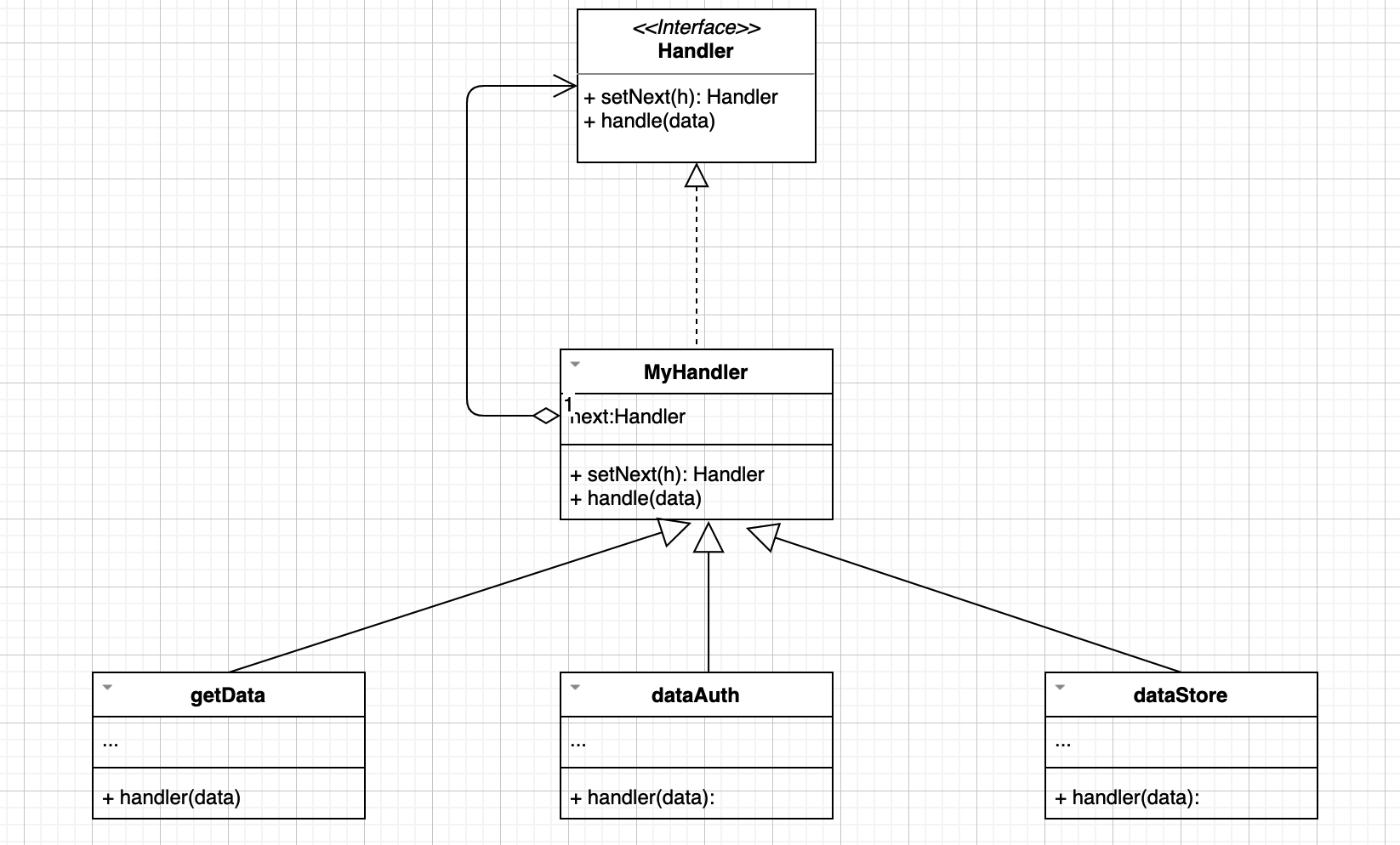
伪代码如下:
// 基类接口
interface Handler
method setNext() //设置下一个调用的类
method handler() //具体的处理函数
class MyHandler implements Handler
field next //下一个处理的类
method setNext() //设置下一个调用的类
method handler() //具体的处理函数
class getData extends MyHandler
... //上面的next、setNext、field
method handler() //具体的爬取数据处理函数
class dataAuth extends MyHandler
... //上面的next、setNext、field
method handler() //具体的验证清洗数据处理函数
