leetcode 528/ LCR 071 按权重随机选择
题目描述
给定一个正整数数组 w ,其中 w[i] 代表下标 i 的权重(下标从 0 开始),请写一个函数 pickIndex ,它可以随机地获取下标 i,选取下标 i 的概率与 w[i] 成正比。
例如,对于 w = [1, 3],挑选下标 0 的概率为 1 / (1 + 3) = 0.25 (即,25%),而选取下标 1 的概率为 3 / (1 + 3) = 0.75(即,75%)。
也就是说,选取下标 i 的概率为 w[i] / sum(w) 。
示例 1:
输入:
inputs = ["Solution","pickIndex"]
inputs = [[[1]],[]]
输出:
[null,0]
解释:
Solution solution = new Solution([1]);
solution.pickIndex(); // 返回 0,因为数组中只有一个元素,所以唯一的选择是返回下标 0。
示例 2:
输入:
inputs = ["Solution","pickIndex","pickIndex","pickIndex","pickIndex","pickIndex"]
inputs = [[[1,3]],[],[],[],[],[]]
输出:
[null,1,1,1,1,0]
解释:
Solution solution = new Solution([1, 3]);
solution.pickIndex(); // 返回 1,返回下标 1,返回该下标概率为 3/4 。
solution.pickIndex(); // 返回 1
solution.pickIndex(); // 返回 1
solution.pickIndex(); // 返回 1
solution.pickIndex(); // 返回 0,返回下标 0,返回该下标概率为 1/4 。
由于这是一个随机问题,允许多个答案,因此下列输出都可以被认为是正确的:
[null,1,1,1,1,0]
[null,1,1,1,1,1]
[null,1,1,1,0,0]
[null,1,1,1,0,1]
[null,1,0,1,0,0]
......
诸若此类。
提示:
1 <= w.length <= 100001 <= w[i] <= 10^5pickIndex将被调用不超过10000次
解答
第一直觉解答(超时)
根据题目所述:需要随机取下标,但是要保证下标的比例,会很容易想到构建一个按照比例存放的数组,然后随机从中取出下标
例如:
当w = [3, 1, 2]时,我构建一个下标数组:indexArr = [0, 0, 0, 1, 2, 2],再随机从indexArr 中随机取下标,就能保证0、1、2的比例为w数组所确定的3: 1: 2
代码:
class Solution {
#indexArr: number[] = [];
constructor(w: number[]) {
for (let i = 0; i < w.length; i++) {
this.#indexArr = this.#indexArr.concat(new Array(w[i]).fill(i));
}
}
pickIndex(): number {
return this.#indexArr[Math.round(Math.random() * (this.#indexArr.length - 1))];
}
}
但是此方法在数据量特别大的时候会出现超时,导致无法通过leetcode测试用例:
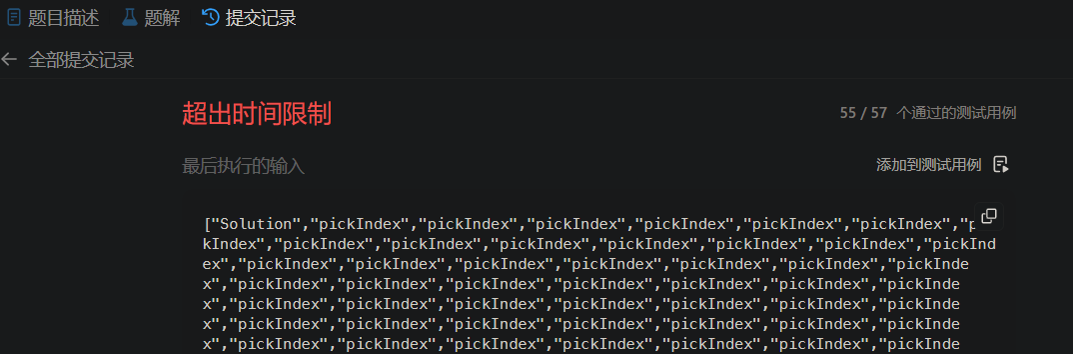
超时的原因在于concat与fill方法分别为O(n+m)与O(m)的时间复杂度,再在外面套一层遍历w的for循环导致时间复杂度上升到O(n^2),而本题是有O(n)时间复杂度的解法的,所以这里无法通过测试。
前缀和+二分法
这种方法本质上也是想办法按照比例“拉长”下标数组(例如上述例子,将[3, 1, 2]拉长为[0, 0, 0, 1, 2, 2]),此方法是根据前缀和的特点将[3, 1, 2]“视作”为[1, 2, 3, 4, 5, 6],再从1至6中取随机数,当随机数为1或2或3时,返回下标0;当随机数为4时,返回下标1;当随机数为5或6时,返回下标2。这样也能保证取出的随机数比例是3: 1: 2。
方法原理:
当w = [3, 1, 2]时,构建前缀和数组[3, 4, 6],如果此时我们从1开始,在脑海或者草稿纸上使用虚拟的数字填满1至6,可知比例确实是3: 1: 2

代码逻辑
根据上面所述,我们的函数逻辑只需要构建前缀和数组,然后随机取1到前缀和数组的最后一项的值,然后在前缀和数组中找到刚好大于或等于该随机值的数组元素,然后返回此数组元素对应的下标即可。
class Solution {
#suffixSumArr: number[];