class dataStore extends MyHandler
... //上面的next、setNext、field
method handler() //具体的存储处理函数
main(){
g=new getData()
d=new dataAuth()
s=new dataStore()
g.setNext(d)
d.setNext(s)
g.handler()
}
此外,还可以采用外观模式,为上述复杂的代码提供一个简单的接口,这里不再赘述
2 数据库设计与核心数据结构
数据库的设计采取文档数据库MongoDB,能够存储多样化的数据信息
| 序号 | 说明 | 名称 | 类型 | 长度 | 主键 |
|---|---|---|---|---|---|
| 1 | 编号 | _id | Int | 32 | Y |
| 2 | 作者名 | author_name | string | 不限 | N |
| 3 | 评论数 | comment_count | Int | 32 | N |
| 4 | 点赞数目 | veteup_count | Int | 32 | N |
| 5 | 内容 | content | string | 不限 | N |
| 6 | 摘要 | excerpt | string | 不限 | N |
| 7 | 问题id | question_id | string | 不限 | N |
| 8 | 创建时间 | Create_time | data | 不限 | N |
2.1 接口API
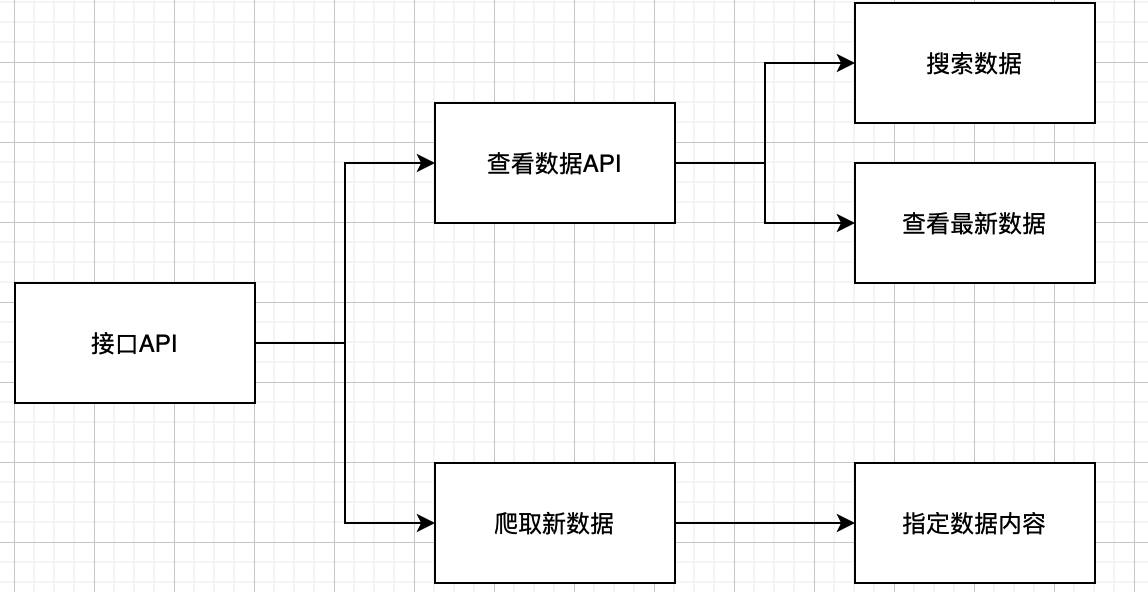
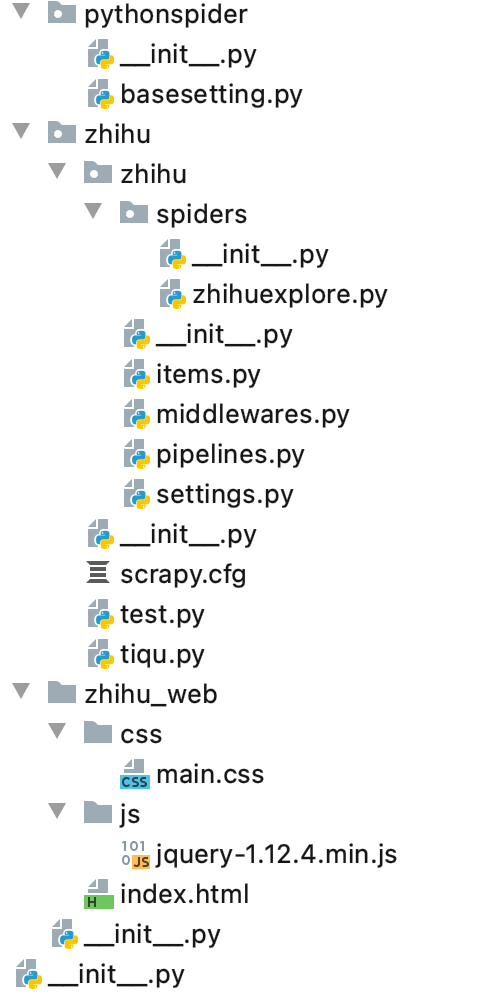
3 项目的目录文件结构
项目文件的目录结构如下:
4 项目视图
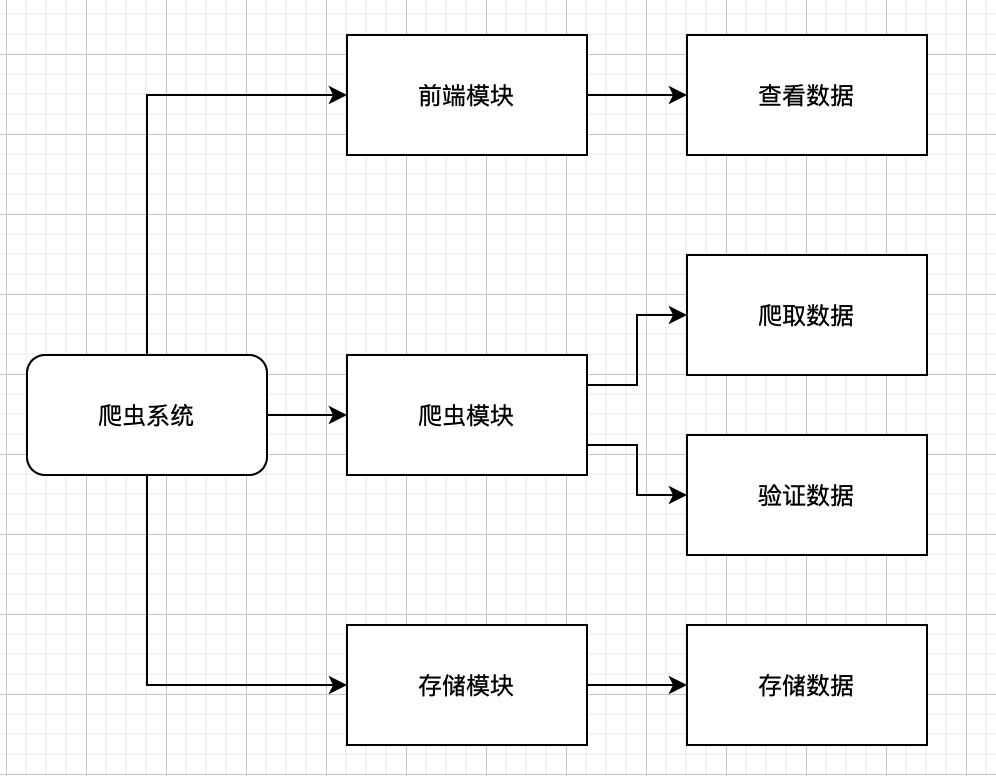
4.1 分解视图
分解是构建软件架构模型的关键步骤,分解视图也是描述软件架构模型的关键视图,一般分解视图呈现为较为明晰的分解结构(breakdown structure)特点。分解视图用软件模块勾划出系统结构,往往会通过不同抽象层级的软件模块形成层次化的结构。组件主要有类、软件模块、软件单元、子系统等。
分解视图如下:
4.2 依赖视图
依赖视图展现了软件模块之间的依赖关系。比如一个软件模块A调用了另一个软件模块B,那么我们说软件模块A直接依赖软件模块B。如果一个软件模块依赖另一个软件模块产生的数据,那么这两个软件模块也具有一定的依赖关系。
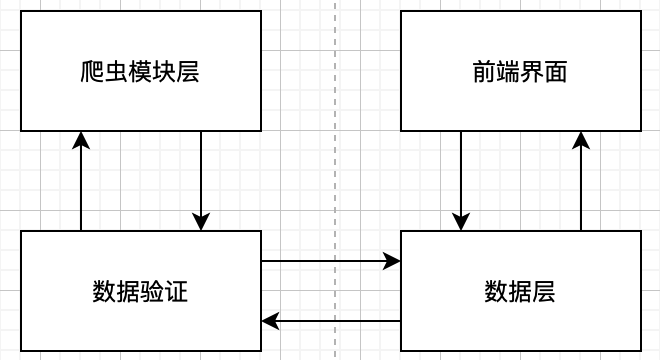
4.3 泛化视图
泛化视图展现了软件模块之间的一般化或具体化的关系,典型的例子就是面向对象分析和设计方法中类之间的继承关系。值得注意的是,采用对象组合替代继承关系,并不会改变类之间的泛化特征。因此泛化是指软件模块之间的一般化或具体化的关系,不能局限于继承概念的应用。