constructor(w: number[]) {
let sum = 0;
// 构建前缀和数组
this.#suffixSumArr = w.map((num) => (sum += num));
}
pickIndex(): number {
const randomNum = Math.random() * this.#suffixSumArr.at(-1)! - 1 + 1;
// 寻找刚好大于randomNum的前缀和数组元素的下标
let i = 0;
while (true) {
if (this.#suffixSumArr[i] >= randomNum) return i;
i++
}
}
}
此时方法还有优化空间,可以采用二分法将“寻找刚好大于等于随机数的前缀和数组元素的下标”这一步的时间复杂度由O(n)进一步优化到O(logn)
class Solution {
#suffixSumArr: number[];
constructor(w: number[]) {
let sum = 0;
// 构建前缀和数组
this.#suffixSumArr = w.map((num) => (sum += num));
}
pickIndex(): number {
const randomNum = Math.random() * this.#suffixSumArr.at(-1)! - 1 + 1;
let l = 0;
let r = this.#suffixSumArr.length;
// 二分法查找刚好大于或等于randomNum的值的下标
while (true) {
const middle = (l + r) >> 1;
const middleNum = this.#suffixSumArr[middle];
const middleLeftNum = this.#suffixSumArr[middle - 1] ?? -Infinity;
if (middleNum < randomNum) {
// middle下标对应值过小
l = middle + 1;
continue;
} else if (middleLeftNum >= randomNum) {
// middle下标对应值过大
r = middle - 1;
continue;
}
return middle;
}
}
}
gpt总结
这段代码是一个基于权重随机选择索引的解决方案。其主要思路是通过构建一个前缀和数组,然后利用二分查找的方式,在这个数组中随机选择一个索引。下面是针对该代码的详细分析:
- 算法逻辑: 该算法首先通过输入的权重数组
w构建一个前缀和数组#suffixSumArr。构建过程中,每个元素的值等于它之前所有元素的和(包括自身),这样可以根据元素值的大小反映出它的权重。接着,在pickIndex方法中,算法生成一个介于0到前缀和数组最后一个元素值之间的随机数。通过二分查找,算法寻找到一个索引,使得该索引对应的前缀和刚好大于或等于这个随机数,这样根据权重随机选择索引的目的得以实现。 - 变量解释:
#suffixSumArr:一个私有数组,存储输入数组w的前缀和。前缀和数组的每个元素代表了到当前位置为止,所有输入权重的累计和。w:构造函数的输入参数,一个包含非负整数的数组,代表每个索引的权重。sum:局部变量,用于在构建前缀和数组时,累加权重。randomNum:在pickIndex方法中生成的随机数,用于根据权重随机选择一个索引。l和r:二分查找过程中使用的左右指针,用于定位前缀和数组中的搜索范围。middle:二分查找过程中的中间索引。middleNum和middleLeftNum:分别代表中间索引及其左侧索引在前缀和数组中的值。
- 关键代码分析:
- 前缀和数组的构建:
this.#suffixSumArr = w.map((num) => (sum += num));。这一步是算法的基础,通过累加输入数组的元素,构建了一个前缀和数组。 - 二分查找:
while循环体内通过二分法逐步缩小搜索范围,直到找到随机数对应的权重索引。
- 前缀和数组的构建:
- 性能分析:
- 时间复杂度:构造函数的时间复杂度为O(N),其中N是输入数组
w的长度,因为需要遍历一次数组来构建前缀和数组。pickIndex方法的时间复杂度为O(logN),因为采用了二分查找。 - 空间复杂度:O(N),主要空间开销来源于前缀和数组
#suffixSumArr,其大小与输入数组w相同。
- 时间复杂度:构造函数的时间复杂度为O(N),其中N是输入数组
- 适用场景: 这种算法适用于需要根据不同的权重随机选择元素的场景,例如负载均衡中根据服务器的处理能力分配请求、在线抽奖系统中根据不同奖项的中奖概率抽取奖项等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号