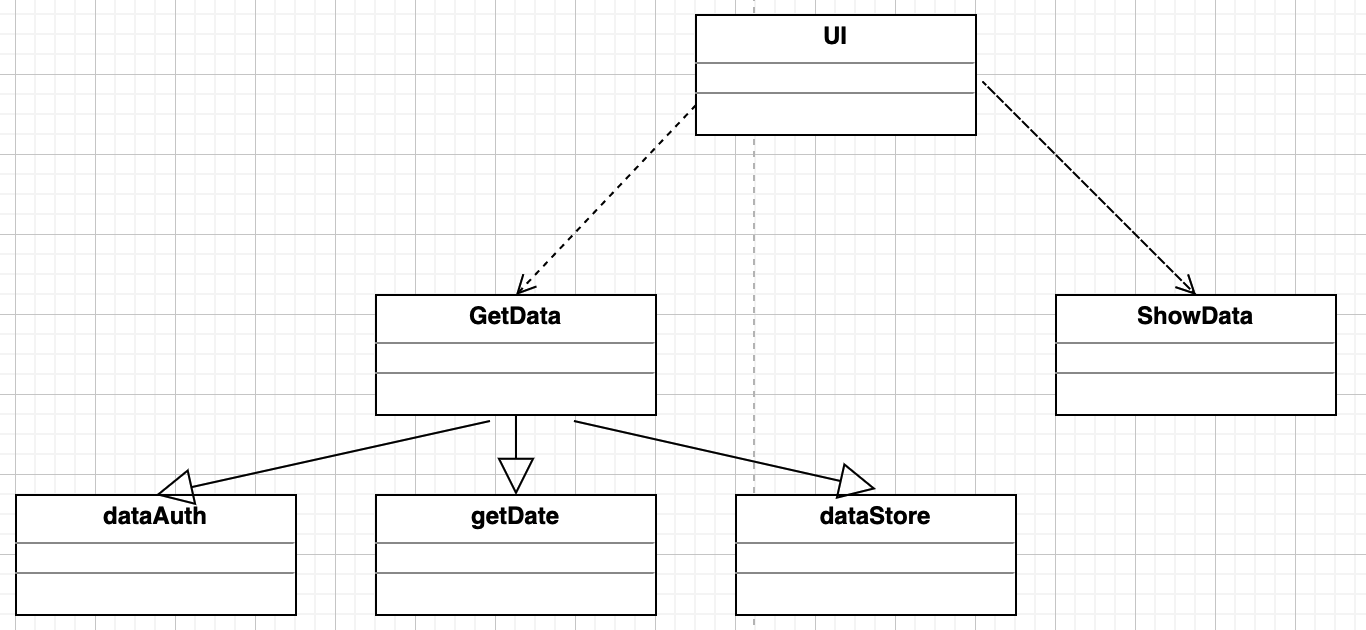
在用户可以使用的UI类里,用户可以进行爬取数据和查看数据,相应的子类再去调用具体的功能
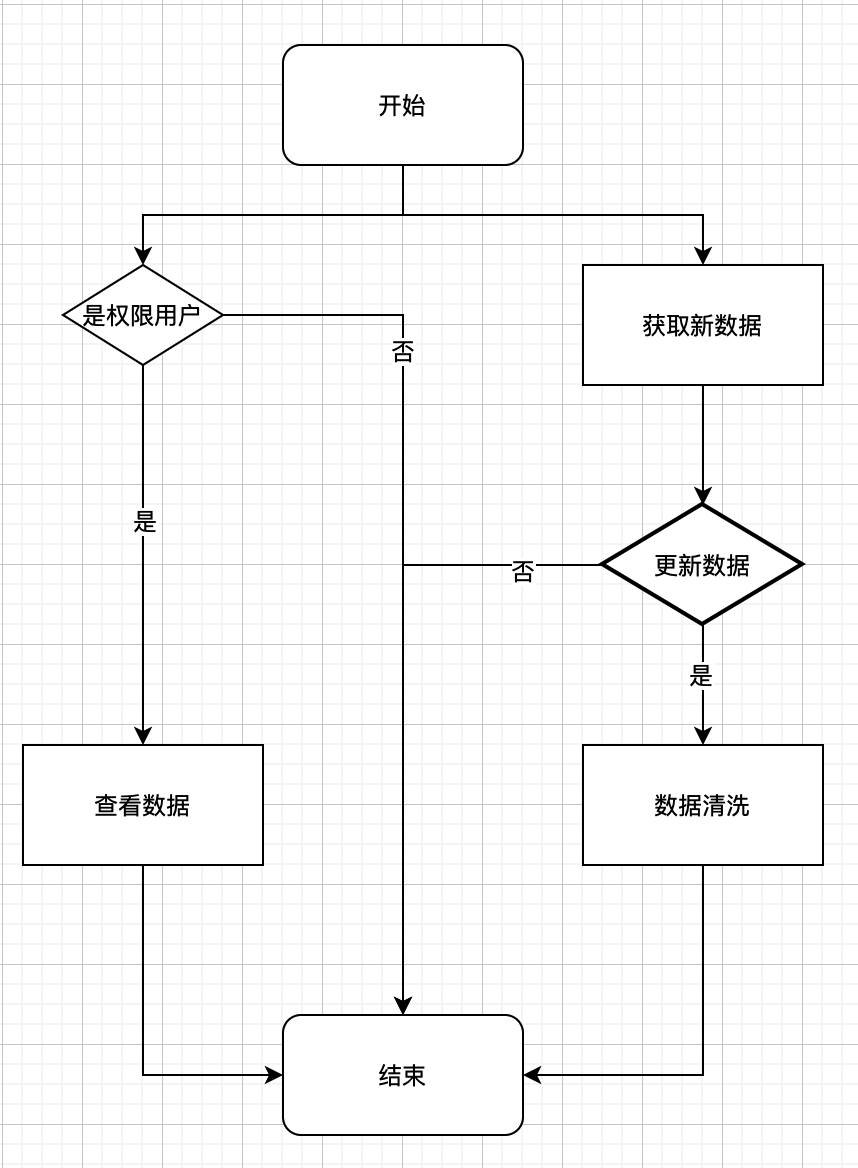
4.4 执行视图
执行视图展示了系统运行时的时序结构特点,比如流程图、时序图等。执行视图中的每一个执行实体,一般称为组件(Component),都是不同于其他组件的执行实体。如果有相同或相似的执行实体那么就把它们合并成一个。
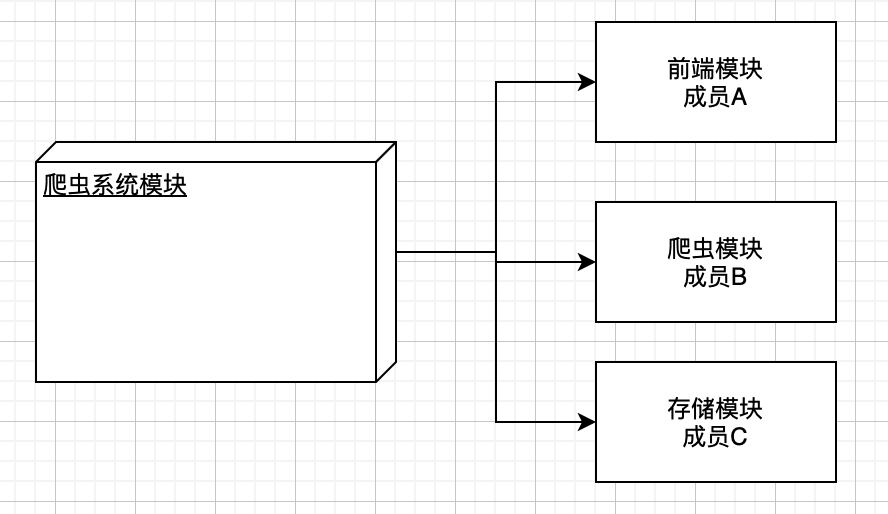
4.6 工作分配视图
工作分配视图将系统分解成可独立完成的工作任务,以便分配给各项目团队和成员。工作分配视图有利于跟踪不同项目团队和成员的工作任务的进度,也有利于在个项目团队和成员之间合理地分配和调整项目资源,甚至在项目计划阶段工作分配视图对于进度规划、项目评估和经费预算都能起到有益的作用。
此外还有一些其他视图
4.7 开发视图
开发视图:着重于软件开发环境中实际软件模块的组织。也称模块视图,主要侧重于软件模块的组织和管理。主要是在编程人员视角的视图
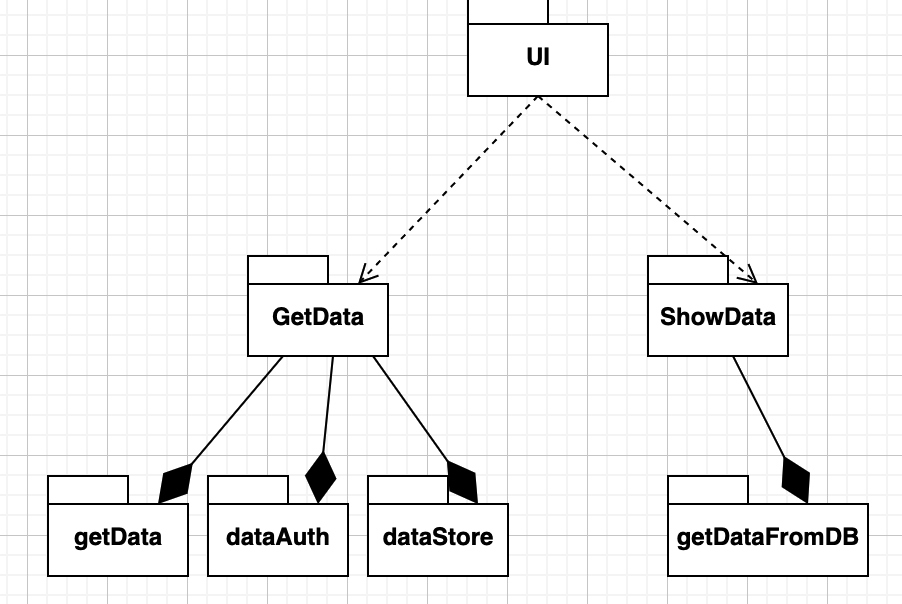
对于开发人员来说,多加了一步在展示数据的时候从数据库获取数据
4.8进程视图
侧重于系统的运行特性,主要关注一些非功能性的需求,如性能和系统的可用性。强调并发性、分布性、系统集成性和容错能力。
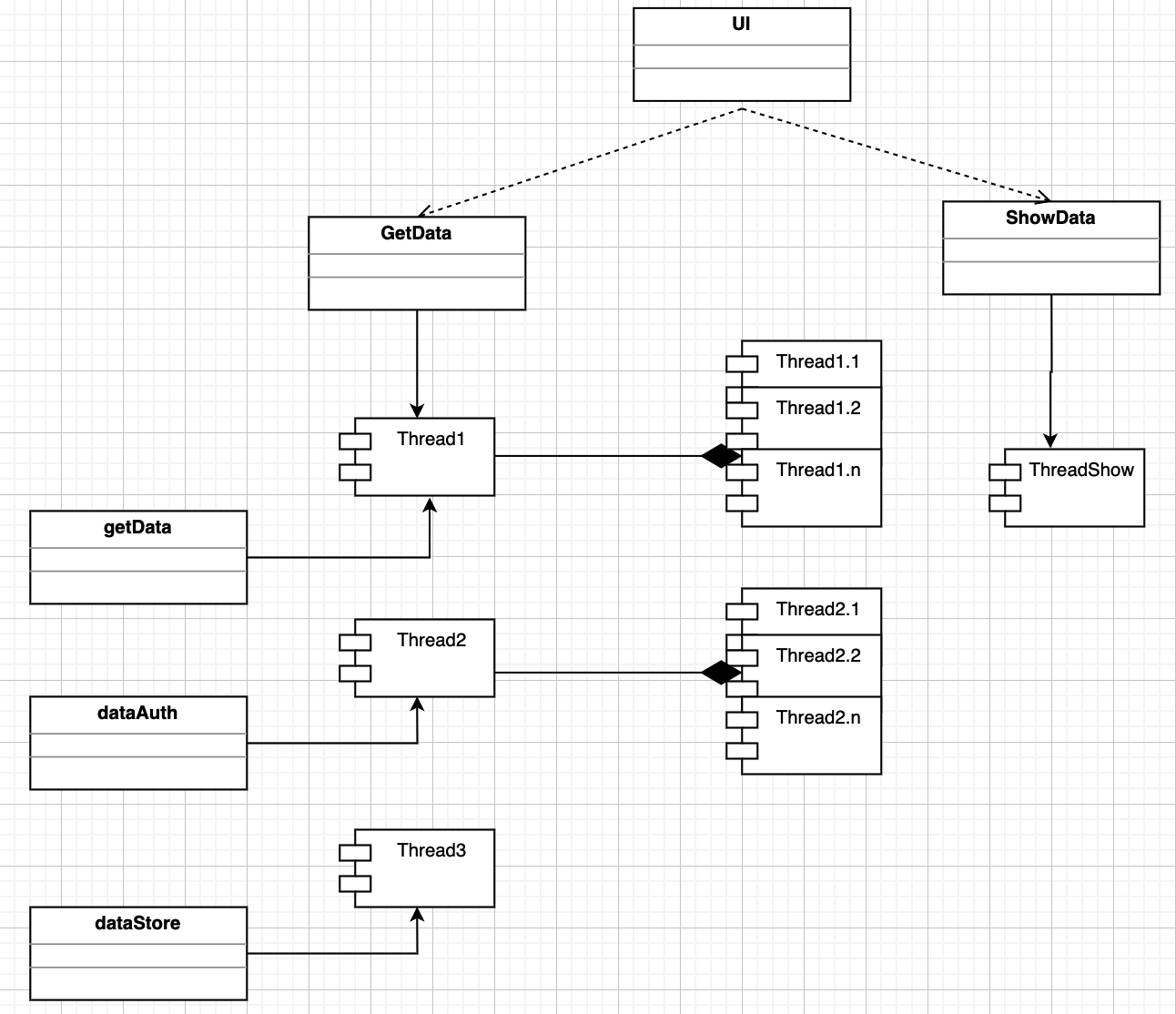
对于每一个获取数据和数据验证清洗的时候可以并行执行
4.9 部署视图
主要考虑系统的非功能性需求,如系统可用性、可靠性(容错)、性能(吞吐量)以及规模。
主要侧重于硬件方面

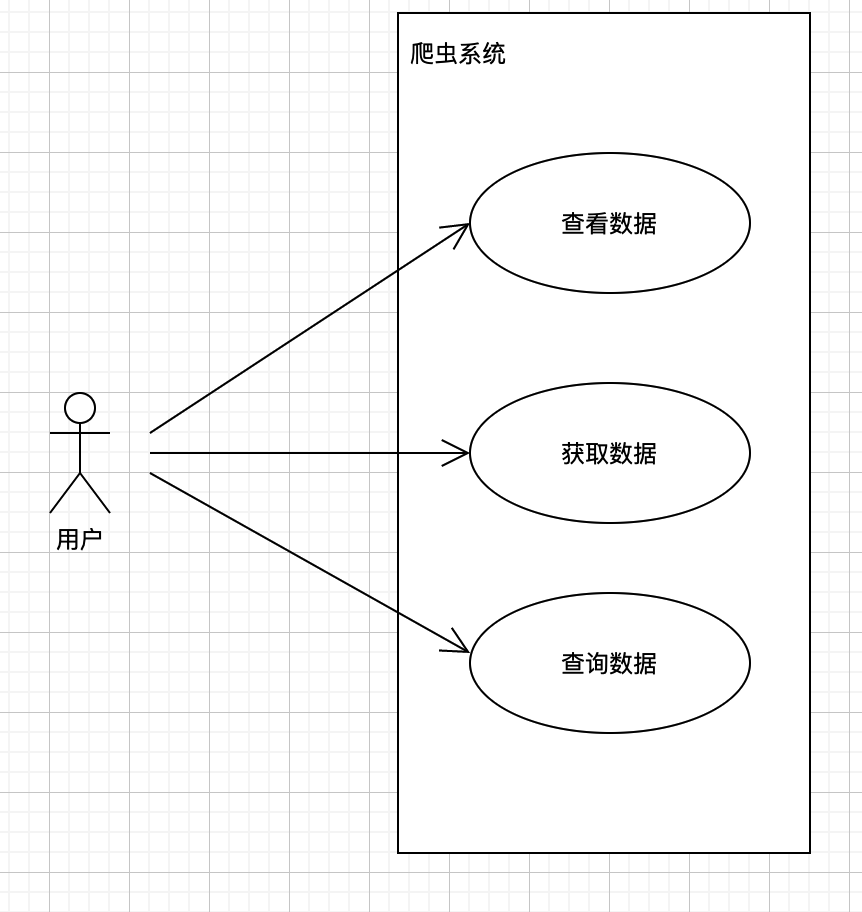
4.10 用例图
在开发体系结构时,用例图可以帮助设计者找到体系结构的构件和它们之间的作用关系。可以用用例图来分析一个特定的视图,或描述不同视图构件间是如何相互作用的。
5 运行环境和技术选型
结合项目的分析,决定使用python语言作为项目的主要语言。基于Scrapy库实现爬虫的爬取,旨在快速、便捷的实现一个有一定并发量的爬取数据部分。在数据验证清洗部分和数据存储部分,则根据自己的实际寻求手动实现相关类的操作。另外,项目还开发了一个前端界面,结合HTML、CSS、JavaScript技术以及flask库实现前端的开发。数据库方面则使用MongoDB来存储获得到的数据。实现前后端的分离操作。
6 系统概念原型的核心工作机制
每个视图都是从不同的角度对软件架构进行描述和建模,比如从功能的角度、从代码结构的角度、从运行时结构的角度、从目录文件的角度,或者从项目团队组织结构的角度。
软件架构代表了软件系统的整体设计结构,它应该是所有这些视图的集合。但我们不会将不同角度的这些视图整合起来,因为不便于阅读和更新。不过我们会有意识地将不同角度的视图之间的映射关系和重叠部分了然于胸,从而深刻理解软件架构内在的一致性和完整性,这就是系统概念原型。
整个概念模型的工作过程为:
用户这个用程序下达执行命令,系统开始根据知乎网的数据进行信息的爬取,在爬取过程中多开线程并行执行,在数据爬取到本地以后,将数据进行验证清洗,剔除不合理和没有高价值的数据。最后一步将验证清洗后的数据存储到数据库中。
当用户要查看数据的时候,打开一个网络界面,从数据库取数据,然后展示给用户。
7 总结
这篇文章主要讲述了一个 知乎爬虫程序的设计方案,给出了架构选择,设计模式的选择,数据库设计和核心数据结构的分析,给出了项目的视图,因为才疏学浅,可能有不足之处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号